是时候学装B了——大佬们都在说的SLM是个啥?

是时候学装B了——大佬们都在说的SLM是个啥?

乐小野
发布于 2026-06-01 21:33:18
发布于 2026-06-01 21:33:18
大模型圈子里有个鄙视链:参数越大越牛,千亿是起步,万亿才算牌面。
但2026年,风向变了。一批十亿参数级别的小模型,开始在特定任务上吊打千亿巨兽。它们有个共同的名字:SLM。
【出处】
SLM(Small Language Model,小语言模型)是2026年边缘计算和端侧AI的核心关键词。
MachineLearningMastery将其定义为“参数少于100亿的语言模型,通常在10亿到70亿之间”。
2026年2月,arXiv上发布的Nanbeige4.1-3B论文展示了一个仅有30亿参数的模型,却能稳定执行高达600轮的工具调用,性能超越某些300亿参数的大模型。
【意思】
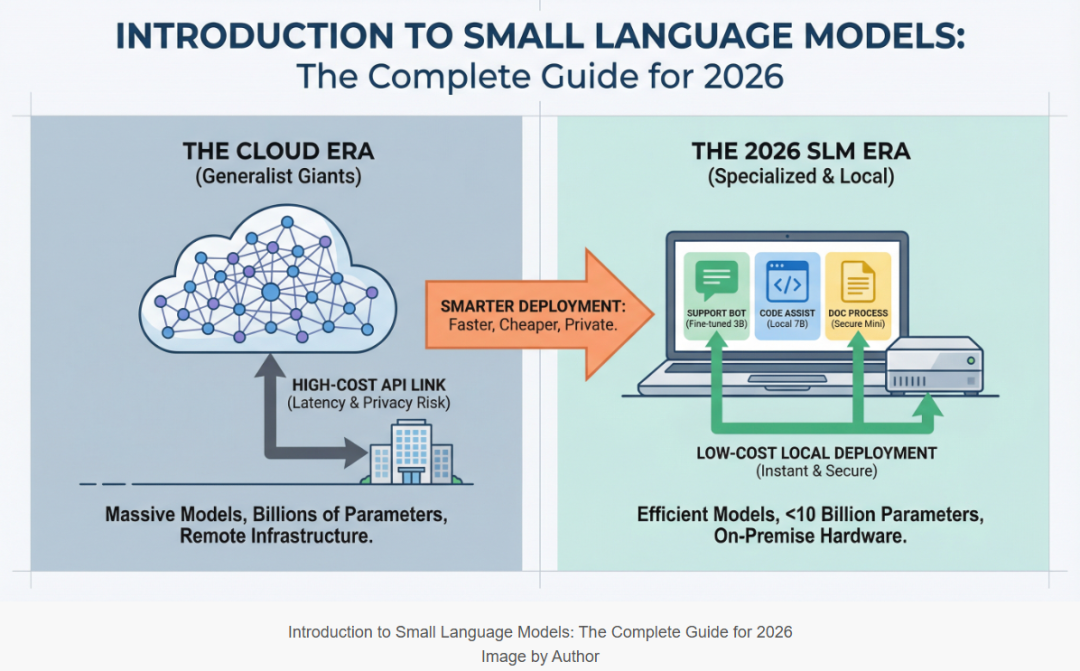
SLM不是简单的“缩水版LLM”。它是以特定任务、特定场景、特定硬件为目标设计的语言模型。
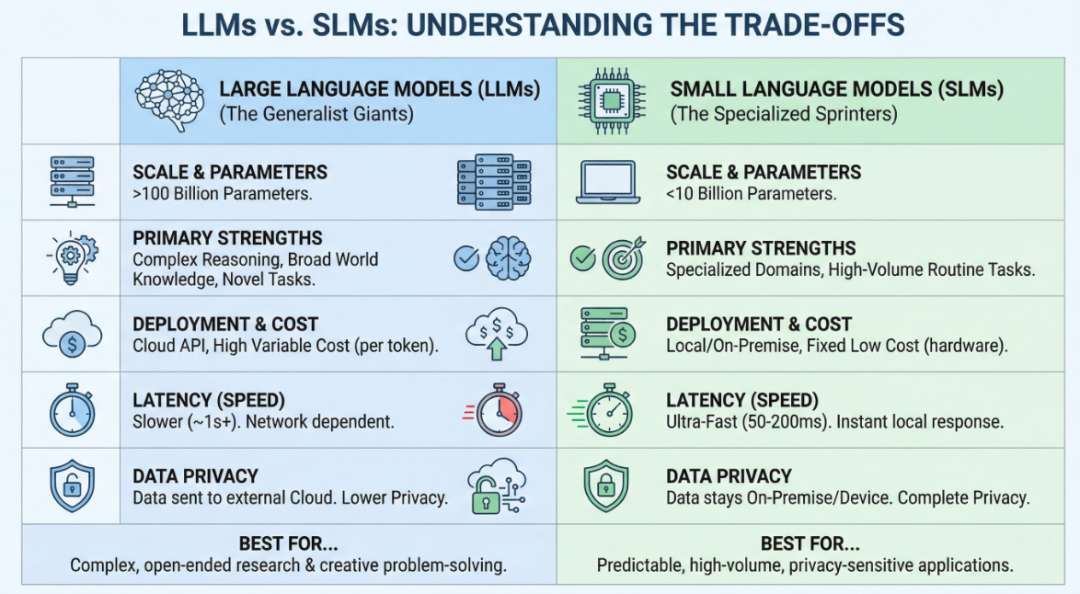
众所周知,LLM是“通才”:啥都知道,但啥都贵;SLM是“专才”:知识面窄,但在自己的一亩三分地上,又快又准又便宜。
【技术点:硬核部分来了】
1. 参数规模的再定义
SLM的典型参数范围是10亿-70亿。对比一下:
- GPT-4:超1万亿参数
- Claude Opus:数千亿
- Llama 3.1 70B:700亿(勉强算大模型的守门员)
SLM以十分之一甚至百分之一的参数,追求90%以上的任务性能。
Nanbeige4.1-3B只有30亿参数,但在复杂问题求解中,能稳定执行600轮工具调用。也就是说它可以在长达数小时的多步任务中保持“记忆”和“操作一致性”。
2. 三大核心压缩技术
SLM的高性能依赖一整套模型压缩技术:
(1)知识蒸馏(Knowledge Distillation)
让大模型当“老师”,小模型当“学生”。老师输出软标签(不仅仅是“正确/错误”,而是每个候选的概率分布),学生学习模仿老师的思考过程。
微软的Phi-3系列就是蒸馏的典型产物:从超大模型中提炼核心能力,保留90%以上的性能,体积只有5%。
(2)量化(Quantization)
把模型参数的精度从FP16(16位浮点数)压缩到INT8(8位整数)甚至INT4。
一个70亿参数的模型:
- FP16精度:需要14GB内存
- INT4量化后:只需3.5GB内存
现代量化技术如GGUF,能在压缩75%体积的同时,保留95%以上的模型质量。
(3)剪枝(Pruning)
砍掉模型中不重要的连接。神经网络的很多参数对最终输出贡献极小,剪掉它们,模型变瘦了,但精度几乎不变。
3. 训练策略的差异化
LLM的训练哲学是“数据越多越好”——把整个互联网都喂进去。SLM的训练哲学是“数据越精越好”。
Phi-3的训练数据是“教科书级”的合成数据,经过严格过滤,去除了冗余和噪声。这意味着SLM不是“见多识广”,而是“学得深、记得准”。
4. 混合架构的实践
以Nanbeige4.1-3B为例,它采用了点式+成对奖励建模(point-wise and pair-wise reward modeling)来优化推理能力和偏好对齐。
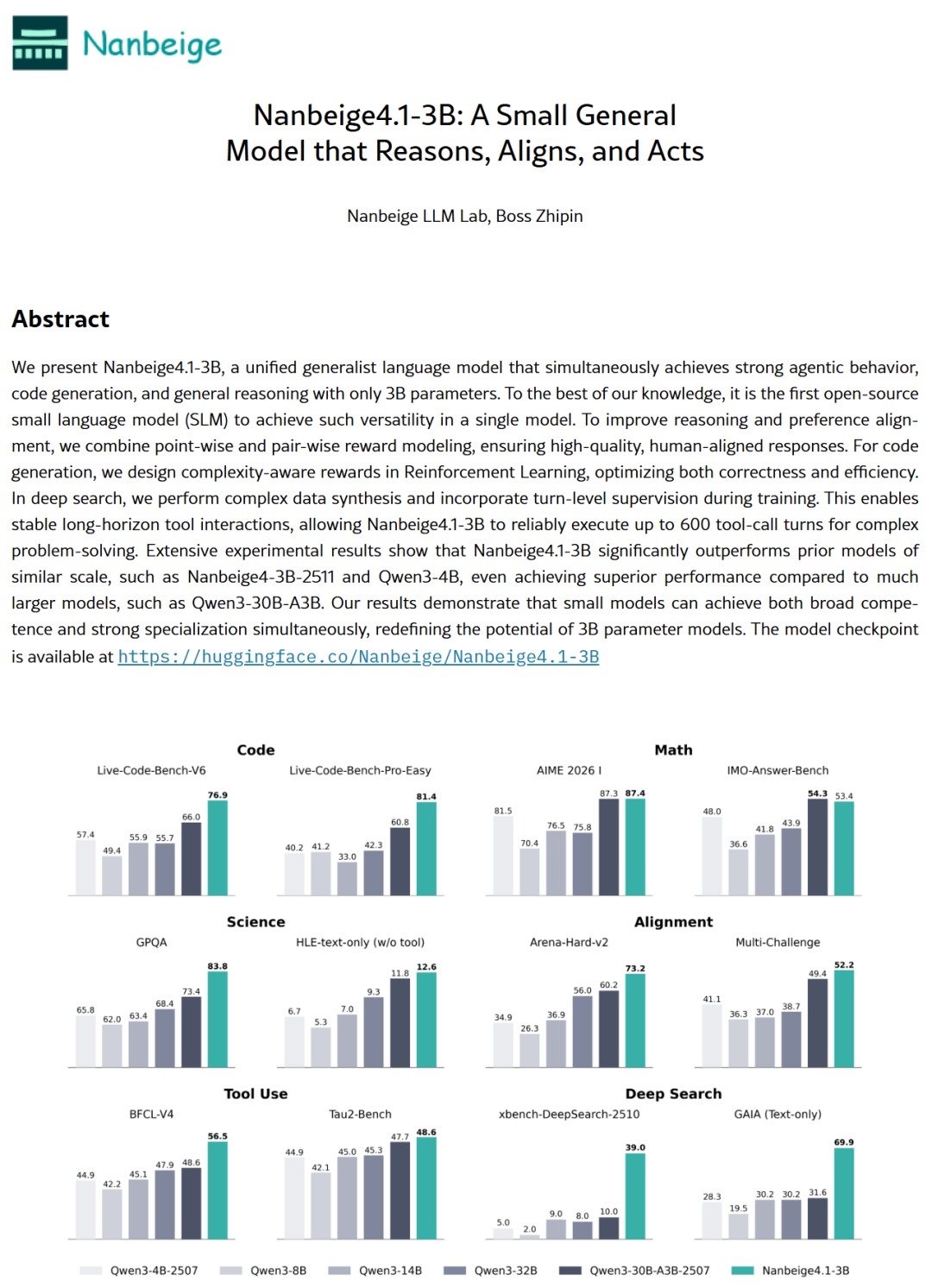
在代码生成任务中,它引入复杂度感知奖励,在强化学习阶段同时优化正确性和效率——既要代码跑得通,又要跑得快。
5. 边缘部署的极致优化
加州大学圣地亚哥分校等机构的研究表明,针对SLM的边缘部署,通过异常值感知量化框架,可以实现:
- 内存使用减少6.3倍-7.3倍
- 外部数据传输减少7.6倍
- 能耗降低11.7倍
- 延迟降低12.5倍
也就是说SLM可以跑在手机、智能音箱、车载系统上——数据不出设备、响应零延迟、隐私不外泄。
【圈内话】
SLM的崛起,可以看作是AI经济学的重构。
成本维度:一个日处理10万次客服查询的系统,用GPT-4 API月花费可能超3万美元;用SLM自部署,硬件成本一次投入,后续边际成本趋近于零。
隐私维度:医疗、金融、法律等强监管行业,不可能把敏感数据送进云端API。SLM让这些机构终于能用上AI——数据不动模型动。
混合架构正在成为主流,或许大模型界也会有个2/8分:80%的常规请求交给SLM,20%的复杂问题“升级”给LLM。这种“路由器模式”,兼顾成本和能力。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号