IM分布式架构系列(05) 消息丢了吗 | at least once生产实践
原创
IM分布式架构系列(05) 消息丢了吗 | at least once生产实践
原创
拉丁解牛说技术
发布于 2026-05-27 19:18:09
发布于 2026-05-27 19:18:09
读书笔记:马斯克说过,"如果有什么事情足够重要,即便胜算不大,也要去做。"
费曼:"如果你不能用简单的语言解释一件事,说明你自己也没真懂。"
一、消息可靠投递的生产问题
1.1 一条消息要穿过几道险关
1.2 消息可靠性的三个真实故障形态
二、IM 消息可靠投递的关键设计
2.1 可靠投递的可验证目标
2.2 三层 ACK 的责任边界
2.3 客户端的本地暂存与阶梯重试
2.4 服务端的"落盘后 ACK"与 MQ 兜底
2.5 全局唯一 msgId 与幂等去重
2.6 在线离线切换的"丢消息窗口"
2.7 可靠投递的端到端骨架
三、大厂如何设计
3.1 闲某鱼从 95% 到 99.9% 的治理路径
3.2 融某云的上下行拆分与重发模型
3.3 某钉 DTIM 的全局唯一 ID 与同步通道
3.4 三家方案的横向对比
四、如何优化提升
4.1 投递语义的硬决策
4.2 漏消息检测要主动跑
4.3 重试节奏的反共识
4.4 死信不是终点是流程
4.5 可观测先于可靠
一、消息可靠投递的生产问题
老板拍桌:"昨天客户说他发的消息我们没收到,赔了 5 万。"产品经理来找你:"消息会丢?不是有 ACK 吗?"你查日志翻三小时:消息确实到了服务端,MQ 也消费成功了——但客户端从头到尾没收到那条消息。继续查:用户当时在地铁里长连接闪断,服务端推了一次没人收,然后就没有然后了。
“宁可慢点,也不能丢”“就算重发,也不能重复”这些话听着像废话,实际是 IM 所有可靠投递设计的总纲。我们做可靠投递,第一反应几乎都是加 ACK——这话不算错,但落地时 ACK 加在哪一层、什么时机发、超时怎么办,每个细节都决定一条消息是不是真的能"到家"。
1.1 一条消息要穿过几道险关
一条聊天消息从发送方按下"发送"到接收方屏幕亮起,最少要穿过这些环节:
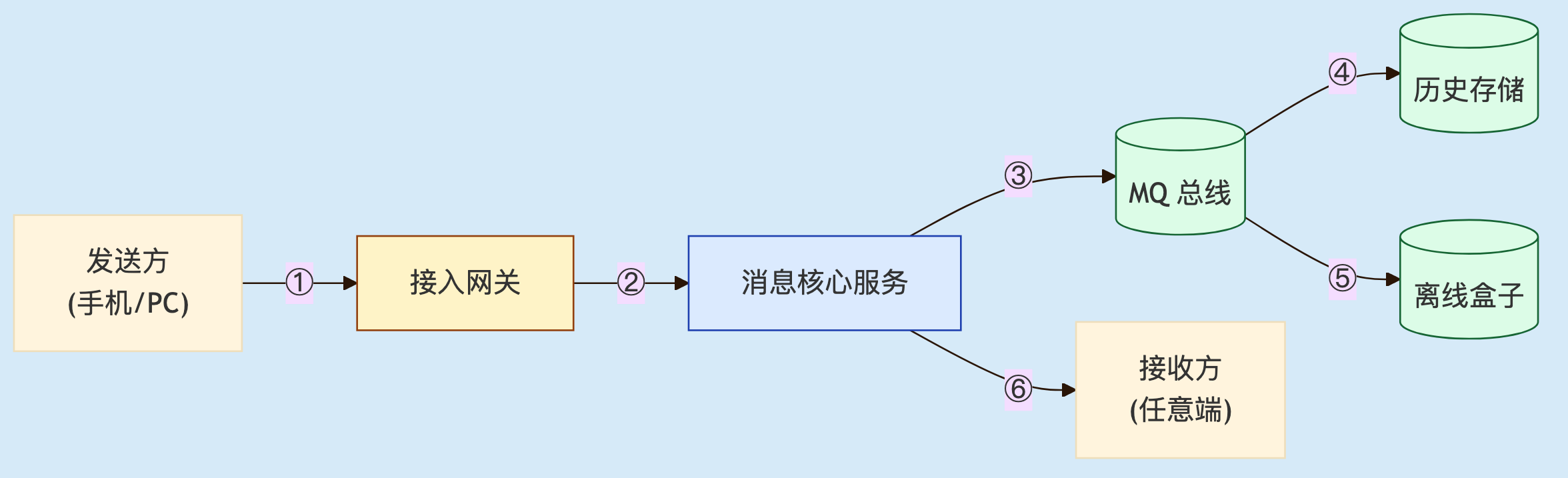
1
图 1. 一条消息的最短链路。每一道箭头都是一个可能丢失或重复的点。
每条箭头都可能出问题:
① 客户端闪断没发出去;
② 网关收到但还没扔进核心服务就 crash;
③ MQ 写盘但还没刷盘就掉电;
④ MQ 消费者抛异常被吃掉没落库;
⑤ 离线盒子写失败接收方上线就漏;
⑥ 推送时长连接已死但服务端还以为它活着。
ACK 只能解决某一段的可靠,不能解决整条链路的可靠——这就是"加个 ACK 就完事"的天真。把每段可靠拼起来,才是可靠投递设计的实质。
1.2 消息可靠性的三个真实故障形态
用户口中的"消息丢了",通常不是真丢,而是落在某个用户看不到的角落——服务端有对方没有,或反过来。三种典型形态:
故障形态 | 表现 | 根因 |
|---|---|---|
真丢 | 双方都没这条消息 | 网关吃异常 / MQ 消费失败被吞 / 推送时离线但未落离线盒子 |
半丢 | 发送方"已发送"、接收方没有 | 服务端落盘前就回 ACK / 弱网推送失败但不重投 |
假丢 | 双方都有,接收方界面没显示 | 客户端落库失败但已回 ACK / 多端不同步 |
消息可靠一旦做不好,产品的信任前提就破了——用户不会排查"真丢还是假丢",他们只会得出"这个 IM 不能用"。
消息的可靠投递,毫无疑问就是IM的命脉。
二、IM 消息可靠投递的关键设计
2.1 可靠投递的可验证目标
要做到消息可靠,从产品体验和技术架构上至少达到几个目标:
- 不丢:任何一条用户已发出的消息,必须最终送达所有应收的接收方设备,允许延迟,不允许永久丢失。
- 不重:at-least-once 下接收方可能多次收到同一条消息,但客户端展示给用户的必须是一次。
- 可追责:链路任一段出问题,能定位是哪一段,而不是只能说"消息丢了"。
- 故障可降级:MQ 抖动 / Redis 故障 / 推送全挂时,系统能退到慢但仍能投递的状态,不全面雪崩。
2.2 三层 ACK 的责任边界
IM 里只加一层 ACK 不够,要加三层——每层只解决自己那段的可靠,合起来才是端到端可靠:
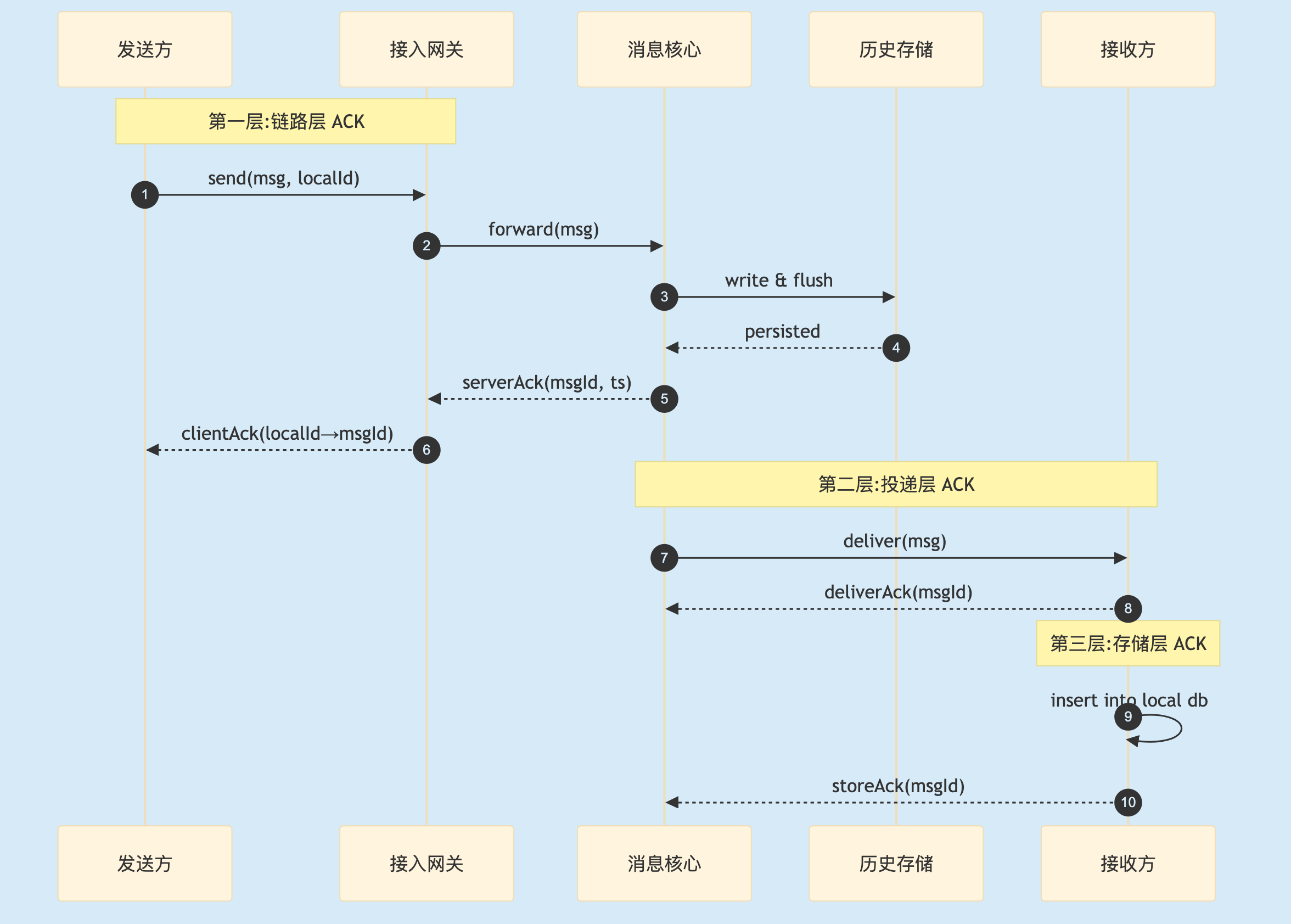
2
图 2. 三层 ACK 各管各的:链路保"服务端收到了",投递保"接收方拿到了",存储保"接收方本地不会丢"。
三层 ACK 的边界要分清:
- 第一层链路 ACK:发送方到服务端,语义"服务端已经持久化"。绝不能内存收到就回,必须等 MQ / 历史存储落盘成功,否则是"虚假确认";
- 第二层投递 ACK:服务端到接收方,语义"接收方设备收到了"。超时不回 → 重投或转写离线盒子;
- 第三层存储 ACK:接收方写入本地 DB 后再回,语义"接收方本地不会丢"。多数项目省了这层,代价是客户端 crash 时窗口内消息会丢;
第三层大家容易忽略,尤其是服务端开发——很多项目只做前两层就上线。但业务对"消息一定要送达"的要求强一点(toB 协作、客服、订单通知),第三层迟早要补上。
2.3 客户端的本地暂存与阶梯重试
发送方点击"发送"那一刻消息只在内存里——这是最脆弱的瞬间。我们的经验是:发送动作必须先落本地数据库,再发起网络请求。
on_user_send(msg):
msg.localId = uuid()
msg.status = SENDING
local_db.insert(msg) // 关键:必须先落库,后发网络
network.send_async(msg, on_ack, on_timeout)
on_ack(localId, msgId, ts):
local_db.update(localId, status=SENT, msgId=msgId, ts=ts)
on_timeout(localId):
msg = local_db.get(localId)
if msg.retry_count < MAX_RETRY:
schedule_retry(msg, backoff(++msg.retry_count))
else:
local_db.update(localId, status=FAILED)这个很朴素却能挡掉三类故障:App 崩溃 / 手机重启、网络闪断、服务端瞬时 5xx——下次打开把 SENDING 状态消息捞出来重发。只有第一层 ACK 明确回来才改 SENT。收不到 ACK 就当没发成功,是客户端可靠的核心。
重试要走阶梯 backoff——实践中常见的一种参考序列是 1s → 3s → 7s → 15s → 30s,3~5 次失败标 FAILED 让用户手动重发,不要无限重试。无限重试在弱网恢复时会引发雪崩——几百万设备同时把堆积消息扔回,网关瞬间被打满。--这是真实生产bug,移动端1s上百次的重试,前天放假期间,还含泪查了1天,哭晕。
2.4 服务端的"落盘后 ACK"与 MQ 兜底
服务端收到消息绝不能直接 ACK——必须等消息真正持久化。落盘前回 ACK 是 IM 最常见的"伪可靠":发送方以为发成功了,服务端一掉电消息就没了。
on_recv_from_client(msg, channel):
msg.id = id_gen.next()
// 关键:先写 MQ(MQ 内部已刷盘),再回 ACK
mq.send(MSG_ROUTE_TOPIC, msg).waitForBrokerAck()
channel.write(serverAck(msg.localId, msg.id, msg.ts))历史存储和扇出都是 MQ 消费者的工作。整套是典型 at-least-once:MQ 投递保证 ≥1 次;
消费失败 → MQ 重试 → 死信,由补偿任务每小时重投。
服务端还要警惕异常吞噬:MQ 消费回调里 catch (Throwable t) { log.error(...) } 默默吃异常返回 SUCCESS——这一行能把整条链路废掉。消费回调必须区分可重试与不可重试错误:DB / Redis 瞬时错返回 RECONSUME_LATER 让 MQ 重投;参数错误主动扔死信而非堵队列。
2.5 全局唯一 msgId 与幂等去重
at-least-once + 重试 = 必然重复。处理思路有两种:
- 被动——接收方按 msgId 去重,客户端入库前查本地;
- 主动——服务端按业务键去重,处理前抢锁(
SETNX msgId 1 EX 86400)。
两层都要做:漏客户端去重死信补投会让用户看到两条"在吗?",漏服务端去重客户端重发会让发送方出现两条相同 msgId 的"已发送"。
这里的关键是 msgId 全局唯一。很多项目初版用 (sessionId + seq + version) 三元组凑唯一,业务跑起来才发现:多端发送、网络重传、跨服务器 forward 时三元组会冲突,导致"消息看似进来了实际丢一条+多一条重复"。这是闲鱼治理实践遇到的坑。
方案 | 优势 | 代价 |
|---|---|---|
UUID v4 | 客户端能生成,无中心依赖 | 32 字节、无序、DB 索引差 |
雪花算法 | 64 位有序,DB 友好 | workerId 唯一性、时钟回拨 |
中心化发号器 | 全局严格有序、会话内单调 | 单点,需高可用 |
UUID 在大多数中等规模 IM 项目里够用——真到要求会话内严格单调时再考虑发号器。不要为"未来扩展"提前上发号器——它的运维复杂度远超它能解决的问题。判重键常做组合 (senderUid, msgId, action),"发送"和"撤回"是不同 action,不能因 msgId 相同就把撤回判成重复的发送丢掉。
2.6 在线离线切换的"丢消息窗口"
最隐蔽的丢消息窗口是在线离线切换:B 在线 Redis 状态 ONLINE;B 进地铁 TCP 半死;服务端看 ONLINE 直接推送;推送超时但服务端不知道 B 已断;B 出地铁重连拉离线——离线盒子里没有那条,因为它被算作"在线投递"了。
经典的"在线状态判断滞后"丢消息。处理思路有三:
- 推送失败回写离线盒子:第二层 ACK 超时后追加到离线盒子,代价是离线盒子写入压力增加
- 上线时按 lastReadSeq 增量拉:重连后拉"我离线期间所有发给我的消息",代价是要维护每会话连续 seq
- 推拉结合:服务端只发通知,客户端收到通知后主动拉,通知丢了有定时拉兜底
中等规模项目通常 1+2 组合。定时拉取特别值得做——客户端收到最后一条消息后启动 3~5 分钟周期定时器,即使长连接活着也定期主动拉,专门防"长连接看上去好的但实际已死"的半死状态。代价是一点流量,收益是把丢消息从被动等投诉变成主动发现并补。
2.7 端到端骨架
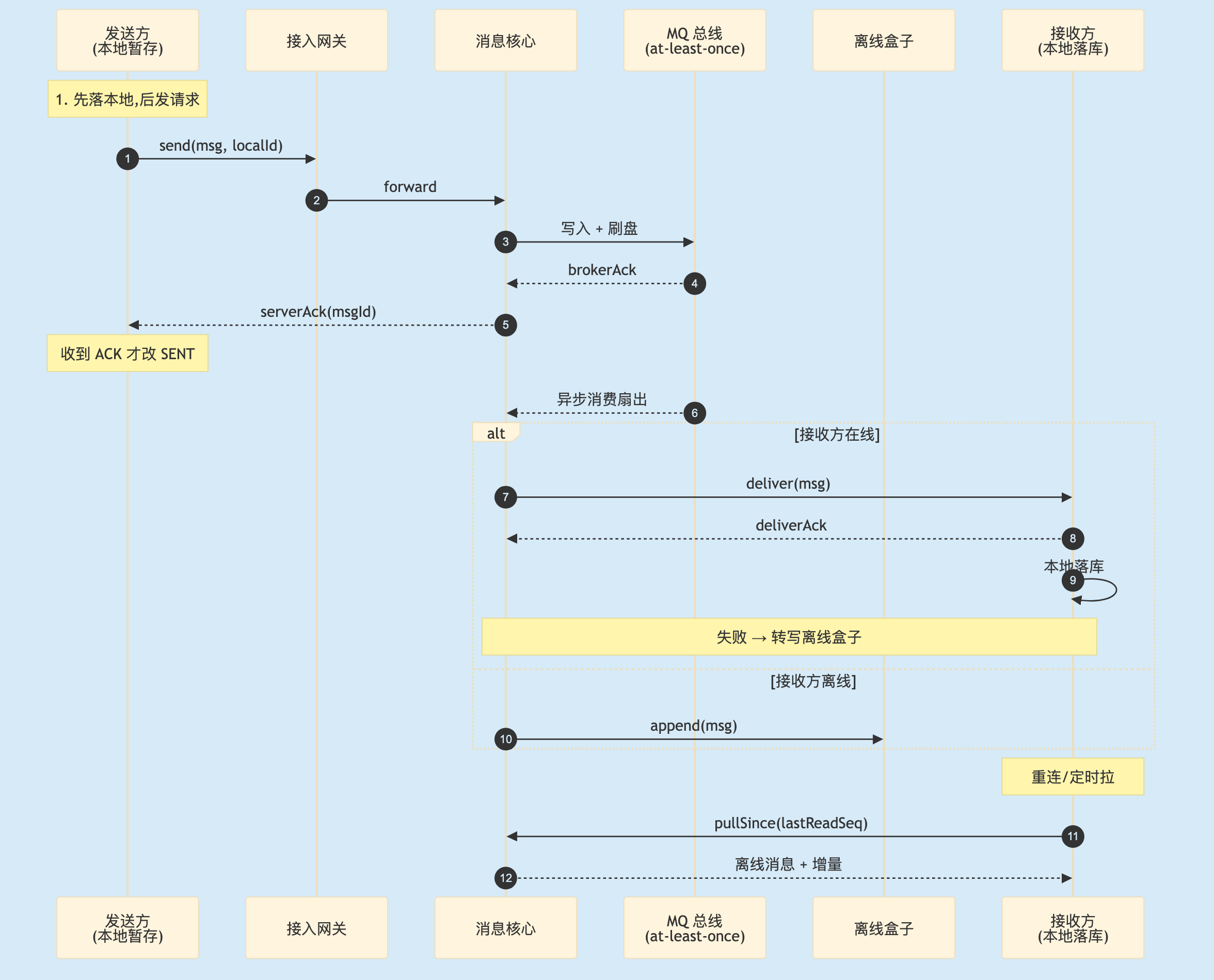
3
图 3. 可靠投递的端到端骨架。5 层防护组合。
消息可靠不是某处的巧设计,是整条链路每段都做了"假设这段会失败"的兜底。任一段不做兜底,整链就破。
三、大厂如何设计
闲某鱼把"消息可靠"从 95% 治到 99.9%,有数据支撑有教训;融某云提供"上下行拆分 + 推拉结合"的协议级模型;某钉 DTIM 走"全局唯一 ID + 同步通道"的高一致路线。
3.1 闲某鱼从 95% 到 99.9% 的治理路径
闲某鱼 IM 团队公开过一段把消息可靠从 95% 治到 99.9% 的实践。早期最大的设计缺陷是没有全局唯一 msgId——靠 (sessionId, seqId, version) 三元组凑唯一,并发发送时会冲突:A 和 B 同时发,服务端 version 递增逻辑会把一条识别成已存在而过滤掉,另一条 version 重复——一条丢、一条重。
治理分两步:改造唯一性——客户端生成 UUID,接收后先按 msgId 去重再按 timestamp 排序;重发重连机制——服务端推送加超时,客户端定时检测长连接联通性。数据治理做了全链路埋点(每跳打点,Flink 清洗到日志服务做端到端追踪)和对账系统(用户离开会话时客户端计算最近 N 条消息的 md5 上报,服务端比对,抽样准确率 99.99%)。最终公开指标:到达率 99.9%。
优势 | 全链路埋点能定位丢点;对账主动发现漏消息;UUID 彻底解决唯一性 |
|---|---|
代价 | UUID 32 字节占用大;埋点引入独立可观测栈;对账抽样不覆盖 100% |
3.2 融某云的上下行拆分与重发模型
融某云的思路是上下行拆分 + 客户端服务端互补。上行段靠自研协议(类 RMTP)的 QoS 和 ACK 保证字节流可靠;客户端通过导航服务按 userId 落到固定接入服务器,同账号的多端连同一台业务服务器让上行排序和多端维护简化。
下行段有三种行为:客户端主动拉(连接建立时拉离线 + 每 3~5 分钟定时拉一次,防长连接半死)、服务端直发消息(适合低频持续交互)、服务端通知拉取(适合高频场景,只发通知,客户端按通知里的时间戳主动拉)。直发和通知之间有状态机切换——上一条消息发送流程没结束,下一条就用通知避免推送阻塞。
优势 | 推拉结合天然挡住"通知丢失"和"长连接半死";同 userId 落同一服务器让排序简化 |
|---|---|
代价 | 长连接调度复杂,需要导航服务;推/拉切换需状态机;客户端定时拉增加少量流量 |
3.3 某钉 DTIM 的全局唯一 ID 与同步通道
某钉 DTIM 走强一致路线。服务端全局维护消息的唯一 ID(不依赖客户端),所有冲突由服务端裁决——这是去重、漫游、多端同步等强一致语义的基础。
同步机制用独立的"数据同步通道":服务端维护用户级 FIFO 位点流,所有给该用户的消息(以及已读 / 撤回等事件)按自增 id 串行入流,客户端按位点增量拉,丢段就重拉,不乱序也不漏事件。代价是同步服务本身要扛高并发,超大账号要做位点拆分避热点。
优势 | 全局唯一 ID 让去重、漫游、多端同步都简化;位点流提供"丢段重拉"的能力 |
|---|---|
代价 | ID 有中心化依赖;位点流对超大账号是单点瓶颈;架构复杂,小团队接不住 |
3.4 三家方案的横向对比
维度 | 闲鱼 | 融某云 | 某钉 DTIM |
|---|---|---|---|
msgId 生成 | 客户端 UUID + 服务端补 | 服务端全局唯一 | 服务端全局唯一 |
上行可靠 | HTTP + 服务端落库后 ACK | 自研协议 QoS + ACK | 长连协议 + ACK |
下行可靠 | 推送 + 重试 + 客户端 ACK | 推拉结合 + 定时拉 | 位点流增量拉 |
去重位置 | 客户端按 msgId | 客户端 + 服务端按 msgId | 服务端按全局 ID |
漏消息检测 | 对账 md5 校验 | 客户端定时拉兜底 | 位点连续性自动检测 |
公开指标 | 到达率 99.9% | 亿级规模可靠投递 | 高一致(无具体数字公开) |
三家的共性:没有一家靠"一次推送 + 一个 ACK"——都至少有客户端兜底、服务端重投、定时拉取 / 对账中的两层。分歧在 ID 体系:UUID 路线改造小但去重前移到客户端,全局 ID 路线强一致但中心化。选哪个看业务一致性强弱和团队工程能力。
四、如何优化提升
4.1 投递语义的硬决策
业务是 at-least-once 够用,还是真需要 exactly-once? 绝大多数 IM 场景 at-least-once + 客户端去重就够了——用户看一条总比两条强。真正需要 exactly-once 的是消息触发的副作用(收到消息扣费 / 发邮件),但这类副作用必须在业务层做幂等,不要指望消息通道自己保证 exactly-once:通道层面的 exactly-once 在分布式环境是伪命题,大厂也不做。
选择at-least-once 后,产品上明确告知"消息可能重复但不会丢失",客户端按 msgId 去重把重复在用户层面变透明。强行追求 exactly-once 会引入两阶段提交,把 MQ 吞吐拉低一个量级,得不偿失。
4.2 漏消息检测要主动跑
可靠投递最难的不是"防丢",是"知道有没有丢"。被动等投诉等到的永远是已经发酵的问题。三个主动检测手段:
- 接收方 seq 空洞监控:服务端发消息带递增 seq,客户端按连续性检查,发现空洞主动上报并补拉
- 对账抽样:用户离开会话时上报最近 N 条消息的 hash,服务端定时比对,差异率超阈值告警
- MQ 死信巡检:每天扫死信条数,超阈值告警并自动尝试补投
可靠投递这块项目的关键指标不是当下到达率(那只是结果),而是有没有能力在不依赖用户投诉的情况下发现退化。
4.3 重试节奏的反共识
重试不是越频越好。我们做重试,第一反应几乎都是固定间隔或线性递增。实践过程中绕不开三个问题:
- 雪崩:断网恢复瞬间几百万设备把堆积消息扔回服务端,网关被打满
- 僵尸消息:无限重试让已过期的消息一直在重投
- 资源浪费:服务端明知投递不出去还在按节奏重试
工程化的做法是指数退避 + 抖动 + 最大重试上限。实践中常见的一种参考:1s → 3s → 7s → 15s → 30s,每步加 0~50% 随机抖动避免同步雪崩,3~5 次失败后落入"发送失败"。关键是「指数增长」和「加抖动」两个原则,间隔设多少取决于用户等待容忍度和服务端恢复速度。
另一个反共识细节:接收端重试和发送端重试要分开调参。发送端是"用户在等"节奏要快(秒级),接收端重投是"用户已不在线"节奏可以慢(分钟级)配合离线盒子兜底。混在一起调两边都不对。
4.4 死信不是终点是流程
死信队列是 at-least-once 链路最被忽视的"终点"。多数项目 MQ 默认 16 次重试失败 → 进死信 → 然后没有然后。等用户投诉时打开控制台,几万条堆在那。
死信要做成流程而不是终点:每天统计死信条数超阈值告警;死信入队打全字段日志便于排查;补偿任务每小时把可重试消息(DB 瞬时错)重投主队列;真正不可重试的(参数错误、格式损坏)留在死信存档定期 review。工程量不大,但是消息可靠从"统计意义 99%"提到"对每条负责 99.99%"的分水岭。
4.5 可观测先于可靠
很多项目把加监控当成可靠投递的最后一步,我们的经验是反过来:可观测要先于可靠。没有指标,所有"提升可靠"都只能凭感觉。最值得先做的三个指标:
- 端到端延迟 P99:发送方按下"发送"到接收方界面亮起的全链路耗时,正常应在 2 秒内
- 服务端落盘成功率:链路 ACK 回前 MQ 写盘的成功率,下降即退化先兆
- 客户端漏消息率:接收方 seq 空洞告警频次,直接反映对账真实情况
消息可靠的取舍,是接受"可能慢、可能重",换"绝对不丢"——反过来追求"绝对不重不慢",可靠就是空中楼阁。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号