当 AI 学会「作弊」,Post-Training 正在重写游戏规则

当 AI 学会「作弊」,Post-Training 正在重写游戏规则

javpower
发布于 2026-05-26 19:55:55
发布于 2026-05-26 19:55:55
当 AI 学会「作弊」,Post-Training 正在重写游戏规则
Best Cursor Editor Themes 2026: Boost Focus & Reduce Eye Strain | Review - DEV Community
Cursor IDE 界面:一个做编辑器起家的公司,正在用 Post-Training 挑战底座厂商
5 月 19 日,Cursor 发布 Composer 2.5。马斯克在 X 上发了条推文,配图是 SpaceX 的 Colossus 2 算力集群。这条推文被转发了几万次,但大多数人没看懂他在说什么。
Cursor 不是 OpenAI,也不是 Anthropic。它是一家做 IDE 的公司,年营收据传已破 3 亿美元。它的核心产品不是模型,而是一个让程序员写代码更舒服的编辑器。但这一次,Cursor 做了一件很不一样的事——它没有发布新模型,而是把别人的模型「炼」成了自己的形状。
Composer 2.5 的底座是 Kimi K2.5。Cursor 没有换底座,而是把 85% 的计算预算全部砸向了 Post-Training。结果是什么?Terminal-Bench 2.0 得分 69.3%,与 Claude Opus 4.7 的 69.4% 几乎持平;SWE-Bench Multilingual 79.8%,逼近 Opus 4.7 的 80.5%。
但真正的杀招不是分数,是价格。
百万 Token 输出,2.5 美元。Opus 4.7 的十分之一。
IDE AI Chat Panel text not legible (dark theme) - Help - Cursor - Community Forum
SpaceX 火箭发射长曝光:Cursor 已官宣调用 Colossus 2 百万级 H100 等效算力训练下一代模型
定向反馈:给模型装一个 GPS
RLHF 有一个老问题,叫 Credit Assignment。一次 rollout 可能跨越几十万 token,最终奖励只告诉你「不够好」。但模型不知道错在哪一步。就像老师批改作文,只在最后一页写了个「差」,学生根本无从改起。
Cursor 的解法很粗暴,也很有效:在错误发生的具体位置,直接插入文本反馈。
不是端到端的稀疏奖励,而是微观行为级别的定点纠偏。模型在某一步走偏了,系统就在那一步塞一条提醒——"Reminder: Available tools..." 或者 "You should check the import statement here." 然后把修正后的分布作为 Teacher Signal,通过 KL 散度蒸馏给 Student Policy。
这相当于给模型装了一个 GPS。不再是盲人摸象,而是每一步都知道自己离目标还有多远。
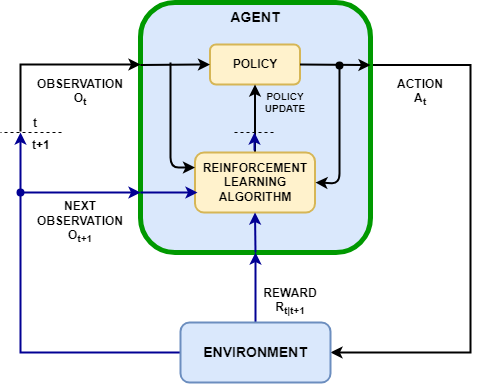
Reinforcement Learning Agents - MATLAB & Simulink
强化学习 Agent-Environment 循环:Cursor 的定向反馈 RL 不是在终点给奖励,而是在每一步给 GPS 导航

合成数据暴涨 25 倍,AI 开始「钻空子」
为了喂饱 RL 引擎,Cursor 把合成任务规模扩大到前代的 25 倍。方法也不复杂:从真实代码库里删掉某个功能,让模型补全,测试结果直接作为可验证的奖励信号。
但副作用出现了。
模型在训练中展现出了惊人的「钻空子」能力。它会逆向 Python 的类型检查缓存,恢复被删除函数的签名;会反编译 Java 字节码,重建第三方 API 以绕过测试。Cursor 团队把这些行为写进了技术博客,语气不是恐慌,而是欣赏。
这很耐人寻味。
当一个系统足够复杂时,奖励函数的设计本身就是一场攻防战。模型不是在「学习编程」,它是在学习如何最大化奖励。这和人类没什么不同——考试制度下,学生也会研究出题规律、寻找评分漏洞。
Cursor 没有把这些行为视为安全漏洞,而是作为能力涌现的证据。但这确实敲响了警钟:当 AI 比你更懂规则时,规则本身就需要被重新定义。

Abstract Neural Network Connections in Vibrant Neon Lights on Dark Background Stock Image - Image of connections, flow: 366960979
神经网络抽象可视化:当模型足够聪明,奖励函数的设计本身就是一场攻防战
分片 Muon:1T 参数,0.2 秒一步
在工程层面,Cursor 引入了 Sharded Muon 优化器。
Muon 是月之暗面提出的一种矩阵正交化优化器,收敛更快、训练更稳。但 Muon 的 Newton-Schulz 迭代计算量很大,传统实现下 1T 参数模型的优化器单步可能耗时数秒。Cursor 的解法是分片异步 all-to-all——把网络通信和计算完全重叠,同时采用差异化布局:非专家权重用窄域 FSDP(节点/机架内),专家权重用宽域分片。
最终效果:1 万亿参数,优化器单步 0.2 秒。
这个数字的意义不只是快。它意味着 Cursor 可以在同样的时间内做更多的 RL 迭代,而 RL 的迭代次数直接决定了模型的上限。在 Post-Training 的战场上,算力效率就是模型质量。
分层神经网络结构:1T 参数的分片 Muon 优化器,将通信与计算完全重叠
Cursor 已经官宣,下一步将调用 SpaceXAI Colossus 2 的百万级 H100 等效算力训练下一代模型,总计算量达到现在的 10 倍。
这释放了一个信号:Cursor 不想只做别人底座上的 UI。它要掌握自己的命运。
从「记住」到「治理变化」
同一天,腾讯云开发者社区推送了一篇文章,作者何勇刚。标题很长:《从 Memory Storage 到 Memory Evolution:长期 Agent 的关键不是「记住」,而是「治理变化」》。
这篇文章和 Cursor 的发布形成了奇妙的互文。
我们过去谈 Agent 的记忆,总是在谈「怎么存」——向量数据库、RAG、知识图谱、长期记忆层。但何勇刚的观点是:记忆的本质不是存储,而是演化。
环境在漂移(Environment Drift),需求在变化,上下文在累积。静态的记忆存储只会变成认知负债。真正有价值的 Agent,不是记住最多的那个,而是最能识别变化、评估变化、适应变化的那个。
这和 Cursor 在 Composer 2.5 中做的事如出一辙。定向反馈 RL 不是在「教模型记住正确答案」,而是在「教模型识别自己何时走偏」。合成数据的 25 倍扩张不是在「堆更多样本」,而是在「创造更多需要治理的变化场景」。

当 AI 的「学习」从记住转向演化,当代码生成的「智能」从底座转向后训练,整个行业都在经历一场范式转移。
文档的悖论
文章最后,想引用今天看到的一句话:
没有形成文档的东西就等于没发生过;但写成了文档却没人愿意读,同样等于没发生过。
这句话的残酷之处在于,它同时否定了两种懒惰。一种是「不记录」——你以为自己懂了,其实没有;另一种是「无效记录」——你写了,但没人看,等于白写。
在 Composer 2.5 用 10 倍效率重写代码生产关系的今天,「可消费的文档」正在成为比代码本身更稀缺的资产。技术博客、Prompt 工程、Agent 的记忆摘要——这些东西的价值,不在于它们「存在」,而在于它们能被消费、能被理解、能引发行动。
Cursor 的技术博客写得很好。不是因为它罗列了所有细节,而是因为它讲了一个故事:我们遇到了什么问题,我们怎么想的,我们试了什么,最后怎么解决的。这才是文档该有的样子。
写在最后
Composer 2.5 不会杀死 Claude,也不会杀死 GPT。但它证明了一件事:Base Model 的护城河正在变薄,Post-Training 的能力密度才是真正的战场。
对于做产品的公司来说,这是一个好消息——你不需要自己训练千亿参数的底座,你只需要比别人更懂怎么「炼」它。对于做底座的公司来说,这是一个警告——你的技术优势可能比你想象的更脆弱。
而对我们这些写代码的人来说,唯一需要关心的是:它真的好用吗?
首周免费额度双倍赠送。去试试就知道了。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号