IM分布式架构系列(06) "撤回了一条消息"后 | 系统如何"买单"
原创
IM分布式架构系列(06) "撤回了一条消息"后 | 系统如何"买单"
原创
拉丁解牛说技术
发布于 2026-05-29 00:04:09
发布于 2026-05-29 00:04:09
史铁生有一段话,我觉得是关于"苦难"写得最好的一段:
"就命运而言,休论公道。"
意思是——命运本来就是不公平的,你跟它讲公道,是徒劳的。
一、撤回没有想的那么简单
1.1 撤回这件事在 IM 链路里的位置
1.2 一次撤回触发的真实改动面
二、撤回功能如何设计
三、大厂如何设计
四、如何优化提升
一、撤回没有想的那么简单
产品经理:"撤回功能加一下,跟某信一样,2 分钟内可撤回。" 此外toB 客户要求:"我们合规要求撤回的内容也要留底审计,你们怎么实现?"
"撤回"是 IM 里用户感知最轻、但是工程代价并不小的功能。用户点两个字,后端要联动消息表、会话表、未读计数、离线 inbox、推送通道、已读回执——任何一处不一致都会被立刻看出来。
有经验的读者,读到06这篇,其实就可以发现IM的研发,其实有很大的经验壁垒、技术壁垒。IM的功能非常常见,数起来也屈指可数。但是细究起来,每个功能的设计研发都不简单,而且对稳定、可靠要求非常高。
1.1 撤回这件事在 IM 链路里的位置
和之前一样,我们先捋一捋这个功能在整体链路的位置和逻辑。撤回它不是"删除消息",而是把一条已经投递出去的消息,在所有接收方设备上把展示状态翻成"已撤回",同时让它不再被任何下游引用(已读、引用、未读、搜索)。跨越消息核心、存储、推送、各种业务支撑模块。
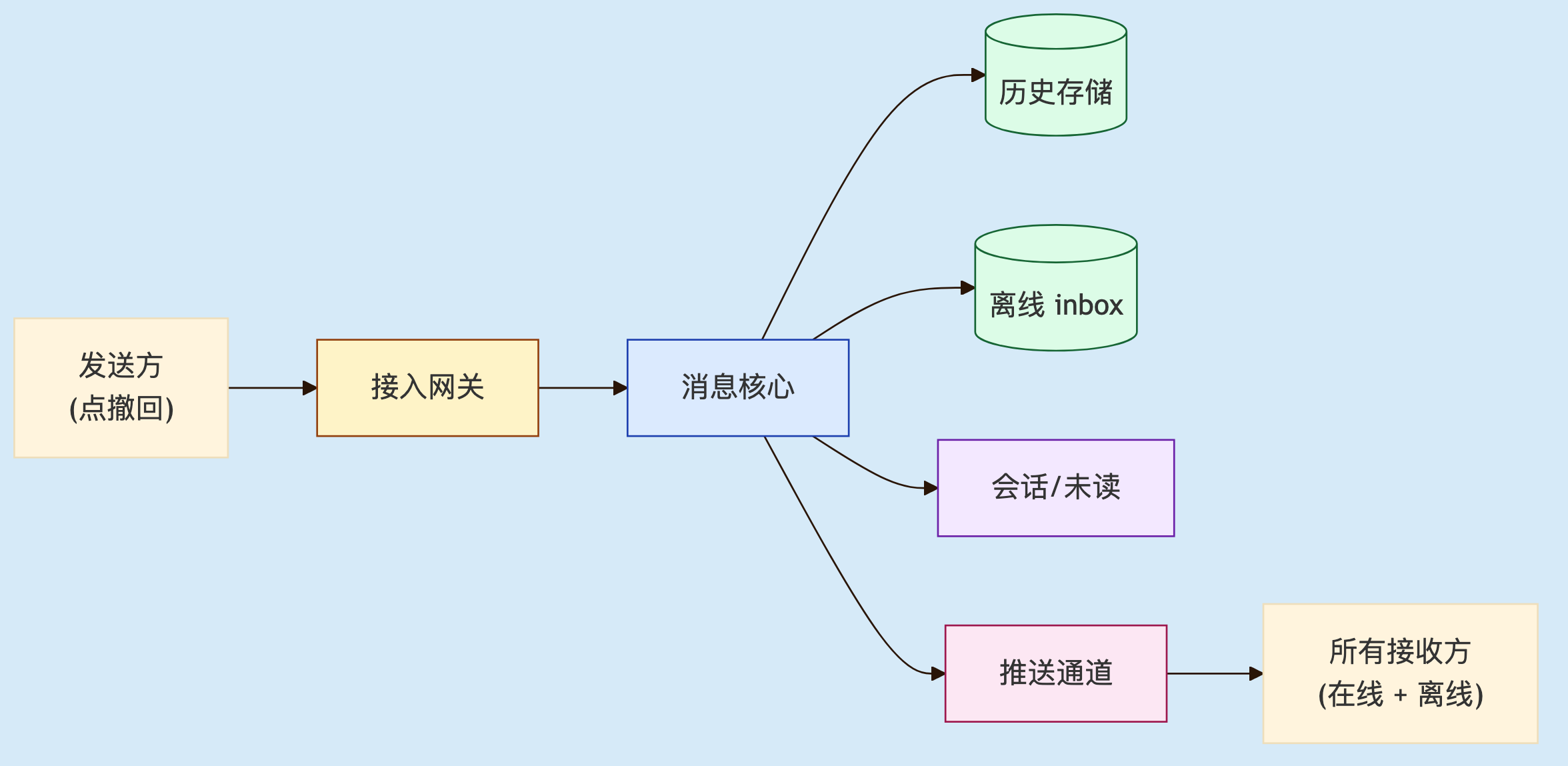
1
图 1. 撤回一条消息需要联动的模块。看似简单的"改状态",实际牵动整个核心链路。
从字面看是改一个字段,从系统视角度看它是一次小型的级联状态机更新。这也就是是为什么"加个撤回功能"几乎不可能像想象那样简单,没法两天做完。
1.2 一次撤回触发的真实改动面
把一次撤回拆开看,服务端要做的事非常多:
- 原消息状态翻新:历史存储里标记已撤回
- 下行通知所有端:对方 + 自己其他端 + 群里所有人
- 会话预览回退:撤回的如果是最后一条
- 未读 -1:接收方没读过则减
- 引用消息回刷:被引用展示变"该消息已撤回"
- 已读列表回滚:群已读那条清理或标记
- 离线 inbox 覆盖:接收方还离线,inbox 里那条要覆盖
- 三方推送 banner:APNs / FCM 锁屏通知基本收不回
这个功能上线后,用户容易看出端倪的异常有:"对方撤了但锁屏通知还显示原文"、"会话列表显示已撤回的预览还在",都是真实生产问题。
二、撤回功能如何设计
2.1 撤回的可验证目标
撤回有几个硬约束:
- 可达性:撤回指令要送达所有接收方的所有端(在线立刻收,离线下次上线必须收到)
- 一致性:所有端最终看到的都是"已撤回",不能 A 端撤了 B 端还显示原文
- 窗口边界明确:超过时间窗的撤回必须明确失败,客户端给出清晰提示
- 不可被规避:撤回后正文不能通过任何接口被拿到(已读、引用、搜索都不能反查)
- 可审计(toB 必备):撤回动作有日志,谁何时撤了什么、内容是否留底,合规可查
2.2 控制消息 vs 原地改状态:两种撤回模型
服务端拿到撤回请求,把它变成"所有接收方都知道这条消息被撤回了"——有2个方案:
方案 A · 原地改状态:历史存储里那条 msgId 的 status 从 normal 改成 recalled、清空 body。读历史接口看到 status=recalled 就显示"已撤回"。简单、存储小;但致命问题是消息一旦下行到客户端,客户端本地按 msgId 缓存——不会再回头拉历史。原地改状态对已下行的消息完全不起作用。
方案 B · 控制消息:撤回不改原消息,而是新写一条对消息(mimeType = application/withdraw),带"撤回 msgId=XXX"。它跟普通消息一样走完整下行链路(扇出、推送、离线 inbox)。客户端收到时把本地缓存里 msgId=XXX 渲染成"已撤回"。
recall_by_control_message(origMsgId, operator):
origMsg = history.get(origMsgId)
check_permission(origMsg, operator)
check_time_window(origMsg.createTime)
ctrlMsg = build_control_msg(
mimeType = "withdraw",
targetMsgId = origMsgId,
targetTime = origMsg.createTime,
operatorUid = operator.uid
)
deliver_as_normal_message(ctrlMsg) // 走正常消息链路扇出
history.update(origMsgId, status='recalled', body=null) // 兜底新设备拉历史方案B控制消息的核心是复用消息通道——既实时推在线、又进离线 inbox 等用户上线拉、还能进同步流让多端补齐。生产实践更成熟的选择是方案B。代价是消息表多一类业务无关的对消息,统计搜索时都要过滤。
而我们进行了优化整合,控制消息 + 原消息改状态双轨并存最稳——控制消息保证已下行消息被收回,原消息改状态保证后续新设备拉历史也能正确显示。
2.3 时间窗与撤回权限校验
时间窗校验看着像 if-else,但是也有几个问题要考虑:
- 用谁的时间?客户端时间戳是可以篡改;纯服务端当前时间也不稳——客户端时钟偏差会触发"客户端以为还能撤、服务端说超时"。生产做法是服务端时钟 + 留余地:时间窗 2 分钟,我们的经验是服务端放宽到 125 秒、客户端按 120 秒置灰按钮,避免最后一秒撤了被服务端拒。所有校验用消息服务端落库时间戳作为基准。
- 群内特殊权限:群主 / 管理员能撤群员消息(toB 常见需求)。校验从"是不是发送方"扩成"是发送方 OR 群主 / 群管"。权限要查群服务、不能信客户端报上来的角色,是跨服务 RPC、要做缓存 + 短超时——撤回链路对耗时敏感。
2.4 已下行消息的回收:在线推送与离线 inbox
控制消息生成后要触达所有接收方的所有端,三种状态分别处理。
接收方在线:控制消息走正常下行通道推到每个在线端,客户端立刻刷新本地缓存。亚秒级,无难度。
接收方离线:控制消息进离线 inbox 按 seq 排队。一个不显眼的优化是写控制消息的同时把 inbox 里原消息 body 清掉。接收方上线只拉到"已撤回"占位,没有"原文一闪再变撤回"的闪烁,也省一次往返。
消息已推但尚未 ACK:控制消息照常推,客户端按 msgId 标记"已撤回",后到的原消息也能正确渲染——顺序不影响最终态。
三方推送 banner:APNs / FCM 是单向系统通道,推过去就撤不回锁屏通知。有团队发空 payload 静默推送覆盖,效果极有限。我们的经验是不必死磕,系统通道很难控制, 产品上明确告知"撤回后对方锁屏通知可能仍显示"即可。
2.5 群撤回的二次扇出代价
单聊撤回扇出范围小,群撤回是写扩散账单的第二次开销——原消息扇出过一次,撤回控制消息再扇一次。1000 人群发一条消息扇出 999 次,撤回时再来 999 次。
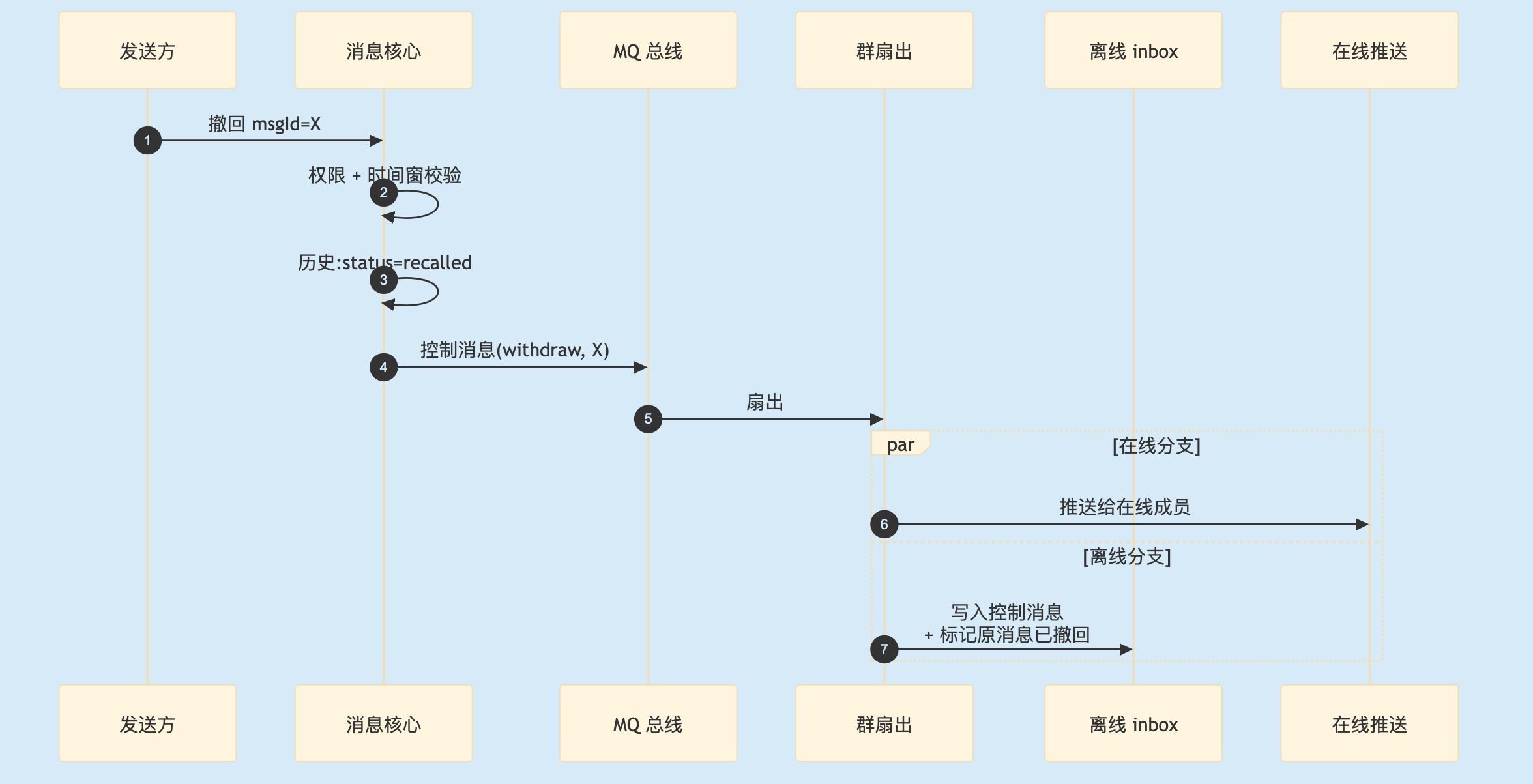
2
图 2. 撤回是一次完整的"写扩散账单"——再扇一遍。
群越大撤回成本越大。toB 万人群常见做法是给群撤回限频(每用户每分钟 N 次)避免恶意刷撤回造成 MQ 风暴,或按群规模收紧时间窗——小群可允许更长时间窗,大群必须收紧。
2.6 撤回的级联清理:已读、引用、未读、通知
消息本身被回收做完了,但有四件相关的级联操作不能漏。
未读数同步:撤回的消息接收方没读过则未读 -1(对于接收方来说,这个消息相当于不存在,反正我也没看到)。未读数存储常和消息表分开(Redis / 单独表),撤回时要同步触发更新未读数。漏掉的话用户看到"会话显示 1 条未读,点进去什么都没有"——那就可能被误会为:系统漏消息了???这个可是P0 bug。
会话最后一条预览:撤回的如果是最后一条,列表预览要回退到前一条非撤回——多一次查询。
引用消息处理:别的消息引用这条怎么办?我们选择保留引用关系,引用内容变成"该消息已撤回"——切断引用会破坏对话上下文。客户端收到撤回控制消息时把本地索引里所有引用的展示刷一遍。
已读列表回滚: 需要清掉这条消息已读列表数据。但是我们toB 场景,部分客户要求撤回前的已读记录需要留底, 他们的意思是就要保留已读数据加上"对应消息已撤回"标记。
我们选择把这四件事做成订阅撤回事件的下游消费者,不塞进主链路。主链路只保证"控制消息扇出 + 原消息状态翻新",其它走异步 MQ。撤回链路耗时短、可靠;级联清理失败不影响撤回成功——这样的代价是可能有几秒的级联不一致窗口。
2.7 一条撤回指令在系统里走完一圈
撤回看着像删一条消息,实际它走的是"再发送一条系统消息"的完整链路——从发送方点击那一刻到所有接收方那条变灰,中间经过的环节是这样:
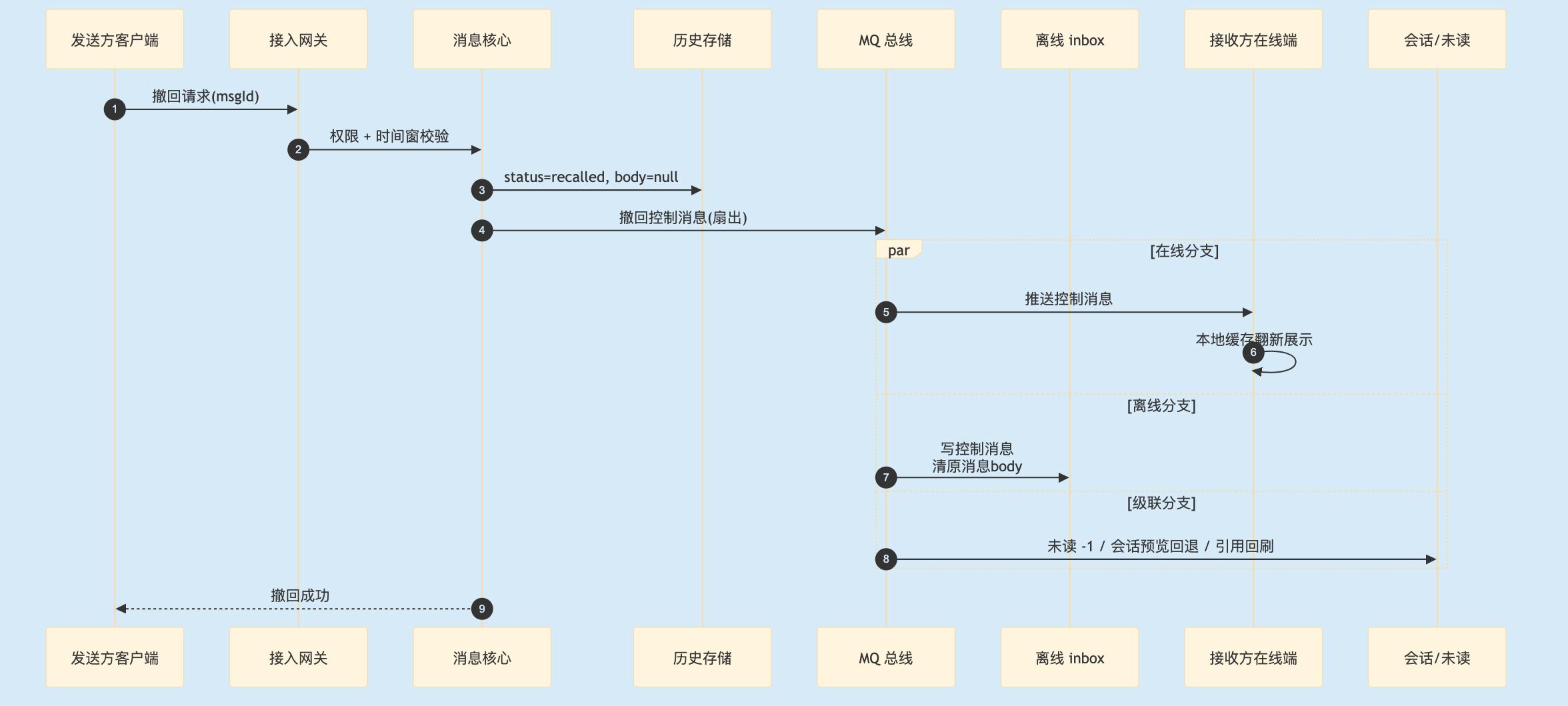
3
图 3. 撤回的完整端到端链路。主链路只保证"翻状态 + 扇出控制消息",级联清理走 MQ 异步。
这套链路里最脆弱的地方是级联清理任意一处都可能失败。控制消息送达失败可重试; 但是级联的处理:未读 / 会话预览 / 引用回刷有一个失败,用户那侧就是"撤回了但还有点不对劲"——这种半成功状态最难排查。
三、大厂如何设计
撤回功能的产品定义差异比技术差异更大。同一句"撤回",时间窗从 2 分钟到无限,产品形态从静默回收到双向删除。
3.1 某信:2 分钟限时与隐藏式提示
某信撤回有几个鲜明特征:时间窗 2 分钟;撤回后保留占位"对方撤回了一条消息"——接收方知道"对方撤了什么"但看不到内容;从产品行为观察,撤回后不显式做已读级联清理;单聊群聊统一时间窗。
从产品行为推断走的是控制消息 + 占位模型——聊天框里那条变成系统占位,而非彻底消失。这种"留痕"是 toC 大产品的保守做法:完全消失会带来"我是不是看错了"的怀疑感,占位提示事件发生过。
维度 | 详情 |
|---|---|
优势 | 时间窗短,合规审计代价小;占位让接收方知情;单一窗口简化产品认知 |
代价 | 2 分钟对 toB 工作沟通太短;锁屏 banner 收不回;群里被撤的消息其他人能拼出蛛丝马迹 |
3.2 企某信:24 小时撤回的控制消息方案
企某信团队在公开分享说过,时间窗 24 小时(toB 必须够长);用控制消息实现——撤回不改原消息,在每个接收方的消息流里插入一条控制消息,带 appinfo(全局唯一消息标识)和 sendtime(双重校验防 appinfo 碰撞)。
为什么不用 referid 直接指向原 msgId? 他们的分享解释: 撤回要修改所有接收方的消息状态,而每个接收方的同一条消息 msgId 不同(写扩散每接收方一份)。沿用 referid 要记录所有接收方的 msgId,代价大;appinfo 是这条消息的"逻辑标识符",在所有接收方上相同,用它做指向是天然的。
维度 | 详情 |
|---|---|
优势 | 24 小时窗口适合 toB 工作场景;控制消息复用消息通道,可靠性强;appinfo + sendtime 双重校验避免误撤;模型可复用到编辑场景 |
代价 | 长时间窗导致"可撤回消息池"更广,合规留底逻辑复杂;群撤回是完整的二次扇出;客户端要维护"按 appinfo 反查本地消息"的索引 |
3.3 国外某Tele某gram:任意时间撤回与双向删除
某Tele某gram 把撤回做到了最激进:任意时间撤回不限时;双向删除(Delete for everyone)——接收方那侧聊天里彻底消失,连占位都没有;用户可选删除对象——"只在我这里删"或"双方都删"。
这套做法呼应 Telegram 的隐私通信定位。技术上能做到,前提是它没有 toB 合规审计、强搜索、AI 摘要——撤回内容从系统彻底消失对它无负担。
但这种激进做法在 toB / 国内产品完全不能用——合规会立刻否决"员工撤了一条骂老板的消息,你说不留底?"。所有某Tele某gram 模型适合纯个人即时通讯,toB 眼馋也学不来。
维度 | 详情 |
|---|---|
优势 | 用户体验极致,真正"删干净";不限时间窗,无产品边界争议;双向删除让被撤一方也无痕 |
代价 | 完全不兼容合规审计 / 强搜索 / AI 摘要等服务端富功能;不限时撤回意味着任何历史消息理论上都可被撤,存储与扇出模型都要支持;不适用于 toB |
四、如何优化提升
4.1 撤回模型的硬决策
对于我们ToM的中小长IM,撤回难点不在于"时间窗多长",而是撤回后内容是否要留底。因为不留底走"控制消息 + 原消息 body 清空";留底(toB 必需)走"控制消息标记 + 原消息整条保留 + 加可见性标记"——管理员后台用单独接口拉,普通接口拉不到。
我们的经验是先跟法务对齐"撤回内容是否进合规审计范围"再倒推架构。toB 项目的答案通常是对外消失、对管理员留底——"应用层撤回但存储层不删"。这跟技术团队第一反应的"撤回就 body 清空"完全不同,提早讨论能省很多返工。
4.2 离线撤回的兜底窗口
撤回控制消息与离线 inbox 的协作是最容易掉的细节。两个反共识做法值得做:
写控制消息时直接清掉 inbox 里原消息的 body,而不是只插控制消息让用户上线拉两条。接收方上线只拉到"已撤回"占位,没有"原文一闪再变撤回"的闪烁,也省一条往返。
撤回控制消息 TTL 大于原消息在 inbox 的存活时间。否则原消息因 inbox 过期被回收时,撤回控制消息找不到对象会被客户端默默丢弃,造成残留。
4.3 群大撤回的批量化
500 人以上群的撤回扇出,主链路成本不小。优化思路有2个:
按 IDC 聚合——群成员分布多 IDC 时,在每个 IDC 内做本地批量推送,跨 IDC 只发一份汇总后的撤回事件,省大量跨 IDC RPC。
降级到拉模式——大群的消息撤回,不主动推每个成员,而是写到群的"事件流"里,客户端下次进群 / 拉历史时主动同步。代价是看到"已撤回"的延迟从秒级变成分钟级;好处是 MQ 流量降一个数量级。万人广播群里很有用——毕竟成员不会一直盯着群。
4.4 撤回的可观测与回滚
撤回链路最大的坑不在主链路,而在级联清理失败时没人知道——未读没减、引用没刷、会话预览没回退,这些不是"撤回失败"而是"撤回成功了但残留",特别难排查。我们的经验做法:
- 撤回事件链全 traceId 打通:主链路到每个级联消费者都带同一 traceId,任意环节失败能反查到原撤回操作
- 级联消费者的失败率单独看板:分别看"未读 -1"、"会话预览回退"、"引用回刷"成功率,任一低于 99.9% 都告警
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号