npj Drug Discov.|MAMMAL: 面向药物发现的分子多模态对齐模型

npj Drug Discov.|MAMMAL: 面向药物发现的分子多模态对齐模型

DrugOne
发布于 2026-05-26 20:34:07
发布于 2026-05-26 20:34:07
2026年5月4日,IBM以色列研究院与以色列理工学院的研究团队在《NPJ Drug Discovery》发表文章,题为“MAMMAL-Molecular Aligned Multi-Modal Architecture and Language for Biomedical Discovery”。

该研究提出了一种名为MAMMAL的基础模型,能够整合蛋白质与抗体序列、小分子结构及基因表达数据,实现跨模态生物信息的统一表示,为药物发现提供了系统化的计算工具。
代码仓库:
https://github.com/BiomedSciAI/biomed-multialignment
背景
近年来,人工智能尤其是深度学习技术在生物医药领域展现出巨大潜力,为药物研发提供了全新的计算工具。通过从大规模、高维的生物数据中学习,AI模型能够捕捉复杂的序列、结构和表达模式,从而预测蛋白质功能、抗体结合亲和力、小分子活性及基因表达调控等关键信息。然而,生物医药数据类型极为多样,包括蛋白质和抗体的氨基酸序列、三维结构信息、小分子化学图、以及细胞或组织的基因表达谱等,这使得单一模态模型难以充分利用不同数据之间的互补信息。
MAMMAL应运而生,旨在解决多模态药物发现任务中的数据整合与跨模态理解难题。该模型通过预训练大规模生物分子数据,实现蛋白质、抗体、小分子及基因表达的统一编码,并将多种异构数据映射到共享潜在空间中,从而实现跨模态特征对齐。该方法不仅能够支持分类和回归任务,如蛋白质家族功能预测和小分子-蛋白质亲和力预测,还能够进行生成任务,例如基于蛋白序列生成候选小分子或根据基因表达谱预测蛋白质功能,为药物发现提供全流程计算支持。
方法
MAMMAL的核心在于构建分子级跨模态对齐架构。模型采用四类输入:蛋白质序列、抗体序列、小分子结构及基因表达谱。蛋白质与抗体序列通过改进的语言模型表示,捕捉序列上下文和功能位点信息;小分子通过图神经网络进行结构嵌入,基因表达谱采用连续向量编码方法。跨模态对齐通过共享潜在表示空间实现,使得不同类型的生物分子在统一空间中保持功能相关性与交互信息。
MAMMAL采用多任务学习策略,同时优化分类、回归和生成任务。分类任务包括蛋白质家族分类及抗体结合预测,回归任务包括小分子-蛋白质亲和力预测和基因表达量预测,而生成任务则可以从蛋白质或抗体序列生成候选小分子,或根据基因表达谱预测蛋白功能。通过联合损失函数训练,模型在兼顾多任务性能的同时保持良好的泛化能力。
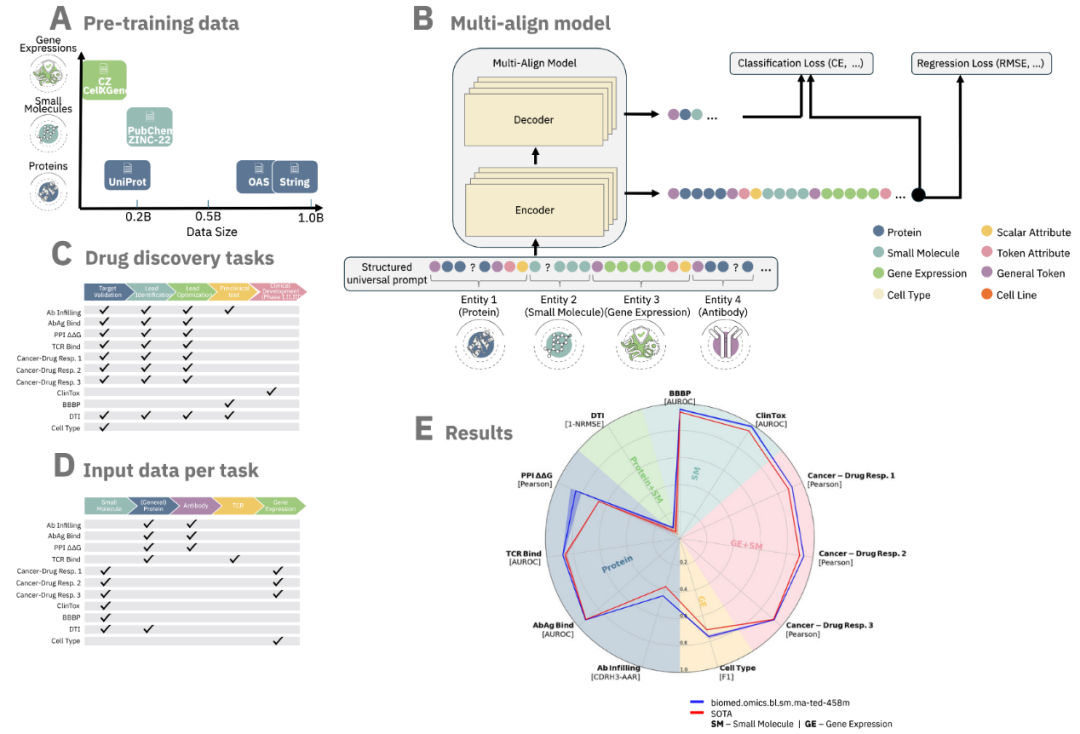
图1 MAMMAL预训练数据、模型架构及下游任务
MAMMAL的预训练覆盖蛋白质序列、抗体序列、小分子结构及基因表达谱,总样本量约20亿。蛋白质和抗体序列使用自注意力Transformer构建嵌入,捕捉远程氨基酸间相互作用;小分子结构通过图神经网络捕捉原子与键拓扑关系;基因表达谱利用连续向量编码反映细胞状态与功能特征。模型在预训练中同时优化跨模态对齐损失和多任务预测损失,确保嵌入空间在保留模态特征的同时实现跨模态可比性和任务泛化能力。
表1 预训练任务
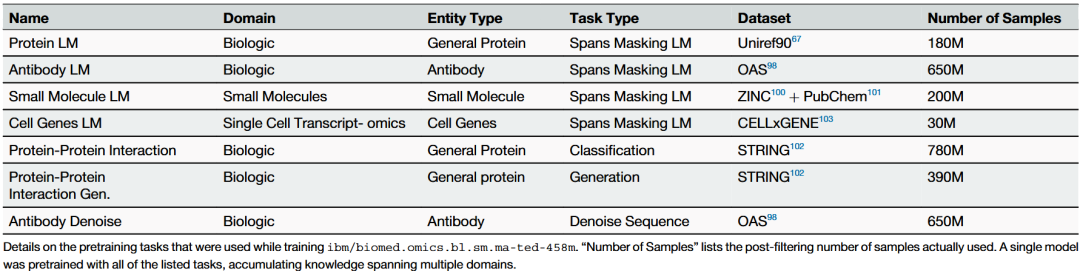
模型性能评估
模型在药物发现全流程中进行了广泛评测,包括蛋白质功能预测、抗原-抗体结合预测、小分子活性回归、基因表达预测及跨模态生成任务。为了直观展示MAMMAL的优势,研究团队将模型在所有基准任务上的性能与现有最先进方法进行了对比。
结果显示,在11项任务中,MAMMAL在9项任务上达到最先进性能,其他两项任务则取得了竞争性结果,尤其在抗体-抗原结合预测和蛋白质功能分类任务上表现突出。进一步分析表明,模型的跨模态对齐机制和多任务学习策略是其性能提升的关键。在多任务训练过程中,模型能够同时保留各模态信息的特征,同时捕捉跨模态间的潜在相关性,从而在不同类型的任务中均表现出稳健性和准确性。此外,微调阶段针对特定靶点或抗原的优化进一步提升了模型在持出测试集上的预测能力,使其能够快速适应新的任务和数据类型。
表2 MAMMAL与现有最先进方法在各基准任务上的性能指标比较
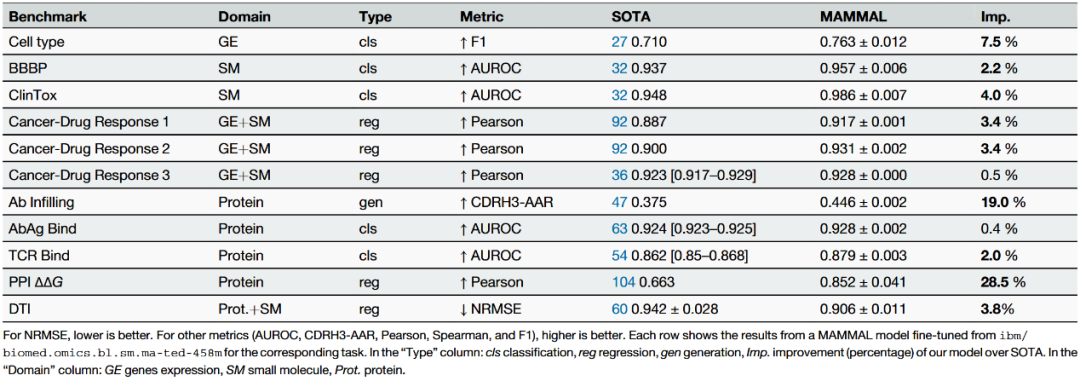
抗体-抗原结合预测案例分析
在七种不同抗原的结合预测实验中,微调后的MAMMAL模型在五个抗原上显著优于 AlphaFold3(AF3)预测置信度分数,AUROC提升幅度在0.15–0.35之间。以HER2为例,AF3对HER2的预测表现不佳,主要原因是AF3预测的结合构象集中在与已知FDA批准抗体不同的区域,导致难以区分高亲和力与低亲和力抗体。相比之下,MAMMAL能够利用跨模态信息识别HER2的关键结合位点,从而准确预测高亲和力抗体。
在TBG任务中,AF3能区分结合与非结合抗体,但结合构象分布仍有一定重叠,模型难以完全捕捉空间特异性。而MAMMAL在同一任务上,通过序列-结构联合嵌入,清晰地将结合抗体与非结合抗体在潜在空间分开,预测精度显著提高。跨抗原分析显示,MAMMAL能够适应不同抗原的结合模式,包括表面暴露位点多样性和结合界面复杂性较高的抗原,这表明模型具备良好的泛化能力。
表3 每靶点AUROC比较(MAMMAL vs AF3)
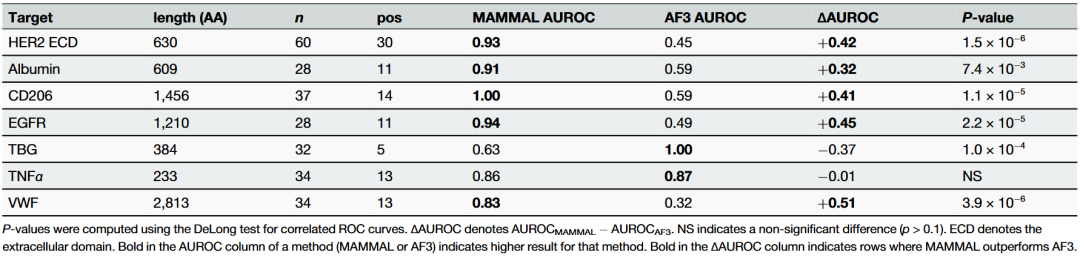
此外,实验还分析了微调过程中不同数据类型对预测性能的贡献。结果发现,联合使用抗体序列、抗原序列及小分子辅助信息的模型表现最佳,而仅依赖序列的模型性能略低。这验证了跨模态对齐嵌入能够有效融合多种生物信息,从而提升抗体-抗原结合预测的准确性。
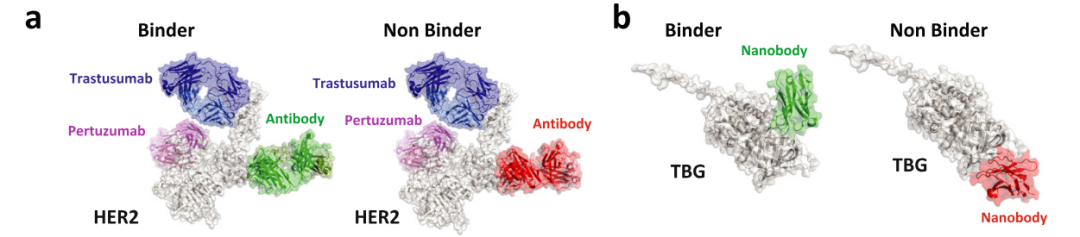
图2 AF3预测的纳米抗体结合构象(HER2与TBG)
总结
MAMMAL建立统一跨模态基础模型,将蛋白质、抗体、小分子和基因表达信息整合于同一潜在空间,实现药物发现任务的高性能预测。其在抗体-抗原结合预测、小分子活性回归及跨模态生成任务上表现优异,为生物医药领域的AI应用提供了新工具。公开可用的模型和框架将推动跨机构合作、提高计算药物发现效率,并为未来多模态药物设计奠定基础。
参考链接:
Shoshan, Y., Raboh, M., Ozery-Flato, M. et al. MAMMAL - Molecular Aligned Multi-Modal Architecture and Language for biomedical discovery. npj Drug Discov. 3, 14 (2026).
https://doi.org/10.1038/s44386-026-00047-4
--------- End ---------
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号