NCP-AIN 备考(4):AI 数据中心设计之GPU 间通信优化

NCP-AIN 备考(4):AI 数据中心设计之GPU 间通信优化

GPUS Lady
发布于 2026-05-29 12:29:08
发布于 2026-05-29 12:29:08

本课程隶属于英伟达认证专业人工智能网络工程师(NCP-AIN)培训体系,带你掌握面向人工智能业务的高性能网络拓扑设计与优化方法。
NCP-AIN 是英伟达专业级 AI 网络认证,全称 AI Networking。该认证考核从业者运用英伟达高速网络技术,部署、配置与运维 AI 数据中心网络环境的能力。
(考试信息可以访问:https://www.nvidia.cn/training/certification/ai-networking-professional/)
非NVIDIA官方课程,仅供参考学习。
NCP-AIN 备考(2):人工智能数据中心打造AI算力工厂
欢迎参加本次关于人工智能数据中心设计与优化的培训。
今天,我们将探索GPU间通信的关键领域,它是现代人工智能工厂的命脉。
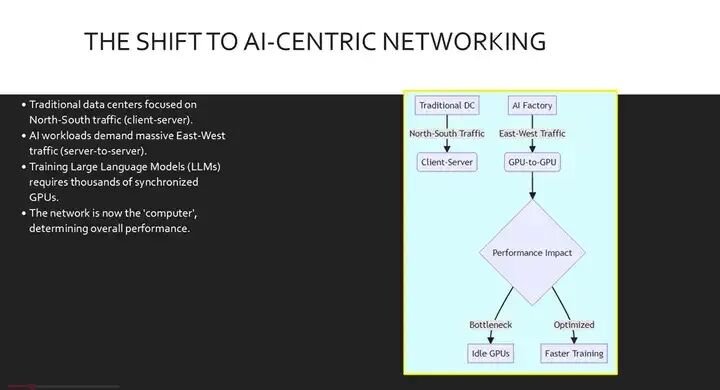
在传统的云数据中心中,主要的流量模式是南北向的,这意味着数据在数据中心内外流动,用户和应用程序之间传输。然而,人工智能时代从根本上改变了这种模式。现在,我们面对的是专为大规模工作流设计的人工智能工厂,例如训练大型语言模型。这些工作流计算密集,需要分布式计算,将单个作业拆分到数千个GPU上执行。因此,主要的流量模式变成了东西向或服务器间通信。在这种环境下,网络不再仅仅是一条管道,它实际上变成了计算机本身。如果网络出现瓶颈,昂贵的GPU就会闲置,浪费时间和资源。上图展示了网络流量的根本性转变。左侧是传统的南北向流量主导的模型。右侧是AI工厂模型,其中东西向的GPU间流量占据主导地位。请注意关键的决策点。这种东西向通信的质量直接决定了GPU是闲置还是能够实现更快的训练速度。
我们由此了解到,网络设计现在与计算能力同等重要。
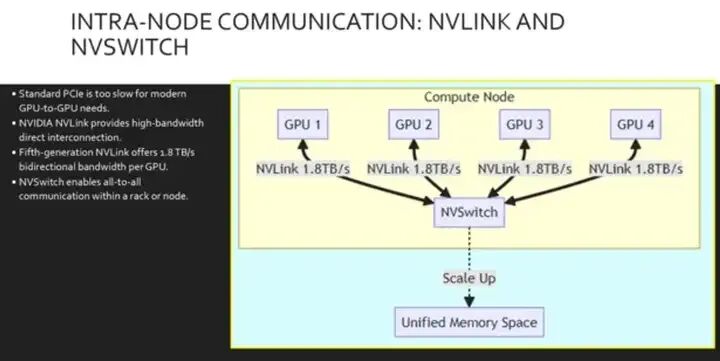
在考虑更广泛的网络之前,我们必须优化服务器节点内部的通信。标准的PCIe接口根本无法处理GPU高效共享内存和计算所需的带宽。为了解决这个问题,我们使用NVIDIA NVLink,一种高速纵向扩展的互连技术。第五代NVLink每个GPU可提供高达1.8TB/s的双向吞吐量,是PCIe Gen Punch带宽的14倍以上。为了连接多个GPU,我们使用NVSwitch。这款芯片连接多个 NV 链路,以全速提供完全的全对全通信,使一整排 GPU 能够作为一个单一的 大型加速器运行。
这里我们可视化 节点内部拓扑结构。请注意,每个 GPU 如何通过 NV 链路直接连接到 NVSwitch , 绕过速度较慢的 PCIe 总线进行点对点流量传输。 这创建了一个高带宽网状结构,数据 以 1.8TB/s的速率在 GPU 之间自由流动, 有效地创建了一个统一的内存 空间。这种结构对于模型并行至关重要, 因为单个 AI 模型太大,无法在单个 GPU 上运行。
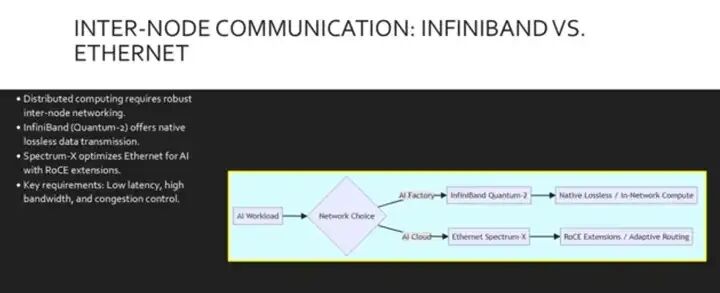
一旦流量离开节点,我们就进入 节点间网络领域。
对于 AI 工厂,Nvidia Quantum 2 Infiniband 通常是首选平台, 因为它具有超低延迟、 自愈能力和对网络内计算的原生 支持。 然而,许多 AI 云平台更倾向于使用以太网。 标准以太网存在丢包,并且并非 专为 AI 关键耦合工作负载而设计。 为了弥合这一差距,NVIDIA Spectrum X 平台通过融合以太网 RoCE 扩展增强了以太网的 RDMA 功能。 它为以太网引入了自适应路由和拥塞控制,从而提供了多租户 AI 云所需的性能隔离。
此流程图可帮助您选择合适的架构。 如果您正在构建专用 AI 工厂,则应选择 InfiniBand Quantum 2,因为它具有原生无损功能以及网络计算方面的 特性,例如 Sharp。 如果您正在构建多租户 AI 云,则应选择通过 Spectrum X 连接的以太网,它为标准以太网添加了 ROC 和自适应路由等必要功能。
我们了解到, 这两个部分都旨在通过不同的协议来解决拥塞和延迟问题。
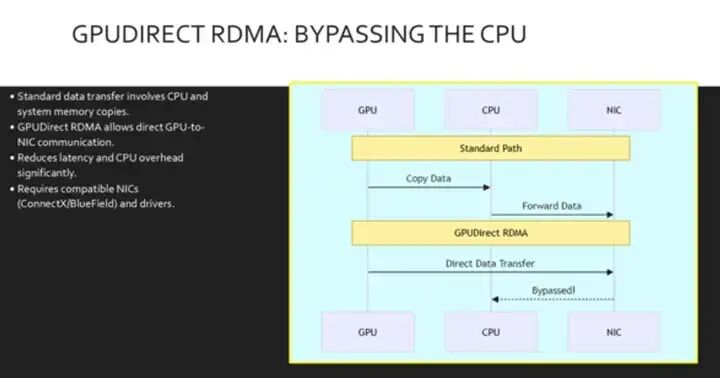
在标准网络中, 将数据从 GPU 移动到网络 首先需要将数据复制到 CPU 的系统 内存。这会增加延迟并 消耗宝贵的 CPU 周期。GPU 直接 RDMA 远程直接内存访问 消除了这一瓶颈。它允许 网络接口卡 (NIC) 直接访问 GPU 的内存。这创建了一条直接的数据交换路径,在 GPU 和对等设备之间,使用标准的 PCI Express 功能进行数据交换。通过将CPU 从 GPU 之间的 GPU 通信中完全卸载, 网络通信显著降低了通信延迟。
此序列图 对比了两种传输方法。顶部部分显示了 标准路径,数据必须从 GPU 跳转到 CPU 再跳转到 NIC,从而引入延迟。底部部分演示了 GPU 直接 RDMA,其中 GPU 直接将数据发送到 NIC。请注意,CPU 如何被完全 绕过, 使其可以用于其他 任务并加速数据流水线。这种机制对于 高性能训练和推理至关重要。
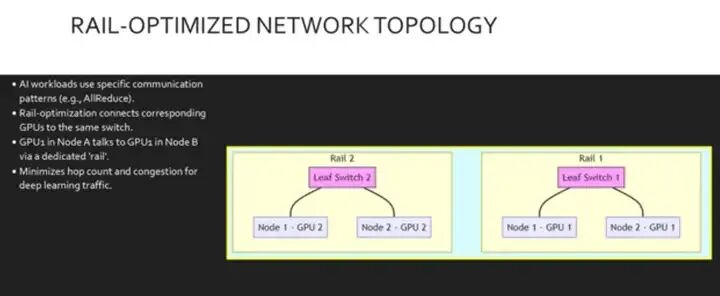
拓扑结构很重要。人工智能集群通常 采用轨道优化设计,而不是标准的叶脊式配置。
在深度学习中,诸如所有 reduce 之类的操作需要跨 不同节点的特定 GPU 进行同时通信。在轨道优化拓扑中,我们确保例如每个服务器上的 GPU 1 都连接到同一个 叶交换机。这为该 GPU 等级创建了一条专用的 轨道。这种设计 确保不同节点中 对应 GPU 之间的流量 通常只需经过零个或极少的 额外交换机,从而显著 降低拥塞和延迟, 与传统设计相比。此图 可视化了集群中的两条轨道。 请注意,左侧的叶交换机 1 仅从 节点 1 和 节点 2 连接到 GPU 1。节点 1 的叶交换机 仅从 两个节点连接到 GPU 2。这种物理隔离 意味着 GPU 1 的流量永远不会与 GPU 2 的流量争夺带宽。
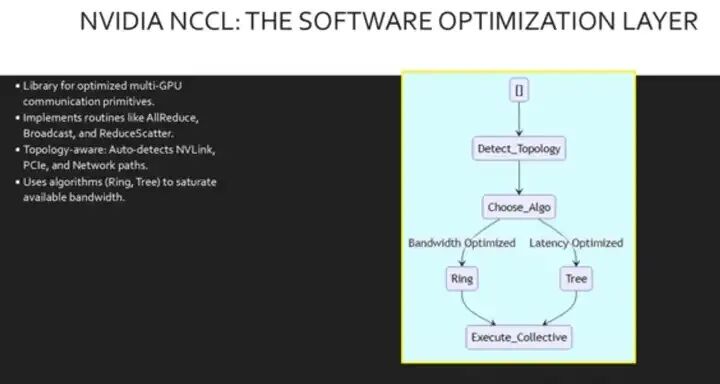
这种并行的高速网络系统就是我们所说的轨道优化拓扑结构。硬件 需要软件来驱动它。NVIDIA 集体通信库 (NCCL) 是 GPU 间通信的标准。 NCCL 为集体操作(例如所有归约和广播操作)提供了优化的原语,这些操作对深度学习至关重要。 至关重要的是, NCCL 具有拓扑感知能力。它会自动 检测可用的硬件路径,无论是 PCIe、NVLink、Infiniband 还是 RoCE,并选择最高效的算法(例如环形或树形)来传输数据。 这使得开发人员能够跨节点扩展应用程序,而无需手动针对特定硬件配置进行调整。
这里我们看到了 NCCL 的决策过程。它首先检测底层拓扑结构, 确定 NVLink 或 Infiniband 是否可用。 基于此,系统会进行如下转换: 选择算法,在环形算法(通常带宽最优)和树形算法(通常延迟最优)之间进行选择。 最后,执行集体操作。
此自动化流程确保 您的应用程序始终高效地利用底层硬件。
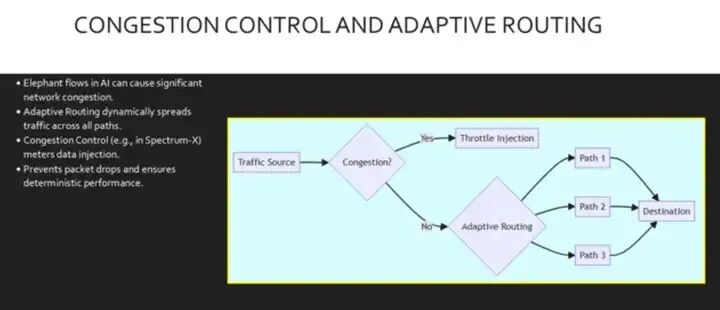
AI工作负载会生成大量数据流,这些数据流持续时间长且数量庞大,很容易阻塞静态网络路径。 为了解决这个问题,我们使用自适应路由。与静态哈希和 ECMP 不同,自适应路由会动态地为每个数据包选择拥塞程度最低的路径,从而确保链路利用率均衡。
此外,NVIDIA Spectrum X 等技术实现了细粒度的拥塞控制。 通过使用遥测技术在超级网卡级别计量数据注入速率, 我们可以防止缓冲区溢出和数据包丢失。 这确保了可预测的 AI 训练时间所需的确定性性能。 此图展示了实现稳定性的双管齐下方法。 首先,系统会检查拥塞情况。 如果检测到流量,是的,它会在源头限制注入。如果流量正常,则不会, 自适应路由会接管,动态地将数据包分发到路径 1、2 和 3 上。这避免了静态路由可能造成的热点,确保所有带宽都得到有效利用,从而到达目的地。
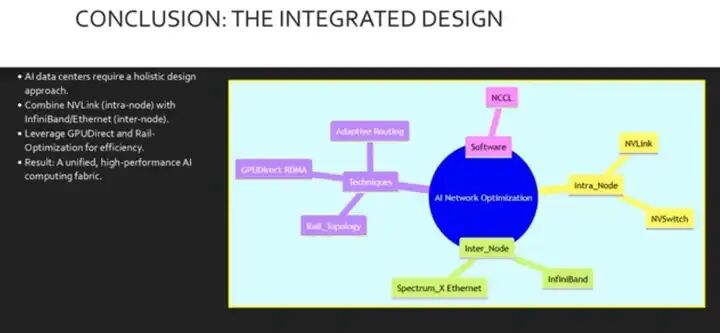
总之,优化 GPU 通信需要一种整体方法。这不仅仅是关于一根电缆或交换机。它涉及将高速节点内连接(例如 NVL 链路)与强大的节点间架构(例如 InfiniBand 或 Spectrox 以太网)相结合。我们必须利用 GPU 直接 RDMA 等技术来绕过 CPU 瓶颈,并设计轨道优化的拓扑结构,使物理布线与逻辑流量模式保持一致。通过将这些硬件策略与 NCCL 等软件集成,我们创建了一个统一的高性能架构,能够高效地训练世界上最先进的 AI 模型。我们最终的思维导图总结了我们讨论的关键支柱。其根基在于人工智能网络 优化。由此延伸出 节点内部技术,例如 NVL 链路。 节点间选项,例如 InfiniBand 以及关键技术 包括轨道拓扑和 GPU 直连 最后是软件层,NCCL 将所有这些技术 连接在一起。理解 这些元素如何相互作用是 成功构建人工智能数据中心的关键。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号