快被KV Cache搞破产了

快被KV Cache搞破产了

乐小野
发布于 2026-06-01 21:21:40
发布于 2026-06-01 21:21:40
上周跟一个创业的朋友喝酒,他做AI服务的,刚融了一千万。
我问:钱够花吗?
他苦笑:够烧半年吧。你知道我们最大的成本是什么吗?不是买卡,不是电费,是内存。
我说:别闹,你又不是开网吧。
他把手机推过来,给我看监控面板:40%的A100显存被一个叫KV Cache的东西吃掉了。而且用户越多,对话越长,它吃得越狠。
一、先算笔账:这块“临时工”到底多能吃?
先拿一个13B参数的模型来算。这个规模在中型部署里很常见,数据也透明。
公式
KV Cache的占用公式是:
2(Key和Value两份) × 隐藏层维度 × 层数 × 数据类型字节
对于OPT-13B这样的模型:
- 隐藏层维度:5120
- 层数:40
- 数据类型:FP16(2字节)
代入:2 × 5120 × 40 × 2 = 819,200字节 ≈ 800KB/Token
这是论文里给出的典型值。
前提:这是FP16精度、MHA架构的计算结果。如果换成MQA/GQA,系数会小一些;如果换成INT8量化,字节数减半。
场景代入
假设用户问了个500字的问题,你生成了500字的回答。中文场景下,1个汉字 ≈ 1-2个Token,咱们取中位数按1.5算:
1000字 × 1.5 = 1500个Token
1500 × 800KB = 1.2GB
这是单个请求的KV Cache占用。
前提:假设所有Token的KV Cache都保留,没有做任何压缩或稀疏化。
GPU能扛几个并发?
一块A100 40GB:
- 模型权重(FP16):13B × 2字节 = 26GB(固定,加载一次)
- CUDA内核、激活值(Activations)、临时缓冲区:至少再吃掉2-4GB(取决于批处理大小和序列长度)
- 留给KV Cache的空间:大概10GB左右
10GB ÷ 1.2GB ≈ 8个请求
这是理想情况——前提是:
- 所有请求的上下文长度一模一样(1500 Token)
- 显存没有碎片,预分配全部命中
- 批处理引擎效率100%,没有额外开销
- 不考虑Continuous Batching带来的动态变化
现实中,能做到4-6并发,已经算优化得很好了。
如果换成70B模型?
- 隐藏层维度:8192
- 层数:80
- 同样的1500 Token:2 × 8192 × 80 × 2 × 1500 ≈ 3.9GB/请求
- 40GB A100能扛的并发:2-3个
这就是为什么大厂都在疯狂优化KV Cache——模型越大,内存墙越狠。
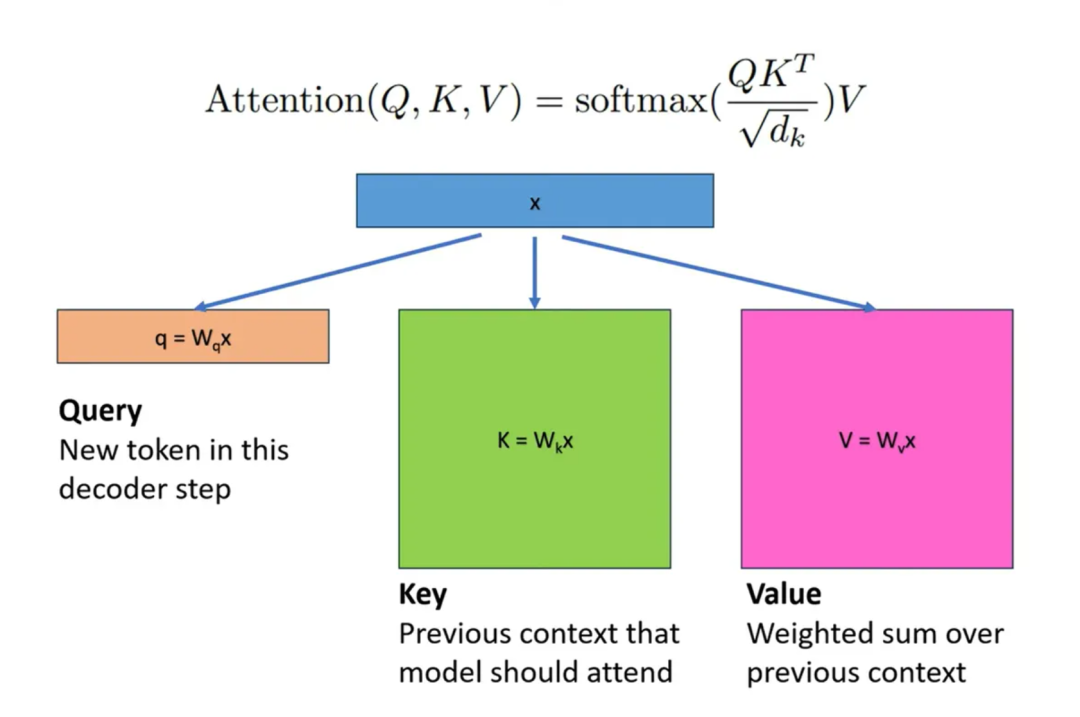
二、PagedAttention:把操作系统课本翻出来
传统系统怎么管理KV Cache?预分配一整块连续内存,按最大可能长度(比如2048 Token)圈地。结果:
- 用户A:50 Token,占2048的坑 → 内部碎片
- 用户B:300 Token,占2048的坑 → 内部碎片
- 用户C:700 Token,占2048的坑 → 内部碎片
- 不同请求之间:内存块大小不一,产生外部碎片
论文里给过一个触目惊心的数据:传统系统中,真正用于存放KV Cache的有效内存占比,最低只有20.4%。
PagedAttention的核心设计
vLLM团队从操作系统虚拟内存里抄了作业:
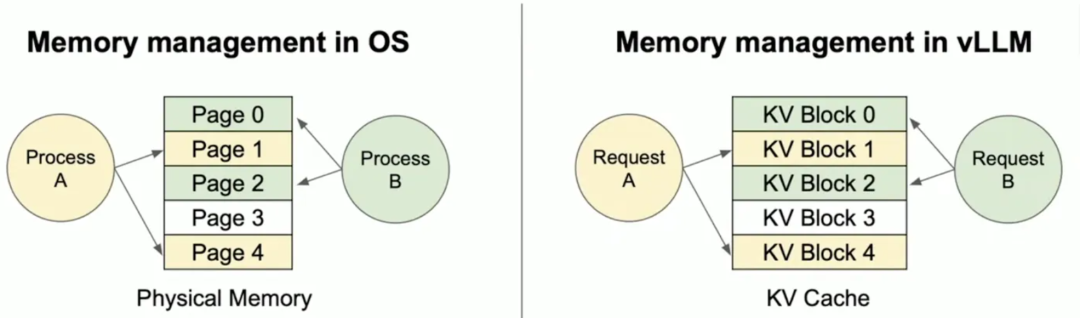
- 固定大小的块(Block):默认16个Token的KV向量作为一个块。为什么是16?块太大浪费内存,块太小增加映射开销,16是工程上折中的结果。
- 逻辑块 → 物理块的映射:每个请求看到的KV Cache是连续的“逻辑块”,但实际存储在分散的“物理块”里,通过块表(Block Table)维护映射关系。
- 按需分配:生成多少Token,分配多少块,不预占坑。
内核级别的并行读取
PagedAttention的CUDA内核做了精细的并行设计:
- 线程组(Thread Group):THREAD_GROUP_SIZE个线程一组,一次获取一个Query Token和一个Key Token
- 向量化读取:每组一次读16字节,实现内存合并
- Warp调度:每个Warp(32线程)一次处理一个Query Token与一个完整块的Key Token的计算
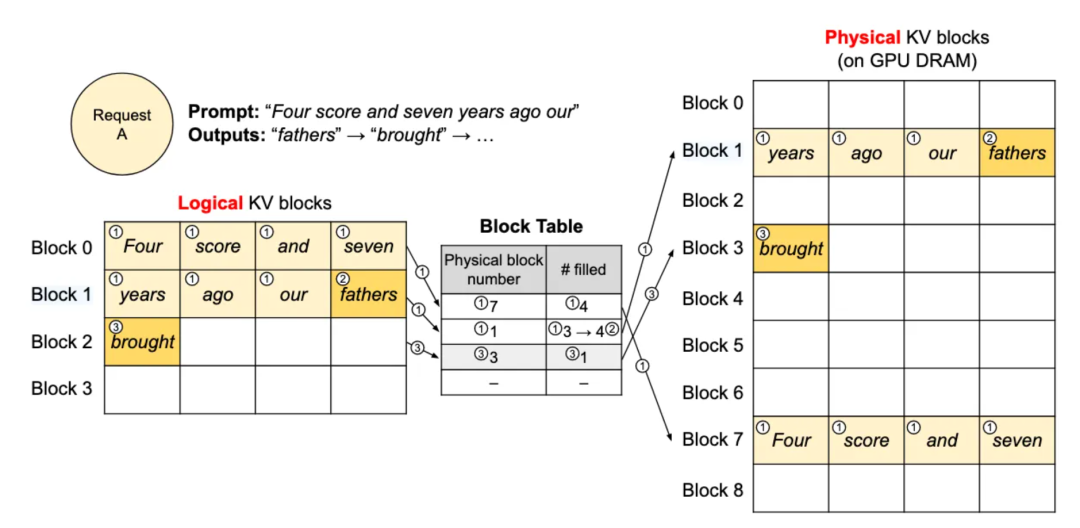
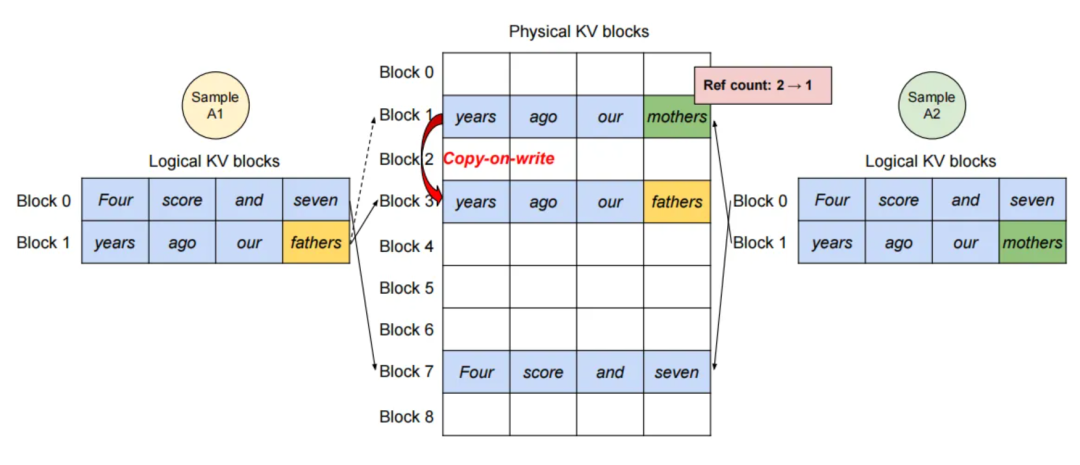
共享机制
在并行采样或束搜索时,多个生成分支共享同一个Prompt。PagedAttention用写时复制(Copy-on-Write):
- 所有分支先共享Prompt的KV Cache块
- 只有当某个分支需要写入新Token时,才复制相关块到新物理位置
论文里的实测数据:
- 并行采样:内存节省6.1%-30.5%
- 束搜索(宽度6):内存节省37.6%-66.3%
format,webp
效果
与HuggingFace Transformers比,吞吐量最高提升24倍;与HuggingFace TGI比,最高提升3.5倍。
三、Mooncake:把KVCache做成共享池
单机优化到头了,阿里云开源的Mooncake把目光投向集群。
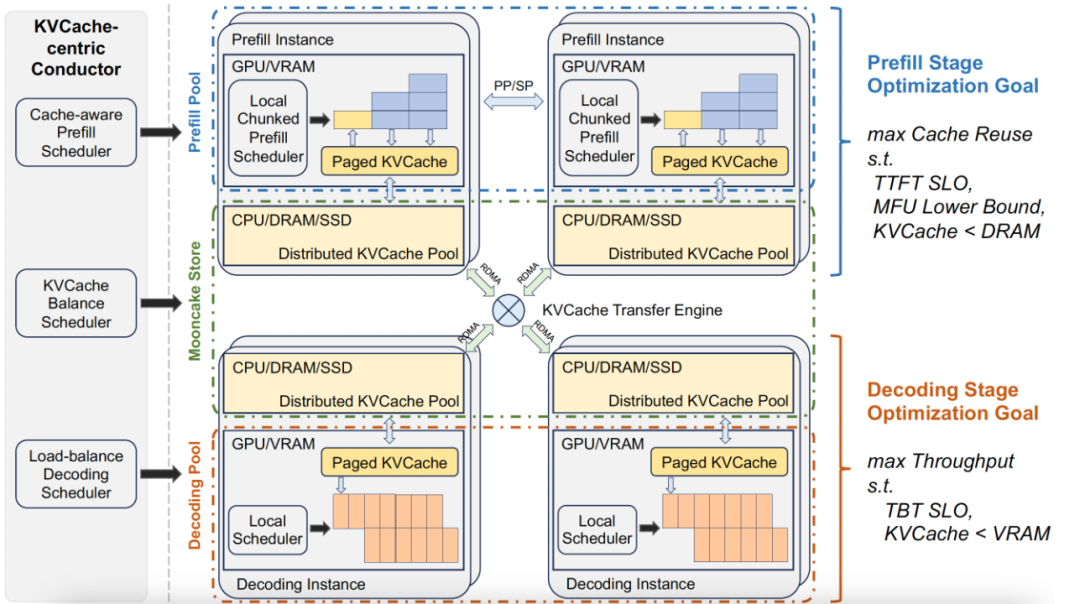
PD分离架构
Mooncake的核心是以KVCache为中心的PD分离架构:
- P(Prefill)节点:计算密集型,负责首Token生成
- D(Decode)节点:存储密集型,负责后续Token生成
- 分离部署,互不干扰
为什么要拆?因为Prefill和Decode的计算特征完全不同:
- Prefill:输入Token多,并行计算,算力瓶颈
- Decode:一次一个Token,频繁读写KV Cache,内存瓶颈
KVCache池化
Mooncake构建了一个分布式KVCache池,让所有节点可以共享缓存的上下文。
比如:用户A问“公司上个季度财报怎么样”,系统算完把KV Cache存进池子。几分钟后用户B问同样的问题——直接从池子里读缓存,不用重新计算。
传输引擎的挑战
跨节点传输KV Cache是最大难点。Mooncake的解决方案:
- 全链路零拷贝
- 多网卡聚合:最高支持8×400Gbps
- 兼容eRDMA、NVLink、CXL、GPUDirect
论文里给出了传输成本的判断公式:只要满足 B/G > 2ds/[gqa×(apd +bd²)],传输就有正收益。其中B是带宽,G是算力,d是隐藏层维度。
前提:带宽达到100Gbps以上,收益即可为正。
调度算法
Mooncake的调度器会为每个新请求选择最优的P节点和D节点:
- 计算请求的prefix hash,找到前缀匹配最优的节点
- 遍历每个P节点,估算三种耗时:
- KV Cache传输时间(如果需要从最佳节点拷贝)
- 排队时间
- Prefill计算时间
- 选择总耗时最短的P节点,再根据负载选D节点
效果
- 响应时间降低69.1%
- TPOT下降20%
- 成本压到0.2美元/百万Token
四、量化+剪枝+蒸馏:给KVCache减肥
说完系统层面,再说算法层面的“瘦身”。
KIVI:2-bit量化的突破
KIVI团队对主流LLM的KV Cache元素分布做了研究,发现两个关键事实:
- Key缓存存在通道级异常值:某些固定通道的数值远大于其他通道,且持续存在
- Value缓存没有明显异常值
基于此,KIVI提出非对称量化策略:
- Key缓存:按通道量化(沿通道维度分组量化)
- Value缓存:按Token量化
流式处理的实现难题
Key缓存的按通道量化不能直接在流式场景中实现,因为量化过程跨越不同Token。KIVI的解决方案:
把Key缓存分成两部分:
- 分组部分
XKg = XK[:l-r]:每G个Token一组,存储量化后的版本 - 余留部分
XKr = XK[l-r:]:保持全精度
解码过程中,新到达的Key先添加到 XKr,当 XKr 积累到R个Token时,将其量化并与之前的 XKg 拼接,然后重置 XKr。
实验结果
- Llama2-7B:从16位压缩到2位,精度下降最多2%
- 峰值内存减少2.6倍
- 最大批量大小提升4倍
- 吞吐量提高2.35倍到3.47倍
CommVQ:苹果的1-bit突破
苹果的研究团队提出了Commutative Vector Quantization(CommVQ),利用加法量化(Additive Quantization)和与RoPE可交换的码本设计,实现了更激进的压缩。

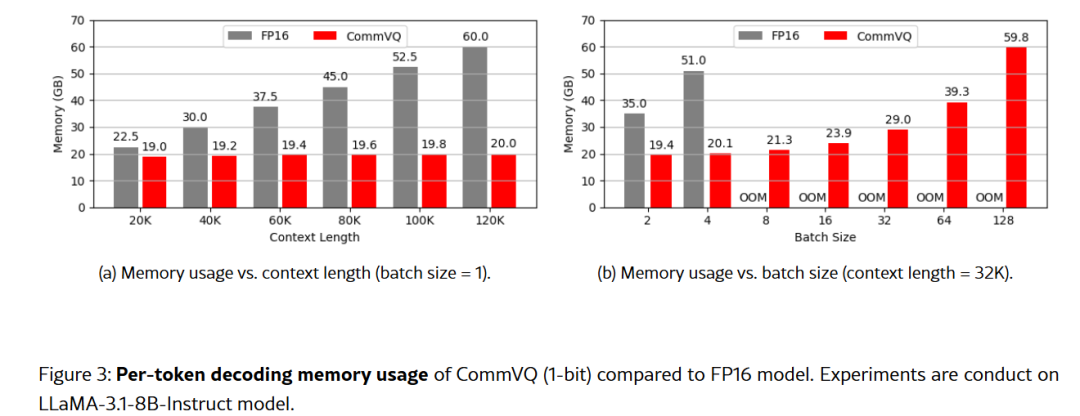
关键数据:
- FP16 KV Cache减少87.5%(2-bit量化)
- 1-bit量化可行,精度下降极小
- LLaMA-3.1 8B + 128K上下文,单张RTX 4090可跑
前提:需要轻量级Encoder和EM算法训练码本,推理时用矩阵乘法解码。
KVC-Q:动态精度分配
最新的KVC-Q框架提出了一个更有趣的思路:不要均匀量化,按Token重要性动态分配精度。
三个核心机制:
- Recency Priority:最近的Token保留高精度
- Importance Preservation:动态识别重要的长程Token,保持高精度
- Head-Aware allocation:根据注意力头部的敏感度分配精度
效果:
- 内存减少70%(约4倍压缩)
- 保留94%以上的基线性能
- 消费级GPU上,可处理4倍以上的上下文长度
五、未来:当内存不够,就偷硬盘的
分层存储
ODCC和NVIDIA最近发了个评测,核心思路是分层存储:
- 热数据:GPU显存
- 温数据:主机内存
- 冷数据:NVMe SSD
- 冻数据:分布式存储
结果:首Token延迟优化97%,吞吐量提升22倍。
ROM+SRAM:端侧的“物理焊死”
上海交大、辉羲智能和微软亚洲研究院的ROMA/TOM系列研究,走得更远:
ROMA架构:
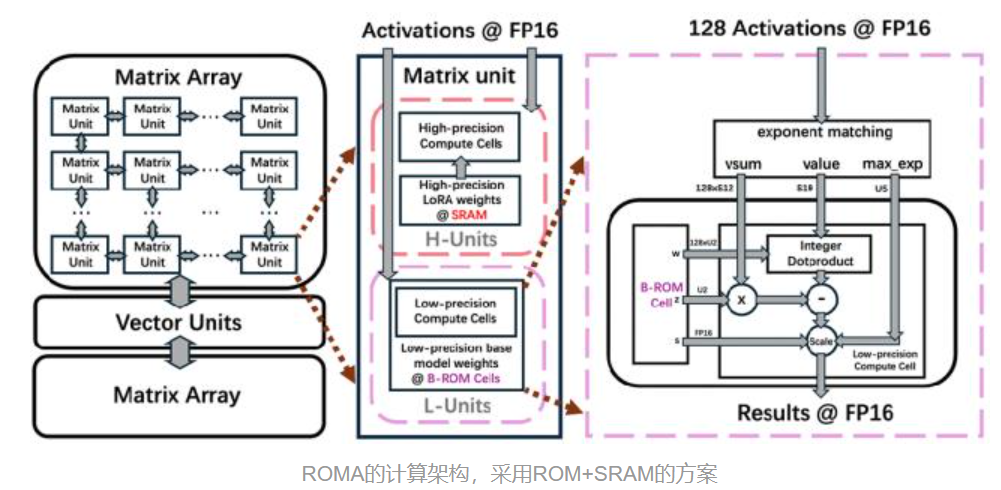
- 把模型权重“固化”进只读存储(ROM)
- QLoRA机制:ROM存基座模型,SRAM存LoRA适配器,兼顾固化与灵活
- 7nm工艺,500mm²芯片,可完整容纳4-bit LLaMA3.2-3B或2-bit LLaMA3-8B
- 推理速度:20,000 tokens/s
TOM架构(针对BitNet/Ternary模型):
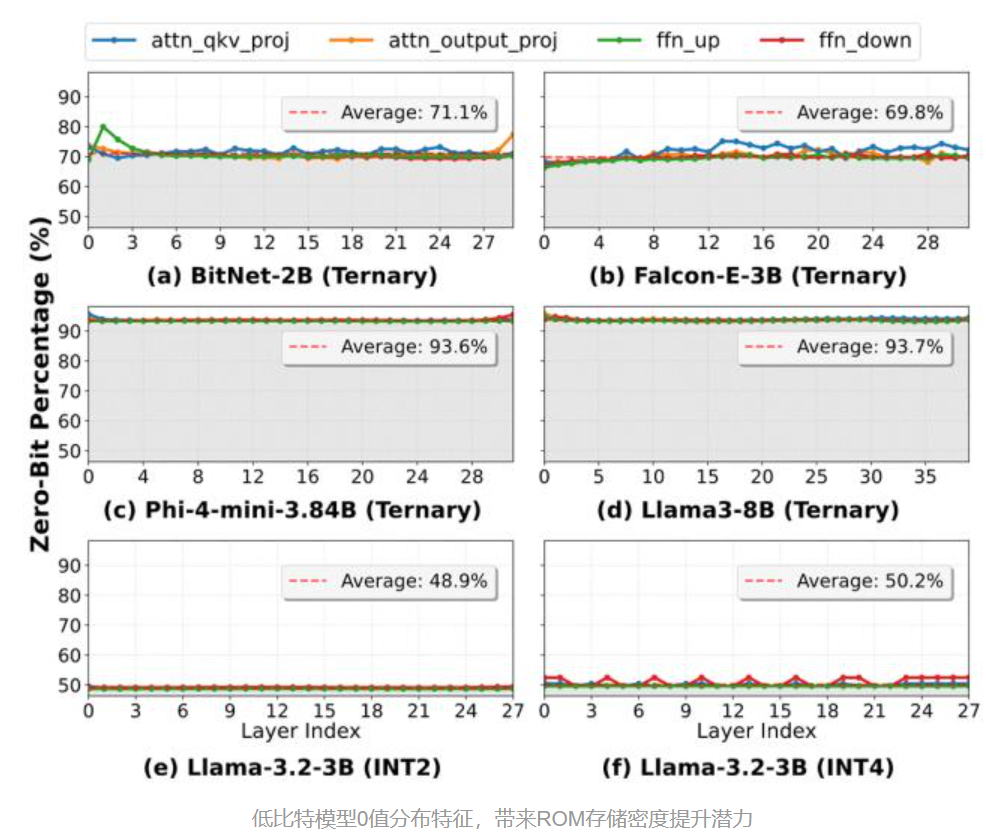
- 利用三值化权重(-1,0,1)的0值稀疏性
- 通过逻辑合成直接消除“0”的存储电路
- 存储密度比ROMA再提升数倍
应用场景:具身智能(机器人需要毫秒级确定性的“脊髓反射”)、深海/火星探测器(DRAM怕辐射,ROM天然稳定)、端侧隐私计算。
尾声
写到这,想起开头那个创业的朋友。
他说:你知道我现在最怕什么吗?不是技术跟不上,也不是融不到钱。是用户一多,内存就爆。爆一次,几十万就没了。
我说:那你怎么办?
他说:PagedAttention上了,量化在测,Mooncake还在看。实在不行,就去跟投资人讲个新故事——我们不只做大模型,我们还做KV缓存管理平台。
我说:投资人信吗?
他笑了:信不信不重要,重要的是现在谁家做推理不焦虑内存?谁焦虑,谁就得花钱。花钱,就是我们的机会。
我想了想,好像确实是这么个道理。
毕竟在Token的世界里,记忆力就是生产力,而生产力,从来都不便宜。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号