房价预测入门:ArcGIS Pro 回归分析教程的七个问题

房价预测入门:ArcGIS Pro 回归分析教程的七个问题

renhai
发布于 2026-06-01 10:40:19
发布于 2026-06-01 10:40:19
教程链接:使用线性回归预测房价[1]
学这个教程的时候,有七个地方卡住了。每个卡点我都查了资料、写了解答,整理成这篇笔记。如果你也在学空间回归,这些问题大概率你也会遇到。
1. Q1:可视化软件 vs 纯代码,怎么选?
ArcGIS Pro 做可视化确实比写代码友好太多——散点图矩阵点几下就出来了,Python 里要写一堆 matplotlib 代码。
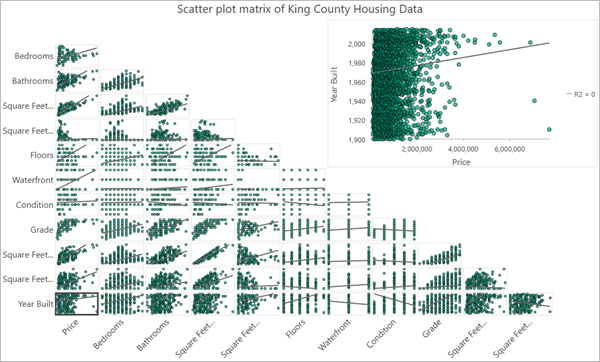
arcgispro中的散点矩阵图
实际建议:
- 数据清理 → 用代码(Python/pandas),灵活、可复现、能处理大数据
- 探索性分析 + 可视化 → 用 ArcGIS Pro,交互式操作,改参数实时看效果
- 最终报告 / 可复现的研究 → 代码更好,因为能存成脚本反复跑
两者不矛盾。很多 GIS 从业者的工作流是:代码清理数据 → 导入 ArcGIS Pro 做分析和出图。ArcGIS Pro 也能做数据清理(字段计算器、Python 脚本工具),但效率不如 pandas。
2. Q2:变量变换——为什么要求立方?
2.1 问题背景
教程里 grade(建筑质量 1-13 分)和 price(售价)的关系是凸形的:低分段(1-7 分)价格差别不大,高分段(10-13 分)价格差别急剧拉大。画出来是一条向上弯曲的曲线,不是直线。 转换变量后的变量与价格额度关系:
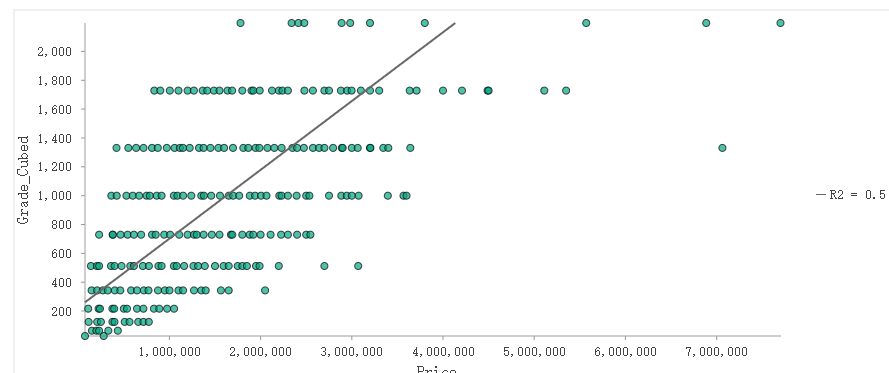
线性回归要求自变量和因变量之间是线性关系(直线)。如果是弯的,模型就拟合不好。
2.2 什么是「求立方」
就是把 grade 这个字段的每个值都乘以自身三次:
Grade_Cubed = grade × grade × grade
2.3 为什么是立方而不是平方?
手动判断确实靠经验,但有更系统的方法——Box-Cox 变换。
2.4 Box-Cox 变换:让数据告诉你该用什么幂次
Box-Cox 的核心思想:遍历一系列幂次 λ,看哪个让数据最接近正态分布。
公式:
Y' = (Y^λ - 1) / λ (λ ≠ 0 时)
Y' = ln(Y) (λ = 0 时,即对数变换)
常见的 λ 值对应关系:
λ 值 | 变换 | 适用场景 |
|---|---|---|
λ = 2 | 平方 (Y²) | 左偏分布(大部分值大,少数值小) |
λ = 1 | 无变换 (Y) | 已经是正态分布 |
λ = 0.5 | 平方根 (√Y) | 计数数据,方差与均值成比例 |
λ = 0 | 对数 (ln Y) | 右偏分布(大部分值小,少数值大) |
λ = -1 | 倒数 (1/Y) | 强右偏 |
λ = -0.5 | 负平方根 (1/√Y) | 强右偏 |
λ 怎么选? 不用猜,让最大似然估计(MLE)自动算。工具会画一条似然函数曲线,峰值对应的 λ 就是最优解。
2.5 在 ArcGIS Pro 里怎么操作
工具:Transform Field(数据管理工具箱)
操作步骤:
- 打开 ArcGIS Pro → 分析 → 工具箱 → 数据管理工具 → 字段 → Transform Field
- 输入要素:你的图层
- 输入字段:选要变换的字段(如 grade)
- 变换方法:选 BOX-COX
- 幂参数(Power):留空,让工具自动用 MLE 找最优 λ
- 运行 → 工具会输出最优 λ 值、变换后的直方图、以及变换前后的统计对比
如果你知道要什么 λ,也可以手动指定。比如你已经知道要用立方,就填 Power = 3。
Python 等效操作:
import arcpy
arcpy.management.TransformField(
in_table="YourLayer",
field="grade",
transform_method="BOX-COX"
# 不指定 power → 自动找最优 λ
)
2.6 这个教程为什么直接用立方?
因为 Esri 做教程时已经验证过 grade³ 效果好。实际项目中,你应该:
- 先跑 Transform Field,让工具自动算最优 λ
- 看输出的 λ 值接近哪个「整数」(0、0.5、1、2、3)
- 用最近的整数变换,因为好解释(「我用了立方变换」比「我用了 λ=2.7 的变换」容易理解)
参考:ArcGIS Pro - Transform Field[3] | Stattrek - Transformations in Regression[4]
2.7 变换前的自变量和因变量,能不能说它们有「三次方关系」?
不完全准确,但方向对。
更精确的说法是:grade 和价格之间存在非线性关系,而立方变换刚好能把这种非线性变成线性。
区别在于:
- 「三次方关系」暗示 Y = X³ 的精确数学关系——但实际上 grade 和价格不是严格三次方关系,只是近似符合加速上升的形态
- 你可以说「grade 和价格之间存在单调递增的非线性关系,立方变换能有效线性化」——这是统计学上的标准表述
类比理解:
- 就像你看到一个弯的东西,用「立方变换」把它掰直了
- 你不能说原来的东西一定是某种精确的曲线,但你知道掰直之后能用直线去拟合
判断标准: 变换后 R² 提升了 → 说明变换有效 → 不需要纠结原来的关系到底「叫什么」。
3. Q3:残差地图 vs Python 统计输出
你说得对——残差放在地图上看,比看 Python 输出的统计数字直观太多了。
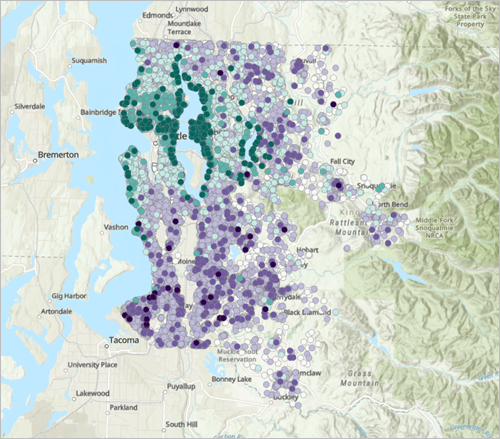
Python 输出的残差统计(均值、标准差、VIF)是全局数字,告诉你「平均猜错多少」。但它不会告诉你哪些地方猜错了。
ArcGIS Pro 的残差地图会用颜色标出:
- 深绿色 = 模型低估了(实际价格比预测高)
- 深红色 = 模型高估了(实际价格比预测低)
你一眼就能看到:「哦,水边全是绿色,模型系统性低估了湖边房子。」这种空间模式在数字统计里是看不出来的。
这就是空间分析的核心价值:同样的数据,加了地理位置维度之后,能看到纯统计看不到的规律。
4. Q4:ArcGIS Pro 图表类型速查(含示例图)
教程里用的是散点图矩阵,但 ArcGIS Pro 的图表功能远不止这些。按用途分类:
4.1 比较类别和数量
图表 | 用途 | 文档链接 |
|---|---|---|
条形图 | 比较不同类别的数量(如各区成交量) | Bar chart[5] |
组合图表 | 条形图 + 折线图混合,双 Y 轴 | Combo chart[6] |
饼图 | 看占比(如各房型成交比例) | Pie chart[7] |
矩阵热点图 | 类别变量之间的关系热力图 | Matrix heat chart[8] |
4.2 探索关系和相关性
图表 | 用途 | 文档链接 |
|---|---|---|
散点图 | 两个数值变量的关系(如面积 vs 价格) | Scatter plot[9] |
散点图矩阵 | 多个数值变量两两对比,本教程重点 | Scatter plot matrix[10] |
QQ 图 | 检验变量是否符合正态分布 | QQ plot[11] |
4.3 可视化分布和频数
图表 | 用途 | 文档链接 |
|---|---|---|
直方图 | 看一个变量的分布形态(偏态、正态?) | Histogram[12] |
箱形图 | 看分布的四分位数、异常值(教程三用这个比较模型) | Box plot[13] |
4.4 显示时间或距离的变化
图表 | 用途 | 文档链接 |
|---|---|---|
折线图 | 随时间/距离的变化趋势 | Line chart[14] |
数据时钟 | 季节性/周期性模式 | Data clock[15] |
日历热点图 | 年/周的时间模式 | Calendar heat chart[16] |
剖面图 | 高程变化或沿 3D 线的测量 | Profile chart[17] |
实操建议:做探索性分析时,先用散点图矩阵看全局关系,再用直方图看单个变量分布,最后用箱形图对比不同模型/分组的结果。
每个链接点进去都有 ArcGIS Pro 官方示例图,比文字描述直观。
5. Q5:多重共线性到底是什么问题?
5.1 一句话解释
两个自变量太像了,模型分不清谁的功劳。
5.2 具体例子
教程里的 sqft_living(居住面积)和 sqft_above(地上面积)相关性 R² = 0.77——几乎是一个变量。
模型要做的是:给每个自变量分配一个系数,表示「这个变量每增加 1 单位,价格变化多少」。
但如果两个变量几乎一样,模型就懵了:
- 「价格涨了,是因为 sqft_living 增加了,还是 sqft_above 增加了?」
- 答案是:说不清。因为两个变量一起变,模型没法把功劳拆开。
5.3 后果
- 系数变得不稳定——数据稍微变一点,系数就大幅跳动,甚至符号翻转
- 标准误差膨胀——本来显著的变量变得不显著
- 但!预测能力不受影响——R² 还是那么高,预测还是准的
5.4 怎么判断
用 VIF(方差膨胀因子):
- VIF < 5 → 没问题
- VIF 5-10 → 有隐患
- VIF > 10 → 严重多重共线性
5.5 怎么解决
- 最简单:删掉一个(教程就是这么做的,留 sqft_living,删 sqft_above)
- 合并成一个变量(取平均或做主成分分析)
- 用正则化方法(Ridge / Lasso 回归),专门处理共线性
关键点:多重共线性影响的是解释能力(你没法说清哪个变量更重要),不影响预测能力(模型照样能预测准)。如果你只关心预测不关心解释,可以不管它。 参考:IBM - What Is Multicollinearity?[18]
6. Q6:GLR 的三种模型类型分别用于什么?
广义线性回归(GLR)不只是做线性回归,它有三种模式,对应三种不同的因变量类型:
6.1 Continuous(连续)—— 高斯模型
- 因变量是什么: 连续数值,范围很广
- 例子: 房价、温度、销售额、GDP
- 要求: 因变量最好接近正态分布
- 本教程用的就是这个
6.2 Binary(二进制)—— 逻辑回归
- 因变量是什么: 只有两个值(0 或 1),是/否,发生/不发生
- 例子:
- 房子是否卖出了高于 50 万?(1=是,0=否)
- 某地是否发生滑坡?(1=发生,0=未发生)
- 犯罪是否被逮捕?(1=逮捕,0=未逮捕)
- 用途: 预测概率、做分类
6.3 Count(计数)—— 泊松模型
- 因变量是什么: 离散的计数数据(0, 1, 2, 3…),不能是负数或小数
- 例子:
- 某区域的犯罪数量
- 某路口的交通事故次数
- 每月的 911 报警次数
- 每万人的癌症发病数
- 要求: 均值和方差大致相等(如果不等,需要用负二项回归)
参考:ArcGIS Pro - How Generalized Linear Regression Works[19]
7. Q7:添加空间变量后,属于空间回归吗?
不算。 加了「距西雅图距离」作为解释变量,本质上还是 GLR(全局线性回归),只是多了一个自变量。
真正的空间回归是 GWR(地理加权回归)——它不只是加了空间变量,而是让每个位置的系数都不同。
区别:
- GLR + 空间变量: 一个全局方程,但包含距离信息 → 「距市中心越近越贵,这个规律全县统一」
- GWR: 每个点有自己的方程 → 「在西雅图市区,距市中心影响大;在郊区,距市中心影响小」
教程二[20]才会讲 GWR。教程一只是在 GLR 框架里加了空间变量做铺垫。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号