腾讯云OCR × WorkBuddy:财报三表勾稽自动化Skills最佳实践
原创
腾讯云OCR × WorkBuddy:财报三表勾稽自动化Skills最佳实践
原创
腾讯云AI
修改于 2026-05-28 17:36:29
修改于 2026-05-28 17:36:29
1、什么是财报三表勾稽?
所谓"三表",是企业财报的三大核心报表:
报表名称 | 核心内容 | 关键作用 |
|---|---|---|
资产负债表 | 资产、负债、所有者权益 | 反映企业某一时点的财务状况 |
利润表 | 收入、成本、费用、利润 | 反映企业某一期间的经营成果 |
纳税申报表 | 应税收入、应纳税额 | 反映企业某一期间的纳税情况 |
常见勾稽点包括:
- ✅ 跨期一致性:资产负债表"期初数" = 上期"期末数";
- ✅ 表内平衡:资产 = 负债 + 所有者权益;
- ✅ 跨表勾稽:利润表"净利润" → 资产负债表"未分配利润"变动;
- ✅ 税会差异:利润表"所得税费用" vs 纳税申报表"应纳所得税";
- ✅ 现金流勾稽:经营活动现金流 vs 利润表营业收入规模。
三张表之间存在严密的数学勾稽关系,任何一处数字对不上,都可能意味着录入数据错误、虚增收入、隐匿负债或跨表造假等风险信号。传统做法是人工翻 PDF、手动录入 Excel、逐条公式核对,效率低且易出错。本次最佳实践通过WorkBuddy平台,基于腾讯云OCR表格识别能力打造的financial-statement-check Skill,成功将这一流程从数小时压缩至几分钟。
该技能已上架ClawHub社区:https://clawhub.ai/zt1314p-design/financial-statement-check
2、场景痛点:拆解财报审核的三重门槛
财报审核的难度是逐层递进的:
痛点1: 纸质材料量大,人工审阅耗时耗力
企业提交的财报通常是 PDF、扫描件甚至翻拍图片,动辄数十上百页。人工逐页翻阅、定位关键表格、抄录数字,一份年报仅数据录入就要数小时,准确率还难以保证。在批量审核场景下(如信贷审批一天过十几家),人力瓶颈尤为突出。
痛点2: 版式复杂、文件类型多样,常规工具无法理解
财报表格存在跨行合并、跨列嵌套、多级小计等复杂版式,且格式五花八门——有文字型 PDF、有扫描图片型 PDF、有拍照件。普通工具面对这些文件,要么无法读取图片内容,要么丢失表格结构,根本无法完成结构化提取。
痛点3: 深入内容层面,单位币种混乱、措辞不一、批量计算繁琐易错
即使拿到了数据,真正的挑战才刚开始。同一份财报里资产负债表可能用"万元",利润表用"元";涉外企业还夹杂美元、港币。不同企业对同一科目的措辞各异("应交税费"vs"应交税金"),三表之间数十条勾稽规则涉及跨期、跨表、税会差异等多维度校验。手工统一单位、对齐口径、逐条核算,多一个零少一个零都可能引发重大决策偏差。
3、最佳实践:基于WorkBuddy 平台实操演示
我们以腾讯公司 2025 年度财报为例,演示基于在 WorkBuddy 平台使用 financial-statement-check 技能的全流程实操。
📌 说明:上市公司公开年报格式规范,适合作为演示样本;实际场景中该流程同样适用于中小企业报表、银行流水财报等。
3.1 传统方案:人工 + Excel
步骤 | 耗时 |
|---|---|
定位三表页码 | 10~20 分钟 |
数据录入 Excel | 60~90 分钟 |
公式设置与核对 | 30~60 分钟 |
差异复查 | 20~40 分钟 |
合计 | 2~4 小时 |
主要风险:手工录入错误率高,规则漏检高,扫描件/图片型 PDF 完全无法处理。
3.2 腾讯云OCR 表格识别方案:financial-statement-check 技能包
financial-statement-check 是一个API封装的Skill(技能包),它将腾讯云 OCR 表格识别能力、智能页码定位、三表字段映射、规则引擎校验等完整流水线封装为开箱即用的技能,核心资源包括:
scripts/table_ocr.py—— 腾讯云 RecognizeTableAccurateOCR 调用脚本(支持 PDF/图片、并行识别);references/cross-check-rules.md—— 六大类勾稽校验规则定义;references/field-mapping.md—— 三表科目字段映射、单位币种统一规则;
与直接调用腾讯云 API 不同,该技能在感知层(自动触发)、编排层(流水线串联)、输出层(结构化报告)做了完整封装,无需理解底层 API 即可使用。
如何使用?
确认技能已启用
在 workbuddy 等平台导入 financial-statement-check 技能。(Skill地址:https://clawhub.ai/zt1314p-design/financial-statement-check,支持CLI与Prompt安装)
配置腾讯云密钥
在环境变量中设置:
2 1export TENCENTCLOUD_SECRET_ID="你的SecretId"2export TENCENTCLOUD_SECRET_KEY="你的SecretKey"🔗 密钥申请:腾讯云 API 密钥管理 🔗 OCR 服务购买:腾讯云文字识别 OCR(选择"表格识别高精度版")
发送财报文件,一句话触发
在 WorkBuddy 中,用户只需:
- 上传财报 PDF
- 发一句话,例如:"帮我对这份财报做三表勾稽检查"
技能会自动触发完整流水线,无需任何额外配置或编码。
接下里看看实际演示和效果。
Step 1: 上传财报 PDF,触发智能页码定位与并行 OCR 识别
上传腾讯 2025 年报 PDF 后,workbuddy 自动进入处理流水线。首先通过 PyMuPDF 提取全文文本进行页码定位,随后对定位到的页面并行调用腾讯云表格 OCR:
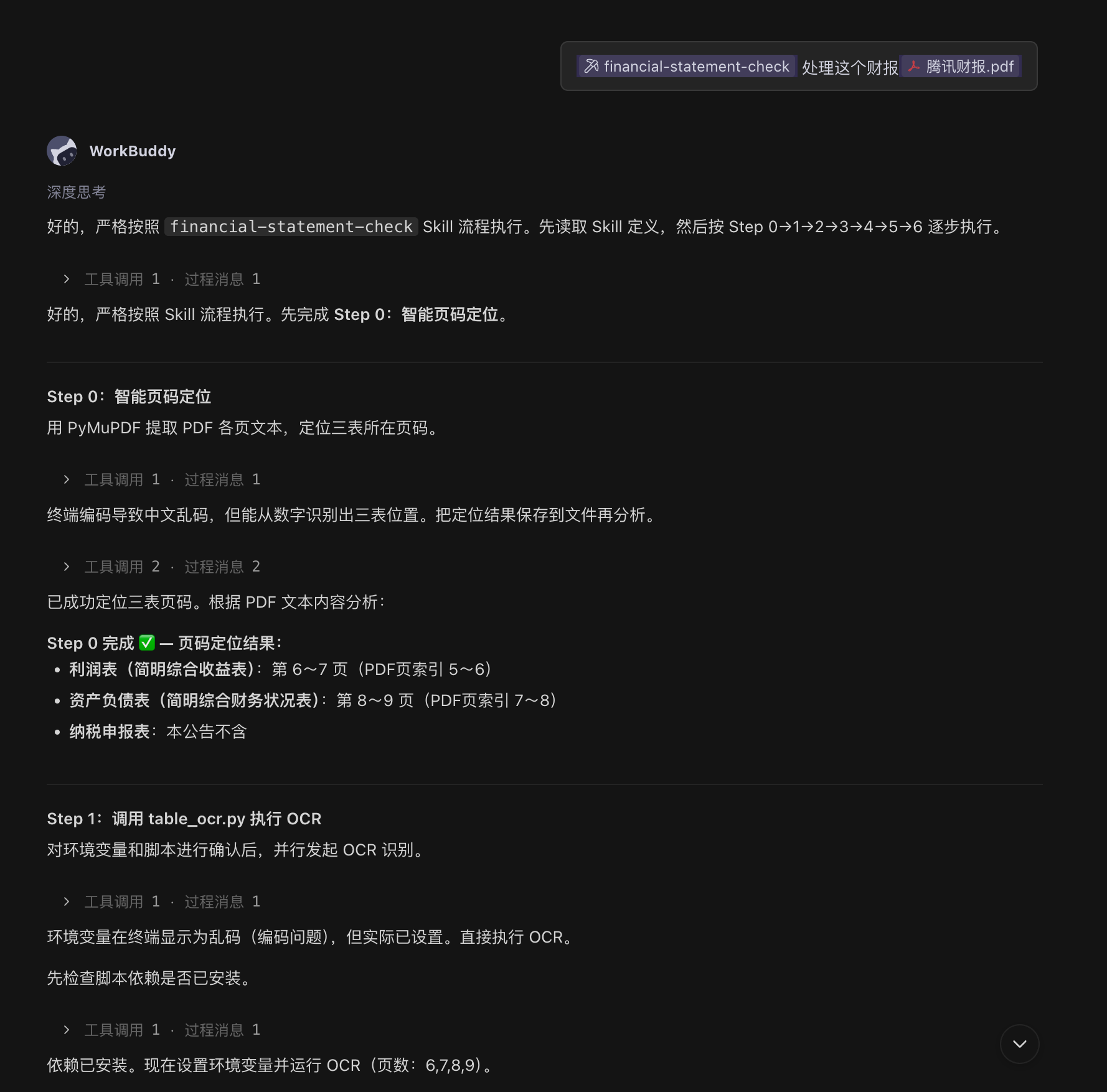
可以看到:
- Step 0:通过关键词自动定位到利润表(第6、7页)、资产负债表(第8、9页),并识别出本公告不含纳税申报表
- Step 1:仅对相关页面调用 OCR(节省配额),并行识别完成
Step 2: 全流程自动执行(Step 0 ~ Step 6)
整个 financial-statement-check 技能流水线包含 7 个步骤,自动串联执行:

各步骤摘要:
- Step 0(页码定位):定位三表所在页
- Step 1(OCR识别):并行识别,共提取 31 个表格
- Step 2-4(字段映射 + 单位转换):单位从"百万元"自动转换为"万元",币种 CNY 无需折算
- Step 5(勾稽校验):资产负债表平衡(差异=0)、毛利勾稽(差异=0)、净利润率 30.57%(合理区间)——全部通过
- Step 6(报告输出):自动生成结构化审核报告
Step 3: 输出审核报告 — 基础信息与原始指标
技能最终输出标准化的审核报告,包含报告元信息、时间检查、原始指标等:
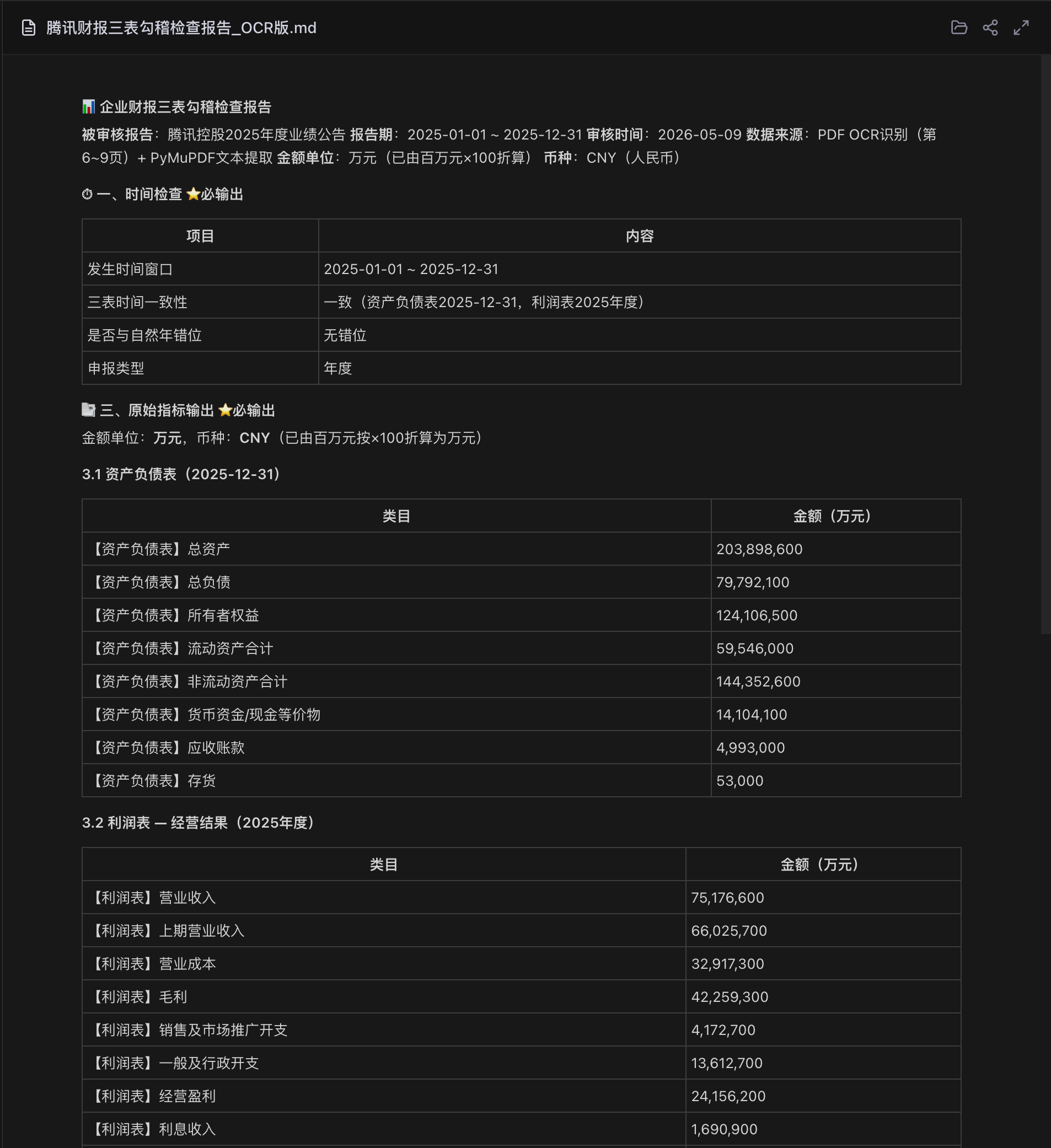
报告要点:
- 元信息:自动标注报告期间、数据来源(PDF OCR 第6~9页)、金额单位(万元,已由百万元×100折算)
- 时间检查:三表时间一致,年度申报,无错位
- 原始指标:清晰列出资产负债表各科目(总资产、总负债、权益、货币资金等)和利润表经营指标(营业收入、成本、毛利、经营盈利等)
Step 4: 输出审核报告 — 税务指标与跨表校验

- 税务指标:因本公告不含纳税申报表,相关项标记为"⚠️ 异常(未识别/未匹配)"——这正是系统的严谨之处,未找到数据不会捏造;
- 核心指标检查:资产负债表平衡(差异=0)✅、毛利勾稽(差异=0)✅、净利润率 30.57% ✅;
- 跨表校验:因无纳税申报表,相关跨表项标记为"无法校验"并说明原因。
除 WorkBuddy 外,CodeBuddy、Qclaw、OpenClaw、Hermes Agent等平台也可支持类似能力,大家可以参考以上实践。
3.3 不同方案效果对比
维度 | 人工+Excel | Skills技能(推荐) | 裸 API 自行开发 |
|---|---|---|---|
单份耗时 | 2~4 小时 | 3~8 分钟 | 开发后同等 |
录入错误率 | 5~8% | <0.5% | <0.5% |
规则覆盖率 | 60~70% | 90%+ | 取决于实现 |
扫描件/图片处理 | ❌ | ✅ | ✅ |
单位/币种统一 | 手工易错 | ✅ 自动 | 需自行实现 |
上手门槛 | 需资深经验 | 零门槛 | 需开发资源 |
维护成本 | — | 技能自动更新 | 需持续维护 |
4. 技术支撑:腾讯云 OCR 表格识别 × Skill封装
4.1 底层能力:腾讯云 OCR 表格识别
技能的核心 OCR 能力来自腾讯云 RecognizeTableAccurateOCR(表格识别高精度版)接口:
- 复杂表格支持:跨行合并、跨列嵌套、多级小计等财报常见版式均可准确识别;
- 高精度:表格内容准确率 >97%,远超手工录入;
- 结构化输出:返回 HTML/JSON 格式,便于后续字段映射和自动化处理;
- 多格式兼容:支持文字型 PDF、扫描图片型 PDF、拍照件,Base64 和 URL 两种输入方式。
4.2 Skill 封装的增值能力
在原有 OCR API 基础上,financial-statement-check 技能还增加了:
能力 | 说明 |
|---|---|
智能页码定位 | 先用 PyMuPDF 文本扫描定位三表页码,再针对性调用 OCR,避免浪费配额 |
三表自动识别 | 根据表头关键词和字段映射规则,自动判定每个表格归属 |
字段标准化 | 将不同企业的措辞差异("应交税费" vs "应交税金"等)统一映射为标准字段名 |
规则引擎 | 内置数十条勾稽规则,覆盖时间一致性、表内平衡、跨表校验、税会差异等六大类 |
异常分级输出 | 区分"必输出"与"仅异常时输出",报告简洁高效 |
用户自定义检查 | 支持附带自定义关注点,灵活扩展 |
财报审核是一个典型的"规则密集 + 数据提取"型任务。基于腾讯云OCR表格识别能力打造的financial-statement-check 技能,在 workbuddy 平台本质上做了三件事:
- 给 AI 装上眼睛:腾讯云 OCR 解决了 PDF/图片财报的"视觉盲区"问题,扫描件、翻拍件、复杂合并表格——这些过去让工具束手无策的格式,现在都能被准确识别和结构化提取。
- 把经验固化为技能:资深审计师脑中的勾稽规则、行业常识、异常阈值,被封装为可复用、可更新的技能包。它不会因为疲劳而遗漏,不会因为经验不足而误判,覆盖率从人工的 60~70% 提升到 90% 以上。
- 让使用者零门槛:不需要写代码、不需要理解 API、不需要配置规则引擎——上传 PDF,一句话搞定。
除了本文演示的财报三表勾稽场景,腾讯云 OCR 技能矩阵还覆盖了更广泛的业务场景:
- 财务报销场景:接入增值税发票识别技能,OpenClaw 可以自动读取发票金额、税率、购销方信息,告别手动填报;
- 合规审查场景:接入营业执照、身份证识别技能,企业资质核验、KYC 流程秒级完成;
- 跨境业务场景:接入多国护照识别技能,80+ 国家证件信息一键提取,国际化团队协作不再受语言壁垒所困;
- 教育评测场景:接入试题批改 Agent,手写答案自动识别、知识点分析一气呵成。
同时,官方也上架了众多腾讯云OCR Skills在Skillhub、ClawHub等技能社区,满足不同的场景需要,用户可以根据自己的场景按需选择:
skills名称 | 链接 | 介绍 |
|---|---|---|
TencentCloud IDCard OCR | 腾讯云身份证识别(IDCardOCR)接口调用技能。可识别身份证图片中中国大陆居民二代身份证正反面信息(姓名、性别、民族、出生日期、住址、身份证号、签发机关、有效期限等),支持身份证图片照片裁剪和多种告警功能 | |
TencentCloud BizLicense OCR | 腾讯云营业执照识别(BizLicenseOCR)接口调用技能。可识别营业执照图片上的字段信息(统一社会信用代码、公司名称、主体类型、法定代表人、注册资本、组成形式、成立日期、营业期限、经营范围等)时,支持复印件/翻拍件告警检测、有效期自动拼接、电子营业执照图片识别及非营业执照的营业类证件图片识别。 | |
TencentCloud General OCR | 腾讯云广告文字识别(AdvertiseOCR)接口调用技能。当用户需要从图片中识别文字内容时,应使用此技能。支持中英文、横排、竖排及倾斜场景的图片文字识别,支持90度、180度、270度翻转场景的图片识别,返回文本框位置与文字内容。 | |
TencentCloud LicensePlate OCR | 腾讯云车牌识别(LicensePlateOCR)接口调用技能。当用户需要对中国大陆机动车车牌进行自动定位和识别时,应使用此技能。支持返回车牌号码、车牌颜色、置信度和像素坐标信息,支持多车牌场景识别。 | |
TencentCloud MLIDPassport OCR | 腾讯云护照识别(多国多地区)(MLIDPassportOCR)接口调用技能。当用户需要识别护照图片中中国大陆、港澳台地区或其他国家/地区的护照信息(护照ID、姓名、出生日期、性别、有效期、发行国、国籍、国家地区代码、MRZ码等)时,应使用此技能。支持图片Base64和URL两种输入方式,支持护照图片人像照片裁剪功能,支持80+国家/地区的可机读护照图片识别,同时支持复印件、翻拍、PS、反光、模糊、边框不完整等告警功能(仅国际站生效) | |
TencentCloud RecognizeTable OCR | 腾讯云表格识别v3(RecognizeTableAccurateOCR)接口调用技能。当用户需要从表格图片或PDF中识别常规表格、无线表格、多表格的内容,提取每个单元格的文字信息,或将表格图片识别结果导出为Excel文件时,应使用此技能。支持中英文表格图片、旋转表格图片、嵌套表格图片等复杂场景,识别效果优于表格识别V2。 | |
TencentCloud VatInvoice OCR | 腾讯云通用票据识别高级版(VatInvoiceOCR)接口调用技能。当用户需要识别发票图片中增值税专用发票、增值税普通发票、增值税电子专票、增值税电子普票、电子发票(普通/增值税专用)的全字段信息时,应使用此技能。支持识别发票图片中的发票代码、发票号码、开票日期、合计金额、校验码、税率、合计税额、价税合计、购买方/销售方信息、明细条目等全部字段,同时支持PDF格式发票图片识别。 | |
TencentCloud VehicleLicense OCR | 腾讯云行驶证识别(VehicleLicenseOCR)接口调用技能。当用户需要识别行驶证图片主页(车牌号码、车辆类型、所有人、住址、使用性质、品牌型号、识别代码、发动机号、注册日期、发证日期)或副页(号牌号码、档案编号、核定载人数、总质量、整备质量、核定载质量、外廓尺寸、准牵引总质量、备注、检验记录)信息时,应使用此技能。支持图片Base64和URL两种输入方式,支持复印件、翻拍、反光、模糊、边框不完整等告警功能,支持电子行驶证图片和拖拉机行驶证图片识别。 | |
TencentCloud ExtractDoc OCR | 腾讯云实时文档抽取Agent(ExtractDocAgent)接口调用技能。当用户需要从图片或PDF中按自定义字段名称进行结构化信息抽取时,应使用此技能。支持自定义字段名称、字段类型(KV对或表格字段)和字段提示词,实现灵活的文档信息提取。适用于合同、发票、报告等各类文档的结构化数据抽取场景。 | |
TencentCloud QuestionMark OCR | 腾讯云试题批改Agent接口调用技能。当用户需要对试卷图片或试题图片中的K12试卷或试题进行自动批改、手写答案识别、知识点分析时,应使用此技能。支持整卷图片批改和单题图片批改,提供题目切题、正误判定、答案对比、错误分析、知识点输出等结构化评估结果。 |
当机械性的数据提取和规则核对被AI技能接管之后,财务人员才有更多时间去做高价值的事情:审视异常背后的商业逻辑,判断数字之外的经营风险,做出需要行业洞察和职业判断的决策。工具解决效率问题,人解决判断问题,这才是 AI 在专业领域的正确打开方式。
扫码加入腾讯云AI产品Skills交流群:

原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号