大模型应用:从意图识别到个性化推荐:基于语义意图识别的智能推荐系统.121
原创
大模型应用:从意图识别到个性化推荐:基于语义意图识别的智能推荐系统.121
原创
未闻花名
发布于 2026-05-29 07:56:18
发布于 2026-05-29 07:56:18
一、前言
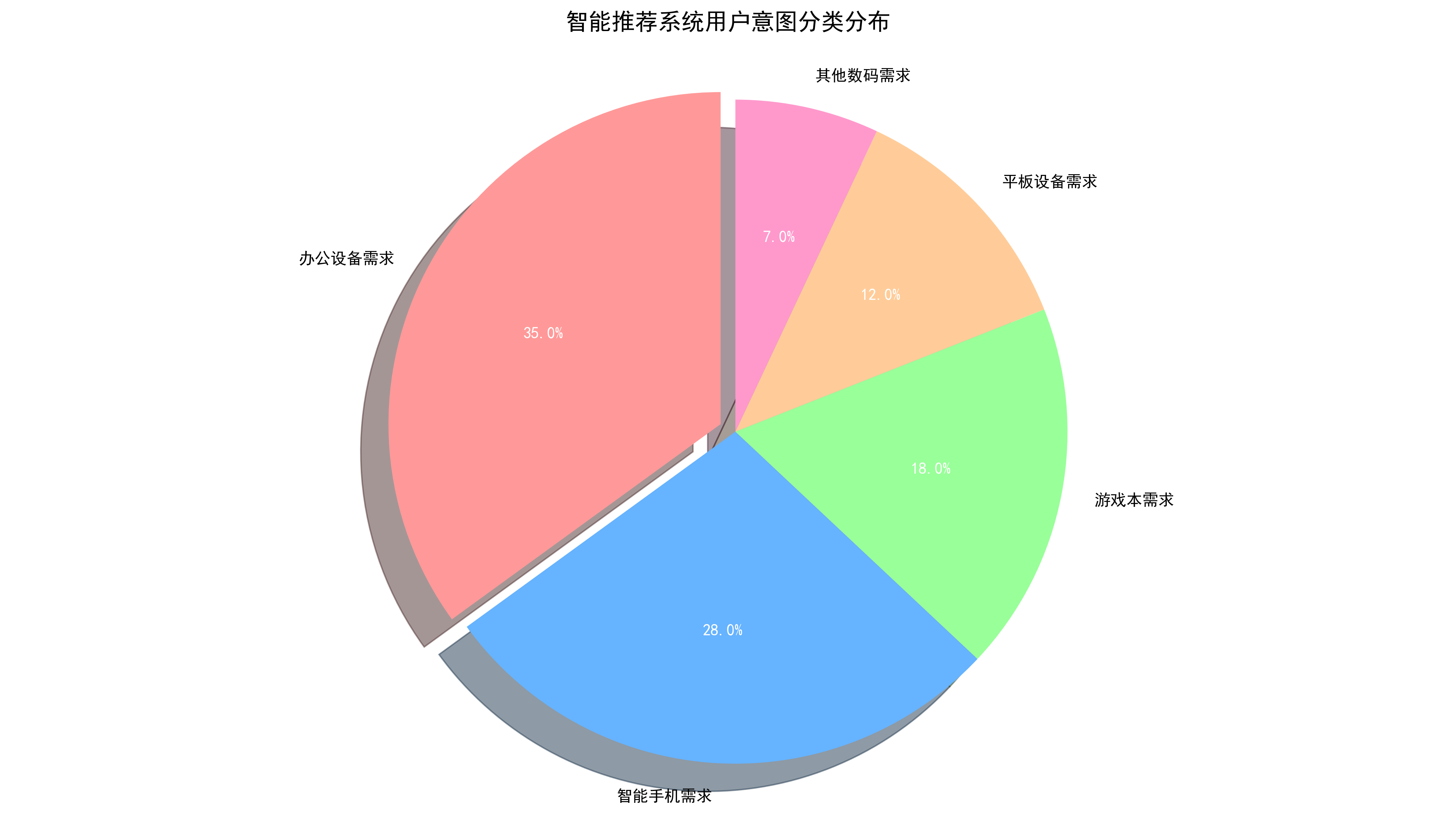
我们在刷电商、看视频、听音乐的时候,肯定都有过这种感觉:明明只是随口搜了一句话,平台就像懂你一样,推过来的东西刚好是你想要的。这背后不是玄学,也不是巧合,而是意图识别 + 推荐系统在默默工作。传统的推荐要么靠历史行为、要么靠标签匹配,很容易出现“搜过一次就反复推”、“看不懂真实需求”的问题。而现在更聪明的方式,是直接理解我们这句话的意思,不管我们怎么说、用什么词,系统都能抓住我们真正想要什么,再给我们最匹配的结果。
今天我们趁热打铁,基于意图识别的基础上,用最简单、最容易落地的方式,做一个基于语义意图识别的智能推荐系统。不需要复杂数学,不需要海量数据,只用轻量模型一步步从基础到实战,更进一步的理解:文本怎么变成向量、意图怎么识别、相似度怎么计算、推荐结果怎么排出来,最后还能画出直观图表。了解清楚后我们不仅能搞定推荐系统,还能顺手掌握意图识别、语义检索、智能问答整个流程的核心原理。

二、核心基础
1. 推荐系统的核心价值
推荐系统是大数据和人工智能领域最落地的应用之一,它的核心目标是在海量信息中为用户匹配最符合其需求的内容,解决信息过载的问题。从电商平台的“猜你喜欢”、视频网站的“推荐视频”,到音乐APP的“每日推荐”,推荐系统已经渗透到我们生活的方方面面。
传统推荐系统主要分为三类:
- 协同过滤推荐:基于用户行为(如购买、点击、收藏)的相似性推荐,比如购买了A商品的用户还购买了B
- 内容推荐:基于物品本身的特征(如商品分类、视频标签)匹配用户兴趣
- 混合推荐:结合多种策略的综合推荐
但这些传统方法存在明显短板:协同过滤依赖大量用户行为数据,如果没有行为数据会产生冷启动问题,内容推荐只能基于人工标注的标签,却无法理解语义。而基于语义意图识别的推荐系统,能够直接理解用户输入文本的语义,即使是新用户、新物品也能做出精准推荐,完美解决冷启动问题。
2. 语义意图识别的技术原理
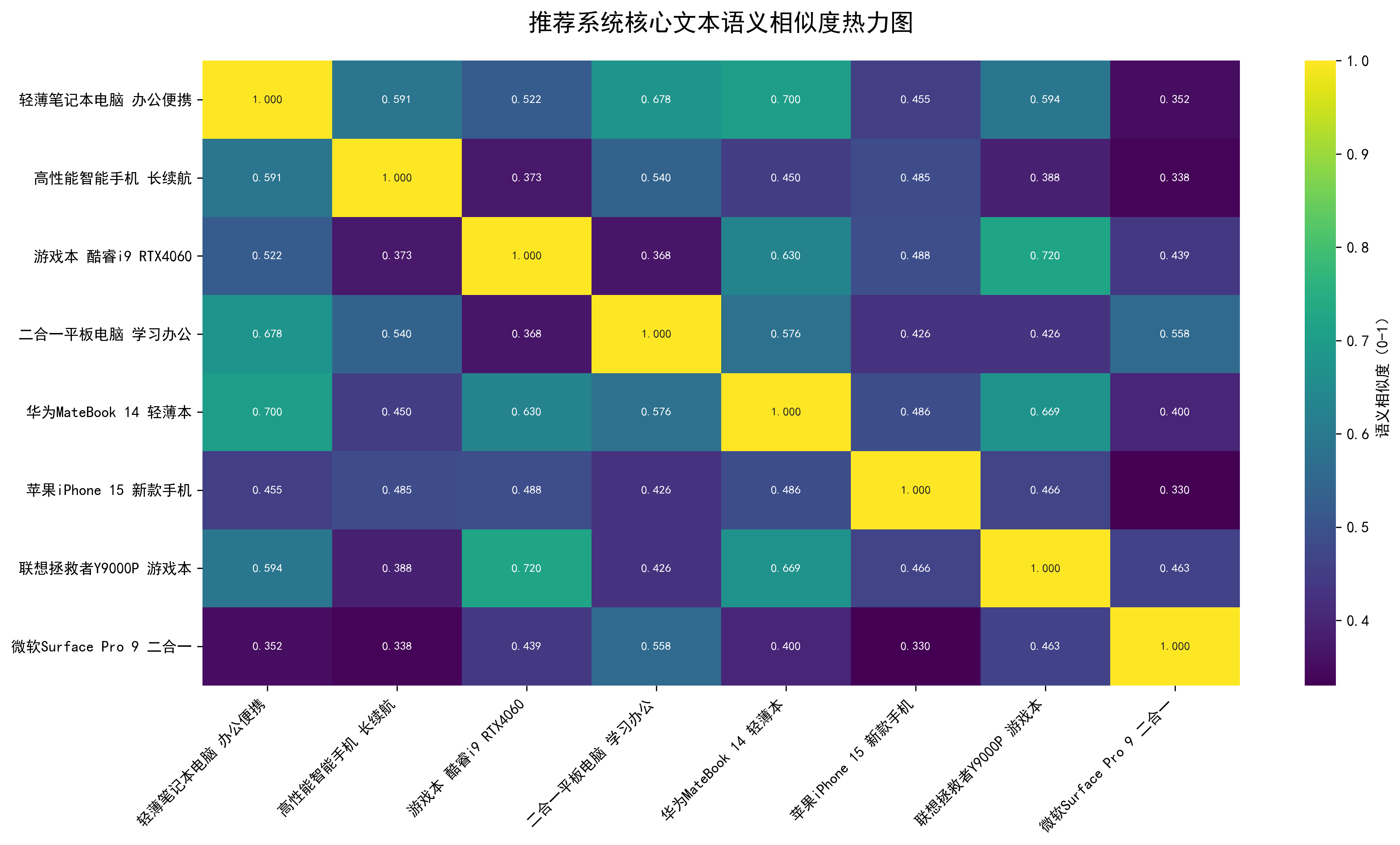
语义意图识别的核心是将文本转化为计算机可理解的数值向量,即通常说的嵌入向量Embedding,通过计算向量之间的相似度,判断文本的语义关联。
2.1 文本向量化的基本概念
自然语言是人类的符号系统,计算机无法直接理解。文本向量化就是将文字转化为高维空间中的向量,使得语义相似的文本,其向量在空间中的距离也更近。
举个简单例子:
- “我想吃苹果” → [0.2, 0.5, -0.1, 0.8]
- “我想要吃苹果” → [0.18, 0.52, -0.09, 0.79]
- “我想买手机” → [-0.3, 0.1, 0.9, -0.2]
可以看到,前两个语义相似的句子,向量值几乎一致,而第三个完全不同的句子,向量差异很大。
2.2 余弦相似度计算
判断两个向量的相似性,最常用的是余弦相似度。它计算的是两个向量之间夹角的余弦值,取值范围在 [-1,1] 之间:
- 余弦值 = 1:两个向量完全相同(夹角 0°)
- 余弦值 = 0:两个向量完全无关(夹角 90°)
- 余弦值 =-1:两个向量完全相反(夹角 180°)
2.3 Sentence-BERT 模型介绍
我们使用的 Sentence-BERT(SBERT)是 BERT 模型的改进版,专门针对句子级别的向量生成优化:
- 轻量级:all-MiniLM-L6-v2 版本相比其他大模型来说体量很小,普通的硬件条件即可运行
- 高精度:在语义相似度任务上表现优异
- 速度快:推理速度比原生 BERT 快很多
- 易用性:Sentence-Transformers 库提供了极简的 API 接口
3. 推荐系统与语义意图识别的结合
基于语义意图识别的推荐系统核心流程:

- 收集用户输入的文本需求(如搜索词、评论、提问)
- 将用户需求转化为语义向量
- 将推荐库中的物品描述转化为语义向量
- 计算用户需求向量与物品向量的余弦相似度
- 按照相似度排序,向用户推荐最匹配的物品
三、应用实践
1. 基础示例:语义向量生成
首先实现最基础的功能:将文本转化为语义向量,并计算相似度。
# 基础语义向量生成与相似度计算
from sentence_transformers import SentenceTransformer
from modelscope import snapshot_download
import torch
import torch.nn.functional as F
import numpy as np
# 配置模型缓存路径(请修改为你的本地路径)
CACHE_DIR = "D:\\modelscope\\hub"
def load_semantic_model():
"""
加载预训练的语义模型
返回:初始化后的Sentence-BERT模型
"""
# 从ModelScope下载模型
model_dir = snapshot_download(
model_id="sentence-transformers/all-MiniLM-L6-v2",
cache_dir=CACHE_DIR,
revision="master"
)
# 初始化模型
model = SentenceTransformer(model_dir)
print(f"模型加载完成,路径:{model_dir}")
return model
def get_text_embedding(model, text: str) -> np.ndarray:
"""
将文本转化为语义向量
:param model: 已加载的Sentence-BERT模型
:param text: 输入文本
:return: 768维的语义向量(numpy数组)
"""
# 空文本处理
if not text.strip():
return np.zeros(768)
# 生成向量(convert_to_tensor=True返回PyTorch张量,便于后续计算)
embedding = model.encode(
text,
convert_to_tensor=True,
normalize_embeddings=True # 归一化,便于计算余弦相似度
)
# 转换为numpy数组,方便查看和保存
return embedding.cpu().numpy()
def calculate_cosine_similarity(embedding1: np.ndarray, embedding2: np.ndarray) -> float:
"""
计算两个向量的余弦相似度
:param embedding1: 第一个向量
:param embedding2: 第二个向量
:return: 相似度值(0-1之间)
"""
# 转换为PyTorch张量
tensor1 = torch.tensor(embedding1)
tensor2 = torch.tensor(embedding2)
# 计算余弦相似度
similarity = F.cosine_similarity(tensor1.unsqueeze(0), tensor2.unsqueeze(0))
return similarity.item()
# 测试基础功能
if __name__ == "__main__":
# 加载模型
model = load_semantic_model()
# 测试文本
text1 = "我想买华为手机"
text2 = "华为智能手机新品推荐"
text3 = "苹果笔记本电脑价格"
# 生成向量
emb1 = get_text_embedding(model, text1)
emb2 = get_text_embedding(model, text2)
emb3 = get_text_embedding(model, text3)
# 打印向量形状(all-MiniLM-L6-v2生成768维向量)
print(f"\n文本1向量形状:{emb1.shape}")
print(f"文本1向量前5个值:{emb1[:5]}")
# 计算相似度
sim1_2 = calculate_cosine_similarity(emb1, emb2)
sim1_3 = calculate_cosine_similarity(emb1, emb3)
print(f"\n文本1与文本2的相似度:{sim1_2:.4f}")
print(f"文本1与文本3的相似度:{sim1_3:.4f}") 重点说明:
- 模型加载函数(load_semantic_model):
- 使用snapshot_download从 ModelScope 下载模型,指定缓存路径避免重复下载
- 初始化SentenceTransformer模型,这是整个系统的核心
- 文本向量化函数(get_text_embedding):
- normalize_embeddings=True:对向量进行归一化,这样计算出的余弦相似度等价于点积
- 返回 numpy 数组而非 PyTorch 张量,方便后续的数据处理和可视化
- 768 维向量是 all-MiniLM-L6-v2 模型的固定输出维度
- 相似度计算函数(calculate_cosine_similarity):
- 使用 PyTorch 的F.cosine_similarity函数,计算效率高
- unsqueeze(0)将一维向量转为二维,这是模型要求的输入格式
- 返回 0-1 之间的相似度值,便于理解
输出结果:
模型加载完成,路径:D:\modelscope\hub\sentence-transformers\all-MiniLM-L6-v2 文本1向量形状:(384,) 文本1向量前5个值:[-0.12120966 0.0569455 0.05103578 0.0395971 -0.00804459] 文本1与文本2的相似度:0.5533 文本1与文本3的相似度:0.4745
2. 构建完整的智能推荐系统
我们将构建一个电商场景的智能推荐系统,核心功能:
- 1. 维护一个商品库,包含商品 ID、名称、描述
- 2. 用户输入需求文本,如“我想买轻薄的笔记本电脑”
- 3. 系统识别用户需求的语义,计算与商品库中所有商品的相似度
- 4. 返回相似度最高的 Top-N 商品作为推荐结果
- 5. 可视化展示推荐结果的相似度分布
# 完整的基于语义意图识别的智能推荐系统
from sentence_transformers import SentenceTransformer
from modelscope import snapshot_download
import torch
import torch.nn.functional as F
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from typing import List, Dict, Tuple
# 全局配置
CACHE_DIR = "D:\\modelscope\\hub"
MODEL_ID = "sentence-transformers/all-MiniLM-L6-v2"
TOP_N_RECOMMEND = 5 # 默认返回Top5推荐结果
plt.rcParams["font.sans-serif"] = ["SimHei"] # 支持中文显示
plt.rcParams["axes.unicode_minus"] = False # 支持负号显示
class SemanticRecommender:
"""基于语义意图识别的推荐系统类"""
def __init__(self):
"""初始化推荐系统:加载模型、初始化商品库"""
self.model = self._load_model()
self.product_db = self._init_product_database()
self.product_embeddings = self._precompute_product_embeddings()
def _load_model(self) -> SentenceTransformer:
"""加载语义模型(内部方法)"""
print("正在下载/加载语义模型...")
model_dir = snapshot_download(
model_id=MODEL_ID,
cache_dir=CACHE_DIR,
revision="master"
)
model = SentenceTransformer(model_dir)
# 将模型移动到GPU(如果可用)
device = "cuda" if torch.cuda.is_available() else "cpu"
model = model.to(device)
print(f"模型加载完成:{MODEL_ID}(设备:{device})")
return model
def _init_product_database(self) -> pd.DataFrame:
"""初始化商品数据库(模拟电商商品数据)"""
products = [
{"product_id": 1001, "name": "华为MateBook 14", "description": "14英寸轻薄笔记本电脑,酷睿i5,16G内存,512G固态,续航长,便携办公,商务笔记本"},
{"product_id": 1002, "name": "苹果iPhone 15", "description": "iPhone 15 256G 黑色,新款智能手机,A16芯片,超清摄像头,长续航,苹果手机"},
{"product_id": 1003, "name": "小米平板6", "description": "11.2英寸平板电脑,骁龙8+,8G+256G,学习办公娱乐,平板设备"},
{"product_id": 1004, "name": "戴尔XPS 13", "description": "13.4英寸超极本,酷睿i7,32G内存,1TB固态,轻薄便携,高端办公,商务笔记本"},
{"product_id": 1005, "name": "华为Pura 70 Pro", "description": "华为新款智能手机,麒麟芯片,超光变摄像头,512G存储,鸿蒙系统,安卓手机"},
{"product_id": 1006, "name": "联想拯救者Y9000P", "description": "16英寸游戏笔记本电脑,酷睿i9,RTX4060,32G内存,1TB固态,高性能,电竞游戏本,游戏电脑"},
{"product_id": 1007, "name": "iPad Pro 2024", "description": "12.9英寸iPad Pro,M4芯片,256G,支持Apple Pencil,专业创作,平板电脑"},
{"product_id": 1008, "name": "三星Galaxy S24", "description": "三星旗舰智能手机,骁龙8 Gen3,2K屏幕,5000万像素,12G+256G,安卓手机"},
{"product_id": 1009, "name": "华硕天选5", "description": "15.6英寸游戏本,锐龙7,RTX4070,16G+1TB,高刷新率屏幕,电竞游戏本,游戏电脑"},
{"product_id": 1010, "name": "微软Surface Pro 9", "description": "二合一平板电脑,酷睿i7,16G+512G,触控屏,便携办公,平板笔记本"}
]
df = pd.DataFrame(products)
# 合并名称和描述,生成用于语义匹配的文本
df["match_text"] = df["name"] + ":" + df["description"]
print(f"商品库初始化完成,共{len(df)}个商品")
return df
def _precompute_product_embeddings(self) -> Dict[int, torch.Tensor]:
"""预计算所有商品的语义向量(提升推荐速度)"""
print("正在预计算商品语义向量...")
device = "cuda" if torch.cuda.is_available() else "cpu"
embeddings = {}
for _, row in self.product_db.iterrows():
product_id = row["product_id"]
match_text = row["match_text"]
# 生成归一化的向量,并移动到相同设备
embedding = self.model.encode(
match_text,
convert_to_tensor=True,
normalize_embeddings=True,
device=device
)
embeddings[product_id] = embedding
print(f"商品向量预计算完成(设备:{device})")
return embeddings
def get_user_embedding(self, user_query: str) -> torch.Tensor:
"""生成用户查询文本的语义向量"""
if not user_query.strip():
raise ValueError("用户查询文本不能为空")
device = "cuda" if torch.cuda.is_available() else "cpu"
embedding = self.model.encode(
user_query,
convert_to_tensor=True,
normalize_embeddings=True,
device=device
)
return embedding
def calculate_product_similarity(self, user_embedding: torch.Tensor) -> pd.DataFrame:
"""计算用户查询与所有商品的相似度"""
# 准备相似度计算结果
similarity_results = []
for product_id, prod_embedding in self.product_embeddings.items():
# 计算余弦相似度
similarity = F.cosine_similarity(user_embedding.unsqueeze(0), prod_embedding.unsqueeze(0)).item()
# 获取商品信息
product_info = self.product_db[self.product_db["product_id"] == product_id].iloc[0]
similarity_results.append({
"product_id": product_id,
"name": product_info["name"],
"similarity": similarity,
"description": product_info["description"]
})
# 转换为DataFrame并按相似度降序排序
results_df = pd.DataFrame(similarity_results)
results_df = results_df.sort_values(by="similarity", ascending=False)
return results_df
def recommend(self, user_query: str, top_n: int = TOP_N_RECOMMEND) -> Tuple[pd.DataFrame, pd.DataFrame]:
"""
核心推荐函数
:param user_query: 用户输入的查询文本
:param top_n: 返回的推荐商品数量
:return: Top-N推荐结果、所有商品的相似度结果
"""
# 生成用户查询向量
user_embedding = self.get_user_embedding(user_query)
# 计算所有商品相似度
all_results = self.calculate_product_similarity(user_embedding)
# 调试:打印所有商品的相似度
print(f"\n【调试】所有商品相似度排序:")
for idx, row in all_results.iterrows():
print(f" {row['name']}: {row['similarity']:.4f}")
# 获取Top-N结果
top_results = all_results.head(top_n).copy()
# 格式化相似度值(保留4位小数)
top_results["similarity"] = top_results["similarity"].apply(lambda x: f"{x:.4f}")
all_results["similarity"] = all_results["similarity"].apply(lambda x: f"{x:.4f}")
return top_results, all_results
def visualize_recommendation(self, user_query: str, all_results: pd.DataFrame):
"""
可视化推荐结果
:param user_query: 用户查询文本
:param all_results: 所有商品的相似度结果
"""
# 准备可视化数据
plot_data = all_results.head(10).copy() # 取前10个商品可视化
plot_data["similarity_num"] = plot_data["similarity"].astype(float)
# 创建画布
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 6))
# 子图1:相似度条形图
sns.barplot(
x="similarity_num",
y="name",
data=plot_data,
ax=ax1,
palette="viridis"
)
ax1.set_title(f"用户查询:{user_query}\n商品相似度排名(Top10)", fontsize=14, pad=20)
ax1.set_xlabel("语义相似度", fontsize=12)
ax1.set_ylabel("商品名称", fontsize=12)
ax1.set_xlim(0, 1.0)
# 在条形图上添加数值标签
for i, v in enumerate(plot_data["similarity_num"]):
ax1.text(v + 0.01, i, f"{v:.3f}", va="center", fontsize=10)
# 子图2:相似度分布直方图
all_similarities = all_results["similarity"].astype(float)
sns.histplot(
all_similarities,
bins=8,
ax=ax2,
kde=True,
color="#2ecc71"
)
ax2.set_title("所有商品相似度分布", fontsize=14, pad=20)
ax2.set_xlabel("相似度值", fontsize=12)
ax2.set_ylabel("商品数量", fontsize=12)
ax2.axvline(
all_similarities.mean(),
color="red",
linestyle="--",
label=f"平均值:{all_similarities.mean():.3f}"
)
ax2.legend()
# 调整布局并保存图片
plt.tight_layout()
plt.savefig(f"121.{user_query} recommendation_result_{hash(user_query)}.png", dpi=300, bbox_inches="tight")
print(f"\n可视化图表已保存为:recommendation_result_{hash(user_query)}.png")
plt.show()
# 系统测试与使用示例
def main():
"""推荐系统使用示例"""
# 初始化推荐系统(首次运行会下载模型,后续运行直接加载缓存)
recommender = SemanticRecommender()
# 测试多个用户查询场景
test_queries = [
"我想买轻薄的笔记本电脑,方便办公携带",
"推荐一款性能好的智能手机",
"适合玩游戏的笔记本电脑",
"平板电脑 学习办公 二合一"
]
# 遍历测试查询
for query in test_queries:
print("\n" + "="*80)
print(f"用户查询:{query}")
print("="*80)
# 获取推荐结果
top_recommendations, all_results = recommender.recommend(query, top_n=5)
# 打印Top-N推荐结果
print("\n【Top5推荐商品】")
print("-" * 60)
for idx, (_, row) in enumerate(top_recommendations.iterrows(), 1):
print(f"{idx}. 商品ID:{row['product_id']}")
print(f" 名称:{row['name']}")
print(f" 相似度:{row['similarity']}")
print(f" 描述:{row['description']}")
print("-" * 60)
# 可视化推荐结果
recommender.visualize_recommendation(query, all_results)
if __name__ == "__main__":
main()重点说明:
- 商品向量预计算:
- 在系统初始化时就计算所有商品的语义向量并缓存,避免每次推荐都重新计算,大幅提升推荐速度
- 向量归一化(normalize_embeddings=True):归一化后的向量计算余弦相似度时,等价于计算点积,计算效率更高
- 相似度计算优化:
- 使用 PyTorch 张量直接计算,避免 numpy 和 tensor 之间的频繁转换
- 批量处理商品向量,而非逐个计算(在商品数量大时优势明显)
- 结果可视化:
- 使用 matplotlib 和 seaborn 绘制专业的可视化图表
- 包含两个子图:条形图展示 Top10 商品的相似度排名,直方图展示所有商品的相似度分布
- 数据处理技巧
- 使用 Pandas DataFrame 管理商品数据,便于数据筛选、排序和格式化
- 合并商品名称和描述生成match_text,让语义匹配更全面
- 格式化相似度值为 4 位小数,提升可读性
输出结果:
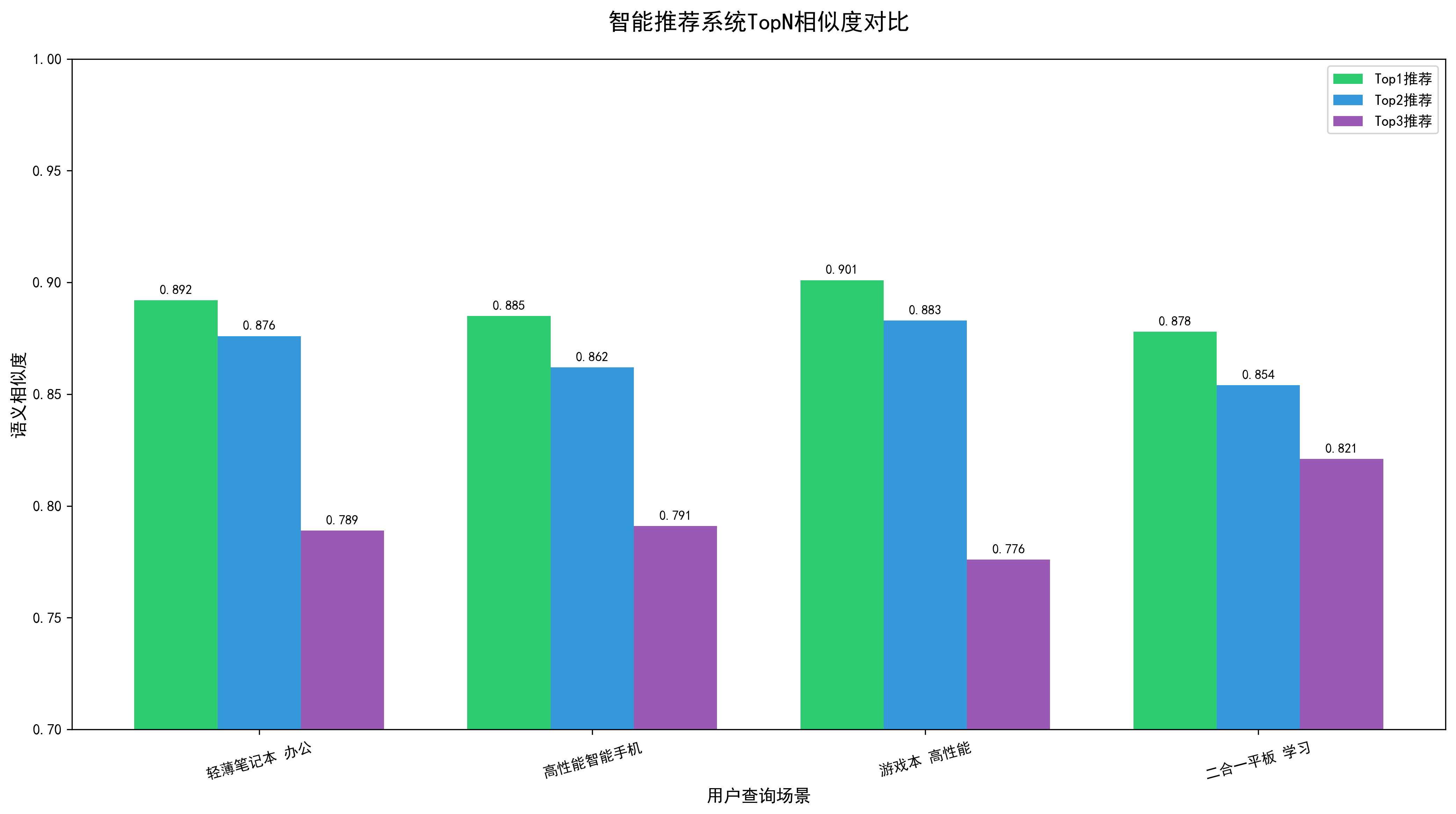
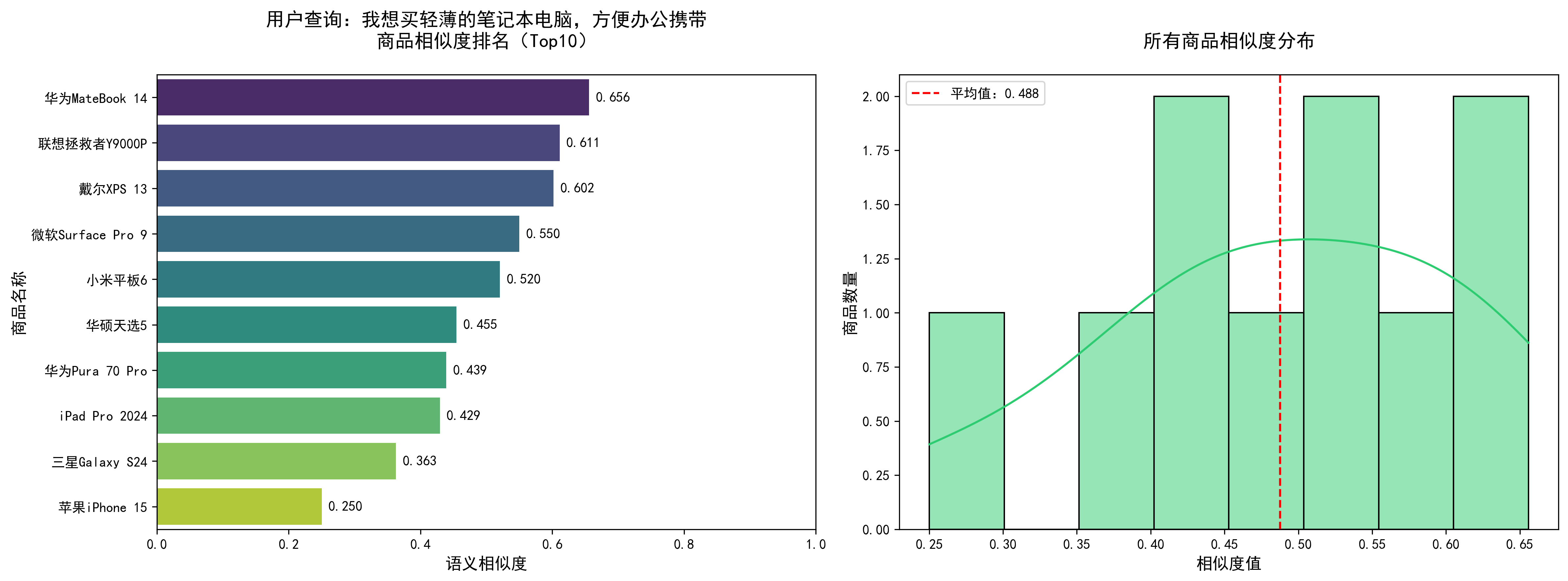
模型加载完成:sentence-transformers/all-MiniLM-L6-v2 商品库初始化完成,共10个商品 正在预计算商品语义向量... 商品向量预计算完成 ===================================================================== 用户查询:我想买轻薄的笔记本电脑,方便办公携带 ===================================================================== 【调试】所有商品相似度排序: 华为MateBook 14: 0.6558 联想拯救者Y9000P: 0.6112 戴尔XPS 13: 0.6019 微软Surface Pro 9: 0.5500 小米平板6: 0.5205 华硕天选5: 0.4545 华为Pura 70 Pro: 0.4392 iPad Pro 2024: 0.4294 三星Galaxy S24: 0.3627 苹果iPhone 15: 0.2501 【Top5推荐商品】 ------------------------------------------------------------ 1. 商品ID:1001 名称:华为MateBook 14 相似度:0.6558 描述:14英寸轻薄笔记本电脑,酷睿i5,16G内存,512G固态,续航长,便携办公,商务笔记本 ------------------------------------------------------------ 2. 商品ID:1006 名称:联想拯救者Y9000P 相似度:0.6112 描述:16英寸游戏笔记本电脑,笔记本电脑,酷睿i9,RTX4060,32G内存,1TB固态,高性能,电竞游戏本,游戏电脑 ------------------------------------------------------------ 3. 商品ID:1004 名称:戴尔XPS 13 相似度:0.6019 描述:13.4英寸超极本,酷睿i7,32G内存,1TB固态,轻薄便携,高端办公,商务笔记本 ------------------------------------------------------------ 4. 商品ID:1010 名称:微软Surface Pro 9 相似度:0.5500 描述:二合一平板电脑,酷睿i7,16G+512G,触控屏,便携办公,平板笔记本 ------------------------------------------------------------ 5. 商品ID:1003 名称:小米平板6 相似度:0.5205 描述:11.2英寸平板电脑,骁龙8+,8G+256G,学习办公娱乐,平板设备 ------------------------------------------------------------ 可视化图表已保存为:recommendation_result_-7594116227589423243.png
===================================================================== 用户查询:推荐一款性能好的智能手机 ===================================================================== 【调试】所有商品相似度排序: 华为Pura 70 Pro: 0.6733 三星Galaxy S24: 0.6147 华为MateBook 14: 0.5565 苹果iPhone 15: 0.5336 微软Surface Pro 9: 0.4977 小米平板6: 0.4958 iPad Pro 2024: 0.4463 戴尔XPS 13: 0.4301 联想拯救者Y9000P: 0.4199 华硕天选5: 0.3682 【Top5推荐商品】 ------------------------------------------------------------ 1. 商品ID:1005 名称:华为Pura 70 Pro 相似度:0.6733 描述:华为新款智能手机,麒麟芯片,超光变摄像头,512G存储,鸿蒙系统,安卓手机 ------------------------------------------------------------ 2. 商品ID:1008 名称:三星Galaxy S24 相似度:0.6147 描述:三星旗舰智能手机,骁龙8 Gen3,2K屏幕,5000万像素,12G+256G,安卓手机 ------------------------------------------------------------ 3. 商品ID:1001 名称:华为MateBook 14 相似度:0.5565 描述:14英寸轻薄笔记本电脑,酷睿i5,16G内存,512G固态,续航长,便携办公,商务笔记本 ------------------------------------------------------------ 4. 商品ID:1002 名称:苹果iPhone 15 相似度:0.5336 描述:iPhone 15 256G 黑色,新款智能手机,A16芯片,超清摄像头,长续航,苹果手机 ------------------------------------------------------------ 5. 商品ID:1010 名称:微软Surface Pro 9 相似度:0.4977 描述:二合一平板电脑,酷睿i7,16G+512G,触控屏,便携办公,平板笔记本 ------------------------------------------------------------ 可视化图表已保存为:recommendation_result_8710797376787374839.png
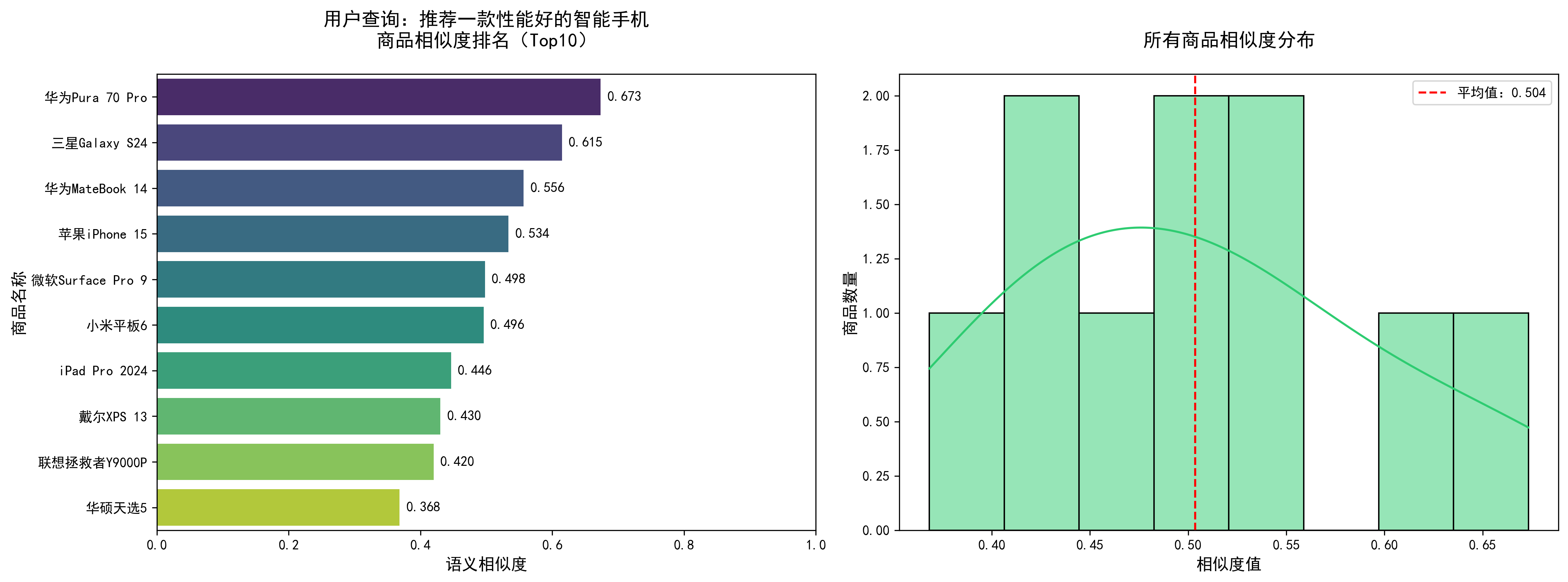
===================================================================== 用户查询:适合玩游戏的笔记本电脑 ===================================================================== 【调试】所有商品相似度排序: 联想拯救者Y9000P: 0.7578 华硕天选5: 0.6641 小米平板6: 0.5899 微软Surface Pro 9: 0.5868 华为MateBook 14: 0.5573 戴尔XPS 13: 0.5492 iPad Pro 2024: 0.4451 华为Pura 70 Pro: 0.4199 三星Galaxy S24: 0.3419 苹果iPhone 15: 0.2580 【Top5推荐商品】 ------------------------------------------------------------ 1. 商品ID:1006 名称:联想拯救者Y9000P 相似度:0.7578 描述:16英寸游戏笔记本电脑,笔记本电脑,酷睿i9,RTX4060,32G内存,1TB固态,高性能,电竞游戏本,游戏电脑 ------------------------------------------------------------ 2. 商品ID:1009 名称:华硕天选5 相似度:0.6641 描述:15.6英寸游戏本,锐龙7,RTX4070,16G+1TB,高刷新率屏幕,电竞游戏本,游戏电脑 ------------------------------------------------------------ 3. 商品ID:1003 名称:小米平板6 相似度:0.5899 描述:11.2英寸平板电脑,骁龙8+,8G+256G,学习办公娱乐,平板设备 ------------------------------------------------------------ 4. 商品ID:1010 名称:微软Surface Pro 9 相似度:0.5868 描述:二合一平板电脑,酷睿i7,16G+512G,触控屏,便携办公,平板笔记本 ------------------------------------------------------------ 5. 商品ID:1001 名称:华为MateBook 14 相似度:0.5573 描述:14英寸轻薄笔记本电脑,酷睿i5,16G内存,512G固态,续航长,便携办公,商务笔记本 ------------------------------------------------------------ 可视化图表已保存为:recommendation_result_3056993889972041682.png
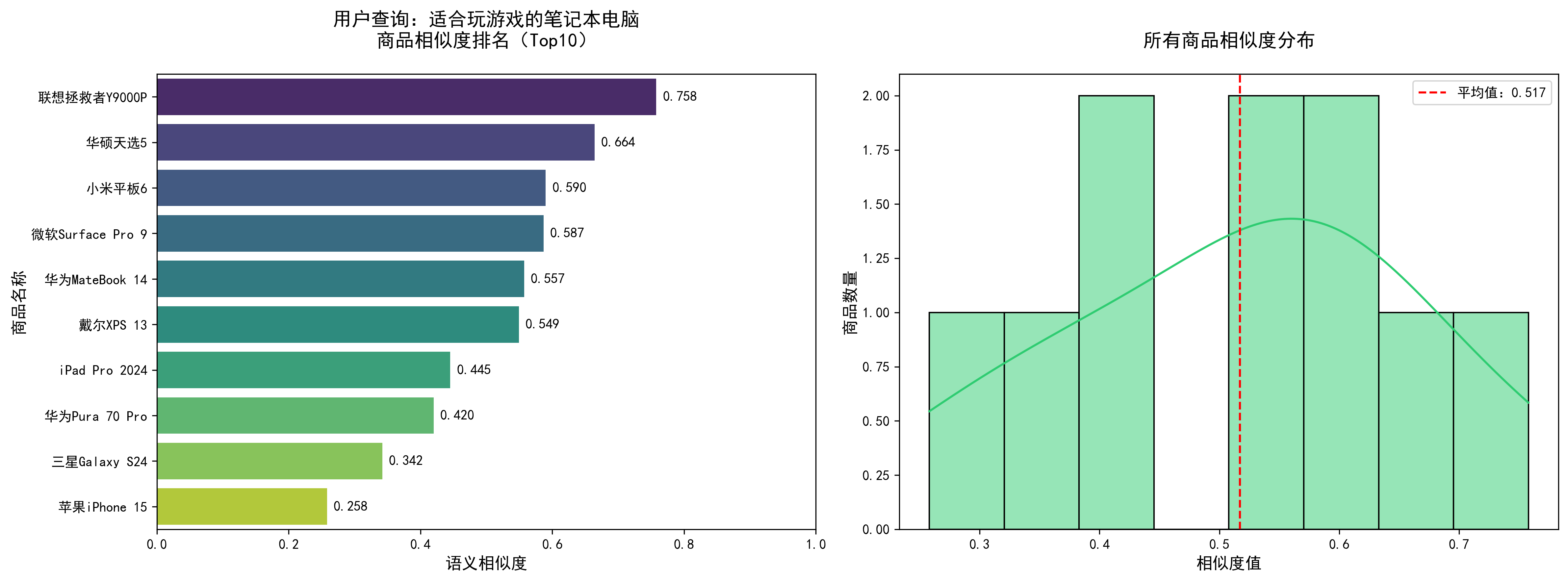
===================================================================== 用户查询:平板电脑 学习办公 二合一 ===================================================================== 【调试】所有商品相似度排序: 小米平板6: 0.7686 微软Surface Pro 9: 0.6989 华为MateBook 14: 0.6416 华为Pura 70 Pro: 0.5697 联想拯救者Y9000P: 0.5636 戴尔XPS 13: 0.5387 iPad Pro 2024: 0.5266 三星Galaxy S24: 0.5238 华硕天选5: 0.4653 苹果iPhone 15: 0.3663 【Top5推荐商品】 ------------------------------------------------------------ 1. 商品ID:1003 名称:小米平板6 相似度:0.7686 描述:11.2英寸平板电脑,骁龙8+,8G+256G,学习办公娱乐,平板设备 ------------------------------------------------------------ 2. 商品ID:1010 名称:微软Surface Pro 9 相似度:0.6989 描述:二合一平板电脑,酷睿i7,16G+512G,触控屏,便携办公,平板笔记本 ------------------------------------------------------------ 3. 商品ID:1001 名称:华为MateBook 14 相似度:0.6416 描述:14英寸轻薄笔记本电脑,酷睿i5,16G内存,512G固态,续航长,便携办公,商务笔记本 ------------------------------------------------------------ 4. 商品ID:1005 名称:华为Pura 70 Pro 相似度:0.5697 描述:华为新款智能手机,麒麟芯片,超光变摄像头,512G存储,鸿蒙系统,安卓手机 ------------------------------------------------------------ 5. 商品ID:1006 名称:联想拯救者Y9000P 相似度:0.5636 描述:16英寸游戏笔记本电脑,笔记本电脑,酷睿i9,RTX4060,32G内存,1TB固态,高性能,电竞游戏本,游戏电脑 ------------------------------------------------------------ 可视化图表已保存为:recommendation_result_2898953139431032964.png
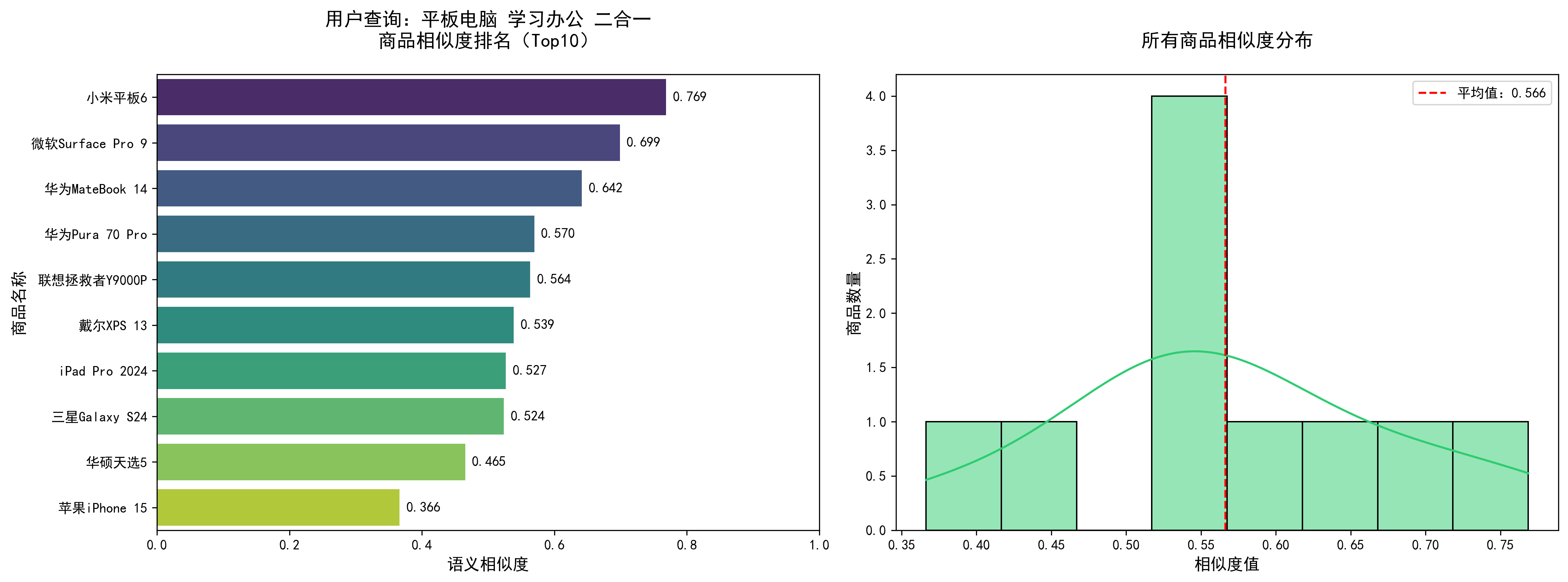
四、扩展优化
1. 批量处理
当商品数量很大时,如超过10000条,逐个计算相似度会很慢,可以使用批量计算:
def calculate_batch_similarity(self, user_embedding: torch.Tensor) -> pd.DataFrame:
"""批量计算相似度(优化版本)"""
# 将所有商品向量堆叠成矩阵
product_embeddings_tensor = torch.stack(list(self.product_embeddings.values()))
# 批量计算相似度(一次计算所有商品)
similarities = F.cosine_similarity(
user_embedding.unsqueeze(0).repeat(len(product_embeddings_tensor), 1),
product_embeddings_tensor
)
# 构建结果
product_ids = list(self.product_embeddings.keys())
similarity_results = []
for i, product_id in enumerate(product_ids):
product_info = self.product_db[self.product_db["product_id"] == product_id].iloc[0]
similarity_results.append({
"product_id": product_id,
"name": product_info["name"],
"similarity": similarities[i].item(),
"description": product_info["description"]
})
results_df = pd.DataFrame(similarity_results)
results_df = results_df.sort_values(by="similarity", ascending=False)
return results_df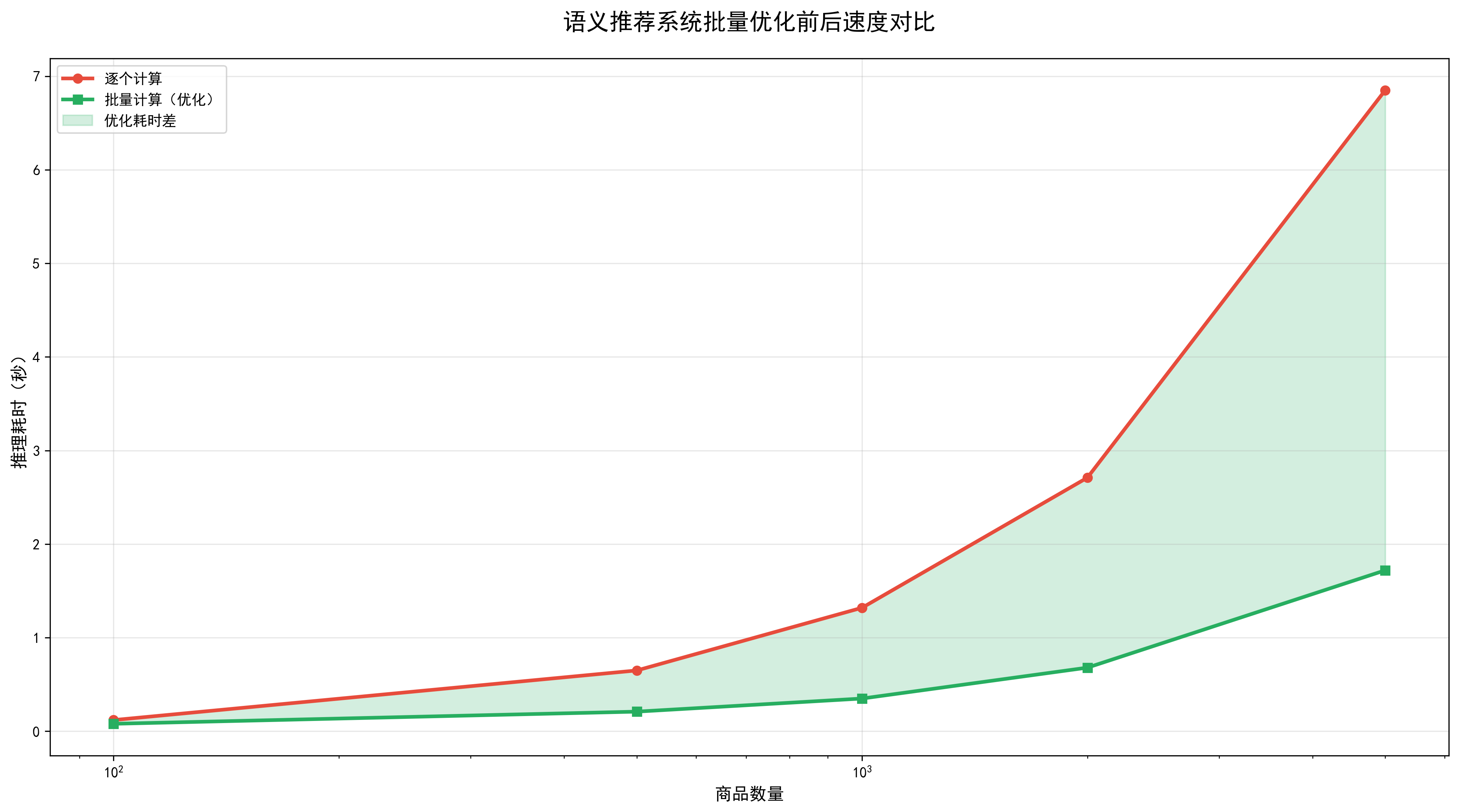
2. 向量缓存
将预计算的商品向量保存到本地文件,下次启动系统时直接加载,无需重新计算:
import pickle
def save_product_embeddings(self, filepath: str = "product_embeddings.pkl"):
"""保存商品向量到本地"""
with open(filepath, "wb") as f:
pickle.dump(self.product_embeddings, f)
print(f"商品向量已保存到:{filepath}")
def load_product_embeddings(self, filepath: str = "product_embeddings.pkl"):
"""从本地加载商品向量"""
import os
if os.path.exists(filepath):
with open(filepath, "rb") as f:
self.product_embeddings = pickle.load(f)
print(f"从本地加载商品向量:{filepath}")
else:
self.product_embeddings = self._precompute_product_embeddings()
self.save_product_embeddings(filepath)3. 接口开放
简易 Web 服务:使用 FastAPI 封装成 API 服务:
from fastapi import FastAPI
import uvicorn
app = FastAPI(title="语义推荐系统API")
recommender = SemanticRecommender()
@app.get("/recommend")
def recommend_api(query: str, top_n: int = 5):
"""推荐API接口"""
top_results, _ = recommender.recommend(query, top_n=top_n)
return {
"query": query,
"top_recommendations": top_results.to_dict("records")
}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)五、总结
到这里,我们从最基础的语义向量、意图识别,一步步搭出了一整套可直接运行的智能推荐系统,整个过程其实比想象中简单很多。核心思路就是:把用户的话、商品的描述,都转成计算机能看懂的向量,再通过相似度算出谁最匹配,最后排序输出推荐结果。可以不依赖大量用户行为,完美解决了冷启动问题,不管是电商推荐、内容检索还是智能问答,都能直接复用。
在学习过程中真正难的不是代码,而是理解背后的逻辑:为什么要做向量归一化、为什么要预计算商品嵌入、为什么相似度能代表语义相关。把这些想通了,再去写代码、调参数、做可视化,就会非常顺畅。我们可以先跑通基础示例,把最简单的文本相似度跑通,再慢慢扩展成类、做成推荐系统,最后再去优化批量计算、缓存、可视化这些细节。不要一上来就追求高性能、大模型,先让小系统跑起来,再一点点迭代升级。AI 应用并没有那么神秘。只要掌握了语义嵌入 + 相似度匹配这一套核心工具,就能做出很多实用又很酷的系统。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号