【论文解读】再谈Attention Residuals

【论文解读】再谈Attention Residuals

乐小野
发布于 2026-06-01 21:45:34
发布于 2026-06-01 21:45:34
写在前面
你有没有想过一个问题:Transformer里几十上百层网络,第50层做计算的时候,真的还需要第3层的原始信息吗? 现实是,不管你需不需要,残差连接都把它们等权地加在一起。就像你收拾房间,不管有用没用,所有东西都往箱子里塞。箱子越来越重,真正重要的东西反而被淹没了。 Kimi团队最近公开了一篇技术报告,决定不再忍受这种“暴力堆叠”。他们提出Attention Residuals(AttnRes),给残差连接装上一个“记忆管理器”——自己决定该从前面各层提取多少信息。想法不算新,但他们是第一个把它真正做进48B模型、跑通1.4T tokens预训练、还把推理开销控制在2%以内的团队。代码已开源。
技术报告:https://github.com/MoonshotAI/Attention-Residuals 苏剑林(共同作者)回忆录:https://kexue.fm/archives/11664
苏剑林在回忆录里写得很坦诚:“‘Depth Attention’或者说‘Layer Attention’是一个毫无新意的想法,但如何将它用于足够大的模型,作为Residuals足够强的替代品,同时还满足训练和推理的效率需求,并不是一件容易的事情”。今天我们重点看看别人改“残差”的思路。
残差连接:一个十年来没人敢动的“标准配件”
残差连接大家都不陌生,2015年何恺明在ResNet里提出,核心作用是给梯度一条“高速公路”,让深层网络能稳定训练。公式极其简单:
表面上看,每层只接收上一层的输出。但把这个递推展开,你会发现:
第50层的输入里,包含了第1层到第49层的所有输出之和,而且权重全是1——谁也不会多,谁也不会少。
这有什么问题?论文里指出一个被很多人忽视的现象:PreNorm稀释。随着层数增加,隐藏状态的模长以的速度增长,每一层新加进去的信息,相对于已经堆积如山的旧信息,占比越来越小。到后面,单层的贡献几乎可以忽略不计——这也是为什么很多实验里,把深层参数剪掉一大半,模型性能几乎不下降。
打个比方:你在开一个超长的会,每个人发言后,会议记录员不是择要记录,而是把所有人的发言稿逐字叠在一起。开到最后,记录本上全是字,但谁说了什么重点,早就分不清了。
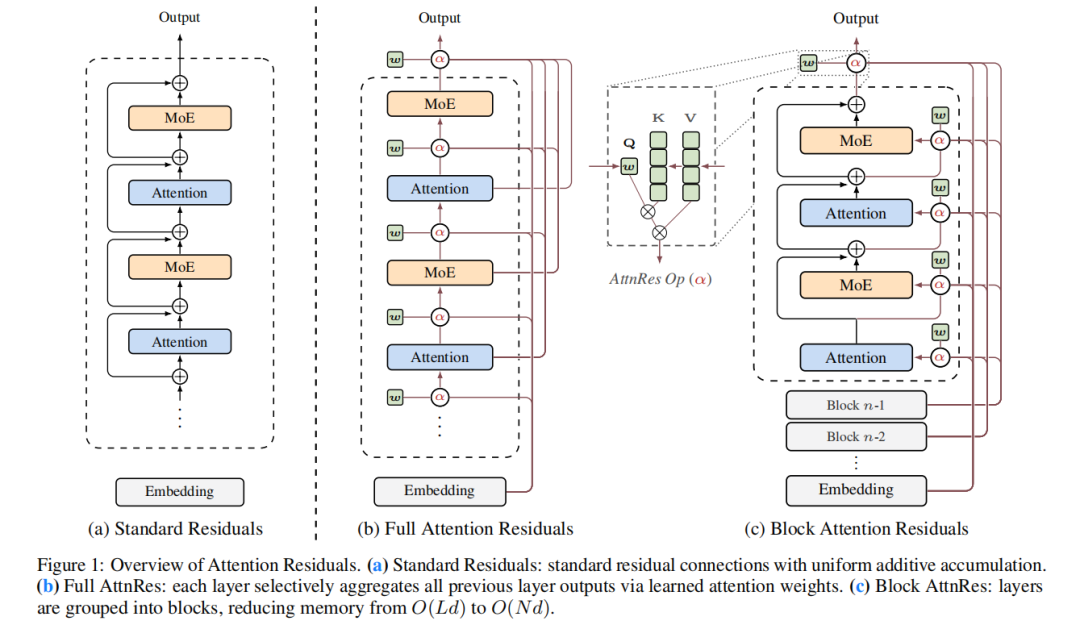
Figure 1: 标准残差 vs AttnRes 对比
▲ 原论文 Figure 1。左边是标准残差——每层只能被动接收上一层的累积状态。右边是 AttnRes——每层通过注意力机制,从前面所有层中精准选择自己需要的信息。虚线箭头,粗细不同,代表可学习的注意力权重。
把深度方向当成“序列”来处理
既然问题出在“等权相加”上,那解决方案也呼之欲出:加个注意力机制,让每层自己决定该看哪些层。
这个想法有清晰的“基因图谱”。Transformer本身就是因为注意力机制解决了RNN在时间维度上的信息压缩瓶颈,才一统江湖的。RNN把序列上所有过去信息压缩成一个固定向量,到了一定长度必然丢失细节;注意力机制把“压缩”变成了“选择性检索”——每个位置都能直接从前面任意位置提取信息。那为什么深度维度还要忍受类似的压缩?层层递推的残差连接,本质上就是把深度当成一个“单向序列”在跑。
序列上的难题用注意力解决了,深度上的同样可以。
AttnRes的核心数学非常简单。给每一层分配一个可学习的查询向量,再把前面所有层的输出当成“键-值对”。每一层用查到的相似度分数(经过softmax归一化),决定从前面各层“提取”多少信息:
注意力权重:
层输入:
新增的参数量极小——每层只多了一个 维向量和一个RMSNorm。初始化为零,训练刚开始时所有注意力权重均匀分布,等同于标准残差,不会引起训练波动。
这个设计遵循一种“奥卡姆剃刀”式的自限——参数量被控制在最小。不是因为更强的方案不存在(论文实验了更复杂的动态查询投影,也拿到了更低loss),而是因为在工程上“简洁”本身就是壁垒:更少的参数意味着更低的通信开销、更简单的并行策略,最终决定了方案能否落地到大规模训练。
AttnRes
加权求和
Embedding
注意力聚合
Layer 1输出
Layer 2输出
Layer 3输出
Layer 4输入
标准残差
+f1
+f2
+f3
Embedding
Layer 1
Layer 2
Layer 3
...
▲ 标准残差 vs AttnRes 的简化对比。AttnRes 的核心区别:每层不是只接收上一层的输出,而是从前面所有层中“选择性提取”。虚线框的宽度代表注意力权重的大小。
“块”的设计:让好想法能在大模型上跑起来
到这里,你可能觉得方案很自然——既然序列上的softmax注意力已经被广泛验证,搬到深度上有什么难的?
问题不在数学,在工程。
在大模型训练里,为了省显存,各层的中间结果通常不会全部保存在显存里——用完了就释放,需要的时候再重新计算(激活重计算)。但在Full AttnRes下,每一层需要“翻阅”前面所有层的输出,这些中间结果必须全部保留,不能释放。更要命的是,在多GPU流水线并行下,这些数据还需要跨GPU传输——通信量是,是层数,是隐藏维度。
论文给出了一个务实的折中方案:Block AttnRes。把层分成个块(比如每6层一块),块内保留原来的标准残差(等权求和),块间才用注意力机制连接。这样需要保留和传输的表示,从个降到了个。论文里用了。
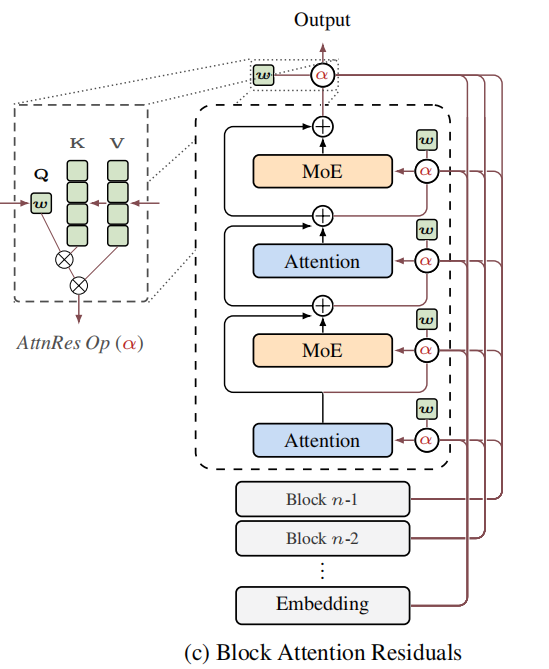
Figure 1(c): Block AttnRes 结构
▲ 原论文 Figure 1(c)。层被分成几个块(虚线框),块内仍旧是标准残差,块间通过注意力选择性聚合。这是论文工程上最关键的设计。
加权输出
块表示 b1
块表示 b2
块表示 b3
Block 3
Layer 7
Layer 8
Layer 9
Block 2
Layer 4
Layer 5
Layer 6
Block 1
Layer 1
Layer 2
Layer 3
注意力聚合
下一层
▲ Block AttnRes 的信息流。块内照旧等权求和,块间用注意力聚合。这样需要存储和传输的“记忆单元”从 L 个降到了 N 个。
论文还介绍了两项配套的系统优化:
- • 跨阶段缓存:在多GPU流水线并行中,不让GPU重复传输已经传过的块表示,而是缓存起来,只传增量的那一小部分。
- • 两阶段推理调度:推理时,先把一个块内所有层的跨块注意力批量计算(因为query在训练后固定不变,无需每一层单独访存),再顺序处理块内依赖。最终推理延迟开销不到2%。
这三板斧下来,一个“理论上行得通但实际跑不动”的想法,变成了能在大模型训练流水线里稳定运行的标准组件。
效果好不好?看这三个层面
论文从三个层层递进的层面验证了AttnRes。
第一层:规模验证——给小模型加AttnRes,等于给大模型加了25%的算力
论文在五个模型规模上(从194M到528M激活参数)做了标准的Scaling Law实验。结果很清晰:三条loss-算力曲线几乎平行,但Full AttnRes整条线都在Baseline下方,Block AttnRes夹在中间,但紧贴Full。
换算下来:相同算力下,Block AttnRes的验证loss更低;或者说,Baseline要额外投入25%的算力才能达到Block AttnRes的效果(Fig. 4)。
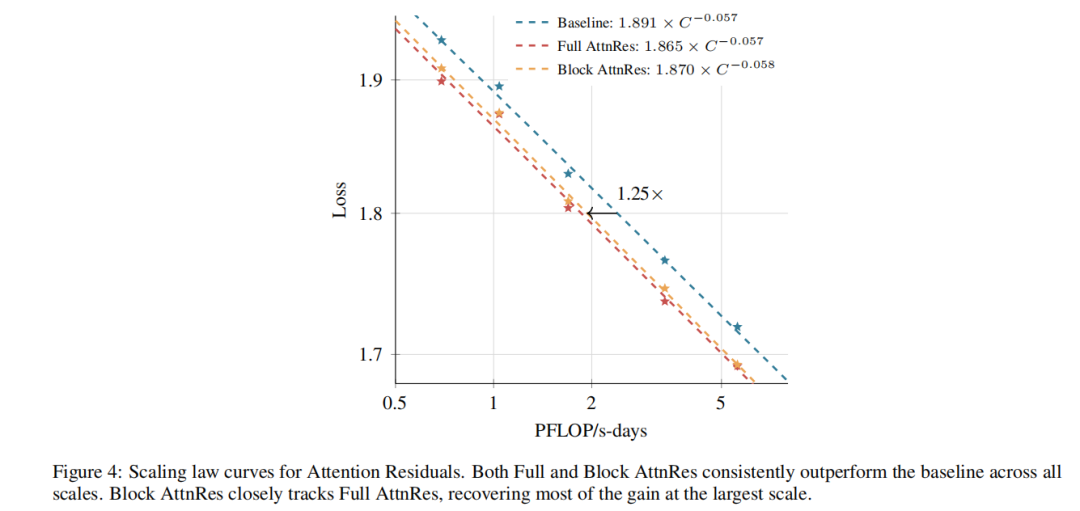
Figure 4: Scaling Law 曲线
▲ 原论文 Figure 4。横轴是训练算力(PFLOP/s-days),纵轴是验证loss。Full AttnRes(绿)和Block AttnRes(蓝虚线)整条线都在纯PreNorm Baseline(红)的下方。在最大算力处,Block AttnRes的loss(1.692)约等于Baseline用1.25倍算力才能达到的水平。
第二层:48B真刀真枪——在Kimi Linear上预训练1.4T tokens
最大的模型是Kimi Linear 48B(MoE架构,激活3B参数),训练数据1.4T tokens。Block AttnRes在全部15个下游评测中都不弱于纯PreNorm baseline。增益最大的是需要多步推理的任务:GPQA-Diamond涨了7.5个点,MATH涨了3.6个点,HumanEval涨了3.1个点。知识类任务也有稳健提升(MMLU +0.0→+1.1,TriviaQA +1.9)。
Table 3:下游性能对比(节选)
任务 | Baseline | +Block AttnRes | 提升 |
|---|---|---|---|
GPQA-Diamond | 36.9 | 44.4 | +7.5 |
MATH | 53.5 | 57.1 | +3.6 |
HumanEval | 59.1 | 62.2 | +3.1 |
MMLU | 73.5 | 73.5 | 0.0 |
BBH | 76.3 | 78.0 | +1.7 |
▲ 多步推理任务提升最高。GPQA-Diamond是研究生级别的“防谷歌”问答,需要深层逻辑链,AttnRes的跨层信息提取优势在这里最明显。
第三层:深层剖析——AttnRes到底改变了什么?
论文还分析了训练过程中,每一层的输出模长和梯度分布(Fig. 5)。
标准残差的训练动态是:越深的层,输出模长越大,增长几乎是单调的——因为后面层必须输出更大的值,才能在被稀释的信息流里刷出一点存在感。同时,最浅的几层梯度远大于中间层,因为恒等映射让误差信号几乎无衰减地传到最前面。
Block AttnRes下的训练动态完全变了:输出模长在每个block边界被“重置”,呈周期性锯齿状,整体有界。梯度在各层之间分布也更均匀——因为注意力权重引入了竞争,浅层不再靠“唯一通道”的特权获得不成比例的梯度信号。
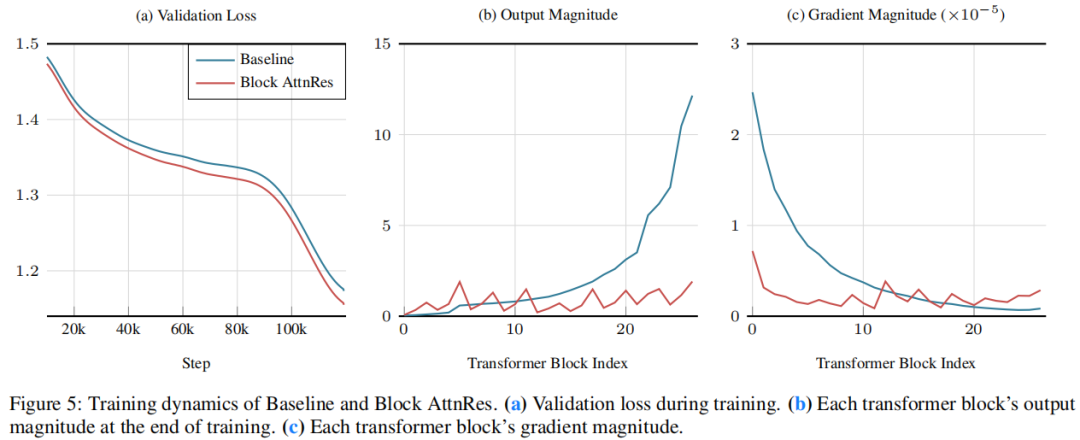
Figure 5: 训练动态对比
▲ 原论文 Figure 5(b)(c)。左为各层输出模长:标准残差(红)单调上升,Block AttnRes(蓝)在每个块边界被重置,呈锯齿形。右为梯度模长:标准残差前半段极高,AttnRes 整体平滑。这说明 AttnRes 让训练信号在深度方向上分配得更均匀。
在MoE架构里,AttnRes和专家路由是怎么分工的?
论文在Table 2的脚注中提到一个细节:所有实验模型都是MoE架构,每个token动态激活256个专家中的8个(外加1个共享专家)。MoE的专家路由在“功能维度”上实现了选择性——每个token根据自己的内容,选择最合适的专家来处理。而AttnRes在“深度维度”上实现了选择性——每一层根据自己的需求,选择最相关的浅层信息来参考。
两个机制是正交的、互补的。 一个在宽度上做选择,一个在深度上做选择。把它们叠在一起,形成了一个更完整的“选择性网络”——横向上,token知道自己该找哪些专家;纵向上,每一层知道自己该回顾哪些历史层。这种横向选择+纵向选择的组合,可能是MoE架构进一步挖潜的方向。
AttnRes: 深度方向的选择性
注意力
高权重
中权重
低权重
Layer 4
聚合模块
Layer 1 输出
Layer 3 输出
Layer 2 输出
MoE: 宽度方向的选择性
高权重
高权重
低权重
低权重
Token
Gate/Router
专家1
专家3
专家2
专家4
▲ MoE与AttnRes的分工:MoE在“选专家”(宽度),AttnRes在“选层”(深度)。两者协同,构成了更完整的选择性信息处理网络。
这个小改动,是怎么撬动整个架构设计偏好的?
论文里的Fig. 7展示了一个颇有启发性的架构搜索实验:在固定总算力和总参数下,枚举25种 (宽度-深度配比)和 (头数-深度配比)的组合,看Baseline和AttnRes分别偏好什么样的架构。
结果很有意思:Baseline的最优架构偏向“宽而浅”(),而AttnRes的最优架构偏向“深而窄”()。
这意味着,过去“Transformer不宜太深”的设计经验,有一部分其实是残差连接的“等权求和”造成的假象。一旦给深度方向加上了注意力,让信息提取不再靠蛮力堆积,更深的网络就从“负担”变成了“优势”——多出来的那些层不再是噪声源,而是可供精准检索的知识库。
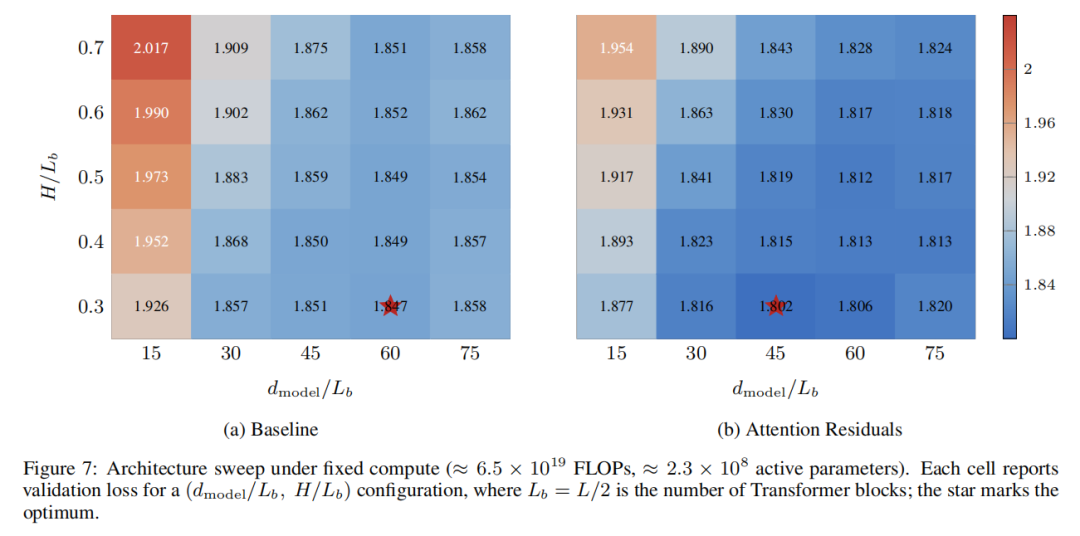
Figure 7: 架构搜索热力图
▲ 原论文 Figure 7。两张热力图分别对应 Baseline 和 AttnRes。横轴是 (注意力头数/块数比),纵轴是 (宽度/深度比)。颜色越浅 loss 越低。星标显示 Baseline 最优在 y≈60,AttnRes 最优下移到 y≈45(代表更深更窄的网络)。
当然,这篇论文明确说明这是诊断性结论,不是部署建议——更深的网络推理延迟更高,实际落地需要权衡。但它提示了一个方向:如果AttnRes让深度扩展不再是“边际收益递减”的事,那么Transformer架构的深度天花板可能会被重新定义。
注意力权重可视化:模型学会了什么?
这是整篇论文里最“看图说话”的部分。Fig. 8展示了训练完成后,每一层对前面各层的注意力权重分布。
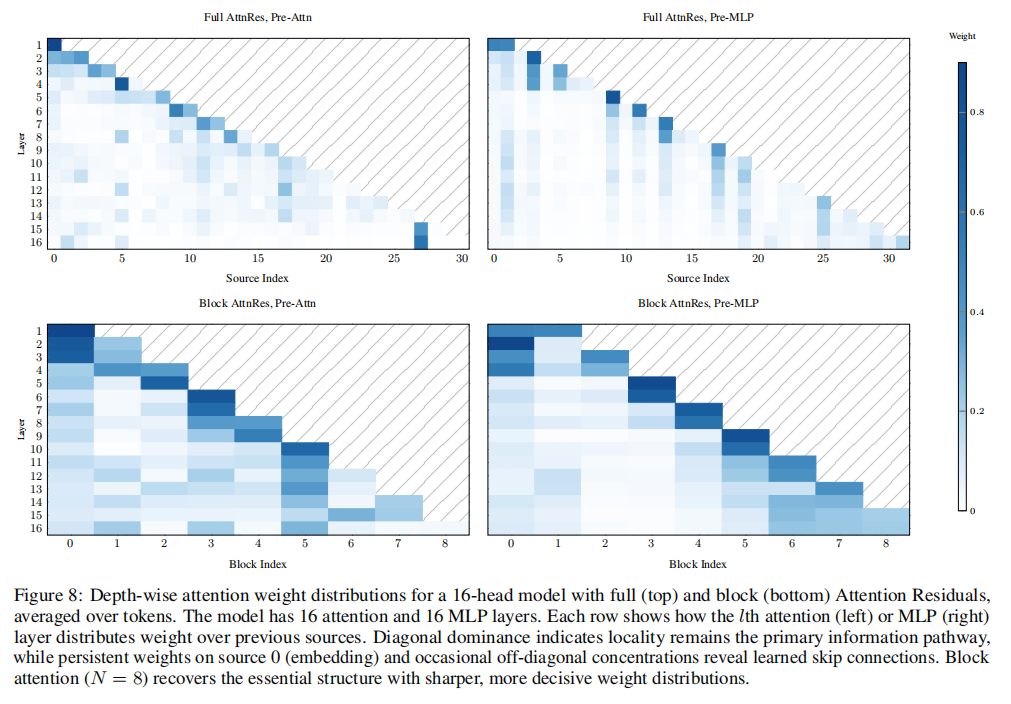
Figure 8: 注意力权重热力图
▲ 原论文 Figure 8。上半为 Full AttnRes,下半为 Block AttnRes(N=8)。横轴是源层(被参考的层),纵轴是目标层(发起参考的层)。颜色越亮,权重越大。对角线主导,但出现了几个值得注意的“远距离关注”模式。
几个值得琢磨的现象:
- • 对角线依然最亮——下一层最关注的还是紧挨着的上一层。残差连接的“近邻优先”没有被颠覆,而是被保留并增强。
- • 但某些层学会了“看远不看近”——比如Layer 4持续关注embedding层(Source 0),Layer 15-16在Block AttnRes下有明显的回望早期层的倾向。这些“远距离跳跃”不是任何人事先设定的,而是训练中自动涌现的。
- • 注意力层和MLP层的模式不同——Pre-Attention层对embedding保持持续关注,感受野更宽;Pre-MLP层更聚焦近邻,对角线更尖锐。这和直觉一致:注意力层需要全局路由信息,MLP层更偏向局部特征变换。
理论溯源:“深度-序列对偶”到底在说什么?
论文在Section 6.1谈了一个不常被讨论但很核心的理论视角:深度和序列之间存在形式上的对偶关系。
残差连接在深度上的递推:,和RNN在时间上的递推:,数学结构是一致的。
关键突破来自Test-Time Training(TTT)的视角:如果把RNN的每一次状态更新理解为对某个内部损失函数做一步梯度下降————那么当是线性变换时,这个更新恰好等价于线性注意力的加性形式。
残差连接在深度方向上恰好也满足这个结构。
搞懂了这个对偶,很多“为什么”就有答案了。为什么mHC/Hyper-Connections用多流状态增强了残差连接?因为它相当于在深度方向上做了状态扩展——把隐状态从维扩到维,增加了线性注意力在半可分矩阵下的秩。为什么AttnRes比mHC更进一步?因为它把深度方向上的线性注意力推到了softmax注意力——序列端早已完成、而深度端一直搁置的升级。
我们重新总结这条理论线索:从ResNet到mHC到AttnRes,是深度方向上“均匀聚合 → 线性注意力 → softmax注意力”的演进路径,和序列方向上“RNN → 线性Transformer → 标准Transformer”的路径完美对应。
哪些问题还没解决?论文自己怎么说
论文在结尾和消融实验里,坦诚地标记了当前方案的边界:
- • Full AttnRes的通信瓶颈:当前硬件下,的跨GPU通信量让Full AttnRes难以直接用于大模型训练。团队建议使用Block AttnRes()作为实际部署方案,同时指出随互联带宽提升,Full AttnRes的实用性会逐步改善。
- • 位置编码的作用没有统计显著:苏剑林在回忆录里提到,他们尝试过在query-key点积里加入可学习的深度位置偏置,但在当前实验规模下没有带来显著提升。他同时指出,在多模态、多任务等源层数量更多且噪声更高的场景下,位置编码可能重新变得必要。
- • 跨架构的泛化性待验证:当前只在Kimi Linear(混合KDA+MLA的MoE架构)上验证了效果。在纯Dense架构、纯SSM架构上的表现如何,还是开放问题。
- • 更深网络的相变行为:实验中的最大层数约54层。如果有几百上千层的超深网络,注意力权重的模式会不会出现新的相变?目前没有答案。
为什么整个社区十年没动残差连接,现在该动了?
标准残差连接是2015年ResNet提出来的。这之后十年,从ResNet到Transformer,从BERT到GPT-4,残差连接始终是标配,很少有人去动它的核心公式。
不是大家没看到问题。PreNorm vs PostNorm的争论持续了很多年,DeepNorm、LayerScale、ReZero、SiameseNorm等变体先后出现,但它们的共同点是:保留“等权求和”的基本范式,在范式内部打补丁。
mHC跨出了实质性的一步——用多流状态和可学习混合矩阵,让残差流不再完全均匀。但它仍然停留在线性注意力的范畴内,没有引入softmax的选择性压力。
AttnRes的意义不在于发明了什么惊人的新东西(层间注意力在文献里早有苗头),而在于它把这条线索推到了逻辑终点:深度方向的信息聚合,不应再是“被动累加”,而应是可学习的、输入相关的、有选择性的。这句话其实也是这篇技术报告最想传达的核心信息——与其在残差连接上继续打补丁,不如换个思路,把深度当成值得认真对待的信息维度来建模。
总之,它揭示了深度方向上的信息聚合还有巨大的优化空间。如果这个方向继续推进下去,我们或许能看到深度、宽度、序列三个维度的注意力机制逐渐统一,那将是Transformer架构的又一次结构性升级。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号