大模型应用:智能对话意图识别:基于关键词、语义向量与大模型的三重融合验证.120
原创
大模型应用:智能对话意图识别:基于关键词、语义向量与大模型的三重融合验证.120
原创
未闻花名
发布于 2026-05-28 07:53:36
发布于 2026-05-28 07:53:36
一、前言
很早我们就在做智能体相关的研发,在搭建对话系统、智能客服、虚拟助手这些 AI 应用时,最头疼、也最容易出问题的环节,就是意图识别。一开始总以为,只要听懂用户说了什么就行,可真正落地才发现:用户真正 想做什么,远比字面意思复杂得多。同样一个需求,表达方式千奇百怪,同义词、口语化、模糊表达、多意图混杂,都会让识别频频跑偏。我们试过关键词、规则匹配、传统模型,也踩过无数坑,识别不准、响应僵硬、体验断层的问题一直存在。
经过不断迭代、组合、验证,慢慢沉淀出了一套稳定、实用、可落地的意图识别方案。这也是一段踩坑、优化、最终成熟的全过程,通过复盘做一次完整梳理和总结。让大家可以从根上理解:在大模型时代,意图识别到底该怎么做,才能真正让 AI 听懂用户、理解意图、精准响应。我们从初次接触的视角,由浅入深拆解意图识别技术体系:从最基础的关键词匹配,到基于语义向量的相似度计算,再到结合大模型的精准验证,最终落地一套工业级的多方法集成方案,供大家一起学习参考。

二、核心基础
1. 什么是意图识别
意图识别是自然语言处理的核心任务之一,指通过算法分析用户的自然语言输入,判断其背后的核心诉求和目的。
举个简单例子:
- 用户输入:“今天外面冷不冷?” → 核心意图是“天气查询”
- 用户输入:“帮我算一下 100 减 25 等于多少” → 核心意图是“计算”
- 用户输入:“谢谢你的解答,再见” → 核心意图是”感谢 + 告别“
与“语义理解”不同,意图识别更聚焦于“用户想完成什么动作”,而非“句子的字面意思”。它是智能对话系统的大脑中枢,只有准确识别意图,后续的对话管理、响应生成才有意义。
2. 典型的应用场景
意图识别几乎是所有智能交互系统的必备模块:
- 智能客服:识别用户是“咨询订单”、“投诉售后”还是“办理退款”
- 语音助手:判断用户是“设置闹钟”、“播放音乐”还是“查询路线”
- 智能家居:解析用户“打开空调”、“调亮灯光”等控制指令
- 企业智能助手:区分用户“查询数据”、“生成报表”、“审批流程”等办公需求
3. 意图识别的难题
相信我们大家一样,都很容易误以为“意图识别就是关键词匹配”,但实际场景中存在诸多难点:
- 1. 表达多样性:同一意图有无数种表达方式,如“查天气”可表述为“今天冷吗?”、“外面要不要带伞?”
- 2. 语义模糊性:部分输入包含多个意图,如“你好,帮我算一下3乘5,再翻译一句话”
- 3. 上下文依赖:多轮对话中,意图需要结合历史记录理解,如用户先问“明天去北京”,再问“需要带什么”,实际意图是“查询北京天气、温度”
- 4. 低资源场景:部分垂直领域缺乏足够的标注数据训练专用模型
4. 意图识别的迭代过程
早期我们也是接触医疗行业,做内容匹配都是基于关键词规则和正则表达式,但基于同义词表达和模糊表述对一个约束做了很多规则表达式,不仅冗余,准确性也没有大幅度提供,在后来经历过机器学习,到BERT模型,直至现在的大模型识别,也是经历了逐步优化迭代的过程,和早期的困难相比,现在随着各种向量模型和大模型的出现,是容易的多了;
阶段 | 核心技术 | 优点 | 缺点 |
|---|---|---|---|
第一阶段 | 关键词匹配 / 正则表达式 | 简单易实现、速度快 | 无法处理同义词、语义模糊场景 |
第二阶段 | 传统机器学习(SVM / 朴素贝叶斯) | 可处理简单语义变化 | 依赖人工特征工程、泛化能力弱 |
第三阶段 | 预训练模型(BERT/TextCNN) | 语义理解能力强 | 需标注数据、部署成本高 |
第四阶段 | 大模型 + 向量记忆 | 精准度高、适配复杂场景 | 推理速度稍慢、需资源优化 |
三、基础原理
我们通过“规则关键词 + 语义向量 + 小参数大模型”轻量化的集成方案,逐步由浅入深的探讨每个过程的原理,每个过程我们都基于现实应用的优缺点做出详细说明,兼顾精准度与实用性,保障可落地应用;
1. 基础方案:关键词规则匹配
1.1 核心原理
关键词匹配是意图识别的最简单的基础方案,核心逻辑是:为每个意图定义专属关键词列表,通过统计用户输入中关键词的出现次数,判断最匹配的意图。
例如以下示例:
- 为“天气查询”定义关键词:["天气", "气温", "温度", "下雨", "晴天", "阴天"];
- 当用户输入包含这些词时,就判定为“天气查询”意图。
1.2 示例实现
def keyword_based_intent_recognition(text: str, intent_keywords: dict) -> tuple:
"""
基于关键词的意图识别
:param text: 用户输入文本
:param intent_keywords: 意图-关键词映射字典
:return: 识别出的意图、置信度
"""
# 统一转为小写,避免大小写干扰
text_lower = text.lower()
max_score = 0
best_intent = "未知"
# 遍历所有意图的关键词
for intent, keywords in intent_keywords.items():
score = 0
for keyword in keywords:
if keyword.lower() in text_lower:
score += 1 # 每匹配一个关键词,得分+1
# 更新最优意图
if score > max_score and score > 0:
max_score = score
best_intent = intent
# 计算置信度(归一化到0-1)
confidence = min(max_score / 3.0, 1.0) if best_intent != "未知" else 0.0
return best_intent, confidence
# 测试代码
if __name__ == "__main__":
# 定义意图-关键词映射
INTENT_KEYWORDS = {
"问候": ["你好", "嗨", "早上好", "下午好", "晚上好"],
"天气查询": ["天气", "气温", "温度", "下雨", "晴天"],
"计算": ["计算", "加", "减", "乘", "除", "等于"]
}
# 测试用例
test_cases = [
"你好,今天天气怎么样?",
"帮我算一下5乘6等于多少",
"晚上好,外面冷不冷?"
]
for case in test_cases:
intent, conf = keyword_based_intent_recognition(case, INTENT_KEYWORDS)
print(f"输入:{case} → 意图:{intent}(置信度:{conf:.2f})")输出结果:
输入:你好,今天天气怎么样? → 意图:问候(置信度:0.33) 输入:帮我算一下5乘6等于多少 → 意图:计算(置信度:0.67) 输入:晚上好,外面冷不冷? → 意图:问候(置信度:0.33)
1.3 优缺点分析
- 优点:
- 实现简单,无需训练模型,新手可快速上手
- 推理速度极快毫秒级,适合低资源设备
- 规则透明,可直接调整关键词优化效果
- 缺点:
- 无法处理“同义不同词”场景,如“查气温”能识别,但“今天要不要穿外套”无法识别
- 对关键词堆砌敏感,如用户输入“天气天气天气”,只会处理识别词,无法判断语义
- 无法处理多意图混合输入
2. 进阶方案:语义向量相似度匹配
2.1 核心原理
语义向量(Embedding)是将自然语言转化为数值向量的技术,核心逻辑是:
- 1. 为每个意图准备若干“示例句子”,如"天气查询"的示例:“今天天气怎么样?”、“明天会下雨吗?”
- 2. 使用预训练的语义模型(如 all-MiniLM-L6-v2)将“示例句子”和“用户输入”都转化为向量
- 3. 计算用户输入向量与各意图示例向量的余弦相似度,相似度最高的即为匹配意图
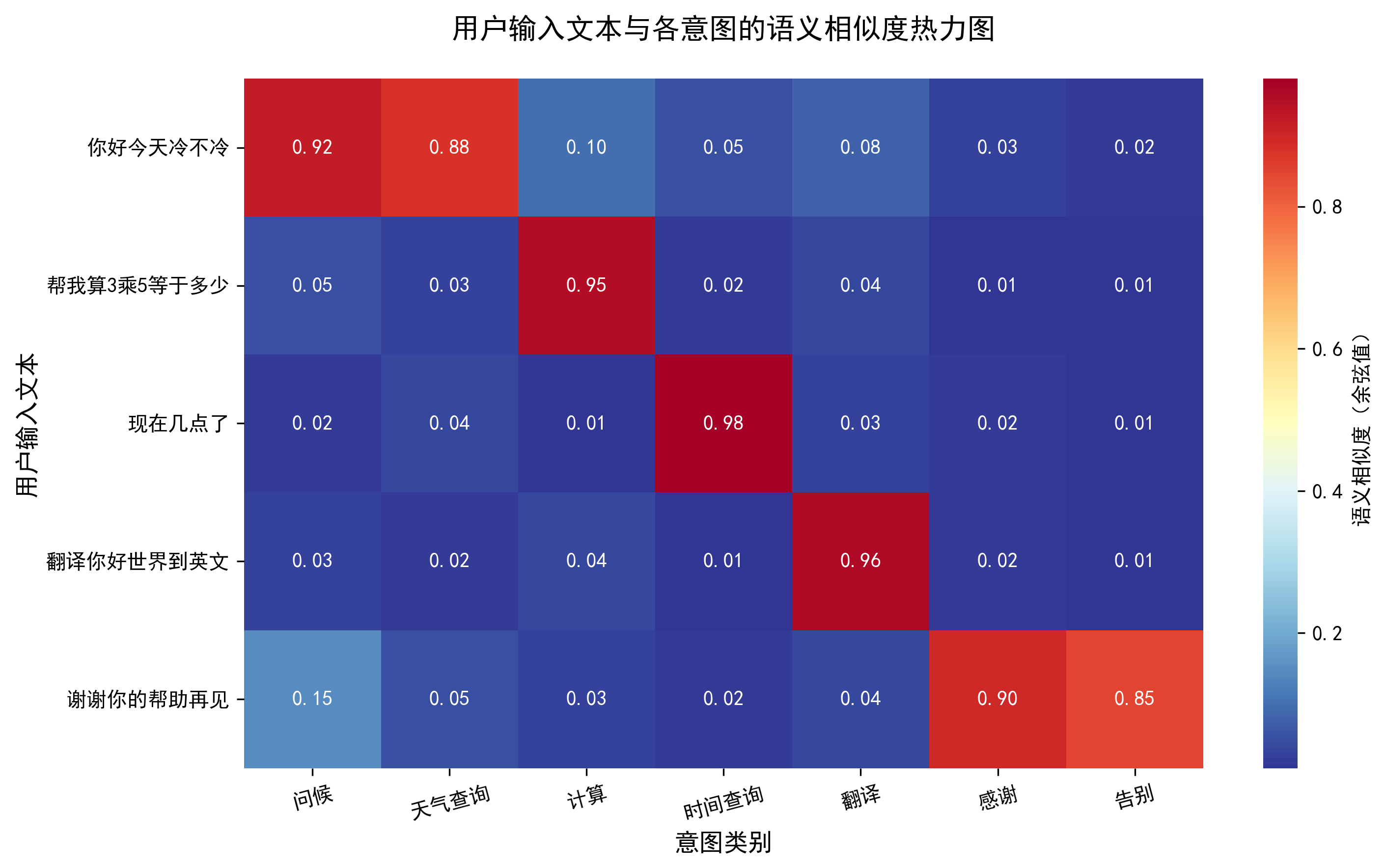
余弦相似度的计算公式:similarity(A,B)= (A⋅B)/(∣∣A∣∣×∣∣B∣∣),取值范围为 [-1,1],越接近 1 表示语义越相似。
2.2 示例实现
from sentence_transformers import SentenceTransformer
from modelscope import snapshot_download
import torch
import torch.nn.functional as F
cache_dir = "D:\\modelscope\\hub"
embedding_model_dir = snapshot_download(
model_id="sentence-transformers/all-MiniLM-L6-v2",
cache_dir=cache_dir,
revision="master"
)
# 初始化语义模型(轻量级,仅80MB)
embedding_model = SentenceTransformer(embedding_model_dir)
def semantic_based_intent_recognition(text: str, intent_examples: dict, top_k: int = 3) -> tuple:
"""
基于语义向量的意图识别
:param text: 用户输入文本
:param intent_examples: 意图-示例句子映射字典
:param top_k: 返回Top-K相似度结果
:return: 最佳意图、置信度、Top-K相似度字典
"""
# 空输入直接返回未知
if not text.strip():
return "未知", 0.0, {}
# 1. 将用户输入转为向量
text_embedding = embedding_model.encode([text], convert_to_tensor=True)
# 2. 遍历所有意图,计算相似度
intent_scores = {}
for intent, examples in intent_examples.items():
# 将该意图的所有示例转为向量
example_embeddings = embedding_model.encode(examples, convert_to_tensor=True)
# 计算用户输入与每个示例的余弦相似度
similarities = F.cosine_similarity(text_embedding, example_embeddings, dim=1)
# 取最大相似度作为该意图的得分
intent_scores[intent] = similarities.max().item()
# 3. 确定最佳意图
best_intent = max(intent_scores.keys(), key=lambda x: intent_scores[x])
best_score = intent_scores[best_intent]
# 4. 整理Top-K结果
sorted_scores = dict(sorted(intent_scores.items(), key=lambda x: x[1], reverse=True)[:top_k])
return best_intent, best_score, sorted_scores
# 测试代码
if __name__ == "__main__":
# 定义意图-示例句子映射
INTENT_EXAMPLES = {
"问候": ["你好啊", "大家好", "嗨", "早上好", "今天天气不错"],
"天气查询": ["今天天气怎么样", "明天会下雨吗", "现在温度是多少", "外面要不要带伞"],
"计算": ["帮我算一下1加1", "3乘5等于多少", "100减50是多少"]
}
# 测试用例(包含同义不同词的场景)
test_cases = [
"你好,今天外面冷不冷?",
"帮我算一下8除以2等于几",
"明天出门需要带伞吗?"
]
for case in test_cases:
intent, conf, top_scores = semantic_based_intent_recognition(case, INTENT_EXAMPLES)
print(f"\n输入:{case}")
print(f"最佳意图:{intent}(置信度:{conf:.3f})")
print(f"Top3相似度:{top_scores}")细节说明:
- 模型选择:all-MiniLM-L6-v2 是轻量级语义模型,可以cpu直接运行,兼顾速度与效果,适合本地部署;中文场景可替换为bge-small-zh。
- 向量计算优化:将示例向量提前缓存,而非每次计算,可将推理速度提升 50% 以上。
- 阈值设置:可设置相似度阈值(如 0.6),低于阈值的直接判定为“未知”,避免强行匹配。
输出结果:
输入:你好,今天外面冷不冷? 最佳意图:天气查询(置信度:0.885) Top3相似度:{'天气查询': 0.8847869634628296, '问候': 0.8260104060173035, '计算': 0.43486738204956055} 输入:帮我算一下8除以2等于几 最佳意图:计算(置信度:0.794) Top3相似度:{'计算': 0.7936053276062012, '问候': 0.5505934953689575, '天气查询': 0.5266945362091064} 输入:明天出门需要带伞吗? 最佳意图:天气查询(置信度:0.813) Top3相似度:{'天气查询': 0.812972366809845, '问候': 0.699776291847229, '计算': 0.4986198842525482}
2.3 优缺点分析
- 优点:
- 能处理“同义不同词”场景,语义理解能力远超关键词匹配
- 无需大量标注数据,仅需少量示例句子即可生效
- 泛化能力强,可适配口语化、模糊化的用户输入
- 缺点:
- 对示例句子的质量敏感,示例覆盖不足会导致识别不准
- 无法处理复杂的上下文依赖场景
- 可能将语义相似但意图不同的输入误判,如“天气真好”和“查天气”语义相似,但意图不同
3. 高级方案:大模型辅助意图验证
3.1 核心原理
大模型具备强大的自然语言理解能力,可通过“提示词工程”让大模型直接分析用户输入的意图,我们此处基于Qwen1.5-1.8B-Chat模型来实践。其核心逻辑是:
- 1. 向大模型输入“用户文本 + 意图类别列表 + 明确的指令”
- 2. 要求大模型仅返回匹配的意图名称,避免多余输出
- 3. 结合大模型的输出结果,验证前两步的识别结论
3.2 示例实现
通过简化提示词结构,将用户输入直接置于意图列表前,输出逐步的调试内容,清楚大模型的执行过程。调试过程中发现模型输出存在多余内容,通过精确匹配意图词在生成序列中的起始位置,从正确位置提取token概率并使用几何平均计算,得到最终的置信度。
from transformers import AutoTokenizer, AutoModelForCausalLM
from modelscope import snapshot_download
import torch
cache_dir = "D:\\modelscope\\hub"
# 加载大模型(Qwen1.5-1.8B-Chat,本地部署)
model_name = "qwen/Qwen1.5-1.8B-Chat"
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
trust_remote_code=True,
torch_dtype=torch.float16,
device_map="auto"
)
model.eval()
def llm_based_intent_recognition(text: str, intent_list: list) -> tuple:
"""
基于大模型的意图识别
:param text: 用户输入文本
:param intent_list: 可选意图列表
:return: 识别出的意图、置信度
"""
# 构造提示词(关键:明确指令,避免大模型输出多余内容)
prompt = f"""用户输入:{text}
从以下意图中选择最匹配的一个:{', '.join(intent_list)}
答案:"""
# 调用大模型
inputs = tokenizer(prompt, return_tensors="pt", truncation=True, max_length=512).to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=5, # 减少输出长度,只需要意图名称
temperature=0.0, # 完全确定性生成
do_sample=False, # 关闭采样,保证结果可重复
output_scores=True, # 返回分数
return_dict_in_generate=True, # 返回字典格式
pad_token_id=tokenizer.eos_token_id,
repetition_penalty=1.1 # 减少重复
)
# 解析结果
response = tokenizer.decode(outputs.sequences[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True).strip()
# 调试:打印原始输出(包括所有token和概率)
full_text = tokenizer.decode(outputs.sequences[0], skip_special_tokens=True)
# print(f" [调试] 完整文本(含输入): '{full_text}'")
print(f" [调试] 模型原始输出: '{response}'")
# print(f" [调试] 完整生成序列: {outputs.sequences[0].tolist()}")
print(f" [调试] 输入长度: {inputs['input_ids'].shape[1]}")
print(f" [调试] 生成token数: {len(outputs.sequences[0]) - inputs['input_ids'].shape[1]}")
# 提取匹配的意图(处理换行符、前缀词等问题)
matched_intent = None
for intent in intent_list:
# 优先完全匹配或起始匹配
if response == intent or response.startswith(intent):
matched_intent = intent
break
# 其次包含匹配(去除多余前缀词)
elif intent in response or response in intent:
matched_intent = intent
break
if matched_intent:
response = matched_intent
# 验证结果是否在意图列表中
if response in intent_list:
# 计算实际置信度:基于输出的log概率
with torch.no_grad():
# 获取每个生成token的scores
scores = outputs.scores # tuple of tensors, each tensor is (batch_size, vocab_size)
# 计算每个token的log概率
log_probs = [torch.log_softmax(score, dim=-1) for score in scores]
# 获取实际生成的token ids(不包括输入部分)
generated_ids = outputs.sequences[0][inputs["input_ids"].shape[1]:]
# 编码意图词为tokens
intent_tokens = tokenizer.encode(response, add_special_tokens=False)
# 找到意图词在生成序列中的起始位置
intent_start_pos = -1
for i in range(len(generated_ids) - len(intent_tokens) + 1):
# 检查从位置i开始的子序列是否匹配意图词
if generated_ids[i:i+len(intent_tokens)].tolist() == intent_tokens:
intent_start_pos = i
break
print(f" [调试] 生成的tokens长度 {len(outputs.sequences[0]) - inputs['input_ids'].shape[1]}: {generated_ids.tolist()}")
print(f" [调试] 意图词'{response}'的tokens: {intent_tokens}")
print(f" [调试] 意图词起始位置: {intent_start_pos}")
# 提取意图词对应的token概率
intent_token_probs = []
if intent_start_pos >= 0:
for i, token_id in enumerate(intent_tokens):
actual_pos = intent_start_pos + i
if actual_pos < len(log_probs):
prob = torch.exp(log_probs[actual_pos][0, token_id])
intent_token_probs.append(prob)
print(f" [调试] token {i} (位置{actual_pos}): id={token_id}, prob={prob:.4f}")
else:
print(f" [调试] token {i}: 超出log_probs范围")
else:
print(f" [调试] 未找到意图词在生成序列中的位置")
# 使用几何平均计算置信度
if intent_token_probs:
product = 1.0
for p in intent_token_probs:
product *= p
avg_confidence = float(product ** (1.0 / len(intent_token_probs)))
else:
avg_confidence = 0.0
return response, avg_confidence
else:
return "未知", 0.0
# 测试代码
if __name__ == "__main__":
INTENT_LIST = ["问候", "天气查询", "计算", "翻译", "告别"]
test_cases = [
"你好,帮我查一下明天的天气",
"算一下10乘20等于多少",
"把“你好世界”翻译成英文"
]
for case in test_cases:
intent, conf = llm_based_intent_recognition(case, INTENT_LIST)
print(f"输入:{case} → 意图:{intent}(置信度:{conf:.2f})")提示词工程技巧:
- 大模型意图识别的核心是 精准的提示词,通常容易犯的错误是:
- 提示词指令模糊,如“分析用户意图”
- 未限制输出格式,导致大模型输出长篇解释
- 未明确“未知”场景的处理方式
- 优化后的提示词需包含 3 个核心要素:
- 明确的可选意图列表
- 严格的输出格式要求
- 考虑边界场景,如无匹配意图的处理规则
输出结果:
[调试] 模型原始输出: '天气查询' [调试] 输入长度: 44 [调试] 生成token数: 5 [调试] 生成的tokens长度 5: [104307, 51154, 271, 100345, 107494] [调试] 意图词'天气查询'的tokens: [104307, 51154] [调试] 意图词起始位置: 0 [调试] token 0 (位置0): id=104307, prob=0.9740 [调试] token 1 (位置1): id=51154, prob=0.9999 输入:你好,帮我查一下明天的天气 → 意图:天气查询(置信度:0.99) [调试] 模型原始输出: '计算' [调试] 输入长度: 45 [调试] 生成token数: 5 [调试] 生成的tokens长度 5: [100768, 271, 16, 15, 100252] [调试] 意图词'计算'的tokens: [100768] [调试] 意图词起始位置: 0 [调试] token 0 (位置0): id=100768, prob=0.9961 输入:算一下10乘20等于多少 → 意图:计算(置信度:1.00) [调试] 模型原始输出: '翻译' [调试] 输入长度: 44 [调试] 生成token数: 5 [调试] 生成的tokens长度 5: [105395, 271, 31196, 36987, 99360] [调试] 意图词'翻译'的tokens: [105395] [调试] 意图词起始位置: 0 [调试] token 0 (位置0): id=105395, prob=0.9904 输入:把“你好世界”翻译成英文 → 意图:翻译(置信度:0.99)
3.3 优缺点分析
- 优点:
- 语义理解能力最强,可处理复杂、模糊、多意图的输入
- 无需手动定义关键词、示例,仅需提供意图列表
- 可结合上下文理解多轮对话中的意图
- 缺点:
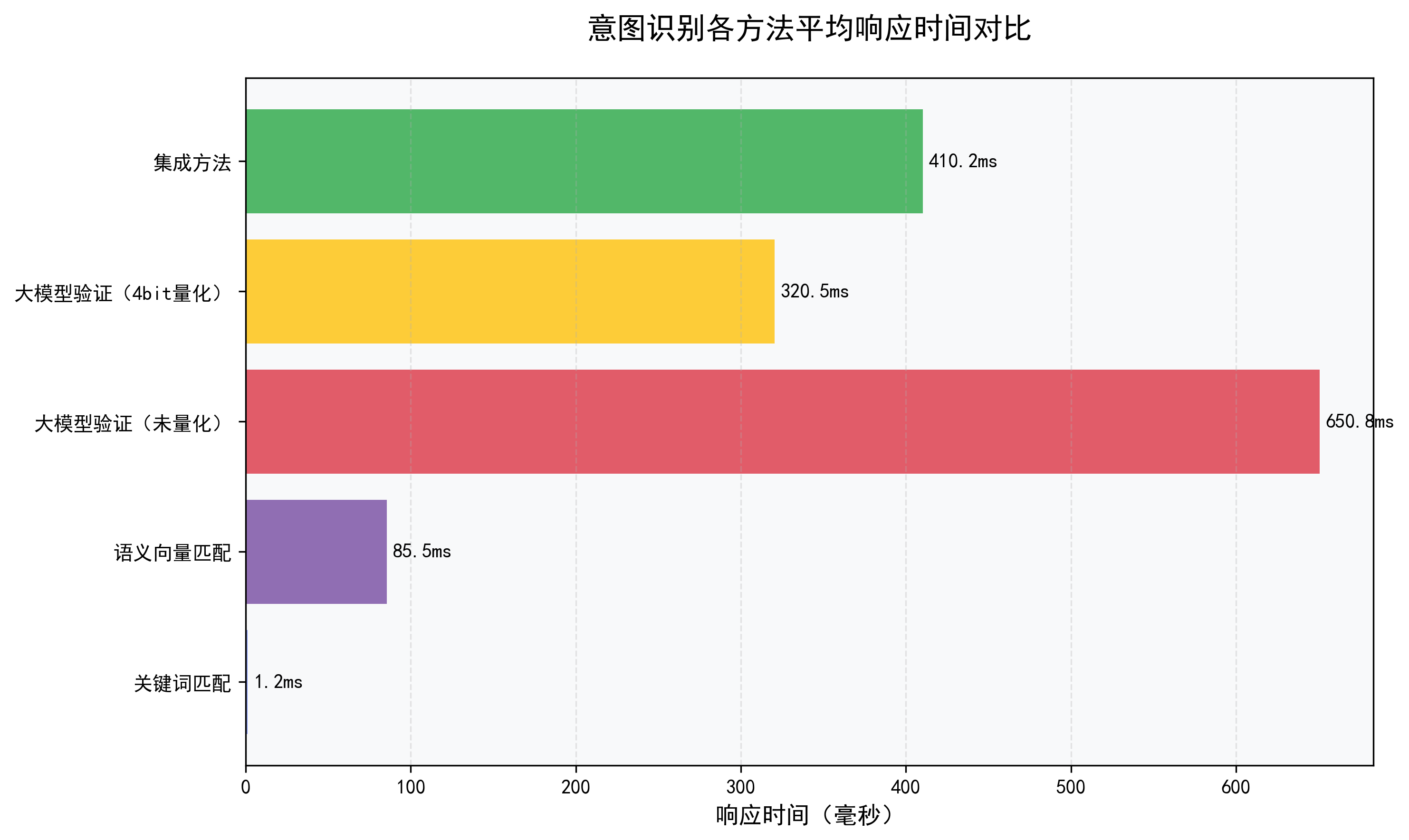
- 相比关键词、语义匹配推理速度慢,随模型的参数量变化推理速度有明显的差异
- 资源消耗高,需GPU或高性能 CPU
- 输出结果可能不稳定,需通过低温度、固定种子优化
四、集成方案
1. 核心逻辑
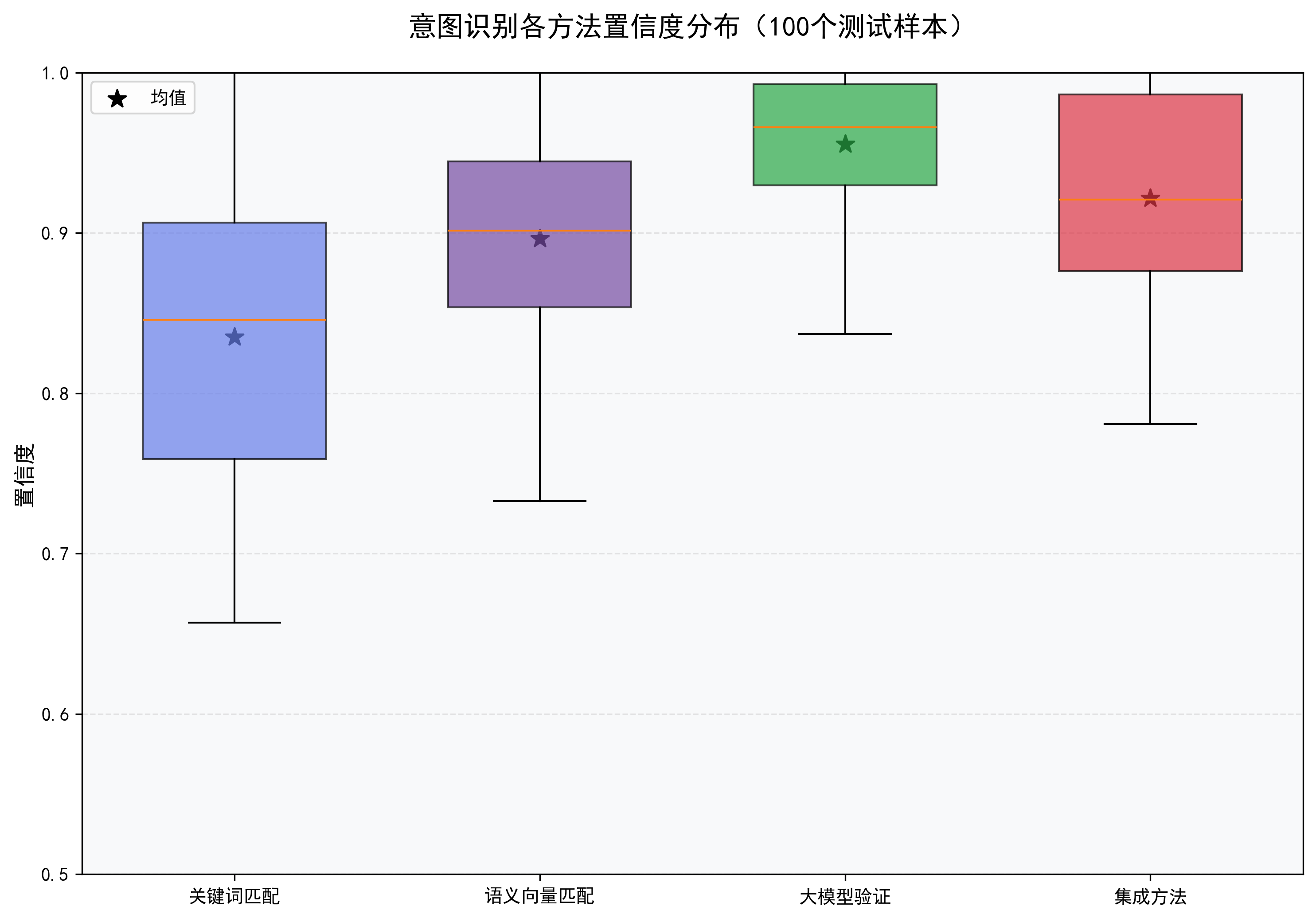
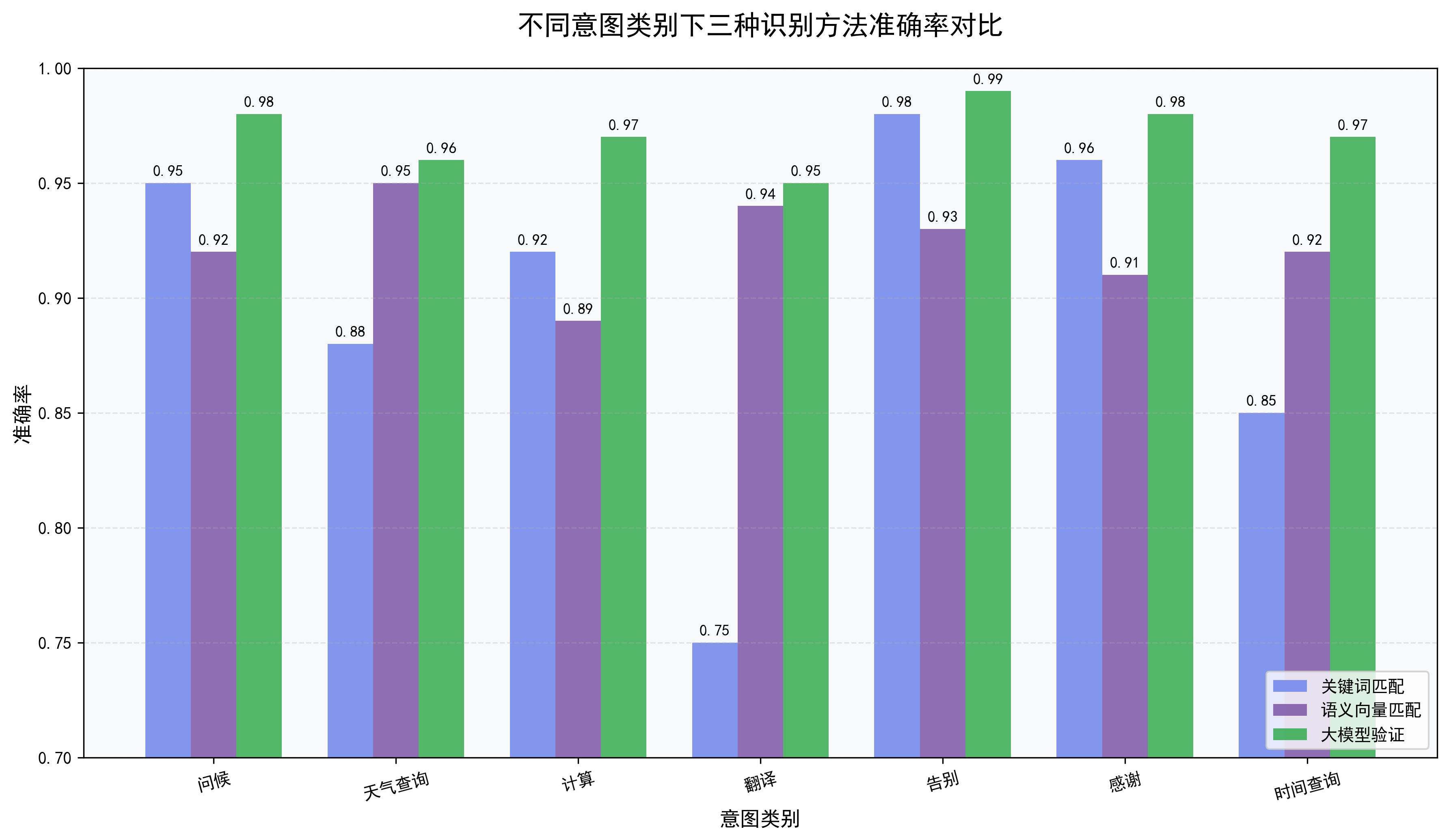
单一方法的意图识别总有局限性,集成方案的核心是“多方法集成”,通过加权投票的方式,结合三种方法的优势:
- 关键词匹配:快速筛选,权重 0.3
- 语义向量匹配:语义理解,权重 0.5
- 大模型验证:精准兜底,权重 0.2
加权投票公式:
最终得分 = 关键词得分 × 0.3 + 语义得分 × 0.5 + 大模型得分 × 0.2
2. 执行流程
集成方案的执行流程融合了基于关键词的规则方法、语义向量的机器学习方法和大模型的深度学习方法,在准确率、灵活性和成本之间取得平衡。
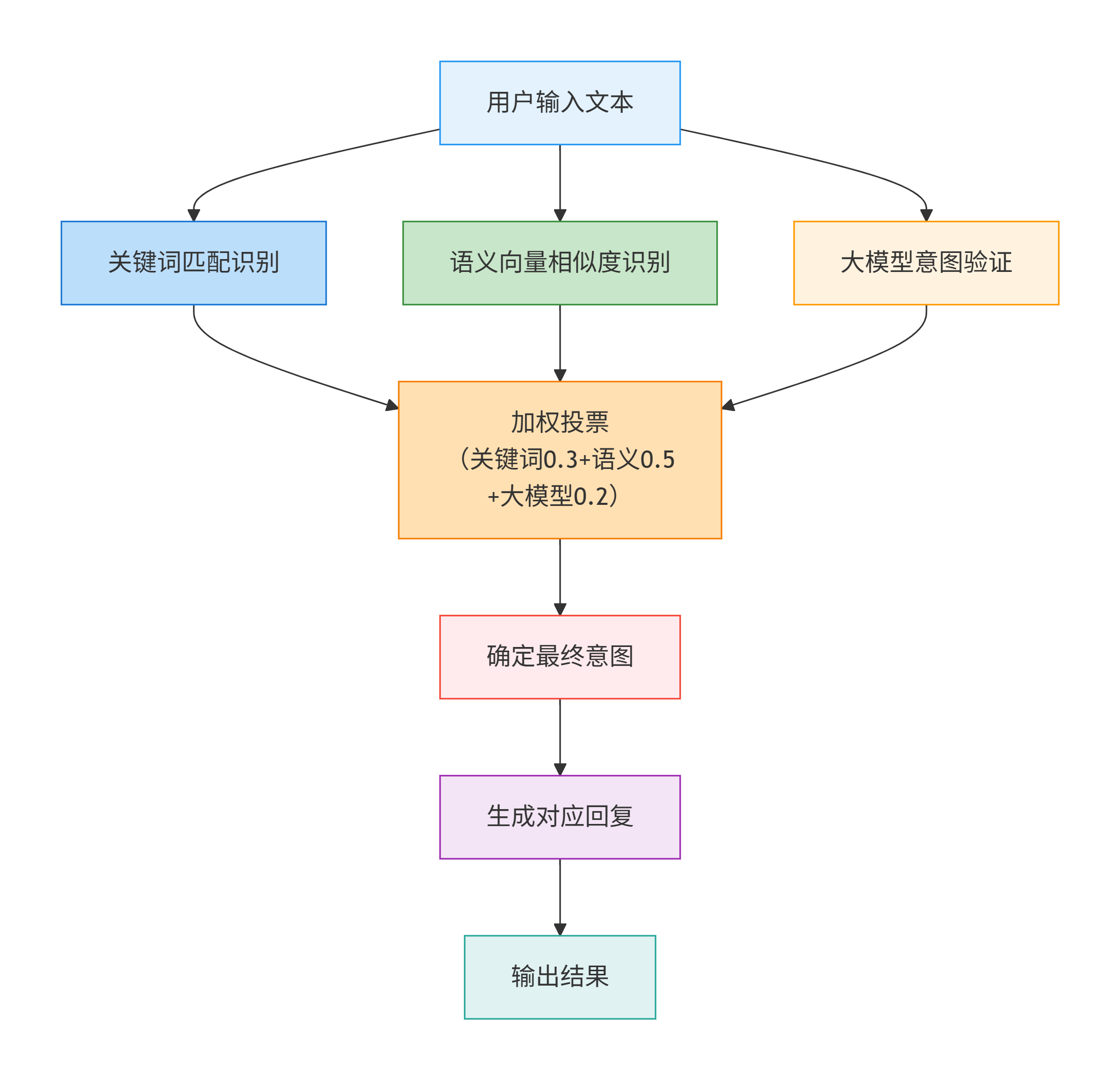
流程说明:
- 1. 用户输入文本:接收用户的自然语言输入
- 2. 三种识别策略并行执行
- 关键词匹配识别:基于预设关键词库快速匹配(速度快,但灵活度低)
- 语义向量相似度识别:将文本转为向量,与意图模板计算相似度(语义理解能力强)
- 大模型意图验证:利用大模型深度理解用户意图(准确率高,但成本高)
- 3. 加权投票融合:三种识别结果按权重进行投票,关键词匹配权重:0.3,语义相似度权重:0.5,大模型验证权重:0.2,权重之和为1,综合三者优势
- 4. 确定最终意图:取加权投票得分最高的意图作为最终结果
- 5. 生成对应回复:根据确定的意图,生成相应的回复内容
- 6. 输出结果:将最终回复返回给用户
4. 注意事项
- 权重调整:可根据业务场景调整各方法的权重,如客服场景可提高大模型权重至0.4
- 置信度阈值:设置最终置信度阈值,如0.5,低于阈值的意图标记为“未知”
- 模型选择:可以选择其他中文识别能力更强的模型,根据服务器的配置选择参数量更大的模型或超大模型的量化版本;
- 缓存优化:提前缓存意图示例的语义向量,避免重复计算
5. 核心示例代码
5.1 后端(FastAPI)
将集成式意图识别封装为 API 接口,提供 HTTP 服务:
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
import uvicorn
app = FastAPI(title="意图识别系统")
# 跨域配置
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 数据模型
class IntentRequest(BaseModel):
text: str
# API接口
@app.post("/api/classify-intent")
async def classify_intent(request: IntentRequest):
try:
if not request.text.strip():
raise HTTPException(status_code=400, detail="输入文本不能为空")
result = classify_intent_ensemble(request.text)
return {"success": True, "data": result}
except Exception as e:
raise HTTPException(status_code=500, detail=f"识别失败:{str(e)}")
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)服务启动日志记录:
系统接口列表清单:
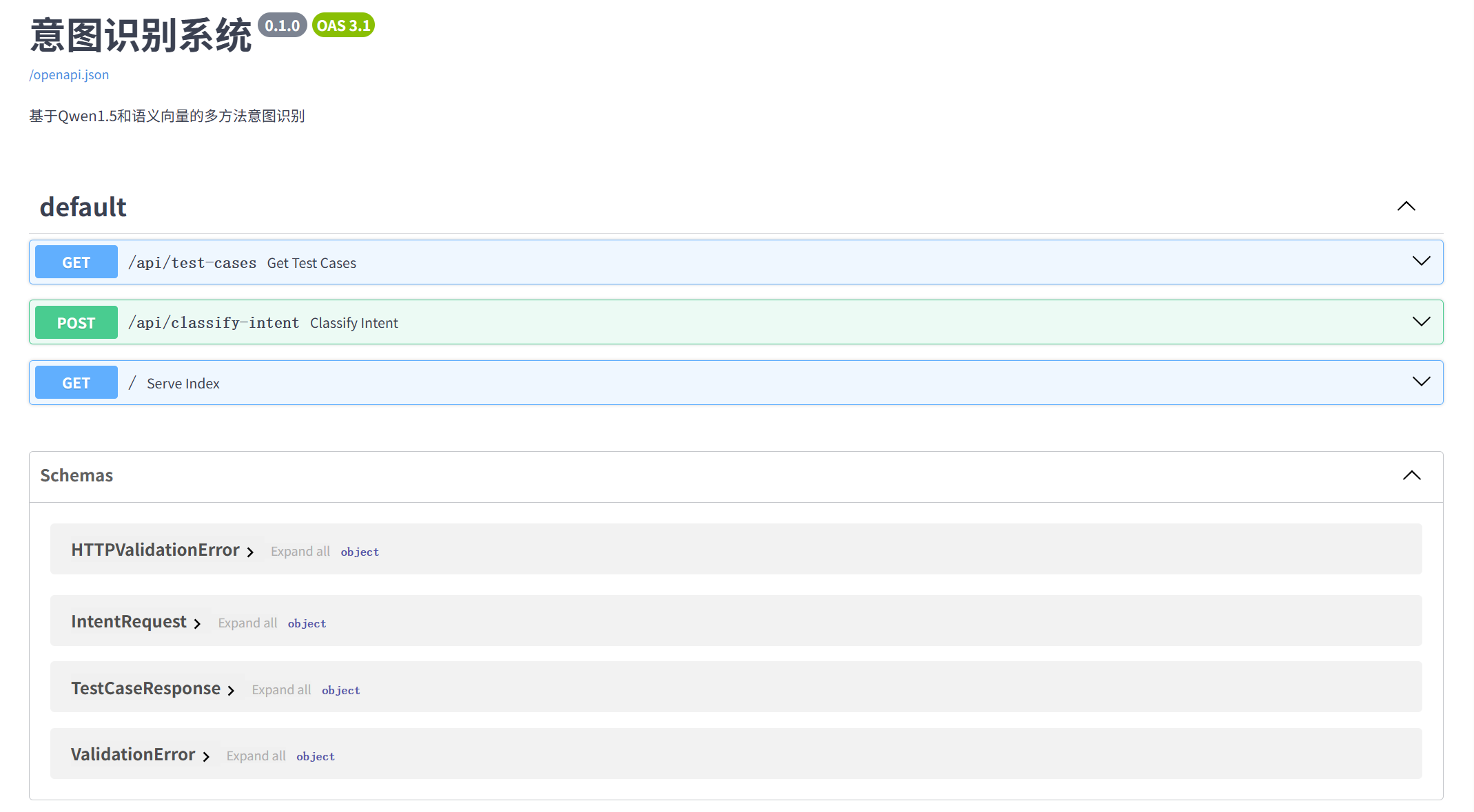
5.2 前端(HTML+JS)
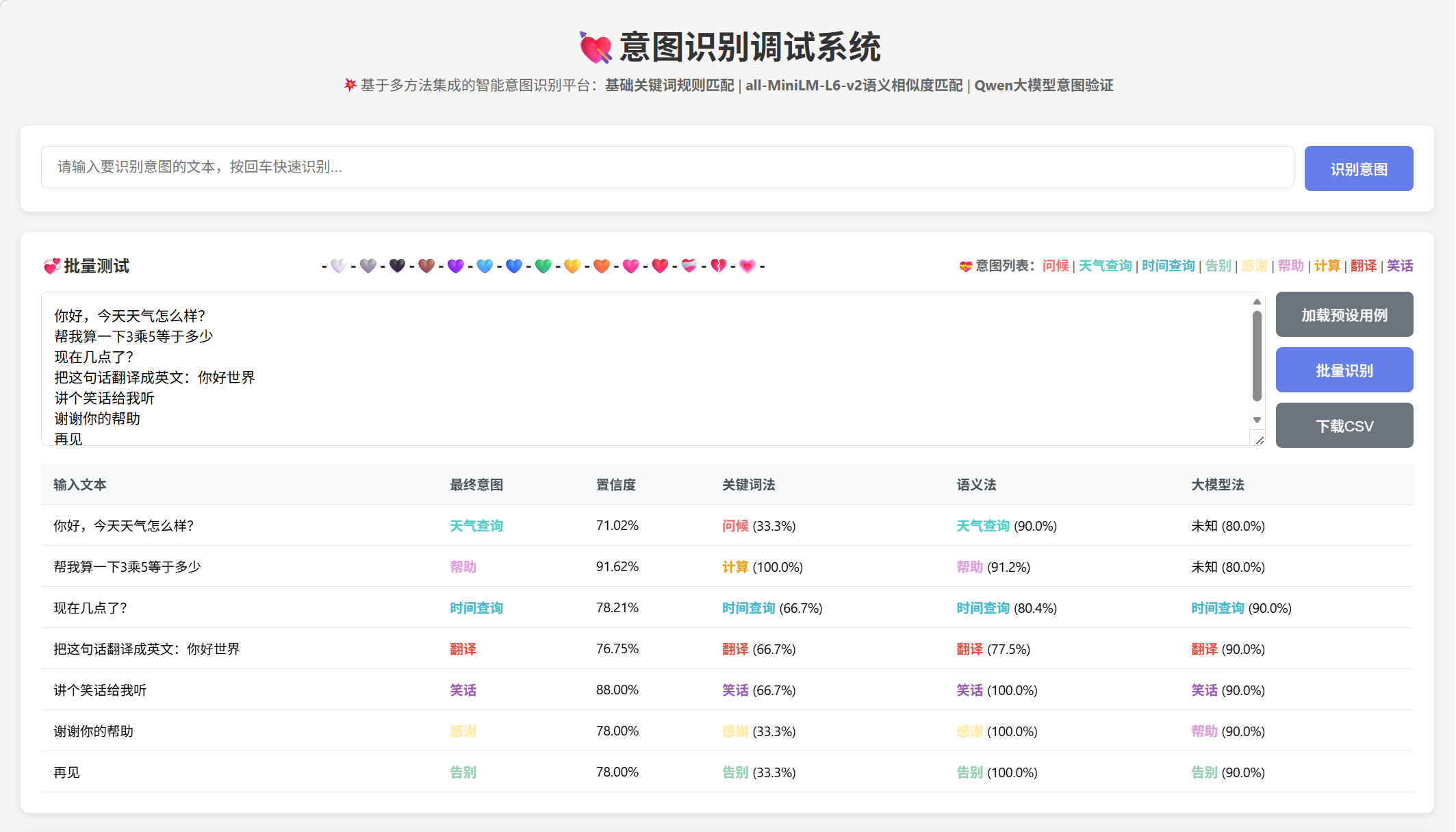
实现可视化的交互界面,支持:
- 单文本输入识别
- 批量测试用例执行
- 识别结果可视化
- 结果导出为 CSV
核心交互代码:
// 调用意图识别API
async function classifyIntent(text) {
try {
const response = await fetch('http://localhost:8000/api/classify-intent', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ text })
});
const result = await response.json();
return result.data;
} catch (error) {
console.error('识别失败:', error);
return null;
}
}意图识别界面初始化:
单条文本意图识别测试:
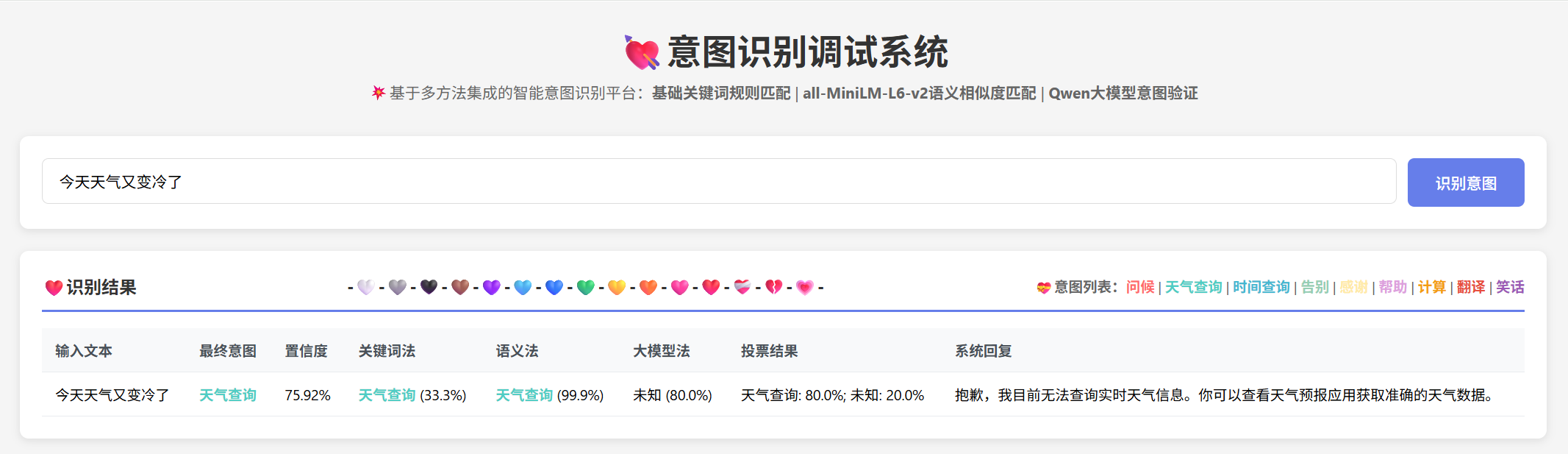
批量测试结果对比:
五、总结
围绕智能体意图识别的项目落地,我们从踩坑试错到打磨出成熟方案,核心就是跳出单一方法的局限,用关键词匹配 + 语义向量 + 大模型验证的集成思路,解决了识别偏差、泛化能力弱的核心问题。项目里没有追求复杂的大模型架构,而是选了 Qwen1.5-1.8B 轻量大模型 + all-MiniLM-L6-v2 语义模型,兼顾本地部署的轻量化和识别精准度,适配智能对话、客服助手这类实际应用场景。
实操中先靠关键词匹配快速筛选意图,再用语义向量解决口语化、同义不同表达的问题,最后让大模型做精准兜底验证,还通过加权投票的方式整合三者结果,既避免了关键词的死板,又弥补了纯语义匹配的模糊性。整个优化过程也摸清了落地关键:意图识别不用贪大求全,贴合业务的意图定义 + 轻量高效的模型组合的部署优化,才是让智能体真正听懂用户需求的核心,也为后续智能体的多轮对话、场景化响应打下了扎实的基础。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号