Elasticsearch ES|QL 中的近似查询:在数十亿条记录上实现百倍加速,并内置置信区间

Elasticsearch ES|QL 中的近似查询:在数十亿条记录上实现百倍加速,并内置置信区间

点火三周
发布于 2026-05-20 15:11:55
发布于 2026-05-20 15:11:55
Elasticsearch ES|QL 中的近似查询:在数十亿条记录上实现百倍加速,并内置置信区间
立即动手体验 Elasticsearch:深入了解 Elasticsearch Labs 代码库 中的示例笔记本,开始 免费云试用,或现在就在你的 本地机器上试用 Elastic。
只需在任何 Elasticsearch 查询语言 (ES|QL) 查询中添加一行,即可在数十亿文档上获得快 100 倍以上的答案。数据量越大,性能提升越显著。内置的置信信号会告诉你何时结果带有正式保证,何时是最佳估计。
一行代码:随数据增长而扩展的速度
在处理数十亿文档时,分析查询面临着真实的效率与精度权衡。我们一直致力于突破这一限制。我们的 原生列式存储支持 是业界领先的技术之一。ES|QL 本身就是一个快速、专为分析而构建的引擎,在聚合执行方面也越来越智能。Elasticsearch 也持续推出各种效率创新,例如 Block k-dimensional (BKD) 树剪枝 等,并且新的创新不断涌现。
即便如此,原生的近似查询依然表现出色。从 Elasticsearch 9.4 开始,ES|QL 支持近似查询执行。你所要做的只是在查询中添加一行:在查询前加上 SET approximation = true。现在,Elasticsearch 将自动抽取数据子集,在该样本上运行聚合,推断结果,并报告置信区间。所有这些都透明地进行。
1
2
3
4
SET approximation = true;
FROM logs-*
| STATS count = COUNT(*) BY time = BUCKET(@timestamp, 5 MINUTE)
| SORT time
你现有的查询保持不变。SET 指令告诉 Elasticsearch 为你处理采样、推断和统计验证。无需重写查询,无需手动计算采样,也无需猜测采样概率。
SET approximation = true 是一个向前兼容的指令。目前,它能加速最常用的聚合。随着我们扩展对更多功能的支持,你现有的查询将自动受益。尚未支持近似的查询将准确无误地运行;一个警告头会解释原因。
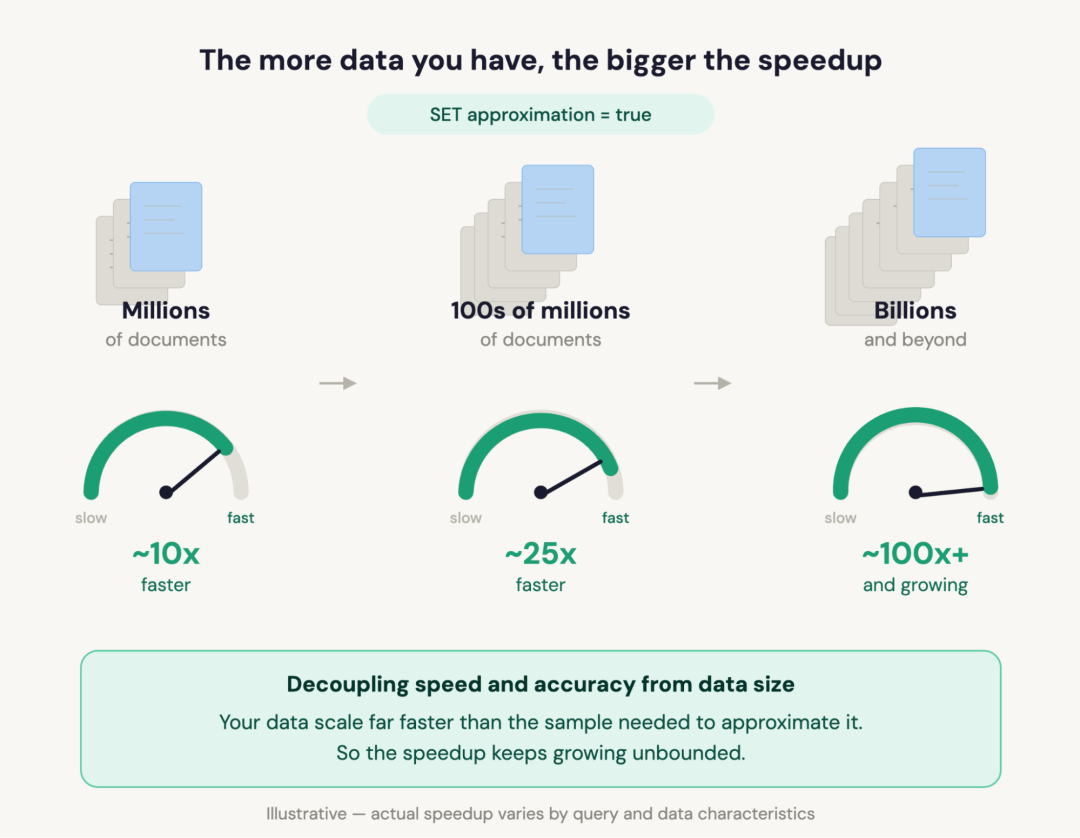
究竟有多快?
在 ClickBench 基准测试中,开启置信区间后,运行良好的分析查询平均快了 23 倍。单个查询达到了 约 100 倍。如果禁用置信区间计算,最高效的查询甚至能接近 约 300 倍。
alt
这种优势会随着数据集的增长而增加。近似模式的成本受限于配置的样本大小,而精确执行的成本则与行数成比例。索引翻倍会使精确查询时间翻倍,但对相同精度的近似查询时间几乎没有影响!这是底层数学的一个优美特性,而非工程技巧,这也是为什么近似查询在规模化时变得更有价值的原因。
加速效果还取决于查询结构、分组基数和样本大小。有关所有因素和调优技巧,请参阅 FAQ。请直接阅读此功能创建者撰写的“快速近似 ES|QL”两部分文章(第一部分,第二部分)。
你能获得什么?
响应中包含你原始的聚合值,这些值已自动按比例缩放以代表完整数据集;例如,对 1% 样本的 COUNT 返回的是估计的总数,而非样本计数。列名和类型都得以保留(向后兼容)。此外,每个近似值还会额外增加两列:
- • 置信区间 (Confidence Interval):在配置的置信水平(默认为 90%)下,限定真实值范围的区间。例如,计数为 268,473,区间为 [264,444–273,179],意味着你有 90% 的信心认为真实计数落在此范围内。
- • 认证标志 (Certified Flag):一个布尔值,表示该值的置信区间是否符合正式的统计保证。当
certified为true时,数据分布允许我们直接依赖结果。当false时,近似值通常仍然很接近,但我们无法声明相同的正式保证,这通常是因为分布可能高度偏斜或涉及组中文档过少。可以将其理解为“统计学证明”和“最佳估计”之间的区别。

alt
这是一个经过深思熟虑的设计选择:不关心置信元数据的消费者可以选择完全不计算它们(参见“需要时进行精细控制”)或忽略额外的列并像以前一样使用结果。而关心的消费者(例如以编程方式读取结果的 AI 代理)则无需第二次查询即可获得所需的一切。
ES|QL 中近似查询的用例:它在哪里发挥作用?
AI 代理和代理工作流
近似查询不仅能加速代理查询;它们还支持一种以前在大规模场景下不切实际的“扫描-增强”调查模式。代理可以在亚秒级时间内扫描数十亿文档,识别候选对象,并深入获取精确答案,所有这些都在一个推理循环中完成。certified 标志将近似转化为决策信号:当它为 true 时,直接按结果进行;当它为 false 且该步骤需要严格保证时,则升级为精确查询。随着 ES|QL 成为 Elastic 中代理分析的基础,近似查询是实现这种规模调查的速度层。
大型数据集上的仪表板和图表
随着数据量的增长,聚合数周或数月数据的仪表板可能会变得迟缓。通过 SET approximation = true,相同的仪表板加载速度更快。未来,Kibana 将透明地注入此设置,因此用户无需知道它的发生;他们只会看到更快的图表。
ES|QL 中大规模日志模式分析
CATEGORIZE、GROK 和大量使用正则表达式的条件是 ES|QL 中计算最密集的部分之一,因为它们需要对每个文档进行非平凡的计算。启用近似执行后,这些大规模的模式和探索性工作流在超大型索引上变得可行。
探索性分析和假设检验
当你探索数据以形成假设时,例如“本周哪些服务的错误率最高?”,你很少需要精确的计数。你需要的是趋势、相对大小和异常值。近似模式以交互式速度为你提供这些,而置信区间会告诉你何时切换回精确模式以获取最终答案。
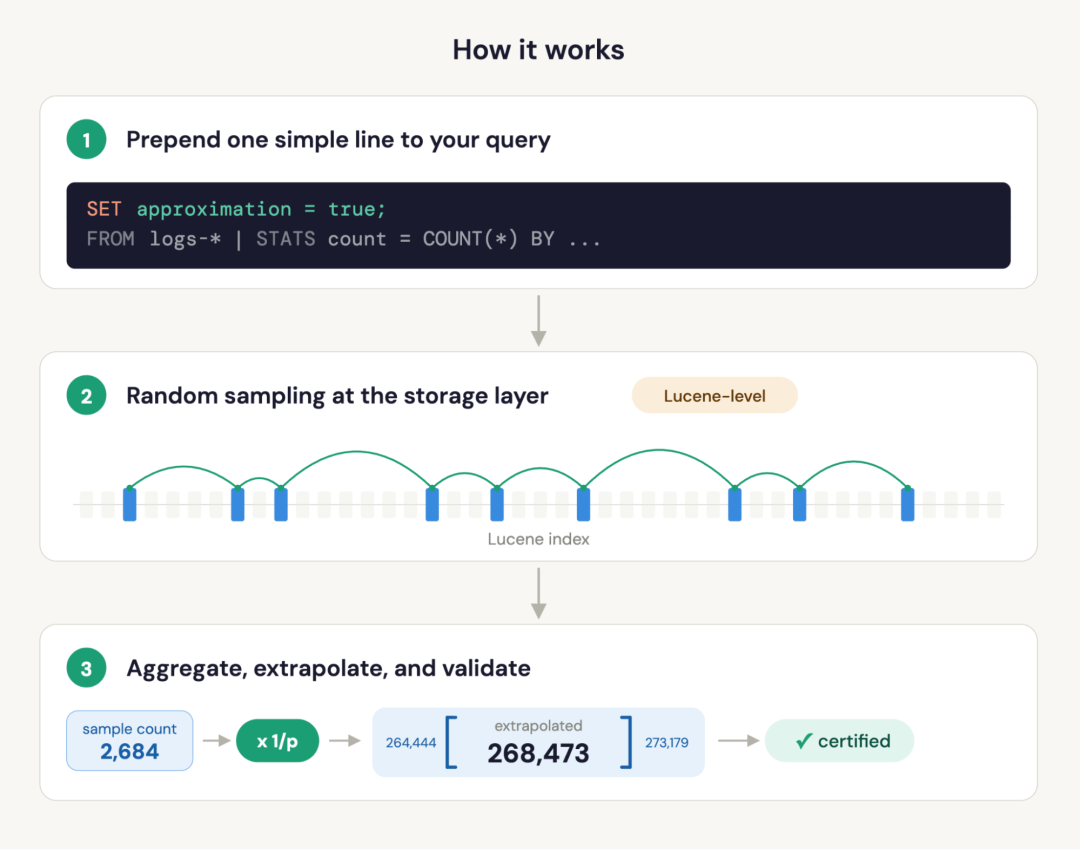
ES|QL 中近似查询的工作原理,不涉及数学原理
这种加速是真实的工程成果,而非查询规划器的小技巧。采样发生在 Lucene 层:Elasticsearch 只读取样本中的文档,因此 I/O 和计算节省与采样率成正比。聚合在样本上运行,结果会自动按比例缩放以代表完整数据集。
置信区间是通过对样本的多个子分区进行引导程序计算的:这在统计学上是严谨的,而不是启发式或猜测。这正是 certified 标志的依据:当方法论的假设得到满足时,区间就带有正式的保证。
alt
一行代码:巨大收益、结果推断和置信信号。
需要时进行精细控制
默认设置旨在开箱即用,但你可以对其进行调整:
1
2
3
SET approximation = {"rows": 500000, "confidence_level": 0.95};
FROM logs-*
| STATS count = COUNT(*), avg_duration = AVG(duration) BY service.name
- • rows:要采样的文档数量(默认值:非分组查询为 100,000,分组查询为 1,000,000)。行数越多意味着精度越高,运行时间越长。
- • confidence_level:区间的置信水平。默认为 0.9。将其设置为更高的水平可以增加值落在置信区间内的概率。
- • 跳过置信区间以获得最大速度:将
confidence_level设置为null,Elasticsearch 将只返回点估计值,在近似执行的基础上再增加 2-5 倍的速度。这就是最高效的查询能达到 300 倍 左右的原因。
下一步计划
SET approximation = true 是一个向前兼容的指令。随着我们增加对 FORK、JOIN、链式 STATS 和其他聚合的支持,你现有的查询将自动受益。
未来的工作还包括与 Kibana 更紧密的集成,以便仪表板和 Discover 可以自动启用近似查询,以及改进对高度偏斜分组字段的处理。
此外,我们将使近似查询能够原生被代理访问,以便它们可以将其作为分析工具和推理循环的一部分,选择快速执行。
开始使用
近似查询在 Elasticsearch 9.4 中作为技术预览版提供,适用于企业订阅层。在查询开头添加 SET approximation = true;,然后查看效果。请查阅 ES|QL SET 命令参考 以获取配置选项。
常见问题 (FAQ)
Elasticsearch 中的近似查询执行是什么?
近似查询执行是一种模式,Elasticsearch 会抽取数据子集,在样本上运行聚合,并将结果推断到完整数据集。你将获得估计值以及显示其可信度的置信区间。它通过在现有 ES|QL 查询前添加一个 SET 指令来控制;无需重写查询。
如何在不减少数据保留的情况下加速 ES|QL 聚合?
只需在查询中添加 SET approximation = true。近似执行是在查询时采样的,而不是在索引时。你的数据保持完全索引、完全保留,并且可以进行精确和近似查询。Elasticsearch 会即时处理采样和推断。随时删除该指令即可获得精确结果;底层数据没有任何变化。
近似查询有多快?
在 ClickBench 基准测试中,非常适合采样的聚合密集型 ES|QL 查询,在启用置信区间的情况下,通常运行速度快 10-40 倍,单个查询可达到 100 倍或更高。禁用置信区间计算 (SET approximation = {"confidence_level": null}) 还会在此基础上额外增加 2-5 倍的速度,因此最高效的查询可达到近 300 倍。优势随数据集大小而增长:采样成本受配置的样本大小限制,而精确执行成本随行数增加,因此你的索引越大,在相同精度下获得的收益就越大。
近似查询的准确性如何?我能相信结果吗?
每个近似值都带有两个信号:一个置信区间(在可配置的置信水平下,限定真实值的范围)和一个认证布尔标志。当 certified 为 true 时,置信区间带有正式的统计保证。当 false 时,结果通常仍然很接近,但数据分布不符合正式保证所需的假设。准确性取决于数据特征和查询结构,而非文档数量,因此加速收益会随着数据集的增长而增加。
加速效果取决于什么?
主要有五个因素:
- • 数据集大小。更大的数据集会带来更大的加速,原因如上所述(精确扫描随 N 增长;采样扫描则不然)。
- • 查询结构。那些扫描大量数据以计算相对较少结果的查询(大型
STATS,特别是MEDIAN和PERCENTILE)受益最大。那些本身就很快的查询(匹配少量行的简单WHERE过滤器,或命中索引摘要统计信息的简单计数)则加速效果不明显。 - • 分组基数和分布。分布良好且每个组样本数量健康的
BY字段会获得明显的收益。非常稀疏或高度偏斜的分组(例如,接近唯一的字段或长尾的稀有值)会侵蚀收益,因为稀有组最终采样的文档过少。 - • 置信区间计算。计算区间会增加开销。将
confidence_level设置为null,你将牺牲区间报告以换取额外的 2-5 倍加速。 - • 样本大小。默认值(非分组
STATS为 10 万,STATS … BY为 100 万)适用于大多数查询。增加行数可以提高高基数分组的准确性,但会牺牲部分速度;减少行数则相反。
我可以使用近似查询进行日志分析和模式检测吗?
是的。CATEGORIZE、GROK 和大量使用正则表达式的条件是 ES|QL 中计算最密集的操作之一,因为它们需要进行逐文档处理。通过 SET approximation = true,这些操作在采样子集上运行,而不是在完整索引上运行,从而使大规模日志模式分析和探索在超大型数据集上变得快速可行。
我必须重写 ES|QL 查询才能使用近似模式吗?
不。在现有查询前添加 SET approximation = true 即可。聚合表达式、列名和输出类型保持不变。响应会为每个近似值添加两列(置信区间和认证标志),但现有不使用这些列的消费者不会看到任何破坏性更改。
近似模式在 9.4 中支持哪些聚合?
COUNT、SUM、AVG、WEIGHTED_AVG、MEDIAN、PERCENTILE(极端值除外)、MEDIAN_ABSOLUTE_DEVIATION 和 STD_DEV(对于高度偏斜的分布有注意事项)。更多功能正在开发中。
对同一查询,我会得到两次相同的结果吗?
不完全相同。近似执行会在查询时随机采样文档,因此对同一查询的连续运行会返回略微不同的点估计值和置信区间。运行之间的差异相对于每次运行报告的置信区间而言很小。如果你需要逐位重现性,请运行精确查询。对于仪表板,根据用例,这种差异通常可以小于图表的视觉分辨率。
本文中描述的任何特性或功能的发布和时间安排仍由 Elastic 自行决定。任何当前不可用的特性或功能可能无法按时或根本无法交付。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号