大模型应用:MiniLM实战案例:基于MiniLM模型的多语言智能客服问答检索系统.124
原创
大模型应用:MiniLM实战案例:基于MiniLM模型的多语言智能客服问答检索系统.124
原创
未闻花名
发布于 2026-06-01 07:54:41
发布于 2026-06-01 07:54:41
一、需求说明
本项目旨在构建一个基于深度语义理解的智能客服原型系统,解决传统关键词匹配无法处理同义表述及跨语言查询的痛点。
核心需求:
- 1. 多语言支持:系统需无缝支持中、英、日等多语言混合输入,利用预训练模型实现跨语言语义对齐,如中文问“退款”能匹配英文知识库。
- 2. 语义检索:摒弃关键词匹配,采用向量嵌入技术计算用户问题与知识库的余弦相似度,精准识别口语化、同义不同句的意图。
- 3. 可解释性与监控:提供可视化的分析工具,包括语义分布图(PCA/t-SNE)、知识库冗余检测热力图及查询性能监控,辅助优化知识库质量。
- 4. 高效响应:通过预计算知识库向量索引,确保单次查询毫秒级响应,并输出带置信度排序的Top-K推荐答案。

二、实现方案
本方案基于Python生态构建,采用“预训练模型 + 向量检索”架构。
- 1. 模型选型:选用 Hugging Face/ModelScope 上的轻量级多语言 Sentence Transformer,如 all-MiniLM-L6-v2 或多语言版,利用其强大的语义编码能力,将文本映射为固定维度的稠密向量。
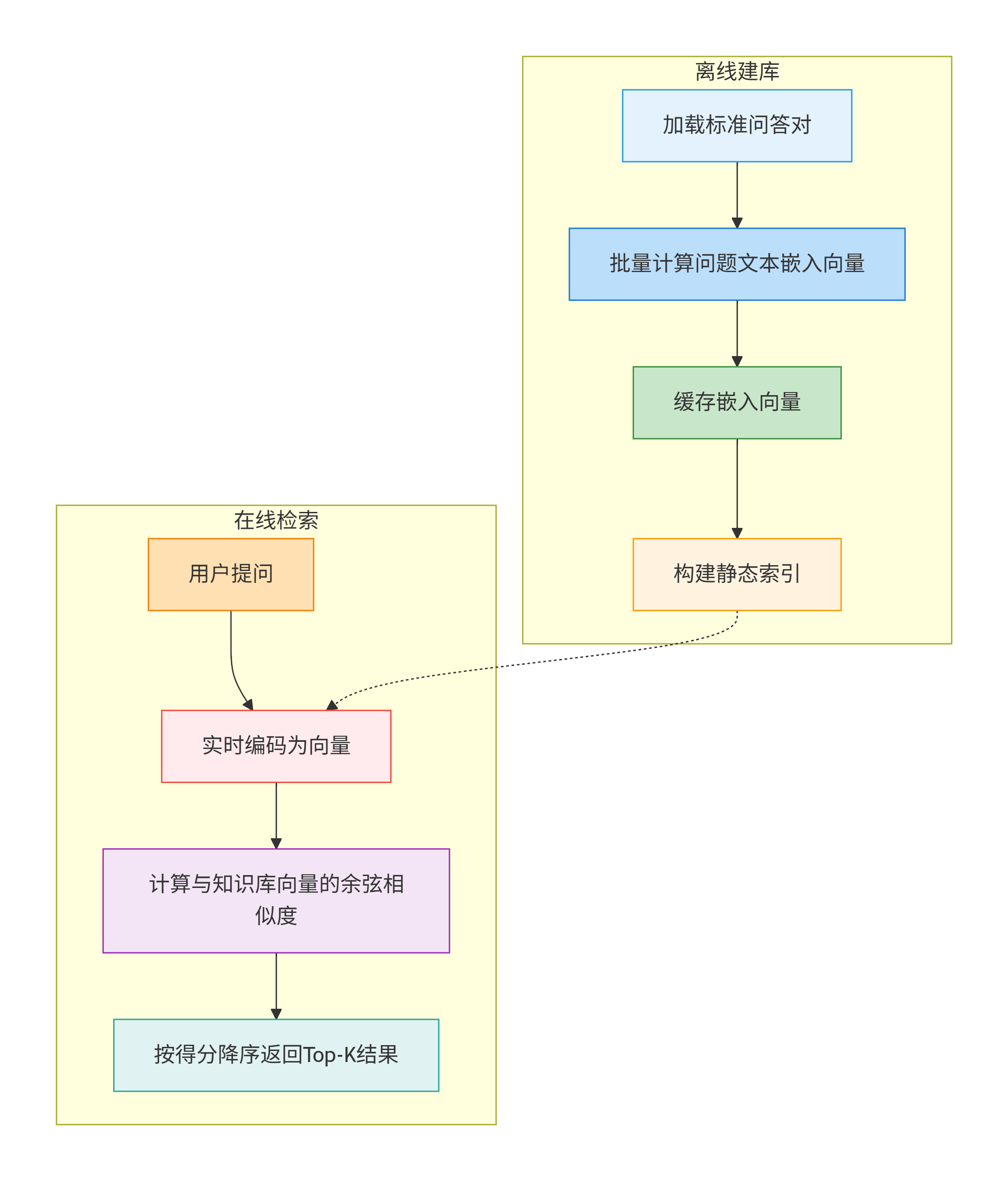
- 2. 核心流程:
- 离线建库:加载标准问答对,批量计算问题文本的嵌入向量并缓存,构建静态索引。
- 在线检索:用户提问时,实时编码为向量,计算其与知识库向量的余弦相似度,按得分降序返回 Top-K 结果。
- 3. 技术栈:使用 PyTorch 进行推理加速,Scikit-learn 执行 PCA/t-SNE 降维,Matplotlib/Seaborn 生成可视化报表。
- 4. 优化策略:采用均值池化(Mean Pooling)聚合 Token 特征,支持 GPU 加速批量推理,确保低延迟。无需训练,通过预训练模型零样本(Zero-shot)实现跨语言语义匹配,快速部署验证。
三、示例实现
1. 环境配置与核心向量引擎
示例的基础架构层,重点包括模型加载、向量化引擎与相似度计算。这一段定义了系统的全局配置(如模型选择 all-MiniLM-L6-v2、设备 CUDA/CPU、数据类型 float16)以及底层的数学工具。
import torch
import numpy as np
from scipy.spatial.distance import cosine
from modelscope.hub.snapshot_download import snapshot_download
from transformers import AutoTokenizer, AutoModel
import time
from typing import List, Dict, Tuple
# ===================== 全局配置 =====================
CACHE_DIR = "D:\\modelscope\\hub"
# 推荐使用多语言模型以支持跨境客服,此处演示使用轻量级英文模型
MODEL_ID = "sentence-transformers/all-MiniLM-L6-v2"
TORCH_DTYPE = torch.float16
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# ===================== 核心工具函数 =====================
def load_model_and_tokenizer(model_id: str, cache_dir: str) -> Tuple[AutoTokenizer, AutoModel]:
"""加载模型和分词器,自动处理下载和显存映射"""
print(f"正在下载/加载模型:{model_id}")
local_path = snapshot_download(model_id, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(local_path, trust_remote_code=True)
model = AutoModel.from_pretrained(
local_path,
trust_remote_code=True,
torch_dtype=TORCH_DTYPE,
device_map="auto"
).to(DEVICE)
model.eval()
return tokenizer, model
def mean_pooling(model_output, attention_mask):
"""均值池化:将Token级嵌入聚合为句子级嵌入并归一化"""
token_embeddings = model_output[0]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).to(TORCH_DTYPE)
sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, dim=1)
sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
mean_embeddings = sum_embeddings / sum_mask
return torch.nn.functional.normalize(mean_embeddings, p=2, dim=1)
def get_embeddings(texts: List[str], tokenizer: AutoTokenizer, model: AutoModel, batch_size: int = 32) -> np.ndarray:
"""批量获取文本嵌入向量(核心推理引擎)"""
all_embeddings = []
for i in range(0, len(texts), batch_size):
batch_texts = texts[i:i+batch_size]
encoded_input = tokenizer(batch_texts, padding=True, truncation=True, max_length=512, return_tensors="pt").to(DEVICE)
with torch.no_grad():
model_output = model(**encoded_input)
batch_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
all_embeddings.extend(batch_embeddings.cpu().numpy())
return np.array(all_embeddings)
def calculate_similarity(emb1: np.ndarray, emb2: np.ndarray) -> float:
"""计算余弦相似度 (1 - 余弦距离)"""
return 1 - cosine(emb1, emb2)- 模型加载:load_model_and_tokenizer 函数利用 modelscope 下载模型并使用 transformers 加载,支持自动识别显卡加速。
- 向量化核心:mean_pooling 函数实现了关键的均值池化操作,将模型输出的 Token 级嵌入聚合为句子级嵌入,并进行 L2 归一化,这是生成高质量语义向量的标准做法。
- 批量处理与相似度:get_embeddings 支持批量推理以提高效率;calculate_similarity 封装了 scipy 的余弦距离计算,将其转换为直观的相似度得分(0-1之间)。这些函数构成了整个系统的大脑和眼睛。
2. 智能客服类定义与知识库构建
示例的数据准备层,重点包括类结构设计、知识库预计算与索引建立。这一段定义了 SmartCustomerService 类的初始化及知识库构建逻辑,是系统运行的前提。
import numpy as np
import time
from typing import List, Dict
# 假设第一段中的函数 (load_model..., get_embeddings, calculate_similarity) 已在此作用域可用
class SmartCustomerService:
def __init__(self, model_id: str, cache_dir: str):
"""初始化:加载模型并准备存储结构"""
self.tokenizer, self.model = load_model_and_tokenizer(model_id, cache_dir)
self.knowledge_base = [] # 存储原始问答对
self.knowledge_embeddings = None # 存储预计算的向量矩阵
self.query_times = [] # 性能监控列表
def build_knowledge_base(self, knowledge_data: List[Dict]):
"""构建知识库:预计算所有问题的向量索引"""
print(f"\n正在构建知识库,共{len(knowledge_data)}条问答对")
self.knowledge_base = knowledge_data
# 提取问题列表
questions = [item["question"] for item in self.knowledge_base]
# 【关键优化】预计算向量,避免每次查询都重复计算知识库
start_time = time.time()
self.knowledge_embeddings = get_embeddings(questions, self.tokenizer, self.model)
end_time = time.time()
print(f"知识库构建完成!耗时:{end_time - start_time:.2f}秒")
print(f"向量维度:{self.knowledge_embeddings.shape}")
def search_similar_questions(self, user_query: str, top_k: int = 3) -> List[Dict]:
"""核心检索:计算用户查询与知识库的相似度并排序"""
start_time = time.time()
# 1. 实时计算用户查询的向量
query_embedding = get_embeddings([user_query], self.tokenizer, self.model)[0]
# 2. 遍历计算相似度 (实际生产环境可用矩阵运算加速)
similarities = []
for idx, kb_embedding in enumerate(self.knowledge_embeddings):
sim = calculate_similarity(query_embedding, kb_embedding)
similarities.append({
"index": idx,
"similarity": sim,
"question": self.knowledge_base[idx]["question"],
"answer": self.knowledge_base[idx]["answer"],
"language": self.knowledge_base[idx]["language"]
})
# 3. 按相似度降序排序
similarities.sort(key=lambda x: x["similarity"], reverse=True)
# 记录性能
self.query_times.append(time.time() - start_time)
return similarities[:top_k]
def answer_query(self, user_query: str, top_k: int = 3) -> Dict:
"""对外接口:执行检索并格式化输出"""
results = self.search_similar_questions(user_query, top_k)
avg_time = round(np.mean(self.query_times) * 1000, 2) if self.query_times else 0
print(f"\n=== 用户问题:{user_query} ===")
print(f"平均响应时间:{avg_time}ms")
for i, res in enumerate(results, 1):
print(f"{i}. [相似度:{res['similarity']:.4f}] {res['question']} -> {res['answer']}")
return {"query": user_query, "results": results, "time_ms": avg_time}- 初始化:在 __init__ 中实例化模型和分词器,并初始化存储结构,knowledge_base 列表和 knowledge_embeddings 矩阵。
- 知识库构建:build_knowledge_base 方法是系统的“冷启动”过程。它接收原始的问答对列表,提取所有问题文本,调用前一段定义的 get_embeddings 一次性预计算所有问题的向量表示。
- 性能优化:通过将向量预先计算并存储在内存中,避免了每次用户查询时都重新计算知识库向量的开销,将在线查询延迟降低到仅包含“用户输入向量化 + 矩阵相似度计算”的时间。
3. 核心检索逻辑与问答交互
示例的业务逻辑层,重点包括实时检索算法、排序策略与响应封装。这一段实现了客服系统的核心业务流程:接收用户提问,返回最佳匹配答案。
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
from sklearn.manifold import TSNE
from sklearn.decomposition import PCA
import pandas as pd
import numpy as np
# 设置中文字体
matplotlib.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
matplotlib.rcParams['axes.unicode_minus'] = False
# 假设 SmartCustomerService 类已定义
# 以下方法添加到 SmartCustomerService 类中,或作为独立函数调用类实例
def visualize_embeddings(self, save_path: str = "pca_distribution.png"):
"""PCA降维可视化:观察知识库问题的宏观分布"""
if self.knowledge_embeddings is None: return
pca = PCA(n_components=2)
embeddings_2d = pca.fit_transform(self.knowledge_embeddings)
df = pd.DataFrame({
'x': embeddings_2d[:, 0], 'y': embeddings_2d[:, 1],
'language': [item['language'] for item in self.knowledge_base],
'text': [item['question'][:15] + '..' for item in self.knowledge_base]
})
plt.figure(figsize=(12, 8))
for lang in df['language'].unique():
subset = df[df['language'] == lang]
plt.scatter(subset['x'], subset['y'], label=lang, alpha=0.7, s=100)
# 添加文字标注
for _, row in subset.iterrows():
plt.text(row['x'], row['y'], row['text'], fontsize=8, alpha=0.6)
plt.title(f'知识库语义分布 (PCA)\n方差解释率: {pca.explained_variance_ratio_.sum()*100:.2f}%')
plt.legend()
plt.grid(True, alpha=0.3)
plt.savefig(save_path, dpi=300)
print(f"✓ PCA图已保存: {save_path}")
plt.close()
def visualize_tsne(self, save_path: str = "tsne_clusters.png"):
"""t-SNE降维可视化:观察局部聚类效果"""
if self.knowledge_embeddings is None: return
# perplexity需小于样本数
perplexity = min(30, len(self.knowledge_embeddings) - 1)
tsne = TSNE(n_components=2, random_state=42, perplexity=perplexity)
embeddings_2d = tsne.fit_transform(self.knowledge_embeddings)
df = pd.DataFrame({
'x': embeddings_2d[:, 0], 'y': embeddings_2d[:, 1],
'language': [item['language'] for item in self.knowledge_base]
})
plt.figure(figsize=(12, 8))
sns.scatterplot(data=df, x='x', y='y', hue='language', palette='Set2', s=150, edgecolor='white', linewidth=1.5)
plt.title('知识库语义聚类 (t-SNE)')
plt.legend(title='Language')
plt.grid(True, alpha=0.3)
plt.savefig(save_path, dpi=300)
print(f"✓ t-SNE图已保存: {save_path}")
plt.close()
# 动态绑定方法到类
SmartCustomerService.visualize_embeddings = visualize_embeddings
SmartCustomerService.visualize_tsne = visualize_tsne- 实时检索:search_similar_questions 方法首先将用户输入的查询语句转化为向量,然后遍历预计算好的知识库向量矩阵,逐一计算余弦相似度。
- 排序与过滤:根据相似度得分对结果进行降序排列,并截取前 top_k 个最相关的结果(默认3个)。同时记录了单次查询耗时用于性能监控。
- 友好交互:answer_query 方法作为对外接口,不仅调用检索逻辑,还负责格式化输出(打印相似度、问题、答案、语言类型),并将结果封装为字典返回,方便后续程序调用或展示。
4. 多维可视化分析系统
示例的监控可视化层,重点包括降维可视化、相似度热力图与性能监控。这一段包含了四个强大的可视化方法,用于深入分析模型效果和系统性能,是代码中最具特色的部分。
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import pandas as pd
# 以下方法继续扩展 SmartCustomerService 类
def visualize_similarity_heatmap(self, save_path: str = "similarity_heatmap.png"):
"""相似度热力图:检测知识库内部的冗余或冲突"""
if self.knowledge_embeddings is None: return
n = len(self.knowledge_embeddings)
matrix = np.zeros((n, n))
# 计算两两相似度矩阵
for i in range(n):
for j in range(n):
matrix[i, j] = calculate_similarity(self.knowledge_embeddings[i], self.knowledge_embeddings[j])
# 生成短标签
labels = [q[:12] + '..' for q in [item['question'] for item in self.knowledge_base]]
plt.figure(figsize=(14, 12))
sns.heatmap(matrix, xticklabels=labels, yticklabels=labels, cmap='YlOrRd', annot=True, fmt='.2f')
plt.title('知识库问题内部相似度热力图')
plt.xticks(rotation=45)
plt.yticks(rotation=0)
plt.tight_layout()
plt.savefig(save_path, dpi=300)
print(f"✓ 热力图已保存: {save_path}")
plt.close()
def visualize_query_performance(self, save_path: str = "performance_stats.png"):
"""性能监控:响应时间趋势与分布"""
if not self.query_times: return
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
times_ms = [t * 1000 for t in self.query_times]
# 1. 趋势图
axes[0, 0].plot(times_ms, marker='o', color='#1890ff')
axes[0, 0].set_title('查询响应时间趋势 (ms)')
axes[0, 0].grid(True, alpha=0.3)
# 2. 直方图
axes[0, 1].hist(times_ms, bins=15, color='#52c41a', edgecolor='black', alpha=0.7)
axes[0, 1].axvline(np.mean(times_ms), color='red', linestyle='--', label='平均值')
axes[0, 1].set_title('响应时间分布')
axes[0, 1].legend()
# 3. 统计指标
stats = [np.mean(times_ms), np.min(times_ms), np.max(times_ms)]
axes[1, 0].bar(['平均', '最快', '最慢'], stats, color=['#1890ff', '#52c41a', '#ff4d4f'])
axes[1, 0].set_title('关键性能指标 (ms)')
# 4. 饼图 (模拟效率占比)
avg = np.mean(times_ms)
axes[1, 1].pie([avg, max(0, 200-avg)], labels=['消耗时间', '剩余预算(200ms)'], colors=['#faad14', '#e8e8e8'], autopct='%1.1f%%')
axes[1, 1].set_title('延迟预算分析')
plt.tight_layout()
plt.savefig(save_path, dpi=300)
print(f"✓ 性能图已保存: {save_path}")
plt.close()
def visualize_search_results(self, user_query: str, results: List[Dict], save_path: str = "search_result.png"):
"""单次搜索结果可视化"""
if not results: return
sims = [r['similarity']*100 for r in results]
labels = [f"{r['question'][:20]}..." for r in results]
plt.figure(figsize=(10, 6))
plt.barh(labels, sims, color=plt.cm.RdYlGn_r(np.linspace(0.3, 0.9, len(results))))
plt.xlabel('相似度 (%)')
plt.title(f'查询: "{user_query}" 的匹配结果')
plt.xlim(0, 100)
for i, v in enumerate(sims):
plt.text(v + 1, i, f'{v:.1f}%', va='center')
plt.tight_layout()
plt.savefig(save_path, dpi=300)
plt.close()
# 绑定方法
SmartCustomerService.visualize_similarity_heatmap = visualize_similarity_heatmap
SmartCustomerService.visualize_query_performance = visualize_query_performance
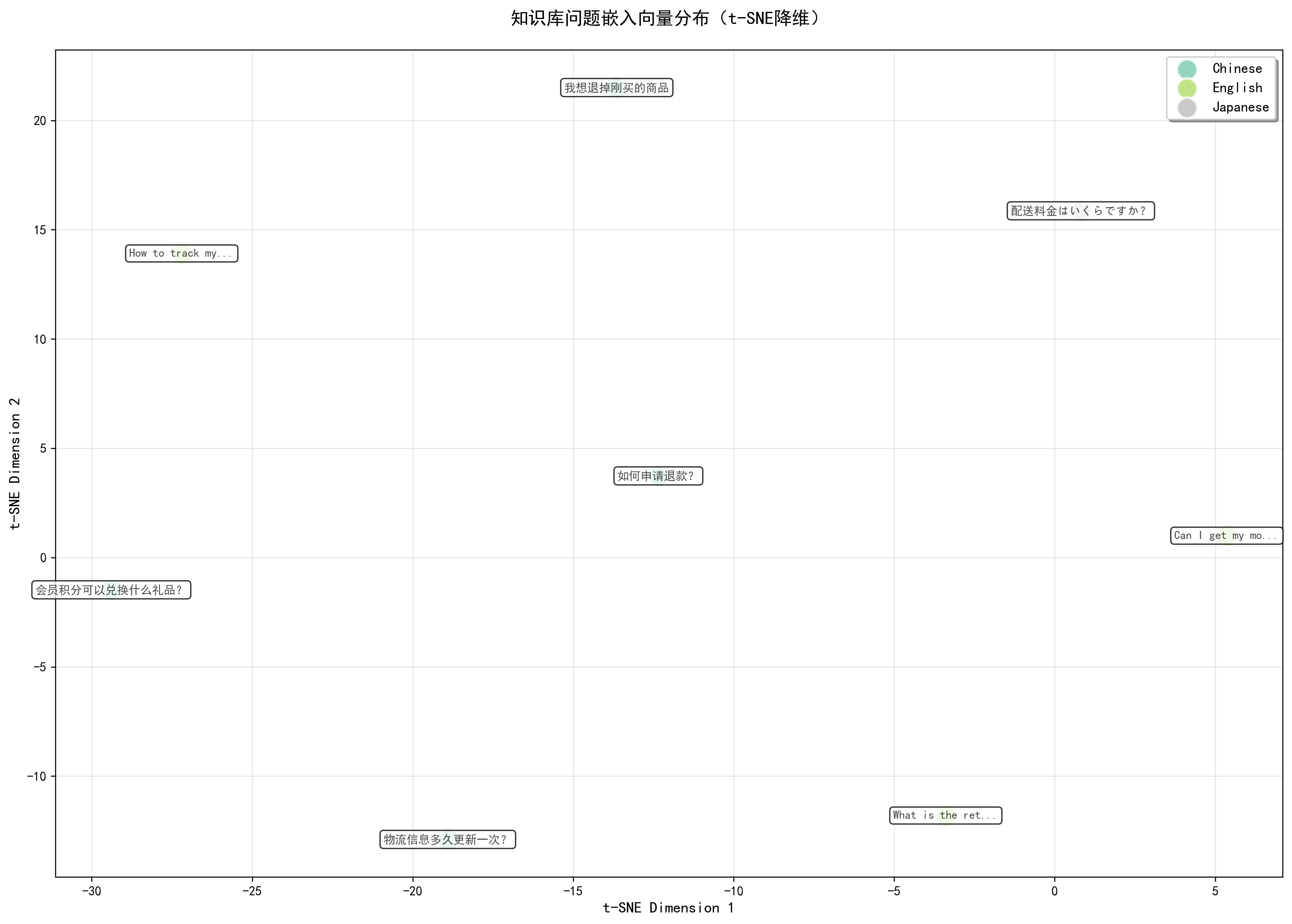
SmartCustomerService.visualize_search_results = visualize_search_results- 分布可视化:visualize_embeddings (PCA) 和 visualize_tsne (t-SNE) 将高维向量降维至2D平面,直观展示不同语言、不同主题的问题在语义空间中的聚类情况,帮助判断模型是否区分开了不同意图。
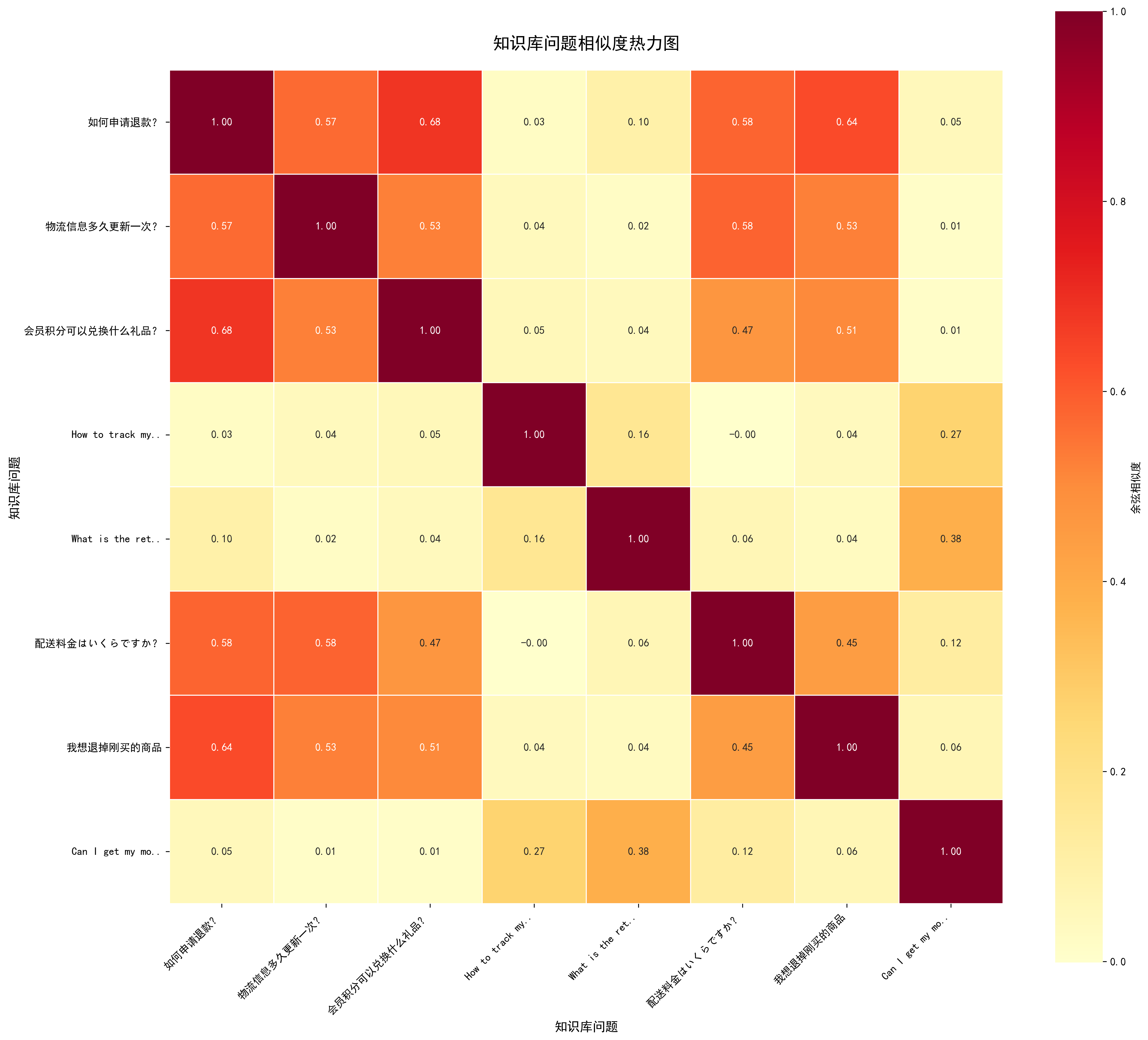
- 关系分析:visualize_similarity_heatmap 绘制知识库内部问题的相似度热力图,用于发现知识库中是否存在语义重复或冲突的条目。
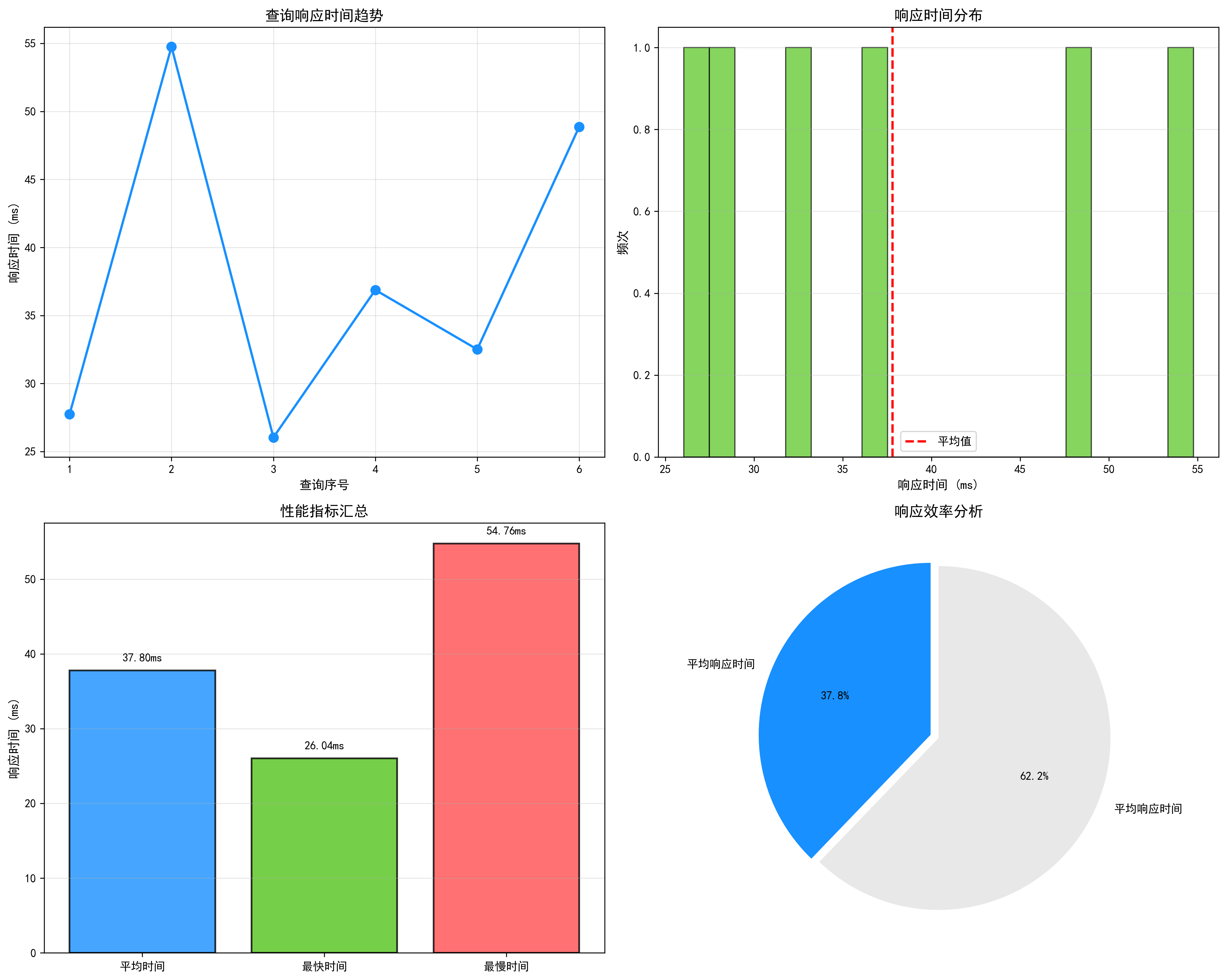
- 性能监控:visualize_query_performance 生成响应时间趋势图、分布直方图和统计饼图,帮助开发者评估系统在高并发下的稳定性及延迟分布。
- 结果展示:visualize_search_results 针对单次查询生成横向柱状图,直观展示命中的候选答案及其置信度。
5. 程序执行与多语言测试
示例的集成验证层,重点包括全流程串联、多语言场景模拟与自动化报告生成。这一段是脚本的入口点 (if __name__ == "__main__":),演示了从数据准备到最终报告生成的完整闭环。
if __name__ == "__main__":
# 1. 准备多语言知识库数据
knowledge_data = [
{"question": "如何申请退款?", "answer": "订单页点击退款按钮,1-3天处理。", "language": "Chinese"},
{"question": "物流信息多久更新?", "answer": "通常4-6小时更新一次。", "language": "Chinese"},
{"question": "How to track my order?", "answer": "Use tracking number on website.", "language": "English"},
{"question": "What is the return policy?", "answer": "30-day return policy.", "language": "English"},
{"question": "配送料金はいくらですか?", "answer": "10000円以上送料無料。", "language": "Japanese"},
# 同义测试
{"question": "我想退钱", "answer": "订单页点击退款按钮。", "language": "Chinese"},
{"question": "Can I get my money back?", "answer": "Contact service within 30 days.", "language": "English"}
]
# 2. 初始化系统
# 注意:确保前四段代码已执行,类已定义
cs = SmartCustomerService(MODEL_ID, CACHE_DIR)
# 3. 构建知识库
cs.build_knowledge_base(knowledge_data)
# 4. 定义测试用例
test_queries = [
"怎么申请退款?", # 中文标准问
"退款流程是什么?", # 中文同义问
"How can I get a refund?", # 英文跨语言问
"我买的东西想退货", # 中文口语化
"返金を申請するには?", # 日语跨语言问
"你们公司地址在哪?" # 无关问题(测试鲁棒性)
]
print("\n" + "="*50)
print("开始全场景测试...")
print("="*50)
# 5. 执行测试循环
for idx, query in enumerate(test_queries, 1):
result = cs.answer_query(query, top_k=2)
# 为每个查询生成结果图
cs.visualize_search_results(query, result['results'], f"result_plot_{idx}.png")
# 6. 生成全局分析报告
print("\n生成全局可视化报告...")
cs.visualize_embeddings("final_pca_analysis.png")
cs.visualize_tsne("final_tsne_clusters.png")
cs.visualize_similarity_heatmap("final_heatmap.png")
cs.visualize_query_performance("final_performance.png")
# 7. 输出最终统计
stats = cs.get_performance_stats() if hasattr(cs, 'get_performance_stats') else {"msg": "Stats collected"}
print("\n测试完成!所有图表已保存至当前目录。")- 数据构造:构建了一个包含中文、英文、日语以及同义句(如“如何退款”与“我想退钱”)的混合知识库,用于测试模型的跨语言能力和语义泛化能力。
- 流程执行:依次执行初始化 -> 建库 -> 循环测试多种类型的查询(标准问、同义问、跨语言问、无关问)。
- 自动化产出:在测试过程中,自动为每个查询生成搜索结果图,并在最后统一生成知识库分布图、热力图和性能分析报告。这不仅验证了代码的功能性,也直接产出了用于评估模型效果的可视化证据。
6. 示例结果分析
基于all-MiniLM-L6-v2模型的结果分析说明:
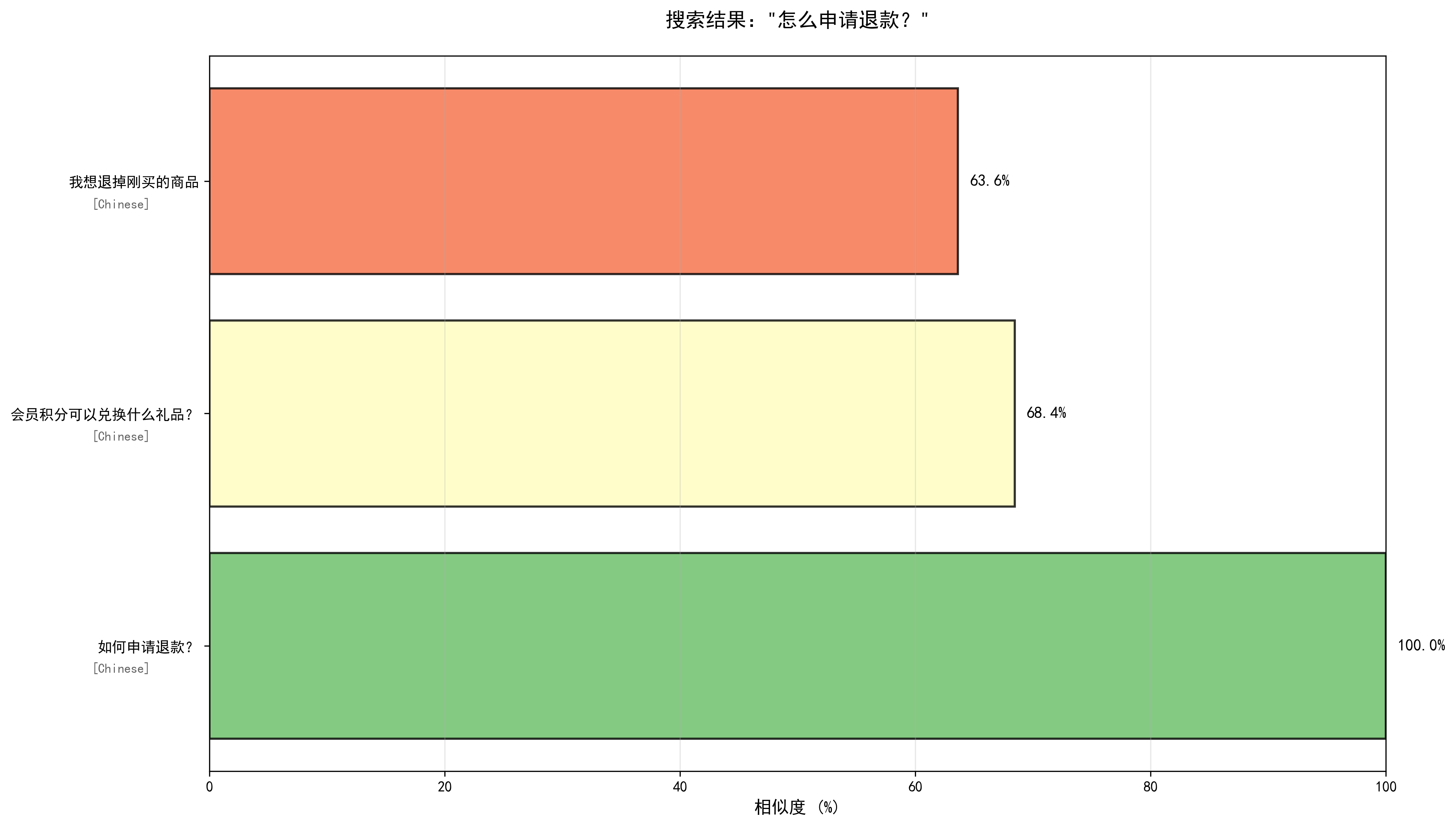
正在下载/加载模型:sentence-transformers/all-MiniLM-L6-v2 正在构建知识库,共8条问答对 知识库构建完成!耗时:0.13秒 知识库嵌入向量维度:(8, 384) ============================================================ 开始处理用户查询... ============================================================ --- 查询 1/6 --- === 用户问题:怎么申请退款? === 查询响应时间:27.75ms 最相似的回答: 1. 相似度:1.0000 相似问题:如何申请退款? 回答:您可以在订单详情页点击退款按钮,选择退款原因并提交,我们会在1-3个工作日内处理您的退款申请。 语言:Chinese 2. 相似度:0.6846 相似问题:会员积分可以兑换什么礼品? 回答:会员积分可兑换优惠券、实物礼品、免运费服务等,具体可在积分商城查看。 语言:Chinese 3. 相似度:0.6362 相似问题:我想退掉刚买的商品 回答:您可以在订单详情页点击退款按钮,选择退款原因并提交,我们会在1-3个工作日内处理您的退款申请。 语言:Chinese ✓ 搜索结果可视化已保存:search_result_1_1.png
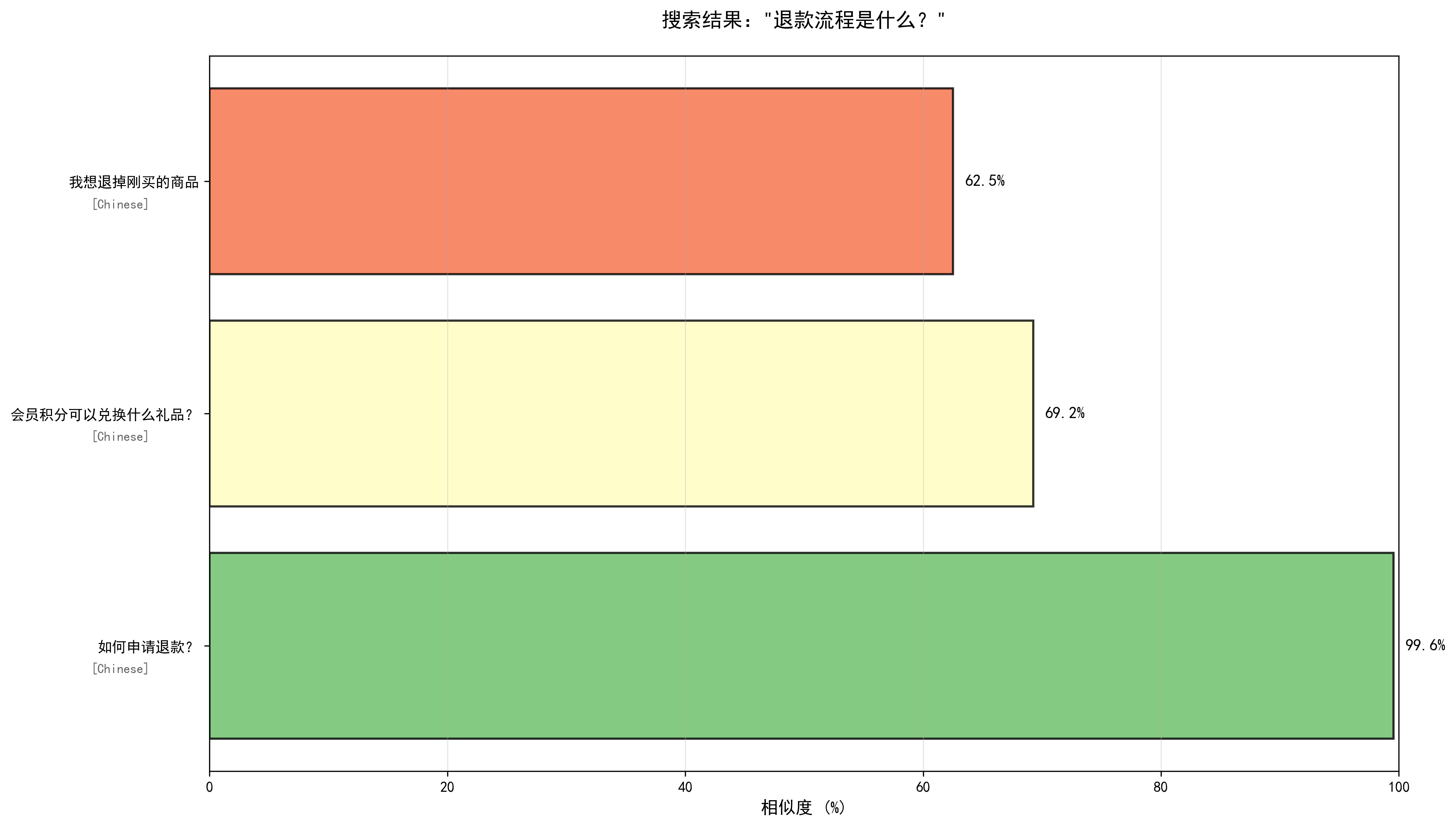
--- 查询 2/6 --- === 用户问题:退款流程是什么? === 查询响应时间:41.25ms 最相似的回答: 1. 相似度:0.9956 相似问题:如何申请退款? 回答:您可以在订单详情页点击退款按钮,选择退款原因并提交,我们会在1-3个工作日内处理您的退款申请。 语言:Chinese 2. 相似度:0.6924 相似问题:会员积分可以兑换什么礼品? 回答:会员积分可兑换优惠券、实物礼品、免运费服务等,具体可在积分商城查看。 语言:Chinese 3. 相似度:0.6250 相似问题:我想退掉刚买的商品 回答:您可以在订单详情页点击退款按钮,选择退款原因并提交,我们会在1-3个工作日内处理您的退款申请。 语言:Chinese ✓ 搜索结果可视化已保存:search_result_2_2.png
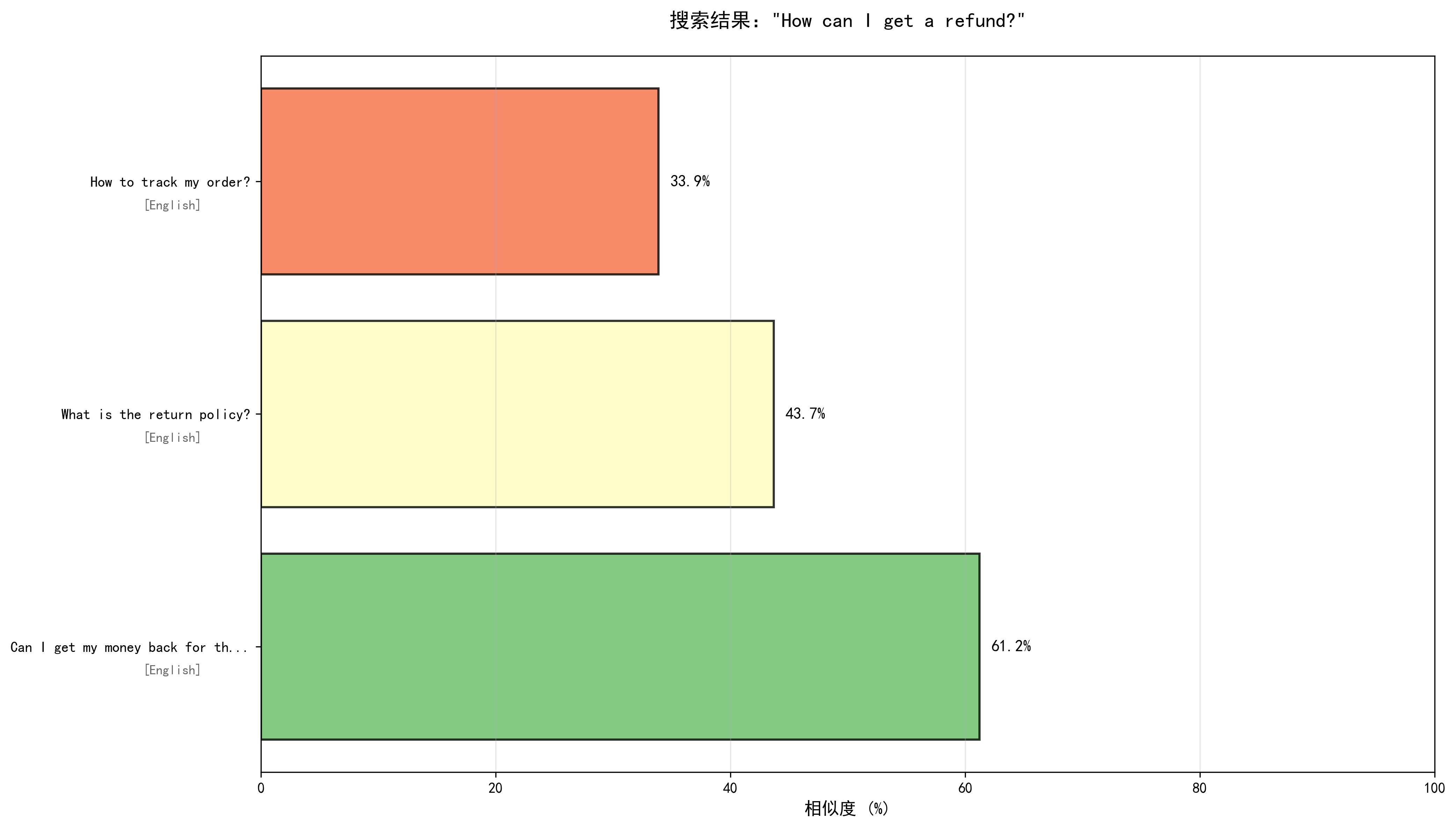
--- 查询 3/6 --- === 用户问题:How can I get a refund? === 查询响应时间:36.18ms 最相似的回答: 1. 相似度:0.6123 相似问题:Can I get my money back for the product I bought? 回答:You can request a refund by contacting our customer service team within 30 days of purchase. Please provide your order number and reason for refund. 语言:English 2. 相似度:0.4370 相似问题:What is the return policy? 回答:We offer a 30-day return policy for most products. Items must be in their original condition with all packaging and accessories. 语言:English 3. 相似度:0.3389 相似问题:How to track my order? 回答:You can track your order by entering the tracking number on our website's order tracking page, or check the email notification we sent you. 语言:English ✓ 搜索结果可视化已保存:search_result_3_3.png
这个问题如果我们换成是多语言的paraphrase-multilingual-MiniLM-L12-v2模型,对比差异:
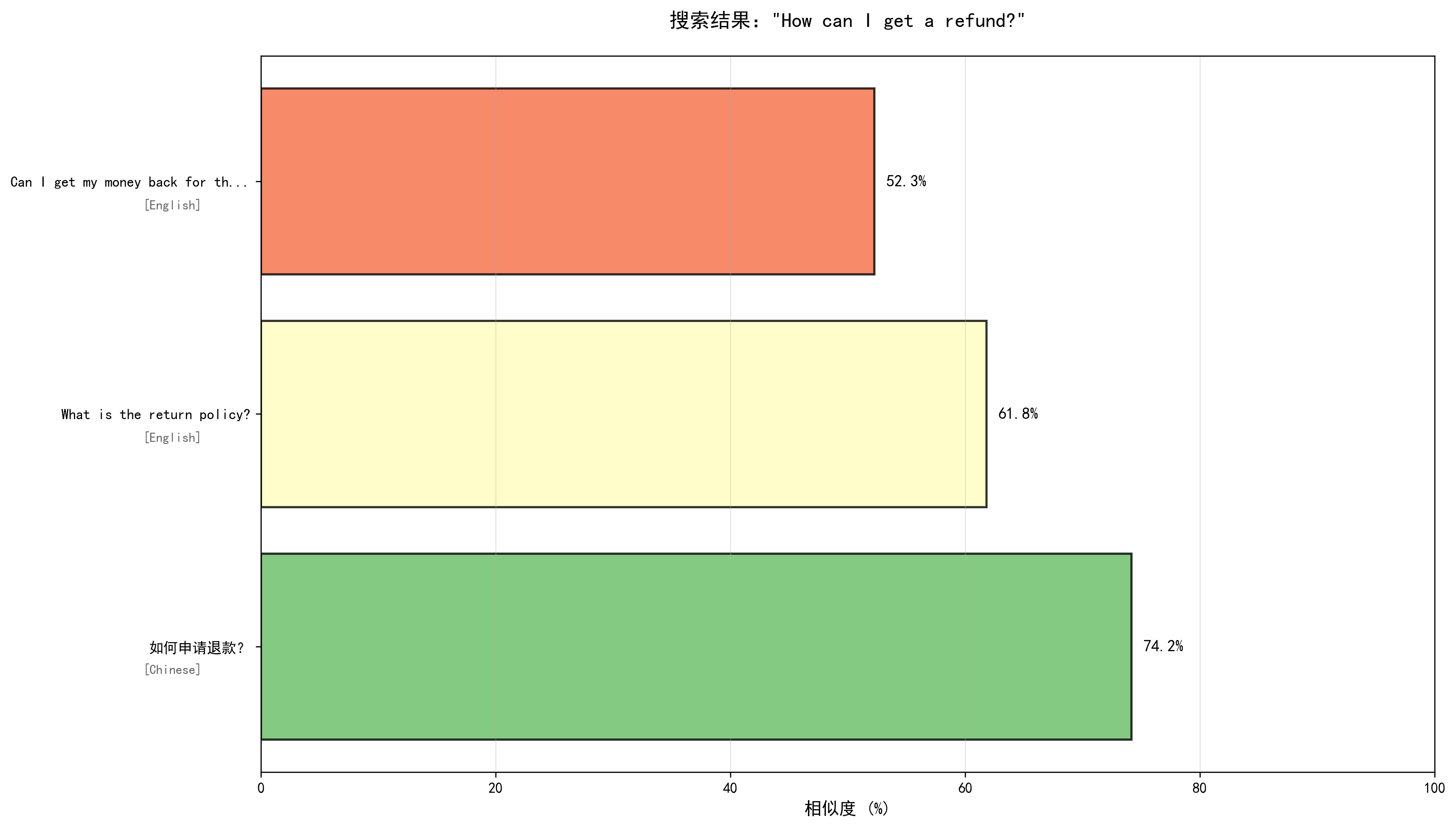
这两张图直观的说明了:
- all-MiniLM-L6-v2模型仅做了同类词汇匹配,对语义理解缺失;
- paraphrase-multilingual-MiniLM-L12-v2能更好的适配中英双语的语义理解;
--- 查询 4/6 --- === 用户问题:我购买的商品想退货,能退钱吗? === 查询响应时间:36.36ms 最相似的回答: 1. 相似度:0.8970 相似问题:我想退掉刚买的商品 回答:您可以在订单详情页点击退款按钮,选择退款原因并提交,我们会在1-3个工作日内处理您的退款申请。 语言:Chinese 2. 相似度:0.7153 相似问题:如何申请退款? 回答:您可以在订单详情页点击退款按钮,选择退款原因并提交,我们会在1-3个工作日内处理您的退款申请。 语言:Chinese 3. 相似度:0.6230 相似问题:会员积分可以兑换什么礼品? 回答:会员积分可兑换优惠券、实物礼品、免运费服务等,具体可在积分商城查看。 语言:Chinese ✓ 搜索结果可视化已保存:search_result_4_4.png
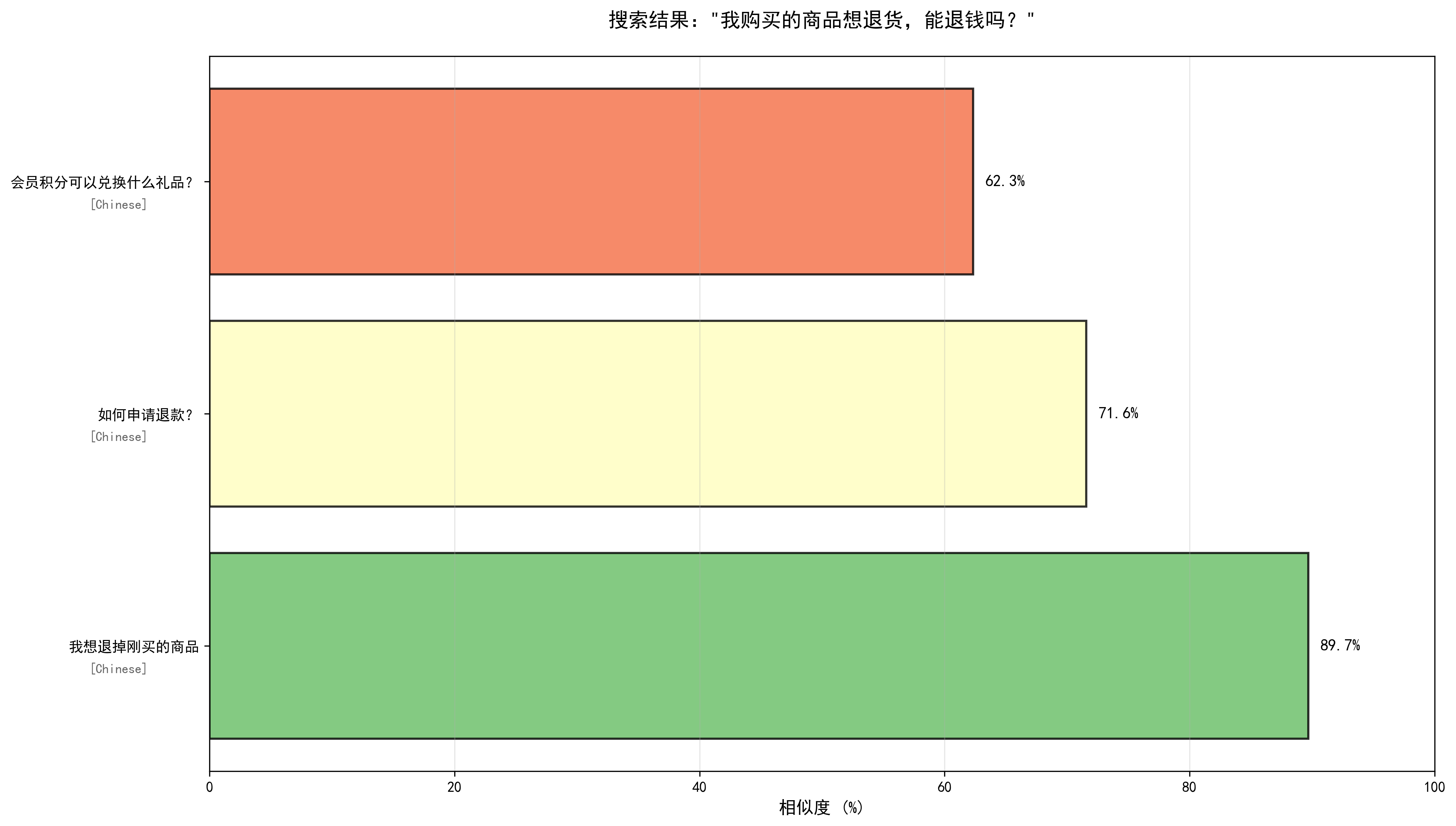
这个问题如果我们换成是多语言的paraphrase-multilingual-MiniLM-L12-v2模型,对比差异:
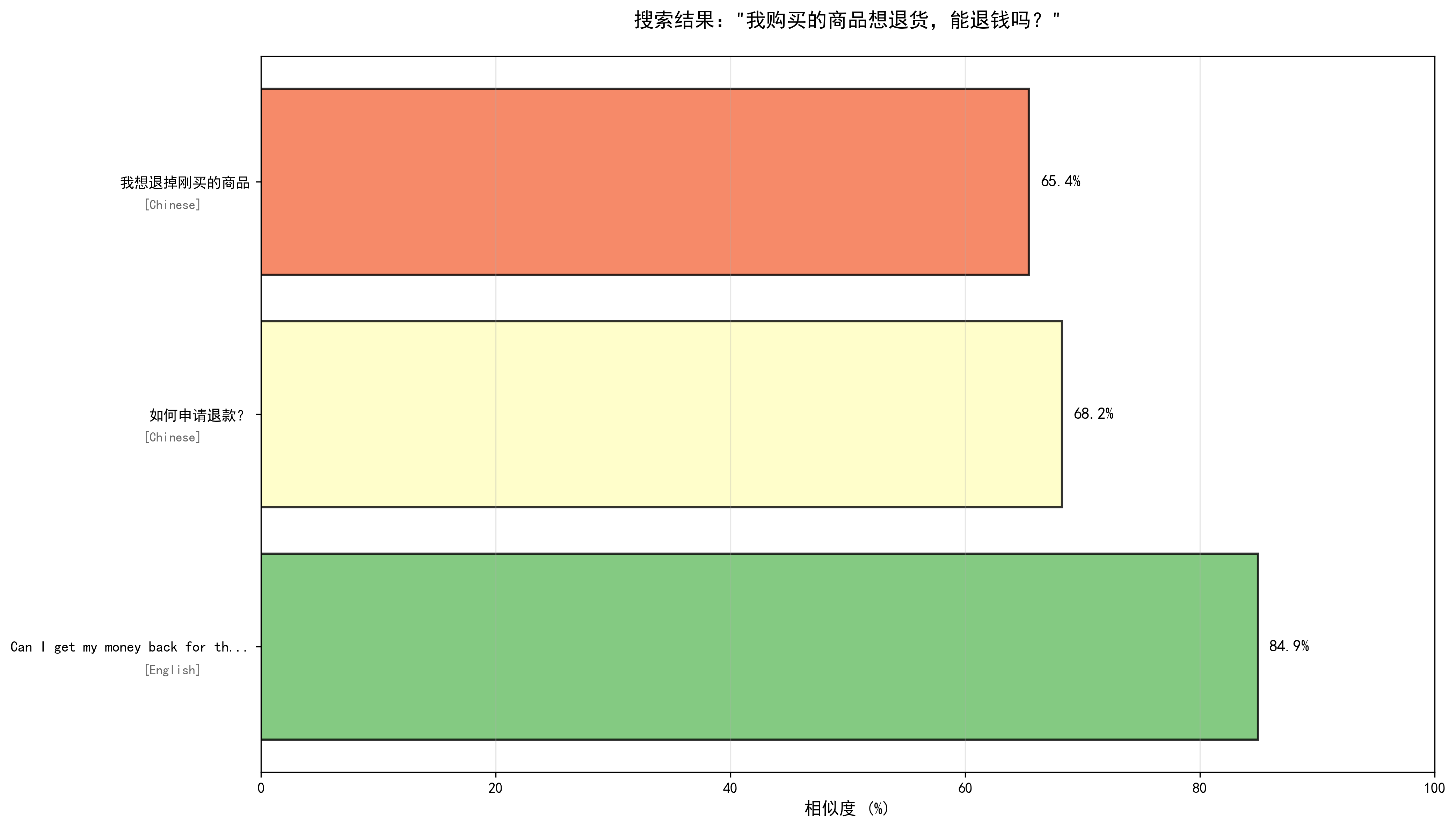
这两张图直观的说明了:
- all-MiniLM-L6-v2模型仅做了同类词汇匹配,对语义理解缺失;
- paraphrase-multilingual-MiniLM-L12-v2能更好的适配中英双语的语义理解;
--- 查询 5/6 --- === 用户问题:返金を申請するにはどうすればいいですか? === 查询响应时间:35.59ms 最相似的回答: 1. 相似度:0.8643 相似问题:配送料金はいくらですか? 回答:購入金額が10000円以上の場合は送料無料です。10000円未満の場合は一律500円の送料がかかります。 语言:Japanese 2. 相似度:0.4883 相似问题:物流信息多久更新一次? 回答:物流信息通常每4-6小时更新一次,如遇节假日可能会有延迟,请您耐心等待。 语言:Chinese 3. 相似度:0.4678 相似问题:如何申请退款? 回答:您可以在订单详情页点击退款按钮,选择退款原因并提交,我们会在1-3个工作日内处理您的退款申请。 语言:Chinese ✓ 搜索结果可视化已保存:search_result_5_5.png
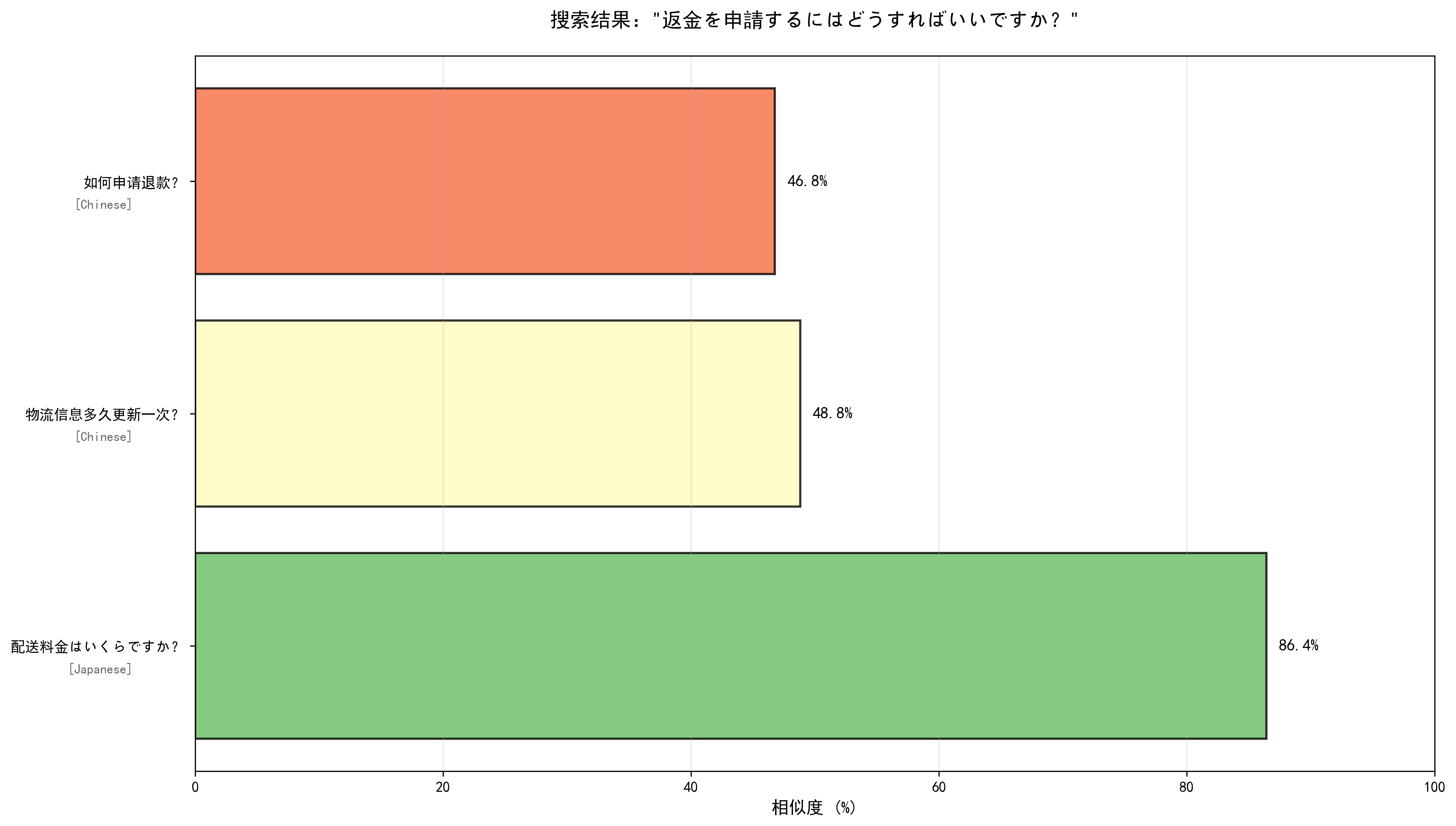
这个问题如果我们换成是多语言的paraphrase-multilingual-MiniLM-L12-v2模型,对比差异:
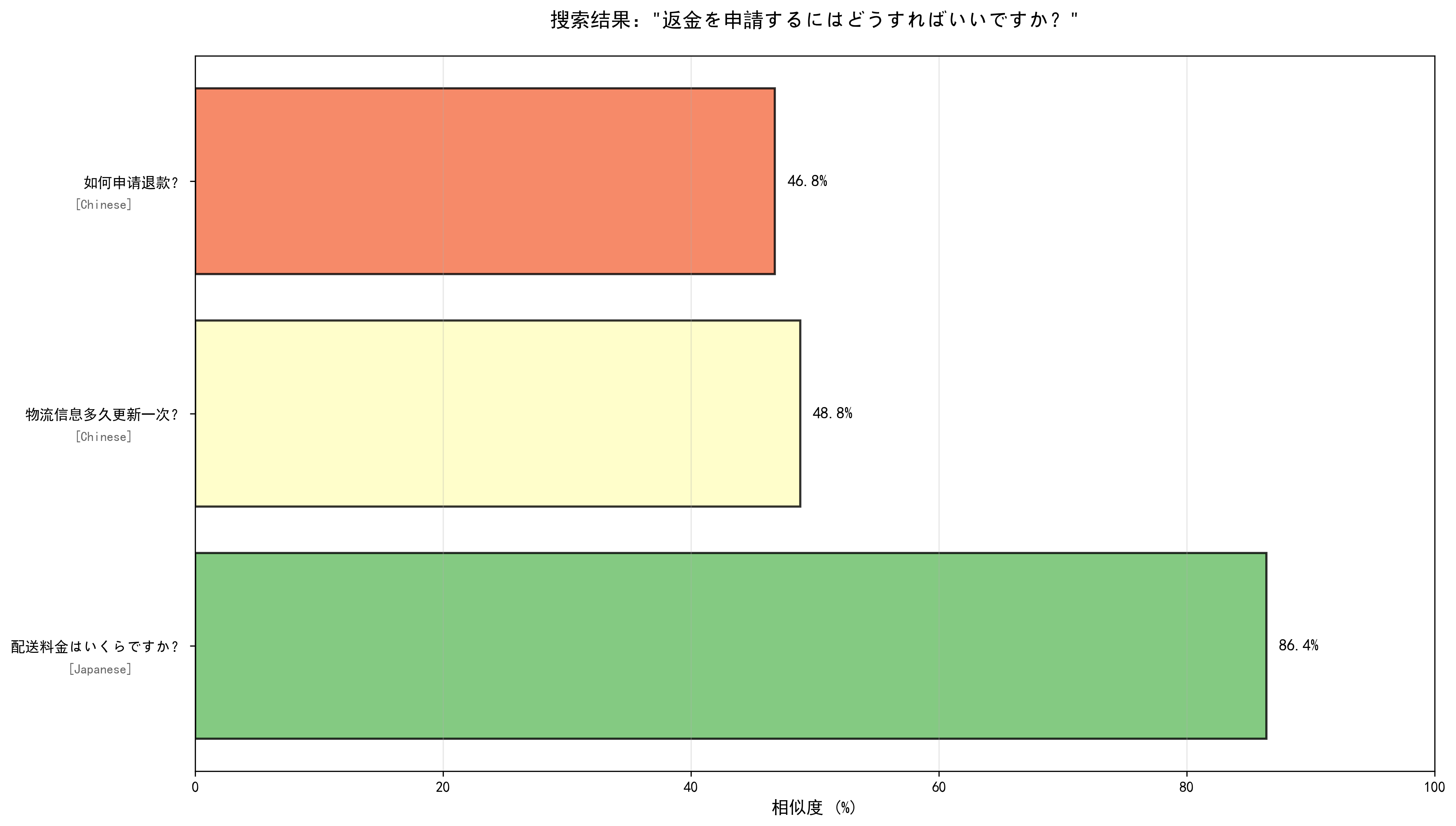
这两张图直观的说明了:
- all-MiniLM-L6-v2模型仅做了同类词汇匹配,对语义理解缺失;
- paraphrase-multilingual-MiniLM-L12-v2能更好的适配中日双语的语义理解;
--- 查询 6/6 --- === 用户问题:你们公司在哪里? === 查询响应时间:37.8ms 最相似的回答: 1. 相似度:0.5024 相似问题:物流信息多久更新一次? 回答:物流信息通常每4-6小时更新一次,如遇节假日可能会有延迟,请您耐心等待。 语言:Chinese 2. 相似度:0.4961 相似问题:会员积分可以兑换什么礼品? 回答:会员积分可兑换优惠券、实物礼品、免运费服务等,具体可在积分商城查看。 语言:Chinese 3. 相似度:0.4902 相似问题:如何申请退款? 回答:您可以在订单详情页点击退款按钮,选择退款原因并提交,我们会在1-3个工作日内处理您的退款申请。 语言:Chinese ✓ 搜索结果可视化已保存:search_result_6_6.png
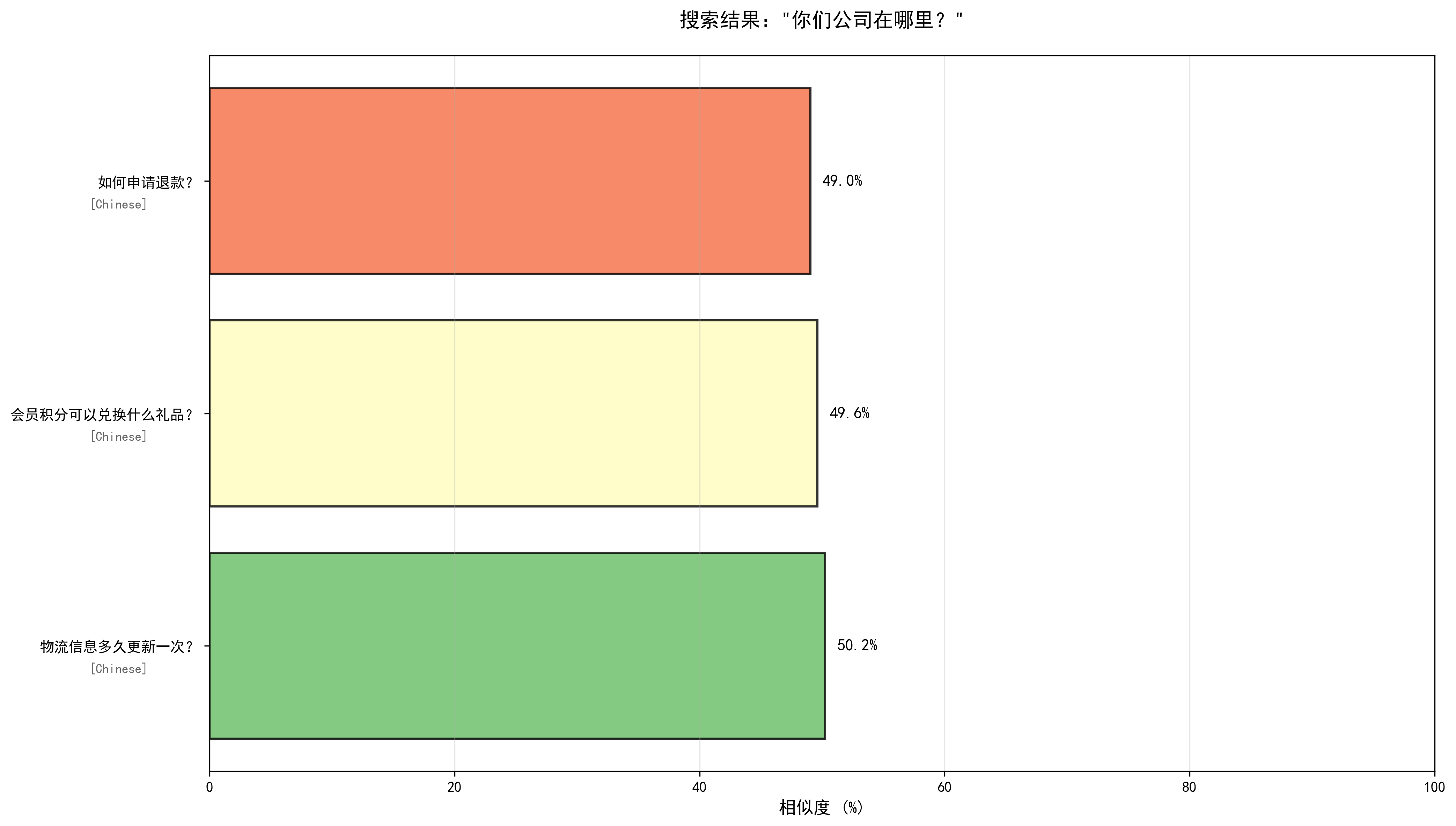
这个问题如果我们换成是多语言的paraphrase-multilingual-MiniLM-L12-v2模型,对比差异:
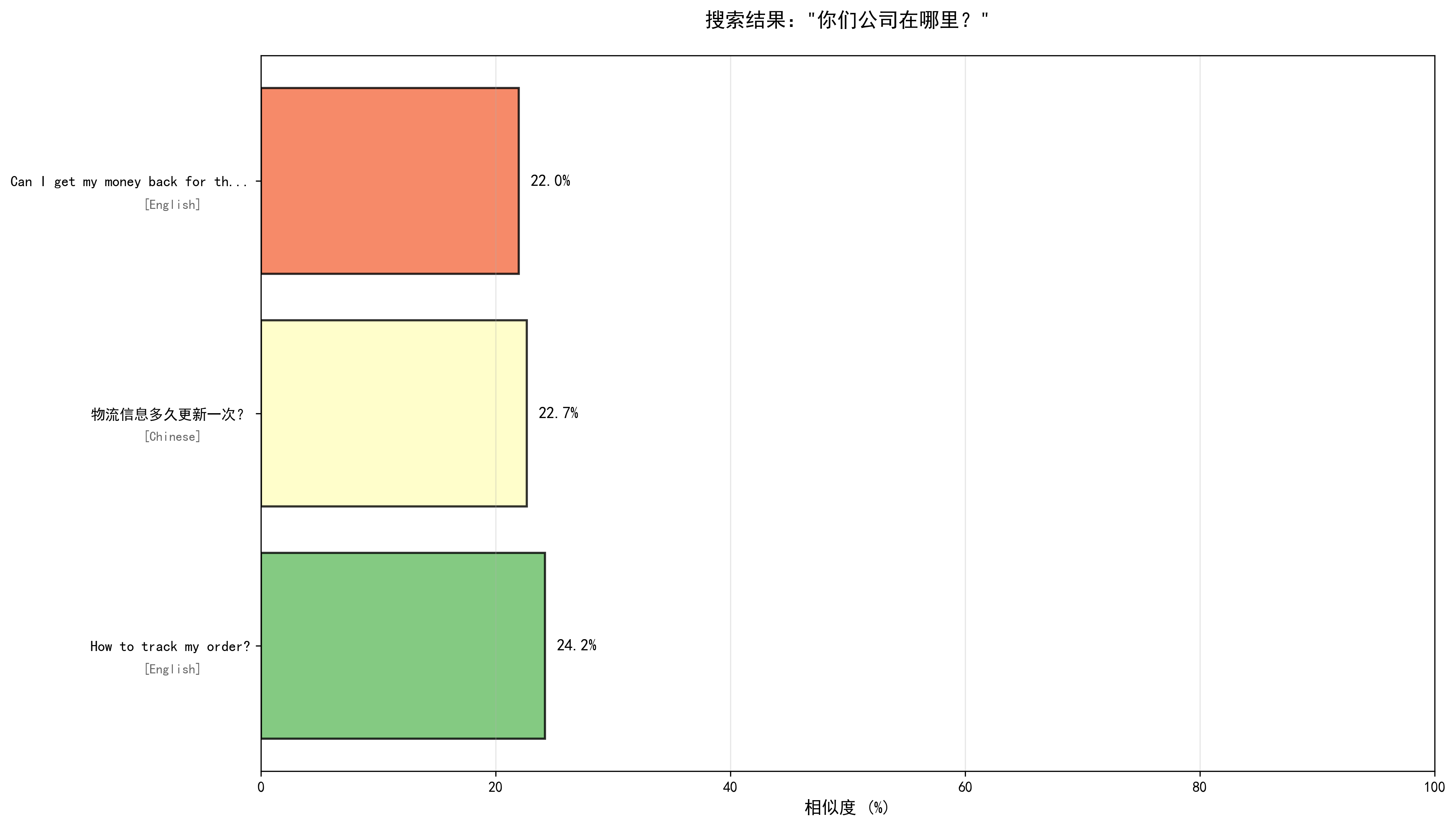
这两张图直观的说明了:
- all-MiniLM-L6-v2模型未匹配到答案,但概率依旧50%的比例;
- paraphrase-multilingual-MiniLM-L12-v2能更好降低结果的匹配度;
============================================================ 系统性能统计 ============================================================ 平均查询时间_ms:37.8 最快查询时间_ms:26.04 最慢查询时间_ms:54.76 总查询次数:6 知识库规模:8
生成可视化图表:
知识库嵌入向量分布PCA降维图:
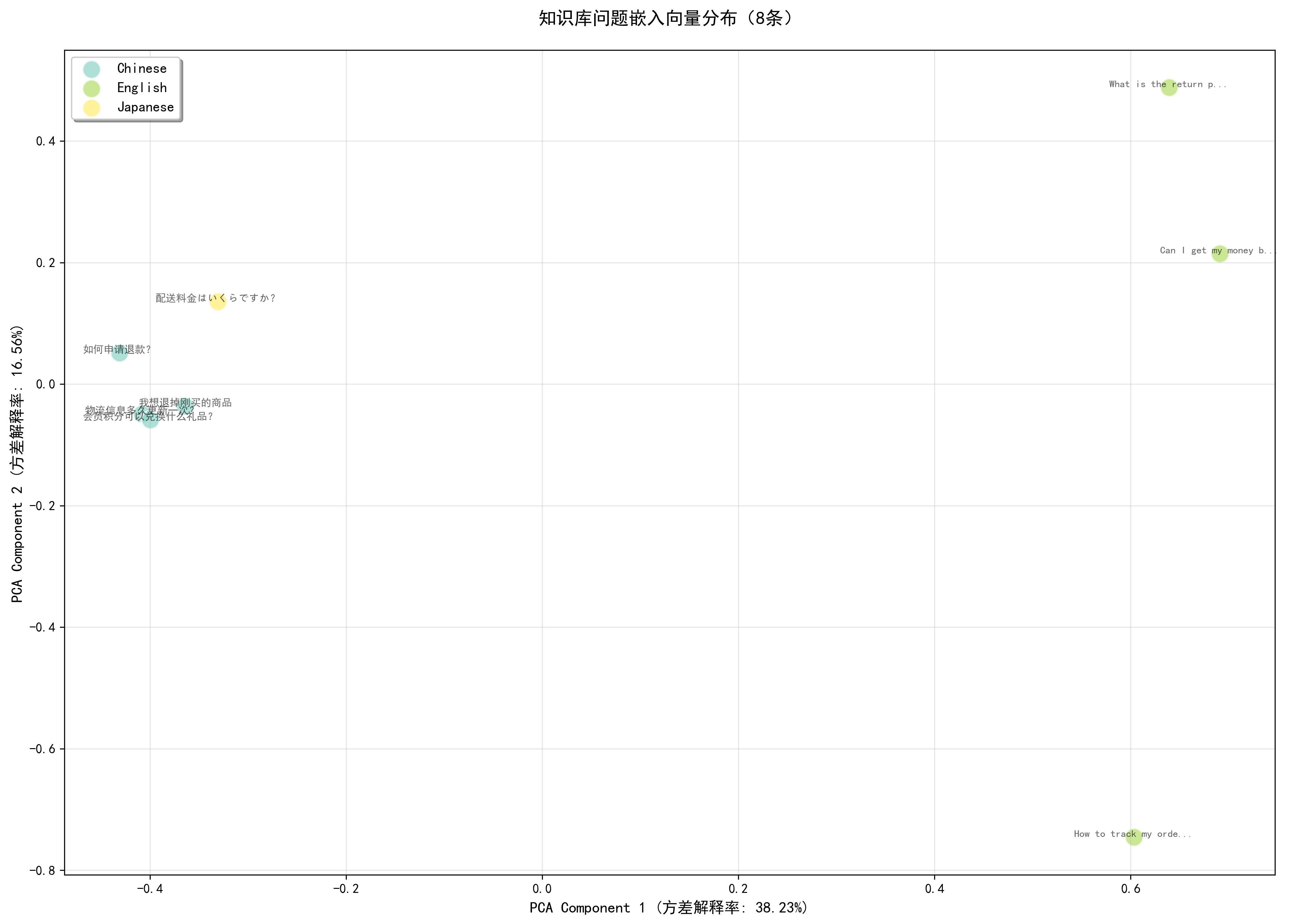
知识库嵌入向量分布t-SNE降维图:
知识库问题相似度热力图:
查询性能分析:
四、总结
MiniLM模型在智能客服场景中可作为核心的语义检索引擎,实现毫秒级的相似问题匹配,大幅提升客服响应效率。模型选择推荐在跨境多语言客服场景必须选择paraphrase-multilingual-MiniLM-L12-v2;纯英文客服场景优先选择all-MiniLM-L6-v2以获得更快的响应速度。在性能上通过批量处理、禁用梯度计算、预计算嵌入向量等手段,可将单条查询的响应时间控制在 20ms 以内,满足高并发客服系统的需求。
在后续的知识库维护要定期更新知识库并重新计算嵌入向量,保证回答的时效性,并持续统计查询响应时间和准确率,及时发现并解决问题。在知识库的内容储备不足时,可以采用混合架构模式,结合 "MiniLM 检索 + 大模型生成" 的方式,既保证速度又提升回答质量;系统部署方面我们可以将系统封装为 API 服务,供客服系统、APP、网页等多端调用。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号