Claude Opus 4.8 vs GPT-5.5,到底该用谁?

Claude Opus 4.8 vs GPT-5.5,到底该用谁?

程序视点
发布于 2026-06-01 15:59:25
发布于 2026-06-01 15:59:25
大家好!欢迎来到程序视点,我是你们的老朋友.安戈👋
前言
最近刷AI相关的新闻,满屏都是 laude Opus 4.8。我第一反应不是「又出新模型了」,而是:4.7 才出来多久啊?

文章配图-1
Anthropic 以前发版,Sonnet、Haiku 动不动隔好几个月。这次这么急,说明 4.7 的口碑,Anthropic他们自己也收到了。
不少开发者吐槽过:Opus 4.7注释写得比代码还长、工具调用不稳、复杂任务里爱自作主张。OpenAI、Google 那边又在编程 Agent 上猛推,Anthropic 没法慢慢磨。
因此,Claude Opus 4.8 的定位很直白——不是换架构的大改,是把该补的短板补上。
需要Claude优惠激活的读者朋友,可以关注微信公众号【程序视点】,回复claude,了解最新Claude Max 5x/20x优惠激活!
目前最新的Cursor版本也已经支持使用Opus 4.8模型了。需要Cursor的读者朋友,也可以联系我们获取优惠!
Claude Opus 4.8跑分涨了,但别只盯着榜单
官方数据我帮你们捋了一遍!
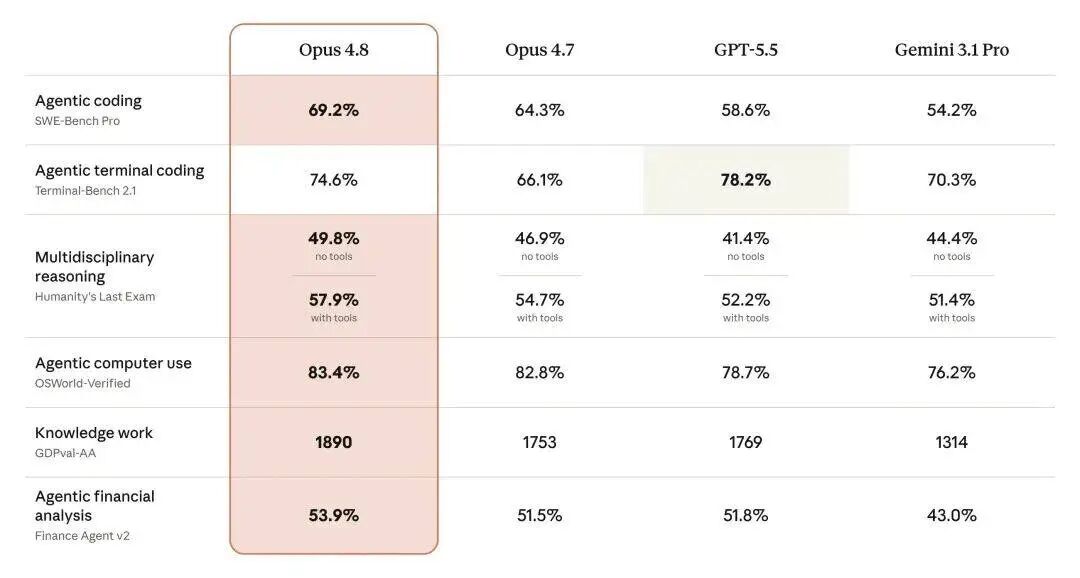
文章配图-1
SWE-Bench Pro 编程 69.2%,比 4.7 高近 5 个点,也压过 GPT-5.5 和 Gemini 3.1 Pro。Computer Use、知识工作、金融分析几项,基本都在前面。
唯一丢分项是 Terminal-Bench 终端编程,GPT-5.5 78.2%,Opus 4.8 大概 74%。Anthropic 没藏着,发布材料里写得很清楚——这点我倒是挺服。
但说实话,跑分看看就行。真正让我感兴趣的,是下面两件事。
第一:它终于愿意说「我不确定」
大模型老毛病你们都懂:证据不够也敢拍胸脯,代码有坑也当没看见。
Claude Opus 4.8 在这块下了功夫。官方说,代码缺陷悄悄溜过去的概率,降到 4.7 的四分之一。
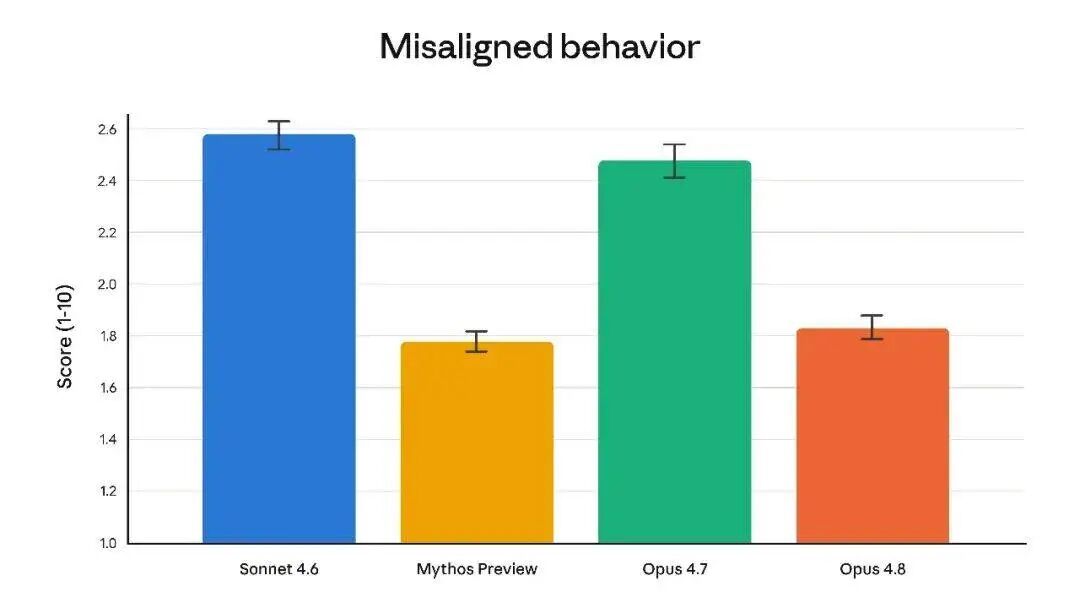
文章配图-1
Devin 的 CEO 用过之后说,工具调用干净多了,注释啰嗦的毛病也好了。投资圈有人反馈,它会主动提醒你输入输出哪里有问题。
对齐测试里,「不当行为」分数从 2.48 降到 1.83,接近内部 Mythos 预览版。模型变强还能变「乖」,比多考几分难多了。进生产环境,这种能力比炫技实在。
第二:Dynamic Workflows,真·Token 绞肉机
这次最狠的功能叫 Dynamic Workflows(动态工作流)。Claude Code 里一次会话能并行调度几百个子 Agent——规划、分工、执行、自检、汇总,一条龙。
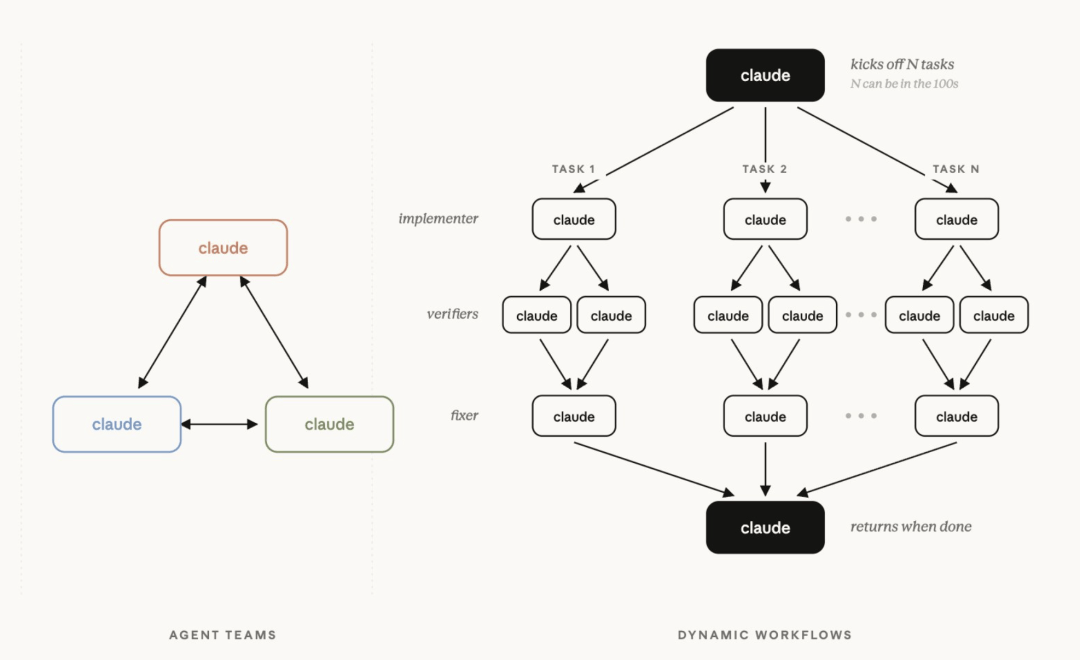
文章配图-1
以前几十万行代码的库迁移,你得拆成无数小任务反复喂;现在理论上可以一口气扔给它。官方拿 Bun 从 Zig 迁 Rust 举例:75 万行代码、测试通过率 99.8%、11 天搞定。
听着很爽,但心里要有数:能力越强,账单越厚。Enterprise、Team、Max 用户先用。
另外加了思考强度调节:默认高档,难题可以拉到 extra 或 max;想省 token 就调低。Messages API 也更新了,Agent 跑到一半能改 system 指令,还不打断 prompt cache——做复杂 Agent 的兄弟会喜欢。
价格没变,单位成本反而降
常规价还是输入 5/百万token,输出 25/百万token。Fast 模式比上一代便宜约 3 倍。Databricks 那边有人测过,agentic 任务上单 token 成本比 4.7 低 61%。
能力涨了,标价不动,跑起来还更省——Anthropic 这次打的是效率牌,不是「我又是最强」。
选型指南:Opus 4.8 vs GPT-5.5,该用谁?
Anthropic 这次似乎没有把重点放在冲击排行榜,而是强调 Token 效率 和 真实工作流。
当 Opus 4.8 与 GPT-5.5 能力已非常接近、「谁更聪明」难以简单区分时,真正的问题变成:你准备用它来做什么。
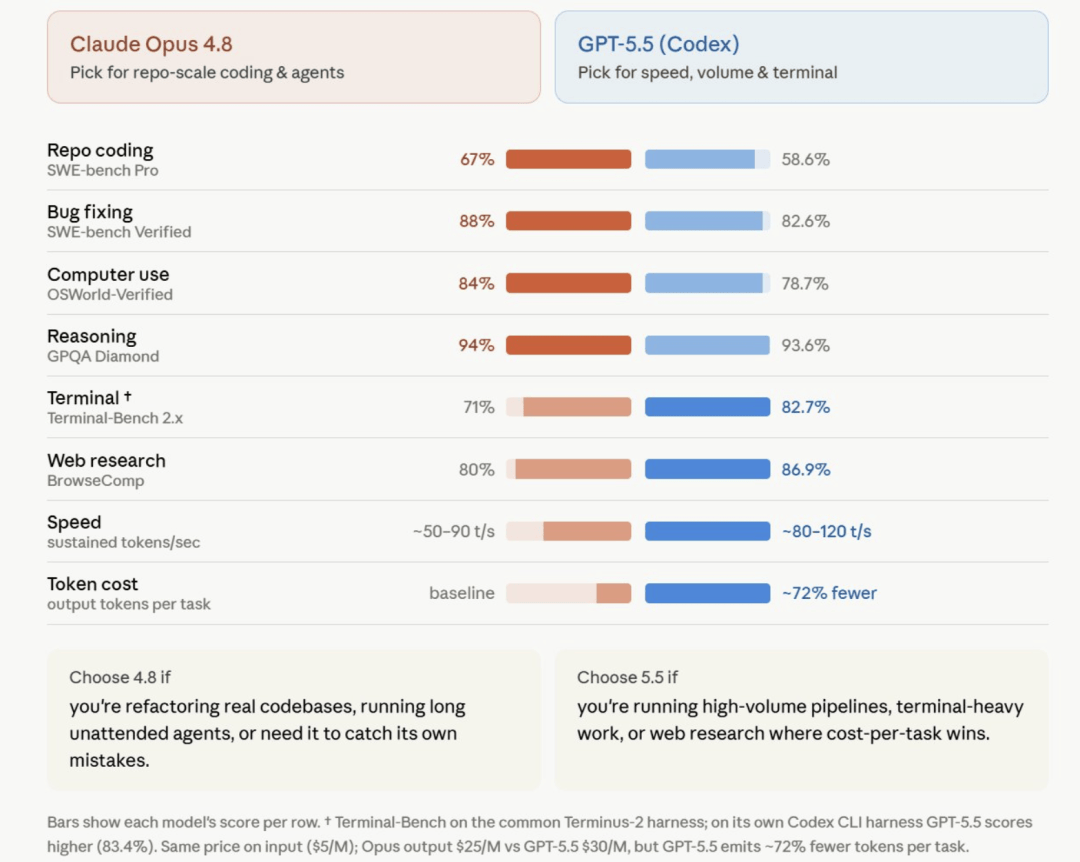
文章配图-1
更适合 Claude Opus 4.8 | 更适合 GPT-5.5 / Codex |
|---|---|
大型代码仓库开发与维护 | 大量依赖终端(Terminal)的工作流 |
长时间无人值守的 Agent 任务 | Web 搜索与信息研究 |
需要模型主动发现并纠正自身错误 | 高吞吐量、批量化任务 |
Computer Use 类任务 | 对响应速度要求较高的场景 |
纯推理能力和首 Token 延迟(TTFT),两者基本同一水平,很难拉开明显差距。
总结下来:
- Opus 4.8 更合适: 大仓库维护、长时间无人值守的 Agent、Computer Use、需要模型自己发现错误并纠正的场景。
- GPT-5.5 更合适: 终端操作多的工作流、Web 搜索研究、高吞吐批量任务、对响应速度要求高的情况。
写在最后
根据Anthropic官方态度的猜测,Mythos 估计几周后也要来了,有人猜 Claude Opus 4.8 可能是 Mythos 正式登场前最后一个 Opus。
大模型竞争,正在从「谁分数高」变成「谁能在真实项目里少闯祸、多干活」。毕竟,干事才是硬道理!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号