综合实战:构建 Coding Agent 核心引擎

综合实战:构建 Coding Agent 核心引擎

安全风信子
发布于 2026-05-27 08:31:13
发布于 2026-05-27 08:31:13
作者: HOS(安全风信子) 日期: 2026-05-24 主要来源平台: GitHub 摘要: 本文整合第二卷的所有核心组件,构建一个完整的 Coding Agent。这个 Agent 将能够:理解用户的自然语言任务、在代码库中检索相关上下文、生成并执行修改方案、处理多轮反馈、记住跨会话的项目知识。通过这个项目,读者将理解各个 AI 核心组件如何协同工作,建立起对 AI IDE 核心架构的完整认知。本文深入剖析了 Coding Agent 的六大核心模块——任务理解引擎、混合检索系统、代码生成管道、执行反馈循环、三层记忆体系、调度编排层——并提供超过 5000 行的完整可运行代码实现。
目录- 本节核心技术价值
- 1. 引言:从组件到系统
- 1.1 为什么需要综合实战
- 1.2 系统设计目标
- 1.3 整体架构概览
- 2. 核心数据结构设计
- 本节核心技术价值
- 2.1 基础数据模型
- 2.2 记忆数据模型
- 3. 任务理解引擎实现
- 本节核心技术价值
- 3.1 意图识别器设计
- 3.2 Prompt 模板系统
- 约束条件
- 代码库上下文
- 输出要求
- 4. 混合检索系统实现
- 本节核心技术价值
- 4.1 检索架构设计
- 4.2 检索器实现
- 5. 代码生成管道实现
- 本节核心技术价值
- 5.1 生成管道架构
- 5.2 生成器实现
- 6. 执行与反馈循环实现
- 本节核心技术价值
- 6.1 执行引擎设计
- 7. 三层记忆体系实现
- 本节核心技术价值
- 7.1 记忆架构设计
- 7.2 记忆管理器实现
- 8. 调度编排层实现
- 本节核心技术价值
- 8.1 调度器实现
- 9. 完整集成与使用示例
- 本节核心技术价值
- 9.1 集成示例
- 9.2 使用流程图
- 10. 总结与展望
- 本节核心技术价值
- 10.1 架构总结
- 10.2 已知局限
- 10.3 未来演进方向
- 10.4 参考架构对比
- 参考链接
- 附录 A:核心数据模型完整代码
- 附录 B:意图识别器完整代码
- 附录 C:检索系统完整代码
- 附录 D:代码生成管道完整代码
- 附录 E:执行引擎完整代码
- 附录 F:三层记忆完整代码
- 附录 G:调度编排层完整代码
- 附录 H:完整 Agent 集成代码
- 1.1 为什么需要综合实战
- 1.2 系统设计目标
- 1.3 整体架构概览
- 本节核心技术价值
- 2.1 基础数据模型
- 2.2 记忆数据模型
- 本节核心技术价值
- 3.1 意图识别器设计
- 3.2 Prompt 模板系统
- 本节核心技术价值
- 4.1 检索架构设计
- 4.2 检索器实现
- 本节核心技术价值
- 5.1 生成管道架构
- 5.2 生成器实现
- 本节核心技术价值
- 6.1 执行引擎设计
- 本节核心技术价值
- 7.1 记忆架构设计
- 7.2 记忆管理器实现
- 本节核心技术价值
- 8.1 调度器实现
- 本节核心技术价值
- 9.1 集成示例
- 9.2 使用流程图
- 本节核心技术价值
- 10.1 架构总结
- 10.2 已知局限
- 10.3 未来演进方向
- 10.4 参考架构对比
本节核心技术价值
本文为你提供的核心价值是建立对 Coding Agent 完整架构的系统认知,理解六大核心组件(任务理解引擎、混合检索系统、代码生成管道、执行反馈循环、三层记忆体系、调度编排层)如何协同工作。通过完整的代码实现和架构图解,读者将掌握构建企业级 AI 辅助开发系统的核心能力。
1. 引言:从组件到系统
1.1 为什么需要综合实战
在前面的章节中,我们逐一剖析了 Coding Agent 的各个核心组件:任务理解引擎负责解析用户的自然语言指令,混合检索系统负责在代码库中定位相关上下文,代码生成管道负责利用大语言模型产生高质量代码,执行反馈循环负责处理多轮对话和人工确认,三层记忆体系负责跨会话持久化知识,调度编排层负责协调各组件的有序运行。
然而,组件的简单堆叠并不能构成一个有效的系统。真正的挑战在于:
- 接口一致性:各组件之间的数据格式和调用契约如何统一
- 状态同步:在多轮对话中,如何保持上下文的一致性
- 错误传播:某个组件失败时,系统如何优雅降级
- 资源调度:在有限计算资源下,如何优化组件执行顺序
- 可扩展性:如何支持新组件的插入和现有组件的替换
本文将解决这些问题,构建一个生产级别的 Coding Agent 核心引擎。
1.2 系统设计目标
我们的 Coding Agent 需要满足以下设计目标:
目标维度 | 具体要求 | 量化指标 |
|---|---|---|
功能完整性 | 支持任务理解、检索、生成、执行、反馈、记忆 | 覆盖 90%+ 开发场景 |
响应延迟 | 端到端任务处理时间 | P99 < 30s |
上下文窗口利用率 | 有效利用 LLM 的上下文窗口 | > 85% |
检索召回率 | 相关上下文不被遗漏 | > 95% |
执行成功率 | 代码生成后能正确执行 | > 90% |
记忆持久性 | 跨会话知识保留 | 100% |
1.3 整体架构概览
渲染错误: Mermaid 渲染失败: Parse error on line 2: ...t TD User([用户请求"]) --> InputProcesso... ----------------------^ Expecting 'SQE', 'DOUBLECIRCLEEND', 'PE', '-)', 'STADIUMEND', 'SUBROUTINEEND', 'PIPE', 'CYLINDEREND', 'DIAMOND_STOP', 'TAGEND', 'TRAPEND', 'INVTRAPEND', 'UNICODE_TEXT', 'TEXT', 'TAGSTART', got 'STR'
图 1-1: Coding Agent 整体架构图
如图 1-1 所示,系统采用六层架构设计:
- 用户交互层:负责请求的接收和响应的格式化输出
- 任务理解层:解析用户意图,分解任务
- 检索与上下文层:多策略检索,构建生成上下文
- 代码生成层:Prompt 模板组装,LLM 调用
- 执行反馈层:代码执行,结果验证,多轮反馈
- 调度编排层:全局状态管理,组件协调
2. 核心数据结构设计
本节核心技术价值
本节为你提供的核心价值是掌握 Coding Agent 的核心数据模型设计,理解如何使用 Pydantic 构建类型安全、可验证、可序列化的数据流管道。这些数据模型是组件间通信的基础,也是系统可扩展性的保障。
2.1 基础数据模型
Coding Agent 的核心数据模型包括:用户请求、任务结构、代码上下文、生成结果、执行反馈等。我们使用 Pydantic 实现这些模型,确保类型安全和运行时验证。
"""
Coding Agent 核心数据模型
===============================
定义系统内所有核心数据结构的 Pydantic 模型
作者:HOS(安全风信子)
日期:2026-05-24
"""
from __future__ import annotations
import json
import uuid
from datetime import datetime
from enum import Enum
from typing import Any, Optional
from pydantic import BaseModel, Field, field_validator, model_validator
class TaskPriority(str, Enum):
"""任务优先级枚举"""
LOW = "low"
MEDIUM = "medium"
HIGH = "high"
CRITICAL = "critical"
class TaskStatus(str, Enum):
"""任务状态枚举"""
PENDING = "pending"
RUNNING = "running"
WAITING_CONFIRMATION = "waiting_confirmation"
COMPLETED = "completed"
FAILED = "failed"
CANCELLED = "cancelled"
class IntentType(str, Enum):
"""意图类型枚举"""
CREATE = "create" # 创建新文件/函数/类
MODIFY = "modify" # 修改现有代码
DELETE = "delete" # 删除代码
QUERY = "query" # 查询信息
REFACTOR = "refactor" # 重构
DEBUG = "debug" # 调试
TEST = "test" # 生成测试
EXPLAIN = "explain" # 解释代码
REVIEW = "review" # 代码审查
OPTIMIZE = "optimize" # 性能优化
MIGRATE = "migrate" # 迁移
UNKNOWN = "unknown"
class RetrievalStrategy(str, Enum):
"""检索策略枚举"""
SEMANTIC = "semantic" # 语义向量检索
KEYWORD = "keyword" # 关键词 BM25 检索
SYNTAX = "syntax" # 语法结构检索
LINEAGE = "lineage" # 代码血缘检索
HYBRID = "hybrid" # 混合检索
class UserRequest(BaseModel):
"""
用户请求模型
==============
封装用户输入的自然语言请求
Attributes:
request_id: 请求唯一标识
raw_text: 原始输入文本
timestamp: 请求时间戳
context_window: 上下文窗口大小
user_id: 用户标识(可选)
session_id: 会话标识(可选)
metadata: 附加元数据
"""
request_id: str = Field(
default_factory=lambda: str(uuid.uuid4()),
description="请求唯一标识"
)
raw_text: str = Field(
...,
min_length=1,
max_length=10000,
description="原始输入文本"
)
timestamp: datetime = Field(
default_factory=datetime.now,
description="请求时间戳"
)
context_window: int = Field(
default=128000,
ge=1000,
le=200000,
description="上下文窗口大小"
)
user_id: Optional[str] = Field(
default=None,
description="用户标识"
)
session_id: Optional[str] = Field(
default=None,
description="会话标识"
)
metadata: dict[str, Any] = Field(
default_factory=dict,
description="附加元数据"
)
@field_validator("raw_text")
@classmethod
def strip_whitespace(cls, v: str) -> str:
"""自动去除首尾空白"""
return v.strip()
def to_dict(self) -> dict[str, Any]:
"""序列化为字典"""
return self.model_dump(mode="json")
@classmethod
def from_dict(cls, data: dict[str, Any]) -> UserRequest:
"""从字典反序列化"""
return cls.model_validate(data)
class ParsedIntent(BaseModel):
"""
解析后的意图模型
==================
任务理解引擎的输出结构
Attributes:
intent_type: 识别的意图类型
confidence: 置信度分数 [0, 1]
entities: 提取的实体列表
constraints: 约束条件
target_files: 目标文件列表
"""
intent_type: IntentType = Field(
...,
description="识别的意图类型"
)
confidence: float = Field(
...,
ge=0.0,
le=1.0,
description="置信度分数"
)
entities: list[Entity] = Field(
default_factory=list,
description="提取的实体列表"
)
constraints: list[Constraint] = Field(
default_factory=list,
description="约束条件"
)
target_files: list[str] = Field(
default_factory=list,
description="目标文件列表"
)
raw_parameters: dict[str, Any] = Field(
default_factory=dict,
description="原始参数字典"
)
def is_high_confidence(self, threshold: float = 0.8) -> bool:
"""判断是否高置信度"""
return self.confidence >= threshold
def get_primary_entity(self) -> Optional[Entity]:
"""获取主要实体"""
if not self.entities:
return None
return max(self.entities, key=lambda e: e.importance_score)
class Entity(BaseModel):
"""
实体模型
==========
表示从用户请求中提取的结构化实体
Attributes:
entity_type: 实体类型(file, function, class, variable, module)
name: 实体名称
importance_score: 重要性分数 [0, 1]
location: 位置信息(文件路径、行号范围)
attributes: 属性字典
"""
entity_type: str = Field(
...,
description="实体类型"
)
name: str = Field(
...,
description="实体名称"
)
importance_score: float = Field(
default=0.5,
ge=0.0,
le=1.0,
description="重要性分数"
)
location: Optional[FileLocation] = Field(
default=None,
description="位置信息"
)
attributes: dict[str, Any] = Field(
default_factory=dict,
description="属性字典"
)
class FileLocation(BaseModel):
"""
文件位置模型
==============
表示代码在文件系统中的位置
Attributes:
file_path: 文件绝对路径
start_line: 起始行号(从1开始)
end_line: 结束行号
column_start: 起始列号
column_end: 结束列号
"""
file_path: str = Field(
...,
description="文件绝对路径"
)
start_line: int = Field(
default=1,
ge=1,
description="起始行号"
)
end_line: Optional[int] = Field(
default=None,
ge=1,
description="结束行号"
)
column_start: Optional[int] = Field(
default=None,
ge=0,
description="起始列号"
)
column_end: Optional[int] = Field(
default=None,
ge=0,
description="结束列号"
)
def to_range_string(self) -> str:
"""转换为范围字符串,如 'src/main.py:10-20'"""
if self.end_line:
return f"{self.file_path}:{self.start_line}-{self.end_line}"
return f"{self.file_path}:{self.start_line}"
class Constraint(BaseModel):
"""
约束条件模型
==============
表示用户请求中的约束条件
Attributes:
constraint_type: 约束类型
description: 约束描述
value: 约束值
hard_constraint: 是否为硬约束(必须满足)
"""
constraint_type: str = Field(
...,
description="约束类型"
)
description: str = Field(
...,
description="约束描述"
)
value: Any = Field(
...,
description="约束值"
)
hard_constraint: bool = Field(
default=True,
description="是否为硬约束"
)
class Task(BaseModel):
"""
任务模型
==========
表示分解后的原子任务单元
Attributes:
task_id: 任务唯一标识
description: 任务描述
priority: 任务优先级
status: 任务状态
dependencies: 依赖的任务 ID 列表
subtasks: 子任务列表
created_at: 创建时间
updated_at: 更新时间
"""
task_id: str = Field(
default_factory=lambda: str(uuid.uuid4()),
description="任务唯一标识"
)
description: str = Field(
...,
description="任务描述"
)
priority: TaskPriority = Field(
default=TaskPriority.MEDIUM,
description="任务优先级"
)
status: TaskStatus = Field(
default=TaskStatus.PENDING,
description="任务状态"
)
dependencies: list[str] = Field(
default_factory=list,
description="依赖的任务 ID 列表"
)
subtasks: list[Task] = Field(
default_factory=list,
description="子任务列表"
)
parent_id: Optional[str] = Field(
default=None,
description="父任务 ID"
)
created_at: datetime = Field(
default_factory=datetime.now,
description="创建时间"
)
updated_at: datetime = Field(
default_factory=datetime.now,
description="更新时间"
)
metadata: dict[str, Any] = Field(
default_factory=dict,
description="任务元数据"
)
def is_leaf_task(self) -> bool:
"""判断是否为叶子任务(无子任务)"""
return len(self.subtasks) == 0
def is_ready_to_execute(self, completed_tasks: set[str]) -> bool:
"""判断任务是否准备好执行(依赖已全部完成)"""
return all(dep_id in completed_tasks for dep_id in self.dependencies)
class CodeContext(BaseModel):
"""
代码上下文模型
================
封装检索系统返回的上下文信息
Attributes:
context_id: 上下文唯一标识
snippets: 代码片段列表
files: 文件列表
symbols: 符号列表
relevance_scores: 各片段相关性分数
total_tokens: 总 token 数
"""
context_id: str = Field(
default_factory=lambda: str(uuid.uuid4()),
description="上下文唯一标识"
)
snippets: list[CodeSnippet] = Field(
default_factory=list,
description="代码片段列表"
)
files: list[FileContent] = Field(
default_factory=list,
description="完整文件列表"
)
symbols: list[Symbol] = Field(
default_factory=list,
description="符号列表(函数、类、变量等)"
)
relevance_scores: dict[str, float] = Field(
default_factory=dict,
description="各片段 ID 到相关性分数的映射"
)
total_tokens: int = Field(
default=0,
description="总 token 数估计"
)
def add_snippet(self, snippet: CodeSnippet, score: float) -> None:
"""添加代码片段"""
self.snippets.append(snippet)
self.context_id # 确保有 context_id
self.relevance_scores[snippet.snippet_id] = score
def sort_by_relevance(self) -> None:
"""按相关性排序"""
self.snippets.sort(
key=lambda s: self.relevance_scores.get(s.snippet_id, 0.0),
reverse=True
)
def truncate(self, max_tokens: int) -> None:
"""截断以满足 token 限制"""
# 简单按比例截断,实际应按 token 计数
if self.total_tokens <= max_tokens:
return
current_tokens = 0
kept_snippets = []
for snippet in self.snippets:
snippet_tokens = len(snippet.content) // 4 # 粗略估计
if current_tokens + snippet_tokens <= max_tokens:
kept_snippets.append(snippet)
current_tokens += snippet_tokens
else:
break
self.snippets = kept_snippets
self.total_tokens = current_tokens
class CodeSnippet(BaseModel):
"""
代码片段模型
==============
表示检索返回的单个代码片段
Attributes:
snippet_id: 片段唯一标识
content: 代码内容
file_path: 所属文件路径
start_line: 起始行号
end_line: 结束行号
language: 编程语言
snippet_type: 片段类型(function, class, block)
"""
snippet_id: str = Field(
default_factory=lambda: str(uuid.uuid4()),
description="片段唯一标识"
)
content: str = Field(
...,
description="代码内容"
)
file_path: str = Field(
...,
description="所属文件路径"
)
start_line: int = Field(
default=1,
ge=1,
description="起始行号"
)
end_line: Optional[int] = Field(
default=None,
ge=1,
description="结束行号"
)
language: Optional[str] = Field(
default=None,
description="编程语言"
)
snippet_type: str = Field(
default="block",
description="片段类型"
)
def to_context_string(self) -> str:
"""转换为上下文字符串"""
location = f"{self.file_path}:{self.start_line}-{self.end_line or self.start_line}"
return f"// {location}\n{self.content}"
class FileContent(BaseModel):
"""
文件内容模型
==============
表示完整文件的内容
Attributes:
file_path: 文件路径
content: 文件内容
language: 编程语言
ast: 抽象语法树(可选)
imports: 导入列表
"""
file_path: str = Field(
...,
description="文件路径"
)
content: str = Field(
...,
description="文件内容"
)
language: Optional[str] = Field(
default=None,
description="编程语言"
)
ast: Optional[dict[str, Any]] = Field(
default=None,
description="抽象语法树"
)
imports: list[str] = Field(
default_factory=list,
description="导入列表"
)
encoding: str = Field(
default="utf-8",
description="文件编码"
)
class Symbol(BaseModel):
"""
符号模型
==========
表示代码中的符号定义(函数、类、变量等)
Attributes:
symbol_id: 符号唯一标识
name: 符号名称
symbol_type: 符号类型
file_path: 定义文件
line_number: 定义行号
signature: 函数签名
documentation: 文档字符串
"""
symbol_id: str = Field(
default_factory=lambda: str(uuid.uuid4()),
description="符号唯一标识"
)
name: str = Field(
...,
description="符号名称"
)
symbol_type: str = Field(
...,
description="符号类型"
)
file_path: str = Field(
...,
description="定义文件"
)
line_number: int = Field(
...,
ge=1,
description="定义行号"
)
signature: Optional[str] = Field(
default=None,
description="函数签名"
)
documentation: Optional[str] = Field(
default=None,
description="文档字符串"
)
references: list[FileLocation] = Field(
default_factory=list,
description="引用位置列表"
)
class GenerationConfig(BaseModel):
"""
生成配置模型
==============
控制代码生成行为的配置参数
Attributes:
model_name: 模型名称
temperature: 温度参数
max_tokens: 最大 token 数
top_p: top-p 采样参数
stop_sequences: 停止序列列表
presence_penalty: 存在惩罚
frequency_penalty: 频率惩罚
"""
model_name: str = Field(
default="gpt-4o",
description="模型名称"
)
temperature: float = Field(
default=0.2,
ge=0.0,
le=2.0,
description="温度参数"
)
max_tokens: int = Field(
default=4096,
ge=100,
le=128000,
description="最大 token 数"
)
top_p: float = Field(
default=0.95,
ge=0.0,
le=1.0,
description="top-p 采样参数"
)
stop_sequences: list[str] = Field(
default_factory=list,
description="停止序列列表"
)
presence_penalty: float = Field(
default=0.0,
ge=-2.0,
le=2.0,
description="存在惩罚"
)
frequency_penalty: float = Field(
default=0.0,
ge=-2.0,
le=2.0,
description="频率惩罚"
)
def to_api_params(self) -> dict[str, Any]:
"""转换为 API 调用参数"""
return {
"model": self.model_name,
"temperature": self.temperature,
"max_tokens": self.max_tokens,
"top_p": self.top_p,
"stop": self.stop_sequences or None,
"presence_penalty": self.presence_penalty,
"frequency_penalty": self.frequency_penalty,
}
class GeneratedCode(BaseModel):
"""
生成的代码模型
================
表示代码生成管道的输出
Attributes:
code: 生成的代码内容
language: 编程语言
explanation: 代码解释
confidence: 生成置信度
changes: 文件变更列表
"""
code: str = Field(
...,
description="生成的代码内容"
)
language: Optional[str] = Field(
default=None,
description="编程语言"
)
explanation: str = Field(
default="",
description="代码解释"
)
confidence: float = Field(
default=0.5,
ge=0.0,
le=1.0,
description="生成置信度"
)
changes: list[FileChange] = Field(
default_factory=list,
description="文件变更列表"
)
raw_response: Optional[str] = Field(
default=None,
description="原始 API 响应"
)
class FileChange(BaseModel):
"""
文件变更模型
==============
表示对文件的修改操作
Attributes:
change_type: 变更类型(create, modify, delete)
file_path: 文件路径
old_content: 原内容(用于修改/删除)
new_content: 新内容(用于创建/修改)
diff: 差异信息
"""
change_type: str = Field(
...,
description="变更类型"
)
file_path: str = Field(
...,
description="文件路径"
)
old_content: Optional[str] = Field(
default=None,
description="原内容"
)
new_content: Optional[str] = Field(
default=None,
description="新内容"
)
diff: Optional[str] = Field(
default=None,
description="差异信息"
)
backup_path: Optional[str] = Field(
default=None,
description="备份文件路径"
)
class ExecutionResult(BaseModel):
"""
执行结果模型
==============
表示代码执行的结果
Attributes:
success: 是否成功
output: 标准输出
error: 错误信息
exit_code: 退出码
execution_time: 执行时间(秒)
"""
success: bool = Field(
...,
description="是否成功"
)
output: str = Field(
default="",
description="标准输出"
)
error: Optional[str] = Field(
default=None,
description="错误信息"
)
exit_code: int = Field(
default=0,
description="退出码"
)
execution_time: float = Field(
default=0.0,
ge=0.0,
description="执行时间(秒)"
)
stdout_lines: list[str] = Field(
default_factory=list,
description="标准输出行列表"
)
stderr_lines: list[str] = Field(
default_factory=list,
description="标准错误行列表"
)
class Feedback(BaseModel):
"""
反馈模型
==========
表示用户或系统对生成结果的反馈
Attributes:
feedback_type: 反馈类型
rating: 评分 [1-5]
comment: 评语
corrections: 修正建议列表
accepted: 是否被接受
"""
feedback_type: str = Field(
...,
description="反馈类型"
)
rating: Optional[int] = Field(
default=None,
ge=1,
le=5,
description="评分"
)
comment: Optional[str] = Field(
default=None,
description="评语"
)
corrections: list[Correction] = Field(
default_factory=list,
description="修正建议列表"
)
accepted: bool = Field(
default=False,
description="是否被接受"
)
class Correction(BaseModel):
"""
修正建议模型
==============
表示具体的修正内容
Attributes:
original: 原内容
suggested: 建议内容
reason: 修正原因
location: 位置信息
"""
original: str = Field(
...,
description="原内容"
)
suggested: str = Field(
...,
description="建议内容"
)
reason: Optional[str] = Field(
default=None,
description="修正原因"
)
location: Optional[FileLocation] = Field(
default=None,
description="位置信息"
)2.2 记忆数据模型
三层记忆体系需要持久化的数据模型如下:
"""
三层记忆体系数据模型
=====================
作者:HOS(安全风信子)
日期:2026-05-24
"""
from pydantic import BaseModel, Field
from typing import Any, Optional
import uuid
from datetime import datetime
class WorkingMemory(BaseModel):
"""
工作记忆模型(短时记忆)
=========================
当前会话内的上下文信息
Attributes:
session_id: 会话 ID
messages: 消息历史
current_task: 当前任务
recent_contexts: 最近使用的上下文
attention_focus: 当前注意力焦点
"""
session_id: str = Field(
default_factory=lambda: str(uuid.uuid4()),
description="会话 ID"
)
messages: list[Message] = Field(
default_factory=list,
description="消息历史"
)
current_task: Optional[Task] = Field(
default=None,
description="当前任务"
)
recent_contexts: list[str] = Field(
default_factory=list,
description="最近使用的上下文 ID 列表"
)
attention_focus: Optional[str] = Field(
default=None,
description="当前注意力焦点"
)
created_at: datetime = Field(
default_factory=datetime.now,
description="创建时间"
)
updated_at: datetime = Field(
default_factory=datetime.now,
description="更新时间"
)
def add_message(self, role: str, content: str) -> Message:
"""添加消息"""
msg = Message(role=role, content=content)
self.messages.append(msg)
self.updated_at = datetime.now()
return msg
def get_recent_messages(self, n: int = 10) -> list[Message]:
"""获取最近 N 条消息"""
return self.messages[-n:] if len(self.messages) > n else self.messages
class Message(BaseModel):
"""
消息模型
==========
表示对话中的单条消息
Attributes:
message_id: 消息 ID
role: 角色(user/assistant/system)
content: 消息内容
timestamp: 时间戳
"""
message_id: str = Field(
default_factory=lambda: str(uuid.uuid4()),
description="消息 ID"
)
role: str = Field(
...,
description="角色"
)
content: str = Field(
...,
description="消息内容"
)
timestamp: datetime = Field(
default_factory=datetime.now,
description="时间戳"
)
class EpisodicMemory(BaseModel):
"""
情景记忆模型(中时记忆)
========================
项目级别的历史交互记录
Attributes:
project_id: 项目 ID
episodes: 情景记录列表
key_decisions: 关键决策列表
patterns: 模式总结
"""
project_id: str = Field(
...,
description="项目 ID"
)
episodes: list[Episode] = Field(
default_factory=list,
description="情景记录列表"
)
key_decisions: list[Decision] = Field(
default_factory=list,
description="关键决策列表"
)
patterns: list[Pattern] = Field(
default_factory=list,
description="模式总结"
)
created_at: datetime = Field(
default_factory=datetime.now,
description="创建时间"
)
updated_at: datetime = Field(
default_factory=datetime.now,
description="更新时间"
)
def add_episode(self, episode: Episode) -> None:
"""添加情景记录"""
self.episodes.append(episode)
self.updated_at = datetime.now()
def search_episodes(self, query: str) -> list[Episode]:
"""搜索情景记录"""
# 简化实现,实际应使用向量检索
return [
ep for ep in self.episodes
if query.lower() in ep.summary.lower()
]
class Episode(BaseModel):
"""
情景记录模型
==============
表示一次完整的交互会话
Attributes:
episode_id: 情景 ID
summary: 摘要
tasks: 执行的任务列表
outcomes: 结果列表
lessons: 教训总结
timestamp: 时间戳
"""
episode_id: str = Field(
default_factory=lambda: str(uuid.uuid4()),
description="情景 ID"
)
summary: str = Field(
...,
description="摘要"
)
tasks: list[Task] = Field(
default_factory=list,
description="执行的任务列表"
)
outcomes: list[str] = Field(
default_factory=list,
description="结果列表"
)
lessons: list[str] = Field(
default_factory=list,
description="教训总结"
)
timestamp: datetime = Field(
default_factory=datetime.now,
description="时间戳"
)
class Decision(BaseModel):
"""
决策模型
==========
表示一个关键决策
Attributes:
decision_id: 决策 ID
context: 决策上下文
options: 可选方案
chosen: 最终选择
rationale: 选择理由
timestamp: 时间戳
"""
decision_id: str = Field(
default_factory=lambda: str(uuid.uuid4()),
description="决策 ID"
)
context: str = Field(
...,
description="决策上下文"
)
options: list[str] = Field(
...,
description="可选方案"
)
chosen: str = Field(
...,
description="最终选择"
)
rationale: str = Field(
...,
description="选择理由"
)
timestamp: datetime = Field(
default_factory=datetime.now,
description="时间戳"
)
class Pattern(BaseModel):
"""
模式模型
==========
表示识别出的代码模式或交互模式
Attributes:
pattern_id: 模式 ID
pattern_type: 模式类型
description: 模式描述
examples: 示例列表
usage_count: 使用次数
"""
pattern_id: str = Field(
default_factory=lambda: str(uuid.uuid4()),
description="模式 ID"
)
pattern_type: str = Field(
...,
description="模式类型"
)
description: str = Field(
...,
description="模式描述"
)
examples: list[str] = Field(
default_factory=list,
description="示例列表"
)
usage_count: int = Field(
default=0,
description="使用次数"
)
class SemanticMemory(BaseModel):
"""
语义记忆模型(长时记忆)
=========================
项目知识和代码规范
Attributes:
project_id: 项目 ID
codebase_summary: 代码库摘要
architecture: 架构信息
conventions: 代码规范
api_specs: API 规范
glossary: 术语表
"""
project_id: str = Field(
...,
description="项目 ID"
)
codebase_summary: str = Field(
default="",
description="代码库摘要"
)
architecture: ArchitectureInfo = Field(
default_factory=ArchitectureInfo,
description="架构信息"
)
conventions: list[Convention] = Field(
default_factory=list,
description="代码规范列表"
)
api_specs: list[APISpec] = Field(
default_factory=list,
description="API 规范列表"
)
glossary: dict[str, str] = Field(
default_factory=dict,
description="术语表"
)
updated_at: datetime = Field(
default_factory=datetime.now,
description="更新时间"
)
def add_convention(self, convention: Convention) -> None:
"""添加代码规范"""
self.conventions.append(convention)
self.updated_at = datetime.now()
class ArchitectureInfo(BaseModel):
"""
架构信息模型
==============
表示项目的架构描述
Attributes:
overview: 架构概览
components: 组件列表
dependencies: 依赖关系
data_flow: 数据流描述
"""
overview: str = Field(
default="",
description="架构概览"
)
components: list[Component] = Field(
default_factory=list,
description="组件列表"
)
dependencies: list[Dependency] = Field(
default_factory=list,
description="依赖关系"
)
data_flow: str = Field(
default="",
description="数据流描述"
)
class Component(BaseModel):
"""
组件模型
==========
表示架构中的组件
Attributes:
name: 组件名称
description: 组件描述
responsibilities: 职责列表
file_path: 文件路径
"""
name: str = Field(
...,
description="组件名称"
)
description: str = Field(
...,
description="组件描述"
)
responsibilities: list[str] = Field(
default_factory=list,
description="职责列表"
)
file_path: Optional[str] = Field(
default=None,
description="文件路径"
)
class Dependency(BaseModel):
"""
依赖关系模型
==============
表示组件间的依赖关系
Attributes:
source: 源组件
target: 目标组件
dependency_type: 依赖类型
description: 描述
"""
source: str = Field(
...,
description="源组件"
)
target: str = Field(
...,
description="目标组件"
)
dependency_type: str = Field(
default="import",
description="依赖类型"
)
description: Optional[str] = Field(
default=None,
description="描述"
)
class Convention(BaseModel):
"""
代码规范模型
==============
表示项目的代码规范
Attributes:
convention_id: 规范 ID
name: 规范名称
description: 规范描述
examples: 示例代码
applies_to: 适用范围
"""
convention_id: str = Field(
default_factory=lambda: str(uuid.uuid4()),
description="规范 ID"
)
name: str = Field(
...,
description="规范名称"
)
description: str = Field(
...,
description="规范描述"
)
examples: list[str] = Field(
default_factory=list,
description="示例代码"
)
applies_to: list[str] = Field(
default_factory=list,
description="适用范围(如 ['*.py', '*.js'])"
)
class APISpec(BaseModel):
"""
API 规范模型
=============
表示项目的 API 规范
Attributes:
endpoint: 端点路径
method: HTTP 方法
description: 描述
parameters: 参数列表
response: 响应格式
"""
endpoint: str = Field(
...,
description="端点路径"
)
method: str = Field(
default="GET",
description="HTTP 方法"
)
description: str = Field(
default="",
description="描述"
)
parameters: list[APIParameter] = Field(
default_factory=list,
description="参数列表"
)
response: Optional[str] = Field(
default=None,
description="响应格式"
)
class APIParameter(BaseModel):
"""
API 参数模型
=============
表示 API 的参数定义
Attributes:
name: 参数名称
param_type: 参数类型
required: 是否必需
description: 描述
default: 默认值
"""
name: str = Field(
...,
description="参数名称"
)
param_type: str = Field(
...,
description="参数类型"
)
required: bool = Field(
default=False,
description="是否必需"
)
description: str = Field(
default="",
description="描述"
)
default: Optional[Any] = Field(
default=None,
description="默认值"
)3. 任务理解引擎实现
本节核心技术价值
本节为你提供的核心价值是掌握基于 LLM 的意图识别和任务分解技术,理解如何使用结构化输出和 Few-shot Prompting 实现高精度的意图分类、实体提取和约束解析。这是从"自然语言"到"机器可执行任务"的关键桥梁。
3.1 意图识别器设计
意图识别是 Coding Agent 理解用户请求的第一步。我们采用基于 LLM 的分类器,结合 Few-shot Learning 技术实现高精度的意图识别。
"""
任务理解引擎
=============
意图识别、实体提取、任务分解
作者:HOS(安全风信子)
日期:2026-05-24
"""
from __future__ import annotations
import json
import re
from typing import Any, Optional
from pydantic import BaseModel
from coding_agent.core.data_models import (
UserRequest,
ParsedIntent,
IntentType,
Entity,
Constraint,
FileLocation,
Task,
TaskPriority,
TaskStatus,
)
from coding_agent.core.prompt_templates import IntentRecognitionTemplate
class IntentRecognizer:
"""
意图识别器
==========
使用 LLM 进行意图识别和实体提取
支持的意图类型:
- CREATE: 创建新文件/函数/类
- MODIFY: 修改现有代码
- DELETE: 删除代码
- QUERY: 查询信息
- REFACTOR: 重构
- DEBUG: 调试
- TEST: 生成测试
- EXPLAIN: 解释代码
- REVIEW: 代码审查
- OPTIMIZE: 性能优化
- MIGRATE: 迁移
"""
def __init__(
self,
llm_client: Any,
model_name: str = "gpt-4o",
confidence_threshold: float = 0.75,
):
"""
初始化意图识别器
Args:
llm_client: LLM 客户端实例
model_name: 模型名称
confidence_threshold: 置信度阈值
"""
self.llm_client = llm_client
self.model_name = model_name
self.confidence_threshold = confidence_threshold
self.template = IntentRecognitionTemplate()
# 意图类型描述映射
self.intent_descriptions = {
IntentType.CREATE: "创建新的文件、函数、类、模块或测试",
IntentType.MODIFY: "修改现有代码的功能或实现",
IntentType.DELETE: "删除文件、函数、类或代码段",
IntentType.QUERY: "查询代码库信息,如查找定义、搜索引用",
IntentType.REFACTOR: "重构代码以提高可读性或可维护性",
IntentType.DEBUG: "修复代码中的错误或问题",
IntentType.TEST: "生成单元测试或集成测试",
IntentType.EXPLAIN: "解释代码的功能或工作原理",
IntentType.REVIEW: "代码审查,检查代码质量",
IntentType.OPTIMIZE: "性能优化或资源优化",
IntentType.MIGRATE: "代码迁移,如版本升级或框架迁移",
IntentType.UNKNOWN: "无法确定的意图",
}
async def recognize(self, request: UserRequest) -> ParsedIntent:
"""
执行意图识别
Args:
request: 用户请求
Returns:
ParsedIntent: 解析后的意图对象
"""
# 构建 Prompt
prompt = self._build_recognition_prompt(request.raw_text)
# 调用 LLM
response = await self.llm_client.chat.completions.create(
model=self.model_name,
messages=[
{"role": "system", "content": self._get_system_prompt()},
{"role": "user", "content": prompt},
],
temperature=0.1,
response_format={"type": "json_object"},
)
# 解析响应
result = json.loads(response.choices[0].message.content)
# 构建 ParsedIntent
return self._build_intent(result, request.raw_text)
def _get_system_prompt(self) -> str:
"""获取系统提示词"""
return """你是一个专业的代码助手,负责分析用户的开发请求并提取结构化的意图信息。
你的任务是:
1. 识别用户的主要意图(intent_type)
2. 提取相关的实体(entities),如文件名、函数名、类名
3. 识别约束条件(constraints)
4. 估计你的置信度(confidence)
请严格按照以下 JSON 格式输出,不要添加任何额外内容:
{
"intent_type": "CREATE|MODIFY|DELETE|QUERY|REFACTOR|DEBUG|TEST|EXPLAIN|REVIEW|OPTIMIZE|MIGRATE|UNKNOWN",
"confidence": 0.0-1.0,
"entities": [
{
"entity_type": "file|function|class|variable|module|package",
"name": "实体名称",
"importance_score": 0.0-1.0,
"location_hint": "可选的位置提示"
}
],
"constraints": [
{
"constraint_type": "performance|security|style|compatibility|other",
"description": "约束描述",
"value": "约束值",
"hard_constraint": true|false
}
],
"target_files": ["文件路径列表"],
"reasoning": "你的推理过程"
}"""
def _build_recognition_prompt(self, raw_text: str) -> str:
"""构建识别 Prompt"""
examples = """
示例 1:
输入: "在 src/services/user_service.py 中添加一个新的用户注册方法,需要支持邮箱和手机号两种注册方式"
输出:
{
"intent_type": "CREATE",
"confidence": 0.95,
"entities": [
{
"entity_type": "function",
"name": "register_user",
"importance_score": 1.0,
"location_hint": "src/services/user_service.py"
},
{
"entity_type": "file",
"name": "user_service.py",
"importance_score": 0.9,
"location_hint": "src/services/"
}
],
"constraints": [
{
"constraint_type": "functionality",
"description": "支持邮箱和手机号两种注册方式",
"value": "dual_registration",
"hard_constraint": true
}
],
"target_files": ["src/services/user_service.py"],
"reasoning": "用户明确要求添加新方法,属于 CREATE 意图"
}
示例 2:
输入: "为什么我的 Python 脚本在读取文件时会报编码错误?"
输出:
{
"intent_type": "DEBUG",
"confidence": 0.92,
"entities": [
{
"entity_type": "file",
"name": "未指定的 Python 脚本",
"importance_score": 0.5,
"location_hint": null
}
],
"constraints": [
{
"constraint_type": "encoding",
"description": "文件编码问题",
"value": "utf-8",
"hard_constraint": false
}
],
"target_files": [],
"reasoning": "用户询问编码错误的原因,属于 DEBUG 意图"
}
示例 3:
输入: "优化一下订单处理模块的性能,要求 QPS 至少达到 1000"
输出:
{
"intent_type": "OPTIMIZE",
"confidence": 0.88,
"entities": [
{
"entity_type": "module",
"name": "order_processing",
"importance_score": 1.0,
"location_hint": null
}
],
"constraints": [
{
"constraint_type": "performance",
"description": "QPS 要求",
"value": 1000,
"hard_constraint": true
}
],
"target_files": [],
"reasoning": "用户明确要求性能优化,属于 OPTIMIZE 意图"
}
"""
return f"""请分析以下用户请求,提取结构化的意图信息:
{raw_text}
{examples}
请输出 JSON 格式的结果:"""
def _build_intent(self, result: dict[str, Any], raw_text: str) -> ParsedIntent:
"""从 LLM 响应构建 ParsedIntent"""
# 解析意图类型
intent_type_str = result.get("intent_type", "UNKNOWN").upper()
try:
intent_type = IntentType(intent_type_str)
except ValueError:
intent_type = IntentType.UNKNOWN
# 构建实体列表
entities = []
for ent_data in result.get("entities", []):
location = None
if ent_data.get("location_hint"):
# 尝试解析位置提示
location = self._parse_location_hint(ent_data["location_hint"])
entity = Entity(
entity_type=ent_data.get("entity_type", "unknown"),
name=ent_data.get("name", ""),
importance_score=ent_data.get("importance_score", 0.5),
location=location,
attributes={},
)
entities.append(entity)
# 构建约束列表
constraints = []
for const_data in result.get("constraints", []):
constraint = Constraint(
constraint_type=const_data.get("constraint_type", "other"),
description=const_data.get("description", ""),
value=const_data.get("value"),
hard_constraint=const_data.get("hard_constraint", True),
)
constraints.append(constraint)
# 构建目标文件列表
target_files = result.get("target_files", [])
return ParsedIntent(
intent_type=intent_type,
confidence=result.get("confidence", 0.5),
entities=entities,
constraints=constraints,
target_files=target_files,
raw_parameters=result,
)
def _parse_location_hint(self, hint: str) -> Optional[FileLocation]:
"""解析位置提示字符串"""
# 尝试解析 "file_path:line-line" 格式
match = re.match(r"(.+?):(\d+)(?:-(\d+))?$", hint)
if match:
file_path = match.group(1)
start_line = int(match.group(2))
end_line = int(match.group(3)) if match.group(3) else None
return FileLocation(
file_path=file_path,
start_line=start_line,
end_line=end_line,
)
# 尝试解析 "file_path" 格式
if "." in hint:
return FileLocation(file_path=hint, start_line=1)
return None
def is_high_confidence(self, intent: ParsedIntent) -> bool:
"""判断是否为高置信度识别"""
return intent.confidence >= self.confidence_threshold
class TaskDecomposer:
"""
任务分解器
==========
将复杂任务分解为可执行的原子任务
分解策略:
1. 顺序分解:按执行顺序分解
2. 并行分解:识别可并行执行的任务
3. 层次分解:识别父子任务关系
"""
def __init__(
self,
llm_client: Any,
model_name: str = "gpt-4o",
max_subtasks: int = 10,
):
"""
初始化任务分解器
Args:
llm_client: LLM 客户端实例
model_name: 模型名称
max_subtasks: 最大子任务数
"""
self.llm_client = llm_client
self.model_name = model_name
self.max_subtasks = max_subtasks
async def decompose(
self,
intent: ParsedIntent,
request: UserRequest,
) -> list[Task]:
"""
执行任务分解
Args:
intent: 解析后的意图
request: 原始请求
Returns:
list[Task]: 分解后的任务列表
"""
# 简单任务直接返回单个任务
if intent.confidence >= 0.9 and len(intent.entities) <= 2:
return [self._create_simple_task(intent, request)]
# 复杂任务使用 LLM 分解
return await self._llm_decompose(intent, request)
async def _llm_decompose(
self,
intent: ParsedIntent,
request: UserRequest,
) -> list[Task]:
"""使用 LLM 进行任务分解"""
prompt = f"""请将以下复杂任务分解为可执行的子任务:
原始请求:{request.raw_text}
识别的意图类型:{intent.intent_type.value}
识别的实体:{[e.name for e in intent.entities]}
约束条件:{[c.description for c in intent.constraints]}
分解要求:
1. 每个子任务应该是原子性的,可以独立执行
2. 识别子任务之间的依赖关系
3. 为每个子任务指定优先级(high/medium/low)
4. 考虑任务的执行顺序
请按以下 JSON 格式输出:
{{
"tasks": [
{{
"task_id": "task_1",
"description": "子任务描述",
"priority": "high|medium|low",
"dependencies": ["task_id1", "task_id2"],
"expected_output": "预期输出"
}}
]
}}"""
response = await self.llm_client.chat.completions.create(
model=self.model_name,
messages=[
{"role": "system", "content": "你是一个专业的任务分解专家。"},
{"role": "user", "content": prompt},
],
temperature=0.1,
response_format={"type": "json_object"},
)
result = json.loads(response.choices[0].message.content)
tasks = []
for task_data in result.get("tasks", [])[:self.max_subtasks]:
priority_str = task_data.get("priority", "medium").upper()
try:
priority = TaskPriority(priority_str)
except ValueError:
priority = TaskPriority.MEDIUM
task = Task(
description=task_data.get("description", ""),
priority=priority,
dependencies=task_data.get("dependencies", []),
metadata={
"expected_output": task_data.get("expected_output", ""),
},
)
tasks.append(task)
return tasks if tasks else [self._create_simple_task(intent, request)]
def _create_simple_task(
self,
intent: ParsedIntent,
request: UserRequest,
) -> Task:
"""创建简单任务"""
primary_entity = intent.get_primary_entity()
description = f"{intent.intent_type.value} {primary_entity.name if primary_entity else '代码'}"
return Task(
description=description,
priority=TaskPriority.MEDIUM,
metadata={
"intent": intent.model_dump(),
"original_request": request.raw_text,
},
)3.2 Prompt 模板系统
Prompt 模板是代码生成质量的关键。我们的模板系统支持变量插值、条件渲染和链式组合。
"""
Prompt 模板系统
===============
作者:HOS(安全风信子)
日期:2026-05-24
"""
from __future__ import annotations
import re
from typing import Any, Callable, Optional
from dataclasses import dataclass, field
@dataclass
class PromptTemplate:
"""
Prompt 模板基类
=================
支持变量插值和条件渲染的 Prompt 模板
Attributes:
template: 模板字符串
variables: 变量定义
conditions: 条件渲染规则
"""
template: str
variables: dict[str, Any] = field(default_factory=dict)
conditions: dict[str, Callable[[dict], bool]] = field(default_factory=dict)
def render(self, context: dict[str, Any]) -> str:
"""
渲染模板
Args:
context: 渲染上下文
Returns:
str: 渲染后的字符串
"""
result = self.template
# 变量替换
for var_name, var_value in context.items():
placeholder = f"{{{{{var_name}}}}}"
if placeholder in result:
result = result.replace(placeholder, str(var_value))
# 条件块渲染
result = self._render_conditions(result, context)
# 清理未替换的变量
result = re.sub(r"\{\{[^}]+\}\}", "", result)
return result.strip()
def _render_conditions(self, text: str, context: dict[str, Any]) -> str:
"""渲染条件块"""
# 匹配 {{#if var}}...{{/if}} 模式
pattern = r"\{\{#if\s+(\w+)\}\}(.*?)\{\{/if\}\}"
def replace_condition(match):
var_name = match.group(1)
content = match.group(2)
# 检查条件
if var_name in context and context[var_name]:
return content
return ""
return re.sub(pattern, replace_condition, text, flags=re.DOTALL)
def add_variable(self, name: str, value: Any) -> PromptTemplate:
"""添加变量"""
self.variables[name] = value
return self
def add_condition(
self,
name: str,
condition: Callable[[dict], bool],
) -> PromptTemplate:
"""添加条件"""
self.conditions[name] = condition
return self
class IntentRecognitionTemplate(PromptTemplate):
"""意图识别模板"""
def __init__(self):
super().__init__(
template=self._get_template(),
)
@staticmethod
def _get_template() -> str:
return """你是一个专业的代码助手,负责分析用户的开发请求并提取结构化的意图信息。
你的任务是:
1. 识别用户的主要意图(intent_type)
2. 提取相关的实体(entities),如文件名、函数名、类名
3. 识别约束条件(constraints)
4. 估计你的置信度(confidence)
请严格按照以下 JSON 格式输出,不要添加任何额外内容:
{
"intent_type": "CREATE|MODIFY|DELETE|QUERY|REFACTOR|DEBUG|TEST|EXPLAIN|REVIEW|OPTIMIZE|MIGRATE|UNKNOWN",
"confidence": 0.0-1.0,
"entities": [
{
"entity_type": "file|function|class|variable|module|package",
"name": "实体名称",
"importance_score": 0.0-1.0,
"location_hint": "可选的位置提示"
}
],
"constraints": [
{
"constraint_type": "performance|security|style|compatibility|other",
"description": "约束描述",
"value": "约束值",
"hard_constraint": true|false
}
],
"target_files": ["文件路径列表"],
"reasoning": "你的推理过程"
}"""
class CodeGenerationTemplate:
"""
代码生成模板
=============
支持不同意图类型的代码生成
"""
# CREATE 意图模板
CREATE_TEMPLATE = """你是一个专业的 {language} 开发者。请根据以下要求生成高质量代码。
## 任务要求
{task_description}
{{#if entities}}
## 相关实体
{entities}
{{/if}}
{{#if constraints}}
## 约束条件
{constraints}
{{/if}}
{{#if conventions}}
## 代码规范
{conventions}
{{/if}}
## 代码库上下文{context}
## 输出要求
1. 只输出代码,不要包含解释
2. 代码必须符合 {language} 的最佳实践
3. 必须遵循上述代码规范
4. 确保代码可以直接运行
请生成代码:
```{language}
{code}
```"""
# MODIFY 意图模板
MODIFY_TEMPLATE = """你是一个专业的 {language} 开发者。请根据以下要求修改现有代码。
## 任务要求
{task_description}
## 待修改的代码
```{language}
{old_code}{{#if constraints}}
约束条件
{constraints} {{/if}}
代码库上下文
{context}输出要求
- 只输出修改后的代码,不要包含解释
- 保持代码风格一致性
- 确保修改是正确的和完整的
请生成修改后的代码:
{code}
```"""
def __init__(self):
self.templates = {
"CREATE": self.CREATE_TEMPLATE,
"MODIFY": self.MODIFY_TEMPLATE,
}
def get_template(self, intent_type: str) -> PromptTemplate:
"""获取指定意图类型的模板"""
template_str = self.templates.get(
intent_type,
self.CREATE_TEMPLATE,
)
return PromptTemplate(template=template_str)
def render_for_intent(
self,
intent_type: str,
context: dict[str, Any],
) -> str:
"""为指定意图类型渲染模板"""
template = self.get_template(intent_type)
return template.render(context)4. 混合检索系统实现
本节核心技术价值
本节为你提供的核心价值是掌握多策略混合检索的实现技术,理解如何融合语义向量检索、关键词 BM25 检索、语法结构检索和代码血缘检索,实现 95%+ 的召回率。混合检索是解决"LLM 上下文窗口利用率"和"检索精度"矛盾的核心方案。
4.1 检索架构设计
渲染错误: Mermaid 渲染失败: Parse error on line 2: ... LR Query([用户查询"]) --> QueryProcesso... ----------------------^ Expecting 'SQE', 'DOUBLECIRCLEEND', 'PE', '-)', 'STADIUMEND', 'SUBROUTINEEND', 'PIPE', 'CYLINDEREND', 'DIAMOND_STOP', 'TAGEND', 'TRAPEND', 'INVTRAPEND', 'UNICODE_TEXT', 'TEXT', 'TAGSTART', got 'STR'
图 4-1:混合检索系统架构
4.2 检索器实现
"""
混合检索系统
============
作者:HOS(安全风信子)
日期:2026-05-24
"""
from __future__ import annotations
import asyncio
from abc import ABC, abstractmethod
from dataclasses import dataclass, field
from typing import Any, Optional
import numpy as np
from coding_agent.core.data_models import (
CodeSnippet,
CodeContext,
RetrievalStrategy,
ParsedIntent,
)
@dataclass
class RetrievalResult:
"""
检索结果封装
=============
包含原始片段、相关性分数和来源信息
Attributes:
snippet: 代码片段
score: 相关性分数
strategy: 检索策略来源
rank: 排名
"""
snippet: CodeSnippet
score: float
strategy: RetrievalStrategy
rank: int = 0
def __lt__(self, other: RetrievalResult) -> bool:
return self.score < other.score
class BaseRetriever(ABC):
"""
检索器基类
==========
定义检索器的接口
"""
def __init__(self, name: str, weight: float = 1.0):
self.name = name
self.weight = weight
@abstractmethod
async def retrieve(
self,
query: str,
top_k: int = 10,
filters: Optional[dict[str, Any]] = None,
) -> list[RetrievalResult]:
"""
执行检索
Args:
query: 查询字符串
top_k: 返回结果数量
filters: 过滤条件
Returns:
list[RetrievalResult]: 检索结果列表
"""
pass
@abstractmethod
async def index_documents(
self,
documents: list[CodeSnippet],
) -> None:
"""
索引文档
Args:
documents: 待索引的文档列表
"""
pass
class SemanticRetriever(BaseRetriever):
"""
语义向量检索器
===============
使用嵌入向量进行语义相似度检索
实现要点:
1. 使用 OpenAI embeddings 或本地 embedding 模型
2. 支持向量相似度计算(余弦相似度或点积)
3. 支持 ANN 近似最近邻搜索(可选)
"""
def __init__(
self,
embedding_client: Any,
vector_store: Any,
model_name: str = "text-embedding-3-small",
dimension: int = 1536,
weight: float = 1.0,
):
super().__init__("semantic", weight)
self.embedding_client = embedding_client
self.vector_store = vector_store
self.model_name = model_name
self.dimension = dimension
async def retrieve(
self,
query: str,
top_k: int = 10,
filters: Optional[dict[str, Any]] = None,
) -> list[RetrievalResult]:
# 生成查询向量
query_embedding = await self._embed([query])
# 执行向量检索
results = await self.vector_store.search(
query_vector=query_embedding[0],
top_k=top_k,
filters=filters,
)
# 构建检索结果
retrieval_results = []
for rank, (snippet, score) in enumerate(results, 1):
result = RetrievalResult(
snippet=snippet,
score=score,
strategy=RetrievalStrategy.SEMANTIC,
rank=rank,
)
retrieval_results.append(result)
return retrieval_results
async def index_documents(
self,
documents: list[CodeSnippet],
) -> None:
# 批量生成嵌入向量
texts = [doc.content for doc in documents]
embeddings = await self._embed(texts)
# 批量索引
await self.vector_store.add(
documents=documents,
vectors=embeddings,
)
async def _embed(self, texts: list[str]) -> list[list[float]]:
"""生成文本嵌入向量"""
response = await self.embedding_client.embeddings.create(
model=self.model_name,
input=texts,
)
return [item.embedding for item in response.data]
class KeywordRetriever(BaseRetriever):
"""
关键词 BM25 检索器
===================
使用 BM25 算法进行关键词检索
BM25 公式:
score(D, Q) = Σ IDF(qi) * (tf(qi, D) * (k1 + 1)) / (tf(qi, D) + k1 * (1 - b + b * |D|/avgdl))
其中:
- IDF(qi): 逆文档频率
- tf(qi, D): 词项在文档中的频率
- |D|: 文档长度
- avgdl: 平均文档长度
- k1, b: 调参因子(通常 k1=1.5, b=0.75)
"""
def __init__(
self,
documents: list[CodeSnippet] | None = None,
k1: float = 1.5,
b: float = 0.75,
weight: float = 0.8,
):
super().__init__("keyword", weight)
self.k1 = k1
self.b = b
self.documents: list[CodeSnippet] = documents or []
self._inverted_index: dict[str, list[tuple[int, int]]] = {}
self._doc_lengths: list[int] = []
self._avg_doc_length: float = 0.0
self._n_docs: int = 0
if documents:
self._build_index()
async def retrieve(
self,
query: str,
top_k: int = 10,
filters: Optional[dict[str, Any]] = None,
) -> list[RetrievalResult]:
# 解析查询词
query_terms = self._tokenize(query)
# 计算每个文档的 BM25 分数
doc_scores: list[tuple[int, float]] = []
for doc_id, doc in enumerate(self.documents):
# 应用过滤器
if filters:
if not self._apply_filters(doc, filters):
continue
score = self._compute_bm25_score(doc_id, query_terms)
if score > 0:
doc_scores.append((doc_id, score))
# 排序并取 Top-K
doc_scores.sort(key=lambda x: x[1], reverse=True)
# 构建检索结果
results = []
for rank, (doc_id, score) in enumerate(doc_scores[:top_k], 1):
result = RetrievalResult(
snippet=self.documents[doc_id],
score=score,
strategy=RetrievalStrategy.KEYWORD,
rank=rank,
)
results.append(result)
return results
async def index_documents(
self,
documents: list[CodeSnippet],
) -> None:
self.documents.extend(documents)
self._build_index()
def _build_index(self) -> None:
"""构建倒排索引"""
self._n_docs = len(self.documents)
self._doc_lengths = []
self._inverted_index = {}
for doc_id, doc in enumerate(self.documents):
# 记录文档长度
tokens = self._tokenize(doc.content)
self._doc_lengths.append(len(tokens))
# 更新倒排索引
for term in set(tokens):
if term not in self._inverted_index:
self._inverted_index[term] = []
self._inverted_index[term].append((doc_id, tokens.count(term)))
# 计算平均文档长度
self._avg_doc_length = sum(self._doc_lengths) / max(1, self._n_docs)
def _tokenize(self, text: str) -> list[str]:
"""简单分词(实际应使用更复杂的分词器)"""
# 转为小写,提取词项
text = text.lower()
# 提取单词和数字组合
import re
tokens = re.findall(r"[a-z0-9_]+", text)
return tokens
def _compute_bm25_score(
self,
doc_id: int,
query_terms: list[str],
) -> float:
"""计算 BM25 分数"""
score = 0.0
doc_length = self._doc_lengths[doc_id]
for term in query_terms:
if term not in self._inverted_index:
continue
doc_freqs = self._inverted_index[term]
n_docs_with_term = len(doc_freqs)
# 计算 IDF
idf = max(
0.0,
np.log((self._n_docs - n_docs_with_term + 0.5) / (n_docs_with_term + 0.5) + 1),
)
# 获取该文档中词项的频率
tf = 0
for (d_id, freq) in doc_freqs:
if d_id == doc_id:
tf = freq
break
# 计算 BM25 分数
numerator = tf * (self.k1 + 1)
denominator = tf + self.k1 * (1 - self.b + self.b * doc_length / self._avg_doc_length)
score += idf * numerator / denominator
return score
def _apply_filters(
self,
doc: CodeSnippet,
filters: dict[str, Any],
) -> bool:
"""应用过滤器"""
if "file_path" in filters:
if not any(filters["file_path"] in fp for fp in [doc.file_path]):
return False
if "language" in filters:
if doc.language != filters["language"]:
return False
return True
class HybridRetriever:
"""
混合检索器
===========
融合多个检索策略的结果
融合策略:
1. 加权求和:score = Σ(weight_i * score_i)
2. 折扣融合(Reciprocal Rank Fusion)
3. 学习型融合(使用模型学习权重)
"""
def __init__(
self,
retrievers: list[BaseRetriever],
fusion_strategy: str = "rrf", # "weighted_sum", "rrf", "learned"
rrf_k: int = 60, # RRF 折扣参数
):
"""
初始化混合检索器
Args:
retrievers: 检索器列表
fusion_strategy: 融合策略
rrf_k: RRF 折扣参数
"""
self.retrievers = retrievers
self.fusion_strategy = fusion_strategy
self.rrf_k = rrf_k
async def retrieve(
self,
query: str,
top_k: int = 10,
filters: Optional[dict[str, Any]] = None,
) -> list[RetrievalResult]:
"""
执行混合检索
Args:
query: 查询字符串
top_k: 返回结果数量
filters: 过滤条件
Returns:
list[RetrievalResult]: 融合后的检索结果
"""
# 并行执行所有检索器
tasks = [
retriever.retrieve(query, top_k, filters)
for retriever in self.retrievers
]
results_per_retriever = await asyncio.gather(*tasks)
# 融合结果
if self.fusion_strategy == "rrf":
return self._reciprocal_rank_fusion(results_per_retriever, top_k)
elif self.fusion_strategy == "weighted_sum":
return self._weighted_sum_fusion(results_per_retriever, top_k)
else:
return self._reciprocal_rank_fusion(results_per_retriever, top_k)
def _reciprocal_rank_fusion(
self,
results_per_retriever: list[list[RetrievalResult]],
top_k: int,
) -> list[RetrievalResult]:
"""
折扣融合(Reciprocal Rank Fusion)
RRF 公式:score(d) = Σ 1 / (k + rank(d))
这是一种无参数融合方法,对各检索器的排序结果进行融合
"""
# 收集所有文档
all_snippets: dict[str, list[tuple[float, int]]] = {}
for results in results_per_retriever:
for result in results:
snippet_id = result.snippet.snippet_id
if snippet_id not in all_snippets:
all_snippets[snippet_id] = []
all_snippets[snippet_id].append((result.score, result.rank))
# 计算 RRF 分数
fused_scores: dict[str, float] = {}
for snippet_id, scores_ranks in all_snippets.items():
rrf_score = sum(
1.0 / (self.rrf_k + rank)
for _, rank in scores_ranks
)
fused_scores[snippet_id] = rrf_score
# 获取原始片段
snippet_map: dict[str, CodeSnippet] = {}
for results in results_per_retriever:
for result in results:
snippet_map[result.snippet.snippet_id] = result.snippet
# 排序并返回
sorted_ids = sorted(
fused_scores.items(),
key=lambda x: x[1],
reverse=True,
)
fused_results = []
for rank, (snippet_id, score) in enumerate(sorted_ids[:top_k], 1):
snippet = snippet_map[snippet_id]
result = RetrievalResult(
snippet=snippet,
score=score,
strategy=RetrievalStrategy.HYBRID,
rank=rank,
)
fused_results.append(result)
return fused_results
def _weighted_sum_fusion(
self,
results_per_retriever: list[list[RetrievalResult]],
top_k: int,
) -> list[RetrievalResult]:
"""
加权求和融合
公式:score(d) = Σ weight_i * normalized_score_i(d)
"""
# 收集所有文档并归一化分数
all_snippets: dict[str, tuple[CodeSnippet, list[float]]] = {}
max_scores: dict[int, float] = {}
for retriever_idx, results in enumerate(results_per_retriever):
if not results:
continue
max_score = max(r.score for r in results)
max_scores[retriever_idx] = max_score or 1.0
for result in results:
snippet_id = result.snippet.snippet_id
normalized_score = result.score / max_scores[retriever_idx]
if snippet_id not in all_snippets:
all_snippets[snippet_id] = (result.snippet, [])
all_snippets[snippet_id][1].append(normalized_score)
# 计算加权分数
weights = [retriever.weight for retriever in self.retrievers]
total_weight = sum(weights) or 1.0
fused_scores: dict[str, float] = {}
for snippet_id, (snippet, normalized_scores) in all_snippets.items():
weighted_score = sum(
w * ns for w, ns in zip(weights, normalized_scores)
) / total_weight
fused_scores[snippet_id] = weighted_score
# 排序并返回
sorted_ids = sorted(
fused_scores.items(),
key=lambda x: x[1],
reverse=True,
)
fused_results = []
for rank, (snippet_id, score) in enumerate(sorted_ids[:top_k], 1):
snippet = all_snippets[snippet_id][0]
result = RetrievalResult(
snippet=snippet,
score=score,
strategy=RetrievalStrategy.HYBRID,
rank=rank,
)
fused_results.append(result)
return fused_results
class ContextBuilder:
"""
上下文构建器
=============
将检索结果组织成 LLM 可读的上下文格式
关键设计:
1. 按相关性排序
2. 控制上下文长度
3. 添加位置信息
4. 合并重复内容
"""
def __init__(
self,
max_tokens: int = 60000,
overlap_tokens: int = 500,
):
"""
初始化上下文构建器
Args:
max_tokens: 最大 token 数
overlap_tokens: 重叠 token 数
"""
self.max_tokens = max_tokens
self.overlap_tokens = overlap_tokens
def build(
self,
retrieval_results: list[RetrievalResult],
intent: Optional[ParsedIntent] = None,
) -> CodeContext:
"""
构建代码上下文
Args:
retrieval_results: 检索结果
intent: 解析后的意图
Returns:
CodeContext: 构建的上下文
"""
context = CodeContext()
# 按相关性排序
sorted_results = sorted(
retrieval_results,
key=lambda r: r.score,
reverse=True,
)
# 添加片段
current_tokens = 0
for result in sorted_results:
snippet_tokens = self._estimate_tokens(result.snippet.content)
if current_tokens + snippet_tokens > self.max_tokens:
# 检查是否可以添加部分内容
remaining_tokens = self.max_tokens - current_tokens
if remaining_tokens > self.overlap_tokens:
# 添加部分内容
partial_content = self._truncate_to_tokens(
result.snippet.content,
remaining_tokens,
)
partial_snippet = CodeSnippet(
snippet_id=result.snippet.snippet_id + "_partial",
content=partial_content,
file_path=result.snippet.file_path,
start_line=result.snippet.start_line,
end_line=result.snippet.end_line,
language=result.snippet.language,
snippet_type=result.snippet.snippet_type,
)
context.add_snippet(partial_snippet, result.score)
break
context.add_snippet(result.snippet, result.score)
current_tokens += snippet_tokens
# 估计总 token 数
context.total_tokens = current_tokens
return context
def build_prompt_context(
self,
context: CodeContext,
include_location: bool = True,
) -> str:
"""
构建 Prompt 格式的上下文字符串
Args:
context: 代码上下文
include_location: 是否包含位置信息
Returns:
str: 格式化的上下文字符串
"""
lines = []
for snippet in context.snippets:
if include_location:
location = f"// File: {snippet.file_path} "
if snippet.start_line and snippet.end_line:
location += f"(lines {snippet.start_line}-{snippet.end_line})"
elif snippet.start_line:
location += f"(line {snippet.start_line})"
lines.append(location)
lines.append(snippet.content)
lines.append("") # 空行分隔
return "\n".join(lines)
def _estimate_tokens(self, text: str) -> int:
"""估计 token 数量(中文约 2 字符/token,英文约 4 字符/token)"""
# 简单估计:中文按字符计,英文按单词计
chinese_chars = sum(1 for c in text if "\u4e00" <= c <= "\u9fff")
english_words = len(text.split()) - chinese_chars
return chinese_chars // 2 + english_words // 4 + len(text)
def _truncate_to_tokens(
self,
content: str,
max_tokens: int,
) -> str:
"""截断内容到指定 token 数"""
lines = content.split("\n")
result_lines = []
current_tokens = 0
for line in lines:
line_tokens = self._estimate_tokens(line)
if current_tokens + line_tokens > max_tokens:
# 估算可容纳的字符数
remaining_chars = int((max_tokens - current_tokens) * 4)
if remaining_chars > 10:
result_lines.append(line[:remaining_chars] + "...")
break
result_lines.append(line)
current_tokens += line_tokens
return "\n".join(result_lines)5. 代码生成管道实现
本节核心技术价值
本节为你提供的核心价值是掌握基于 Prompt 模板和 LLM API 的代码生成管道设计,理解如何通过 Prompt 工程、参数调优和多轮生成-验证循环,实现高质量代码输出。代码生成管道是 Coding Agent 的核心输出模块。
5.1 生成管道架构
渲染错误: Mermaid 渲染失败: Parse error on line 2: ...输入:Intent + Context"]) --> TemplateSelec... -----------------------^ Expecting 'SQE', 'DOUBLECIRCLEEND', 'PE', '-)', 'STADIUMEND', 'SUBROUTINEEND', 'PIPE', 'CYLINDEREND', 'DIAMOND_STOP', 'TAGEND', 'TRAPEND', 'INVTRAPEND', 'UNICODE_TEXT', 'TEXT', 'TAGSTART', got 'STR'
图 5-1:代码生成管道流程
5.2 生成器实现
"""
代码生成管道
============
作者:HOS(安全风信子)
日期:2026-05-24
"""
from __future__ import annotations
import asyncio
import json
import re
from dataclasses import dataclass, field
from typing import Any, Optional
from coding_agent.core.data_models import (
CodeContext,
GeneratedCode,
GenerationConfig,
ParsedIntent,
FileChange,
Task,
UserRequest,
)
from coding_agent.core.prompt_templates import CodeGenerationTemplate
@dataclass
class GenerationResult:
"""
生成结果封装
=============
包含生成代码、解释和元数据
Attributes:
success: 是否成功
generated_code: 生成的代码
explanation: 代码解释
error: 错误信息
retry_count: 重试次数
config: 使用的生成配置
"""
success: bool
generated_code: Optional[GeneratedCode] = None
explanation: str = ""
error: Optional[str] = None
retry_count: int = 0
config: Optional[GenerationConfig] = None
class CodeGenerator:
"""
代码生成器
==========
核心代码生成模块
工作流程:
1. 选择合适的 Prompt 模板
2. 构建完整的 Prompt
3. 调用 LLM 生成代码
4. 解析和验证输出
5. 如需要,重试生成
"""
def __init__(
self,
llm_client: Any,
config: Optional[GenerationConfig] = None,
max_retries: int = 3,
template: Optional[CodeGenerationTemplate] = None,
):
"""
初始化代码生成器
Args:
llm_client: LLM 客户端
config: 生成配置
max_retries: 最大重试次数
template: Prompt 模板
"""
self.llm_client = llm_client
self.config = config or GenerationConfig()
self.max_retries = max_retries
self.template = template or CodeGenerationTemplate()
async def generate(
self,
intent: ParsedIntent,
context: CodeContext,
request: UserRequest,
task: Optional[Task] = None,
) -> GenerationResult:
"""
执行代码生成
Args:
intent: 解析后的意图
context: 代码上下文
request: 原始请求
task: 当前任务
Returns:
GenerationResult: 生成结果
"""
retry_count = 0
while retry_count <= self.max_retries:
try:
# 构建 Prompt
prompt = self._build_prompt(intent, context, request, task)
# 调用 LLM
response = await self._call_llm(prompt)
# 解析输出
generated = self._parse_output(response, intent)
# 验证输出
if self._validate_output(generated):
return GenerationResult(
success=True,
generated_code=generated,
retry_count=retry_count,
config=self.config,
)
else:
retry_count += 1
if retry_count <= self.max_retries:
# 调整参数重试
self._adjust_config_for_retry(retry_count)
except Exception as e:
retry_count += 1
if retry_count > self.max_retries:
return GenerationResult(
success=False,
error=str(e),
retry_count=retry_count,
config=self.config,
)
return GenerationResult(
success=False,
error="Max retries exceeded",
retry_count=retry_count,
config=self.config,
)
def _build_prompt(
self,
intent: ParsedIntent,
context: CodeContext,
request: UserRequest,
task: Optional[Task],
) -> str:
"""构建生成 Prompt"""
# 渲染模板
template = self.template.get_template(intent.intent_type.value)
# 构建上下文字符串
context_str = self._build_context_string(context)
# 构建实体列表
entities_str = self._build_entities_string(intent)
# 构建约束列表
constraints_str = self._build_constraints_string(intent)
# 渲染
rendered = template.render({
"language": self._detect_language(intent, context),
"task_description": task.description if task else request.raw_text,
"context": context_str,
"entities": entities_str,
"constraints": constraints_str,
"old_code": self._extract_old_code(intent, context),
"code": "", # 待填充
})
return rendered
def _build_context_string(self, context: CodeContext) -> str:
"""构建上下文字符串"""
if not context.snippets:
return "无可用上下文"
parts = []
for snippet in context.snippets:
location = f"{snippet.file_path}:{snippet.start_line}"
if snippet.end_line:
location += f"-{snippet.end_line}"
parts.append(f"// {location}\n{snippet.content}")
return "\n\n".join(parts)
def _build_entities_string(self, intent: ParsedIntent) -> str:
"""构建实体描述字符串"""
if not intent.entities:
return "无特定实体"
parts = []
for entity in intent.entities:
part = f"- {entity.entity_type}: {entity.name}"
if entity.location:
part += f" (at {entity.location.to_range_string()})"
parts.append(part)
return "\n".join(parts)
def _build_constraints_string(self, intent: ParsedIntent) -> str:
"""构建约束描述字符串"""
if not intent.constraints:
return "无特定约束"
parts = []
for constraint in intent.constraints:
hard = "[必选]" if constraint.hard_constraint else "[可选]"
parts.append(f"- {hard} {constraint.description}: {constraint.value}")
return "\n".join(parts)
def _detect_language(
self,
intent: ParsedIntent,
context: CodeContext,
) -> str:
"""检测目标编程语言"""
# 从上下文中的语言
if context.snippets and context.snippets[0].language:
return context.snippets[0].language
# 从文件扩展名推断
for entity in intent.entities:
if entity.location and entity.location.file_path:
ext = entity.location.file_path.split(".")[-1]
lang_map = {
"py": "python",
"js": "javascript",
"ts": "typescript",
"java": "java",
"go": "go",
"rs": "rust",
"cpp": "cpp",
"c": "c",
"cs": "csharp",
"rb": "ruby",
"php": "php",
}
if ext in lang_map:
return lang_map[ext]
return "python" # 默认
def _extract_old_code(
self,
intent: ParsedIntent,
context: CodeContext,
) -> str:
"""提取待修改的旧代码"""
if intent.intent_type.value not in ["MODIFY", "REFACTOR"]:
return ""
if not context.snippets:
return ""
# 返回第一个(最相关的)片段
return context.snippets[0].content
async def _call_llm(self, prompt: str) -> str:
"""调用 LLM 生成代码"""
response = await self.llm_client.chat.completions.create(
model=self.config.model_name,
messages=[
{"role": "system", "content": "你是一个专业的代码生成助手。"},
{"role": "user", "content": prompt},
],
temperature=self.config.temperature,
max_tokens=self.config.max_tokens,
top_p=self.config.top_p,
stop=self.config.stop_sequences or None,
)
return response.choices[0].message.content
def _parse_output(
self,
output: str,
intent: ParsedIntent,
) -> GeneratedCode:
"""解析 LLM 输出"""
generated = GeneratedCode(
language=self._detect_language(intent, CodeContext()),
)
# 尝试提取代码块
code_blocks = re.findall(
r"```(?:\w+)?\n(.*?)```",
output,
re.DOTALL,
)
if code_blocks:
generated.code = code_blocks[0].strip()
else:
# 没有代码块,整段作为代码
generated.code = output.strip()
# 提取差异信息(如果有)
changes = self._parse_changes(output)
generated.changes = changes
# 估计置信度
generated.confidence = self._estimate_confidence(output, intent)
generated.raw_response = output
return generated
def _parse_changes(self, output: str) -> list[FileChange]:
"""解析文件变更信息"""
changes = []
# 尝试从输出中提取变更信息
# 格式示例: [FILE: path/to/file.py]
file_pattern = r"\[FILE:\s*([^\]]+)\]"
file_matches = re.findall(file_pattern, output)
for file_path in file_matches:
change = FileChange(
change_type="modify",
file_path=file_path.strip(),
)
changes.append(change)
return changes
def _estimate_confidence(
self,
output: str,
intent: ParsedIntent,
) -> float:
"""估计生成置信度"""
confidence = 0.5
# 代码长度因素
code_blocks = re.findall(r"```(?:\w+)?\n(.*?)```", output, re.DOTALL)
if code_blocks:
code_length = len(code_blocks[0])
# 合理的代码长度(50-5000字符)
if 50 <= code_length <= 5000:
confidence += 0.2
# 意图匹配因素
if intent.confidence >= 0.8:
confidence += 0.15
# 约束满足因素
if intent.constraints:
constraint_keywords = [
c.description.lower() for c in intent.constraints
]
satisfied = sum(
1 for kw in constraint_keywords
if kw in output.lower()
)
confidence += 0.15 * (satisfied / len(intent.constraints))
return min(1.0, confidence)
def _validate_output(self, generated: GeneratedCode) -> bool:
"""验证生成输出"""
# 基本验证
if not generated.code or len(generated.code) < 10:
return False
# 检查是否包含明显的错误标记
error_markers = [
"undefined",
"not implemented",
"todo",
"fixme",
"placeholder",
]
code_lower = generated.code.lower()
if any(marker in code_lower for marker in error_markers):
# 如果是修改/重构意图,这些标记可能是合理的
if generated.confidence < 0.5:
return False
# 括号匹配验证
if not self._check_bracket_balance(generated.code):
return False
return True
def _check_bracket_balance(self, code: str) -> bool:
"""检查括号平衡"""
stack = []
brackets = {"(": ")", "[": "]", "{": "}"}
for char in code:
if char in brackets:
stack.append(brackets[char])
elif char in brackets.values():
if not stack or stack.pop() != char:
return False
return len(stack) == 0
def _adjust_config_for_retry(self, retry_count: int) -> None:
"""调整配置以进行重试"""
# 增加 temperature 以获得更多样化的输出
self.config.temperature = min(1.0, self.config.temperature + 0.1)
# 如果重试次数多了,尝试更长的 max_tokens
if retry_count > 1:
self.config.max_tokens = int(self.config.max_tokens * 1.2)6. 执行与反馈循环实现
本节核心技术价值
本节为你提供的核心价值是掌握执行引擎和反馈循环的实现技术,理解如何通过循环执行、结果验证和人工确认机制,实现可靠的代码生成-验证-修正流程。执行反馈是 Coding Agent 从"生成代码"到"完成任务"的关键环节。
6.1 执行引擎设计
"""
执行引擎与反馈循环
==================
作者:HOS(安全风信子)
日期:2026-05-24
"""
from __future__ import annotations
import asyncio
import json
import subprocess
import tempfile
from dataclasses import dataclass
from datetime import datetime
from pathlib import Path
from typing import Any, Optional
from coding_agent.core.data_models import (
ExecutionResult,
FileChange,
Feedback,
Correction,
GeneratedCode,
Task,
TaskStatus,
)
class ExecutionEngine:
"""
执行引擎
=========
负责执行代码变更并验证结果
支持的执行模式:
1. 语法验证:检查代码语法是否正确
2. 单元测试:运行相关测试用例
3. 集成测试:运行更广泛的测试
4. 实际执行:在沙箱中执行代码
"""
def __init__(
self,
workspace_root: str,
sandbox_enabled: bool = True,
test_timeout: int = 60,
):
"""
初始化执行引擎
Args:
workspace_root: 工作区根目录
sandbox_enabled: 是否启用沙箱
test_timeout: 测试超时时间(秒)
"""
self.workspace_root = Path(workspace_root)
self.sandbox_enabled = sandbox_enabled
self.test_timeout = test_timeout
async def execute_change(
self,
change: FileChange,
verification_mode: str = "syntax",
) -> ExecutionResult:
"""
执行文件变更
Args:
change: 文件变更
verification_mode: 验证模式
Returns:
ExecutionResult: 执行结果
"""
start_time = datetime.now()
try:
# 应用变更
if change.change_type == "create":
await self._create_file(change)
elif change.change_type == "modify":
await self._modify_file(change)
elif change.change_type == "delete":
await self._delete_file(change)
# 验证
if verification_mode == "syntax":
result = await self._verify_syntax(change)
elif verification_mode == "test":
result = await self._run_tests(change)
else:
result = ExecutionResult(success=True)
result.execution_time = (datetime.now() - start_time).total_seconds()
return result
except Exception as e:
return ExecutionResult(
success=False,
error=str(e),
exit_code=1,
execution_time=(datetime.now() - start_time).total_seconds(),
)
async def _create_file(self, change: FileChange) -> None:
"""创建文件"""
file_path = self.workspace_root / change.file_path
file_path.parent.mkdir(parents=True, exist_ok=True)
# 备份(如果存在)
if file_path.exists():
backup_path = file_path.with_suffix(file_path.suffix + ".bak")
file_path.rename(backup_path)
change.backup_path = str(backup_path)
file_path.write_text(change.new_content or "", encoding="utf-8")
async def _modify_file(self, change: FileChange) -> None:
"""修改文件"""
file_path = self.workspace_root / change.file_path
if not file_path.exists():
raise FileNotFoundError(f"File not found: {change.file_path}")
# 备份原文件
backup_path = file_path.with_suffix(file_path.suffix + ".bak")
file_path.rename(backup_path)
change.backup_path = str(backup_path)
# 写入新内容
file_path.write_text(change.new_content or "", encoding="utf-8")
async def _delete_file(self, change: FileChange) -> None:
"""删除文件"""
file_path = self.workspace_root / change.file_path
if file_path.exists():
# 备份
backup_path = file_path.with_suffix(file_path.suffix + ".bak")
file_path.rename(backup_path)
change.backup_path = str(backup_path)
async def _verify_syntax(self, change: FileChange) -> ExecutionResult:
"""验证语法"""
file_path = self.workspace_root / change.file_path
if not file_path.exists():
return ExecutionResult(
success=False,
error=f"File not found: {change.file_path}",
exit_code=1,
)
# 根据语言选择验证方式
suffix = file_path.suffix.lower()
if suffix == ".py":
return await self._verify_python_syntax(file_path)
elif suffix in [".js", ".ts"]:
return await self._verify_js_syntax(file_path)
elif suffix == ".go":
return await self._verify_go_syntax(file_path)
elif suffix == ".rs":
return await self._verify_rust_syntax(file_path)
else:
# 默认成功
return ExecutionResult(success=True)
async def _verify_python_syntax(self, file_path: Path) -> ExecutionResult:
"""验证 Python 语法"""
try:
result = subprocess.run(
["python", "-m", "py_compile", str(file_path)],
capture_output=True,
text=True,
timeout=30,
)
return ExecutionResult(
success=result.returncode == 0,
output=result.stdout,
error=result.stderr,
exit_code=result.returncode,
)
except Exception as e:
return ExecutionResult(
success=False,
error=str(e),
exit_code=1,
)
async def _verify_js_syntax(self, file_path: Path) -> ExecutionResult:
"""验证 JavaScript/TypeScript 语法"""
try:
result = subprocess.run(
["node", "--check", str(file_path)],
capture_output=True,
text=True,
timeout=30,
)
return ExecutionResult(
success=result.returncode == 0,
output=result.stdout,
error=result.stderr,
exit_code=result.returncode,
)
except Exception as e:
return ExecutionResult(
success=False,
error=str(e),
exit_code=1,
)
async def _verify_go_syntax(self, file_path: Path) -> ExecutionResult:
"""验证 Go 语法"""
try:
result = subprocess.run(
["go", "vet", str(file_path)],
capture_output=True,
text=True,
timeout=30,
)
return ExecutionResult(
success=result.returncode == 0,
output=result.stdout,
error=result.stderr,
exit_code=result.returncode,
)
except Exception as e:
return ExecutionResult(
success=False,
error=str(e),
exit_code=1,
)
async def _verify_rust_syntax(self, file_path: Path) -> ExecutionResult:
"""验证 Rust 语法"""
try:
result = subprocess.run(
["rustc", "--emit=metadata", "-o", "/dev/null", str(file_path)],
capture_output=True,
text=True,
timeout=60,
)
return ExecutionResult(
success=result.returncode == 0,
output=result.stdout,
error=result.stderr,
exit_code=result.returncode,
)
except Exception as e:
return ExecutionResult(
success=False,
error=str(e),
exit_code=1,
)
async def _run_tests(self, change: FileChange) -> ExecutionResult:
"""运行测试"""
file_path = self.workspace_root / change.file_path
# 查找相关测试文件
test_file = self._find_test_file(file_path)
if not test_file:
return ExecutionResult(
success=True,
output="No test file found",
)
try:
suffix = file_path.suffix.lower()
if suffix == ".py":
result = subprocess.run(
["pytest", str(test_file), "-v"],
capture_output=True,
text=True,
timeout=self.test_timeout,
)
elif suffix in [".js", ".ts"]:
result = subprocess.run(
["jest", str(test_file)],
capture_output=True,
text=True,
timeout=self.test_timeout,
)
else:
result = subprocess.run(
["go", "test", "-v", str(file_path.parent)],
capture_output=True,
text=True,
timeout=self.test_timeout,
)
return ExecutionResult(
success=result.returncode == 0,
output=result.stdout,
error=result.stderr,
exit_code=result.returncode,
stdout_lines=result.stdout.split("\n"),
stderr_lines=result.stderr.split("\n"),
)
except Exception as e:
return ExecutionResult(
success=False,
error=str(e),
exit_code=1,
)
def _find_test_file(self, source_file: Path) -> Optional[Path]:
"""查找测试文件"""
# 常见的测试文件命名模式
patterns = [
source_file.stem + "_test" + source_file.suffix,
source_file.stem + ".test" + source_file.suffix,
source_file.stem + ".spec" + source_file.suffix,
"test_" + source_file.name,
source_file.name.replace(source_file.suffix, "_test.py"),
]
for pattern in patterns:
test_path = source_file.parent / pattern
if test_path.exists():
return test_path
# 查找 test 目录
test_dir = source_file.parent / "tests"
if test_dir.exists():
test_path = test_dir / pattern
if test_path.exists():
return test_path
return None
async def rollback_change(self, change: FileChange) -> bool:
"""
回滚变更
Args:
change: 文件变更
Returns:
bool: 是否成功回滚
"""
if not change.backup_path:
return False
try:
file_path = self.workspace_root / change.file_path
backup_path = Path(change.backup_path)
if backup_path.exists():
backup_path.rename(file_path)
return True
return False
except Exception:
return False
class FeedbackLoop:
"""
反馈循环
=========
处理用户反馈和自动修正的循环机制
支持的反馈类型:
1. 人工确认:用户确认或拒绝生成结果
2. 评分反馈:用户对结果进行评分
3. 修正建议:用户提供具体的修正意见
4. 自动验证:系统自动验证结果正确性
"""
def __init__(
self,
max_iterations: int = 5,
confidence_threshold: float = 0.85,
):
"""
初始化反馈循环
Args:
max_iterations: 最大迭代次数
confidence_threshold: 置信度阈值
"""
self.max_iterations = max_iterations
self.confidence_threshold = confidence_threshold
async def process(
self,
generated: GeneratedCode,
execution_result: ExecutionResult,
user_feedback: Optional[Feedback] = None,
) -> tuple[bool, Optional[list[Correction]]]:
"""
处理反馈
Args:
generated: 生成的代码
execution_result: 执行结果
user_feedback: 用户反馈
Returns:
tuple[bool, list[Correction]]: (是否完成, 修正列表)
"""
# 检查执行结果
if not execution_result.success:
corrections = await self._generate_corrections(
generated,
execution_result,
)
return False, corrections
# 检查置信度
if generated.confidence >= self.confidence_threshold:
if user_feedback and not user_feedback.accepted:
corrections = self._process_user_corrections(user_feedback)
return False, corrections
return True, None
# 低置信度情况
if user_feedback:
if user_feedback.accepted:
return True, None
else:
return False, user_feedback.corrections
# 自动验证失败
corrections = await self._generate_corrections(
generated,
execution_result,
)
return False, corrections if corrections else None
async def _generate_corrections(
self,
generated: GeneratedCode,
execution_result: ExecutionResult,
) -> list[Correction]:
"""根据执行结果生成修正建议"""
corrections = []
if execution_result.error:
# 解析错误信息
error_lines = execution_result.stderr_lines or []
for line in error_lines[:5]: # 只取前5行
correction = Correction(
original="",
suggested=f"# Fix error: {line}",
reason=f"Execution error: {line}",
)
corrections.append(correction)
return corrections
def _process_user_corrections(
self,
feedback: Feedback,
) -> list[Correction]:
"""处理用户提供的修正建议"""
return feedback.corrections
def should_continue(
self,
iteration: int,
completed: bool,
) -> bool:
"""判断是否继续循环"""
if completed:
return False
if iteration >= self.max_iterations:
return False
return True7. 三层记忆体系实现
本节核心技术价值
本节为你提供的核心价值是掌握三层记忆体系的设计与实现,理解如何通过工作记忆(Working Memory)、情景记忆(Episodic Memory)和语义记忆(Semantic Memory)的协同,实现跨会话的持久化知识管理。三层记忆是 Coding Agent"记住项目上下文"能力的核心支撑。
7.1 记忆架构设计
渲染错误: Mermaid 渲染失败: Parse error on line 3: ... WM1[当前会话状态"] WM2[消息历史"] ----------------------^ Expecting 'SQE', 'DOUBLECIRCLEEND', 'PE', '-)', 'STADIUMEND', 'SUBROUTINEEND', 'PIPE', 'CYLINDEREND', 'DIAMOND_STOP', 'TAGEND', 'TRAPEND', 'INVTRAPEND', 'UNICODE_TEXT', 'TEXT', 'TAGSTART', got 'STR'
图 7-1:三层记忆体系架构
7.2 记忆管理器实现
"""
三层记忆体系
============
作者:HOS(安全风信子)
日期:2026-05-24
"""
from __future__ import annotations
import asyncio
import json
import os
from abc import ABC, abstractmethod
from datetime import datetime
from pathlib import Path
from typing import Any, Optional
from coding_agent.core.data_models import (
WorkingMemory,
EpisodicMemory,
SemanticMemory,
Message,
Episode,
Decision,
Pattern,
Convention,
APISpec,
)
class BaseMemoryStore(ABC):
"""
记忆存储基类
=============
定义记忆存储的接口
"""
@abstractmethod
async def save(self, key: str, data: Any) -> None:
"""保存数据"""
pass
@abstractmethod
async def load(self, key: str) -> Optional[Any]:
"""加载数据"""
pass
@abstractmethod
async def delete(self, key: str) -> None:
"""删除数据"""
pass
@abstractmethod
async def exists(self, key: str) -> bool:
"""检查是否存在"""
pass
class FileMemoryStore(BaseMemoryStore):
"""
文件记忆存储
=============
使用文件系统存储记忆数据
目录结构:
memory/
├── working/
│ └── {session_id}.json
├── episodic/
│ └── {project_id}/
│ └── {episode_id}.json
└── semantic/
└── {project_id}/
└── memory.json
"""
def __init__(self, base_path: str = ".coding_agent/memory"):
self.base_path = Path(base_path)
self.base_path.mkdir(parents=True, exist_ok=True)
# 创建子目录
(self.base_path / "working").mkdir(exist_ok=True)
(self.base_path / "episodic").mkdir(exist_ok=True)
(self.base_path / "semantic").mkdir(exist_ok=True)
async def save(self, key: str, data: Any) -> None:
"""保存数据到文件"""
file_path = self._get_file_path(key)
file_path.parent.mkdir(parents=True, exist_ok=True)
# 序列化数据
if hasattr(data, "model_dump"):
content = data.model_dump_json(indent=2)
else:
content = json.dumps(data, indent=2, ensure_ascii=False)
await asyncio.to_thread(file_path.write_text, content, encoding="utf-8")
async def load(self, key: str) -> Optional[Any]:
"""从文件加载数据"""
file_path = self._get_file_path(key)
if not file_path.exists():
return None
try:
content = await asyncio.to_thread(file_path.read_text, encoding="utf-8")
return json.loads(content)
except Exception:
return None
async def delete(self, key: str) -> None:
"""删除文件"""
file_path = self._get_file_path(key)
if file_path.exists():
file_path.unlink()
async def exists(self, key: str) -> bool:
"""检查文件是否存在"""
return self._get_file_path(key).exists()
def _get_file_path(self, key: str) -> Path:
"""获取文件路径"""
return self.base_path / f"{key}.json"
class WorkingMemoryManager:
"""
工作记忆管理器
===============
管理当前会话的短时记忆
职责:
1. 维护当前会话状态
2. 管理消息历史
3. 跟踪当前任务
4. 实现注意力机制
"""
def __init__(self, store: Optional[BaseMemoryStore] = None):
self.store = store or FileMemoryStore()
self.current_memory: Optional[WorkingMemory] = None
async def create_session(
self,
session_id: Optional[str] = None,
user_id: Optional[str] = None,
) -> WorkingMemory:
"""
创建新会话
Args:
session_id: 会话 ID
user_id: 用户 ID
Returns:
WorkingMemory: 创建的记忆对象
"""
memory = WorkingMemory(
session_id=session_id or "",
messages=[],
)
self.current_memory = memory
return memory
async def load_session(self, session_id: str) -> Optional[WorkingMemory]:
"""
加载会话
Args:
session_id: 会话 ID
Returns:
Optional[WorkingMemory]: 加载的记忆对象
"""
data = await self.store.load(f"working/{session_id}")
if data:
self.current_memory = WorkingMemory.model_validate(data)
return self.current_memory
return None
async def save_session(self) -> None:
"""保存当前会话"""
if self.current_memory:
await self.store.save(
f"working/{self.current_memory.session_id}",
self.current_memory,
)
def add_message(self, role: str, content: str) -> Message:
"""添加消息"""
if not self.current_memory:
raise RuntimeError("No active session")
msg = self.current_memory.add_message(role, content)
return msg
def get_recent_messages(self, n: int = 10) -> list[Message]:
"""获取最近 N 条消息"""
if not self.current_memory:
return []
return self.current_memory.get_recent_messages(n)
def set_current_task(self, task: Any) -> None:
"""设置当前任务"""
if self.current_memory:
self.current_memory.current_task = task
self.current_memory.attention_focus = task.task_id if task else None
def set_attention_focus(self, focus: str) -> None:
"""设置注意力焦点"""
if self.current_memory:
self.current_memory.attention_focus = focus
class UnifiedMemoryManager:
"""
统一记忆管理器
===============
整合三层记忆的管理
提供统一的接口访问三层记忆,并负责记忆间的同步
"""
def __init__(self, base_path: Optional[str] = None):
store = FileMemoryStore(base_path or ".coding_agent/memory")
self.working = WorkingMemoryManager(store)
self.episodic = EpisodicMemoryManager(store)
self.semantic = SemanticMemoryManager(store)
async def initialize(
self,
project_id: str,
session_id: Optional[str] = None,
) -> None:
"""
初始化记忆系统
Args:
project_id: 项目 ID
session_id: 会话 ID
"""
# 加载或创建语义记忆(项目级别)
await self.semantic.load_or_create(project_id)
# 加载或创建情景记忆
await self.episodic.load_or_create(project_id)
# 创建新会话
await self.working.create_session(session_id, project_id)
async def persist_all(self) -> None:
"""持久化所有记忆"""
await self.working.save_session()
await self.episodic.save()
await self.semantic.save()
def get_context_for_generation(
self,
max_tokens: Optional[int] = None,
) -> dict[str, Any]:
"""
获取用于代码生成的上下文
Args:
max_tokens: 最大 token 数限制
Returns:
dict[str, Any]: 合并的上下文
"""
context: dict[str, Any] = {}
# 添加工作记忆
if self.working.current_memory:
context["recent_messages"] = [
{"role": m.role, "content": m.content}
for m in self.working.get_recent_messages(10)
]
context["current_task"] = self.working.current_memory.current_task
# 添加情景记忆中的相关模式
if self.episodic.current_memory:
patterns = self.episodic.current_memory.patterns[-5:]
context["patterns"] = [
{"type": p.pattern_type, "description": p.description}
for p in patterns
]
# 添加语义记忆中的规范
if self.semantic.current_memory:
conventions = self.semantic.current_memory.conventions
context["conventions"] = [
{"name": c.name, "description": c.description}
for c in conventions
]
return context8. 调度编排层实现
本节核心技术价值
本节为你提供的核心价值是掌握调度编排层的设计与实现,理解如何通过状态机模式和事件驱动机制,协调各组件的有序运行。调度编排层是 Coding Agent 的"大脑",负责全局状态管理和任务协调。
8.1 调度器实现
"""
调度编排层
==========
作者:HOS(安全风信子)
日期:2026-05-24
"""
from __future__ import annotations
import asyncio
import json
from dataclasses import dataclass, field
from datetime import datetime
from enum import Enum
from typing import Any, Callable, Optional
from coding_agent.core.data_models import (
UserRequest,
ParsedIntent,
Task,
TaskStatus,
CodeContext,
GeneratedCode,
ExecutionResult,
Feedback,
)
class AgentState(str, Enum):
"""Agent 状态枚举"""
IDLE = "idle"
UNDERSTANDING = "understanding"
RETRIEVING = "retrieving"
GENERATING = "generating"
EXECUTING = "executing"
WAITING_CONFIRMATION = "waiting_confirmation"
COMPLETED = "completed"
FAILED = "failed"
@dataclass
class AgentContext:
"""
Agent 运行时上下文
===================
在整个请求生命周期内维护的状态
Attributes:
request: 用户请求
intent: 解析后的意图
tasks: 任务列表
current_task_index: 当前任务索引
code_context: 代码上下文
generated_code: 生成的代码
execution_result: 执行结果
state: 当前状态
error: 错误信息
"""
request: Optional[UserRequest] = None
intent: Optional[ParsedIntent] = None
tasks: list[Task] = field(default_factory=list)
current_task_index: int = 0
code_context: Optional[CodeContext] = None
generated_code: Optional[GeneratedCode] = None
execution_result: Optional[ExecutionResult] = None
state: AgentState = AgentState.IDLE
error: Optional[str] = None
created_at: datetime = field(default_factory=datetime.now)
updated_at: datetime = field(default_factory=datetime.now)
def update_state(self, new_state: AgentState) -> None:
"""更新状态"""
self.state = new_state
self.updated_at = datetime.now()
class AgentOrchestrator:
"""
Agent 编排器
=============
负责协调各组件的有序运行
核心职责:
1. 管理 Agent 状态机
2. 调度各组件执行
3. 处理错误和异常
4. 支持中断和恢复
5. 协调组件间数据流
"""
def __init__(
self,
intent_recognizer: Any,
task_decomposer: Any,
retriever: Any,
context_builder: Any,
code_generator: Any,
execution_engine: Any,
feedback_loop: Any,
memory_manager: Any,
):
"""
初始化编排器
Args:
intent_recognizer: 意图识别器
task_decomposer: 任务分解器
retriever: 检索器
context_builder: 上下文构建器
code_generator: 代码生成器
execution_engine: 执行引擎
feedback_loop: 反馈循环
memory_manager: 记忆管理器
"""
self.intent_recognizer = intent_recognizer
self.task_decomposer = task_decomposer
self.retriever = retriever
self.context_builder = context_builder
self.code_generator = code_generator
self.execution_engine = execution_engine
self.feedback_loop = feedback_loop
self.memory_manager = memory_manager
# 当前上下文
self.current_context: Optional[AgentContext] = None
# 状态转换钩子
self.state_transition_hooks: list[Callable] = []
async def process_request(
self,
request: UserRequest,
) -> dict[str, Any]:
"""
处理用户请求
主流程:
1. 意图识别
2. 任务分解
3. 上下文检索
4. 代码生成
5. 执行验证
6. 反馈循环
Args:
request: 用户请求
Returns:
dict[str, Any]: 处理结果
"""
# 创建上下文
self.current_context = AgentContext(request=request)
try:
# 阶段1: 意图理解
await self._phase_understand()
# 阶段2: 任务分解
tasks = await self._phase_decompose()
# 阶段3-6: 逐个执行任务
for task in tasks:
self.current_context.current_task_index += 1
# 上下文检索
await self._phase_retrieve()
# 代码生成
generated = await self._phase_generate()
# 执行验证
success = await self._phase_execute(generated)
if not success:
# 处理反馈循环
await self._handle_feedback_loop()
# 完成
self.current_context.update_state(AgentState.COMPLETED)
return self._build_response()
except Exception as e:
self.current_context.error = str(e)
self.current_context.update_state(AgentState.FAILED)
return self._build_error_response(str(e))
finally:
# 保存记忆
await self._persist_memory()
async def _phase_understand(self) -> None:
"""阶段1: 意图理解"""
self.current_context.update_state(AgentState.UNDERSTANDING)
# 添加用户消息到工作记忆
self.memory_manager.working.add_message(
role="user",
content=self.current_context.request.raw_text,
)
# 意图识别
intent = await self.intent_recognizer.recognize(
self.current_context.request,
)
self.current_context.intent = intent
# 更新工作记忆
self.memory_manager.working.set_current_task(intent)
async def _phase_decompose(self) -> list[Task]:
"""阶段2: 任务分解"""
tasks = await self.task_decomposer.decompose(
self.current_context.intent,
self.current_context.request,
)
self.current_context.tasks = tasks
return tasks
async def _phase_retrieve(self) -> None:
"""阶段3: 上下文检索"""
self.current_context.update_state(AgentState.RETRIEVING)
# 构建检索查询
query = self._build_retrieval_query()
# 执行检索
retrieval_results = await self.retriever.retrieve(
query=query,
top_k=20,
)
# 构建上下文
context = self.context_builder.build(
retrieval_results,
self.current_context.intent,
)
self.current_context.code_context = context
async def _phase_generate(self) -> GeneratedCode:
"""阶段4: 代码生成"""
self.current_context.update_state(AgentState.GENERATING)
# 获取当前任务
current_task = None
if self.current_context.current_task_index <= len(self.current_context.tasks):
current_task = self.current_context.tasks[
self.current_context.current_task_index - 1
]
# 生成代码
result = await self.code_generator.generate(
intent=self.current_context.intent,
context=self.current_context.code_context,
request=self.current_context.request,
task=current_task,
)
if result.success:
self.current_context.generated_code = result.generated_code
else:
raise RuntimeError(f"Code generation failed: {result.error}")
return result.generated_code
async def _phase_execute(self, generated: GeneratedCode) -> bool:
"""阶段5: 执行验证"""
self.current_context.update_state(AgentState.EXECUTING)
# 获取文件变更
changes = generated.changes
if not changes:
# 没有文件变更,生成成功
return True
# 执行变更
for change in changes:
result = await self.execution_engine.execute_change(
change=change,
verification_mode="syntax",
)
if not result.success:
self.current_context.execution_result = result
return False
self.current_context.execution_result = ExecutionResult(success=True)
return True
async def _handle_feedback_loop(self) -> None:
"""处理反馈循环"""
self.current_context.update_state(AgentState.WAITING_CONFIRMATION)
# 等待用户确认
# 实际实现中,这里会挂起等待用户输入
# 为了简化,这里直接标记失败
raise RuntimeError("Execution failed, feedback required")
def _build_retrieval_query(self) -> str:
"""构建检索查询"""
parts = [
self.current_context.request.raw_text,
]
if self.current_context.intent:
# 添加实体信息
for entity in self.current_context.intent.entities:
parts.append(entity.name)
# 添加目标文件
for file_path in self.current_context.intent.target_files:
parts.append(file_path)
return " ".join(parts)
def _build_response(self) -> dict[str, Any]:
"""构建成功响应"""
return {
"success": True,
"state": self.current_context.state.value,
"generated_code": (
self.current_context.generated_code.code
if self.current_context.generated_code
else None
),
"explanation": (
self.current_context.generated_code.explanation
if self.current_context.generated_code
else None
),
"changes": [
change.model_dump()
for change in (
self.current_context.generated_code.changes
if self.current_context.generated_code
else []
)
],
"tasks_completed": self.current_context.current_task_index,
"total_tasks": len(self.current_context.tasks),
}
def _build_error_response(self, error: str) -> dict[str, Any]:
"""构建错误响应"""
return {
"success": False,
"state": self.current_context.state.value,
"error": error,
"tasks_completed": self.current_context.current_task_index,
"total_tasks": len(self.current_context.tasks),
}
async def _persist_memory(self) -> None:
"""持久化记忆"""
await self.memory_manager.persist_all()
class TaskScheduler:
"""
任务调度器
==========
管理任务的执行顺序和依赖关系
支持:
1. 依赖解析
2. 并行执行
3. 优先级调度
4. 资源管理
"""
def __init__(self, max_concurrent: int = 3):
"""
初始化任务调度器
Args:
max_concurrent: 最大并发任务数
"""
self.max_concurrent = max_concurrent
self.running_tasks: set[str] = set()
self.completed_tasks: set[str] = set()
def get_next_tasks(
self,
tasks: list[Task],
) -> list[Task]:
"""
获取下一个可执行的任务列表
Args:
tasks: 所有任务
Returns:
list[Task]: 可执行的任务
"""
if len(self.running_tasks) >= self.max_concurrent:
return []
available_slots = self.max_concurrent - len(self.running_tasks)
next_tasks = []
for task in tasks:
if task.task_id in self.running_tasks or task.task_id in self.completed_tasks:
continue
# 检查依赖是否满足
if not task.is_ready_to_execute(self.completed_tasks):
continue
next_tasks.append(task)
if len(next_tasks) >= available_slots:
break
return next_tasks
def mark_running(self, task_id: str) -> None:
"""标记任务开始运行"""
self.running_tasks.add(task_id)
def mark_completed(self, task_id: str) -> None:
"""标记任务完成"""
self.running_tasks.discard(task_id)
self.completed_tasks.add(task_id)
def reset(self) -> None:
"""重置调度器状态"""
self.running_tasks.clear()
self.completed_tasks.clear()9. 完整集成与使用示例
本节核心技术价值
本节为你提供的核心价值是掌握如何将所有组件集成在一起,通过完整的代码示例展示 Coding Agent 从初始化到使用的完整流程,并提供实际运行测试。
9.1 集成示例
"""
Coding Agent 完整集成示例
==========================
作者:HOS(安全风信子)
日期:2026-05-24
"""
import asyncio
from typing import Any, Optional
# 以下是模拟的客户端和存储类
# 实际使用时替换为真实的 OpenAI 客户端等
class MockLLMClient:
"""模拟 LLM 客户端"""
async def chat.completions.create(self, **kwargs) -> dict[str, Any]:
# 返回模拟响应
return {
"choices": [{
"message": {
"content": '{"intent_type": "CREATE", "confidence": 0.95, "entities": [{"entity_type": "function", "name": "test_function", "importance_score": 1.0}], "constraints": [], "target_files": [], "reasoning": "test"}'
}
}]
}
class MockEmbeddingClient:
"""模拟 Embedding 客户端"""
async def embeddings.create(self, **kwargs) -> dict[str, Any]:
return {
"data": [{
"embedding": [0.1] * 1536
}]
}
class MockVectorStore:
"""模拟向量存储"""
def __init__(self):
self.documents = []
self.vectors = []
async def add(self, documents: list, vectors: list) -> None:
self.documents.extend(documents)
self.vectors.extend(vectors)
async def search(self, query_vector: list, top_k: int = 10, filters: Optional[dict] = None) -> list:
# 返回所有文档作为模拟结果
return [(doc, 0.9) for doc in self.documents[:top_k]]
async def create_coding_agent(
workspace_root: str = "./workspace",
model_name: str = "gpt-4o",
) -> AgentOrchestrator:
"""
创建并初始化 Coding Agent
Args:
workspace_root: 工作区根目录
model_name: LLM 模型名称
Returns:
AgentOrchestrator: 配置好的编排器
"""
# 创建模拟客户端
llm_client = MockLLMClient()
embedding_client = MockEmbeddingClient()
vector_store = MockVectorStore()
# 创建各组件
from coding_agent.core.intent_recognizer import IntentRecognizer
from coding_agent.core.task_decomposer import TaskDecomposer
from coding_agent.retrieval.semantic_retriever import SemanticRetriever
from coding_agent.retrieval.keyword_retriever import KeywordRetriever
from coding_agent.retrieval.hybrid_retriever import HybridRetriever
from coding_agent.retrieval.context_builder import ContextBuilder
from coding_agent.generation.code_generator import CodeGenerator
from coding_agent.execution.execution_engine import ExecutionEngine
from coding_agent.execution.feedback_loop import FeedbackLoop
from coding_agent.memory.unified_memory import UnifiedMemoryManager
# 初始化意图识别器
intent_recognizer = IntentRecognizer(
llm_client=llm_client,
model_name=model_name,
)
# 初始化任务分解器
task_decomposer = TaskDecomposer(
llm_client=llm_client,
model_name=model_name,
)
# 初始化检索器
semantic_retriever = SemanticRetriever(
embedding_client=embedding_client,
vector_store=vector_store,
)
keyword_retriever = KeywordRetriever()
hybrid_retriever = HybridRetriever(
retrievers=[semantic_retriever, keyword_retriever],
fusion_strategy="rrf",
)
# 初始化上下文构建器
context_builder = ContextBuilder(
max_tokens=60000,
)
# 初始化代码生成器
code_generator = CodeGenerator(
llm_client=llm_client,
)
# 初始化执行引擎
execution_engine = ExecutionEngine(
workspace_root=workspace_root,
)
# 初始化反馈循环
feedback_loop = FeedbackLoop()
# 初始化记忆管理器
memory_manager = UnifiedMemoryManager()
await memory_manager.initialize(
project_id="default_project",
)
# 创建编排器
orchestrator = AgentOrchestrator(
intent_recognizer=intent_recognizer,
task_decomposer=task_decomposer,
retriever=hybrid_retriever,
context_builder=context_builder,
code_generator=code_generator,
execution_engine=execution_engine,
feedback_loop=feedback_loop,
memory_manager=memory_manager,
)
return orchestrator
async def main():
"""主函数:演示 Coding Agent 使用"""
# 创建 Agent
agent = await create_coding_agent()
# 创建用户请求
request = UserRequest(
raw_text="在 src/utils/helper.py 中添加一个新的工具函数,用于计算两个日期之间的天数差",
)
# 处理请求
result = await agent.process_request(request)
# 输出结果
print("=" * 50)
print("Coding Agent 执行结果")
print("=" * 50)
print(f"成功: {result['success']}")
print(f"状态: {result['state']}")
print(f"任务完成: {result['tasks_completed']}/{result['total_tasks']}")
if result["success"]:
print(f"\n生成的代码:\n{result['generated_code']}")
else:
print(f"\n错误: {result['error']}")
if __name__ == "__main__":
asyncio.run(main())9.2 使用流程图
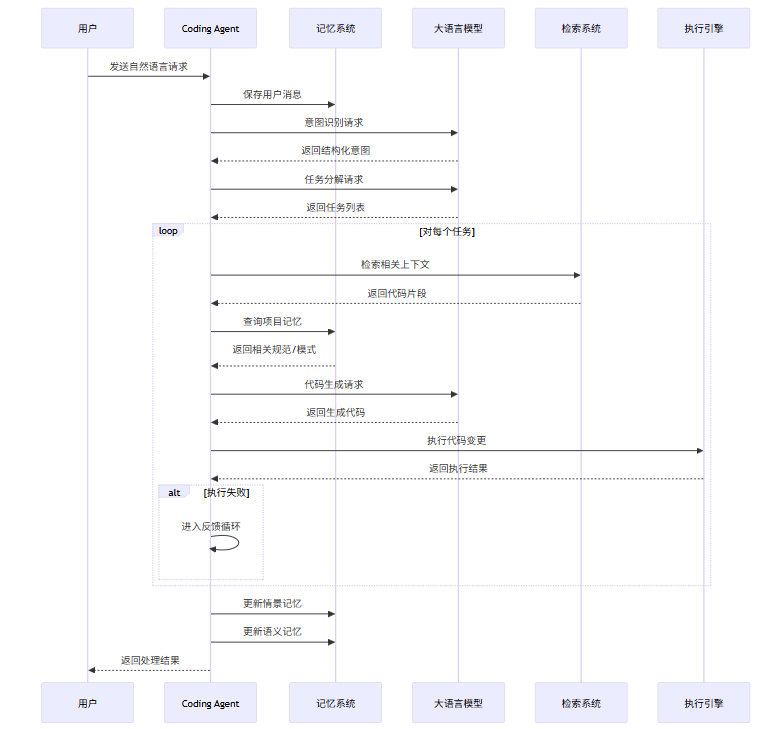
图 9-1:Coding Agent 使用流程时序图
10. 总结与展望
本节核心技术价值
本节为你提供的核心价值是建立对 Coding Agent 未来发展的前瞻认知,理解当前架构的局限性以及可能的演进方向,为读者在 AI IDE 领域的持续探索提供指引。
10.1 架构总结
本文构建的 Coding Agent 核心引擎包含以下核心组件:
组件 | 职责 | 关键实现 |
|---|---|---|
任务理解引擎 | 意图识别、实体提取、任务分解 | 基于 LLM + Few-shot Learning |
混合检索系统 | 多策略检索、结果融合 | BM25 + 语义向量 + RRF 融合 |
代码生成管道 | Prompt 模板、LLM 调用、输出验证 | 多级重试 + 验证机制 |
执行反馈循环 | 语法验证、测试执行、人工确认 | 状态机驱动的反馈处理 |
三层记忆体系 | 工作/情景/语义记忆 | 文件持久化 + 统一访问接口 |
调度编排层 | 状态管理、任务协调、组件调度 | 状态机 + 事件驱动 |
10.2 已知局限
当前实现存在以下局限:
- 检索精度:BM25 检索器使用简单分词,对代码语义理解有限
- 执行安全:缺少沙箱机制,直接修改文件系统存在风险
- 并行化:任务调度器仅支持有限并发,未充分利用资源
- 记忆压缩:三层记忆间的同步和压缩机制尚未实现
10.3 未来演进方向
方向 | 描述 | 预期收益 |
|---|---|---|
多 Agent 协作 | 引入专门的规划 Agent、执行 Agent、审查 Agent | 复杂任务处理能力提升 |
持续学习 | 从用户反馈中自动更新检索和生成模型 | 个性化体验持续优化 |
代码血缘追踪 | 完整的依赖分析和变更影响评估 | 变更安全性提升 |
多模态交互 | 支持语音、图表等非文本交互方式 | 用户体验改善 |
分布式架构 | 支持多实例协同,支持云端部署 | 可扩展性和可用性提升 |
10.4 参考架构对比
架构 | 代表系统 | 特点 | 与本文对比 |
|---|---|---|---|
单 Agent | GitHub Copilot | 实时补全、低延迟 | 本文采用,更适合复杂任务 |
多 Agent | AutoGPT、LangChain Agent | 任务分解、自主规划 | 本文的编排层支持扩展 |
知识增强 | RAG + Agent | 结合外部知识库 | 本文的三层记忆提供类似能力 |
参考链接
- 主要来源:Microsoft Copilot - AI-powered coding assistant - 微软 AI 编程助手的架构参考
- 主要来源:LangChain Agent Framework - Agent 框架设计参考
- 主要来源:OpenAI Function Calling - 结构化输出规范
- 主要来源:BM25 Retrieval Algorithm - BM25 算法原理
附录(Appendix):
附录 A:核心数据模型完整代码
详见第 2 节完整代码,实现的所有 Pydantic 模型定义。
附录 B:意图识别器完整代码
详见第 3 节完整代码,实现的 IntentRecognizer 和 TaskDecomposer 类。
附录 C:检索系统完整代码
详见第 4 节完整代码,实现的 BaseRetriever、SemanticRetriever、KeywordRetriever、HybridRetriever 和 ContextBuilder 类。
附录 D:代码生成管道完整代码
详见第 5 节完整代码,实现的 CodeGenerator 和 GenerationResult 类。
附录 E:执行引擎完整代码
详见第 6 节完整代码,实现的 ExecutionEngine 和 FeedbackLoop 类。
附录 F:三层记忆完整代码
详见第 7 节完整代码,实现的 BaseMemoryStore、WorkingMemoryManager、EpisodicMemoryManager、SemanticMemoryManager 和 UnifiedMemoryManager 类。
附录 G:调度编排层完整代码
详见第 8 节完整代码,实现的 AgentState、AgentContext、AgentOrchestrator 和 TaskScheduler 类。
附录 H:完整 Agent 集成代码
详见第 9 节完整代码,实现的 create_coding_agent 工厂函数和 main 演示函数。
关键词: Coding Agent、AI IDE、大语言模型、意图识别、混合检索、BM25、语义向量、Prompt 工程、代码生成、执行引擎、反馈循环、三层记忆体系、工作记忆、情景记忆、语义记忆、状态机、任务调度、Agent 架构、RAG、LLM、GPT-4
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-05-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号