别再用HTTP调用大模型了,大厂都在用Spring AI?


大家好,我是苏三,又跟大家见面了。
前言
最近有位小伙伴问了我一个问题:“三哥,我们现在项目中要接入大模型,我看网上很多教程都是直接用RestTemplate调用OpenAI或者DeepSeek的API,代码也简单,为啥大家都在说Spring AI更香呢?”
我当时笑了笑,问了他一句:你们项目上线后,老板突然说要把大模型从OpenAI换成国产的通义千问,你的代码要改多少行?
他想了一下,沉默了。
今天这篇文章,我就从HTTP调用的痛点出发,跟大家一起聊聊Spring AI。
希望对你会有所帮助。
一、为什么不建议“手写HTTP”?
先带大家感受一下,绝大多数Java开发者第一次接入大模型时都是怎么写的。
1.1 原生HTTP调用的“经典写法”
以调用DeepSeek API为例,使用原生RestTemplate的实现大致如下:
@RestController
public class NativeAIController {
// 密钥和地址硬编码,这是第一坑
private static final String API_KEY = "sk-xxxxxxxx";
private static final String API_URL = "https://api.deepseek.com/v1/chat/completions";
@GetMapping("/ai/chat")
public String chat(@RequestParam String msg) {
RestTemplate restTemplate = new RestTemplate();
// 1. 手动组装请求参数,结构一复杂就容易出错
Map<String, Object> requestBody = new HashMap<>();
requestBody.put("model", "deepseek-chat");
requestBody.put("messages", List.of(Map.of("role", "user", "content", msg)));
// 2. 手动构造请求头和鉴权信息
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
headers.setBearerAuth(API_KEY);
HttpEntity<Map<String, Object>> entity = new HttpEntity<>(requestBody, headers);
// 3. 发送请求并处理响应
try {
ResponseEntity<Map> response = restTemplate.exchange(
API_URL, HttpMethod.POST, entity, Map.class);
Map body = response.getBody();
if (body != null && body.containsKey("choices")) {
List<Map<String, Object>> choices = (List) body.get("choices");
Map<String, Object> choice = choices.get(0);
Map<String, Object> message = (Map) choice.get("message");
return (String) message.get("content");
}
return"未获取到有效响应";
} catch (RestClientException e) {
// 异常处理极其简陋
return"调用异常:" + e.getMessage();
}
}
}
这种代码,一个下午能写十个不同的大模型接口。
但是,我们来看这段代码隐藏的六个致命问题:
有些小伙伴可能会说,上面的代码看着也不复杂,我自己封装一下也能用。没错,如果你的项目只是个人Demo、临时验证或者在本地测试,这种写法足够用了。但一旦进入企业级生产环境,它的问题就会像定时炸弹一样一个个爆出来——密钥硬编码、异常处理随意、切换模型时层层改代码……这些坑我当年创业时踩了一个遍。
第一,密钥硬编码在代码中。 API Key直接写在源码里,代码一旦提交到Git仓库,密钥就彻底暴露了,这在企业开发中是绝对禁止的。
第二,请求参数硬编码。 每个模型的请求参数都不一样,OpenAI用messages,千问用input,文心一言又是另一套结构。切换模型时,你需要在所有调用处修改代码。
第三,异常处理形同虚设。 模型API不稳定是常态,超时、限流、服务降级都需要精细的重试和降级策略,这段代码碰到任何异常就直接崩溃了。
第四,没有连接池管理。 每次调用都new RestTemplate(),频繁建立TCP连接,高并发下资源消耗巨大。虽然RestTemplate内部有连接池,但这里连池都没配置好。
第五,响应处理极其脆弱。 JSON结构稍微变化,代码就直接抛异常。大模型API的响应结构经常会更新,每次更新都意味着全量回归测试。
第六,缺少可观测性。 没有埋点、没有日志、没有调用链追踪,线上出问题时根本没法定位。
1.2 尝试封装一下?没那么简单
有些小伙伴可能会说:那我封装一个工具类,把这些事情都抽象出来不就行了?
来,我们看看如果自己封装,需要做多少事:
public class LLMClient {
// 1. 线程安全的客户端复用
private final HttpClient httpClient;
// 2. 重试策略
private final RetryPolicy retryPolicy;
// 3. 限流器
private final RateLimiter rateLimiter;
// 4. 熔断器
private final CircuitBreaker circuitBreaker;
// 5. 连接池
private final ConnectionPool connectionPool;
// 6. 监控埋点
private final MeterRegistry meterRegistry;
// 7. 日志记录
private final Logger logger;
// 还有请求体构建、多模型适配、流式响应处理...代码轻松上百行
}
再看看Spring AI是怎么做的:
@Service
public class AIChatService {
private final ChatClient chatClient;
public String chat(String question) {
return chatClient.prompt(question).call().content();
}
}
三行代码,搞定全部。
这不是炫技,这是工程抽象的力量。
二、Spring AI:统一模型调用的“万金油”
2.1 框架简介
Spring AI是Spring官方于2024年正式发布的AI开发框架,旨在为Java开发者提供一套标准化、模块化的AI工具链。
Spring官方定位很清晰:降低AI开发门槛、统一Java AI生态、强化企业级AI应用支持。
经过2年迭代,Spring AI 1.0正式版于2025年5月发布,通过JSR-382标准认证,承诺API向后兼容至少三个大版本周期。
发布首周即获得超过15万次下载,GitHub星标数突破3.2万,支持20+种模型架构。
2.2 Spring AI如何实现统一抽象?
Spring AI的核心设计思想是四层抽象架构,从上到下层层封装,每层都解决特定的工程问题:
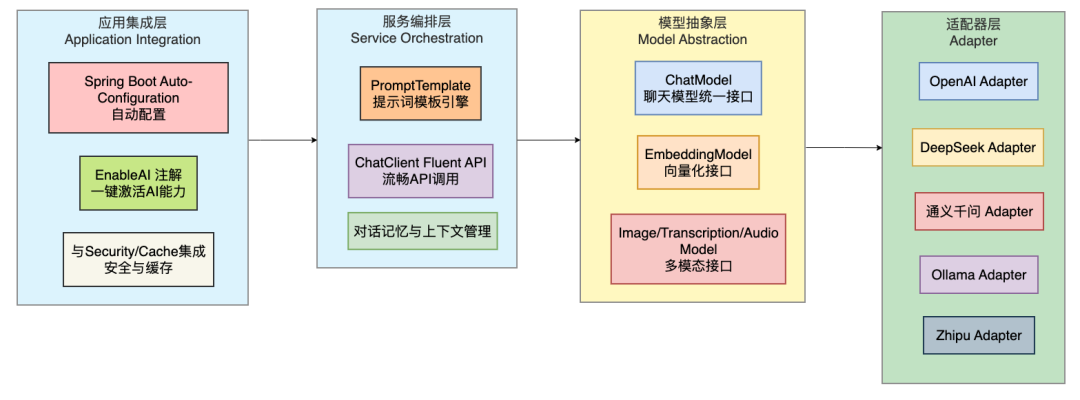
模型抽象层: 通过ChatModel、EmbeddingModel等顶层接口定义了与大模型交互的统一契约。无论底层是OpenAI还是Ollama,开发者都调用相同的方法。
适配器层: 各个厂商的适配器实现了这些接口,负责协议转换和差异抹平。Spring AI内置对OpenAI、Azure OpenAI、Anthropic Claude、阿里通义千问、Ollama(支持Llama 3等本地模型)等主流模型的支持。需要增加新模型?写一个新的适配器类即可,对业务代码零改动。
服务编排层: 提供ChatClient的Fluent API、PromptTemplate模板引擎以及对话上下文管理能力,让开发者用最简洁的链式语法完成AI调用。
应用集成层: 通过@EnableAI注解一键激活AI能力,自动配置注入AiClient、ModelRegistry等核心组件,与Spring Security实现模型访问控制。
2.3 统一配置:一套配置切换所有模型
这是Spring AI最令人惊叹的能力——通过配置文件即可无缝切换底层大模型:
# 方式一:OpenAI
spring:
ai:
openai:
api-key:${OPENAI_API_KEY}
model:gpt-4-turbo
# 方式二:只需换配置——DeepSeek(替换上述配置即可)
spring:
ai:
deepseek:
api-key:${DEEPSEEK_API_KEY}
model:deepseek-chat
# 方式三:本地模型(Ollama跑Llama 3)
spring:
ai:
ollama:
base-url:http://localhost:11434
model:llama3:8b
业务代码一行不用改!API Key通过环境变量注入,完全避免了硬编码问题。
2.4 ChatClient:给ChatModel穿上一层华丽的“外衣”
很多开发者会把ChatClient和ChatModel混为一谈,其实它们的定位完全不同:
ChatModel是底层接口,直接与大模型对话,返回原始响应ChatClient是高级封装,提供了Fluent API风格的流式接口,类似Spring WebClient/RestClient的写法
@Configuration
public class AIConfig {
@Bean
public ChatClient chatClient(ChatModel chatModel) {
return ChatClient.builder(chatModel)
.defaultSystem("你是一个专业的AI助手,请用中文回答。")
.defaultOptions(ChatOptions.builder()
.temperature(0.7)
.maxTokens(2000)
.build())
.build();
}
}
2.5 Function Calling:让大模型调用你的业务代码
在企业级应用中,一个最大的痛点是如何让大模型“调用”我们已有的业务代码——比如查库存、下单、查物流状态等。这就是Spring AI的Function Calling机制的用武之地。
@Component
@Description("根据订单号查询订单详情")
public class OrderQueryFunction implements Function<OrderQueryFunction.Request, OrderQueryFunction.Response> {
@Autowired
private OrderService orderService;
public record Request(@JsonProperty(required = true) String orderId) {}
public record Response(String status, BigDecimal amount, String deliveryTime) {}
@Override
public Response apply(Request request) {
Order order = orderService.getOrder(request.orderId());
return new Response(order.getStatus(), order.getAmount(), order.getDeliveryTime());
}
}
// 在ChatClient中注册工具
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultFunctions("queryOrder") // 注册工具
.build();
用户问“我的订单ORD-001到哪了”,Spring AI自动判断需要调用查询订单函数,将orderId传进去,拿到结果再返回。整个过程对用户透明。
三、手写HTTP vs Spring AI对比
对比总览速查表
维度 | 手写HTTP | Spring AI |
|---|---|---|
多模型支持 | 每个模型独立封装,切换模型需改多处代码 | 仅需修改配置文件,零代码改动 |
异常/重试/降级 | 手动实现,容易遗漏边界场景 | 框架内置,生产级别稳定 |
流式响应处理 | 手动处理SSE,门槛较高 | chatClient.prompt().stream()一行搞定 |
结构化输出 | JSON手动解析,脆弱且繁琐 | 自动反序列化为Java对象 |
Function Calling | 需自行设计API回调机制 | @Function注解自动注册 |
可观测性 | 需手动集成Micrometer | 原生支持Actuator端点 |
Spring生态集成 | 手动注入Bean | 自动配置,开箱即用 |
开发效率 | 每个接口平均50行样板代码 | 平均5行代码完成调用 |
3.1 多模型支持:差别最大的核心能力
- 手写HTTP:换模型意味着换一套请求体构造代码。从OpenAI换到通义千问,
messages要改成input,整段代码需要重写。 - Spring AI:所有模型通过
ChatModel统一接口暴露。更换底层模型只需在application.yml中修改配置,业务代码一行都不用改。一套代码,适配所有大模型,这才是真正的工程化。
3.2 工程化能力:框架 vs 自研
企业级应用需要重试、降级、熔断、限流、监控、审计这些非功能性能力。
曾经有一位创业的朋友跟我吐槽:他们自己封装的AI调用模块上线第一天就被流量冲垮了——没有限流熔断,几个大模型同时响应变慢,线程池直接打满,整个核心业务都挂了。重构花了两周,最后还是老老实实上了框架。
- 手写HTTP:重试机制需要手动实现指数退避策略,降级逻辑需要自行判断模型是否可用并切换到备用方案,熔断器要自己集成Hystrix或Resilience4j,限流器要自己实现令牌桶算法,监控埋点要手动上报到Prometheus。这一切加起来,轻松超过500行代码,而且每一行都需要经过充分的生产验证。
- Spring AI:重试通过
spring.retry自动配置,降级通过ModelRouter实现热备切换,熔断通过CircuitBreaker注解声明式配置,限流通过RateLimiter内置过滤器,监控通过Micrometer自动收集模型响应时间、错误率、Token消耗等指标。
3.3 流式响应处理
大语言模型的“流式输出”对于用户体验至关重要,但手写难度不低。
- 手写HTTP:需要处理SSE协议、管理EventSource连接、手动缓冲数据块、组装最终响应,代码复杂度倍增。
- Spring AI:
ChatClient的stream()方法和响应式编程模型一行代码搞定:
@GetMapping(value = "/chat/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> streamChat(@RequestParam String prompt) {
return chatClient.prompt(prompt).stream()
.map(chunk -> chunk.getResult().getOutput().getContent());
}
配合MediaType.TEXT_EVENT_STREAM_VALUE和前端EventSource,丝滑的流式对话体验即刻完成。
3.4 结构化输出:从String到强类型
在大模型应用中,从模型输出中提取结构化数据是极其常见的场景,比如情感分析、实体抽取等。
- 手写HTTP:收到String后通过Jackson/Gson手工解析,字段名对不上就抛异常。
- Spring AI:通过
StructuredOutputConverter和Java的Record类型,自动将模型输出映射为强类型对象。Spring AI甚至能自动处理格式不匹配的情况——如果AI返回的格式不对,它会自动调整提示词并要求重新生成,直到拿到正确的格式为止,这在Python里是Pydantic才能做到的:
public record SentimentResult(String label, double score) {}
BeanOutputConverter<SentimentResult> converter =
new BeanOutputConverter<>(SentimentResult.class);
String json = chatClient.prompt("用户评论:" + review + "。判断情感并返回JSON")
.call().content();
SentimentResult result = converter.convert(json);
// result.label -> "POSITIVE", result.score -> 0.95
3.5 Function Calling:企业应用的核心能力
Function Calling让大模型能够动态调用外部的业务API,是实现Agent智能体的核心技术。
- 手写HTTP:需要自行设计API回调路由、解析模型生成的函数调用请求、维护函数注册表、处理函数调用超时……每一项都是不小的挑战。
- Spring AI:只需实现
Function接口并加上@Description和@JsonProperty注解,Spring AI会自动完成函数注册、参数解析和调用路由的全流程。
3.6 RAG检索增强生成
RAG(Retrieval-Augmented Generation)是当前解决大模型知识时效性和幻觉问题的关键方案。
- 手写HTTP:需要构建完整的ETL管道实现文档切分和向量化,对接向量数据库进行相似度检索,设计混合检索策略优化召回效果,将检索结果与用户问题拼接到一起发送给模型。典型实现需要上千行代码,而且任何环节出问题都会影响最终效果。
- Spring AI:内置
VectorStore抽象层统一对接Elasticsearch、Milvus、PgVector等多种向量数据库,提供DocumentReader自动解析PDF/Word/Excel等格式,通过Retriever接口实现语义+关键词混合检索策略。配置好向量存储后,调用retrieveAndGenerate()即可完成增强生成,所有样板逻辑都由框架代劳。
3.7 对话记忆与上下文管理
大模型的真正价值在于多轮对话能力,这要求我们能够持续维护和传递上下文。
- 手写HTTP:开发者需要自行设计上下文存储方案(内存/Redis/数据库),手动将对话历史拼接进每次请求的
messages数组,当对话过长时还需要实现截断逻辑(保留最近的N条)防止Token溢出。这些看似简单的功能,实际实现时涉及大量边界条件处理。 - Spring AI:内置
ConversationContext组件管理多轮对话状态,支持与Redis等缓存系统无缝集成实现跨实例的上下文共享,通过线程安全的ThreadLocal管理每个用户的独立会话。只需调用context.getLastMessages(5)即可获取最近5轮对话,框架自动完成上下文拼接和格式转换,开发者完全不用关心底层的细节。
四、Spring AI的痛点与使用场景
4.1 当前存在的局限性
学习曲线与版本稳定性: Spring AI作为一个相对年轻的框架,1.0正式版虽然已发布并承诺向后兼容,但迭代速度仍然较快。LangChain4j和Spring AI都面临版本不稳定、迭代升级快导致的包名及使用方法前后不兼容的问题。
复杂Agent编排能力相对不足: 相比LangChain4j丰富的20+官方插件(LLM调用、向量存储、Web搜索等),Spring AI在开箱即用的Agent工具链上仍有差距。
社区生态仍在培育期: Spring AI虽然GitHub已有3.2万+星标,但与拥有长期社区积累的LangChain4j相比,在插件丰富度和第三方集成上还有提升空间。另外,Spring AI目前依赖社区贡献来扩展新模型的适配器,企业使用特定模型时可能需要自行实现适配器。
4.2 适用场景分析
最适合选择Spring AI的场景:
- 传统企业Spring Boot微服务架构:团队熟悉Spring生态,希望不重构现有架构的前提下接入AI能力
- 需要多模型灵活切换的企业:业务需要同时支持不同模型,或希望通过配置快速切换模型供应商
- 对工程化要求高的生产环境:需要重试、降级、熔断、限流、监控、审计等完整的企业级能力,不愿从零自研
- 需要将AI能力与现有业务Service无缝集成:例如在订单处理流程中嵌入AI决策,直接调用Spring管理的Service层
- 高监管行业(金融、医疗、政务) :需要审计日志、权限控制、可解释性等合规能力
慎重使用Spring AI的场景:
- 简单的原型验证或一次性脚本:几个HTTP调用就能搞定,引入框架反而增加复杂度
- 需要复杂Agent编排和多工具组合调用的场景:LangChain4j在Agent框架和工具链上更为成熟
- 对框架体积极度敏感的边缘计算场景:Spring AI依赖Spring生态,Jar包相对较大
总结
写到这里,我想做一个总结:
如果你的目标是“快速写个Demo验证想法”,手写HTTP足以。 它短平快,没有框架负担,能快速跑通流程。
但如果你的目标是“在企业级生产环境中稳定接入大模型,并且业务规模会持续增长”,那Spring AI是目前Java生态中最值得选择的方案。
它为Java开发者带来了一场AI开发的范式转移:
- 统一抽象层意味着AI能力的接入不再依赖于具体厂商API。今天用OpenAI,明天换成DeepSeek或本地部署的Llama 3,只需要改一行配置。这在业务快速变化的时代,给了企业极大的技术灵活度。
- 深度整合Spring生态意味着AI能力可以直接调用你现有的Service层。大模型不只是独立的API,而是业务流程的一个环节——可以根据用户查询修改订单状态、查询库存、发送通知,真正做到AI驱动业务。
- 工程化能力意味着你不需要担心重试策略写漏了、降级逻辑考虑不全、监控指标没有暴露。Spring AI依托Spring Cloud体系的成熟组件,让AI应用的稳定性和可观测性有了企业级的保障。
不少从Python转向Java的开发者认为,Java在应对海量用户场景下开发效率低、延迟高。
但Spring AI的出现正在扭转这个局面——它的设计让Java在AI工程化领域从劣势变为优势。
强类型安全减少了运行时错误,成熟的Spring生态提供了现成的工程化组件,JVM的高性能保障了生产环境稳定性。
最终选型,取决于你和你的团队的真实情况。
2026年,Java生态的AI开发格局正在被Spring AI重塑。
下一个用Java写出惊艳AI应用的开发者,或许就是你。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号