AI 为什么宁可瞎编,也死活不说“不知道”?


事情是这样的。
一个朋友做了个企业内部知识库问答机器人。
第一轮测试还挺好。
用户问:
★报销发票抬头怎么填?
机器人从制度文档里找到了答案,回答得有条有理。
第二轮,用户又问:
★那如果我是跨部门项目呢?
它也能接上,大概说要走项目负责人审批。
第三轮,用户问:
★那这个要不要补附件?
这时候问题来了。
知识库里其实没有“跨部门项目报销附件”的明确规定。
但机器人没有说“不知道”。
它开始一本正经地编:
★需要补充项目立项书、部门负责人签字页、预算占用说明,缺一不可。
朋友一看就懵了。
因为公司根本没有这个流程。
更要命的是,这句话听起来太像真的了。语气稳定,格式规范,还带着一点制度文件的味道。
这就是今天的问题:
为什么 AI 明明不知道,还非要装作知道?
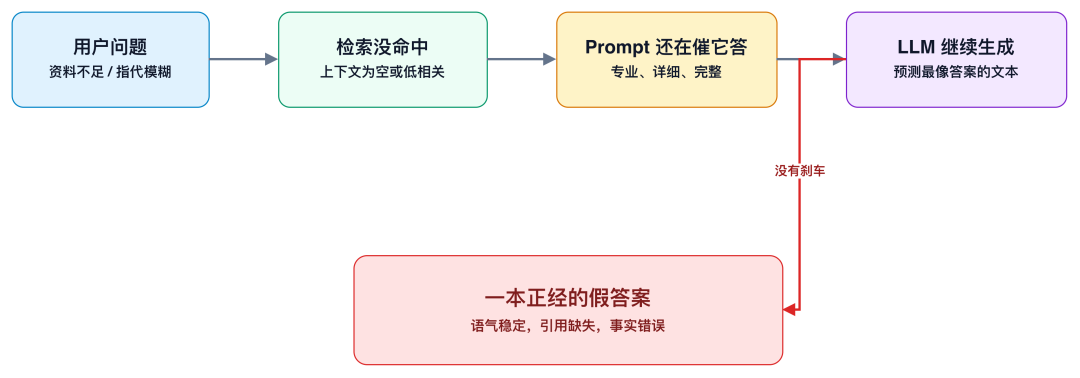
★图 1:AI 很多时候不是“知道答案”,而是在没有证据时继续生成一个“像答案”的文本。
先说结论:它不是嘴硬,它根本不是按“知道不知道”工作的
很多人把 AI 想成一个人。
人回答问题时,大脑里大概有三种状态:
- 我知道
- 我不确定
- 我不知道
但大模型不是这么工作的。
它的底层目标更像是:
★在当前上下文里,预测下一个最可能出现的词。
这件事听起来很无辜。
但放到问答系统里,就很危险。
因为“下一个最合理的词”,不等于“事实正确的词”。
也就是说,模型并不是先查一遍自己的脑子:
★这件事我有没有可靠证据?
然后再决定回答。
它更像是在当前 prompt、上下文、训练经验和解码参数的共同作用下,生成一段“看起来最像答案”的文本。
AI 的默认动作不是求真,而是续写。
如果系统没有额外设计“拒答机制”,它就很容易把“不知道”续写成“像知道”。
第一层,训练目标就没有教它老实闭嘴
大模型在预训练阶段学的是语言规律。
它看过大量网页、书籍、问答、代码、论坛、说明书。
训练时常见目标大概是这样:
输入:报销发票抬头应该填写
目标:预测后面的 token
模型学到的是:
报销发票抬头应该填写公司全称,并确保与税务登记信息一致。
这在很多场景下有用。
问题是,它学到的是语言分布,不是企业制度数据库。
它知道“这种问题通常应该怎么回答”,但它不知道“你们公司到底怎么规定”。
所以,当用户问一个没有证据支撑的问题时,模型仍然有能力生成一个流畅答案。
这就像一个候选人面试时没做过某个项目,但他听过很多八股文,于是现场组织了一套听起来很像项目经验的话。
能说,不代表做过。
能生成,不代表知道。
第二层,很多系统 prompt 正在鼓励它“别冷场”
更现实的问题在工程层。
很多人接大模型时,prompt 是这么写的:
你是一个专业、耐心、友好的企业助手。
请详细回答用户问题。
回答要清晰、完整、有条理。
听起来没问题对吧?
但线上系统最怕的就是这种“只要求有帮助,不要求有证据”。
因为模型会把“专业、详细、完整”理解成一种输出风格。
它会倾向于:
- 不要显得无能
- 不要回答太短
- 不要让用户失望
- 尽量补全缺失信息
于是,当资料不足时,它不是停下来,而是补上去。
更糟糕的 prompt 是这种:
如果没有找到相关资料,请结合你的通用知识回答。
这句话基本等于给幻觉开绿灯。
在企业知识库、法务、财务、医疗、客服这种场景里,“结合通用知识”往往不是兜底,而是事故入口。
正确的方向应该是把拒答写成一等公民:
你只能基于 <context> 中的资料回答。
如果资料不足以支持结论,必须回答:
“根据当前资料无法确认。”
不要编造制度、流程、编号、时间、金额、负责人、审批规则。
注意这里的差别。
不是礼貌地建议它“不确定可以说不知道”。
而是明确告诉它:
没有证据时,拒答就是正确答案。
第三层,RAG 系统经常“没搜到也照样生成”
很多幻觉不是模型单独犯的错,而是 RAG 链路设计错了。
一个很常见的坏实现长这样:
def answer(question):
docs = vector_db.search(question, top_k=5)
prompt = build_prompt(question, docs)
return llm.generate(prompt)
这段代码看起来没什么。
问题在于,它永远会调用 llm.generate()。
不管搜出来的是不是相关文档。
不管相似度分数有多低。
不管文档里有没有答案。
结果就是:
检索没命中
↓
上下文很空或很脏
↓
模型仍然被要求回答
↓
它开始根据语言经验补全
一个稍微靠谱点的实现,至少要有阈值判断:
def answer(question):
docs = vector_db.search(question, top_k=5)
useful_docs = [
doc for doc in docs
if doc.score >= 0.78
]
if not useful_docs:
return {
"answer": "根据当前资料无法确认。",
"status": "insufficient_context",
"citations": []
}
prompt = build_grounded_prompt(question, useful_docs)
return llm.generate(prompt)
这段代码解决的不是“让模型更聪明”。
它解决的是一个更基础的问题:
没有证据时,不要把模型推上台表演。
RAG 里最常见的幻觉链路,不是模型突然疯了。
而是系统拿着一堆低相关资料,甚至空资料,对模型说:
★来,你专业一点,详细回答。
那它当然会编。
第四层,模型没有天然的“置信度仪表盘”
很多人会问:
★它自己难道不知道自己不确定吗?
这话只对一半。
模型在生成时确实有概率分布。
比如下一个 token,可能有这些候选:
需要:0.41
建议:0.22
可以:0.17
不需要:0.08
无法确认:0.03
但这个概率不是事实置信度。
它只表示在当前上下文里,哪个词更像下一个词。
“需要”概率高,不代表现实中真的需要。
这就是很多系统误判的地方。
你让模型输出:
{
"answer": "...",
"confidence": 0.92
}
看起来很高级。
但如果这个 confidence 也是模型自己生成的,它很可能只是另一段文本。
不是监控指标。
不是统计校准。
不是事实保证。
真正可用的置信判断,应该来自系统侧证据,比如:
指标 | 看什么 | 意义 |
|---|---|---|
检索最高分 | top1 文档相似度 | 问题有没有搜到像样资料 |
引用覆盖率 | 回答中的关键结论是否能映射到文档 | 是否基于证据回答 |
多文档一致性 | 不同资料是否互相冲突 | 是否存在制度版本冲突 |
拒答率 | 资料不足时是否拒答 | 模型有没有被迫硬答 |
人工抽检幻觉率 | 结论是否编造 | 真实质量指标 |
模型说“我很确定”,没那么值钱。
系统能证明“这句话来自哪份资料”,才值钱。
第五层,产品体验也在逼它撒谎
还有一个很现实的问题。
很多产品经理不喜欢“不知道”。
客服机器人说“不知道”,用户觉得没用。
销售助手说“不知道”,业务觉得不智能。
知识库助手说“不知道”,老板觉得模型买亏了。
于是系统就会被调成:
尽量回答
尽量详细
尽量给建议
尽量不要拒绝用户
这在演示里很好看。
但线上迟早出事。
因为企业系统里,错误答案的成本经常比没有答案高得多。
比如:
- 财务制度答错,可能导致报销违规
- 法务条款答错,可能导致合同风险
- 运维操作答错,可能导致线上故障
- 医疗建议答错,后果更不用说
所以工程上必须接受一个反直觉的事实:
一个会说“不知道”的 AI,才是更成熟的 AI。
不是每个问题都回答,才叫智能。
知道什么时候该闭嘴,也叫能力。
真正的解法,不是骂模型,而是给它装刹车
如果只在 prompt 里写一句“不要胡说”,作用有限。
因为幻觉是系统性问题。
要解决它,至少要做一套组合拳。
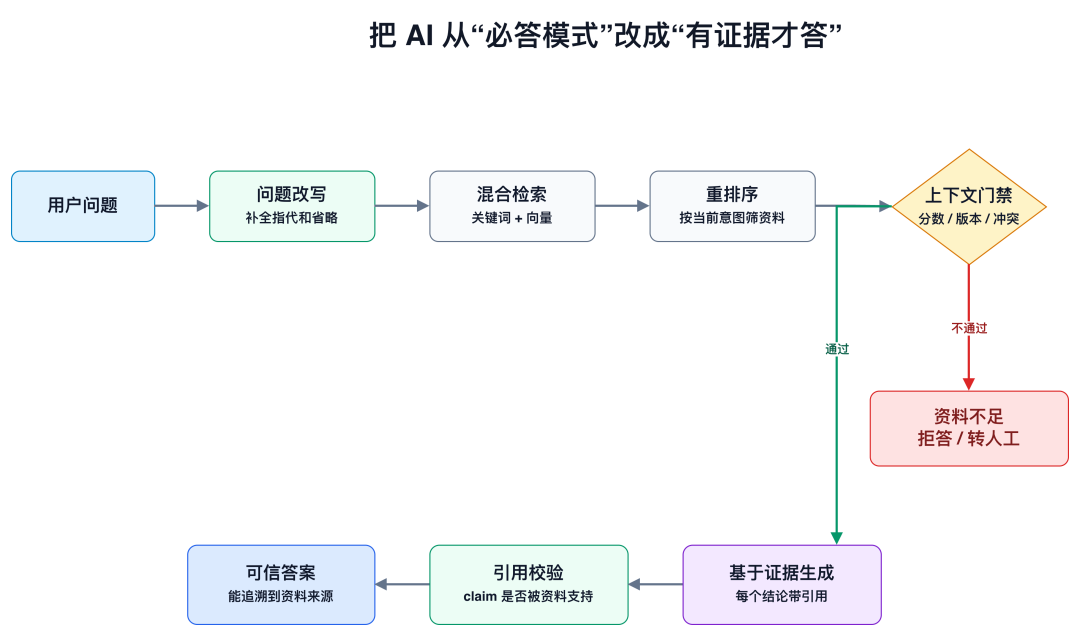
★图 2:工程上要把系统从“必答模式”改成“有证据才答”,否则 prompt 写得再凶也容易漏。
1. 把问题先改写成可检索问题
多轮对话里,用户经常这么问:
那这个要不要补附件?
“这个”是谁?
是普通报销?
是跨部门项目?
是差旅?
是外包采购?
如果直接拿这句话去检索,向量库很可能搜歪。
更好的做法是先做 query rewrite:
用户当前问题:
那这个要不要补附件?
对话历史:
用户询问跨部门项目报销流程。
改写后的检索问题:
跨部门项目报销是否需要补充附件,附件材料包括哪些?
但 query rewrite 也有副作用。
它可能改错用户意图。
所以改写结果要能被记录、调试、回放,不能变成黑盒。
2. 检索结果必须过门禁
不要搜到什么就塞给模型。
要判断:
- 分数够不够
- 文档是否过期
- 来源是否可信
- 内容是否和当前问题同域
- 多份资料是否冲突
可以加一个简单的门禁层:
def validate_context(docs):
if not docs:
return False, "empty_context"
if docs[0].score < 0.78:
return False, "low_retrieval_score"
if has_conflict(docs):
return False, "conflicting_documents"
return True, "ok"
这层逻辑很朴素。
但它能挡住大量“没资料还硬答”的事故。
3. Prompt 里要标清资料边界
不要把资料一股脑塞进去。
要告诉模型每段资料的来源、时间、版本、可信等级。
<context>
[doc_1]
来源:财务制度 v2026.03
更新时间:2026-03-12
可信等级:高
内容:跨部门项目报销需关联项目编号...
[doc_2]
来源:旧版报销 FAQ v2024.11
更新时间:2024-11-02
可信等级:低
内容:部分项目报销可补充审批截图...
</context>
要求:
1. 只基于可信等级高且未过期的资料回答。
2. 如果资料之间冲突,说明无法确认。
3. 每个关键结论必须引用 doc id。
这不是形式主义。
这是在告诉模型:
★哪些信息能用,哪些信息不能用,冲突时怎么处理。
没有这些边界,模型很容易把旧资料、新资料、用户猜测、历史对话混在一起。
4. 输出后做引用校验
生成答案后,不要直接返回给用户。
至少做一层 claim check。
比如模型回答:
跨部门项目报销必须提交项目立项书。
系统要检查:
- “必须”有没有来源?
- “项目立项书”有没有来源?
- 对应文档是否真的这么写?
- 引用是否只是贴了个无关文档?
如果关键结论找不到证据,就降级:
根据当前资料无法确认是否必须提交项目立项书。
已找到的资料只说明需要关联项目编号。
这一步会增加延迟。
但在高风险场景里,这个成本值得。
工程上怎么落地
如果你现在负责一个企业 AI 问答系统,我建议别一上来就追求“回答更聪明”。
先把系统从“必答模式”改成“有证据才答”。
一个可落地的链路大概是这样:
用户问题
↓
问题改写
↓
混合检索
↓
重排序
↓
上下文门禁
↓
基于证据生成
↓
引用校验
↓
答案 / 拒答 / 转人工
上线前重点看这几个指标:
指标 | 目标 |
|---|---|
unsupported claim rate | 没有证据支撑的结论比例要下降 |
correct refusal rate | 资料不足时能正确拒答 |
false refusal rate | 明明有资料却拒答的比例不能太高 |
citation precision | 引用资料必须真的支持答案 |
answer latency | 增加校验后延迟是否可接受 |
这里有个平衡。
拒答太少,幻觉高。
拒答太多,用户觉得没用。
所以不要拍脑袋调 prompt。
要用评估集调。
比如准备 200 个问题:
- 100 个知识库里有明确答案
- 50 个资料不足
- 30 个资料冲突
- 20 个恶意诱导或越权问题
然后看系统有没有能力区分这些问题。
真正的 AI 工程,不是把模型接上去就完事。
而是让它在该回答时回答,该拒绝时拒绝,该转人工时转人工。
面试怎么答这个问题
如果面试官问:
★为什么大模型会幻觉?为什么它不愿意说不知道?
不要只答一句“因为它是概率模型”。
太浅了。
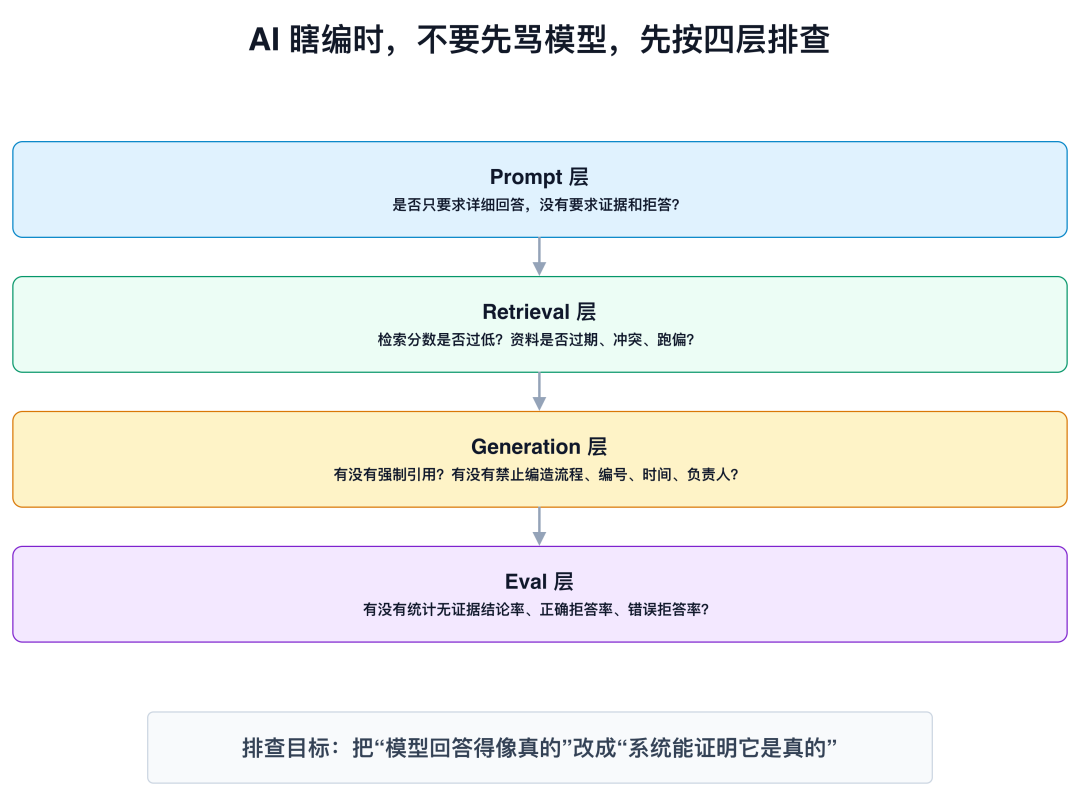
★图 3:面试或排查时,别只盯着模型本身,要从 Prompt、Retrieval、Generation、Eval 四层拆。
可以这么答:
我会从训练目标和系统工程两层看。
第一,大模型预训练目标是预测下一个 token,它天然更擅长生成“像答案的文本”,而不是判断事实是否存在。
第二,很多对话系统的 prompt 强调 helpful、详细、完整,但没有把“资料不足必须拒答”设计成强约束。
第三,RAG 系统如果没有检索阈值、上下文门禁和引用校验,就会出现没搜到也继续生成的情况。
第四,模型自己输出的 confidence 不能直接当事实置信度,真实置信要结合检索分数、引用覆盖率、文档一致性和人工评估。
所以解决幻觉不能只靠一句 prompt,而要从 query rewrite、retrieval gating、grounded generation、claim verification 和 eval 指标一起做。
如果面试官继续追问:
★那怎么让它更愿意说不知道?
可以继续答:
我会做三件事。
第一,在 prompt 和输出协议里明确拒答条件,没有证据时返回 insufficient_context。
第二,在检索层设置门禁,比如 top1 分数过低、文档冲突、资料过期时,不进入生成链路。
第三,在评估层单独统计 correct refusal rate 和 unsupported claim rate,避免系统为了看起来有用而降低拒答率。
这就比“调低 temperature”靠谱多了。
顺便说一句,调低 temperature 可以让输出更稳定,但它不能从根上解决无证据生成。
低温瞎编,还是瞎编。
只是编得更稳定。
最后回到开头那个机器人
它为什么不说“不知道”?
不是因为它有坏心眼。
也不是因为它真的自信。
而是整个系统从训练目标、prompt、检索、生成到产品指标,都在推着它回答。
用户问“这个要不要补附件”。
知识库没给证据。
检索没拦住。
Prompt 还要求它专业、详细、完整。
于是它只能顺着语言惯性往下写。
写出一个像制度、像流程、像标准答案的假答案。
所以别再只问:
★怎么让 AI 更聪明?
在生产系统里,更应该问:
★怎么让 AI 在不知道的时候,体面地停下来?
因为很多时候,AI 最有价值的一句话不是长篇大论。
而是:
★根据当前资料,我无法确认。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号