漫长人工,耗费存储?用 BackupRestore 模块一站式解决跨环境数据同步难题
原创
漫长人工,耗费存储?用 BackupRestore 模块一站式解决跨环境数据同步难题
原创
DolphinDB
发布于 2026-05-21 16:24:21
发布于 2026-05-21 16:24:21
高频交易、数据爆炸,企业数据总量的指数级增长给 DolphinDB 带来了前所未有的运维挑战——从单节点迁移到新集群、定期灾备、跨环境数据共享,每项需求都头疼不已。
传统人工静态备份恢复已经无法满足 TB 级数据的运维:全量操作耗时数小时甚至数天,磁盘空间瞬间紧张,还需协调漫长业务停机窗口……这些问题正消耗运维团队的每一分钟。
针对这些挑战,DolphinDB 推出了 BackupRestore 模块,基于分区粒度进行在线跨集群动态备份与恢复,通过循环备份策略从根本解决迁移过程中磁盘空间紧张和同步效率低下的问题,为复杂生产环境下的数据运维提供了可靠保障。
一、现有集群间同步方案的不足
目前,DolphinDB 环境下跨集群数据同步主要有以下三种方案:
方案一:全量备份与回复。使用 backup 和 restore 系列函数进行备份和恢复,如果旧环境历史数据量过大,一次性备份将占用大量磁盘空间,严重影响业务的连续性。
方案二:集群间异步复制。参考 DolphinDB 的集群间异步复制机制进行数据同步,仅适用于集群异地容灾场景,不支持单节点之间或单节点与集群之间的同步与历史数据回溯。
方案三:在线查询与插入。通过脚本从旧环境查询目标数据再插入新环境,仅适用于待同步数据量较小的场景,应用于大规模数据迁移繁琐且耗时,难以满足实际业务对效率的需求。
二、BackupRestore:数据同步的“黑科技”
本方案基于 DolphinDB 的 backup 和 restore 功能,以分区为单位进行在线数据同步。
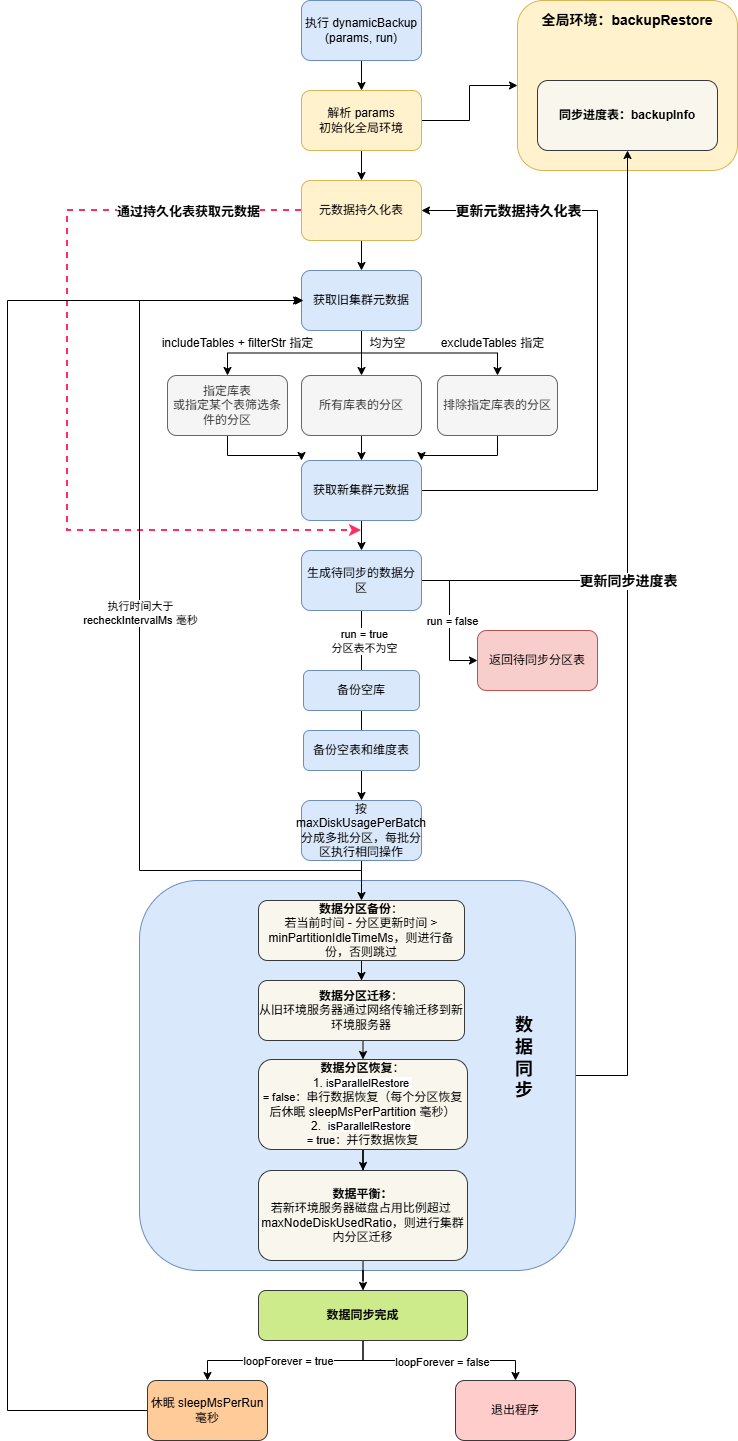
数据动态同步流程图
化整为零,分批循环
这一方案的核心设计思想在于按分区、分批、循环地备份和恢复,确保每批数据量可控,无需长时间停写。方案同时还兼顾单节点与集群环境,能够实现本地和跨服务器两种传输模式。
动态执行流程
整体逻辑封存在 dynamicBackup 函数中,支持单次全量同步和周期性无限循环两种模式:
- 单次全量同步:一次性完成所有数据迁移
- 周期性无限循环:持续刷新元数据,动态调整待同步分区,保证时效性
每批备份恢复完成后,临时文件会被自动清理,防止磁盘堆积。当新环境磁盘使用率过高时,还能自动触发副本迁移,均衡负载。
三、上手实操:三步搞定数据同步
同步前准备
使用 BackupRestore 前需要先将该模块文件上传并同步至目标服务器,当 DolphinDB 调用模块时,系统会在指定路径下查找相应的模块文件。
同步方式如下:
- 使用 xftp 等传输软件,将模块传输至服务器上指定的路径。
- 使用 scp 命令:
scp -r FuturesOLHC <user>@<服务器ip>:/DolphinDB/server/modules/。
模块导入
导入 BackupRestore 模块,文件结构为:
BackupRestore/
├── funcDefine.dos
├── mainFrame.dos
├── newEnv.dos
└── utils.dos该模块需要有以下依赖:
- 两个服务器之间需要设置免密 scp
- 执行模块的节点的配置项需要设置: enableShellFunction=true
定义函数执行备份
params = {
loopForever:true, // 是否无限循环
excludeTables:[], // 排除的库表
includeTables:["dfs://level2_tl_test/entrust"], // 包含的库表
filterStr: NULL, // 适用于只同步某张表某个筛选条件的数据,includeTbs 必须设置且里面只包含一张表
sourceIP:"192.168.100.45", // 旧集群数据节点IP
sourcePort: 7912, // 旧集群数据节点端口号
sourceDDBUser: "admin",// 旧集群 dolphindb 用户名
sourceDDBPwd: "123456",// 旧集群 dolphindb 密码
sourceServerUser: "ymchen",// 旧集群服务器用户名
ctlMetaDbname: "dfs://ctlMeta1", // 存储元数据的库,自动创建
ctlMetaTableName: "data", // 存储元数据的表,自动创建
backupDir:"/data/backup", // 旧集群数据备份目录
restoreDir: "/data/restore", // 新集群数据恢复目录
maxDiskUsagePerBatch:2, // 每一批同步数据的磁盘占用阈值
maxNodeDiskUsedRatio:0.9, // 该执行节点的最大磁盘占用比例
isParallelRestore:true, // 是否并发恢复
sleepMsPerPartition:0, // 每个分区恢复后,停顿多少毫秒
sleepMsPerRun:60.0 * 1000, // 每次循环后,停顿多少毫秒
minPartitionIdleTimeMs:13824097482, // 每个分区的更新时间距离当前时间大于多少毫秒时,才能够备份和恢复(备份时,分区会锁住,如果此时还在写入,会报错,所以需要指定一定时间来避免这个问题)
recheckIntervalMs:20.0 * 60 * 1000 // 每隔多少毫秒重新对比新旧环境元数据
}
// 第二个参数指定是否真实执行
dynamicBackup(params, false)剩下的,只需交给模块自动完成。
四、实战问答:落地过程中的常见问题
Q1:如何查看数据同步进度?
共享字典 backupRestore 中定义同步信息表 backupInfo 记录每个分区的备份恢复信息。
Q2:不同版本之间可以同步吗?
版本 | 是否可以同步 |
|---|---|
2.00.x ⬅➡ 2.00.y | 是 |
3.00.x ⬅➡ 3.00.y | |
2.00.x ➡ 3.00.y | |
3.00.x ➡ 2.00.y | 否 |
Q3:执行程序时对新旧环境的潜在影响?
当数据分区备份和恢复时会锁定该分区,导致该分区的其他事务操作报错,但是不用担心,只需两个参数即可大幅度规避:
- 调大
minPartitionIdleTimeMs:确保分区有足够空闲时间 - 调小
maxDiskUsagePerBatch:缩短每批操作范围,减少冲突概率
Q4:新旧环境数据一样、同一源导入还会同步吗?
通过比对新旧环境的数据分区元数据来判断是否需要同步,元数据不一致则进行同步。
Q5:BackupRestore 同步速度如何?
速度取决于备份恢复速度和网络传输速度。
写在最后
相较于传统的人工静态备份与恢复方式,BackupRestore 模块绝对是更佳的跨环境数据同步选择。BackupRestore 将原本需要繁琐手工备份的 TB 级数据迁移转变成一条命令即可完成的一键式操作,能够灵活应对庞大的数据体量和高业务连续性要求,让运维人员繁彻底告别手工操作的繁琐和风险,将精力投入到更有价值的业务创新上。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号