OpenSpec + OMC 双剑合璧:让 AI 编程从各自为战到规划即执行
原创
OpenSpec + OMC 双剑合璧:让 AI 编程从各自为战到规划即执行
原创
运维有术
发布于 2026-05-31 11:37:57
发布于 2026-05-31 11:37:57
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 121 篇,AI 编程最佳实战「2026」系列第 37 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。
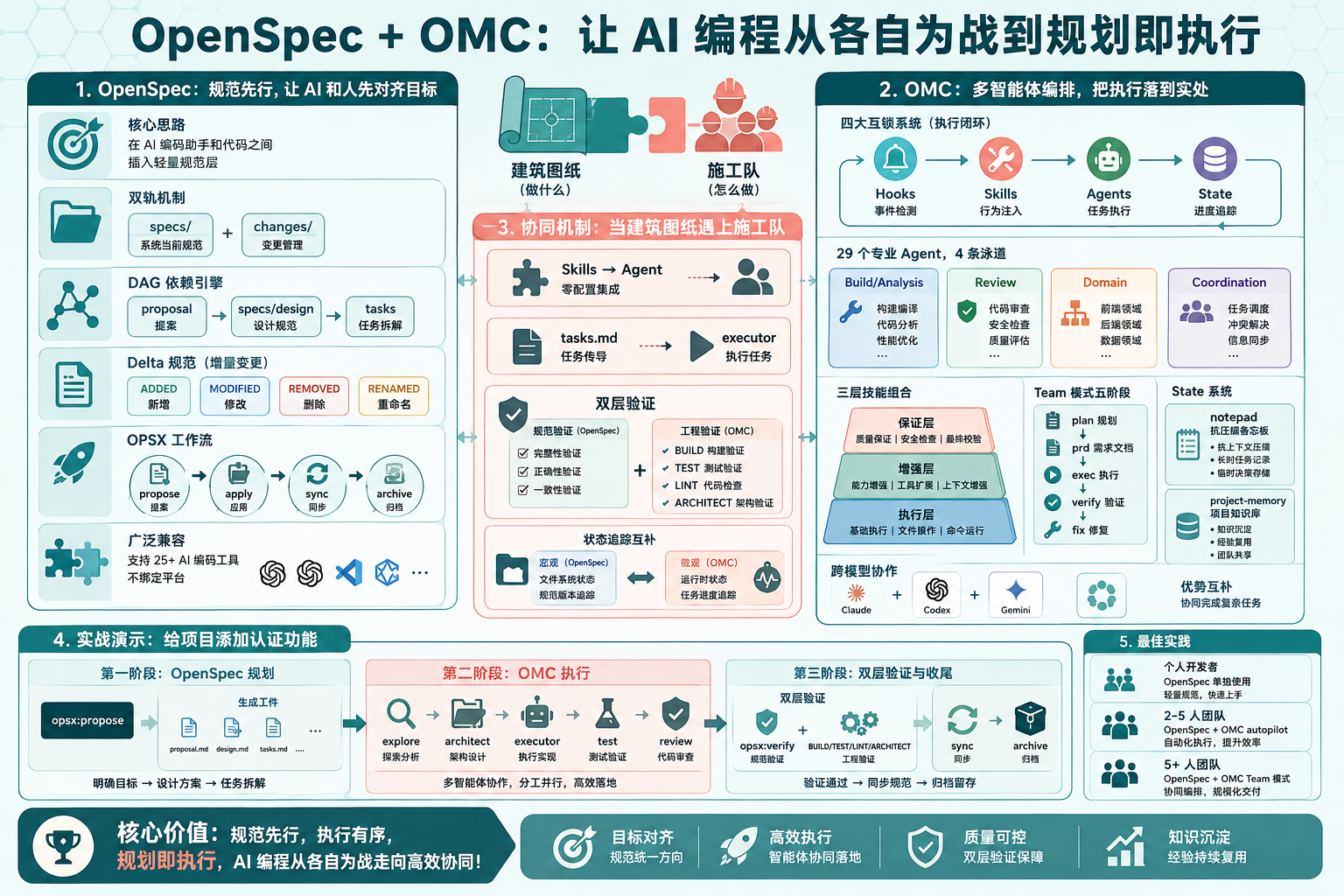
封面图:OpenSpec 规划层与 OMC 执行层的双轨协作架构
图 1:OpenSpec 规划层 + OMC 执行层双轨协作全景
你在用 AI 编程助手做项目时,可能踩过这些坑:
- 跟 AI 聊了半天需求,它转头就忘,重新解释一遍又一遍
- 规范文档写了一堆,AI 写出来的代码压根不按规范走
- 任务拆得挺清楚,但没有自动化的手段追踪完成度和质量
这些问题的根源是同一个:规划和执行之间没有形成闭环。 你告诉 AI 做什么是一回事,AI 真正按规范去执行是另一回事。
OpenSpec 和 OMC(Oh-My-ClaudeCode)分别在这两个环节发力。OpenSpec 在代码和 AI 之间加了一层轻量规范,让双方先就做什么达成一致;OMC 则通过 29 个专业 Agent 和四大互锁系统,把怎么做的执行过程编排得井井有条。
说明:本文内容基于 OpenSpec(Fission-AI/OpenSpec)和 OMC(Yeachan-Heo/oh-my-claudecode)的官方源码及文档分析整理而成,源码分析基于笔者本地仓库版本,尚未在所有场景中完成全量验证。文中的配置模板和参数建议仅供参考,实际效果请以你的项目环境和测试结果为准。如果有实际使用经验,欢迎在评论区分享交流。
单独用它们中的任何一个,已经能解决不少问题。但当这两个工具配合起来的时候,从规划到落地的整条链路才真正跑通。今天这篇文章就来拆解它们各自的架构设计,以及协同使用的具体玩法。
1. OpenSpec:规范先行,让 AI 和人先对齐目标
核心定位
OpenSpec 的核心思路很简单:在 AI 编码助手和代码之间插入一个轻量规范层。写代码之前,先把要做什么说清楚,形成一份人和 AI 都能理解的共识文档。
它不是另一个需求管理工具。它解决的是一个更具体的问题:AI 编码助手收到一个模糊的需求后,要么过度发挥,要么理解偏差。OpenSpec 通过结构化的规范文件把边界画清楚。
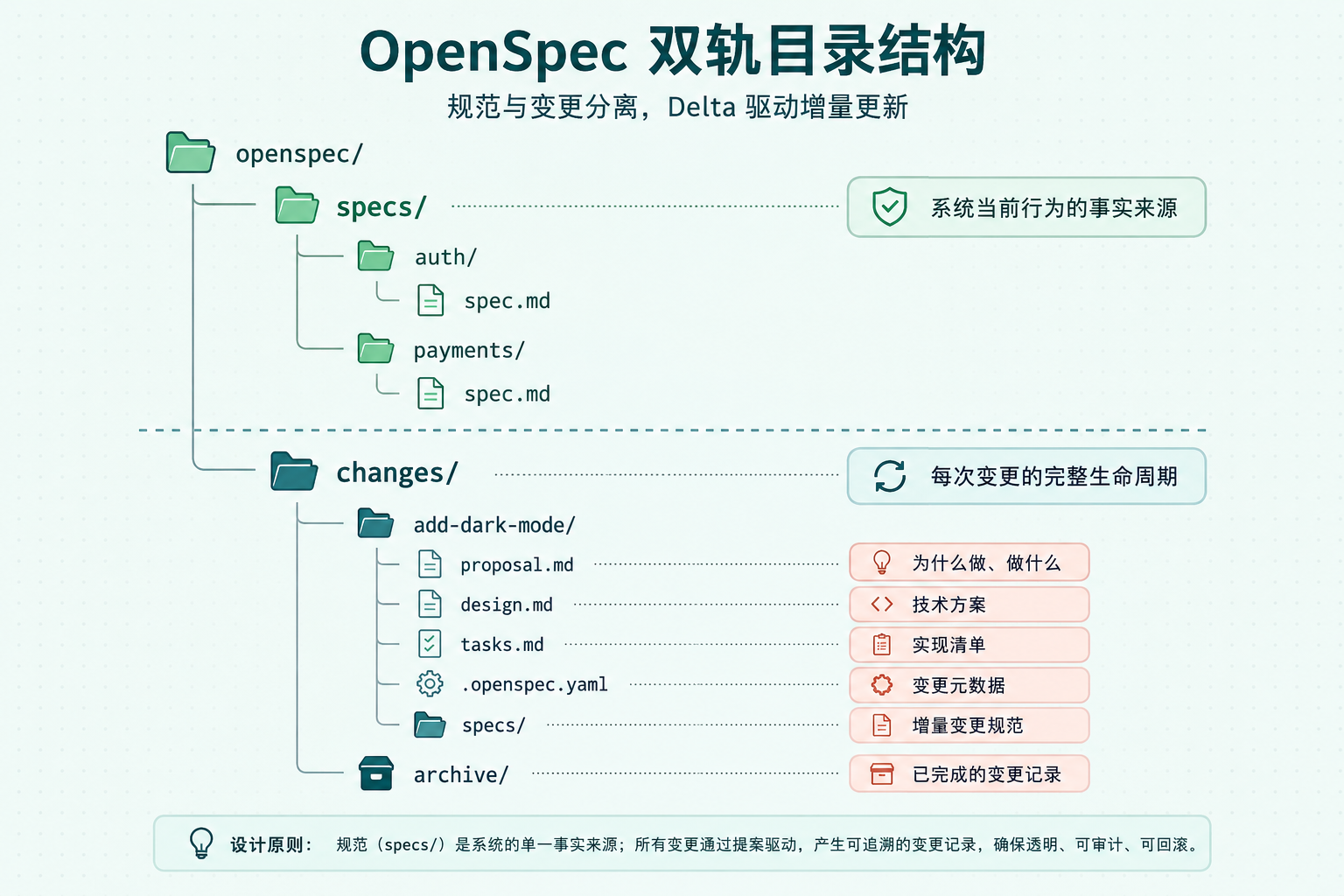
OpenSpec 目录结构示意图
图 2:OpenSpec 双轨目录结构——specs/ 管规范,changes/ 管变更
双轨机制:Specs + Changes
OpenSpec 的目录结构分为两条轨道:
openspec/
├── specs/ # 系统当前行为的规范
│ ├── auth/
│ │ └── spec.md
│ └── payments/
│ └── spec.md
└── changes/ # 待处理的变更
├── add-dark-mode/
│ ├── proposal.md # Why & What
│ ├── design.md # How(技术方案)
│ ├── tasks.md # 实现清单
│ ├── .openspec.yaml # 变更元数据
│ └── specs/ # Delta 规范
└── archive/ # 已归档的变更specs/ 目录是系统的 Source of Truth(事实来源),记录当前系统的行为规范。changes/ 目录则管理每次变更的全生命周期:从提案(proposal)到技术设计(design),再到实现任务清单(tasks)。
这种双轨设计有个好处:主规范不会被频繁修改。每次变更都在独立的子目录里完成,通过 Delta 规范描述要增删改哪些行为,验证通过后再合并回主规范。
DAG 依赖图引擎
这四个工件之间有严格的依赖关系:
proposal(根节点)
│
┌─────────────┴─────────────┐
▼ ▼
specs design
(依赖: proposal) (依赖: proposal)
│ │
└─────────────┬─────────────┘
▼
tasks
(依赖: specs, design)proposal 没有依赖,可以首先创建。specs 和 design 都依赖 proposal。tasks 最重,要等 specs 和 design 都完成才能生成。
OpenSpec 用文件系统存在检测来追踪每个工件的状态:BLOCKED(依赖未满足)→ READY(可以创建)→ DONE(文件已存在)。不需要额外的状态服务,文件本身就是状态。
Delta 规范:增量变更的核心创新
这是 OpenSpec 设计中比较精巧的部分。每次变更不需要重写整个规范,而是用 Delta 规范描述增量:
ADDED Requirements:新增行为,追加到主规范MODIFIED Requirements:变更行为,替换现有需求REMOVED Requirements:废弃行为,从主规范删除RENAMED Requirements:重命名,使用FROM:/TO:格式
这样做的好处是:每次变更的影响范围一目了然。合并时也不容易产生冲突,因为 Delta 只描述差异,不重复已有内容。
OPSX 工作流
OpenSpec 把日常操作封装成了 OPSX 工作流:
/opsx:propose → /opsx:apply → /opsx:sync → /opsx:archive一条命令 /opsx:propose add-dark-mode 就能创建变更目录并生成所有规划工件。/opsx:apply 执行实现。/opsx:sync 合并 Delta 规范到主规范。/opsx:archive 归档已完成的变更。
还有扩展模式:/opsx:explore(探索想法)、/opsx:verify(三维度验证)、/opsx:ff(快进创建所有工件)等。
/opsx:explore 比较特别。它不直接创建变更,而是进入探索模式,帮你在正式规划前理清思路。比如你对某个技术方案有疑虑,先 explore 一下,再决定要不要 propose。
/opsx:verify 从三个维度检查实现:Completeness(所有任务是否完成、所有需求是否实现)、Correctness(实现是否匹配规范意图、边界条件是否处理)、Coherence(设计决策是否反映在代码中、模式是否一致)。这三个维度覆盖了规范验证的关键视角。
OpenSpec 还支持项目级配置。在 openspec/config.yaml 中,你可以指定技术栈上下文和每种工件的规则约束:
schema: spec-driven
context: |
Tech stack: TypeScript, React, Node.js
rules:
proposal:
- Include rollback plan
specs:
- Use Given/When/Then formatcontext 字段给 AI 提供技术栈背景,rules 为每种工件定义额外约束。比如要求每个 proposal 必须包含回滚计划,每个 spec 必须使用 Given/When/Then 格式。这些约束会在生成工件时自动注入到 AI 的上下文中——等于给 AI 加了一层看不见的围栏。
另外,OpenSpec 支持 25+ 种 AI 编码工具,不绑定特定平台。通过 openspec init --tools claude,cursor 可以同时为多个工具生成 Skills 文件。这意味着你的团队里有人用 Cursor 有人用 Claude Code,规范层是统一的。
2. OMC:多智能体编排,把执行落到实处
定位与核心理念
如果说 OpenSpec 是建筑图纸,OMC 就是施工队。它的定位是 Claude Code 的多智能体编排系统,通过 Hooks、Skills、Agents、State 四大互锁系统,把复杂的开发任务拆解成多个专业 Agent 的协同工作。
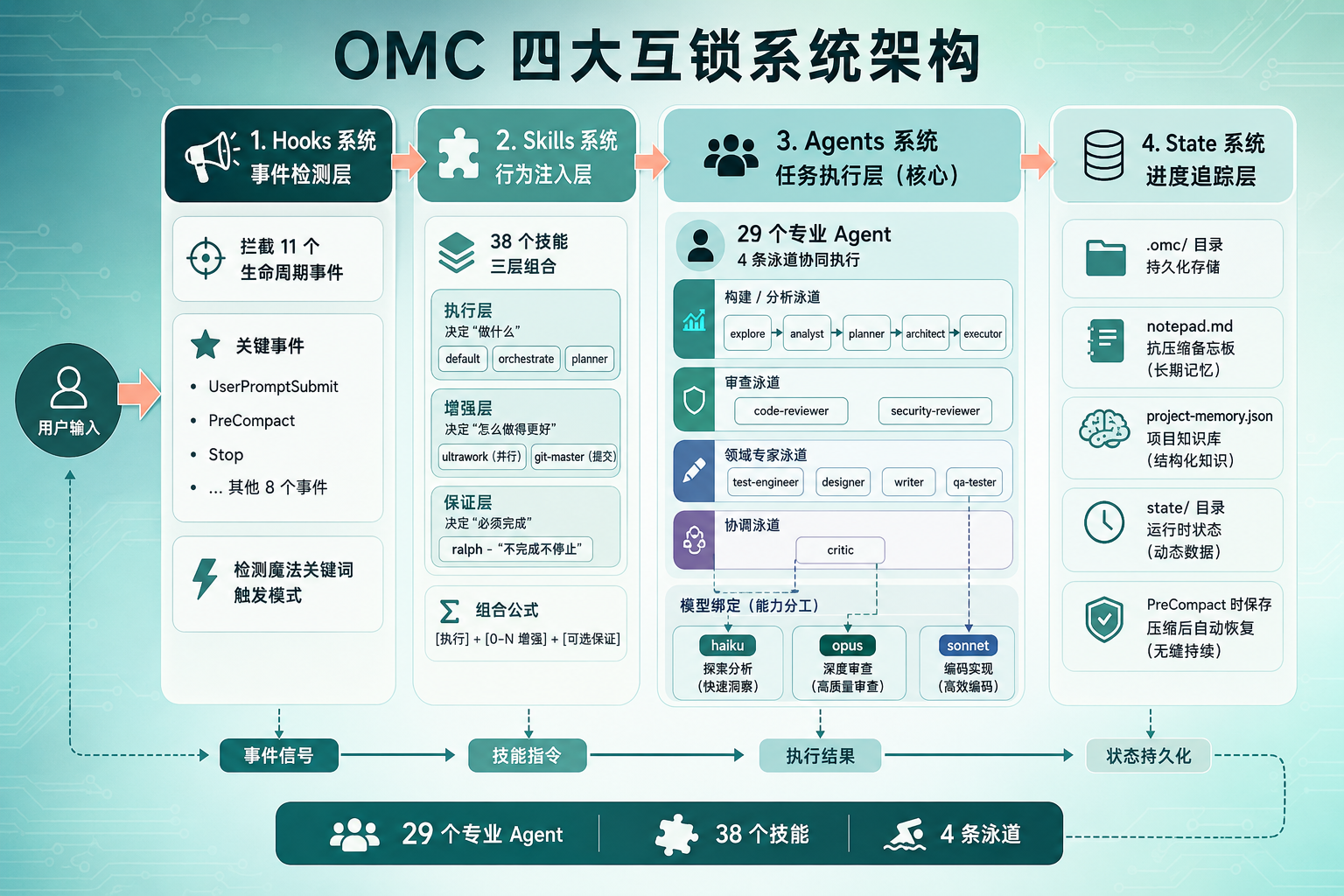
OMC 四大互锁系统流程图
图 3:OMC 四大互锁系统——Hooks → Skills → Agents → State
四大互锁系统
OMC 的架构可以用一条流水线来概括:
User Input → Hooks(事件检测)→ Skills(行为注入)→ Agents(任务执行)→ State(进度追踪)Hooks 系统拦截 11 个生命周期事件。比如 UserPromptSubmit 用来检测魔法关键词(后面会讲到),PreCompact 在上下文压缩前保存关键信息到 notepad,Stop 事件则可以强制 Claude 继续执行。
Skills 系统有 38 个技能,分三层组合:
Guarantee Layer(可选):ralph - "不完成不停止"
Enhancement Layer(0-N):ultrawork(并行)| git-master(提交)
Execution Layer(主要):default | orchestrate | planner组合公式是:[执行技能] + [0-N 增强技能] + [可选保证技能]。比如 orchestrate + ultrawork + ralph 就是编排模式 + 并行执行 + 不完成不停止。
Agents 系统是 OMC 的核心执行层,29 个专业 Agent 分布在 4 条泳道:
泳道 | Agent 示例 | 角色 |
|---|---|---|
Build/Analysis | explore、analyst、planner、architect、executor | 从代码探索到架构设计到代码实现 |
Review | code-reviewer、security-reviewer | 代码质量和安全审查 |
Domain | test-engineer、designer、writer、qa-tester | 测试、UI、文档等专业领域 |
Coordination | critic | 计划审查和质量把关 |
每个 Agent 默认绑定了模型级别:haiku(快速便宜)负责代码探索,opus(高推理质量)负责架构设计和审查,sonnet(平衡)负责日常编码和测试。
State 系统解决了一个很实际的问题:Claude Code 的上下文窗口有限,压缩后容易丢失关键信息。OMC 用 .omc/ 目录下的 notepad(抗压缩备忘板)、project-memory.json(项目知识库)、state/(运行时状态)来实现跨会话的持久化。
.omc/
├── state/ # 每模式状态文件
│ ├── autopilot-state.json
│ ├── team/
│ └── sessions/
├── notepad.md # 抗压缩备忘板
├── project-memory.json # 项目知识库
├── plans/ # 执行计划
└── logs/ # 执行日志Notepad 是其中比较精巧的设计。它通过 MCP 工具读写,在 PreCompact 事件时保存关键信息(比如当前任务的进度、重要的设计决策)。上下文压缩后,这些信息会自动重新注入。说白了就是给 AI 一个压缩抵抗的外挂记忆。
Team 模式:五阶段流水线
OMC 推荐的编排方式是 Team 模式,分为五个阶段:
team-plan → team-prd → team-exec → team-verify → team-fix(循环)规划、需求、执行、验证、修复形成循环,直到验证通过。这和 OpenSpec 的 propose → apply → verify 有异曲同工之处,但 OMC 的关注点在工程执行层面。
魔法关键词
OMC 有个挺有意思的设计:通过魔法关键词触发不同的执行模式。输入 autopilot 启动全自主执行,ralph 激活持久循环(不完成不停止),ultrawork 或 ulw 开启并行化,team 则进入 Team 编排模式。
这些关键词通过 Hooks 系统在 UserPromptSubmit 事件中被检测,然后自动注入对应的 Skills。用户不需要记忆复杂的命令,只要在对话中自然地提到关键词就行。
除了单机编排,OMC v4.4.0+ 还引入了 tmux CLI 工作者,可以跨终端分派任务:
/omc-teams 2:codex "security review"
/omc-teams 2:gemini "redesign UI"这行命令的意思是:在第 2 个 tmux 窗格中,分别用 Codex 和 Gemini 执行不同的任务。OMC 的 ccg 关键词更进一步,同时调度 Claude + Codex + Gemini 三个模型协作。
还有一个容易被忽略的功能:自定义技能。项目作用域的技能放在 .omc/skills/(受版本控制,团队共享),用户作用域的放在 ~/.omc/skills/(所有项目通用)。通过 /skillify 命令可以从当前操作中提取可复用模式,生成新的 Skill。匹配的技能会在后续会话中自动注入——等于 AI 能从你的操作习惯中自动学习。
3. 协同机制:当建筑图纸遇上施工队
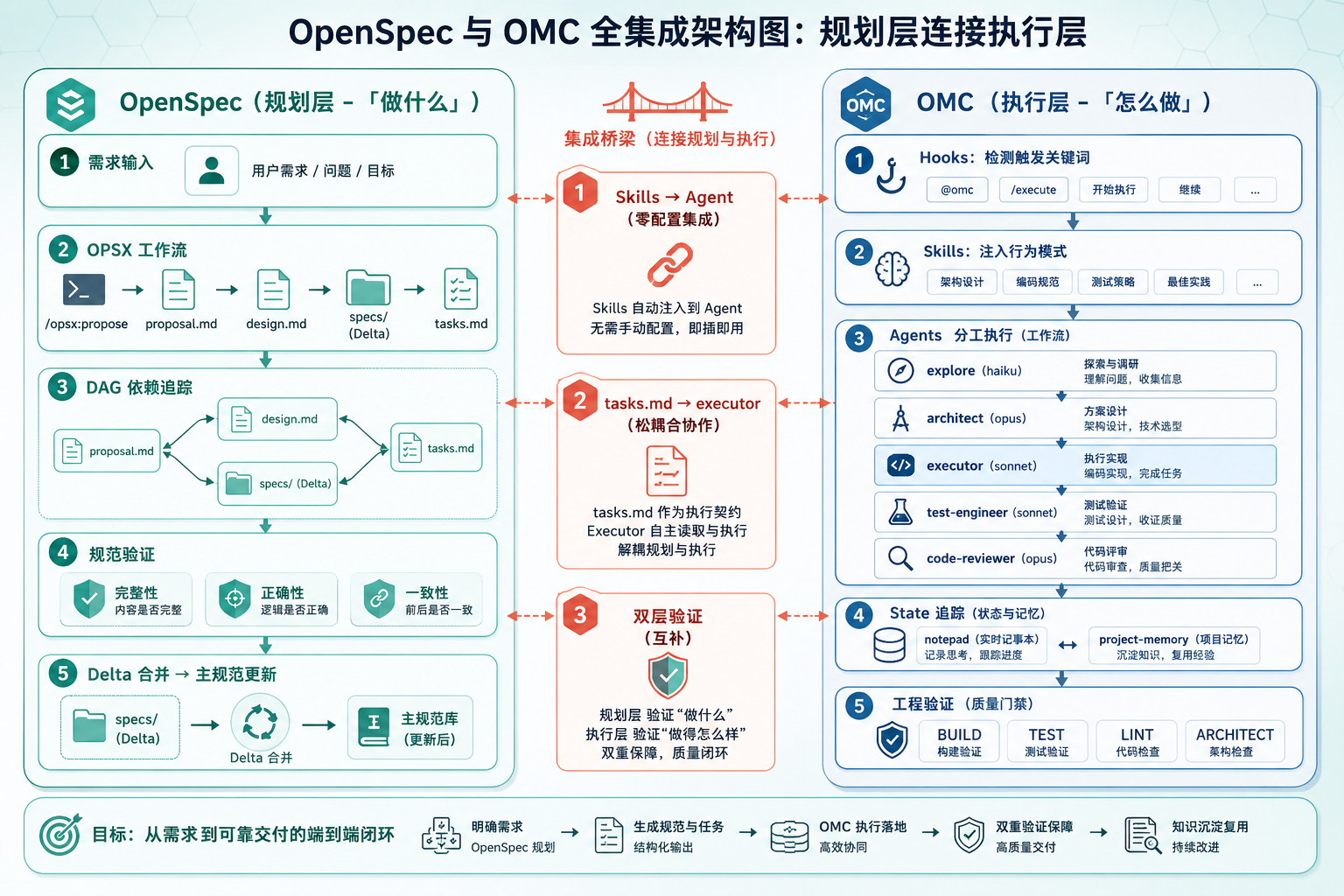
OpenSpec + OMC 联合工作流全景架构图
图 4:OpenSpec + OMC 联合工作流全景——三条关键集成链路
这节是整篇文章的核心。单独看 OpenSpec 和 OMC,它们各自解决了一半的问题。但当它们配合起来,从规划到执行才形成了真正的闭环。
架构层面的互补关系
先说一个关键判断:OpenSpec 和 OMC 不是竞品,它们在不同的抽象层工作。
维度 | OpenSpec | OMC |
|---|---|---|
核心关注点 | 做什么(What) | 怎么做(How) |
工作流阶段 | 规划期 | 执行期 |
多工具支持 | 25+ AI 工具 | Claude Code(+ Codex/Gemini 可选) |
状态管理 | 文件系统(DAG 状态检测) |
|
验证机制 | 完整性/正确性/一致性 | BUILD/TEST/LINT/ARCHITECT |
OpenSpec 管的是这个功能应该满足什么需求、遵循什么规范,OMC 管的是用什么 Agent 去实现、用什么模型去做 code review、怎么追踪进度。
打个比方:OpenSpec 是产品经理写的 PRD 和设计稿,OMC 是项目经理排的迭代计划和分工表。两者缺一不可——没有 PRD 的开发是盲人摸象,没有计划排期的 PRD 是一纸空文。
Skills → Agent 的链路
这是两个工具之间最直接的连接点。
OpenSpec 通过 openspec init --tools claude 在项目中生成 Skills 文件,路径是 .claude/skills/openspec-*/SKILL.md。OMC 作为 Claude Code 的插件,会自动发现并加载这些 Skills。
也就是说,当你用 OpenSpec 定义好一个变更后,OMC 的 Agent 能直接读取这些规范文件作为执行上下文。不需要手动复制粘贴,也不需要额外的配置。
具体的路径是:OpenSpec 的 init 命令在 .claude/skills/openspec-apply-change/SKILL.md 等位置生成技能描述文件。OMC 启动时会扫描这些路径,把 OpenSpec 的规范上下文注入到 Agent 的指令集中。当 executor agent 接到任务时,它已经知道项目的技术栈、变更的目标、设计约束等信息。
这种设计的好处是零配置集成。你不需要写胶水代码,不需要配置 API 对接,两个工具通过共享的文件系统自然地交换信息。
tasks.md → executor agent 的任务传导
OpenSpec 在变更目录下生成 tasks.md,格式是标准的 checkbox 列表:
- [ ] 1.1 创建认证中间件
- [ ] 1.2 实现 JWT 签发和验证
- [ ] 1.3 添加权限校验装饰器OMC 的 executor agent 可以逐条执行这些任务。每完成一项,勾选 checkbox。OMC 的 verifier agent 可以验证完成状态。这不是两个系统之间的 API 对接,而是通过共享的文件格式实现了松耦合的协作。
双层校验:规范验证 + 工程验证
这是协同使用中价值最高的部分。
OpenSpec 的 /opsx:verify 从三个维度验证实现:
- Completeness:所有任务完成、所有需求实现
- Correctness:实现匹配规范意图、边界条件处理
- Coherence:设计决策反映在代码中、模式一致
OMC 的验证协议从工程角度检查:
- BUILD:编译通过
- TEST:所有测试通过
- LINT:无 Lint 错误
- ARCHITECT:Opus 级别审查通过
两层验证互补:OpenSpec 确保你做对了事情(Do the right things),OMC 确保你把事情做对了(Do things right)。
状态追踪的互补
OpenSpec 用文件系统追踪工件状态。proposal.md 存在就说明提案完成,tasks.md 里的 checkbox 勾选了就说明任务完成。简单直接,但粒度有限。
OMC 用 .omc/state/ 追踪运行时进度,支持 notepad(跨压缩的信息持久化)和 project-memory(项目知识积累)。粒度更细,但和规范层没有直接关联。
两个系统叠加后,宏观进度看 OpenSpec 的工件完成度,微观进度看 OMC 的运行时状态。
4. 实战演示:给项目添加认证功能
说完了原理,来跑一遍完整流程。假设要给一个现有的 Node.js 项目添加用户认证功能。
第一阶段:OpenSpec 规划
# 安装 OpenSpec
npm install -g @fission-ai/openspec@latest
# 初始化(指定使用 Claude Code)
cd your-project
openspec init --tools claude初始化后,用 OPSX 工作流创建变更:
/opsx:propose add-auth这条命令会在 openspec/changes/add-auth/ 目录下生成所有规划工件:
# .openspec.yaml 变更元数据
name: add-auth
status: planning# proposal.md - 为什么做、做什么
## 动机
系统目前没有用户认证,所有接口裸奔。
## 目标
添加 JWT 认证,支持登录、注册、token 刷新。# design.md - 技术方案
## 架构决策
使用 JWT + bcrypt,中间件模式拦截请求。
## API 设计
POST /auth/register, POST /auth/login, POST /auth/refresh# tasks.md - 实现清单
- [ ] 1.1 创建 User 模型和数据库迁移
- [ ] 1.2 实现密码哈希工具函数
- [ ] 1.3 创建认证中间件
- [ ] 1.4 实现注册接口
- [ ] 1.5 实现登录接口
- [ ] 1.6 实现 token 刷新接口
- [ ] 1.7 编写单元测试同时,OpenSpec 会在 .claude/skills/ 目录下生成对应的 SKILL.md 文件,为下一阶段的 OMC 执行做准备。
第二阶段:OMC 执行
# 安装 OMC(Claude Code 插件方式)
/plugin marketplace add https://github.com/Yeachan-Heo/oh-my-claudecode
/plugin install oh-my-claudecode
/omc-setup安装完成后,OMC 会自动发现 OpenSpec 生成的 Skills。现在用 ralph 模式执行任务:
ralph: 按照 openspec/changes/add-auth/tasks.md 逐条实现认证功能OMC 会这样编排执行:
- explore agent(haiku 模型)先扫描项目结构,了解现有代码的组织方式、路由配置、数据库连接等
- architect agent(opus 模型)读取
design.md,确认 JWT + bcrypt 的技术方案是否适配当前项目,评估是否有架构风险 - executor agent(sonnet 模型)逐条执行
tasks.md中的任务,每完成一项勾选 checkbox - test-engineer agent(sonnet 模型)编写单元测试,覆盖注册、登录、token 刷新等核心场景
- code-reviewer agent(opus 模型)做代码审查,关注安全性和代码质量
ralph 模式的关键特性是不完成不停止——如果验证没通过,会自动进入修复循环。
如果你有多个独立的任务想要并行执行,也可以用 Team 模式:
/team 3:executor "实现 openspec/changes/add-auth/tasks.md 中的认证功能"这条命令会启动 3 个并行的 executor agent 同时工作,每个负责 tasks.md 中的一部分任务。OMC 还支持混合编排,比如用 /omc-teams 2:codex "security review" 让 Codex 专门做安全审查。
第三阶段:双层验证
执行完成后,先跑 OpenSpec 的规范验证:
/opsx:verify检查三个维度:所有 tasks.md 的 checkbox 是否都勾选了(Completeness),实现是否符合 proposal 中定义的目标(Correctness),代码风格是否和 design.md 中的架构决策一致(Coherence)。
然后跑 OMC 的工程验证:
ultrawork: 运行所有测试,确认无回归检查 BUILD、TEST、LINT 是否全部通过。
两层验证都绿灯后,合并 Delta 规范并归档:
/opsx:sync
/opsx:archive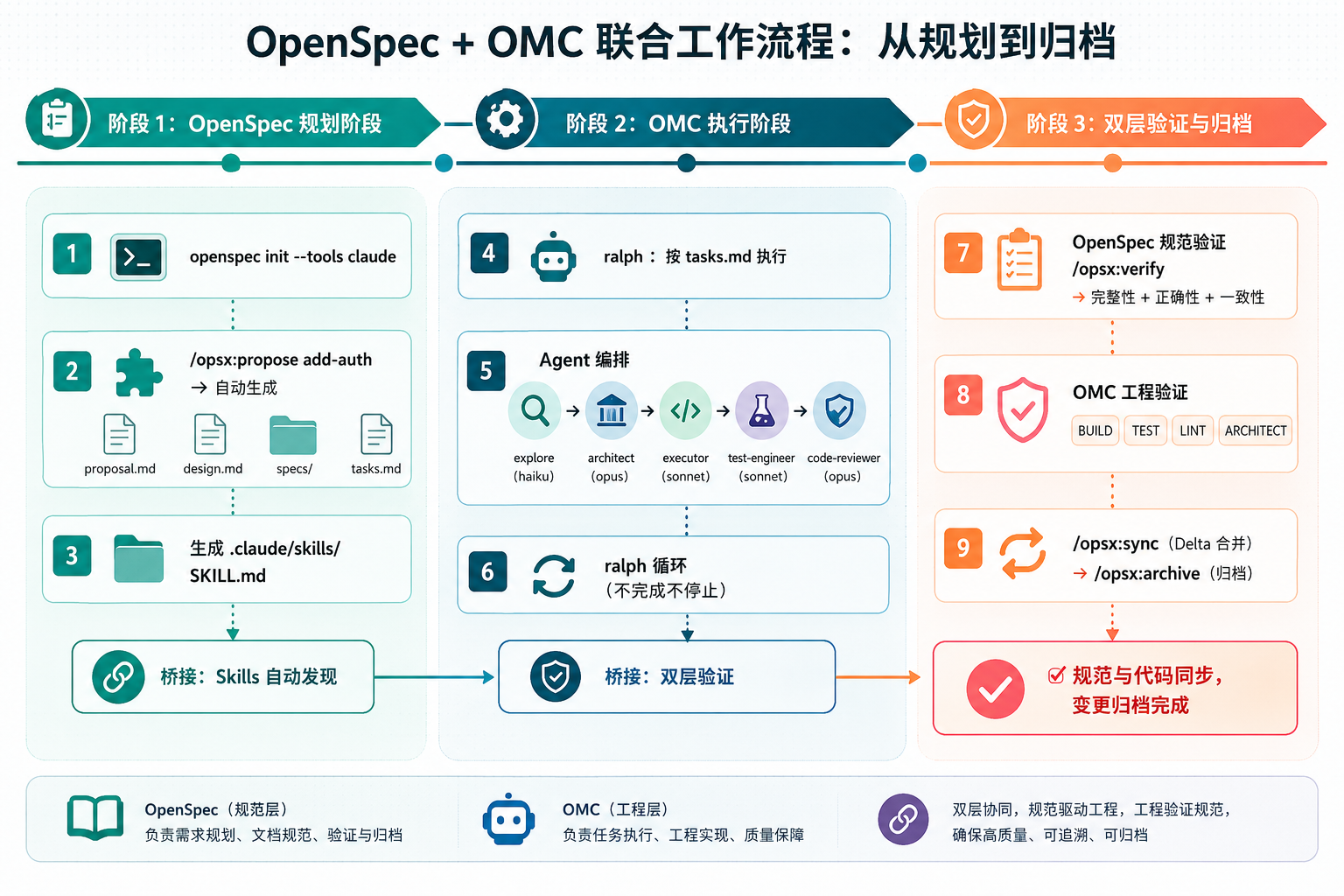
完整的 OpenSpec + OMC 联合工作流时序图
图 5:完整联合工作流时序——规划 → 执行 → 双层验证 → 归档
整个过程可以浓缩为:OpenSpec 负责把做什么说清楚,OMC 负责把执行落实到位,双层验证确保结果靠谱。
你在项目中用过类似的方案吗?比如用规范驱动开发,或者多 Agent 编排?欢迎在评论区聊聊你的经验。
5. 经验总结与最佳实践
翻了一圈官方文档和社区讨论,整理出一些实用建议。
何时只用 OpenSpec
如果你的团队已经在用成熟的 CI/CD 流水线和代码审查流程,OpenSpec 单独使用就够了。它的价值在于给 AI 编码助手提供上下文和约束,防止 AI 过度发挥。
另外一个重要场景:你的团队使用的 AI 编码工具不是 Claude Code。OpenSpec 支持 25+ 种 AI 工具,包括 Cursor、Windsurf、GitHub Copilot、Codex、Gemini CLI 等。OMC 目前只支持 Claude Code(虽然可以通过 tmux 调度 Codex 和 Gemini)。如果你的团队工具栈比较杂,OpenSpec 是更通用的选择。
从使用成本来看,OpenSpec 是纯本地工具,安装只需一条 npm 命令,不需要 API Key,不依赖特定平台。OMC 作为 Claude Code 的插件,需要先有 Claude Code 的订阅。
何时引入 OMC
当项目复杂度上升,单个 AI 会话搞不定的时候,OMC 的价值就体现出来了。29 个专业 Agent 分工协作,opus 级别的模型做架构审查,haiku 级别的做代码探索,既保证了质量又控制了成本。
特别适合这几种场景:
- 大规模代码重构:多个模块需要同步修改,单会话的上下文窗口装不下
- 多人协作的功能开发:需要 code review、security review 等多角色参与
- 严格质量把关:BUILD/TEST/LINT/ARCHITECT 四层验证一个都不能少
- 长时间任务:ralph 模式的不完成不停止特性适合跑批处理式的开发任务
联合使用的注意事项
说实话,两个系统叠加会增加配置的复杂度。几个坑需要提前知道:
- OpenSpec 需要 Node.js 20.19.0+,环境版本要先确认
- OMC 的 Team 模式需要启用实验性功能:
CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1 - OpenSpec 的上下文注入有 50KB 大小限制,复杂项目要控制规范文件的篇幅
- OMC 的 npm 包名是
oh-my-claude-sisyphus,不是oh-my-claudecode,别搜错了 - OpenSpec 官方推荐使用高推理模型(如 Codex 5.5、Opus 4.7)来执行规划任务,低配模型可能生成质量不够的工件
还有一个容易忽略的点:两个系统都通过 Skills 机制扩展,但 Skills 的目录结构不完全相同。OpenSpec 的 Skills 在 .claude/skills/openspec-*/,OMC 的自定义技能在 .omc/skills/。不会冲突,但需要清楚哪个文件归哪个系统管。
不同团队规模的建议
个人开发者:OpenSpec 单独使用足够。轻量、通用、不挑工具。日常开发中用 /opsx:propose 把需求理清楚,再用你惯用的 AI 编码助手执行就行。
2-5 人小团队:OpenSpec + OMC 的 autopilot 模式。规范对齐 + 自动执行,性价比高。OpenSpec 解决大家想的不是同一件事的问题,OMC 解决执行质量不稳定的问题。
5 人以上团队:OpenSpec + OMC 的 Team 模式。多 Agent 协作 + 双层验证,质量更有保障。OpenSpec 的 Delta 规范在多人协作时特别有用——每个人的变更都在独立目录里,合并冲突的概率低。
总结
说到底,AI 辅助开发的瓶颈已经从AI 能不能写代码转向了人怎么和 AI 有效协作。纯粹的 prompt engineering 解决不了系统性的问题——你不可能每次都把所有上下文和约束塞进一个 prompt 里。
OpenSpec 用结构化的规范层解决了对齐的问题。OMC 用多智能体编排解决了执行的问题。两者协同,让从规划到落地的整条链路不再是两条平行线。
如果你正在用 AI 编程助手做复杂项目,建议先试试 OpenSpec 的 openspec init,感受一下规范驱动的开发流程。等项目的复杂度上来了,再把 OMC 加进来做编排和质量保证。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号