Elastic 如何通过合成 _id 和布隆过滤器将时间序列存储空间减少 34%

Elastic 如何通过合成 _id 和布隆过滤器将时间序列存储空间减少 34%

点火三周
发布于 2026-06-01 19:05:20
发布于 2026-06-01 19:05:20
Elastic 如何通过合成 _id 和布隆过滤器将时间序列存储空间减少 34%
探索 Elastic 开箱即用的前沿功能。您可以访问 Elasticsearch Labs 代码库 中的示例笔记本,开始 免费的 Elastic Cloud 试用,或者立即在您的 本地机器上试用 Elastic。
合成 _id 可将时间序列索引的存储空间减少高达 34%,并消除数据摄入时 6% 的 CPU 开销。Elasticsearch 不再为 _id 构建倒排索引,而是根据 _tsid 和 @timestamp 即时计算文档标识符,并使用布隆过滤器进行去重。这项优化功能已在 Elasticsearch 9.4 中发布,并已在 Elastic Cloud Serverless 上线。
本文将深入探讨其具体实现。要了解合成 _id 如何融入更广泛的指标性能优化方案,请参阅 我们如何将 Elasticsearch 重建为领先的列式指标数据存储,该方案使 OpenTelemetry 指标的存储效率提高了 6.6 倍,索引吞吐量提高了 50%。
我们将首先解释为什么 _id 字段对于时间序列工作负载而言成本高昂。接着,我们将描述合成 _id 的工作原理,以及它如何使用布隆过滤器而不是传统的倒排索引来优化文档去重。最后,我们将分享来自基准测试和 Serverless 生产部署的性能结果。
_id 在时间序列索引中的隐性成本
时间序列索引是一种专门的索引模式,针对指标、日志、追踪及其他带时间戳的数据进行了优化。它们存储数据点序列(如 CPU 使用率、股票价格或传感器读数),用于跟踪特定实体随时间的变化。在 Elasticsearch 中,每个数据点都作为一个文档被索引,并带有一个名为 _id 的唯一标识符。此标识符用于查找、更新或删除特定文档。当文档在 Elasticsearch 中被索引时,系统会检查是否已存在具有相同 _id 的文档。根据操作类型 (op_type) 的不同,现有文档要么被替换 (index),要么新文档被拒绝 (create);后者是指标摄入最常见的路径。
为了高效执行此查找,Elasticsearch 会为 _id 字段构建一个 倒排索引。该倒排索引将每个 _id 值映射到其在索引中的位置,从而实现快速的文档查找。在 8.11 版本之前,_id 值也单独存储,以便在搜索结果和其他 API 中返回。从 8.11 版本开始,我们对 Elasticsearch 进行了优化,仅临时存储此值用于文档复制目的,该值会很快被合并并按需重建。
对于许多用例而言,构建和存储倒排索引的开销是可接受的。但对于时间序列数据,如指标或追踪,成本会迅速累积。我们的实验表明,与不构建 _id 倒排索引相比,构建该索引会增加 6% 的 CPU 开销。在某些极端情况下,我们基准测试发现它可能使索引吞吐量降低 25%。
这种开销对于时间序列工作负载尤其令人头痛,因为数据点通常很小(通常只是一个时间戳和几个数值),并且压缩效果极佳。然而,_id 字段无法从相同的压缩中受益。结果,_id 的倒排索引可能在总存储空间中占据不成比例的份额。在我们的 OpenTelemetry (OTel) 指标基准测试中,仅 _id 倒排索引就占用了每个数据点总计 25 字节中的约 5 字节。
我们考虑了几种消除这种开销的方法:
- • 停止索引
_id并停止检查重复项:这将是最简单的解决方案,但如果没有去重功能,重复的数据点可能会导致聚合结果出错。例如,一个仪表盘的平均值可能会因重复值而失真。 - • 索引时接受重复项,查询时去重:这可以保持正确性,但会增加每次查询的开销,从而降低仪表盘的响应速度。
- • 在段合并期间去重:重复项最终会被移除,但对未合并段的查询仍会返回包含重复项的结果。
- • 合成
_id:根据已经唯一标识每个数据点的字段,即时计算文档标识符,并使用轻量级布隆过滤器进行去重,而不是完整的倒排索引。
我们选择了合成 _id,因为它在摄入时保持了正确性,同时消除了传统方法的存储和 CPU 开销。我们决定将其应用于时间序列索引,因为它们非常适合这种优化。
在时间序列索引中,_id 并非任意生成。每个文档都有一个时间序列标识符 (_tsid) 和一个时间戳 (@timestamp)。_tsid 是根据文档的 维度字段 生成的(例如 host.name、pod.name 或 sensor_id),而 @timestamp 标记了文档的时间点。这两个字段结合起来可以唯一标识文档:在给定时间点,给定时间序列只能有一个数据点。这意味着我们可以从 _tsid 和 @timestamp 字段值派生出 _id,而不是单独存储它。
合成 _id 在 Elasticsearch 中如何工作?
通过合成 _id,Elasticsearch 将 _tsid 和 @timestamp 字段的组合即时计算为文档标识符。这个计算出的值用于所有通常需要 _id 的地方:API 响应、文档查找和去重。然而,它从未存储在倒排索引中,也从未存储在磁盘上以供后续检索。
挑战在于去重。当新文档到达时,Elasticsearch 必须验证是否已存在具有相同 _id 的文档。如果没有 _id 上的倒排索引,我们如何高效地执行此检查?
合成 _id 如何在不构建倒排索引的情况下模拟它
我们的 Elastic Lucene 专家提出了一个巧妙的想法:由于 _tsid 和 @timestamp 已经作为 doc values 存储,我们可以公开我们自己的自定义 Lucene postings format,它可以在不实际构建倒排索引的情况下模拟一个倒排索引。
这意味着,当 Elasticsearch 需要通过 _id 查找文档时,它会使用与平时相同的代码路径:它查询底层的 Lucene 索引以查找 _id 术语。但我们的自定义 postings format 会拦截该调用,从合成 _id 中提取编码的 _tsid 和 @timestamp,并使用它们的 doc values 来定位文档,而不是命中真正的倒排索引。由于时间序列索引按这些字段排序,属于同一时间序列的文档是连续存储的。这使得 Elasticsearch 可以跳过大量不匹配的文档子集(有时是整个段),从而快速找到目标文档。
虽然这个过程是高效的,但它可能涉及多次随机访问读取:查找 _tsid 值、扫描匹配文档以及读取时间戳。对于时间序列索引中常见的情况,即我们不期望文档已经存在,我们希望能够快速失败,而根本不接触 doc values。
布隆过滤器实现快速成员测试
我们使用 布隆过滤器 解决了这个问题。布隆过滤器是一种概率数据结构,可以快速回答“此元素可能存在于集合中吗?”这个问题,具有很小的误报风险,但没有漏报风险。换句话说,布隆过滤器偶尔可能会说“是”,而实际答案是“否”,但它绝不会在答案为“是”时说“否”。
当文档被索引时,其合成 _id 会被添加到布隆过滤器中。当新文档到达时,我们首先检查布隆过滤器。如果布隆过滤器说“否”,我们就能确定不存在具有此 _id 的文档,并且可以立即进行索引。如果布隆过滤器说“可能存在”,我们则回退到使用 _tsid 和 @timestamp doc values 进行更昂贵的验证。
合成 _id 索引工作流:分步详解
让我们逐步了解启用合成 _id 的时间序列索引中文档的索引过程:
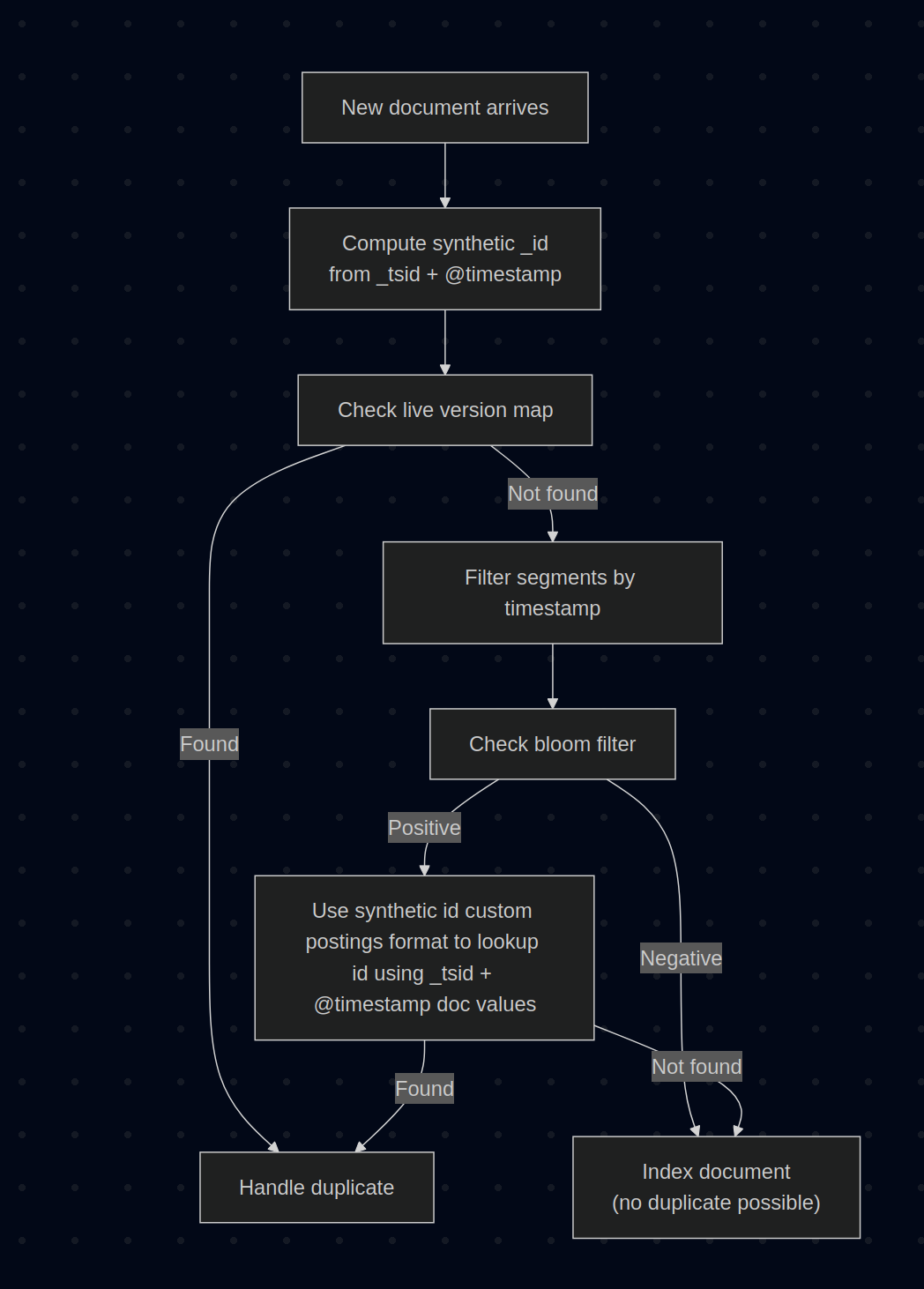
在深色背景上显示的流程图,展示了使用合成 ID、布隆过滤器和重复处理路径的文档索引步骤。
在深色背景上显示的流程图,展示了使用合成 ID、布隆过滤器和重复处理路径的文档索引步骤。
- 1. 计算合成
_id:Elasticsearch 将_id计算为_tsid || @timestamp的组合。 - 2. 检查实时版本映射:像现在一样,我们首先检查最近索引文档的内存映射。如果文档存在于此映射中,我们可以立即处理重复项。
- 3. 按时间戳过滤段:时间序列索引按
_tsid和@timestamp排序。我们可以跳过任何时间戳范围与传入文档时间戳不重叠的段。 - 4. 检查布隆过滤器:对于每个候选段,我们使用布隆过滤器测试
_id是否可能存在。 - 5. 按需验证:如果布隆过滤器返回肯定结果,我们则使用
_tsid和@timestampdoc values 查找文档。由于文档按这些字段排序,此查找是高效的。 - 6. 索引文档:如果未找到现有版本,则索引文档。
_id被添加到该段的布隆过滤器中,但不会构建倒排索引,并且字段值从不存储。
在常见情况下,当新数据以最新时间戳到达时,步骤 3 会消除大部分段的考虑,而步骤 4 会快速确认文档是新文档。步骤 5 中昂贵的验证仅在布隆过滤器误报时发生,而这种情况预计会很少见。
布隆过滤器误报率:Elasticsearch 如何保持低误报率
基于布隆过滤器的去重功能面临的一个挑战是,如何在不牺牲我们所追求的存储效率的情况下控制误报率。为了有效地确定布隆过滤器的大小,我们考虑每个段中的数据点数量,并同时设定较低的误报率和低于 50% 的位集饱和度目标。
饱和度目标具有特定目的:当段合并时,我们对位集进行 OR 运算,而不是从头开始重建布隆过滤器。这使得合并速度更快,但也意味着随着段的反复合并,误报率会趋向于 100%。将合并前的饱和度保持在 50% 以下,可以为我们赢得缓冲空间,从而延缓这种收敛。
较低的误报率目标由访问模式决定:最近的段被检查的频率远高于旧段,因为我们根据数据点时间戳修剪搜索空间。那些经过大量合并且布隆过滤器性能下降的旧段,不太可能被检查。
合成 _id 性能基准测试:索引和存储
我们进行了广泛的基准测试来验证我们的实现。
索引吞吐量
这项工作的核心目标是匹配或提高现有索引吞吐量。原则上,新方法的工作量更少:构建 _id 的倒排索引需要哈希每个值,在内存中构建和维护复杂的数据结构,并将其刷新到磁盘。在吞吐量高的用例中,这些结构在段合并期间也必须重建,增加了 CPU 和 I/O 开销。
构建布隆过滤器并非没有成本(我们仍然哈希每个值),但内存占用更小,并且没有复杂的数据结构需要维护或刷新。布隆过滤器的合并成本也很低:如果可能,我们只需对位集进行 OR 运算,而不是从头开始重建。
合成 _id 的主要成本来自使用 doc values 验证潜在的重复项。然而,这个成本被两个因素所缓解:首先,布隆过滤器的误报率很低,因此大多数文档完全跳过了这一步。其次,时间序列索引按 _tsid 和 @timestamp 排序,这意味着 doc value 查找可以高效地跳过大量不匹配的文档块。
实际上,这正是我们观察到的。即使考虑到当布隆过滤器返回肯定结果时,验证与 _tsid 和 @timestamp 匹配所需的额外查找,吞吐量也与之前相当甚至更好。不构建和合并倒排索引所节省的开销超过了偶尔检查误报的成本,这已通过我们的 夜间基准测试 证实:
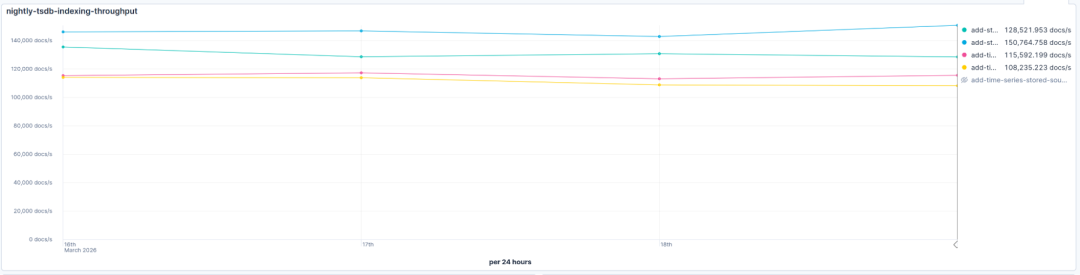
折线图,标题为“nightly‑tsdb‑indexing‑throughput”,显示了三天内文档索引速率(文档/秒)的夜间基准测试结果,其中有四条不同颜色的线代表不同的索引操作。
折线图,标题为“nightly‑tsdb‑indexing‑throughput”,显示了三天内文档索引速率(文档/秒)的夜间基准测试结果,其中有四条不同颜色的线代表不同的索引操作。
存储节省
在我们的 OTel 指标基准测试中,合成 _id 使每个数据点的存储空间减少了大约 5 字节。对于平均每个数据点 25 字节的数据集,仅此一项优化就使存储空间减少了 20%。
这些结果很快得到了我们 夜间基准测试 的证实。下图显示了我们在 2026 年 3 月 19 日启用合成 _id 功能后,存储占用随时间的变化:
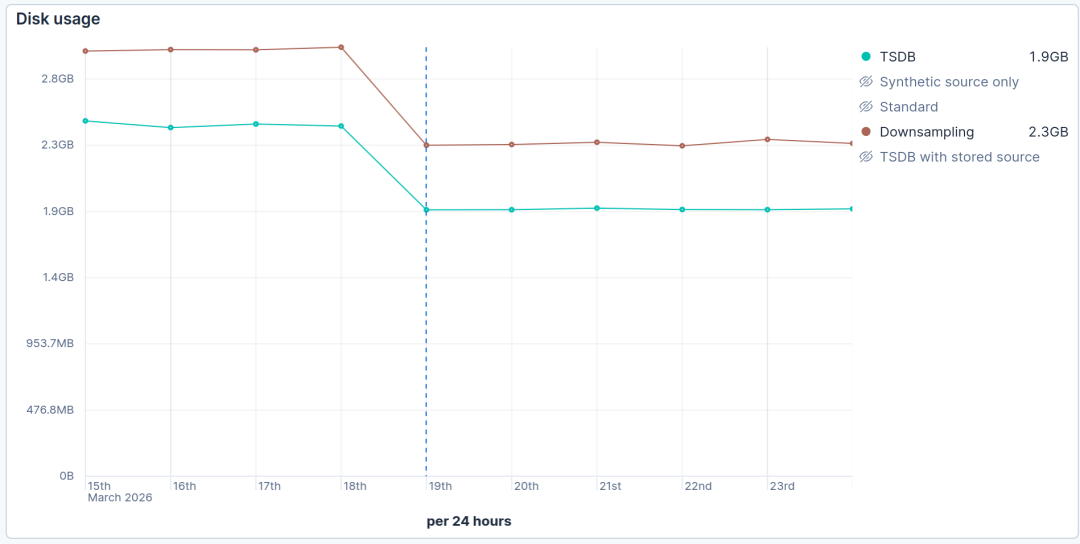
折线图,标题为“磁盘使用情况”,显示了 2026 年 3 月 15 日至 3 月 23 日的 TSDB 和降采样数据,磁盘使用量以每天 GB 为单位。TSDB 的青色线在 3 月 19 日附近下降并稳定在约 1.9 GB,而降采样的棕色线在同一日期后下降到 2.3 GB。
折线图,标题为“磁盘使用情况”,显示了 2026 年 3 月 15 日至 3 月 23 日的 TSDB 和降采样数据,磁盘使用量以每天 GB 为单位。TSDB 的青色线在 3 月 19 日附近下降并稳定在约 1.9 GB,而降采样的棕色线在同一日期后下降到 2.3 GB。
我们的标准时间序列数据库 (TSDB) 基准测试显示,存储空间从 2.5 GiB 减少到 1.9 GiB(减少 24%)。同样,时间序列降采样基准测试也显示了从 3 GiB 减少到 2.3 GiB(减少 23%)的类似效果。
另一项更侧重于指标的基准测试 显示了更好的减少,从 3.0 GiB 减少到 2.0 GiB(减少 34%):
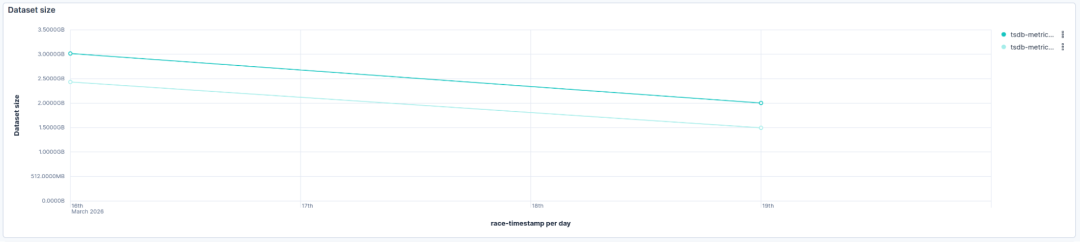
折线图,标题为“数据集大小”,显示了两条青绿色线,从 2026 年 3 月 16 日到 19 日下降,每条线代表一个不同的 TSDB 指标。x 轴标记每日时间戳,y 轴显示数据集大小正在减小。
折线图,标题为“数据集大小”,显示了两条青绿色线,从 2026 年 3 月 16 日到 19 日下降,每条线代表一个不同的 TSDB 指标。x 轴标记每日时间戳,y 轴显示数据集大小正在减小。
API 兼容性
一个重要的设计目标是保持与现有 Elasticsearch API 的兼容性。使用合成 _id,所有文档 API 都能按预期工作:Bulk、Get、Update、Delete、Reindex 以及 Update/Delete by Query。这种兼容性层也限制了更改的影响范围,确保任何问题都将限制在内部实现中。
当 API 请求中未提供 _id 时,Elasticsearch 会根据 _tsid 和 @timestamp 字段计算它。为了检查文档是否已存在,它首先查询布隆过滤器,如果需要,则回退到 doc values。在搜索结果或 API 响应中返回文档时,_id 也会按需从 doc values 中合成。
有一种特殊情况需要处理,即按 _id 前缀或模式进行搜索或过滤。此类查询需要扫描大量文档才能找到匹配的文档,虽然这能正常工作,但与直接 _id 查找相比会带来性能损失。不过,我们预计这种用例在时间序列索引中并不常见。
Elasticsearch 9.4 和 Elastic Cloud Serverless 可用性
合成 _id 功能将在 Elasticsearch 9.4.0 中发布,并已在 Elastic Cloud Serverless 上可用。
无需配置:此功能默认启用,新创建的时间序列索引(包括在数据流滚动时创建的索引)将自动受益于此优化。在 9.4 之前创建的现有时间序列索引将继续为 _id 字段创建倒排索引。
我们预计合成 _id 在所有时间序列用例中都能表现出色。但是,在某些非常特定、更新频繁的用例中,如果您遇到性能问题,可以通过将 index.mapping.synthetic_id 设置为 false 来禁用新索引的此功能。
总结:合成 _id 的存储和性能增益
本文中,我们介绍了合成 _id 如何消除时间序列索引中文档标识符的存储和计算开销。通过根据 _tsid 和 @timestamp 即时计算 _id,并使用布隆过滤器进行去重,我们实现了与现有方法相当或更优的索引性能,并将存储空间减少了高达 34%,同时保持了完整的 API 兼容性。对于运行大规模时间序列工作负载的用户来说,这直接转化为更低的 инфраструк成本。
路线图:合成 _id 之后的发展
合成 _id 是 Elastic 减少存储开销更广泛工作的一部分。
- • 序列号裁剪:每个文档都带有用于复制和并发控制的序列号。对于仅追加的时间序列数据,这些序列号在段合并后变得冗余。Elasticsearch 9.4 现在在合并期间裁剪它们,以回收更多存储空间:我们将在即将发布的博客文章中详细介绍此优化。
- • 合成
_id超越时间序列:我们正在探索如何将合成_id引入常规索引,方法是让用户声明哪些字段唯一标识其文档,并配置这些字段上的索引排序以实现高效查找。
敬请期待!
常见问题
为什么 _id 字段在 Elasticsearch 时间序列索引中开销很大?
_id 字段需要一个用于去重的倒排索引,这会在索引期间增加 6% 的 CPU 开销,并消耗每个数据点大约 5 字节的存储空间。对于小型时间序列文档(通常只有 25 字节),这占总存储空间的 20%。
合成 _id 在 Elasticsearch 中如何工作?
合成 _id 通过组合 _tsid(时间序列标识符)和 @timestamp 来即时计算文档标识符。Elasticsearch 不再存储倒排索引,而是使用布隆过滤器来检查重复项,仅在误报时才回退到 doc values。
我可以从合成 _id 中获得多少存储节省?
基准测试显示,根据您的数据配置文件,存储空间可减少 20-34%。OTel 指标工作负载存储空间减少了 34%(从 3.0 GiB 到 2.0 GiB),而通用 TSDB 工作负载存储空间减少了 24%(从 2.5 GiB 到 1.9 GiB)。
合成 _id 会影响 Elasticsearch API 兼容性吗?
不会。所有文档 API(Bulk、Get、Update、Delete、Reindex、Update/Delete by Query)都能按预期工作。_id 会透明地计算并在 API 响应中返回。
布隆过滤器如何帮助 Elasticsearch 进行去重?
布隆过滤器可以回答“此元素是否存在?”的问题,并且没有漏报。当新文档到达时,Elasticsearch 首先检查布隆过滤器。如果布隆过滤器说“否”,则立即索引该文档。如果布隆过滤器说“可能存在”,Elasticsearch 则使用 doc values 进行验证。这避免了在文档是新文档的常见情况下进行昂贵的查找。
如果遇到问题,我可以禁用合成 _id 吗?
可以。对于新索引,请将 index.mapping.synthetic_id 设置为 false。这仅建议用于您观察到性能问题的特定更新频繁的用例。
合成 _id 何时可用?
合成 _id 已在 Elastic Cloud Serverless 上可用,并将随 Elasticsearch 9.4.0 一同发布。它默认对所有新的时间序列索引启用。
📡 更多 Elastic & AI 可观测性干货
关注公众号「点火三周」,第一时间获取最新技术文章
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号