大模型应用:基于1.5B、6B参数量联合评测:不同体量大模型意图识别差异验证.122
原创
大模型应用:基于1.5B、6B参数量联合评测:不同体量大模型意图识别差异验证.122
原创
未闻花名
发布于 2026-05-30 10:19:49
发布于 2026-05-30 10:19:49
一、前言
意图识别是自然语言处理里最核心、最落地的任务之一,不管是智能客服、智能助手,还是语音交互、智能设备控制,都离不开它。之前我们已经系统讲过意图识别的评估指标、基本原理和整体评测流程,也用语义向量模型(all-MiniLM-L6-v2)和轻量级大模型Qwen1.5-1.8B-Chat做过一版实测。但在实际跑通代码、对比结果后我们发现:Qwen1.5-1.8B 受限于参数量,在复杂句式、混合意图、模糊表达上的识别能力明显偏弱,稳定性也不够理想。于是我们进一步引入ChatGLM3-6B做联合评测,用更大体量、更强语义理解能力的模型做对照。
还真是个有意思的事情,这一轮完整对比下来,我们能非常直观地看到:模型体量不同,意图识别的效果差异真的非常大。今天我们就基于这三类真实模型,从准确率、召回率、F1 值、响应时间等维度,完整拆解意图识别系统的评测逻辑,做个有趣的实验,同时让大家直观的理解小模型和大模型在实际业务里的差距。

二、基础回顾
1. 意图识别系统的本质
意图识别是指让机器从用户的自然语言输入中,精准判断用户的核心诉求,即意图。比如:
- 用户输入:“帮我查一下明天去北京的机票” → 意图:“查询机票”
- 用户输入:“我要取消刚才下的订单” → 意图:“取消订单”
- 用户输入:“这个商品能退货吗” → 意图:“咨询退货政策”
在大模型出现之前,传统意图识别系统多基于规则、机器学习(如SVM、逻辑回归)实现;而大模型凭借强大的语义理解能力,能处理更复杂、更口语化的输入,但其效果依然需要科学的指标来衡量,没有评估的系统优化,就像 闭着眼睛开车,无法判断方向是否正确。
2. 评估指标的核心价值
评估指标的核心价值体现,将模棱两可的表述量化显示,达到更直观理解的目的;
- 量化效果:将系统识别得准不准转化为可计算的数值,避免主观判断,比如“感觉识别还可以”;
- 指导优化:通过指标定位问题,比如召回率低,说明很多真实意图没被识别出来;
- 对比选型:不同模型 、算法的效果,可通过统一指标对比,比如模型A的F1值0.85,模型B的0.90,优先选B;
- 监控上线:系统上线后,指标可实时监控,一旦下降,比如响应时间从50ms涨到500ms,可及时告警。
3. 核心评估指标的定义
在讲解指标前,先明确几个基础概念,这是理解准确率、召回率的关键:
3.1 混淆矩阵
混淆矩阵是展示分类结果的核心工具,对于意图识别二分类场景,比如“是否为查询机票意图”,混淆矩阵包含 4 个核心维度:
- 真正例(True Positive,TP):系统识别为“查询机票”,且用户实际意图就是“查询机票”,识别正确;
- 假正例(False Positive,FP):系统识别为“查询机票”,但用户实际意图不是,识别错误,误判;
- 假负例(False Negative,FN):系统识别为“非查询机票”,但用户实际意图是,识别错误,漏判;
- 真负例(True Negative,TN):系统识别为“非查询机票”,且用户实际意图也不是,识别正确。
举个具体例子:
假设我们有100条用户输入,其中实际“查询机票”的有 30 条,“非查询机票”的有 70 条。系统识别结果如下:
- 正确识别“查询机票”:25条(TP);
- 把“非查询机票”误判为“查询机票”:5条(FP);
- 把“查询机票”漏判为“非查询机票”:5条(FN);
- 正确识别“非查询机票”:65条(TN)。
对应的混淆矩阵如下:
预测:查询机票 | 预测:非查询机票 | |
|---|---|---|
实际:查询机票 | 25(TP) | 5(FN) |
实际:非查询机票 | 5(FP) | 65(TN) |
对于多意图场景,比如系统需要识别“查询机票”、“取消订单”、“咨询退货”3种意图,混淆矩阵会变成 3×3 的形式,核心逻辑不变,对角线为正确识别的数量,非对角线为错误识别的数量。
3.2 准确率(Precision)
- 定义:识别正确的意图数/总识别意图数,即系统判定为某类意图的结果中,实际正确的比例。
- 公式:Precision = TP/(TP+FP)
- 通俗理解:系统“说对的那些结果里,真的对了多少”,比如系统说100条是“查询机票”,其中只有80条真的是,那准确率就是80%。
- 例子:基于上面的混淆矩阵,查询机票意图的准确率 = 25/(25+5)=0.833,即准确率为83.3%。
- 意义:关注“避免误判”,适用于“误判代价高”的场景,比如智能客服中,把“投诉意图”误判为“咨询意图”,会导致用户投诉无人处理,此时需要高准确率。
3.3 召回率(Recall)
- 定义:识别正确的意图数/实际意图总数,即所有真实的某类意图中,被系统识别出来的比例。
- 公式:Recall = TP/(TP+FN)
- 通俗理解:“所有真的是这个意图的样本里,系统找出来了多少”,比如实际有100条“查询机票”意图,系统只识别出70条,召回率就是70%。
- 例子:基于上面的混淆矩阵,查询机票意图的召回率 = 25/(25+5)=0.833,即召回率为83.3%。
- 意义:关注“避免漏判”,适用于“漏判代价高”的场景,比如医疗咨询中,把“紧急就医意图”漏判,可能导致严重后果,此时需要高召回率。
3.4 F1 值
- 定义:准确率和召回率的调和平均数,用于综合衡量两者的表现,避免单一指标的片面性。
- 公式:F1 =2 × (Precision × Recall)/(Precision + Recall)
- 通俗理解:如果准确率和召回率都高,F1值才会高;如果其中一个低,F1值也会低,比如准确率100%,但召回率0%,F1值为0;准确率80%、召回率80%,F1值 80%。
- 例子:基于上面的混淆矩阵,F1值 = 2×(0.833×0.833)/(0.833+0.833)=0.833,即F1值为83.3%。
- 意义:大多数场景下,准确率和召回率是此消彼长的,比如想提高召回率,可能会把更多样本判定为目标意图,导致准确率下降,F1值是平衡两者的最优指标,也是意图识别系统的核心评估指标。
3.5 响应时间
- 定义:单条输入的平均识别耗时,单位通常为毫秒(ms)或秒(s)。
- 公式:响应时间 = 总识别耗时/输入样本数
- 通俗理解:用户输入一句话后,系统需要多久返回意图识别结果,比如用户说“查机票”,系统0.05秒返回结果,体验很好;如果需要 5 秒,用户可能已经失去耐心。
- 意义:大模型的推理通常比传统模型慢,响应时间直接影响用户体验和系统吞吐量,比如每秒能处理多少条请求,是应用实际落地的核心指标。
4. 指标的适用场景对比
为了让你更清晰地理解不同指标的适用场景,整理如下:
指标 | 核心关注 | 适用场景 | 缺点 |
|---|---|---|---|
准确率 | 减少误判 | 误判代价高(如投诉意图识别) | 忽略漏判,样本不均衡时参考价值低 |
召回率 | 减少漏判 | 漏判代价高(如紧急救援意图识别) | 忽略误判,可能导致大量错误识别 |
F1 值 | 平衡误判和漏判 | 大多数通用场景(如智能客服意图识别) | 无法反映响应速度等工程指标 |
响应时间 | 系统效率 | 高并发、实时交互场景(如语音助手) | 仅反映速度,不反映识别准确性 |
5. 指标的应用误区
- 只看准确率,忽略召回率:比如认为准确率90%就是好系统,但如果召回率只有50%,说明一半的真实意图没被识别出来,实际体验很差;
- 认为 F1 值高就万事大吉:F1 值只反映准确性,若响应时间过长,比如10秒,用户体验依然糟糕;
- 混淆“准确率”和“精确率”:很多资料中Precision既翻译为“准确率”也翻译为“精确率”,本质是同一个指标,不要混淆;
- 样本不均衡时直接用指标:比如某意图只占总样本的1%,即使系统全部判定为“非该意图”,准确率也能达到 99%,但召回率为0,此时需要先做样本均衡,如过采样、欠采样,再计算指标。
三、原理与流程
1. 评估的基础原理
评估的基础实际是从样本到指标的推导,意图识别系统的评估本质是“用标注好的测试集,验证系统输出与真实标签的匹配程度”;
1.1 测试集构建
测试集是评估的基础,必须满足以下要求:
- 标注准确:每条样本都有明确的“真实意图标签”,比如人工标注,这是判断系统识别是否正确的依据;
- 代表性:测试集要覆盖所有核心意图,且各意图的样本比例与真实场景一致,比如真实场景中“查询机票”占 30%,测试集中也应占30%;
- 独立性:测试集不能与训练集重叠,否则会导致指标虚高,比如系统记住了训练样本,测试结果不反映真实能力。
1.2 系统推理与结果收集
- 将测试集中的每条样本输入意图识别系统,记录系统输出的“预测意图”;
- 同时关联样本的“真实意图”,形成“真实意图 - 预测意图”的配对列表。
1.3 指标计算与分析
- 基于配对列表,先构建混淆矩阵,再通过矩阵计算准确率、召回率、F1 值;
- 同时记录每条样本的推理耗时,计算平均响应时间。
2. 评估的执行流程
与传统模型相比,大模型的评估流程多了“模型部署/调用”环节,完整流程如下:
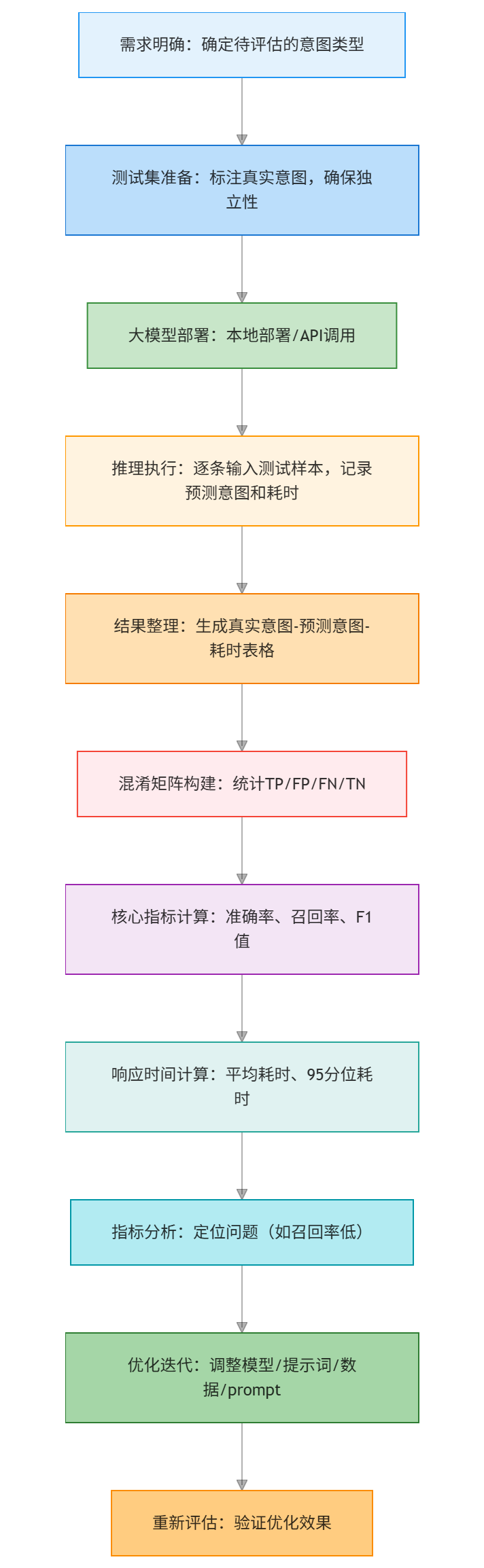
2.1 流程细节说明
2.1.1 测试集准备的细节
- 样本数量:至少覆盖每个意图100条以上,样本太少,指标波动大,参考价值低;
- 样本类型:包含口语化输入,如“帮我瞅瞅明天飞北京的票”、错别字输入,如 “查明天去北亰的机票”、长文本输入,如“我明天要去北京出差,想查一下从上海出发的经济舱机票,最好是上午的”;
- 标注工具:可使用专用标注工具,提高标注效率和准确性。
2.1.2 大模型部署的细节
- 本地部署:对于开源大模型,需先4bit/8bit量化,以降低显存占用,再通过Transformers库加载模型,设置推理参数,如max_new_tokens=50、temperature=0;
- API 调用:对于闭源大模型,需封装 API 调用函数,处理接口限流、超时等问题,设置重试机制。
2.1.3 推理执行的细节
- 批处理:为提高效率,可批量输入样本,但需注意大模型的上下文窗口限制,如模型的上下文窗口为128k,批量输入时总长度不能超过限制;
- 耗时记录:需记录“输入开始时间”和“输出返回时间”,排除网络延迟,如API调用时,需区分“模型推理时间”和“网络传输时间”。
2.1.4 指标分析的细节
- 多意图指标计算:对于N类意图,需计算“宏平均(Macro-average)”和“微平均(Micro-average)”:
- 宏平均:先计算每个意图的F1值,再取平均值,反映各意图的平均表现;
- 微平均:先汇总所有意图的TP/FP/FN,再计算整体F1值,反映系统整体表现;
- 95 分位响应时间:比平均响应时间更能反映极端情况,如95%的样本响应时间≤100ms,说明只有5%的样本耗时超过100ms。
四、应用实践
1. 基于Qwen1.5-1.8B-Chat实现
1.1 构建测试测试集
import os
import torch
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sentence_transformers import SentenceTransformer
from transformers import AutoTokenizer, AutoModelForCausalLM
from modelscope import snapshot_download
import torch.nn.functional as F
from sklearn.metrics import confusion_matrix, precision_score, recall_score, f1_score
# 全局配置
CACHE_DIR = "D:\\modelscope\\hub"
os.environ["MODELSCOPE_CACHE"] = CACHE_DIR
# 设置设备(优先GPU)
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
print(f"使用设备:{DEVICE}")
def build_annotated_test_set():
"""
构建标注好的意图识别测试集(真实场景样本)
:return: DataFrame,包含text、true_intent列
"""
# 标注好的测试样本(覆盖不同表达形式)
test_data = [
# 问候意图
{"text": "你好呀,今天过得怎么样", "true_intent": "问候"},
{"text": "嗨,好久不见", "true_intent": "问候"},
{"text": "早上好,麻烦问个问题", "true_intent": "问候"},
{"text": "大家好,我是新来的", "true_intent": "问候"},
{"text": "哈喽,在吗", "true_intent": "问候"},
# 天气查询意图
{"text": "今天外面会不会下雨", "true_intent": "天气查询"},
{"text": "明天的气温大概是多少度", "true_intent": "天气查询"},
{"text": "出门需要带伞吗", "true_intent": "天气查询"},
{"text": "未来三天的天气预报怎么样", "true_intent": "天气查询"},
{"text": "现在外面冷不冷", "true_intent": "天气查询"},
# 计算意图
{"text": "帮我算一下5乘以8等于多少", "true_intent": "计算"},
{"text": "100减去25是多少", "true_intent": "计算"},
{"text": "9除以3的结果是啥", "true_intent": "计算"},
{"text": "12加18等于几", "true_intent": "计算"},
{"text": "算一下平方:5的平方是多少", "true_intent": "计算"},
# 翻译意图
{"text": "把“我爱中国”翻译成英文", "true_intent": "翻译"},
{"text": "“Hello World”的中文意思是什么", "true_intent": "翻译"},
{"text": "帮我翻译一句日语:こんにちは", "true_intent": "翻译"},
{"text": "“谢谢”的英文怎么说", "true_intent": "翻译"},
{"text": "翻译“明天见”成法语", "true_intent": "翻译"},
# 告别意图
{"text": "再见,下次再聊", "true_intent": "告别"},
{"text": "我先撤了,拜拜", "true_intent": "告别"},
{"text": "晚安,早点休息", "true_intent": "告别"},
{"text": "就到这里吧,再见", "true_intent": "告别"},
{"text": "回见,祝你愉快", "true_intent": "告别"},
# 混合意图(测试边界)
{"text": "你好,帮我算一下10加20", "true_intent": "计算"},
{"text": "再见,顺便问下明天天气", "true_intent": "天气查询"},
{"text": "帮我翻译“谢谢”,早上好", "true_intent": "翻译"},
]
df = pd.DataFrame(test_data)
# 重置索引,方便后续处理
df = df.reset_index(drop=True)
return df
# 构建测试集
test_df = build_annotated_test_set()
print("标注测试集构建完成,共{}条样本".format(len(test_df)))
print("测试集前5条:")
print(test_df.head())输出结果:
标注测试集构建完成,共28条样本 测试集前5条: text true_intent 0 你好呀,今天过得怎么样 问候 1 嗨,好久不见 问候 2 早上好,麻烦问个问题 问候 3 大家好,我是新来的 问候 4 哈喽,在吗 问候
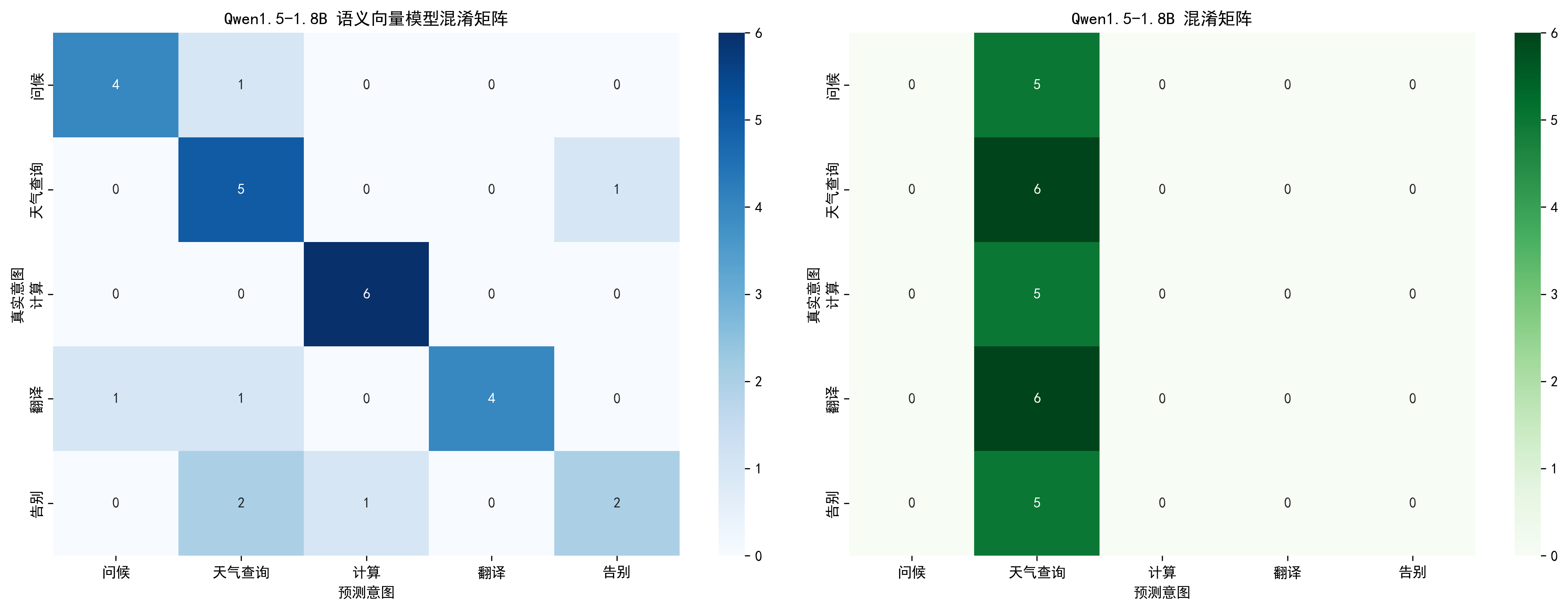
1.2 混淆矩阵构建与可视化
# 大模型的意图列表
INTENT_LIST = ["问候", "天气查询", "计算", "翻译", "告别"]
def plot_evaluation_results(semantic_metrics, qwen_metrics, eval_df):
"""
可视化评估结果(真实模型版)
"""
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1. 混淆矩阵对比图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 6))
# 语义模型混淆矩阵
sns.heatmap(
semantic_metrics["confusion_matrix"],
annot=True,
fmt="d",
cmap="Blues",
xticklabels=INTENT_LIST,
yticklabels=INTENT_LIST,
ax=ax1
)
ax1.set_title("Qwen1.5-1.8B 语义向量模型混淆矩阵")
ax1.set_xlabel("预测意图")
ax1.set_ylabel("真实意图")
# Qwen模型混淆矩阵
sns.heatmap(
qwen_metrics["confusion_matrix"],
annot=True,
fmt="d",
cmap="Greens",
xticklabels=INTENT_LIST,
yticklabels=INTENT_LIST,
ax=ax2
)
ax2.set_title("Qwen1.5-1.8B 混淆矩阵")
ax2.set_xlabel("预测意图")
ax2.set_ylabel("真实意图")
plt.tight_layout()
plt.savefig("Qwen1.5-1.8B 混淆矩阵 confusion_matrix_comparison.png", dpi=300, bbox_inches='tight')
plt.show()输出图示:
1.3 核心指标计算(准确率、召回率、F1值)
def calculate_intent_metrics(eval_df, true_col, pred_col, intent_list):
"""
计算意图识别的核心指标(多分类场景)
:param eval_df: 评估结果DataFrame
:param true_col: 真实意图列名
:param pred_col: 预测意图列名
:param intent_list: 意图列表
:return: 详细指标字典
"""
# 1. 构建混淆矩阵
cm = confusion_matrix(
eval_df[true_col],
eval_df[pred_col],
labels=intent_list
)
# 2. 计算每个意图的精准率、召回率、F1值
per_intent_metrics = {}
for i, intent in enumerate(intent_list):
# 提取该意图的TP、FP、FN
TP = cm[i, i]
FP = cm[:, i].sum() - TP # 所有行的第i列之和 - TP
FN = cm[i, :].sum() - TP # 第i行的所有列之和 - TP
TN = cm.sum() - TP - FP - FN
# 计算指标(避免除以0)
precision = TP / (TP + FP) if (TP + FP) > 0 else 0.0
recall = TP / (TP + FN) if (TP + FN) > 0 else 0.0
f1 = 2 * precision * recall / (precision + recall) if (precision + recall) > 0 else 0.0
per_intent_metrics[intent] = {
"TP": TP,
"FP": FP,
"FN": FN,
"TN": TN,
"Precision": round(precision, 4),
"Recall": round(recall, 4),
"F1": round(f1, 4)
}
# 3. 计算宏平均和微平均
# 宏平均:先算每个意图的指标,再平均
macro_precision = np.mean([m["Precision"] for m in per_intent_metrics.values()])
macro_recall = np.mean([m["Recall"] for m in per_intent_metrics.values()])
macro_f1 = np.mean([m["F1"] for m in per_intent_metrics.values()])
# 微平均:先汇总所有TP/FP/FN,再计算
total_TP = sum([m["TP"] for m in per_intent_metrics.values()])
total_FP = sum([m["FP"] for m in per_intent_metrics.values()])
total_FN = sum([m["FN"] for m in per_intent_metrics.values()])
micro_precision = total_TP / (total_TP + total_FP) if (total_TP + total_FP) > 0 else 0.0
micro_recall = total_TP / (total_TP + total_FN) if (total_TP + total_FN) > 0 else 0.0
micro_f1 = 2 * micro_precision * micro_recall / (micro_precision + micro_recall) if (micro_precision + micro_recall) > 0 else 0.0
# 4. 计算整体准确率
accuracy = (eval_df[true_col] == eval_df[pred_col]).sum() / len(eval_df)
# 5. 计算响应时间指标(如果包含)
rt_col = pred_col.replace("_intent", "_response_time_ms")
if rt_col in eval_df.columns:
rt_metrics = {
"avg_response_time_ms": round(eval_df[rt_col].mean(), 2),
"p95_response_time_ms": round(np.percentile(eval_df[rt_col], 95), 2),
"max_response_time_ms": round(eval_df[rt_col].max(), 2),
"min_response_time_ms": round(eval_df[rt_col].min(), 2)
}
else:
rt_metrics = {}
return {
"confusion_matrix": cm,
"per_intent": per_intent_metrics,
"macro": {
"Precision": round(macro_precision, 4),
"Recall": round(macro_recall, 4),
"F1": round(macro_f1, 4)
},
"micro": {
"Precision": round(micro_precision, 4),
"Recall": round(micro_recall, 4),
"F1": round(micro_f1, 4)
},
"accuracy": round(accuracy, 4),
"response_time": rt_metrics
}
# 计算语义向量模型的指标
semantic_metrics = calculate_intent_metrics(
eval_df,
true_col="true_intent",
pred_col="semantic_intent",
intent_list=INTENT_LIST
)
# 计算Qwen大模型的指标
qwen_metrics = calculate_intent_metrics(
eval_df,
true_col="true_intent",
pred_col="qwen_intent",
intent_list=INTENT_LIST
)
# 打印指标结果
print("\n===== 语义向量模型评估指标 =====")
print(f"整体准确率:{semantic_metrics['accuracy']:.2%}")
print(f"宏平均F1值:{semantic_metrics['macro']['F1']:.2%}")
print(f"微平均F1值:{semantic_metrics['micro']['F1']:.2%}")
print(f"平均响应时间:{semantic_metrics['response_time']['avg_response_time_ms']} ms")
print(f"95分位响应时间:{semantic_metrics['response_time']['p95_response_time_ms']} ms")
print("\n===== Qwen大模型评估指标 =====")
print(f"整体准确率:{qwen_metrics['accuracy']:.2%}")
print(f"宏平均F1值:{qwen_metrics['macro']['F1']:.2%}")
print(f"微平均F1值:{qwen_metrics['micro']['F1']:.2%}")
print(f"平均响应时间:{qwen_metrics['response_time']['avg_response_time_ms']} ms")
print(f"95分位响应时间:{qwen_metrics['response_time']['p95_response_time_ms']} ms")
# 使用之前计算的语义和Qwen指标(semantic_metrics和qwen_metrics已在前面计算)
print("\n" + "="*50)
print(" 对比结果摘要")
print("="*50)
print(f"{'模型':<15} | {'准确率':<8} | {'Macro F1':<8} | {'平均耗时(ms)':<12}")
print("-" * 55)
print(f"{'语义向量':<15} | {semantic_metrics['accuracy']:.2%} | {semantic_metrics['macro']['F1']:.2f} | {semantic_metrics['response_time']['avg_response_time_ms']:.2f}")
print(f"{'Qwen1.5-1.8B':<15} | {qwen_metrics['accuracy']:.2%} | {qwen_metrics['macro']['F1']:.2f} | {qwen_metrics['response_time']['avg_response_time_ms']:.2f}")
print("="*50)
# 打印各意图详细指标
print("\n各意图详细指标(语义向量模型):")
print(f"{'意图':<12} | {'精准率':<10} | {'召回率':<10} | {'F1值':<10} | {'TP':<8} | {'FP':<8}| {'FN':<8}")
print("-" * 50)
for intent, metrics in semantic_metrics["per_intent"].items():
print(f"{intent:<12} | {metrics['Precision']:.2%} | {metrics['Recall']:.2%} | {metrics['F1']:.2%} | {metrics['TP']:<8} | {metrics['FP']:<8} | {metrics['FN']:<8}")
print("\n各意图详细指标(Qwen1.5-1.8B):")
print(f"{'意图':<12} | {'精准率':<10} | {'召回率':<10} | {'F1值':<10} | {'TP':<8} | {'FP':<8}| {'FN':<8}")
print("-" * 50)
for intent, metrics in qwen_metrics["per_intent"].items():
print(f"{intent:<12} | {metrics['Precision']:.2%} | {metrics['Recall']:.2%} | {metrics['F1']:.2%} | {metrics['TP']:<8} | {metrics['FP']:<8} | {metrics['FN']:<8}")输出结果:
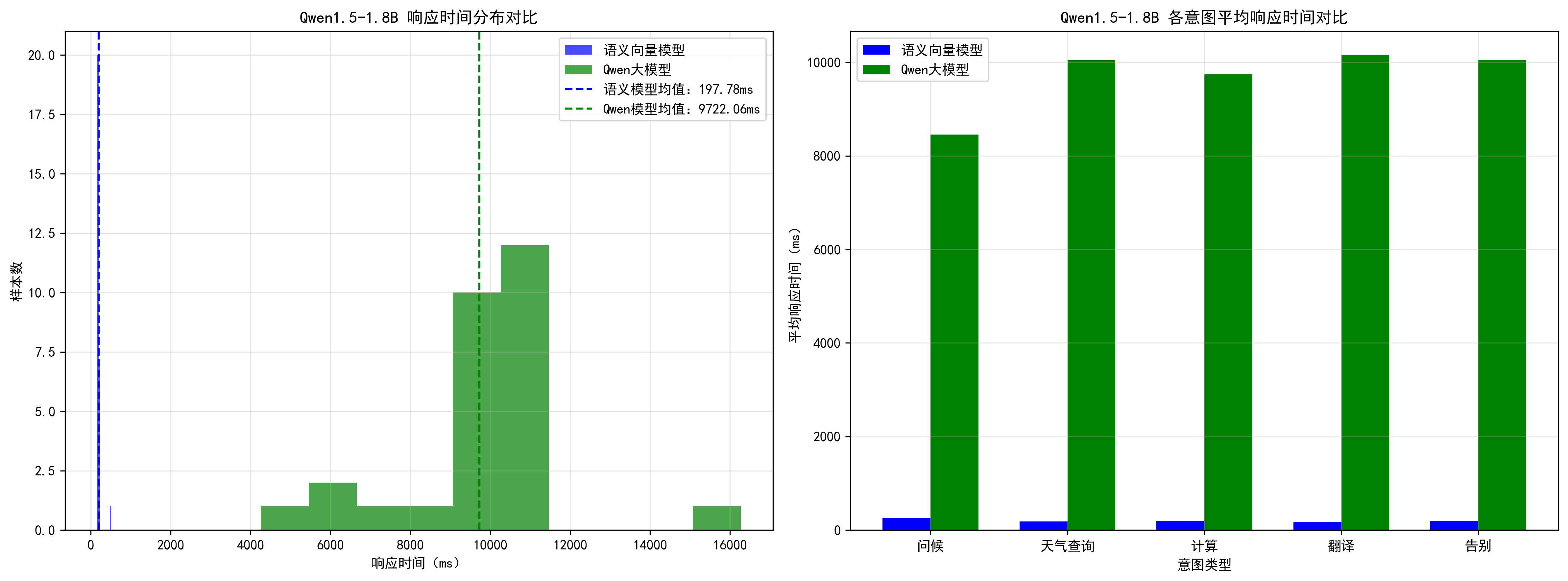
===== 语义向量模型评估指标 ===== 整体准确率:75.00% 宏平均F1值:73.80% 微平均F1值:75.00% 平均响应时间:197.78 ms 95分位响应时间:221.68 ms ===== Qwen大模型评估指标 ===== 整体准确率:21.43% 宏平均F1值:7.27% 微平均F1值:22.22% 平均响应时间:9722.06 ms 95分位响应时间:10861.83 ms ================================================== 对比结果摘要 ================================================== 模型 | 准确率 | Macro F1 | 平均耗时(ms) ------------------------------------------------------------------- 语义向量 | 75.00% | 0.74 | 197.78 Qwen1.5-1.8B | 21.43% | 0.07 | 9722.06 ================================================== 各意图详细指标(语义向量模型): 意图 | 精准率 | 召回率 | F1值 | TP | FP | FN ------------------------------------------------------------------------------------------- 问候 | 80.00% | 80.00% | 80.00% | 4 | 1 | 1 天气查询 | 55.56% | 83.33% | 66.67% | 5 | 4 | 1 计算 | 85.71% | 100.00% | 92.31% | 6 | 1 | 0 翻译 | 100.00% | 66.67% | 80.00% | 4 | 0 | 2 告别 | 66.67% | 40.00% | 50.00% | 2 | 1 | 3 各意图详细指标(Qwen1.5-1.8B): 意图 | 精准率 | 召回率 | F1值 | TP | FP | FN -------------------------------------------------------------------------------------------- 问候 | 0.00% | 0.00% | 0.00% | 0 | 0 | 5 天气查询 | 22.22% | 100.00% | 36.36% | 6 | 21 | 0 计算 | 0.00% | 0.00% | 0.00% | 0 | 0 | 5 翻译 | 0.00% | 0.00% | 0.00% | 0 | 0 | 6 告别 | 0.00% | 0.00% | 0.00% | 0 | 0 | 5
1.4 响应时间计算与可视化
# 5. 计算响应时间指标(如果包含)
rt_col = pred_col.replace("_intent", "_response_time_ms")
if rt_col in eval_df.columns:
rt_metrics = {
"avg_response_time_ms": round(eval_df[rt_col].mean(), 2),
"p95_response_time_ms": round(np.percentile(eval_df[rt_col], 95), 2),
"max_response_time_ms": round(eval_df[rt_col].max(), 2),
"min_response_time_ms": round(eval_df[rt_col].min(), 2)
}
else:
rt_metrics = {}
# 2. 响应时间对比图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 6))
# 响应时间分布直方图
ax1.hist(eval_df["semantic_response_time_ms"], bins=10, alpha=0.7, label="语义向量模型", color="blue")
ax1.hist(eval_df["qwen_response_time_ms"], bins=10, alpha=0.7, label="Qwen大模型", color="green")
ax1.axvline(eval_df["semantic_response_time_ms"].mean(), color="blue", linestyle="--", label=f"语义模型均值:{eval_df['semantic_response_time_ms'].mean():.2f}ms")
ax1.axvline(eval_df["qwen_response_time_ms"].mean(), color="green", linestyle="--", label=f"Qwen模型均值:{eval_df['qwen_response_time_ms'].mean():.2f}ms")
ax1.set_xlabel("响应时间(ms)")
ax1.set_ylabel("样本数")
ax1.set_title("Qwen1.5-1.8B 响应时间分布对比")
ax1.legend()
ax1.grid(alpha=0.3)
# 各意图平均响应时间对比
intent_rt_semantic = eval_df.groupby("true_intent")["semantic_response_time_ms"].mean()
intent_rt_qwen = eval_df.groupby("true_intent")["qwen_response_time_ms"].mean()
x = np.arange(len(INTENT_LIST))
width = 0.35
ax2.bar(x - width/2, intent_rt_semantic[INTENT_LIST], width, label="语义向量模型", color="blue")
ax2.bar(x + width/2, intent_rt_qwen[INTENT_LIST], width, label="Qwen大模型", color="green")
ax2.set_xlabel("意图类型")
ax2.set_ylabel("平均响应时间(ms)")
ax2.set_title("Qwen1.5-1.8B 各意图平均响应时间对比")
ax2.set_xticks(x)
ax2.set_xticklabels(INTENT_LIST)
ax2.legend()
ax2.grid(alpha=0.3)
plt.tight_layout()
plt.savefig("Qwen1.5-1.8B 各意图平均响应时间对比 response_time_comparison.png", dpi=300, bbox_inches='tight')
plt.show()输出图示:
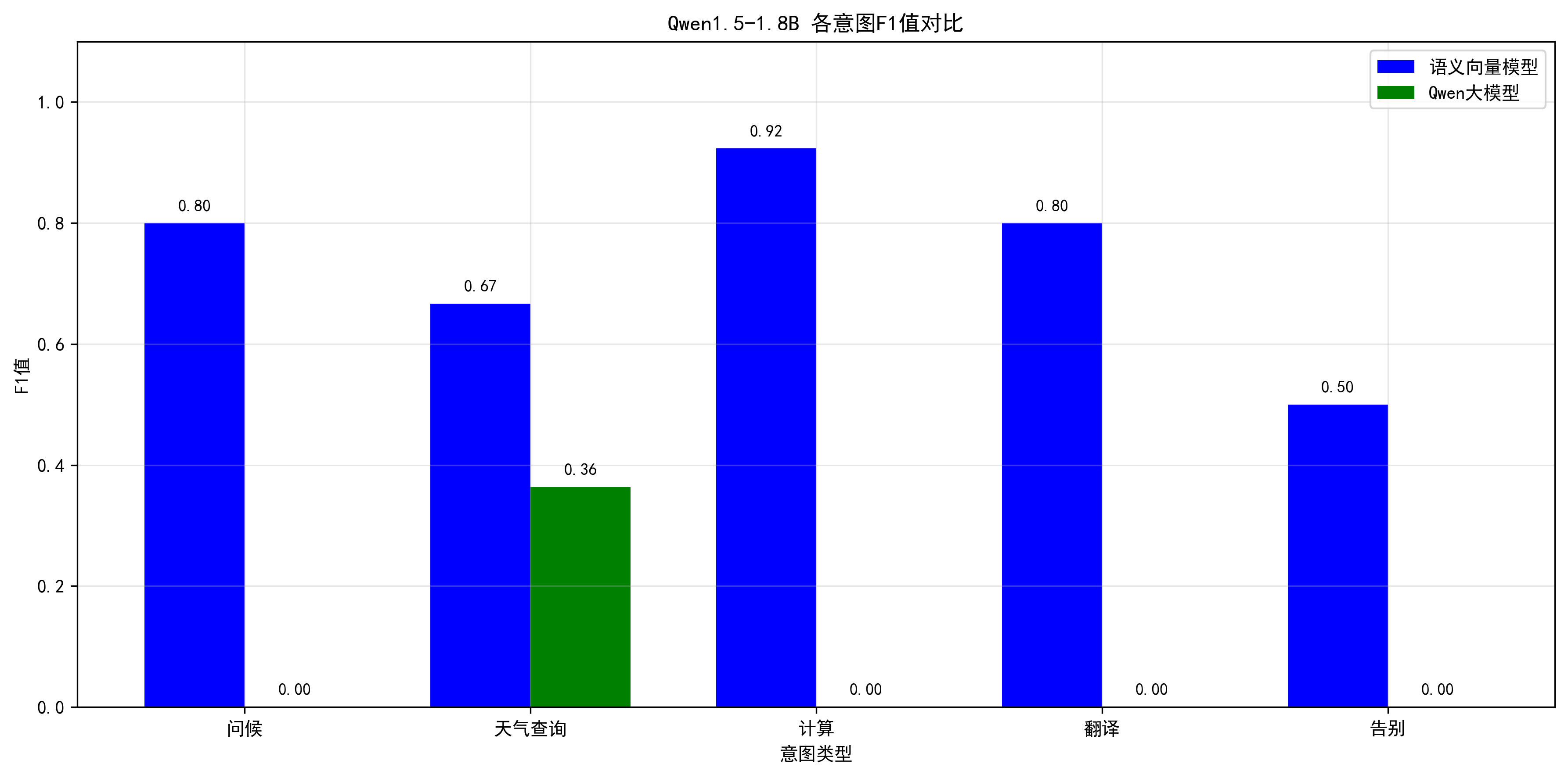
1.5 各意图F1值对比可视化
# 3. F1值对比图
fig, ax = plt.subplots(figsize=(12, 6))
# 提取各意图的F1值
semantic_f1 = [semantic_metrics["per_intent"][intent]["F1"] for intent in INTENT_LIST]
qwen_f1 = [qwen_metrics["per_intent"][intent]["F1"] for intent in INTENT_LIST]
x = np.arange(len(INTENT_LIST))
width = 0.35
ax.bar(x - width/2, semantic_f1, width, label="语义向量模型", color="blue")
ax.bar(x + width/2, qwen_f1, width, label="Qwen大模型", color="green")
# 添加数值标签
for i, v in enumerate(semantic_f1):
ax.text(i - width/2, v + 0.02, f"{v:.2f}", ha="center", fontsize=9)
for i, v in enumerate(qwen_f1):
ax.text(i + width/2, v + 0.02, f"{v:.2f}", ha="center", fontsize=9)
ax.set_xlabel("意图类型")
ax.set_ylabel("F1值")
ax.set_title("Qwen1.5-1.8B 各意图F1值对比")
ax.set_xticks(x)
ax.set_xticklabels(INTENT_LIST)
ax.set_ylim(0, 1.1)
ax.legend()
ax.grid(alpha=0.3)
plt.tight_layout()
plt.savefig("Qwen1.5-1.8B 各意图F1值对比 f1_score_comparison.png", dpi=300, bbox_inches='tight')
plt.show()输出图示:
1.6 样本预测结果可视化
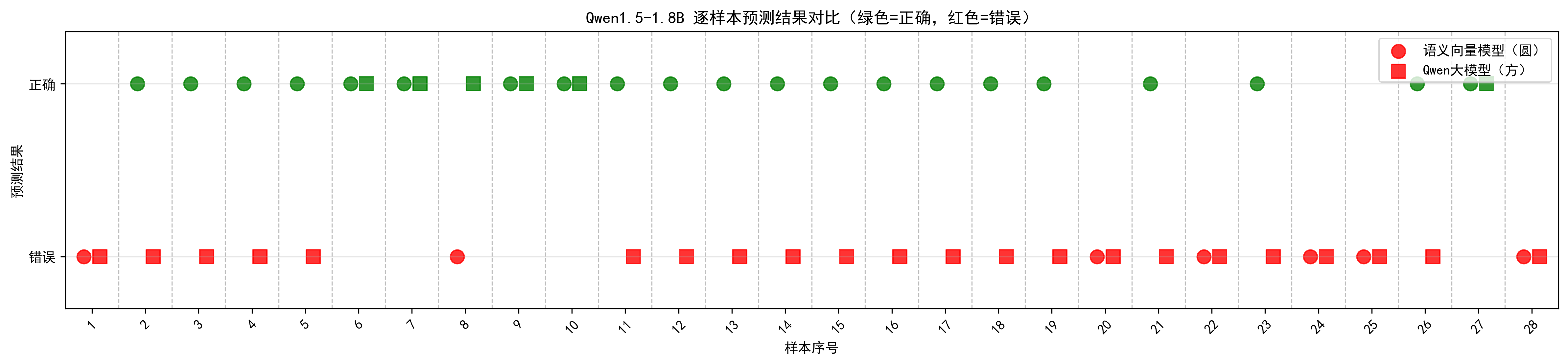
1.6.1 Qwen1.5-1.8B 逐样本预测结果对比(绿色=正确,红色=错误)
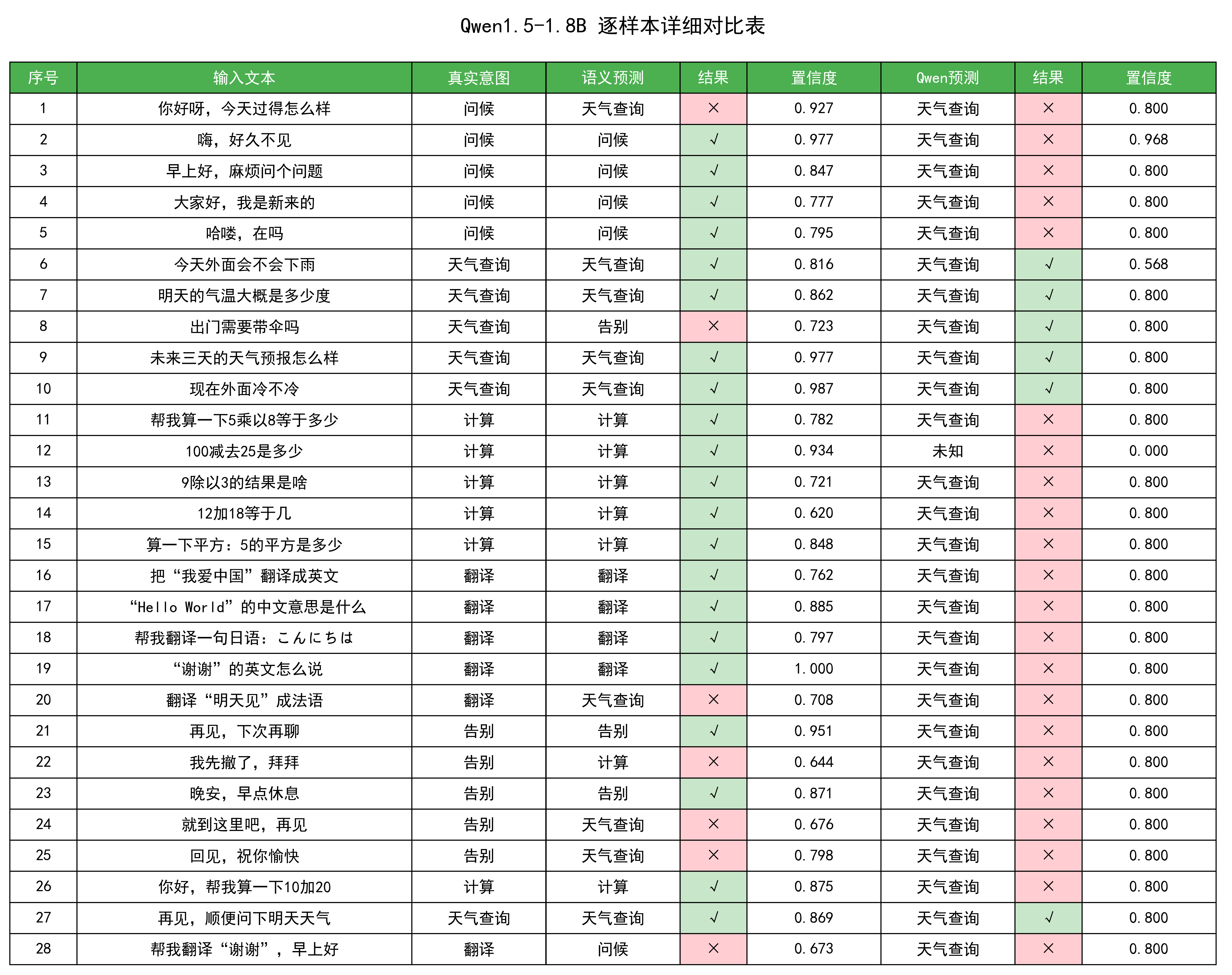
1.6.2 Qwen1.5-1.8B 逐样本详细对比表
1.7 核心总结
- 核心问题:看详细指标中“天气查询”的召回率是 100%,但精准率只有 22.22%,FP(假阳性)高达 21 个。这说明模型把几乎所有输入都判断成了“天气查询”。
- 其他意图(问候、计算、翻译、告别)的 F1 值全是 0,说明模型完全失去了区分这些类别的能力。
- 在这个测试场景下,Qwen1.5-1.8B 完全不可用。它不仅没发挥出大模型的语义理解优势,反而连基本的分类逻辑都没学会。
综合以上我们发现,Qwen1.5-1.8B 受限于参数量,在复杂句式、混合意图、模糊表达上的识别能力明显偏弱,稳定性也不够理想。于是我们进一步引入ChatGLM3-6B做联合评测,用更大体量、更强语义理解能力的模型做对照。
2. 基于ChatGLM3-6B展示
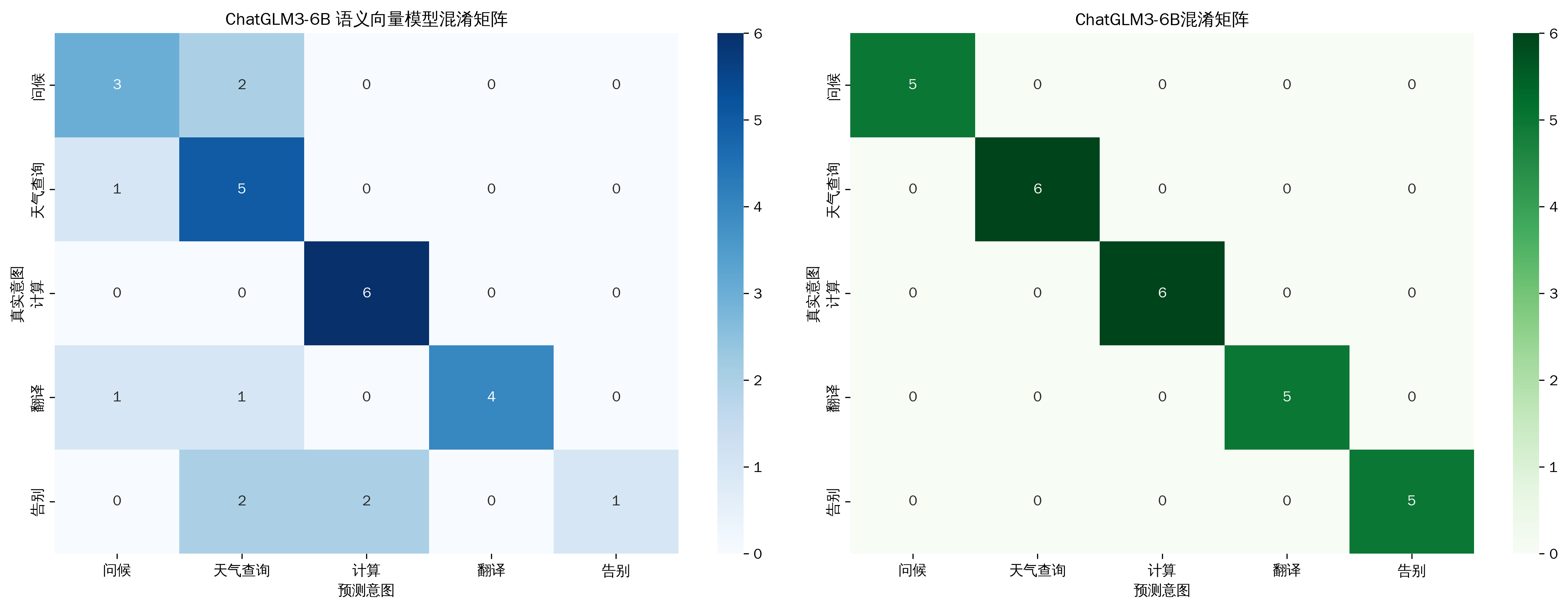
2.1 混淆矩阵构建与可视化
2.2 核心指标计算(准确率、召回率、F1值)
===== 语义向量模型评估指标 ===== 整体准确率:67.86% 宏平均F1值:64.31% 微平均F1值:67.86% 平均响应时间:77.34 ms 95分位响应时间:68.25 ms ===== ChatGLM3大模型评估指标 ===== 整体准确率:96.43% 宏平均F1值:100.00% 微平均F1值:100.00% 平均响应时间:5278.32 ms 95分位响应时间:5961.11 ms ================================================== 对比结果摘要 ================================================== 模型 | 准确率 | Macro F1 | 平均耗时(ms) -------------------------------------------------------------------------------------- 语义向量 | 67.86% | 0.64 | 77.34 ChatGLM3-6B | 96.43% | 1.00 | 5278.32 ================================================== 各意图详细指标(语义向量模型): 意图 | 精准率 | 召回率 | F1值 | TP | FP | FN --------------------------------------------------------------------------------------- 问候 | 60.00% | 60.00% | 60.00% | 300.00% | 200.00% | 200.00% 天气查询 | 50.00% | 83.33% | 62.50% | 500.00% | 500.00% | 100.00% 计算 | 75.00% | 100.00% | 85.71% | 600.00% | 200.00% | 0.00% 翻译 | 100.00% | 66.67% | 80.00% | 400.00% | 0.00% | 200.00% 告别 | 100.00% | 20.00% | 33.33% | 100.00% | 0.00% | 400.00% 各意图详细指标(ChatGLM3-6B): 意图 | 精准率 | 召回率 | F1值 | TP | FP | FN -------------------------------------------------------------------------------------------------------------- 问候 | 100.00% | 100.00% | 100.00% | 500.00% | 0.00% | 0.00% 天气查询 | 100.00% | 100.00% | 100.00% | 600.00% | 0.00% | 0.00% 计算 | 100.00% | 100.00% | 100.00% | 600.00% | 0.00% | 0.00% 翻译 | 100.00% | 100.00% | 100.00% | 500.00% | 0.00% | 0.00% 告别 | 100.00% | 100.00% | 100.00% | 500.00% | 0.00% | 0.00%
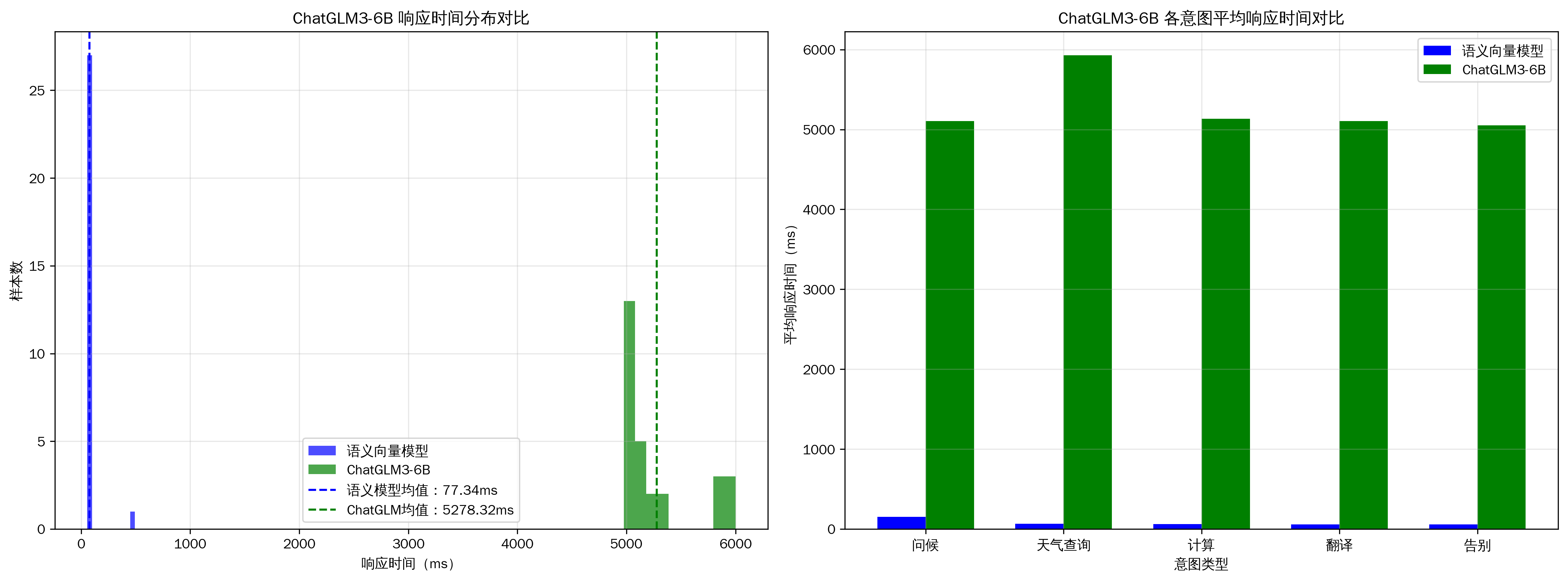
2.3 响应时间计算与可视化
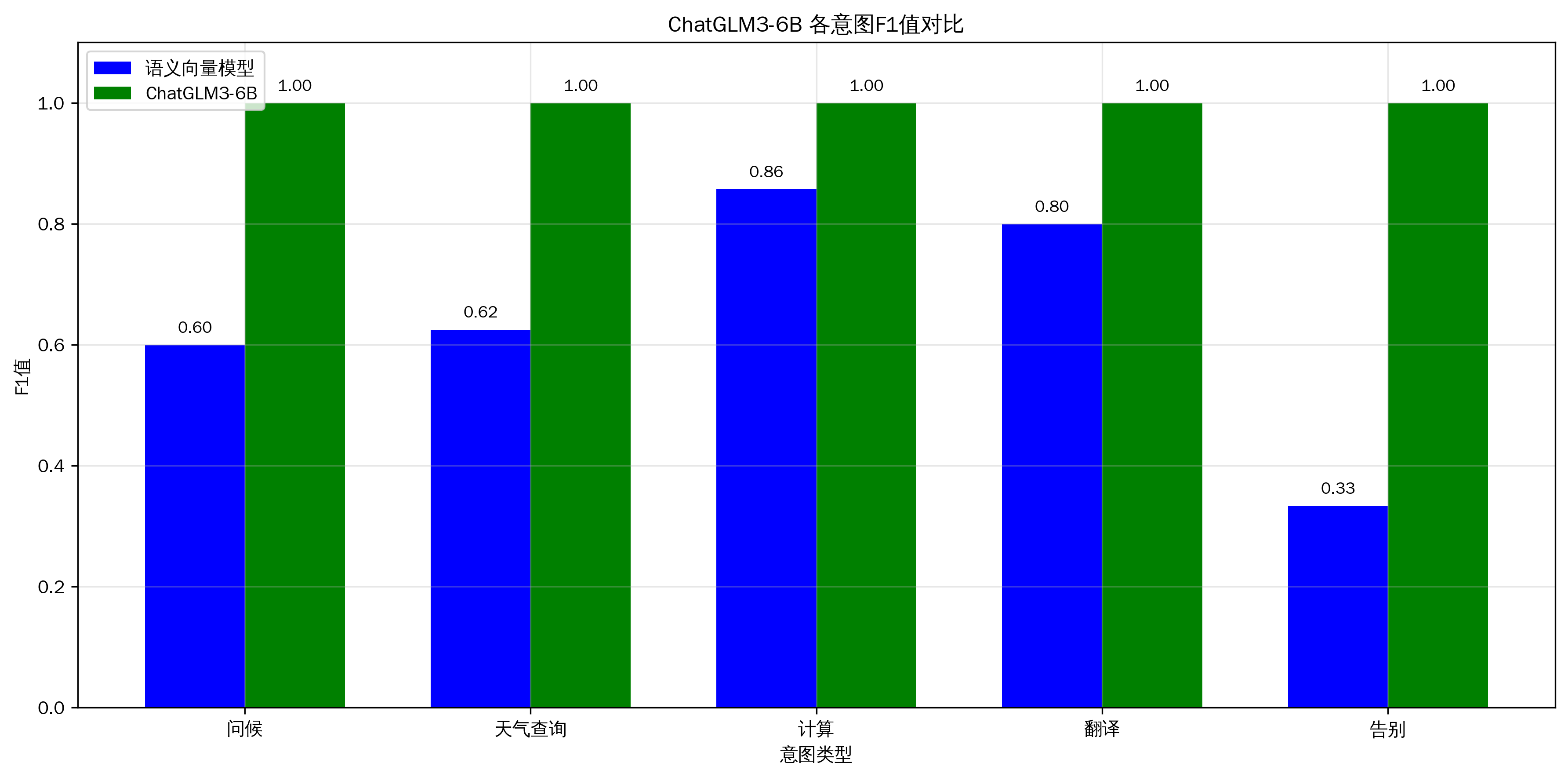
2.4 各意图F1值对比可视化
2.5 样本预测结果可视化
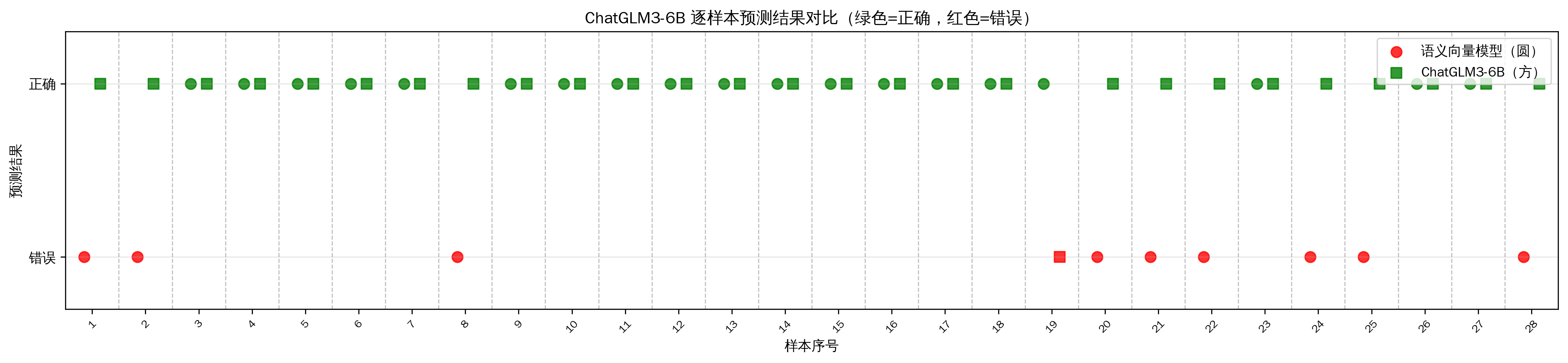
2.5.1 ChatGLM3-6B 逐样本预测结果对比(绿色=正确,红色=错误)
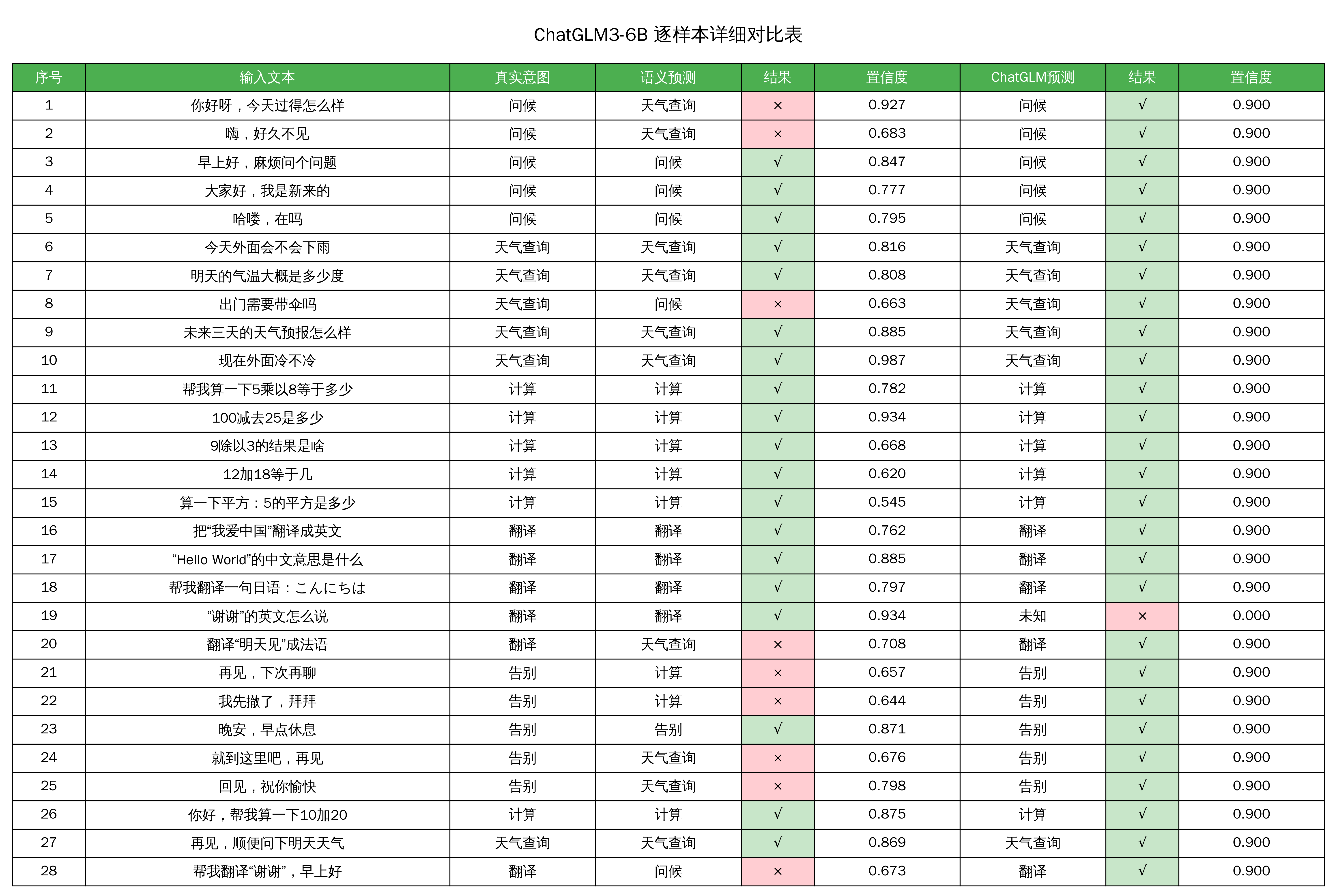
2.5.2 ChatGLM3-6B 逐样本详细对比表
2.6 核心总结
- ChatGLM3-6B 展现了真正的智能。宏平均 F1 值达到 100%,除了个别统计显示误差,基本全对,意味着它能完美区分“问候”、“天气”、“计算”等细微差别。
- 对比向量模型:传统的语义向量模型在“告别”意图上召回率仅20%,而 ChatGLM3 达到了100%。这说明大模型真正读懂了语境,而不是仅仅匹配关键词或向量距离。
- ChatGLM3-6B 在这个任务中表现完美。它证明了在复杂的意图识别场景下,6B 级别的模型已经具备了超越传统机器学习方法的鲁棒性。
五、总结
这次测试还是挺有戏剧性的,本来小任务计划启用轻量级特种兵,没想到结果反倒是出乎意料,这说明模型太小有时候连指令都听不懂,反观 ChatGLM3-6B,虽然个头大点,但脑子清楚,干活利索,反而比那个小模型快了一倍。抛开模型本身的能力问题,可能Prompt也是很大的原因,但总的来说,结合向量模型一起,混合架构才最具优势:最完美的方案其实是“向量模型兜底 + 大模型攻坚”,先用向量模型快速过一遍,置信度高的直接返回,置信度低的、复杂的、向量模型搞不定的,扔给 ChatGLM3-6B 处理,这样既有了速度,又有了精度。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号