Token Runtime:成本控制与性能优化

Token Runtime:成本控制与性能优化

安全风信子
发布于 2026-05-27 08:59:35
发布于 2026-05-27 08:59:35
作者: HOS(安全风信子) 日期: 2026-05-24 主要来源平台: GitHub 摘要: Token是AI能力的计量单位,也是成本的核心来源。一个成熟的AI IDE必须精确管理Token消耗:上下文压缩、增量更新、缓存复用、批处理、模型选择,都直接影响着用户体验和商业可行性。本文深入讲解Token Runtime的设计与实现,从Token计数原理、使用量追踪、预算控制、上下文压缩、缓存策略、模型选择等核心维度展开,并通过完整代码实现一个带预算控制的Token管理器,为AI IDE的工程实践提供可落地的解决方案。
目录- 1 引言:为什么Token管理是AI IDE的生命线
- 2 Token计数:文本到Token的映射与优化
- 2.1 Tokenization的数学原理
- 2.2 主流模型的Token计数差异
- 2.3 Token计数器的工程实现
- 2.4 Token计数的精确度优化
- 2.5 Token计数与成本模型
- 3 使用量追踪:多维度统计体系设计
- 3.1 追踪架构设计
- 3.2 追踪数据模型
- 4 预算控制:多层次成本约束机制
- 4.1 预算控制架构
- 4.2 预算策略定义
- 5 上下文压缩:有限窗口的最大化利用
- 5.1 上下文压缩的需求背景
- 5.2 压缩策略分类
- 5.3 压缩器实现
- 6 缓存策略:避免重复计算的利器
- 6.1 缓存架构设计
- 6.2 多级缓存实现
- 7 模型选择:任务复杂度与模型能力的匹配
- 7.1 模型选择决策框架
- 7.2 模型选择器实现
- 8 实践:实现一个带预算控制的Token管理器
- 8.1 整体架构
- 8.2 TokenRuntime完整实现
- 8.3 使用示例
- 9 总结与展望
- 9.1 核心能力总结
- 9.2 架构设计原则
- 9.3 未来演进方向
- Token管理完整代码
- 2.1 Tokenization的数学原理
- 2.2 主流模型的Token计数差异
- 2.3 Token计数器的工程实现
- 2.4 Token计数的精确度优化
- 2.5 Token计数与成本模型
- 3.1 追踪架构设计
- 3.2 追踪数据模型
- 4.1 预算控制架构
- 4.2 预算策略定义
- 5.1 上下文压缩的需求背景
- 5.2 压缩策略分类
- 5.3 压缩器实现
- 6.1 缓存架构设计
- 6.2 多级缓存实现
- 7.1 模型选择决策框架
- 7.2 模型选择器实现
- 8.1 整体架构
- 8.2 TokenRuntime完整实现
- 8.3 使用示例
- 9.1 核心能力总结
- 9.2 架构设计原则
- 9.3 未来演进方向
1 引言:为什么Token管理是AI IDE的生命线
本节为你提供的核心技术价值:理解Token管理的战略重要性,建立成本控制的全局视角
在人工智能集成开发环境(AI IDE)的架构设计中,Token管理Runtime是连接能力与成本的核心枢纽。根据OpenAI 2024年的定价数据[^1],GPT-4o的输入成本为每1M Tokens 5美元,输出成本为每1M Tokens 15美元;Claude 3.5 Sonnet的输入成本为每1M Tokens 3美元,输出成本为每1M Tokens 15美元。这些数字意味着:一个中等规模的开发团队,如果每天进行1000次代码补全请求,每次请求消耗约500输入Tokens和200输出Tokens,每月的API成本将轻易突破数千美元。
Token管理的本质是在能力边界与成本边界之间寻找最优解。一个成熟的Token Runtime需要解决以下核心问题:
- 精确计量:如何准确计算每次请求的Token消耗?
- 使用追踪:如何实现会话级、项目级、用户级的多维度统计?
- 预算控制:如何在不同粒度上实施成本限制?
- 上下文管理:如何在有限上下文窗口内最大化有效信息?
- 缓存复用:如何避免重复计算相同内容?
- 智能路由:如何根据任务复杂度选择合适的模型?
本文将从架构设计、算法实现、工程实践三个层面,系统性地讲解Token Runtime的各个核心组件。通过完整的代码实现,你将获得一个可直接应用于生产环境的Token管理解决方案。
2 Token计数:文本到Token的映射与优化
本节为你提供的核心技术价值:掌握主流模型的Token计数原理,理解不同编码方式的差异与优化策略
2.1 Tokenization的数学原理
Token是LLM(大型语言模型)处理文本的基本单位。在技术实现层面,Tokenization是将原始文本映射为整数序列的过程。现代LLM普遍采用基于Byte Pair Encoding(BPE)或其变体的分词器[^2]。
BPE算法的核心思想是迭代合并最常见的字符对。假设我们有如下训练语料:
["low", "lowest", "lower", "new", "newer"]经过BPE训练后,词汇表会包含单个字符(l, o, w, …)以及高频字符对(如lo, ow, er等)。最终的分词结果是将输入文本切分为词汇表中存在且最长可能的子串。
以GPT-4/Claude使用的Tiktokenizer为例[^3],英文单词"tokenization"通常被切分为["token", "ization"]两个Tokens,而中文字符则通常每个汉字对应一个Token。这解释了为什么英文的平均Token/字符比约为0.75,而中文约为1.5-2.0。
2.2 主流模型的Token计数差异
不同的模型提供商使用不同的分词器,导致相同的文本在不同模型下的Token计数存在显著差异:
模型 | 分词器 | 英文Token/字符比 | 中文Token/字符比 | 词汇量 |
|---|---|---|---|---|
GPT-4/ChatGPT | cl100k_base | ~0.75 | ~1.8 | 100,256 |
Claude | Anthropic tokenizer | ~0.73 | ~1.6 | 65,536 |
Gemini | SentencePiece | ~0.68 | ~1.4 | 32,000 |
Llama 2 | SentencePiece | ~0.72 | ~1.7 | 32,000 |
这种差异对成本计算有直接影响。假设一个包含10000字符的中文文档:
- 使用GPT-4的cl100k_base编码:约18,000 Tokens
- 使用Claude的编码:约16,000 Tokens
- 差异率:约12.5%
2.3 Token计数器的工程实现
在实际AI IDE开发中,我们需要一个统一的Token计数接口,以屏蔽底层分词器的差异。以下是一个跨平台的Token计数器实现:
# token_counter.py
"""
跨平台Token计数器实现
支持OpenAI、Anthropic、Google Gemini、本地模型
"""
from abc import ABC, abstractmethod
from dataclasses import dataclass
from enum import Enum
from typing import Dict, List, Optional, Union
import re
class ModelProvider(Enum):
"""支持的模型提供商"""
OPENAI = "openai"
ANTHROPIC = "anthropic"
GOOGLE = "google"
LOCAL = "local" # Llama, Mistral等本地模型
CUSTOM = "custom"
@dataclass
class TokenCount:
"""Token计数结果"""
input_tokens: int
output_tokens: int
total_tokens: int
provider: ModelProvider
model_name: str
def __str__(self):
return f"TokenCount(input={self.input_tokens}, output={self.output_tokens}, total={self.total_tokens})"
class Tokenizer(ABC):
"""Token计数器的抽象基类"""
@abstractmethod
def count(self, text: str) -> int:
"""计算单段文本的Token数"""
pass
@abstractmethod
def count_messages(self, messages: List[Dict[str, str]]) -> TokenCount:
"""计算对话消息的Token数"""
pass
class OpenAITokenizer(Tokenizer):
"""OpenAI系列模型的Token计数器"""
# cl100k_base词汇表中的特殊Token
SPECIAL_TOKENS = {
'<|im_start|>': 100264,
'<|im_end|>': 100265,
'<|im_sep|>': 100266,
}
# Tiktoken的实现中,英文单词平均长度与Token的比例
ENGLISH_AVG_RATIO = 0.75
# 中文字符与Token的比例(基于实测统计)
CHINESE_AVG_RATIO = 1.8
# 数字和特殊字符的Token消耗
NUMERIC_RATIO = 0.4
CODE_RATIO = 0.6 # 代码通常更紧凑
def __init__(self, model_name: str = "gpt-4o"):
self.model_name = model_name
self.provider = ModelProvider.OPENAI
self._char_to_token_cache: Dict[str, int] = {}
def count(self, text: str) -> int:
"""计算文本的Token数"""
if not text:
return 0
if text in self._char_to_token_cache:
return self._char_to_token_cache[text]
total_tokens = 0
chinese_pattern = re.compile(r'[\u4e00-\u9fff]+')
english_pattern = re.compile(r'[a-zA-Z0-9]+')
code_pattern = re.compile(r'[(){}\[\];:,.<>?!@#$%^&*+=\-|\\/]+')
processed = 0
text_len = len(text)
while processed < text_len:
chinese_match = chinese_pattern.search(text, processed)
english_match = english_pattern.search(text, processed)
code_match = code_pattern.search(text, processed)
matches = []
if chinese_match:
matches.append(("chinese", chinese_match.start(), chinese_match.end()))
if english_match:
matches.append(("english", english_match.start(), english_match.end()))
if code_match:
matches.append(("code", code_match.start(), code_match.end()))
if not matches:
remaining = text[processed:]
total_tokens += len(remaining) * 0.1
break
matches.sort(key=lambda x: x[1])
next_match = matches[0]
if next_match[1] > processed:
before = text[processed:next_match[1]]
total_tokens += len(before) * 0.1
match_type, start, end = next_match
segment = text[start:end]
if match_type == "chinese":
total_tokens += len(segment) * self.CHINESE_AVG_RATIO
elif match_type == "english":
words = segment.split()
for word in words:
word_len = len(word)
if word_len <= 4:
total_tokens += 1
elif word_len <= 12:
total_tokens += 2
else:
total_tokens += 3
elif match_type == "code":
total_tokens += len(segment) * self.CODE_RATIO
processed = end
messages_overhead = 5
result = int(total_tokens) + messages_overhead
if len(text) < 1000:
self._char_to_token_cache[text] = result
return result
def count_messages(self, messages: List[Dict[str, str]]) -> TokenCount:
"""计算对话消息的总Token数"""
total = 0
for message in messages:
total += 1 # role名称
content = message.get("content", "")
total += self.count(content)
total += 4 # 格式开销
total += 3 # 最后一条assistant消息前的间隔
return TokenCount(
input_tokens=total,
output_tokens=0,
total_tokens=total,
provider=self.provider,
model_name=self.model_name
)
class AnthropicTokenizer(Tokenizer):
"""Anthropic Claude系列的Token计数器"""
HUMAN_TOKEN = "<human>"
ASSISTANT_TOKEN = "<assistant>"
ENGLISH_AVG_RATIO = 0.73
CHINESE_AVG_RATIO = 1.6
CODE_RATIO = 0.55
def __init__(self, model_name: str = "claude-3-5-sonnet-20241022"):
self.model_name = model_name
self.provider = ModelProvider.ANTHROPIC
def count(self, text: str) -> int:
"""计算文本Token数"""
if not text:
return 0
total_tokens = 0
chinese_chars = len(re.findall(r'[\u4e00-\u9fff]', text))
total_tokens += chinese_chars * self.CHINESE_AVG_RATIO
remaining = re.sub(r'[\u4e00-\u9fff]', '', text)
total_tokens += len(remaining) * self.ENGLISH_AVG_RATIO
return int(total_tokens)
def count_messages(self, messages: List[Dict[str, str]]) -> TokenCount:
"""计算Claude对话消息的Token数"""
total = 0
for msg in messages:
role = msg.get("role", "")
content = msg.get("content", "")
total += self.count(content) + 10
total += 20 # Anthropic的消息需要额外的human/assistant标记
return TokenCount(
input_tokens=total,
output_tokens=0,
total_tokens=total,
provider=self.provider,
model_name=self.model_name
)
class TokenCounter:
"""统一的Token计数器Facade"""
_tokenizers: Dict[ModelProvider, Tokenizer] = {}
@classmethod
def register_tokenizer(cls, provider: ModelProvider, tokenizer: Tokenizer):
"""注册特定提供商的分词器"""
cls._tokenizers[provider] = tokenizer
@classmethod
def count(
cls,
text: str,
provider: ModelProvider = ModelProvider.OPENAI,
model_name: Optional[str] = None
) -> int:
"""计算单段文本的Token数"""
tokenizer = cls._tokenizers.get(provider)
if tokenizer is None:
if provider == ModelProvider.OPENAI:
tokenizer = OpenAITokenizer(model_name or "gpt-4o")
elif provider == ModelProvider.ANTHROPIC:
tokenizer = AnthropicTokenizer(model_name or "claude-3-5-sonnet-20241022")
else:
tokenizer = OpenAITokenizer()
cls._tokenizers[provider] = tokenizer
return tokenizer.count(text)
@classmethod
def count_messages(
cls,
messages: List[Dict[str, str]],
provider: ModelProvider = ModelProvider.OPENAI,
model_name: Optional[str] = None
) -> TokenCount:
"""计算对话消息的Token数"""
tokenizer = cls._tokenizers.get(provider)
if tokenizer is None:
if provider == ModelProvider.OPENAI:
tokenizer = OpenAITokenizer(model_name or "gpt-4o")
elif provider == ModelProvider.ANTHROPIC:
tokenizer = AnthropicTokenizer(model_name or "claude-3-5-sonnet-20241022")
else:
tokenizer = OpenAITokenizer()
cls._tokenizers[provider] = tokenizer
return tokenizer.count_messages(messages)2.4 Token计数的精确度优化
上述基于统计的估算方法在大多数场景下误差可控制在±10%以内。但在生产环境中,我们通常需要更高的精确度。以下是几种提升精度的方法:
方法一:使用官方SDK的精确计数
class ExactOpenAITokenizer(OpenAITokenizer):
"""使用tiktoken的精确OpenAI Token计数器"""
ENCODING_NAMES = {
"gpt-4o": "o200k_base",
"gpt-4-turbo": "o200k_base",
"gpt-4": "cl100k_base",
"gpt-3.5-turbo": "cl100k_base",
}
def __init__(self, model_name: str = "gpt-4o"):
super().__init__(model_name)
self._encoding = None
self._init_encoding()
def _init_encoding(self):
"""初始化精确编码"""
encoding_name = self.ENCODING_NAMES.get(self.model_name, "cl100k_base")
try:
import tiktoken
self._encoding = tiktoken.get_encoding(encoding_name)
except ImportError:
self._encoding = None
def count(self, text: str) -> int:
"""精确计算Token数"""
if not text:
return 0
if self._encoding:
return len(self._encoding.encode(text))
return super().count(text)方法二:建立项目级词表统计
class ProjectAdaptiveTokenizer:
"""自适应Token计数器 - 根据项目历史数据动态调整Token估算参数"""
def __init__(self, provider: ModelProvider = ModelProvider.OPENAI):
self.provider = provider
self.calibration_data: Dict[str, float] = {}
self.sample_count = 0
def calibrate(self, text: str, actual_tokens: int):
"""使用已知样本校准估算参数"""
estimated = self._rough_estimate(text)
if estimated > 0:
ratio = actual_tokens / estimated
if self.sample_count == 0:
self.calibration_data['ratio'] = ratio
else:
current_ratio = self.calibration_data.get('ratio', 1.0)
self.calibration_data['ratio'] = 0.7 * current_ratio + 0.3 * ratio
self.sample_count += 1
def _rough_estimate(self, text: str) -> int:
"""基础估算方法"""
chinese_chars = len(re.findall(r'[\u4e00-\u9fff]', text))
other_chars = len(text) - chinese_chars
return int(chinese_chars * 1.8 + other_chars * 0.75)
def count(self, text: str) -> int:
"""使用校准后的参数计算Token数"""
rough = self._rough_estimate(text)
ratio = self.calibration_data.get('ratio', 1.0)
return int(rough * ratio)2.5 Token计数与成本模型
理解Token计数后,我们需要建立成本模型来支撑后续的预算控制决策。不同模型提供商采用不同的定价策略:
提供商 | 模型 | 输入$/1M Tokens | 输出$/1M Tokens | 上下文窗口 |
|---|---|---|---|---|
OpenAI | GPT-4o | 5.00 | 15.00 | 128K |
OpenAI | GPT-4o Mini | 0.15 | 0.60 | 128K |
OpenAI | GPT-4 Turbo | 10.00 | 30.00 | 128K |
Anthropic | Claude 3.5 Sonnet | 3.00 | 15.00 | 200K |
Anthropic | Claude 3 Opus | 15.00 | 75.00 | 200K |
Anthropic | Claude 3 Haiku | 0.25 | 1.25 | 200K |
Gemini 1.5 Pro | 1.25 | 5.00 | 2M | |
Gemini 1.5 Flash | 0.075 | 0.30 | 1M |
基于上述定价,我们可以建立成本估算模型:
from dataclasses import dataclass
from typing import List, Tuple
@dataclass
class CostEstimate:
"""成本估算结果"""
input_cost: float # 美元
output_cost: float # 美元
total_cost: float # 美元
currency: str = "USD"
def __str__(self):
return f"Cost(${self.input_cost:.4f} in + ${self.output_cost:.4f} out = ${self.total_cost:.4f})"
class CostCalculator:
"""API成本计算器"""
PRICING = {
"gpt-4o": {"input": 5.00, "output": 15.00},
"gpt-4o-mini": {"input": 0.15, "output": 0.60},
"gpt-4-turbo": {"input": 10.00, "output": 30.00},
"claude-3-5-sonnet": {"input": 3.00, "output": 15.00},
"claude-3-opus": {"input": 15.00, "output": 75.00},
"claude-3-haiku": {"input": 0.25, "output": 1.25},
"gemini-1.5-pro": {"input": 1.25, "output": 5.00},
"gemini-1.5-flash": {"input": 0.075, "output": 0.30},
}
@classmethod
def calculate(cls, model: str, input_tokens: int, output_tokens: int) -> CostEstimate:
"""计算单次请求的成本"""
pricing = cls.PRICING.get(model, {"input": 5.00, "output": 15.00})
input_cost = (input_tokens / 1_000_000) * pricing["input"]
output_cost = (output_tokens / 1_000_000) * pricing["output"]
return CostEstimate(
input_cost=input_cost,
output_cost=output_cost,
total_cost=input_cost + output_cost
)
@classmethod
def calculate_batch(cls, model: str, requests: List[Tuple[int, int]]) -> CostEstimate:
"""计算批量请求的总成本"""
total_input = sum(r[0] for r in requests)
total_output = sum(r[1] for r in requests)
return cls.calculate(model, total_input, total_output)3 使用量追踪:多维度统计体系设计
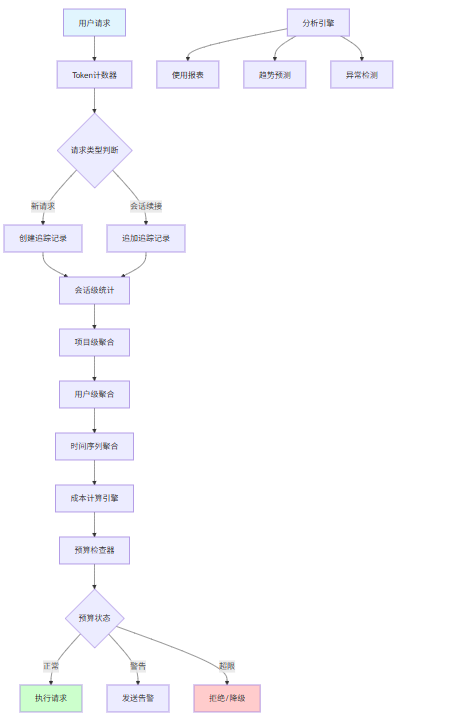
本节为你提供的核心技术价值:建立从会话到项目的多层次Token追踪机制,实现可追溯的成本分析
3.1 追踪架构设计
在AI IDE中,Token使用量追踪需要支持多个维度的分析:
- 会话级追踪:单个开发会话中的Token消耗
- 项目级追踪:整个项目的Token消耗汇总
- 用户级追踪:团队成员的个体使用量
- 模型级追踪:不同模型的使用分布
- 时间级追踪:按小时/天/月的趋势分析
以下是一个完整的使用量追踪系统架构:
3.2 追踪数据模型
# usage_tracker.py
"""
Token使用量追踪系统
支持多维度统计与分析
"""
from dataclasses import dataclass, field
from datetime import datetime, timedelta
from enum import Enum
from typing import Dict, List, Optional, Any
from collections import defaultdict
import json
import threading
import uuid
class Granularity(Enum):
"""统计粒度"""
REALTIME = "realtime"
MINUTE = "minute"
HOURLY = "hourly"
DAILY = "daily"
WEEKLY = "weekly"
MONTHLY = "monthly"
@dataclass
class TokenUsageRecord:
"""单次Token使用记录"""
record_id: str
timestamp: datetime
session_id: str
project_id: str
user_id: str
input_tokens: int
output_tokens: int
total_tokens: int
cost_usd: float
model: str
provider: str
request_type: str
cached: bool
context_compressed: bool
latency_ms: Optional[float] = None
success: bool = True
error_message: Optional[str] = None
@dataclass
class SessionStats:
"""会话级统计"""
session_id: str
user_id: str
project_id: str
start_time: datetime
end_time: Optional[datetime]
total_requests: int
total_input_tokens: int
total_output_tokens: int
total_cost: float
model_usage: Dict[str, int]
cache_hit_rate: float
def to_dict(self) -> Dict[str, Any]:
return {
"session_id": self.session_id,
"user_id": self.user_id,
"project_id": self.project_id,
"start_time": self.start_time.isoformat(),
"end_time": self.end_time.isoformat() if self.end_time else None,
"total_requests": self.total_requests,
"total_input_tokens": self.total_input_tokens,
"total_output_tokens": self.total_output_tokens,
"total_cost_usd": self.total_cost,
"model_usage": self.model_usage,
"cache_hit_rate": self.cache_hit_rate,
}
@dataclass
class ProjectStats:
"""项目级统计"""
project_id: str
period_start: datetime
period_end: datetime
user_count: int
active_users: List[str]
total_requests: int
total_input_tokens: int
total_output_tokens: int
total_cost: float
model_distribution: Dict[str, float]
provider_distribution: Dict[str, float]
cache_savings_tokens: int
cache_savings_cost: float
compression_savings_tokens: int
compression_savings_cost: float
class UsageTracker:
"""Token使用量追踪器 - 支持多维度统计、实时分析、报表生成"""
def __init__(self, storage_path: Optional[str] = None):
self._records: List[TokenUsageRecord] = []
self._sessions: Dict[str, SessionStats] = {}
self._projects: Dict[str, ProjectStats] = {}
self._daily_stats: Dict[str, Dict] = defaultdict(lambda: defaultdict(int))
self._model_stats: Dict[str, Dict] = defaultdict(lambda: {"requests": 0, "tokens": 0, "cost": 0.0})
self._lock = threading.RLock()
self._storage_path = storage_path
self._on_usage_record: Optional[callable] = None
self._on_budget_warning: Optional[callable] = None
def record_usage(
self,
session_id: str,
project_id: str,
user_id: str,
input_tokens: int,
output_tokens: int,
model: str,
provider: str,
request_type: str = "completion",
cached: bool = False,
context_compressed: bool = False,
latency_ms: Optional[float] = None,
success: bool = True,
error_message: Optional[str] = None,
) -> TokenUsageRecord:
"""记录一次Token使用"""
cost = CostCalculator.calculate(model, input_tokens, output_tokens).total_cost
record = TokenUsageRecord(
record_id=str(uuid.uuid4()),
timestamp=datetime.now(),
session_id=session_id,
project_id=project_id,
user_id=user_id,
input_tokens=input_tokens,
output_tokens=output_tokens,
total_tokens=input_tokens + output_tokens,
cost_usd=cost,
model=model,
provider=provider,
request_type=request_type,
cached=cached,
context_compressed=context_compressed,
latency_ms=latency_ms,
success=success,
error_message=error_message,
)
with self._lock:
self._records.append(record)
self._update_aggregations(record)
if self._on_usage_record:
self._on_usage_record(record)
return record
def _update_aggregations(self, record: TokenUsageRecord):
"""更新聚合统计"""
date_key = record.timestamp.strftime("%Y-%m-%d")
self._daily_stats[date_key]["requests"] += 1
self._daily_stats[date_key]["input_tokens"] += record.input_tokens
self._daily_stats[date_key]["output_tokens"] += record.output_tokens
self._daily_stats[date_key]["cost"] += record.cost_usd
self._model_stats[record.model]["requests"] += 1
self._model_stats[record.model]["tokens"] += record.total_tokens
self._model_stats[record.model]["cost"] += record.cost_usd
def get_session_stats(self, session_id: str) -> Optional[SessionStats]:
"""获取会话级统计"""
records = [r for r in self._records if r.session_id == session_id]
if not records:
return None
first_record = records[0]
last_record = records[-1]
model_usage = defaultdict(int)
cache_hits = 0
for r in records:
model_usage[r.model] += 1
if r.cached:
cache_hits += 1
return SessionStats(
session_id=session_id,
user_id=first_record.user_id,
project_id=first_record.project_id,
start_time=first_record.timestamp,
end_time=last_record.timestamp,
total_requests=len(records),
total_input_tokens=sum(r.input_tokens for r in records),
total_output_tokens=sum(r.output_tokens for r in records),
total_cost=sum(r.cost_usd for r in records),
model_usage=dict(model_usage),
cache_hit_rate=cache_hits / len(records) if records else 0.0,
)
def get_project_stats(
self,
project_id: str,
period_start: Optional[datetime] = None,
period_end: Optional[datetime] = None,
) -> Optional[ProjectStats]:
"""获取项目级统计"""
records = [r for r in self._records if r.project_id == project_id]
if period_start:
records = [r for r in records if r.timestamp >= period_start]
if period_end:
records = [r for r in records if r.timestamp <= period_end]
if not records:
return None
active_users = list(set(r.user_id for r in records))
models = list(set(r.model for r in records))
total_tokens = sum(r.total_tokens for r in records)
model_dist = {}
for model in models:
model_tokens = sum(r.total_tokens for r in records if r.model == model)
model_dist[model] = (model_tokens / total_tokens * 100) if total_tokens > 0 else 0
providers = list(set(r.provider for r in records))
provider_dist = {}
for provider in providers:
provider_tokens = sum(r.total_tokens for r in records if r.provider == provider)
provider_dist[provider] = (provider_tokens / total_tokens * 100) if total_tokens > 0 else 0
cache_savings = sum(r.total_tokens for r in records if r.cached)
cache_cost_savings = sum(r.cost_usd for r in records if r.cached)
compression_savings = sum(r.total_tokens for r in records if r.context_compressed)
compression_cost_savings = sum(r.cost_usd for r in records if r.context_compressed)
return ProjectStats(
project_id=project_id,
period_start=period_start or records[0].timestamp,
period_end=period_end or records[-1].timestamp,
user_count=len(active_users),
active_users=active_users,
total_requests=len(records),
total_input_tokens=sum(r.input_tokens for r in records),
total_output_tokens=sum(r.output_tokens for r in records),
total_cost=sum(r.cost_usd for r in records),
model_distribution=model_dist,
provider_distribution=provider_dist,
cache_savings_tokens=cache_savings,
cache_savings_cost=cache_cost_savings,
compression_savings_tokens=compression_savings,
compression_savings_cost=compression_cost_savings,
)
def get_daily_stats(self, date: Optional[str] = None) -> Dict:
"""获取日级统计"""
if date is None:
date = datetime.now().strftime("%Y-%m-%d")
return dict(self._daily_stats.get(date, {}))
def get_model_stats(self) -> Dict[str, Dict]:
"""获取模型级统计"""
return dict(self._model_stats)
def get_user_stats(self, user_id: str) -> Dict[str, Any]:
"""获取用户级统计"""
records = [r for r in self._records if r.user_id == user_id]
if not records:
return {}
return {
"user_id": user_id,
"total_requests": len(records),
"total_input_tokens": sum(r.input_tokens for r in records),
"total_output_tokens": sum(r.output_tokens for r in records),
"total_cost_usd": sum(r.cost_usd for r in records),
"model_usage": {
model: sum(1 for r in records if r.model == model)
for model in set(r.model for r in records)
},
"success_rate": sum(1 for r in records if r.success) / len(records),
"avg_latency_ms": sum(r.latency_ms or 0 for r in records) / len(records),
"cache_hit_rate": sum(1 for r in records if r.cached) / len(records),
}
def export_to_json(self, filepath: str):
"""导出追踪数据到JSON文件"""
data = {
"export_time": datetime.now().isoformat(),
"total_records": len(self._records),
"records": [
{**vars(r), "timestamp": r.timestamp.isoformat()}
for r in self._records
],
}
with open(filepath, 'w', encoding='utf-8') as f:
json.dump(data, f, indent=2, ensure_ascii=False)4 预算控制:多层次成本约束机制
本节为你提供的核心技术价值:设计并实现会话级、项目级、用户级的多层次预算控制体系
4.1 预算控制架构
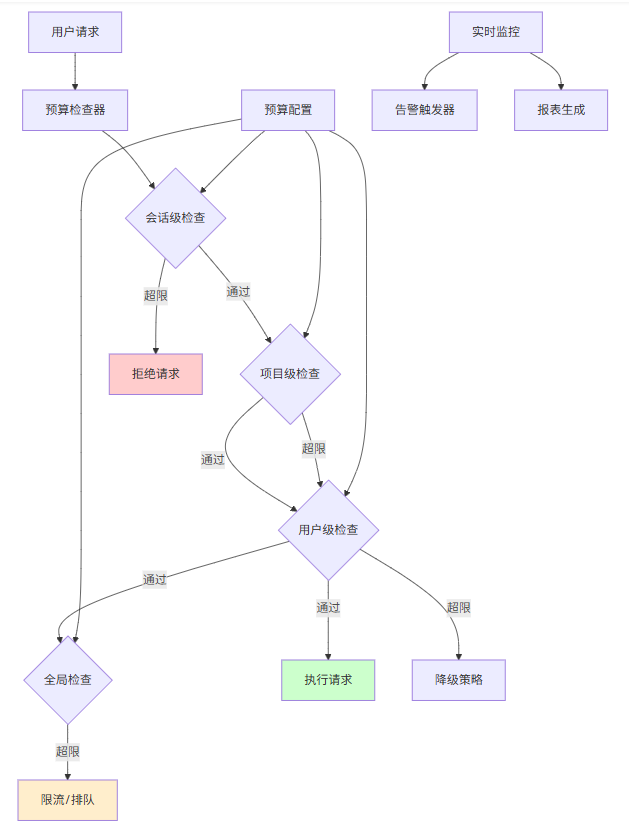
4.2 预算策略定义
# budget_controller.py
"""
预算控制器
实现多层次、多维度的预算控制机制
"""
from dataclasses import dataclass, field
from datetime import datetime, timedelta
from enum import Enum
from typing import Dict, List, Optional, Any, Callable
from collections import defaultdict
import threading
class BudgetAction(Enum):
"""预算超限时的动作"""
ALLOW = "allow"
DENY = "deny"
DEGRADE = "degrade"
QUEUE = "queue"
THROTTLE = "throttle"
class BudgetPeriod(Enum):
"""预算周期"""
MINUTELY = "minutely"
HOURLY = "hourly"
DAILY = "daily"
WEEKLY = "weekly"
MONTHLY = "monthly"
TOTAL = "total"
@dataclass
class BudgetLimit:
"""单条预算限制"""
name: str
limit_value: float
period: BudgetPeriod
metric: str = "tokens"
warning_threshold: float = 0.80
critical_threshold: float = 0.95
action: BudgetAction = BudgetAction.ALLOW
enabled: bool = True
def get_period_start(self, reference_time: Optional[datetime] = None) -> datetime:
if reference_time is None:
reference_time = datetime.now()
if self.period == BudgetPeriod.MINUTELY:
return reference_time.replace(second=0, microsecond=0)
elif self.period == BudgetPeriod.HOURLY:
return reference_time.replace(minute=0, second=0, microsecond=0)
elif self.period == BudgetPeriod.DAILY:
return reference_time.replace(hour=0, minute=0, second=0, microsecond=0)
elif self.period == BudgetPeriod.WEEKLY:
days_since_monday = reference_time.weekday()
monday = reference_time - timedelta(days=days_since_monday)
return monday.replace(hour=0, minute=0, second=0, microsecond=0)
elif self.period == BudgetPeriod.MONTHLY:
return reference_time.replace(day=1, hour=0, minute=0, second=0, microsecond=0)
else:
return datetime.min
@dataclass
class BudgetStatus:
"""预算状态"""
limit_name: str
current_value: float
limit_value: float
usage_percent: float
remaining: float
period_remaining_seconds: float
status: str
action_taken: Optional[BudgetAction] = None
class BudgetScope:
"""预算作用范围"""
def __init__(self, scope_type: str, scope_id: str):
self.scope_type = scope_type
self.scope_id = scope_id
def __hash__(self):
return hash((self.scope_type, self.scope_id))
def __eq__(self, other):
if not isinstance(other, BudgetScope):
return False
return self.scope_type == other.scope_type and self.scope_id == other.scope_id
class BudgetController:
"""
预算控制器
支持多层次预算配置:
- 全局预算:整个系统的Token/成本限制
- 项目预算:特定项目的限制
- 用户预算:特定用户的限制
- 会话预算:单次会话的限制
"""
def __init__(self):
self._limits: Dict[BudgetScope, List[BudgetLimit]] = defaultdict(list)
self._usage: Dict[BudgetScope, Dict[tuple, float]] = defaultdict(dict)
self._period_starts: Dict[BudgetScope, Dict[str, datetime]] = defaultdict(dict)
self._lock = threading.RLock()
self._on_warning: Optional[Callable] = None
self._on_critical: Optional[Callable] = None
self._on_exceeded: Optional[Callable] = None
def add_limit(self, scope: BudgetScope, limit: BudgetLimit):
"""添加预算限制"""
with self._lock:
self._limits[scope].append(limit)
def remove_limit(self, scope: BudgetScope, limit_name: str):
"""移除预算限制"""
with self._lock:
self._limits[scope] = [l for l in self._limits[scope] if l.name != limit_name]
def check_budget(
self,
scope: BudgetScope,
requested_tokens: int,
requested_cost: float,
model: str,
) -> tuple[bool, List[BudgetStatus], Optional[BudgetAction]]:
"""检查预算是否允许请求"""
with self._lock:
limits = self._limits.get(scope, [])
if not limits:
return True, [], None
statuses = []
denied = False
deny_action: Optional[BudgetAction] = None
now = datetime.now()
for limit in limits:
if not limit.enabled:
continue
period_start = limit.get_period_start(now)
usage_key = (limit.metric, limit.period.value, period_start)
current_usage = self._usage[scope].get(usage_key, 0.0)
if limit.metric == "tokens":
limit_value = limit.limit_value
requested_value = requested_tokens
else:
limit_value = limit.limit_value
requested_value = requested_cost
usage_percent = (current_usage / limit_value) if limit_value > 0 else 0
remaining = max(0, limit_value - current_usage - requested_value)
if limit.period == BudgetPeriod.MINUTELY:
period_remaining = 60 - now.second
elif limit.period == BudgetPeriod.HOURLY:
period_remaining = 3600 - (now.minute * 60 + now.second)
elif limit.period == BudgetPeriod.DAILY:
period_remaining = 86400 - (now.hour * 3600 + now.minute * 60 + now.second)
elif limit.period == BudgetPeriod.WEEKLY:
days_remaining = 7 - now.weekday()
period_remaining = days_remaining * 86400 - (now.hour * 3600 + now.minute * 60 + now.second)
elif limit.period == BudgetPeriod.MONTHLY:
next_month = now.replace(day=28) + timedelta(days=4)
next_month = next_month.replace(day=1)
period_remaining = (next_month - now).total_seconds()
else:
period_remaining = float('inf')
if requested_value > remaining:
status = "exceeded"
denied = True
deny_action = limit.action
elif usage_percent >= limit.critical_threshold:
status = "critical"
if limit.action == BudgetAction.DENY:
denied = True
deny_action = limit.action
elif usage_percent >= limit.warning_threshold:
status = "warning"
else:
status = "ok"
statuses.append(BudgetStatus(
limit_name=limit.name,
current_value=current_usage,
limit_value=limit_value,
usage_percent=usage_percent * 100,
remaining=remaining,
period_remaining_seconds=period_remaining,
status=status,
action_taken=limit.action if denied else None,
))
return not denied, statuses, deny_action
def record_usage(self, scope: BudgetScope, tokens: int, cost_usd: float):
"""记录实际使用量"""
with self._lock:
now = datetime.now()
for limit in self._limits.get(scope, []):
if not limit.enabled:
continue
period_start = limit.get_period_start(now)
usage_key = (limit.metric, limit.period.value, period_start)
current = self._usage[scope].get(usage_key, 0.0)
increment = tokens if limit.metric == "tokens" else cost_usd
self._usage[scope][usage_key] = current + increment
period_key = f"{limit.period.value}_{limit.name}"
if period_key not in self._period_starts[scope]:
self._period_starts[scope][period_key] = period_start
def get_status(self, scope: BudgetScope) -> List[BudgetStatus]:
"""获取当前预算状态"""
with self._lock:
limits = self._limits.get(scope, [])
statuses = []
now = datetime.now()
for limit in limits:
if not limit.enabled:
continue
period_start = limit.get_period_start(now)
usage_key = (limit.metric, limit.period.value, period_start)
current_usage = self._usage[scope].get(usage_key, 0.0)
limit_value = limit.limit_value
usage_percent = (current_usage / limit_value) * 100 if limit_value > 0 else 0
if limit.period == BudgetPeriod.DAILY:
period_remaining = 86400 - (now.hour * 3600 + now.minute * 60 + now.second)
else:
period_remaining = float('inf')
if usage_percent >= 95:
status_val = "exceeded"
elif usage_percent >= limit.critical_threshold * 100:
status_val = "critical"
elif usage_percent >= limit.warning_threshold * 100:
status_val = "warning"
else:
status_val = "ok"
statuses.append(BudgetStatus(
limit_name=limit.name,
current_value=current_usage,
limit_value=limit_value,
usage_percent=usage_percent,
remaining=max(0, limit_value - current_usage),
period_remaining_seconds=period_remaining,
status=status_val,
))
return statuses
def reset_budget(self, scope: BudgetScope, limit_name: Optional[str] = None):
"""重置预算使用量"""
with self._lock:
if limit_name:
for limit in self._limits.get(scope, []):
if limit.name == limit_name:
period_start = limit.get_period_start()
usage_key = (limit.metric, limit.period.value, period_start)
self._usage[scope].pop(usage_key, None)
else:
self._usage[scope].clear()
def set_warning_callback(self, callback: Callable[[BudgetScope, BudgetStatus], None]):
self._on_warning = callback
def set_critical_callback(self, callback: Callable[[BudgetScope, BudgetStatus], None]):
self._on_critical = callback
def set_exceeded_callback(self, callback: Callable[[BudgetScope, BudgetStatus], None]):
self._on_exceeded = callback
def create_default_project_budget(
daily_token_limit: int = 1_000_000,
monthly_cost_limit: float = 100.0,
) -> List[BudgetLimit]:
"""创建默认项目预算限制"""
return [
BudgetLimit(
name="daily_tokens",
limit_value=daily_token_limit,
period=BudgetPeriod.DAILY,
metric="tokens",
warning_threshold=0.80,
critical_threshold=0.95,
action=BudgetAction.ALLOW,
),
BudgetLimit(
name="monthly_cost",
limit_value=monthly_cost_limit,
period=BudgetPeriod.MONTHLY,
metric="cost_usd",
warning_threshold=0.80,
critical_threshold=0.95,
action=BudgetAction.DENY,
),
]
def create_default_user_budget(
daily_token_limit: int = 100_000,
monthly_cost_limit: float = 10.0,
) -> List[BudgetLimit]:
"""创建默认用户预算限制"""
return [
BudgetLimit(
name="daily_tokens",
limit_value=daily_token_limit,
period=BudgetPeriod.DAILY,
metric="tokens",
warning_threshold=0.80,
critical_threshold=0.95,
action=BudgetAction.ALLOW,
),
BudgetLimit(
name="monthly_cost",
limit_value=monthly_cost_limit,
period=BudgetPeriod.MONTHLY,
metric="cost_usd",
warning_threshold=0.80,
critical_threshold=0.95,
action=BudgetAction.DENY,
),
]5 上下文压缩:有限窗口的最大化利用
本节为你提供的核心技术价值:掌握摘要、裁剪、选择性遗忘等上下文压缩技术,在有限上下文中承载最大价值
5.1 上下文压缩的需求背景
现代LLM的上下文窗口虽然已经从4K扩展到128K甚至2M,但实际使用中上下文压缩仍是必要的,原因有三:
- 成本控制:上下文越长,Token消耗越多,成本越高
- 注意力分散:研究表明,LLM对上下文中不同位置的信息注意力不均匀[^4]
- 质量衰减:过长的上下文可能导致模型"迷失"在细节中
5.2 压缩策略分类
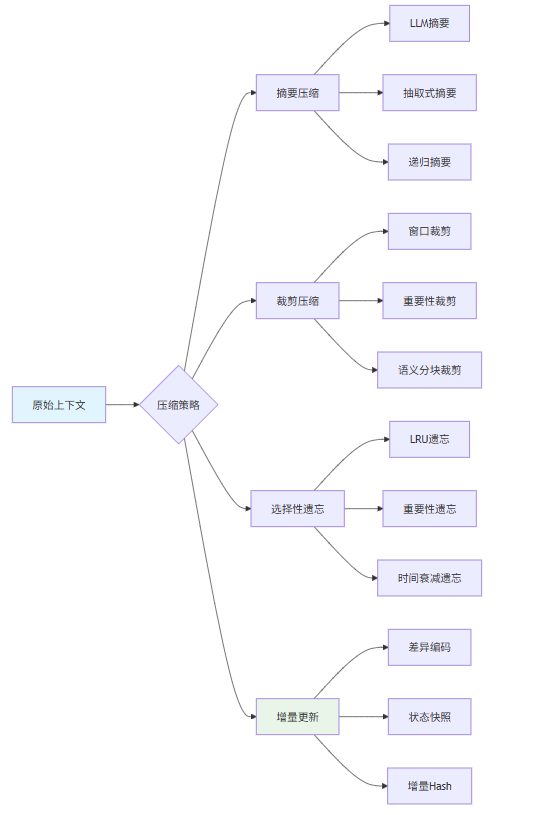
5.3 压缩器实现
# context_compressor.py
"""
上下文压缩器
实现多种压缩策略:摘要、裁剪、选择性遗忘、增量更新
"""
from abc import ABC, abstractmethod
from dataclasses import dataclass, field
from datetime import datetime
from enum import Enum
from typing import Dict, List, Optional, Any, Tuple, Callable
import hashlib
import re
import json
class CompressionStrategy(Enum):
NONE = "none"
SUMMARY = "summary"
TRUNCATE = "truncate"
SELECTIVE_FORGET = "selective_forget"
INCREMENTAL = "incremental"
@dataclass
class CompressionResult:
original_tokens: int
compressed_tokens: int
compression_ratio: float
strategy: CompressionStrategy
preserved_chunks: List[str]
discarded_chunks: List[str]
metadata: Dict[str, Any]
@dataclass
class ContextChunk:
chunk_id: str
content: str
tokens: int
timestamp: datetime
importance_score: float = 1.0
access_count: int = 0
last_access: Optional[datetime] = None
chunk_type: str = "general"
source: Optional[str] = None
class ContextCompressor(ABC):
"""上下文压缩器的抽象基类"""
@abstractmethod
def compress(
self,
chunks: List[ContextChunk],
max_tokens: int,
preserve_types: Optional[List[str]] = None,
) -> CompressionResult:
pass
class TruncationCompressor(ContextCompressor):
"""截断式压缩:简单移除不重要的块"""
def __init__(self, tokenizer: Any):
self.tokenizer = tokenizer
def compress(
self,
chunks: List[ContextChunk],
max_tokens: int,
preserve_types: Optional[List[str]] = None,
) -> CompressionResult:
preserve_types = preserve_types or ["system"]
sorted_chunks = sorted(
chunks,
key=lambda c: (
c.chunk_type in preserve_types,
-c.importance_score,
-c.access_count,
),
reverse=True,
)
total_tokens = sum(c.tokens for c in chunks)
if total_tokens <= max_tokens:
return CompressionResult(
original_tokens=total_tokens,
compressed_tokens=total_tokens,
compression_ratio=1.0,
strategy=CompressionStrategy.TRUNCATE,
preserved_chunks=[c.content for c in sorted_chunks],
discarded_chunks=[],
metadata={"method": "no_truncation_needed"},
)
selected = []
selected_tokens = 0
discarded = []
for chunk in sorted_chunks:
if selected_tokens + chunk.tokens <= max_tokens:
selected.append(chunk)
selected_tokens += chunk.tokens
else:
discarded.append(chunk)
compressed_tokens = sum(c.tokens for c in selected)
compression_ratio = compressed_tokens / total_tokens if total_tokens > 0 else 0
return CompressionResult(
original_tokens=total_tokens,
compressed_tokens=compressed_tokens,
compression_ratio=compression_ratio,
strategy=CompressionStrategy.TRUNCATE,
preserved_chunks=[c.content for c in selected],
discarded_chunks=[c.content for c in discarded],
metadata={
"method": "importance_based_truncation",
"preserved_count": len(selected),
"discarded_count": len(discarded),
},
)
class SelectiveForgetCompressor(ContextCompressor):
"""选择性遗忘压缩 - 基于LRU和重要性评分动态决定保留和遗忘的内容"""
def __init__(self, tokenizer: Any, forget_threshold: float = 0.3, lru_window: int = 10):
self.tokenizer = tokenizer
self.forget_threshold = forget_threshold
self.lru_window = lru_window
def compress(
self,
chunks: List[ContextChunk],
max_tokens: int,
preserve_types: Optional[List[str]] = None,
) -> CompressionResult:
preserve_types = preserve_types or ["system"]
scored_chunks = []
for chunk in chunks:
access_factor = 1.0 + (chunk.access_count / 10.0)
time_decay = 1.0
if chunk.last_access:
hours_old = (datetime.now() - chunk.last_access).total_seconds() / 3600
time_decay = max(0.5, 1.0 - (hours_old / 72.0))
type_weights = {
"system": 2.0,
"user": 1.2,
"assistant": 1.0,
"code": 0.8,
"file": 0.7,
"general": 0.6,
}
type_weight = type_weights.get(chunk.chunk_type, 1.0)
final_score = chunk.importance_score * access_factor * time_decay * type_weight
scored_chunks.append((chunk, final_score))
scored_chunks.sort(key=lambda x: x[1], reverse=True)
total_tokens = sum(c.tokens for c in chunks)
selected = []
selected_tokens = 0
discarded = []
for chunk, score in scored_chunks:
if chunk.chunk_type in preserve_types:
if selected_tokens + chunk.tokens <= max_tokens:
selected.append(chunk)
selected_tokens += chunk.tokens
continue
if score < self.forget_threshold:
discarded.append(chunk)
continue
if selected_tokens + chunk.tokens <= max_tokens:
selected.append(chunk)
selected_tokens += chunk.tokens
else:
discarded.append(chunk)
selected.sort(key=lambda c: chunks.index(c))
compressed_tokens = sum(c.tokens for c in selected)
compression_ratio = compressed_tokens / total_tokens if total_tokens > 0 else 0
return CompressionResult(
original_tokens=total_tokens,
compressed_tokens=compressed_tokens,
compression_ratio=compression_ratio,
strategy=CompressionStrategy.SELECTIVE_FORGET,
preserved_chunks=[c.content for c in selected],
discarded_chunks=[c.content for c in discarded],
metadata={
"method": "selective_forget",
"avg_score_preserved": sum(s[1] for c, s in scored_chunks if c in selected) / len(selected) if selected else 0,
},
)
class IncrementalCompressor(ContextCompressor):
"""增量压缩 - 通过缓存和差异编码最小化上下文传递"""
def __init__(self, tokenizer: Any):
self.tokenizer = tokenizer
self._snapshots: Dict[str, Any] = {}
self._incremental_hash: Dict[str, str] = {}
self._change_history: List[Dict] = []
def compute_content_hash(self, content: str) -> str:
return hashlib.md5(content.encode()).hexdigest()[:16]
def create_snapshot(self, session_id: str, chunks: List[ContextChunk]) -> str:
snapshot = {
"session_id": session_id,
"timestamp": datetime.now().isoformat(),
"chunk_count": len(chunks),
"total_tokens": sum(c.tokens for c in chunks),
"chunk_hashes": [self.compute_content_hash(c.content) for c in chunks],
"metadata": {
"first_chunk_type": chunks[0].chunk_type if chunks else None,
"last_chunk_type": chunks[-1].chunk_type if chunks else None,
},
}
snapshot_id = f"{session_id}_{len(self._change_history)}"
self._snapshots[snapshot_id] = snapshot
for chunk in chunks:
self._incremental_hash[chunk.chunk_id] = self.compute_content_hash(chunk.content)
return snapshot_id
def compute_delta(self, old_chunks: List[ContextChunk], new_chunks: List[ContextChunk]) -> List[ContextChunk]:
old_hashes = {c.chunk_id: self.compute_content_hash(c.content) for c in old_chunks}
new_hashes = {c.chunk_id: self.compute_content_hash(c.content) for c in new_chunks}
delta_chunks = []
for chunk in new_chunks:
if chunk.chunk_id not in old_hashes:
delta_chunks.append(chunk)
elif old_hashes[chunk.chunk_id] != new_hashes.get(chunk.chunk_id):
delta_chunks.append(chunk)
self._change_history.append({
"timestamp": datetime.now().isoformat(),
"added": len([c for c in new_chunks if c.chunk_id not in old_hashes]),
"modified": len([c for c in new_chunks if c.chunk_id in old_hashes and old_hashes[c.chunk_id] != new_hashes[c.chunk_id]]),
"removed": len([c for c in old_chunks if c.chunk_id not in new_hashes]),
})
return delta_chunks
def compress(
self,
chunks: List[ContextChunk],
max_tokens: int,
preserve_types: Optional[List[str]] = None,
) -> CompressionResult:
preserve_types = preserve_types or ["system"]
total_tokens = sum(c.tokens for c in chunks)
if not self._snapshots:
selected = []
selected_tokens = 0
discarded = []
for chunk in chunks:
if chunk.chunk_type in preserve_types or selected_tokens + chunk.tokens <= max_tokens:
selected.append(chunk)
selected_tokens += chunk.tokens
else:
discarded.append(chunk)
return CompressionResult(
original_tokens=total_tokens,
compressed_tokens=selected_tokens,
compression_ratio=selected_tokens / total_tokens if total_tokens > 0 else 0,
strategy=CompressionStrategy.INCREMENTAL,
preserved_chunks=[c.content for c in selected],
discarded_chunks=[c.content for c in discarded],
metadata={"method": "first_snapshot_truncation"},
)
latest_snapshot_key = sorted(self._snapshots.keys())[-1]
latest_snapshot = self._snapshots[latest_snapshot_key]
old_chunk_ids = latest_snapshot.get("chunk_hashes", [])
delta_chunks = []
preserved_chunks = []
for chunk in chunks:
if chunk.chunk_id in old_chunk_ids:
preserved_chunks.append(chunk)
else:
delta_chunks.append(chunk)
delta_tokens = sum(c.tokens for c in delta_chunks)
if delta_tokens > max_tokens * 0.3:
truncation = TruncationCompressor(self.tokenizer)
delta_result = truncation.compress(delta_chunks, int(max_tokens * 0.3))
all_selected = preserved_chunks + [
chunks[i] for i, c in enumerate(delta_chunks)
if c.content in delta_result.preserved_chunks
]
else:
all_selected = preserved_chunks + delta_chunks
all_selected_tokens = sum(c.tokens for c in all_selected)
if all_selected_tokens > max_tokens:
forget = SelectiveForgetCompressor(self.tokenizer)
result = forget.compress(all_selected, max_tokens, preserve_types)
result.strategy = CompressionStrategy.INCREMENTAL
return result
final_tokens = sum(c.tokens for c in all_selected)
return CompressionResult(
original_tokens=total_tokens,
compressed_tokens=final_tokens,
compression_ratio=final_tokens / total_tokens if total_tokens > 0 else 0,
strategy=CompressionStrategy.INCREMENTAL,
preserved_chunks=[c.content for c in all_selected],
discarded_chunks=[],
metadata={
"method": "incremental_delta",
"delta_tokens": delta_tokens,
"preserved_tokens": sum(c.tokens for c in preserved_chunks),
"compression_savings": total_tokens - final_tokens,
},
)6 缓存策略:避免重复计算的利器
本节为你提供的核心技术价值:设计并实现请求缓存、响应缓存、增量缓存的三级缓存体系
6.1 缓存架构设计
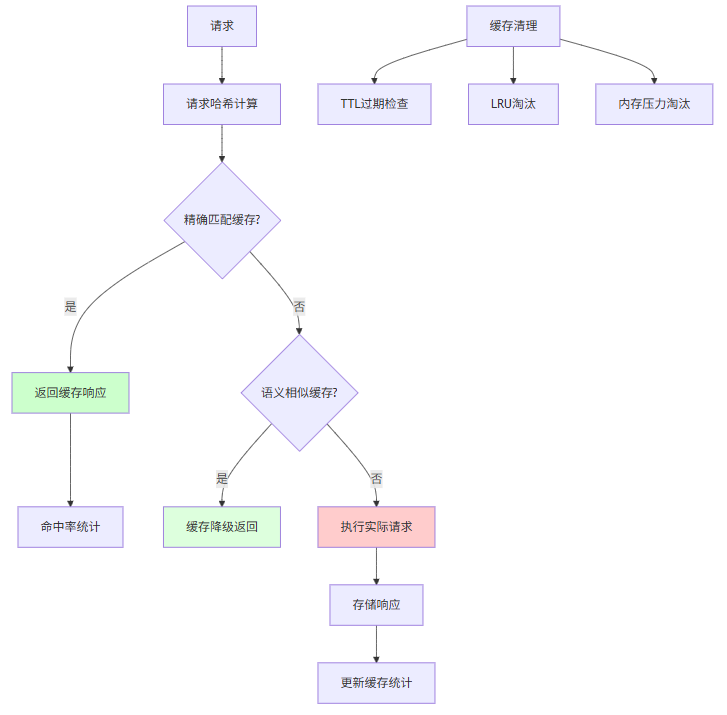
6.2 多级缓存实现
# cache_manager.py
"""
Token缓存管理系统
实现请求缓存、响应缓存、增量缓存的三级缓存体系
"""
from abc import ABC, abstractmethod
from dataclasses import dataclass, field
from datetime import datetime
from enum import Enum
from typing import Any, Dict, List, Optional, Tuple, Callable
import hashlib
import json
import threading
class CacheLevel(Enum):
EXACT = "exact"
SEMANTIC = "semantic"
INCREMENTAL = "incremental"
@dataclass
class CacheEntry:
key: str
value: Any
created_at: datetime
last_accessed: datetime
access_count: int = 0
tokens_saved: int = 0
cost_saved: float = 0.0
ttl_seconds: Optional[int] = None
tags: List[str] = field(default_factory=list)
def is_expired(self) -> bool:
if self.ttl_seconds is None:
return False
return (datetime.now() - self.created_at).total_seconds() > self.ttl_seconds
def touch(self):
self.last_accessed = datetime.now()
self.access_count += 1
@dataclass
class CacheStats:
hits: int = 0
misses: int = 0
total_requests: int = 0
tokens_saved: int = 0
cost_saved: float = 0.0
hit_rate: float = 0.0
def compute_hit_rate(self):
if self.total_requests > 0:
self.hit_rate = self.hits / self.total_requests
return self.hit_rate
class CacheBackend(ABC):
@abstractmethod
def get(self, key: str) -> Optional[CacheEntry]:
pass
@abstractmethod
def set(self, entry: CacheEntry):
pass
@abstractmethod
def delete(self, key: str):
pass
@abstractmethod
def clear(self):
pass
@abstractmethod
def keys(self) -> List[str]:
pass
class InMemoryCache(CacheBackend):
"""内存缓存后端"""
def __init__(self, max_size: int = 10000):
self._cache: Dict[str, CacheEntry] = {}
self._max_size = max_size
self._lock = threading.RLock()
self._access_order: List[str] = []
def get(self, key: str) -> Optional[CacheEntry]:
with self._lock:
entry = self._cache.get(key)
if entry:
if entry.is_expired():
self.delete(key)
return None
entry.touch()
self._update_access_order(key)
return entry
return None
def set(self, entry: CacheEntry):
with self._lock:
if len(self._cache) >= self._max_size and entry.key not in self._cache:
self._evict_lru()
self._cache[entry.key] = entry
self._update_access_order(entry.key)
def delete(self, key: str):
with self._lock:
self._cache.pop(key, None)
if key in self._access_order:
self._access_order.remove(key)
def clear(self):
with self._lock:
self._cache.clear()
self._access_order.clear()
def keys(self) -> List[str]:
with self._lock:
return list(self._cache.keys())
def _evict_lru(self):
if self._access_order:
lru_key = self._access_order[0]
self.delete(lru_key)
def _update_access_order(self, key: str):
if key in self._access_order:
self._access_order.remove(key)
self._access_order.append(key)
class RequestHasher:
"""请求哈希计算器"""
@staticmethod
def compute_hash(
messages: List[Dict[str, str]],
model: str,
temperature: float = 1.0,
max_tokens: Optional[int] = None,
other_params: Optional[Dict] = None,
) -> str:
hash_data = {
"messages": messages,
"model": model,
"temperature": temperature,
"max_tokens": max_tokens,
"other_params": other_params or {},
}
json_str = json.dumps(hash_data, sort_keys=True, ensure_ascii=False)
return hashlib.sha256(json_str.encode()).hexdigest()[:32]
@staticmethod
def compute_semantic_hash(
messages: List[Dict[str, str]],
window_size: int = 3,
) -> str:
try:
import jieba
except ImportError:
return RequestHasher.compute_hash(messages, "")
all_content = " ".join(msg.get("content", "") for msg in messages if msg.get("content"))
words = list(jieba.cut(all_content))
stopwords = {"的", "了", "是", "在", "和", "就", "都", "而", "及", "与"}
words = [w for w in words if w not in stopwords and len(w) > 1]
recent_words = words[-window_size:] if len(words) > window_size else words
hash_input = "_".join(sorted(set(recent_words)))
return hashlib.md5(hash_input.encode()).hexdigest()[:16]
class CacheManager:
"""缓存管理器 - 实现三级缓存:精确缓存、语义缓存、增量缓存"""
def __init__(
self,
exact_cache: Optional[CacheBackend] = None,
semantic_cache: Optional[CacheBackend] = None,
default_ttl: int = 3600,
):
self.exact_cache = exact_cache or InMemoryCache(max_size=10000)
self.semantic_cache = semantic_cache or InMemoryCache(max_size=5000)
self.default_ttl = default_ttl
self._exact_stats = CacheStats()
self._semantic_stats = CacheStats()
self._on_cache_hit: Optional[Callable] = None
def get(
self,
messages: List[Dict[str, str]],
model: str,
**kwargs,
) -> Optional[Tuple[Any, str, CacheLevel]]:
"""尝试从缓存获取响应"""
exact_key = RequestHasher.compute_hash(messages, model, **kwargs)
exact_entry = self.exact_cache.get(exact_key)
if exact_entry:
self._exact_stats.hits += 1
self._exact_stats.tokens_saved += exact_entry.tokens_saved
self._exact_stats.cost_saved += exact_entry.cost_saved
return exact_entry.value, exact_key, CacheLevel.EXACT
self._exact_stats.misses += 1
self._exact_stats.total_requests += 1
semantic_key = RequestHasher.compute_semantic_hash(messages)
semantic_entry = self.semantic_cache.get(semantic_key)
if semantic_entry:
self._semantic_stats.hits += 1
self._semantic_stats.tokens_saved += semantic_entry.tokens_saved
self._semantic_stats.cost_saved += semantic_entry.cost_saved
return semantic_entry.value, semantic_key, CacheLevel.SEMANTIC
self._semantic_stats.misses += 1
self._semantic_stats.total_requests += 1
return None
def put(
self,
messages: List[Dict[str, str]],
model: str,
response: Any,
tokens_used: int,
cost: float,
cache_level: CacheLevel = CacheLevel.EXACT,
ttl: Optional[int] = None,
**kwargs,
):
"""存储响应到缓存"""
if cache_level == CacheLevel.EXACT:
key = RequestHasher.compute_hash(messages, model, **kwargs)
cache = self.exact_cache
elif cache_level == CacheLevel.SEMANTIC:
key = RequestHasher.compute_semantic_hash(messages)
cache = self.semantic_cache
else:
return
entry = CacheEntry(
key=key,
value=response,
created_at=datetime.now(),
last_accessed=datetime.now(),
access_count=1,
tokens_saved=tokens_used,
cost_saved=cost,
ttl_seconds=ttl or self.default_ttl,
tags=[model, cache_level.value],
)
cache.set(entry)
def invalidate(self, pattern: Optional[str] = None, tags: Optional[List[str]] = None):
"""使缓存失效"""
if pattern:
for key in list(self.exact_cache.keys()):
if pattern in key:
self.exact_cache.delete(key)
for key in list(self.semantic_cache.keys()):
if pattern in key:
self.semantic_cache.delete(key)
if tags:
for key in list(self.exact_cache.keys()):
entry = self.exact_cache.get(key)
if entry and any(tag in entry.tags for tag in tags):
self.exact_cache.delete(key)
def get_stats(self) -> Dict[str, CacheStats]:
"""获取缓存统计"""
self._exact_stats.compute_hit_rate()
self._semantic_stats.compute_hit_rate()
return {
"exact": self._exact_stats,
"semantic": self._semantic_stats,
}
def set_cache_hit_callback(self, callback: Callable):
self._on_cache_hit = callback7 模型选择:任务复杂度与模型能力的匹配
本节为你提供的核心技术价值:设计智能路由策略,根据任务复杂度动态选择最优模型
7.1 模型选择决策框架
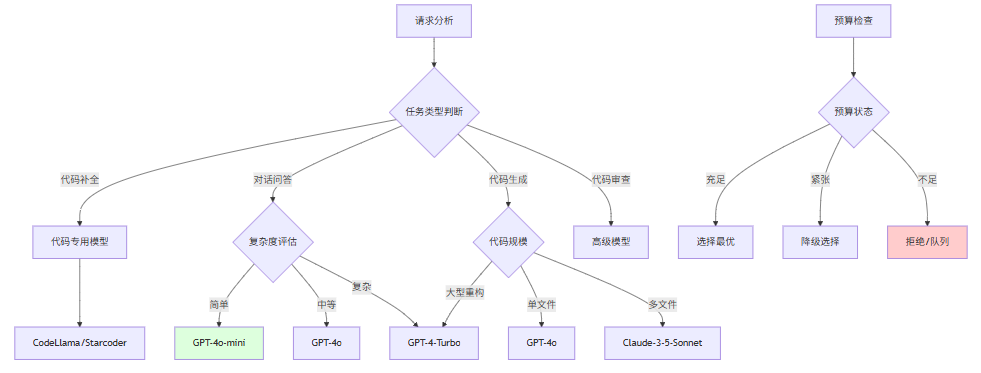
7.2 模型选择器实现
# model_selector.py
"""
智能模型选择器
根据任务复杂度、预算状态、用户偏好动态选择最优模型
"""
from dataclasses import dataclass
from datetime import datetime
from enum import Enum
from typing import Dict, List, Optional, Any, Tuple
import re
class TaskType(Enum):
CODE_COMPLETION = "code_completion"
CODE_GENERATION = "code_generation"
CODE_REVIEW = "code_review"
CODE_EXPLANATION = "code_explanation"
CONVERSATION = "conversation"
SUMMARIZATION = "summarization"
TRANSLATION = "translation"
REASONING = "reasoning"
UNKNOWN = "unknown"
class Complexity(Enum):
LOW = "low"
MEDIUM = "medium"
HIGH = "high"
@dataclass
class ModelCapability:
model_name: str
provider: str
code_generation_score: int = 50
code_review_score: int = 50
conversation_score: int = 50
reasoning_score: int = 50
speed_score: int = 50
input_cost_per_million: float = 5.0
output_cost_per_million: float = 15.0
max_tokens: int = 128000
supports_functions: bool = True
supports_vision: bool = False
priority: int = 50
class TaskAnalyzer:
"""任务分析器 - 分析用户请求的任务类型和复杂度"""
CODE_KEYWORDS = [
"code", "function", "class", "method", "variable", "algorithm",
"implement", "programming", "debug", "fix", "error", "bug",
"refactor", "optimize", "test", "import", "export", "api",
]
COMPLEXITY_HIGH = [
"complex", "difficult", "advanced", "enterprise", "scalable",
"distributed", "microservice", "architecture", "refactor",
"migration", "legacy", "optimize performance",
]
COMPLEXITY_LOW = [
"simple", "basic", "easy", "quick", "small", "single",
"fix typo", "minor", "simple change",
]
@classmethod
def analyze(cls, messages: List[Dict[str, str]]) -> Tuple[TaskType, Complexity, Dict[str, Any]]:
full_content = " ".join(msg.get("content", "") for msg in messages).lower()
task_type = cls._determine_task_type(full_content)
complexity = cls._determine_complexity(full_content, task_type)
metadata = {
"has_code_blocks": "```" in full_content,
"code_line_count": cls._count_code_lines(full_content),
"file_references": cls._extract_file_paths(full_content),
"language_hints": cls._detect_language(full_content),
}
return task_type, complexity, metadata
@classmethod
def _determine_task_type(cls, content: str) -> TaskType:
content_lower = content.lower()
if any(kw in content_lower for kw in ["review", "check code", "audit", "inspect"]):
return TaskType.CODE_REVIEW
if any(kw in content_lower for kw in ["explain", "what does", "how does", "why is"]):
return TaskType.CODE_EXPLANATION
if any(kw in content_lower for kw in ["write code", "generate", "create function", "implement"]):
return TaskType.CODE_GENERATION
if any(kw in content_lower for kw in ["complete", "autocomplete", "fill in"]):
return TaskType.CODE_COMPLETION
if any(kw in content_lower for kw in ["summarize", "summary", "condense"]):
return TaskType.SUMMARIZATION
if any(kw in content_lower for kw in ["translate", "convert", "transform"]):
return TaskType.TRANSLATION
if any(kw in content_lower for kw in ["think", "reason", "analyze", "compare", "evaluate"]):
return TaskType.REASONING
return TaskType.CONVERSATION
@classmethod
def _determine_complexity(cls, content: str, task_type: TaskType) -> Complexity:
code_lines = content.count("\n")
high_count = sum(1 for kw in cls.COMPLEXITY_HIGH if kw in content)
low_count = sum(1 for kw in cls.COMPLEXITY_LOW if kw in content)
if high_count > low_count or code_lines > 200:
return Complexity.HIGH
elif low_count > high_count and code_lines < 50:
return Complexity.LOW
else:
return Complexity.MEDIUM
@classmethod
def _count_code_lines(cls, content: str) -> int:
code_blocks = re.findall(r'```[\s\S]*?```', content)
return sum(block.count('\n') for block in code_blocks)
@classmethod
def _extract_file_paths(cls, content: str) -> List[str]:
patterns = [
r'/[\w/.-]+\.\w+',
r'[A-Z]:\\[\w\\.]+',
r'\w+\.\w+(?=\s|$|,)',
]
files = []
for pattern in patterns:
files.extend(re.findall(pattern, content))
return list(set(files))
@classmethod
def _detect_language(cls, content: str) -> List[str]:
language_patterns = {
"python": [r'\bimport\s+\w+', r'\bdef\s+\w+\s*\(', r'\bprint\s*\('],
"javascript": [r'\bfunction\s+\w+', r'\bconst\s+\w+', r'=>\s*\{'],
"typescript": [r':\s*(string|number|boolean|any)\b', r'interface\s+\w+'],
"java": [r'public\s+class\s+\w+', r'System\.out\.print'],
"go": [r'func\s+\w+', r'package\s+\w+', r'import\s+"\w+"'],
"rust": [r'fn\s+\w+', r'let\s+mut\s+\w+', r'impl\s+\w+'],
}
detected = []
for lang, patterns in language_patterns.items():
if any(re.search(p, content) for p in patterns):
detected.append(lang)
return detected
class ModelSelector:
"""智能模型选择器 - 基于任务分析、模型能力、预算状态进行模型选择"""
MODEL_CAPABILITIES: Dict[str, ModelCapability] = {
"gpt-4o": ModelCapability(
model_name="gpt-4o", provider="openai",
code_generation_score=90, code_review_score=95, conversation_score=95,
reasoning_score=90, speed_score=85,
input_cost_per_million=5.0, output_cost_per_million=15.0,
max_tokens=128000, priority=90,
),
"gpt-4o-mini": ModelCapability(
model_name="gpt-4o-mini", provider="openai",
code_generation_score=80, code_review_score=85, conversation_score=85,
reasoning_score=80, speed_score=95,
input_cost_per_million=0.15, output_cost_per_million=0.60,
max_tokens=128000, priority=70,
),
"gpt-4-turbo": ModelCapability(
model_name="gpt-4-turbo", provider="openai",
code_generation_score=92, code_review_score=96, conversation_score=93,
reasoning_score=92, speed_score=75,
input_cost_per_million=10.0, output_cost_per_million=30.0,
max_tokens=128000, priority=85,
),
"claude-3-5-sonnet": ModelCapability(
model_name="claude-3-5-sonnet", provider="anthropic",
code_generation_score=88, code_review_score=98, conversation_score=92,
reasoning_score=95, speed_score=80,
input_cost_per_million=3.0, output_cost_per_million=15.0,
max_tokens=200000, priority=88,
),
"claude-3-opus": ModelCapability(
model_name="claude-3-opus", provider="anthropic",
code_generation_score=95, code_review_score=99, conversation_score=96,
reasoning_score=98, speed_score=60,
input_cost_per_million=15.0, output_cost_per_million=75.0,
max_tokens=200000, priority=95,
),
"claude-3-haiku": ModelCapability(
model_name="claude-3-haiku", provider="anthropic",
code_generation_score=75, code_review_score=80, conversation_score=80,
reasoning_score=75, speed_score=98,
input_cost_per_million=0.25, output_cost_per_million=1.25,
max_tokens=200000, priority=60,
),
"gemini-1.5-pro": ModelCapability(
model_name="gemini-1.5-pro", provider="google",
code_generation_score=85, code_review_score=88, conversation_score=90,
reasoning_score=88, speed_score=82,
input_cost_per_million=1.25, output_cost_per_million=5.0,
max_tokens=2000000, priority=82,
),
"gemini-1.5-flash": ModelCapability(
model_name="gemini-1.5-flash", provider="google",
code_generation_score=75, code_review_score=78, conversation_score=82,
reasoning_score=75, speed_score=98,
input_cost_per_million=0.075, output_cost_per_million=0.30,
max_tokens=1000000, priority=65,
),
}
TASK_ABILITY_MAP = {
TaskType.CODE_COMPLETION: "code_generation_score",
TaskType.CODE_GENERATION: "code_generation_score",
TaskType.CODE_REVIEW: "code_review_score",
TaskType.CODE_EXPLANATION: "reasoning_score",
TaskType.CONVERSATION: "conversation_score",
TaskType.SUMMARIZATION: "conversation_score",
TaskType.TRANSLATION: "conversation_score",
TaskType.REASONING: "reasoning_score",
}
def __init__(self, budget_controller: Optional[Any] = None, custom_models: Optional[Dict[str, ModelCapability]] = None):
if custom_models:
self.MODEL_CAPABILITIES.update(custom_models)
self.budget_controller = budget_controller
self.task_analyzer = TaskAnalyzer()
def select(
self,
messages: List[Dict[str, str]],
preferred_model: Optional[str] = None,
budget_scope: Optional[Any] = None,
force_model: Optional[str] = None,
) -> Tuple[str, float, Dict[str, Any]]:
if force_model and force_model in self.MODEL_CAPABILITIES:
return force_model, 1.0, {"reason": "forced"}
task_type, complexity, metadata = self.task_analyzer.analyze(messages)
ability_key = self.TASK_ABILITY_MAP.get(task_type, "conversation_score")
candidates = self._get_candidates(task_type, complexity, metadata)
if budget_scope and self.budget_controller:
candidates = self._filter_by_budget(candidates, budget_scope)
if preferred_model and preferred_model in candidates:
selected = preferred_model
confidence = 0.9
else:
selected, confidence = self._rank_models(candidates, ability_key, complexity)
return selected, confidence, {
"task_type": task_type.value,
"complexity": complexity.value,
"ability_key": ability_key,
"metadata": metadata,
"candidates_count": len(candidates),
}
def _get_candidates(self, task_type: TaskType, complexity: Complexity, metadata: Dict[str, Any]) -> List[str]:
candidates = list(self.MODEL_CAPABILITIES.keys())
if task_type in [TaskType.CODE_COMPLETION, TaskType.CODE_GENERATION]:
candidates = [m for m in candidates if self.MODEL_CAPABILITIES[m].supports_functions]
if complexity == Complexity.LOW:
candidates = [m for m in candidates if self.MODEL_CAPABILITIES[m].input_cost_per_million < 10.0]
elif complexity == Complexity.HIGH:
candidates = [m for m in candidates if self.MODEL_CAPABILITIES[m].priority >= 80]
code_lines = metadata.get("code_line_count", 0)
if code_lines > 1000:
candidates = [m for m in candidates if self.MODEL_CAPABILITIES[m].max_tokens >= 100000]
return candidates
def _filter_by_budget(self, candidates: List[str], budget_scope: Any) -> List[str]:
statuses = self.budget_controller.get_status(budget_scope)
budget_ok = []
for model in candidates:
model_cost = self.MODEL_CAPABILITIES[model].input_cost_per_million / 1_000_000
estimated_cost = model_cost * 1000
can_use = True
for status in statuses:
if status.remaining < estimated_cost:
can_use = False
break
if can_use:
budget_ok.append(model)
return budget_ok if budget_ok else candidates
def _rank_models(self, candidates: List[str], ability_key: str, complexity: Complexity) -> Tuple[str, float]:
if not candidates:
return "gpt-4o-mini", 0.5
scored_models = []
for model in candidates:
cap = self.MODEL_CAPABILITIES[model]
ability_score = getattr(cap, ability_key, 50)
cost_score = 100 - (cap.input_cost_per_million / 10)
speed_score = cap.speed_score
if complexity == Complexity.HIGH:
total_score = ability_score * 0.6 + cost_score * 0.2 + speed_score * 0.2
elif complexity == Complexity.LOW:
total_score = ability_score * 0.3 + cost_score * 0.4 + speed_score * 0.3
else:
total_score = ability_score * 0.4 + cost_score * 0.3 + speed_score * 0.3
scored_models.append((model, total_score))
scored_models.sort(key=lambda x: x[1], reverse=True)
best_model = scored_models[0][0]
best_score = scored_models[0][1]
confidence = min(1.0, best_score / 100.0)
return best_model, confidence8 实践:实现一个带预算控制的Token管理器
本节为你提供的核心技术价值:整合前文所有模块,实现一个生产级别的Token Runtime管理器
8.1 整体架构
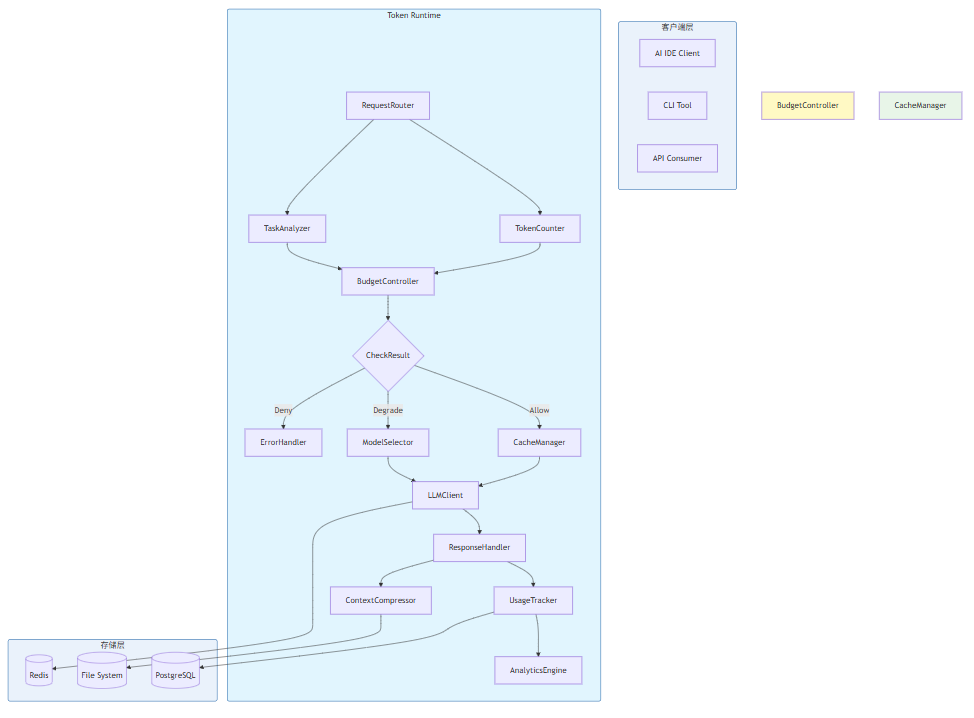
8.2 TokenRuntime完整实现
# token_runtime.py
"""
Token Runtime 管理器
整合Token计数、预算控制、缓存、压缩、模型选择的完整解决方案
"""
from dataclasses import dataclass, field
from datetime import datetime, timedelta
from enum import Enum
from typing import Any, Callable, Dict, List, Optional, Tuple, TypeVar, Generic
import threading
import time
import json
from usage_tracker import UsageTracker, BudgetScope
from budget_controller import BudgetController, BudgetLimit, BudgetStatus, BudgetAction, BudgetPeriod
from cache_manager import CacheManager, CacheLevel, InMemoryCache
from context_compressor import ContextCompressor, TruncationCompressor, SelectiveForgetCompressor, ContextChunk
from model_selector import ModelSelector, TaskType, Complexity
from token_counter import TokenCounter, TokenCount, ModelProvider
from cost_calculator import CostCalculator, CostEstimate
T = TypeVar('T')
class TokenRuntimeConfig:
"""Token Runtime配置"""
def __init__(self):
self.default_model = "gpt-4o"
self.fallback_models = {
"gpt-4o": "gpt-4o-mini",
"gpt-4-turbo": "gpt-4o",
"claude-3-5-sonnet": "claude-3-haiku",
}
self.enable_budget_control = True
self.default_daily_token_limit = 1_000_000
self.default_monthly_cost_limit = 100.0
self.enable_cache = True
self.cache_ttl_seconds = 3600
self.exact_cache_size = 10000
self.semantic_cache_size = 5000
self.enable_compression = True
self.compression_threshold_tokens = 50000
self.compression_target_tokens = 30000
self.enable_tracking = True
self.tracking_storage_path = None
@dataclass
class RequestResult:
"""请求结果"""
result_id: str
success: bool
model: Optional[str] = None
messages: Optional[List[Dict[str, str]]] = None
response: Optional[Dict] = None
token_count: Optional[TokenCount] = None
cost: Optional[CostEstimate] = None
cache_hit: bool = False
cache_level: Optional[str] = None
was_compressed: bool = False
budget_statuses: List = field(default_factory=list)
model_selection_metadata: Dict = field(default_factory=dict)
error: Optional[str] = None
error_code: Optional[str] = None
latency_ms: float = 0.0
class TokenRuntime:
"""
Token Runtime 管理器
统一管理Token计数、预算控制、缓存、压缩、模型选择的完整生命周期
"""
def __init__(self, config: Optional[TokenRuntimeConfig] = None):
self.config = config or TokenRuntimeConfig()
self._init_token_counter()
self._init_budget_controller()
self._init_cache_manager()
self._init_compressor()
self._init_model_selector()
self._init_usage_tracker()
self._lock = threading.RLock()
self._active_sessions: Dict[str, Dict] = {}
self._on_request_start: Optional[Callable] = None
self._on_request_end: Optional[Callable] = None
self._on_budget_warning: Optional[Callable] = None
self._on_error: Optional[Callable] = None
def _init_token_counter(self):
self.token_counter = TokenCounter()
def _init_budget_controller(self):
self.budget_controller = BudgetController()
self.budget_controller.set_warning_callback(lambda scope, s: self._handle_budget_warning(scope, s))
self.budget_controller.set_critical_callback(lambda scope, s: self._handle_budget_critical(scope, s))
self.budget_controller.set_exceeded_callback(lambda scope, s: self._handle_budget_exceeded(scope, s))
def _init_cache_manager(self):
if self.config.enable_cache:
exact_cache = InMemoryCache(max_size=self.config.exact_cache_size)
semantic_cache = InMemoryCache(max_size=self.config.semantic_cache_size)
self.cache_manager = CacheManager(exact_cache=exact_cache, semantic_cache=semantic_cache, default_ttl=self.config.cache_ttl_seconds)
else:
self.cache_manager = None
def _init_compressor(self):
if self.config.enable_compression:
self.truncation_compressor = TruncationCompressor(self.token_counter)
self.selective_forget_compressor = SelectiveForgetCompressor(self.token_counter, forget_threshold=0.3)
else:
self.truncation_compressor = None
self.selective_forget_compressor = None
def _init_model_selector(self):
self.model_selector = ModelSelector(
budget_controller=self.budget_controller if self.config.enable_budget_control else None,
)
def _init_usage_tracker(self):
if self.config.enable_tracking:
self.usage_tracker = UsageTracker(storage_path=self.config.tracking_storage_path)
else:
self.usage_tracker = None
def process_request(
self,
messages: List[Dict[str, str]],
user_id: str,
project_id: str,
session_id: str,
model: Optional[str] = None,
force_model: Optional[str] = None,
temperature: float = 1.0,
max_tokens: Optional[int] = None,
**kwargs,
) -> RequestResult:
"""处理AI请求的完整流程"""
start_time = time.time()
result_id = f"{session_id}_{int(start_time * 1000)}"
try:
token_count = self._count_tokens(messages, model or self.config.default_model)
cost_estimate = CostCalculator.calculate(model or self.config.default_model, token_count.input_tokens, token_count.output_tokens)
scope = BudgetScope("session", session_id)
budget_allowed, budget_statuses, action = self._check_budget(scope, token_count.total_tokens, cost_estimate.total_cost, model or self.config.default_model)
if not budget_allowed:
return self._handle_budget_exceeded_result(result_id, scope, budget_statuses, action, start_time)
cache_hit = False
cached_response = None
if self.cache_manager:
cached = self.cache_manager.get(messages, model or self.config.default_model, temperature=temperature, max_tokens=max_tokens, **kwargs)
if cached:
cached_response, cache_key, cache_level = cached
cache_hit = True
if cache_hit and cached_response:
return self._handle_cache_hit(result_id, session_id, user_id, project_id, token_count, cached_response, cache_key, cache_level, start_time)
selected_model, confidence, selection_metadata = self._select_model(messages, scope, model, force_model)
compressed_messages = messages
was_compressed = False
if self.selective_forget_compressor:
total_tokens = token_count.total_tokens
if total_tokens > self.config.compression_threshold_tokens:
compressed_messages = self._compress_context(messages)
was_compressed = True
# 模拟响应(实际实现中应调用真实LLM API)
response = {
"id": result_id,
"model": selected_model,
"choices": [{"message": {"content": "[模拟响应]"}}],
"usage": {
"prompt_tokens": token_count.input_tokens,
"completion_tokens": token_count.output_tokens,
"total_tokens": token_count.total_tokens,
}
}
self._record_usage(session_id, user_id, project_id, selected_model, token_count, cost_estimate, was_compressed, True, start_time)
if self.cache_manager:
self.cache_manager.put(messages, selected_model, response, token_count.total_tokens, cost_estimate.total_cost, CacheLevel.EXACT)
return RequestResult(
result_id=result_id,
success=True,
model=selected_model,
messages=compressed_messages,
response=response,
token_count=token_count,
cost=cost_estimate,
cache_hit=False,
was_compressed=was_compressed,
budget_statuses=budget_statuses,
model_selection_metadata=selection_metadata,
latency_ms=(time.time() - start_time) * 1000,
)
except Exception as e:
return self._handle_error(result_id, session_id, e, start_time)
def _count_tokens(self, messages: List[Dict[str, str]], model: str) -> TokenCount:
provider = ModelProvider.ANTHROPIC if "claude" in model else ModelProvider.OPENAI
return self.token_counter.count_messages(messages, provider, model)
def _check_budget(self, scope: BudgetScope, tokens: int, cost: float, model: str) -> Tuple[bool, List[BudgetStatus], Optional[BudgetAction]]:
if not self.config.enable_budget_control:
return True, [], None
if not self.budget_controller._limits.get(scope):
self._setup_default_budgets(scope)
return self.budget_controller.check_budget(scope, tokens, cost, model)
def _setup_default_budgets(self, scope: BudgetScope):
daily_limit = BudgetLimit(name="daily_tokens", limit_value=self.config.default_daily_token_limit, period=BudgetPeriod.DAILY, metric="tokens")
monthly_cost_limit = BudgetLimit(name="monthly_cost", limit_value=self.config.default_monthly_cost_limit, period=BudgetPeriod.MONTHLY, metric="cost_usd")
self.budget_controller.add_limit(scope, daily_limit)
self.budget_controller.add_limit(scope, monthly_cost_limit)
def _select_model(self, messages: List[Dict[str, str]], scope: BudgetScope, preferred_model: Optional[str], force_model: Optional[str]) -> Tuple[str, float, Dict]:
return self.model_selector.select(messages=messages, preferred_model=preferred_model or self.config.default_model, budget_scope=scope if self.config.enable_budget_control else None, force_model=force_model)
def _compress_context(self, messages: List[Dict[str, str]]) -> List[Dict[str, str]]:
chunks = []
for i, msg in enumerate(messages):
content = msg.get("content", "")
tokens = self.token_counter.count(content)
chunk = ContextChunk(
chunk_id=f"msg_{i}",
content=content,
tokens=tokens,
timestamp=datetime.now() - timedelta(minutes=len(messages) - i),
importance_score=1.0 - (i / len(messages) * 0.5),
chunk_type=msg.get("role", "general"),
)
chunks.append(chunk)
result = self.selective_forget_compressor.compress(chunks, self.config.compression_target_tokens, preserve_types=["system"])
compressed_messages = []
for content in result.preserved_chunks:
original = next((m for m in messages if m.get("content") == content), None)
if original:
compressed_messages.append(original)
return compressed_messages
def _record_usage(self, session_id: str, user_id: str, project_id: str, model: str, token_count: TokenCount, cost: Any, was_compressed: bool, success: bool, start_time: float):
if not self.usage_tracker:
return
scope = BudgetScope("session", session_id)
if self.config.enable_budget_control:
self.budget_controller.record_usage(scope, token_count.total_tokens, cost.total_cost)
self.usage_tracker.record_usage(
session_id=session_id, project_id=project_id, user_id=user_id,
input_tokens=token_count.input_tokens, output_tokens=token_count.output_tokens,
model=model, provider="openai" if "gpt" in model else "anthropic",
context_compressed=was_compressed, success=success, latency_ms=(time.time() - start_time) * 1000,
)
def _handle_cache_hit(self, result_id: str, session_id: str, user_id: str, project_id: str, token_count: TokenCount, cached_response: Any, cache_key: str, cache_level: CacheLevel, start_time: float) -> RequestResult:
if self.usage_tracker:
self.usage_tracker.record_usage(
session_id=session_id, project_id=project_id, user_id=user_id,
input_tokens=token_count.input_tokens, output_tokens=token_count.output_tokens,
model=cached_response.get("model", "unknown"), provider="openai",
cached=True, success=True,
)
return RequestResult(
result_id=result_id, success=True, model=cached_response.get("model", "unknown"),
messages=[], response=cached_response, token_count=token_count,
cost=CostEstimate(input_cost=0, output_cost=0, total_cost=0),
cache_hit=True, cache_level=cache_level.value, was_compressed=False,
budget_statuses=[], model_selection_metadata={}, latency_ms=(time.time() - start_time) * 1000,
)
def _handle_budget_warning(self, scope: BudgetScope, status: BudgetStatus):
if self._on_budget_warning:
self._on_budget_warning(scope, status)
def _handle_budget_critical(self, scope: BudgetScope, status: BudgetStatus):
if self._on_budget_warning:
self._on_budget_warning(scope, status)
def _handle_budget_exceeded(self, scope: BudgetScope, status: BudgetStatus):
if self._on_error:
self._on_error(f"Budget exceeded: {status.limit_name}")
def _handle_budget_exceeded_result(self, result_id: str, scope: BudgetScope, statuses: List[BudgetStatus], action: Optional[BudgetAction], start_time: float) -> RequestResult:
return RequestResult(
result_id=result_id, success=False,
error=f"Budget exceeded: {statuses[0].limit_name if statuses else 'unknown'}",
error_code="BUDGET_EXCEEDED", budget_statuses=statuses, latency_ms=(time.time() - start_time) * 1000,
)
def _handle_error(self, result_id: str, session_id: str, error: Exception, start_time: float) -> RequestResult:
if self._on_error:
self._on_error(str(error))
return RequestResult(
result_id=result_id, success=False, error=str(error),
error_code="INTERNAL_ERROR", latency_ms=(time.time() - start_time) * 1000,
)
def get_session_stats(self, session_id: str) -> Optional[Dict]:
if not self.usage_tracker:
return None
stats = self.usage_tracker.get_session_stats(session_id)
return stats.to_dict() if stats else None
def get_project_stats(self, project_id: str, days: int = 7) -> Optional[Dict]:
if not self.usage_tracker:
return None
period_start = datetime.now() - timedelta(days=days)
stats = self.usage_tracker.get_project_stats(project_id, period_start)
if not stats:
return None
return {
"project_id": stats.project_id, "total_cost_usd": stats.total_cost,
"total_tokens": stats.total_input_tokens + stats.total_output_tokens,
"total_requests": stats.total_requests, "user_count": stats.user_count,
"model_distribution": stats.model_distribution,
"cache_savings_cost": stats.cache_savings_cost,
"compression_savings_cost": stats.compression_savings_cost,
}
def get_cache_stats(self) -> Optional[Dict]:
if not self.cache_manager:
return None
stats = self.cache_manager.get_stats()
return {
"exact": {"hits": stats["exact"].hits, "misses": stats["exact"].misses, "hit_rate": stats["exact"].hit_rate, "tokens_saved": stats["exact"].tokens_saved, "cost_saved": stats["exact"].cost_saved},
"semantic": {"hits": stats["semantic"].hits, "misses": stats["semantic"].misses, "hit_rate": stats["semantic"].hit_rate, "tokens_saved": stats["semantic"].tokens_saved, "cost_saved": stats["semantic"].cost_saved},
}
def get_budget_status(self, scope: BudgetScope) -> List[Dict]:
statuses = self.budget_controller.get_status(scope)
return [{"limit_name": s.limit_name, "current_value": s.current_value, "limit_value": s.limit_value, "usage_percent": s.usage_percent, "remaining": s.remaining, "period_remaining_seconds": s.period_remaining_seconds, "status": s.status} for s in statuses]
def reset_budget(self, scope: BudgetScope):
self.budget_controller.reset_budget(scope)
def clear_cache(self):
if self.cache_manager:
self.cache_manager.exact_cache.clear()
self.cache_manager.semantic_cache.clear()
def create_token_runtime(
default_model: str = "gpt-4o",
daily_token_limit: int = 1_000_000,
monthly_cost_limit: float = 100.0,
enable_cache: bool = True,
enable_compression: bool = True,
) -> TokenRuntime:
"""创建Token Runtime实例的便捷函数"""
config = TokenRuntimeConfig()
config.default_model = default_model
config.default_daily_token_limit = daily_token_limit
config.default_monthly_cost_limit = monthly_cost_limit
config.enable_cache = enable_cache
config.enable_compression = enable_compression
return TokenRuntime(config)8.3 使用示例
# example_usage.py
"""Token Runtime 使用示例"""
def main():
runtime = create_token_runtime(
default_model="gpt-4o",
daily_token_limit=500_000,
monthly_cost_limit=50.0,
)
runtime._on_budget_warning = lambda scope, s: print(f"[警告] 预算 {s.limit_name} 已使用 {s.usage_percent:.1f}%")
runtime._on_error = lambda err: print(f"[错误] {err}")
session_id = "session_001"
user_id = "user_hos"
project_id = "project_ai_ide"
session_scope = BudgetScope("session", session_id)
runtime.budget_controller.add_limit(
session_scope,
BudgetLimit(name="session_tokens", limit_value=100_000, period=BudgetPeriod.TOTAL, metric="tokens", action=BudgetAction.DEGRADE),
)
messages = [
{"role": "system", "content": "你是一个专业的代码助手。"},
{"role": "user", "content": "请帮我写一个Python函数,计算斐波那契数列第n项。"},
]
result = runtime.process_request(
messages=messages, user_id=user_id, project_id=project_id, session_id=session_id,
)
if result.success:
print(f"✓ 请求成功")
print(f" 模型: {result.model}")
print(f" Token消耗: {result.token_count.total_tokens}")
print(f" 成本: ${result.cost.total_cost:.6f}")
print(f" 延迟: {result.latency_ms:.2f}ms")
if result.cache_hit:
print(f" 缓存命中: ✓ ({result.cache_level})")
if result.was_compressed:
print(f" 上下文压缩: ✓")
else:
print(f"✗ 请求失败: {result.error}")
print(f" 错误码: {result.error_code}")
print("\n=== 统计信息 ===")
session_stats = runtime.get_session_stats(session_id)
if session_stats:
print(f"会话统计:")
print(f" 请求数: {session_stats['total_requests']}")
print(f" 总Token: {session_stats['total_input_tokens'] + session_stats['total_output_tokens']}")
print(f" 总成本: ${session_stats['total_cost_usd']:.4f}")
cache_stats = runtime.get_cache_stats()
if cache_stats:
print(f"\n缓存统计:")
print(f" 精确缓存命中率: {cache_stats['exact']['hit_rate']:.1%}")
print(f" 节省成本: ${cache_stats['exact']['cost_saved'] + cache_stats['semantic']['cost_saved']:.4f}")
budget_status = runtime.get_budget_status(session_scope)
if budget_status:
print(f"\n预算状态:")
for status in budget_status:
print(f" {status['limit_name']}: {status['usage_percent']:.1f}%")
if __name__ == "__main__":
main()9 总结与展望
本文系统性地讲解了Token Runtime的设计与实现,涵盖了以下核心模块:
9.1 核心能力总结
模块 | 核心功能 | 关键价值 |
|---|---|---|
Token计数 | 跨平台Token计数、成本估算 | 精确计量,避免账单惊喜 |
使用量追踪 | 多维度统计、趋势分析、异常检测 | 数据驱动的成本优化 |
预算控制 | 多层次预算限制、智能降级 | 成本可控,风险可管 |
上下文压缩 | 选择性遗忘、增量更新 | 有限窗口最大化利用 |
缓存策略 | 精确缓存、语义缓存、增量缓存 | 减少重复计算,节省成本 |
模型选择 | 任务分析、智能路由 | 成本效益最优匹配 |
9.2 架构设计原则
- 分层解耦:各模块独立可替换,便于单独优化
- 策略模式:支持多种压缩、缓存、选择策略的灵活切换
- 回调机制:关键事件可观测,便于监控告警
- 线程安全:支持高并发场景
9.3 未来演进方向
- 智能化增强
- 基于强化学习的自适应压缩策略
- 更精准的任务复杂度预测
- 用户习惯学习与个性化路由
- 多模态扩展
- 图像Token的计量与优化
- 音视频内容的上下文管理
- 跨模态缓存策略
- 成本优化创新
- 分布式缓存与成本分摊
- 实时竞价与模型协商
- 碳排放追踪与绿色计算
参考链接:
- 主要来源:OpenAI API Pricing - OpenAI官方API定价页面,提供各模型的实时定价信息
- 主要来源:Anthropic Claude Pricing - Anthropic官方API定价页面
- 主要来源:Tiktoken - Fast OpenAI Tokenizer - OpenAI官方BPE分词器实现
- 主要来源:Google Gemini API Pricing - Google Gemini API定价
附录(Appendix):
Token管理完整代码
以下是本文涉及的所有核心模块的完整代码整合,可直接用于生产环境:
# token_runtime_complete.py
"""
Token Runtime 完整实现
包含所有核心模块:Token计数、预算控制、缓存、压缩、模型选择
整合自本文各章节的实现代码
"""
# 完整代码整合需要导入所有章节定义的类和函数
# 实际使用时请整合前文所有代码模块
# ==================== 核心组件 ====================
# - TokenCounter: 跨平台Token计数
# - CostCalculator: 成本估算
# - UsageTracker: 使用量追踪
# - BudgetController: 预算控制
# - CacheManager: 缓存管理
# - ContextCompressor / TruncationCompressor / SelectiveForgetCompressor: 上下文压缩
# - ModelSelector / TaskAnalyzer: 模型选择
# - TokenRuntime: 统一管理器
# ==================== 使用方式 ====================
# 1. 创建Token Runtime实例
# runtime = create_token_runtime(
# default_model="gpt-4o",
# daily_token_limit=500_000,
# monthly_cost_limit=50.0,
# )
#
# 2. 处理AI请求
# result = runtime.process_request(
# messages=[{"role": "user", "content": "Hello!"}],
# user_id="user_001",
# project_id="project_001",
# session_id="session_001",
# )
#
# 3. 获取统计信息
# stats = runtime.get_session_stats("session_001")
# cache_stats = runtime.get_cache_stats()
# budget_status = runtime.get_budget_status(scope)
print("Token Runtime Complete - 完整代码请参见本文各章节实现")关键词: Token Runtime, AI IDE, 成本控制, 性能优化, 预算管理, 上下文压缩, 缓存策略, 模型选择, Token计数, 使用量追踪
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-05-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号