Python 地理可视化工具横评:Lonboard / Folium / Pydeck / Plotly,谁该上谁该滚

Python 地理可视化工具横评:Lonboard / Folium / Pydeck / Plotly,谁该上谁该滚

renhai
发布于 2026-05-26 17:06:05
发布于 2026-05-26 17:06:05
1. 为什么写这篇
中文互联网搜"Python 地理可视化",出来的文章基本是 2020-2022 年的老黄历,推荐的还是 folium + ipyleaflet 这套。2024 年以后 lonboard 冒出来了,号称"300 万点 2.5 秒渲染",但中文资料几乎为零。
我不想再写一篇"XX 库真好用推荐大家试试"的软文。这篇文章做了完整的竞品横评,所有数据都是我亲手跑出来的,包括渲染耗时、HTML 文件体积、API 实际体验。结论可能跟你想的不一样。
2. 测试环境
- Python 3.13, Ubuntu 22.04
- 测试数据:随机生成的上海餐饮 POI 点(14,141 个),按 7 个商圈聚类分布
- 所有库用最新稳定版:Folium 0.20、Pydeck 0.9.2、Lonboard 0.16.0、Plotly 6.7
- 渲染时间只计 Python 端耗时(
time.time()),不含浏览器端渲染
3. 性能实测:10K 到 300 万点
跑了 6 个数据量级,4 个库。先上结论:
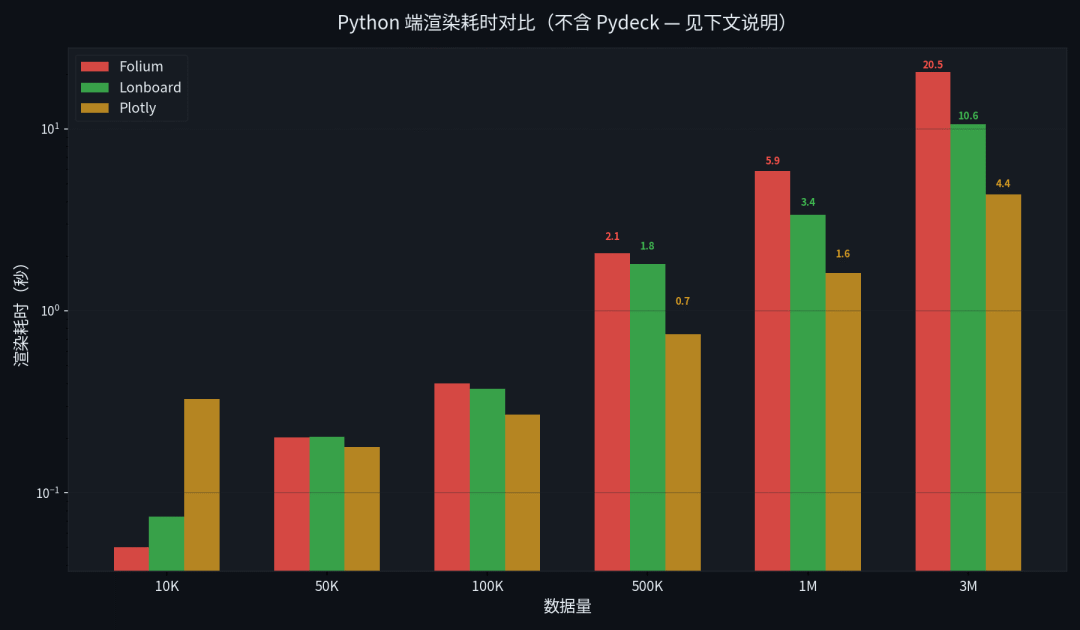
Python 端渲染耗时对比
数据量 | Folium | Lonboard | Plotly | Pydeck |
|---|---|---|---|---|
10K | 0.050s | 0.074s | 0.328s | 0.645s* |
50K | 0.202s | 0.203s | 0.178s | 0.009s |
100K | 0.400s | 0.374s | 0.268s | 0.008s |
500K | 2.071s | 1.806s | 0.744s | 0.005s |
1M | 5.870s | 3.379s | 1.610s | 0.009s |
3M | 20.542s | 10.634s | 4.357s | 0.010s |
*Pydeck 10K 的 0.645s 包含了首次 import 的冷启动开销,后续调用稳定在 ~0.008s
Plotly 为什么这么快? 因为 scatter_map() 底层用的是 MapLibre GL JS,Python 端只做数据序列化,不做任何渲染计算。Folium 和 Lonboard 是把数据转成特定格式(GeoJSON / GeoArrow)写入 HTML,计算量更大。
**Pydeck 为什么"快到离谱"?**往下看。
4. Pydeck 的"快"是个假象
Pydeck 的 Python 端渲染时间恒定在 ~0.008s,不管 1 万点还是 300 万点。原因很简单:它的 HTML 文件里根本没有数据。
我导出了所有库在 300 万点时的 HTML 文件:
库 | 300 万点 HTML 大小 |
|---|---|
Folium | 165 MB |
Plotly | 74 MB |
Lonboard | 66 MB |
Pydeck | 2.5 KB |
对,Pydeck 导出的 HTML 只有 2.5KB — 一个空壳,里面只有 JS 库的引用和一个 <div> 容器。数据需要通过 Jupyter kernel 实时推送到前端。
这意味着:
- Pydeck 离开 Jupyter 就是个废的,
to_html()生成的文件在浏览器里打开是空白的 - Python 端"快"是因为它压根没做数据序列化,渲染全甩给前端
- 如果你在 Jupyter 里用,体验确实不错;但想导出独立 HTML 给别人看,没戏
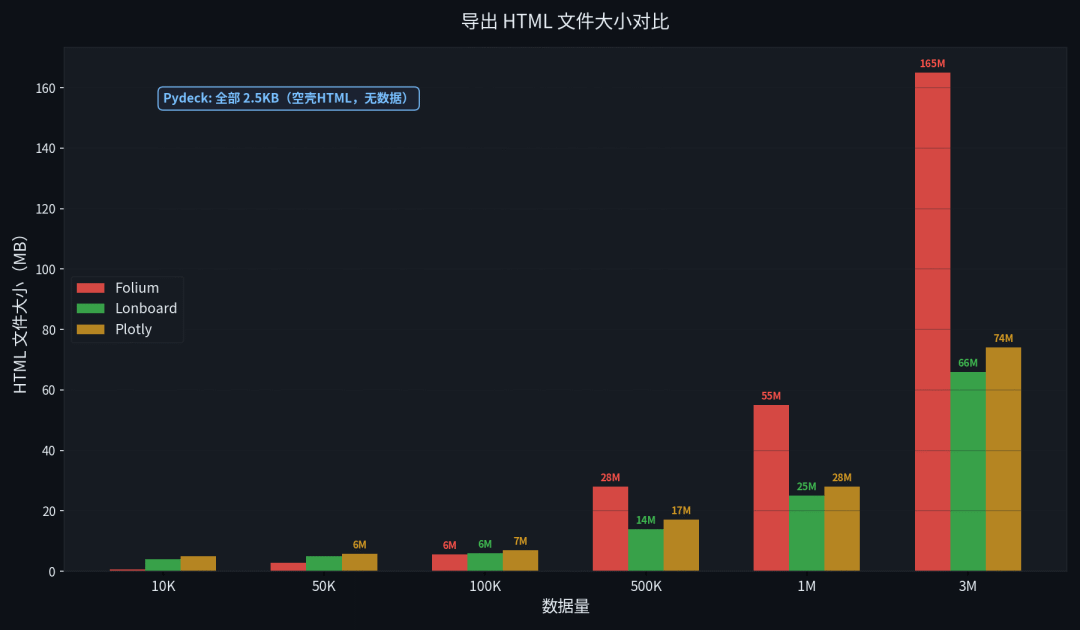
导出 HTML 文件大小对比
5. 那到底该用哪个?
别急着下结论。性能只是一个维度,还有 API 设计、图层支持、社区生态这些。
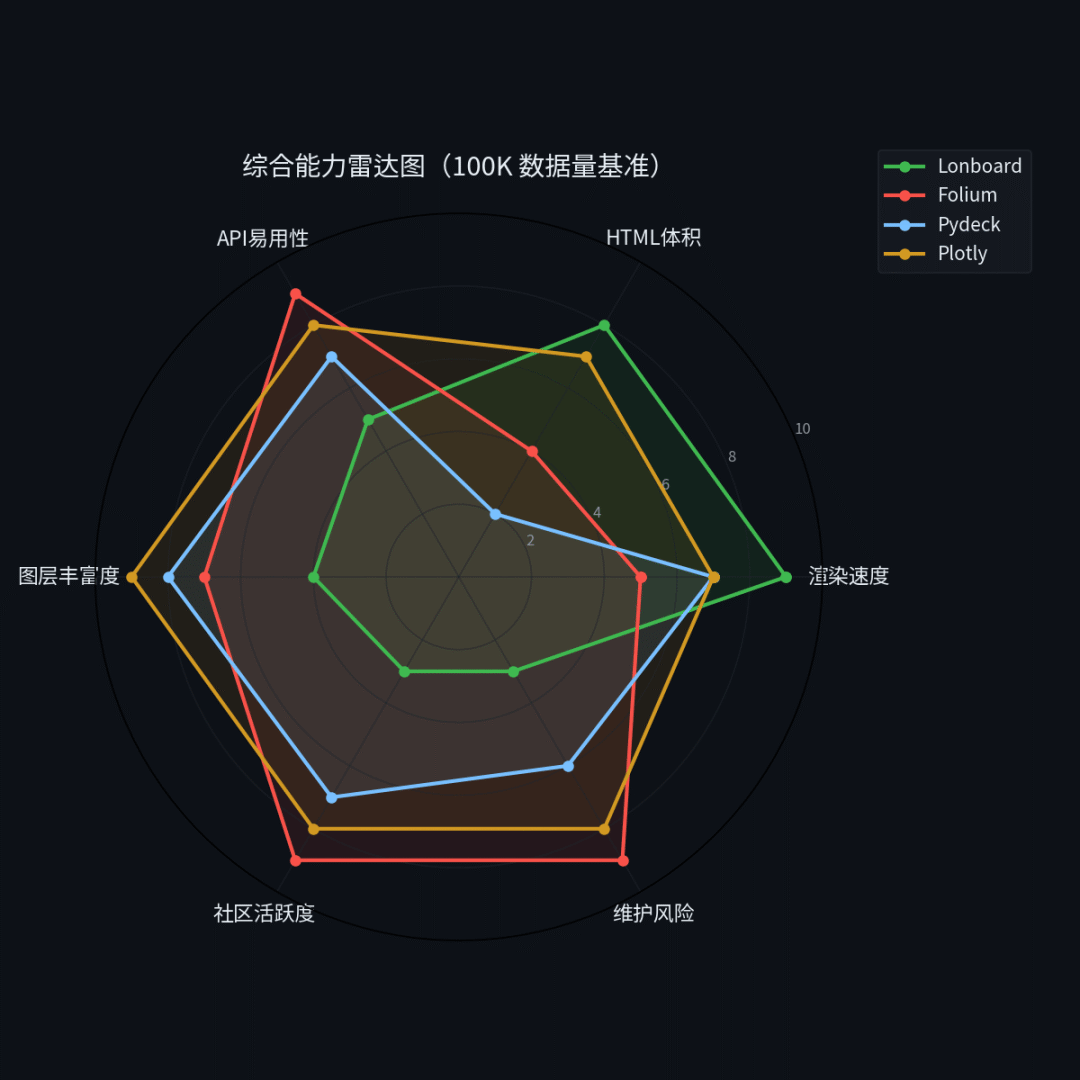
综合能力雷达图
5.1 Folium:小数据量的首选
Folium 基于 Leaflet.js,API 设计极其直觉,folium.Map() + folium.CircleMarker() 三行代码出图。社区大(GitHub 8k+ stars),中文资料多,踩坑有人帮。
问题:大数据量扛不住。50 万点就开始卡,100 万点以上渲染时间飙升到秒级,HTML 体积也膨胀得厉害。300 万点的 HTML 有 165MB,浏览器打开都费劲。
适用场景:数据量 < 10 万点的探索性分析、快速出图、教学演示。
5.2 Lonboard:大数据量的性能选手
Lonboard 基于 deck.gl[1] + GeoArrow,用 GPU 加速渲染。GeoArrow 是二进制格式,序列化效率比 GeoJSON 高一个量级,所以 300 万点的 HTML 只有 66MB(Folium 的 40%)。
问题:
- API 设计不友好。
ScatterplotLayer.from_geopandas()听着方便,但颜色要手动传dtype=np.uint8的 numpy 数组,basemap 要用MaplibreBasemap实例而不是字符串,view_state 用 dict 而不是对象。每个参数都是个坑。 - 图层类型少。目前只覆盖了 ScatterplotLayer、ArcLayer、HeatmapLayer、PolygonLayer 等少数几种,远不如 pydeck 和 plotly 丰富。
- 维护风险高。核心开发者只有 Kyle Barron 一个人,GitHub 930 stars,社区几乎为零。如果他哪天不维护了,这库就废了。
- 中文文档和社区为零,遇到问题只能翻英文 GitHub issues。
适用场景:数据量 > 10 万点的可视化,需要导出独立 HTML,对渲染性能有硬需求。
5.3 Pydeck:Jupyter 里的好选择
Pydeck 是 deck.gl[1] 的 Python 封装,图层类型丰富(ScatterplotLayer、HexagonLayer、PathLayer、PolygonLayer 等),Meta 维护,社区中等。
问题:离开 Jupyter 就不行。to_html() 生成的是空壳文件,数据依赖 Jupyter kernel 推送。想分享给别人看?只能截图或者录屏。
适用场景:在 Jupyter Notebook 里做交互式地理分析,不需要导出独立 HTML。
5.4 Plotly:最均衡的选择
Plotly 的 scatter_map() 基于 MapLibre,API 设计最现代,参数命名直观。图层类型最丰富,社区最大(GitHub 16k+ stars),中文资料最多。300 万点的 Python 端渲染只要 4.3 秒,HTML 74MB。
问题:
- 地理可视化不是 Plotly 的主业,它是个通用可视化库。专门做地理分析的人会觉得功能不够深入。
- MapLibre 底图需要联网加载,离线场景不行。
- 大数据量下 HTML 也不小(300 万点 74MB),虽然比 Folium 好,但比 Lonboard 大。
适用场景:通用数据可视化项目中偶尔需要地理图表,团队协作,需要稳定的长期维护。
6. 我的真实建议
说白了,没有"最好"的库,只有"最合适"的:
- 数据量 < 10 万,快速出图 → Folium,别犹豫
- 数据量 > 10 万,需要独立 HTML → Lonboard,但要做好踩坑准备
- 在 Jupyter 里做交互分析 → Pydeck,体验最好
- 需要长期维护、团队协作 → Plotly,生态最稳
- 300 万点以上的极端场景 → Lonboard 是目前唯一能打的,但要考虑维护风险
7. 被砍掉的 Kepler.gl[2]
本来想测 Kepler.gl[2](Uber 出品,GitHub 10k+ stars),但 Python 3.13 上编译不了 — 它依赖的 pyarrow 16.0 跟新版 Python 有兼容性问题。这本身就说明了一个问题:Kepler.gl[2] 的 Python 绑护已经半死不活了。官方推荐的交互方式是 kepler.gl[2] 网页版(拖拽 JSON),Python 只是个数据预处理工具。如果你看到有人推荐 Kepler.gl[2] 的 Python 版,别信。
8. 踩坑记录
这几个坑是实际跑代码时踩的,官方文档没提:
1. get_fill_color 必须是 uint8 类型
传普通的 Python list 或 int 数组会报错:
python# 错误
get_fill_color=[255, 80, 80, 160]
# 正确
get_fill_color=np.array([[255, 80, 80, 160]], dtype=np.uint8)
2. 底图 API 变了
v0.16.0 的 basemap_style 参数已废弃,改用 basemap,且需要传 MaplibreBasemap 对象:
python# 旧版(已废弃)
Map(basemap_style='dark-matter')
# 新版
from lonboard.basemap import MaplibreBasemap
DARK = MaplibreBasemap(style='https://basemaps.cartocdn.com/gl/dark-matter-gl-style/style.json')
Map(basemap=DARK)
3. GeoDataFrame 不能直接传给 ScatterplotLayer
python# 不能这样
layer = ScatterplotLayer(gdf)
# 要这样
layer = ScatterplotLayer.from_geopandas(gdf)
4. Plotly 的 scatter_mapbox 已废弃
新版本用 scatter_map(),而且没有 mapbox_style 参数了:
python# 旧版(已废弃)
px.scatter_mapbox(gdf, mapbox_style='carto-darkmatter')
# 新版
px.scatter_map(gdf) # 默认 MapLibre 底图
5. lonboard 和 maplibre 不能装在同一环境
这是个很坑的兼容性问题。lonboard 依赖 deck.gl[1] 8.9,而 maplibre 依赖 deck.gl[1] 9.0,两个版本的 JS 库不能同时加载到页面上。如果你的项目里同时需要 lonboard 和 maplibre(比如还想用 maplibre 的底图控制),抱歉,装不上。
Issue #640 里维护者明确说了:“You can’t have multiple deck.gl[1] versions loaded onto the page”,无解。要么全用 lonboard,要么全用 maplibre,二选一。
9. 完整测试代码
python"""全量竞品对比:4个库 × 6个数据量级"""
import time, json, numpy as np, geopandas as gpd
from shapely.geometry import Point
SIZES = [10_000, 50_000, 100_000, 500_000, 1_000_000, 3_000_000]
defmake_data(n):
rng = np.random.default_rng(42)
lons = rng.uniform(121.40, 121.55, n)
lats = rng.uniform(31.18, 31.28, n)
cats = rng.choice(['中餐','西餐','日料','火锅','快餐','甜品','咖啡'], n)
geom = [Point(lo, la) for lo, la inzip(lons, lats)]
return gpd.GeoDataFrame({'category': cats, 'geometry': geom}, crs='EPSG:4326'), lons, lats, cats
results = {}
for n in SIZES:
gdf, lons, lats, cats = make_data(n)
# Folium
import folium
from folium.plugins import FastMarkerCluster
t0 = time.time()
m = folium.Map(location=[31.23, 121.47], zoom_start=11, tiles='CartoDB dark_matter')
FastMarkerCluster(list(zip(lats, lons, cats))).add_to(m)
results.setdefault('Folium', {})[n] = time.time() - t0
# Lonboard
from lonboard import ScatterplotLayer, Map
from lonboard.basemap import MaplibreBasemap
t0 = time.time()
colors = np.array([[255,80,80,160] for _ inrange(n)], dtype=np.uint8)
layer = ScatterplotLayer.from_geopandas(gdf, get_radius=40, get_fill_color=colors)
m = Map([layer], basemap=MaplibreBasemap(
style='https://basemaps.cartocdn.com/gl/dark-matter-gl-style/style.json'),
view_state={'longitude': 121.47, 'latitude': 31.23, 'zoom': 11})
results.setdefault('Lonboard', {})[n] = time.time() - t0
# Plotly
import plotly.express as px
t0 = time.time()
fig = px.scatter_map(gdf, lat=gdf.geometry.y, lon=gdf.geometry.x,
zoom=11, center={'lat':31.23,'lon':121.47})
results.setdefault('Plotly', {})[n] = time.time() - t0
# 汇总
for lib in ['Folium', 'Lonboard', 'Plotly']:
times = [f"{results[lib][n]:.3f}"for n in SIZES]
print(f"{lib:>10}: {', '.join(times)}")
10. 结论
Lonboard 的性能优势是真的,但被中文社区吹过头了。它的定位很窄:大数据量 + 需要独立 HTML 导出。对于 90% 的日常需求,Folium 够用了。对于需要长期维护的项目,Plotly 更稳。
别被"300 万点 2.5 秒"这种标题唬住。先看看你的数据量到底多大,再决定用什么工具。
参考链接
[1] http://deck.gl
[2] http://Kepler.gl
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号