构建企业级 Skills 平台的 5 个关键决策

构建企业级 Skills 平台的 5 个关键决策

AI智享空间
发布于 2026-05-25 12:28:49
发布于 2026-05-25 12:28:49
去年下半年,我接触过一家做金融 SaaS 的公司,他们的技术 VP 跟我说了一件让我至今印象深刻的事:
“我们花了六个月搭 Skills 平台,结果最终跑在上面的 Skill,只有最开始试点的那三个。”
不是因为需求不存在,也不是因为技术不行。是因为他们在最开始的几个关键决策上,走了弯路。等到发现问题,整个平台的架构已经很难改了。
这篇文章不是来介绍 Skills 是什么的——如果你正在考虑为企业构建 Skills 平台,你大概率已经过了那个阶段。这篇文章想聊的,是那些在规划阶段最容易被低估、在落地阶段却最致命的五个关键决策。
每一个决策,背后都有真实的踩坑案例和可操作的判断框架。
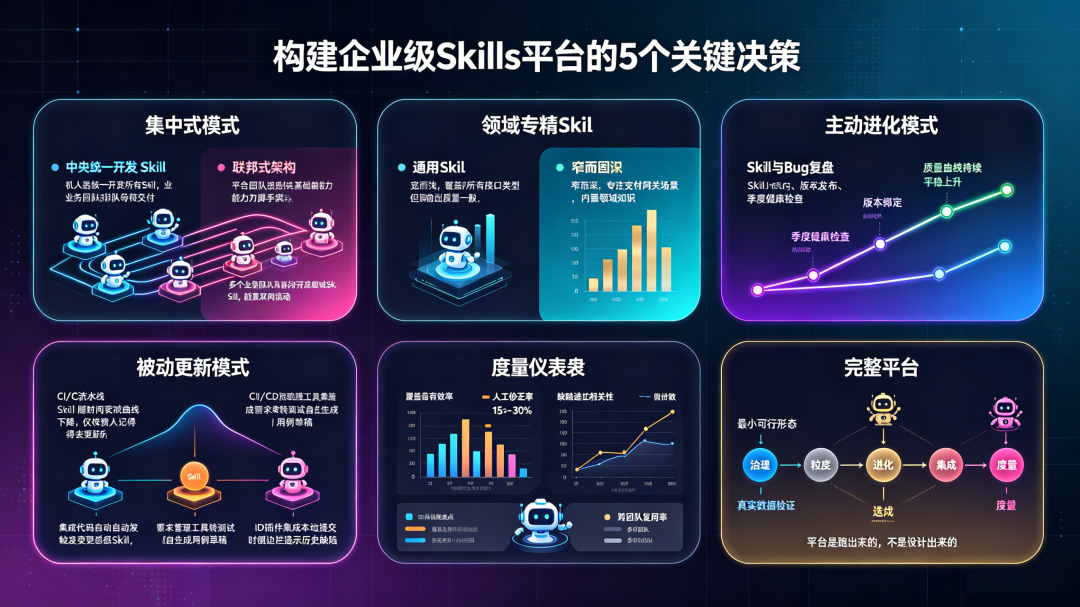
一、集中式还是分布式:平台的治理模式决定你的上限
两种模式,两种命运
企业级 Skills 平台在治理架构上,天然存在两条路:
集中式:由专门的平台团队统一开发、审核、发布所有 Skills。业务团队提需求,平台团队来实现。
分布式:各业务团队自行开发 Skills,平台只提供基础能力和规范,不参与具体 Skill 的开发。
这两种选择,决定的不只是开发方式,而是整个平台的天花板。
集中式的陷阱
集中式看起来最安全——质量可控、规范统一。但它有一个致命缺陷:平台团队永远不可能比业务团队更懂业务。
一个真实的场景:某零售企业,平台团队花了三个月开发了一套“商品上架测试 Skill”。交付给业务团队之后,业务团队反馈说这套 Skill 完全不适用,因为他们有一套自研的商品分类体系,里面有几十个平台团队根本不知道的特殊规则。
重做,又花了两个月。
集中式平台规模越大,这个问题就越严重。平台团队成为瓶颈,需求积压,业务团队等待,最后大家都绕过平台自己搞——平台名存实亡。
分布式的风险
纯分布式同样有问题:没有统一标准,各团队的 Skills 格式、命名、触发条件各行其是,根本无法跨团队复用。更糟的是,同一个业务场景可能被三个团队重复开发了三遍,质量参差不齐。
可操作的判断框架
推荐采用“平台统一基础、业务自治内容”的联邦式架构:
- 平台团队负责:Skill 的运行时、调用协议、权限管控、质量评分体系
- 业务团队负责:具体 Skill 的内容定义、领域知识注入、迭代维护
- 平台团队提供:Skill 开发脚手架、测试工具、发布流程——让业务团队开发 Skill 的成本足够低
衡量这个架构是否健康的指标很简单:平台团队之外的人,能在一周内独立开发并发布一个新 Skill 吗? 如果不能,你的平台对业务团队来说还是一个黑盒。
二、通用能力还是领域专精:Skill 的粒度决定复用率
一个反直觉的结论
“企业级”三个字,容易让人产生一种冲动:要构建覆盖一切的通用 Skills。逻辑看起来很合理——越通用,复用范围越广,ROI 越高。
现实恰恰相反。
过于通用的 Skill,往往什么都能做、什么都做不好,最终沦为没人愿意用的鸡肋。
案例:两种“接口测试 Skill”的命运
某互联网公司同期上线了两个接口测试相关的 Skill:
Skill A(通用版):输入任意接口文档,生成标准化测试用例。覆盖所有接口类型,不做业务假设。
Skill B(领域版):专门针对他们的支付网关接口,内置了支付场景的领域知识——幂等性要求、金额精度规则、渠道异常码映射、监管合规校验点。
六个月后,Skill A 的月调用量:约 200 次,主要是新人在试用。Skill B 的月调用量:超过 3000 次,成为支付团队发版前的标准动作。
差距不是因为 Skill B 的技术实现更好,而是因为它真正解决了一个具体的、高频的、有足够领域复杂度的问题。
找到正确的粒度
Skill 的粒度选择,遵循一个简单原则:宁可窄而深,不要宽而浅。
一个好的企业级 Skill,应该满足:
- 有明确的适用边界(什么场景用,什么场景不用)
- 内置了大量外部无法轻易获得的领域知识
- 在其适用范围内,能做到比通用 Skill 高出至少一个量级的质量
构建平台时,优先把资源投在“高频 × 高复杂度”的领域场景,而不是追求覆盖面。覆盖面可以随时间积累,领域深度才是真正的壁垒。
三、静态配置还是动态学习:Skills 的进化机制决定生命周期
大多数 Skills 平台死于“不更新”
这是企业级 Skills 平台最普遍、也最少被提前考虑到的问题。
Skills 在上线那一刻,往往是质量最高的时刻。因为它封装的是截至那个时间点积累的所有经验。但业务在变、系统在变、风险点在变——如果 Skill 的内容是静态的,它的有效性会随时间线性衰减。
六个月后,一个没有更新机制的 Skill,很可能已经在帮你“测”一些已经不存在的场景,而遗漏了那些新出现的高风险点。
两种更新模式的对比
被动更新:依赖人记得去更新。通常的触发点是:出了线上问题,复盘时发现“这个 Skill 应该覆盖这个场景但没有”,然后有人去修一下。
这种模式的问题是:更新严重滞后,且依赖人的主观记忆。大多数 Skills 在被动更新模式下,一年内几乎不会有任何变化。
主动进化:将 Skill 的更新与工作流节点强绑定。
具体做法:
- Bug 复盘节点:每次线上问题复盘,必须输出“对应 Skill 需要补充哪个场景”的结论,并在复盘后 48 小时内完成 Skill 更新
- 版本发布节点:新功能上线后,对应 Skill 的维护者需要评估是否有新的测试场景需要纳入
- 季度健康检查:由平台团队统一扫描各 Skill 的调用数据,识别长期未更新且调用量下滑的 Skill,触发强制评审
这两种模式的本质差异是:被动更新把 Skill 看作产出物,主动进化把 Skill 看作基础设施。基础设施需要运维,不是交付完就结束了。
一个可以直接用的机制设计
在 Skill 的元数据里,强制要求填写:
最后更新时间:2024-11-20
下次强制评审时间:2025-02-20(每季度一次)
关联 Bug 记录:ISSUE-4421, ISSUE-4589
维护责任人:王某某平台每月生成一份“Skill 健康报告”,标记出超过 90 天未更新的 Skill 为“风险状态”,通知维护责任人。让腐化可见,才能让治理有抓手。
四、能力孤岛还是工具链集成:Skills 的调用场景决定实际价值
Skills 平台最容易犯的错:做成了一个入口
很多企业在构建 Skills 平台时,最终做出来的是一个“Skill 商店”——一个 Web 界面,列出所有可用的 Skills,用户手动选择,复制输出,粘贴到自己的工作流里。
这种模式不是没有价值,但它把 Skill 的使用变成了一个需要额外操作步骤的事情。而任何需要额外操作步骤的工具,都会在用户最忙的时候被跳过。
集成点的选择
企业级 Skills 平台真正发挥价值,是当 Skill 的调用发生在工作流的自然节点,而不是需要用户主动去调用。
几个高价值的集成场景:
集成到 CI/CD 流水线:代码提交触发构建时,自动调用变更感知 Skill,输出本次变更的影响范围和推荐回归用例集。测试工程师不需要做任何额外操作,打开 CI 报告,回归建议已经在那里了。
集成到需求管理工具:需求状态流转到“待测试”时,自动调用需求解析 Skill,在测试任务卡上生成测试用例草稿。测试工程师的第一个动作是“审查”,而不是“创建”。
集成到 IDE 插件:开发工程师在本地提交代码时,IDE 调用代码变更分析 Skill,直接在侧边栏提示“你修改的这个函数历史上出过 3 次 Bug,测试时重点关注 X、Y、Z 场景”。
这三个集成点的共同特征是:Skill 的输出出现在用户本来就要打开的界面里,用户不需要改变已有习惯。
集成的优先级判断
不可能一次性集成所有工具。判断集成优先级的标准:哪个节点的用户,在做决策时最需要 Skill 的输出,且目前获取这个信息的成本最高?
通常,CI/CD 集成的投入产出比最高,建议作为第一个集成点。
五、使用率还是质量分:平台的度量体系决定迭代方向
度量什么,就优化什么
这是所有平台建设者都知道的道理,但在 Skills 平台上,很多团队仍然在用错误的指标来衡量平台价值。
最常见的错误指标:Skill 调用次数。
调用次数高,只说明用户在用。它不说明用户用完之后,这个 Skill 有没有帮他们发现 Bug、节省时间、提升覆盖率。一个输出质量极差但界面做得很漂亮的 Skill,可能调用次数很高,但它在消耗用户对平台的信任。
建立面向结果的度量体系
企业级 Skills 平台,应该追踪的是能力有效性,而不只是使用量。
推荐的核心指标体系:
覆盖有效率:Skill 生成的用例中,在实际执行后发现缺陷的用例比例。这个指标越高,说明 Skill 对风险的预判越准确。
人工修正率:测试工程师在使用 Skill 输出后,需要手动增删的用例比例。修正率过高,说明 Skill 的领域知识不够准确;修正率过低(接近零),可能说明工程师在盲目信任 Skill 而不是真正审查。健康的修正率应该在 15%-30% 之间。
缺陷逃逸相关性:线上出现的 Bug,有多少比例在对应 Skill 的覆盖范围内但没有被发现。这是衡量 Skill 质量最直接的指标,也是驱动 Skill 迭代的最核心数据。
跨团队复用率:一个 Skill 被多少个不同团队在使用。这个指标衡量的是 Skill 的抽象质量——真正抽象得好的 Skill,自然会被跨场景复用。
把度量变成迭代引擎
这些指标的价值,不只是在报告里展示给管理层看。更重要的是把它们作为 Skill 迭代的输入:
- 覆盖有效率低 → Skill 的场景推导逻辑需要优化
- 人工修正率过高 → Skill 的领域知识注入不够准确,需要补充上下文
- 缺陷逃逸相关性高 → 这是紧急信号,需要立即启动 Skill 更新
- 跨团队复用率低 → Skill 的抽象粒度可能过窄,或者发现机制不够好
把度量和迭代闭环连接起来,平台才能做到真正意义上的持续进化,而不是在发布之后等着慢慢腐化。
结语:五个决策,一个核心原则
回顾这五个决策:治理模式、Skill 粒度、进化机制、工具链集成、度量体系。
它们看起来是五个独立的问题,但背后有一个共同的原则:
企业级 Skills 平台的价值,不取决于它能做什么,而取决于它是否真正融入了人们的工作方式。
一个技术上完美但需要额外学习成本的平台,会被绕过。一个 Skill 质量很高但和工具链割裂的平台,会被遗忘。一个没有进化机制的平台,会慢慢腐化直到没人信任。
最后给正在规划或推进 Skills 平台的团队一个务实的建议:
不要等五个决策都想清楚了再开始。选一个你最清楚答案的决策,从最小可行的形态开始跑,让真实的使用数据来回答其他四个问题。
平台是跑出来的,不是设计出来的。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号