Browser Agent:Web 操作的自动化

Browser Agent:Web 操作的自动化

安全风信子
发布于 2026-06-02 08:23:08
发布于 2026-06-02 08:23:08
作者: HOS(安全风信子) 日期: 2026-05-24 主要来源平台: GitHub 摘要: 浏览器是开发者获取信息的重要渠道,Browser Agent 利用 AI 控制浏览器完成搜索、登录、表单填写、数据抓取等操作。本文系统讲解 Browser Agent 的实现机制,涵盖 DOM 解析、元素定位、事件模拟、页面状态管理四大核心模块,深入对比 Selenium、Playwright、Puppeteer 的架构差异与适用场景。详细阐述 CSS Selector、XPath、语义定位的定位策略,探讨加载状态、AJAX 处理、Shadow DOM 等页面状态管理难题。提供表单操作、反爬虫对抗的实战策略,最终实现一个基于 Playwright 的完整 Browser Agent 实例,赋能开发者高效构建自动化测试与信息提取系统。
目录- 1. Browser Agent 概述
- 1.1 什么是 Browser Agent
- 1.2 Browser Agent 的应用场景
- 1.3 Browser Agent 系统架构
- 2. 浏览器自动化框架对比
- 2.1 Selenium:WebDriver 协议的开创者
- 2.2 Playwright:微软的现代自动化方案
- 2.3 Puppeteer:Node.js 原生的 Chrome 自动化
- 2.4 框架综合对比
- 3. 元素定位策略
- 3.1 CSS Selector 定位
- 3.2 XPath 定位
- 3.3 语义定位
- 3.4 定位策略选择与优先级
- 4. 页面状态管理
- 4.1 页面加载状态
- 4.2 AJAX 与动态内容处理
- 4.3 Shadow DOM 处理
- 4.4 页面状态机设计
- 5. 表单操作
- 5.1 文本输入
- 5.2 选择框与下拉菜单
- 5.3 文件上传
- 5.4 表单验证与提交
- 6. 反爬虫对抗策略
- 6.1 人机验证处理
- 6.2 IP 限制与代理轮换
- 6.3 浏览器指纹与请求伪装
- 6.4 访问频率控制
- 7. Playwright Browser Agent 实践
- 7.1 Browser Agent 架构设计
- 7.2 核心实现
- 7.3 使用示例
- 7.4 高级配置与扩展
- 8. 最佳实践与性能优化
- 8.1 稳定性提升策略
- 8.2 性能优化技巧
- 8.3 工程化建议
- 9. 总结与展望
- 参考链接
- A. Browser Agent 完整代码
- B. 常用选择器速查表
- C. 常见问题排查
- 1.1 什么是 Browser Agent
- 1.2 Browser Agent 的应用场景
- 1.3 Browser Agent 系统架构
- 2.1 Selenium:WebDriver 协议的开创者
- 2.2 Playwright:微软的现代自动化方案
- 2.3 Puppeteer:Node.js 原生的 Chrome 自动化
- 2.4 框架综合对比
- 3.1 CSS Selector 定位
- 3.2 XPath 定位
- 3.3 语义定位
- 3.4 定位策略选择与优先级
- 4.1 页面加载状态
- 4.2 AJAX 与动态内容处理
- 4.3 Shadow DOM 处理
- 4.4 页面状态机设计
- 5.1 文本输入
- 5.2 选择框与下拉菜单
- 5.3 文件上传
- 5.4 表单验证与提交
- 6.1 人机验证处理
- 6.2 IP 限制与代理轮换
- 6.3 浏览器指纹与请求伪装
- 6.4 访问频率控制
- 7.1 Browser Agent 架构设计
- 7.2 核心实现
- 7.3 使用示例
- 7.4 高级配置与扩展
- 8.1 稳定性提升策略
- 8.2 性能优化技巧
- 8.3 工程化建议
本节为你提供的核心技术价值:理解 Browser Agent 的本质是连接 AI 决策层与 Web 交互层的桥梁,通过标准化协议将自然语言指令转换为精确的浏览器操作序列。
1. Browser Agent 概述
1.1 什么是 Browser Agent
Browser Agent 是一种基于人工智能的浏览器自动化控制系统,它能够模拟人类用户在浏览器中的操作行为,包括但不限于网页导航、元素交互、表单填写、内容提取等。与传统的脚本自动化工具不同,Browser Agent 具备以下核心特征:
特征 | 传统脚本自动化 | Browser Agent |
|---|---|---|
指令形式 | 预定义脚本 | 自然语言描述 |
决策能力 | 固定逻辑分支 | AI 智能决策 |
错误恢复 | 手动编写错误处理 | 自动重试与修正 |
适应性 | 需针对站点定制 | 跨站点泛化能力 |
学习能力 | 无 | 可从交互中学习 |
Browser Agent 的核心价值在于将复杂的 Web 操作封装为高级语义动作,例如"搜索 GitHub 上关于 Playwright 的热门项目"或"登录邮箱并下载最近的账单"。AI 系统理解用户的意图后,生成对应的浏览器操作序列,并通过反馈机制不断优化执行策略。
1.2 Browser Agent 的应用场景
Browser Agent 的应用范围广泛,以下是几个典型的应用场景:
信息聚合与监控:自动化抓取多个信息源的最新内容,包括新闻聚合、价格监控竞品分析、市场调研数据收集等。
端到端测试:模拟真实用户行为进行 Web 应用的完整功能测试,覆盖从登录到业务操作的完整用户流程。
表单自动填写:基于预设规则或 AI 生成的内容自动填写各种表单,如调查问卷、注册页面、申请流程等。
内容迁移与数据导出:将传统 Web 应用中的数据迁移到现代系统,或将网页内容导出为结构化数据格式。
社交媒体管理:自动化发布内容、回复评论、管理私信等社交媒体运营工作。
价格比较与抢购:监控电商平台价格变化,在符合条件的时机自动完成购买操作。
1.3 Browser Agent 系统架构
Browser Agent 的整体架构可分为四个层次:交互接口层、AI 决策层、操作执行层、浏览器引擎层。
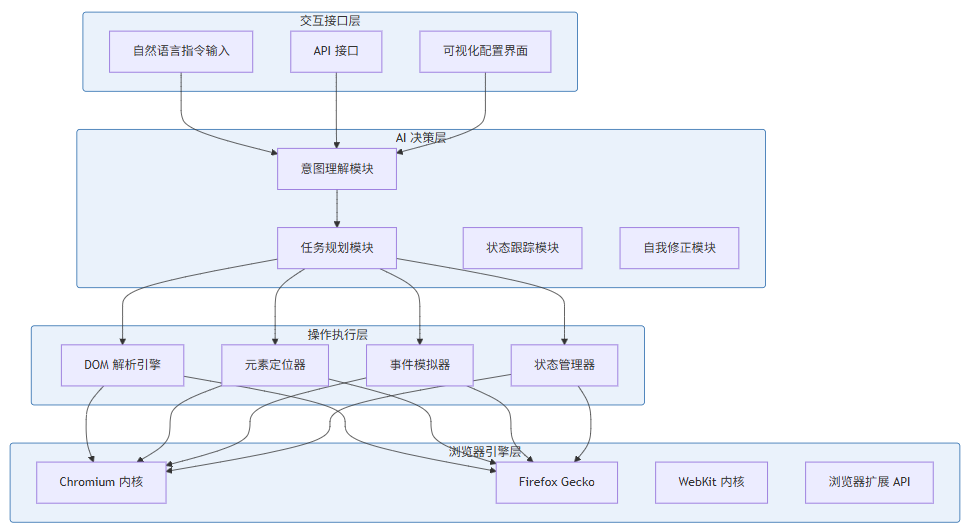
交互接口层负责接收用户的指令请求,支持自然语言描述、API 调用和可视化配置三种方式。自然语言指令通过自然语言处理技术提取关键实体和操作意图。
AI 决策层是 Browser Agent 的核心智能模块。意图理解模块解析用户指令,提取目标网站、操作类型、预期结果等关键信息。任务规划模块将高层指令分解为可执行的原子操作序列。状态跟踪模块维护当前任务执行状态和页面上下文。自我修正模块在操作失败时分析原因并生成修正策略。
操作执行层将 AI 决策转换为具体的浏览器操作。DOM 解析引擎理解页面结构,元素定位器根据多种策略定位目标元素,事件模拟器触发鼠标键盘事件,状态管理器处理页面加载和状态同步。
浏览器引擎层是最终的执行者,通过 CDP(Chrome DevTools Protocol)或类似的调试协议控制真实浏览器内核。
2. 浏览器自动化框架对比
本节为你提供的核心技术价值:深入理解 Selenium、Playwright、Puppeteer 三大框架的设计哲学、架构差异和适用场景,为项目技术选型提供决策依据。
2.1 Selenium:WebDriver 协议的开创者
Selenium 由 Jason Huggins 于 2004 年创建,最初是一个 JavaScript 测试工具。经过多年发展,Selenium 已成为 Web 自动化测试领域的工业标准。Selenium 的核心创新在于提出了 WebDriver 协议,将浏览器操作标准化为跨平台的 API。
Selenium 架构原理:
Selenium 通过 WebDriver 协议与浏览器进行通信。以 Chrome 为例,Selenium 首先启动 ChromeDriver 进程,该进程是 Chrome 浏览器的调试接口。当执行 driver.findElement(By.cssSelector("#username")) 时,Selenium 通过 HTTP 请求将命令发送给 ChromeDriver,ChromeDriver 通过 CDP 协议控制 Chrome 浏览器执行相应操作,结果通过 HTTP 响应返回。

Selenium 支持多种编程语言绑定,包括 Python、Java、JavaScript、C#、Ruby 等,这使得开发团队可以使用熟悉的语言编写自动化脚本。Selenium Grid 允许将测试分布到多台机器上并行执行,大幅缩短测试时间。
Selenium 的优势与局限:
Selenium 的主要优势在于其广泛的浏览器支持和成熟的生态系统。截至 2024 年,Selenium 支持 Chrome、Firefox、Edge、Safari、Opera 等主流浏览器,覆盖率接近 100%。Selenium IDE 提供可视化录制功能,非程序员也能快速创建自动化脚本。
然而,Selenium 也存在明显局限。由于采用 HTTP 协议通信,Selenium 的操作延迟较高,每秒最多执行 10-20 个操作。Selenium 不支持对现代 Web 应用的深度交互,如 Service Worker、WebSocket 实时通信、复杂动画等。此外,Selenium 需要单独安装浏览器驱动程序,版本管理复杂。
2.2 Playwright:微软的现代自动化方案
Playwright 由 Microsoft 于 2020 年发布,是一款专为现代 Web 应用设计的浏览器自动化框架。Playwright 在架构设计上针对现代 Web 特性进行了深度优化,解决了 Selenium 的多项痛点。
Playwright 架构原理:
Playwright 直接通过 CDP(Chrome DevTools Protocol)连接浏览器,无需中间驱动程序。这种直接连接方式带来两个显著优势:延迟极低(毫秒级),支持 CDP 的全部特性(如网络拦截、浏览器扩展、前端性能分析等)。
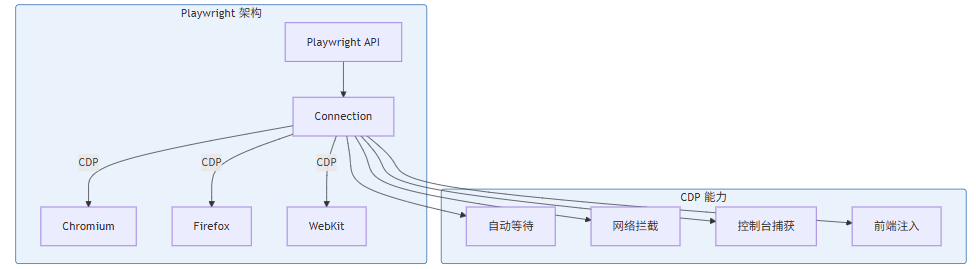
Playwright 的核心特性是自动等待机制。传统的自动化框架需要开发者手动设置固定等待时间,而 Playwright 会自动检测元素的可操作性状态(如可见、启用、可点击),只有在元素满足条件后才执行操作。这大幅降低了测试的不稳定性。
# Playwright 自动等待示例
async def test_login(page):
await page.goto("https://example.com/login")
# Playwright 自动等待 #username 元素可见并可交互
await page.fill("#username", "testuser")
await page.fill("#password", "password123")
await page.click("button[type='submit']")
# 自动等待导航完成
await page.wait_for_url("**/dashboard")Playwright 的独特能力:
Playwright 支持跨域 iframe 操作,能够穿透多层 iframe 结构直接定位元素。对于 Shadow DOM,Playwright 提供专门的 page.locator("::-p-ashadow") 伪元素选择器。对于移动端场景,Playwright 支持模拟触摸事件、地理位置、设备方向等移动端特有交互。
Playwright 还提供视频录制功能,能够记录完整的测试执行视频,方便调试和回归分析。其 Trace Viewer 工具可以保存和回放测试执行的完整状态,包括截图、控制台日志、网络请求等。
2.3 Puppeteer:Node.js 原生的 Chrome 自动化
Puppeteer 由 Google Chrome 团队开发,于 2017 年发布。Puppeteer 的设计理念是提供最原生的 Chrome 控制能力,所有功能都围绕 Chrome 浏览器的 CDP 协议展开。
Puppeteer 架构原理:
Puppeteer 直接使用 Node.js 的 HTTP 客户端连接 Chrome 的调试端口,无需任何中间进程。这种极简架构使得 Puppeteer 能够完全发挥 CDP 协议的能力,包括获取浏览器性能数据、拦截和修改网络请求、注入前端代码等。
// Puppeteer 核心架构示例
const puppeteer = require('puppeteer');
(async () => {
// 启动浏览器,暴露调试端口
const browser = await puppeteer.launch({
headless: true,
args: ['--remote-debugging-port=9222']
});
// 通过 CDP 连接浏览器
const browserWSEndpoint = browser.wsEndpoint();
// 创建页面
const page = await browser.newPage();
// 拦截网络请求
await page.setRequestInterception(true);
page.on('request', request => {
if (request.url().includes('analytics')) {
request.abort(); // 屏蔽分析请求
} else {
request.continue();
}
});
await page.goto('https://example.com');
await browser.close();
})();Puppeteer 与 Chrome 团队的关系:
由于 Puppeteer 由 Chrome 团队直接维护,它总是能够第一时间获得 Chrome 新特性的支持。例如,当 Chrome 推出新的 CDP 命令时,Puppeteer 通常在一周内就会提供对应的 Node.js API。这种紧密关系使 Puppeteer 成为需要最新浏览器特性的场景的最佳选择。
2.4 框架综合对比
特性 | Selenium | Playwright | Puppeteer |
|---|---|---|---|
首次发布 | 2004 | 2020 | 2017 |
维护方 | 开源社区 | Microsoft | Google Chrome |
核心协议 | WebDriver | CDP | CDP |
浏览器支持 | 全系列 | Chromium/Firefox/WebKit | Chromium only |
语言绑定 | 多语言 | 多语言 | Node.js |
自动等待 | ❌ 需手动 | ✅ 原生支持 | ❌ 需手动 |
执行速度 | 慢 | 快 | 快 |
Shadow DOM | 有限支持 | 原生支持 | 原生支持 |
移动端模拟 | 有限 | 完整支持 | 有限 |
社区生态 | 非常成熟 | 快速发展 | 成熟 |
选型建议:
- 选择 Selenium:现有项目需要跨浏览器支持、团队熟悉 Selenium 技术栈、需要与 TestNG/JUnit 集成
- 选择 Playwright:新项目需要现代 Web 特性、需要同时支持多浏览器、移动端 Web 测试、性能要求高
- 选择 Puppeteer:仅需 Chrome 控制、需要 Chrome 特有的 CDP 功能、Node.js 技术栈、追求最新特性支持
3. 元素定位策略
本节为你提供的核心技术价值:掌握 CSS Selector、XPath 和语义定位三大定位策略,能够根据页面结构特点选择最优定位方案,构建稳定可靠的元素定位体系。
3.1 CSS Selector 定位
CSS Selector 是 Web 开发中最常用的元素定位方式,也是 Browser Agent 的首选定位策略。CSS Selector 语法简洁、性能优异,在所有主流浏览器中都有良好的支持。
基础选择器:
选择器类型 | 语法 | 示例 | 说明 |
|---|---|---|---|
ID 选择器 | #id | #username | 定位 id 属性为 username 的元素 |
类选择器 | .class | .btn-primary | 定位 class 包含 btn-primary 的元素 |
标签选择器 | tag | input | 定位所有 input 元素 |
属性选择器 | [attr=value] | [type="text"] | 定位属性完全匹配的元素 |
通配符 | * | * | 匹配所有元素 |
组合选择器:
/* 后代选择器:匹配 form 内的所有 input */
form input
/* 子选择器:匹配 form 的直接子元素 input */
form > input
/* 相邻兄弟选择器:匹配 label 后的 input */
label + input
/* 通用兄弟选择器:匹配 label 后的所有 input */
label ~ input
/* 复合选择器:匹配 type 为 text 的 username 输入框 */
input[type="text"][id="username"]
/* 否定选择器:匹配非禁用状态的按钮 */
button:not([disabled])Playwright 中的 CSS Selector 增强:
Playwright 扩展了标准 CSS Selector,提供了网页抓取场景中常用的伪元素选择器:
# Playwright 扩展选择器示例
await page.locator("::-p-ashadow").click() # Shadow DOM 选择器
await page.locator("::-p-text(/close/i)").click() # 文本内容选择器
await page.locator("::-p-before(content)").click() # ::before 伪元素3.2 XPath 定位
XPath(XML Path Language)是一种用于定位 XML 文档中节点的语言,同样适用于 HTML 文档。XPath 提供轴(Axis)和谓词(Predicate)两大高级特性,使其能够表达 CSS Selector 难以实现的定位逻辑。
基础轴与路径:
轴名称 | 说明 | 示例 |
|---|---|---|
self | 当前节点 | self::input |
parent | 父节点 | parent::* |
child | 子节点 | child::div |
descendant | 后代节点 | descendant::span |
ancestor | 祖先节点 | ancestor::form |
following-sibling | 后续兄弟节点 | following-sibling::button |
preceding-sibling | 前置兄弟节点 | preceding-sibling::label |
谓词条件:
<!-- 定位第一个 td -->
td[1]
<!-- 定位包含特定文本的 a 标签 -->
a[contains(text(), '查看详情')]
<!-- 定位具有多个属性的 input -->
input[@type='text' and @name='email']
<!-- 定位父元素下的第二个子元素 -->
div[2]/input
<!-- 定位倒数第一个 tr -->
tr[last()]
<!-- 定位非隐藏的 tr -->
tr[not(@hidden)]XPath vs CSS Selector:
维度 | XPath | CSS Selector |
|---|---|---|
语法复杂度 | 较复杂 | 简洁 |
执行性能 | 较慢(浏览器需额外解析) | 快(浏览器原生支持) |
文本匹配 | ✅ 支持 contains() | ❌ 不支持 |
兄弟节点 | ✅ 支持前后兄弟轴 | ⚠️ 仅支持相邻兄弟 |
节点类型 | 元素、属性、文本等 | 仅元素 |
可读性 | 较低 | 较高 |
实战 XPath 技巧:
# 文本匹配:定位包含"登录"文本的按钮
xpath = "//button[contains(text(), '登录')]"
# 模糊匹配:定位 title 包含"邮箱"的 div
xpath = "//div[contains(@title, '邮箱')]"
# 逻辑或:定位 type 为 submit 或 button 的元素
xpath = "//input[@type='submit' or @type='button']"
# 层级穿越:跳过中间节点定位深层元素
xpath = "//form//table//tr[3]//input[@name='data']"
# 组合定位:先按文本定位父元素,再找兄弟元素
xpath = "//span[text()='用户名']/following-sibling::input"3.3 语义定位
语义定位是一种高级定位策略,它不依赖于页面的 DOM 结构,而是根据元素的语义角色和可访问性属性进行定位。这种策略对页面结构变化具有很强的鲁棒性,是构建智能 Browser Agent 的关键技术。
可访问性属性定位:
现代 Web 应用遵循 WAI-ARIA(Web Accessibility Initiative - Accessible Rich Internet Applications)规范,定义了语义化的角色(role)、状态(state)和属性(property)。
# Playwright 语义定位示例
# 定位角色为 button 的元素
await page.locator("role=button").click()
# 定位角色为 dialog 的模态框
modal = page.locator("role=dialog")
# 定位 name 为 "Search" 的搜索框
search_input = page.locator("role=searchbox[name='Search']")
# 定位带有 checked 状态的 checkbox
checked_box = page.locator("role=checkbox[checked]")ARIA 属性详解:
ARIA 属性 | 说明 | 示例 |
|---|---|---|
role | 元素角色 | role="button", role="navigation" |
aria-label | 可访问标签 | aria-label="关闭" |
aria-labelledby | 关联标签 ID | aria-labelledby="title-id" |
aria-describedby | 关联描述 ID | aria-describedby="hint-id" |
aria-expanded | 展开状态 | aria-expanded="true" |
aria-hidden | 隐藏状态 | aria-hidden="true" |
标签内容语义定位:
# 定位按钮文本为"提交"的元素
await page.get_by_role("button", name="提交").click()
# 定位 placeholder 为"输入邮箱"的输入框
await page.get_by_placeholder("输入邮箱").fill("user@example.com")
# 定位 alt 文本为"logo"的图片
await page.get_by_alt_text("logo").click()
# 定位 title 属性为"设置"的元素
await page.get_by_title("设置").click()
# 定位 testid 属性为 login-button 的元素
await page.get_by_test_id("login-button").click()3.4 定位策略选择与优先级
构建稳定的 Browser Agent 需要建立合理的定位策略优先级体系。以下是经过实践验证的推荐顺序:
第一优先级:语义定位
# 最佳实践:优先使用语义定位
# 理由:对页面结构变化鲁棒,代码可读性高
await page.get_by_role("button", name="登录").click()
await page.get_by_label("用户名").fill("admin")第二优先级:测试 ID 定位
# 测试 ID 通常由开发团队维护,稳定性较高
await page.get_by_test_id("checkout-button").click()第三优先级:CSS ID/类选择器
# ID 定位性能最优,但需确保 ID 唯一性
await page.locator("#main-form").submit()
# 类选择器适合定位同类型元素组
await page.locator(".menu-item").first.click()第四优先级:XPath
# XPath 用于复杂层级关系或文本匹配场景
await page.locator("xpath=//table//tr[last()]//button").click()定位器组合策略:
class SmartLocator:
"""智能定位器:根据页面特征自动选择最优定位策略"""
def __init__(self, page):
self.page = page
def find_login_form(self):
"""智能定位登录表单"""
# 策略1:ARIA 角色定位
if locator := self.page.get_by_role("form", name=re.compile("登录|login", re.I)):
return locator
# 策略2:ID 定位
if locator := self.page.locator("#login-form, #LoginForm, #frmLogin"):
return locator
# 策略3:XPath 文本匹配
return self.page.locator("xpath=//form[.//button[contains(text(), '登录')]]")
def find_submit_button(self, parent_locator):
"""在父元素内智能定位提交按钮"""
return parent_locator.get_by_role("button", name=re.compile("提交|确定|submit", re.I))4. 页面状态管理
本节为你提供的核心技术价值:解决页面加载、AJAX 异步请求、Shadow DOM 等现代 Web 特性带来的状态管理难题,构建可靠的页面状态同步机制。
4.1 页面加载状态
浏览器页面的加载过程涉及多个阶段的资源获取和渲染,理解这些阶段对于正确处理页面状态至关重要。
页面加载阶段:
阶段 | 说明 | Playwright 事件 | 检测时机 |
|---|---|---|---|
domcontentloaded | DOM 树构建完成 | DOMContentLoaded | CSS/JS 加载完成,图片可能未加载 |
load | 所有资源加载完成 | load | 所有资源包括图片都加载完成 |
networkidle | 网络请求结束 | networkidle | 无网络活动持续 500ms |
commit | 导航提交 | commit | 初始导航开始 |
等待策略:
# 策略1:等待 load 事件(保守但可靠)
await page.goto("https://example.com", wait_until="load")
# 策略2:等待 DOMContentLoaded(更快)
await page.goto("https://example.com", wait_until="domcontentloaded")
# 策略3:等待网络空闲(适合动态内容)
await page.goto("https://example.com", wait_until="networkidle")
# 策略4:自定义等待条件
await page.goto("https://example.com")
await page.wait_for_function("document.querySelector('#app')._isReady")多阶段加载检测:
async def wait_for_app_ready(page: Page):
"""等待应用完全就绪"""
# 等待基本 DOM 加载
await page.wait_for_load_state("domcontentloaded")
# 等待特定元素出现
await page.wait_for_selector("#app", state="attached")
# 等待应用初始化完成
await page.wait_for_function(
"""() => {
const app = document.querySelector('#app');
return app && app.dataset.ready === 'true';
}""",
timeout=30000
)
# 额外等待动画完成
await page.wait_for_timeout(500)4.2 AJAX 与动态内容处理
现代 Web 应用大量使用 AJAX(Asynchronous JavaScript and XML)技术实现无刷新更新,这给 Browser Agent 带来了挑战:操作完成后,页面可能仍在异步加载数据。
网络请求拦截与等待:
# Playwright 网络拦截示例
async def wait_for_api_response(page: Page, url_pattern: str):
"""等待特定 API 返回成功响应"""
response = await page.wait_for_response(
lambda r: re.match(url_pattern, r.url) and r.status in [200, 201],
timeout=10000
)
return response
# 使用示例:等待搜索 API 返回
async with page.expect_response(r"**/api/search\?q=.*") as response_info:
await page.click("#search-btn")
response = await response_info.value
data = await response.json()请求完成检测:
# 方法1:等待函数执行结果变化
async def wait_for_data_update(page: Page):
await page.wait_for_function(
"""() => {
const counter = document.querySelector('#result-count');
return counter && parseInt(counter.textContent) > 0;
}"""
)
# 方法2:监听自定义事件
async def wait_for_custom_event(page: Page):
async with page.expect_event("dataLoaded"):
await page.evaluate("""() => {
document.addEventListener('dataReady', () => {
window.dispatchEvent(new CustomEvent('dataLoaded'));
});
}""")
# 方法3:轮询检查数据模型
async def wait_for_condition(page: Page, condition_fn, timeout=30000):
start = time.time()
while time.time() - start < timeout:
result = await page.evaluate(condition_fn)
if result:
return True
await page.wait_for_timeout(100)
raise TimeoutError(f"Condition not met within {timeout}ms")请求失败处理:
async def robust_api_call(page: Page, url: str, max_retries: int = 3):
"""带重试机制的 API 调用"""
for attempt in range(max_retries):
try:
response = await page.request.get(url)
if response.ok:
return response
# 非成功状态码,重试
logging.warning(f"Attempt {attempt + 1} failed: {response.status}")
except APIError as e:
logging.warning(f"Attempt {attempt + 1} exception: {e}")
if attempt < max_retries - 1:
await page.wait_for_timeout(1000 * (attempt + 1)) # 指数退避
raise APIError(f"Failed after {max_retries} attempts")4.3 Shadow DOM 处理
Shadow DOM 是 Web Components 规范的一部分,允许开发者封装独立的 DOM 树和样式。传统的自动化工具很难穿透 Shadow DOM,而 Playwright 提供了原生支持。
Shadow DOM 工作原理:
Shadow DOM 创建一个封闭的 DOM 子树,外部样式无法直接影响 Shadow DOM 内部的元素,反之亦然。每个 Shadow DOM 都有一个 shadowRoot 根节点,元素通过 attachShadow() 方法创建。
<!-- Shadow DOM 示例 -->
<my-component>
#shadow-root (open)
<div class="inner">Shadow Content</div>
</my-component>Playwright 穿透 Shadow DOM:
# 方法1:使用 Playwright 的 Shadow DOM 选择器
await page.locator("my-component >> ::p-ashadow >> .inner").click()
# 方法2:链式 shadow() 方法
await page.locator("my-component").locator(
page.locator(".inner", has=page.locator("..", has=page.locator(":scope"))
).locator(":scope", has_text="Shadow Content")
).click()
# 方法3:JavaScript 递归穿透
async def shadow_click(page: Page, selector: str):
"""通过 JS 穿透 Shadow DOM 点击元素"""
await page.evaluate("""(sel) => {
const findInShadow = (root, selector) => {
const result = root.querySelector(selector);
if (result) return result;
const shadows = root.querySelectorAll('*');
for (const el of shadows) {
if (el.shadowRoot) {
const found = findInShadow(el.shadowRoot, selector);
if (found) return found;
}
}
return null;
};
const el = findInShadow(document, sel);
if (el) el.click();
}""", selector)嵌套 Shadow DOM 处理:
async def deep_shadow_query(page: Page, path: list):
"""
穿透多层嵌套的 Shadow DOM
path: Shadow DOM 标签路径,如 ['my-app', 'user-panel', 'settings-form']
"""
js_code = """([...path]) => {
const getShadowHost = (element) => {
return element.parentNode;
};
let current = document;
for (const tag of path) {
let found = false;
const walkShadow = (root) => {
const el = root.querySelector(tag);
if (el) {
current = el;
found = true;
return true;
}
const all = root.querySelectorAll('*');
for (const e of all) {
if (e.shadowRoot && walkShadow(e.shadowRoot)) {
found = true;
return true;
}
}
return false;
};
if (found) {
if (current.shadowRoot) {
current = current.shadowRoot;
}
} else {
return null;
}
}
return current;
}"""
return await page.evaluate(js_code, path)4.4 页面状态机设计
一个健壮的 Browser Agent 应该将页面状态管理抽象为状态机,确保操作只在正确的状态下执行。
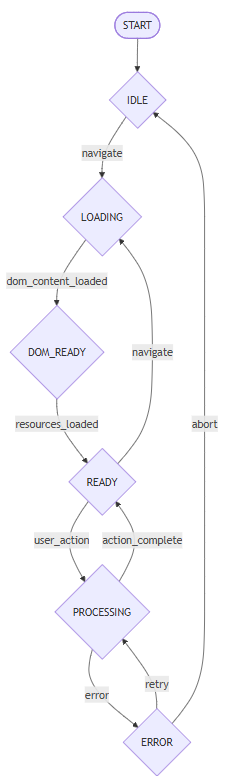
状态机实现:
from enum import Enum, auto
from dataclasses import dataclass, field
from typing import Callable, Optional
import asyncio
class PageState(Enum):
IDLE = auto()
LOADING = auto()
DOM_READY = auto()
READY = auto()
PROCESSING = auto()
ERROR = auto()
@dataclass
class StateTransition:
from_state: PageState
to_state: PageState
trigger: Callable
condition: Optional[Callable] = None
timeout: float = 30.0
class PageStateMachine:
"""页面状态机管理器"""
def __init__(self, page: Page):
self.page = page
self.state = PageState.IDLE
self.state_history: list[tuple[float, PageState]] = []
self.listeners: dict[PageState, list[Callable]] = {}
# 绑定页面事件监听
self._setup_listeners()
def _setup_listeners(self):
"""设置页面事件监听"""
self.page.on("domcontentloaded", lambda: self._on_dom_content_loaded())
self.page.on("load", lambda: self._on_load())
self.page.on("requestfailed", lambda: self._on_request_failed())
async def _on_dom_content_loaded(self):
await self._transition(PageState.DOM_READY)
async def _on_load(self):
await self._transition(PageState.READY)
async def _on_request_failed(self):
if self.state != PageState.ERROR:
await self._transition(PageState.ERROR)
async def _transition(self, new_state: PageState):
old_state = self.state
self.state = new_state
self.state_history.append((asyncio.get_event_loop().time(), new_state))
# 触发状态变更监听器
if new_state in self.listeners:
for callback in self.listeners[new_state]:
await callback(old_state, new_state)
def on_state_change(self, state: PageState, callback: Callable):
"""注册状态变更监听器"""
if state not in self.listeners:
self.listeners[state] = []
self.listeners[state].append(callback)
async def wait_for_state(self, target_state: PageState, timeout: float = 30.0):
"""等待达到目标状态"""
if self.state == target_state:
return
event = asyncio.Event()
def listener(old, new):
if new == target_state:
event.set()
self.on_state_change(target_state, listener)
try:
await asyncio.wait_for(event.wait(), timeout)
except asyncio.TimeoutError:
raise TimeoutError(f"Timeout waiting for state {target_state}")
async def execute_with_state_guard(self, action: Callable):
"""在正确状态下执行操作"""
await self.wait_for_state(PageState.READY)
await self._transition(PageState.PROCESSING)
try:
result = await action()
await self._transition(PageState.READY)
return result
except Exception as e:
await self._transition(PageState.ERROR)
raise5. 表单操作
本节为你提供的核心技术价值:掌握表单填写的各种技术细节,包括文本输入、选择框、下拉菜单、文件上传、特殊输入类型等场景的处理方案。
5.1 文本输入
文本输入是最常见的表单操作,但现代 Web 应用中的输入框往往包含复杂的验证逻辑和交互行为。
基础文本输入:
# 基础 fill 方法 - 直接设置值(触发输入事件)
await page.fill("#username", "admin")
# type 方法 - 模拟逐字符输入(触发 keydown/keyup/input 事件)
await page.locator("#username").press_sequentially("admin", delay=50)
# 清除后输入
await page.locator("#username").clear()
await page.locator("#username").type("admin")特殊输入类型处理:
输入类型 | 特征 | 处理方式 |
|---|---|---|
<input type="email"> | 邮箱格式验证 | 使用 fill,设置标准邮箱格式 |
<input type="password"> | 密码隐藏显示 | 使用 fill,支持特殊字符 |
<input type="number"> | 数字输入,可有范围限制 | 使用 fill 或 step_up/step_down |
<input type="date"> | 日期选择器 | 使用 fill(“2024-01-15”) |
<input type="color"> | 颜色选择器 | 使用 fill(“#ff0000”) |
<textarea> | 多行文本 | 使用 fill 或 press_sequentially |
# 日期输入
await page.fill('input[type="date"]', "2024-06-15")
# 邮箱输入(带验证)
await page.fill('input[type="email"]', "user@example.com")
# 数字输入(带步进)
number_input = page.locator('input[type="number"]')
await number_input.fill("10")
# 或使用步进按钮
await number_input.click()
await page.keyboard.press("ArrowUp") # 加1
await page.keyboard.press("ArrowDown") # 减1
# 特殊字符输入
await page.locator("#bio").fill("John <script>alert('xss')</script>")
# 如果需要转义
await page.locator("#bio").fill("第一行\n第二行")富文本编辑器处理:
# 方法1:ContentEditable div
await page.evaluate("""() => {
const editor = document.querySelector('#editor');
editor.innerHTML = '<p>Hello <strong>World</strong></p>';
editor.dispatchEvent(new Event('input', { bubbles: true }));
}""")
# 方法2:使用 Playwright 的 contenteditable 支持
await page.locator("#editor").fill("<p>Hello World</p>")
# 方法3:模拟粘贴
await page.locator("#editor").click()
await page.keyboard.press("Control+A")
await page.keyboard.type("Pasted content")5.2 选择框与下拉菜单
复选框(Checkbox):
# 单个复选框
await page.check("#agree-terms") # 选中
await page.uncheck("#agree-terms") # 取消选中
await page.check("#agree-terms", force=True) # 强制选中(跳过状态检查)
# 检查状态
is_checked = await page.is_checked("#agree-terms")
# 切换状态
if await page.is_checked("#agree-terms"):
await page.uncheck("#agree-terms")
else:
await page.check("#agree-terms")单选框(Radio):
# 选择单选框
await page.check('input[name="gender"][value="male"]')
# 通过标签定位
await page.check("label:has-text('男') >> input[type='radio']")
# 获取当前选中值
selected = await page.locator('input[name="gender"]:checked').get_attribute("value")下拉菜单(Select):
# 标准下拉菜单
await page.select_option("#country", "CN") # 按值选择
await page.select_option("#country", label="中国") # 按标签选择
await page.select_option("#country", index=1) # 按索引选择
# 多选下拉菜单
await page.select_option("#languages", ["Python", "JavaScript"])
# 获取所有选项
options = await page.locator("#country option").all_text_contents()
values = await page.locator("#country option").all()自定义下拉菜单:
许多现代 Web 应用使用自定义下拉菜单而非原生 <select> 元素,这需要特殊处理:
async def select_custom_option(page: Page, dropdown_selector: str, option_text: str):
"""处理自定义下拉菜单"""
# 点击打开下拉菜单
await page.click(dropdown_selector)
# 等待选项出现
await page.wait_for_selector(".dropdown-menu", state="visible")
# 查找并点击选项(支持模糊匹配)
option_locator = page.locator(".dropdown-option").filter(has_text=re.compile(option_text, re.I))
await option_locator.click()
# 等待下拉菜单关闭
await page.wait_for_selector(".dropdown-menu", state="hidden")
# 组合键操作(如选择全部)
async def select_all_options(page: Page, dropdown_selector: str):
await page.click(dropdown_selector)
await page.wait_for_selector(".dropdown-menu", state="visible")
# Ctrl+A 全选
await page.keyboard.press("Control+a")
await page.click(".dropdown-menu .select-all-option")5.3 文件上传
标准文件上传:
# 单文件上传
await page.set_input_files('input[type="file"]', "/path/to/file.pdf")
# 多文件上传
await page.set_input_files('input[type="file"]', [
"/path/to/file1.pdf",
"/path/to/file2.pdf"
])
# 清除已选文件
await page.set_input_files('input[type="file"]', [])拖拽上传:
# HTML5 拖拽上传
async def upload_via_drag_drop(page: Page, file_path: str):
# 创建 DataTransfer 对象
await page.evaluate("""(filePath) => {
const dropZone = document.querySelector('.drop-zone');
const dataTransfer = new DataTransfer();
const file = new File(['content'], filePath.split('/').pop());
dataTransfer.items.add(file);
const dropEvent = new DragEvent('drop', {
bubbles: true,
cancelable: true,
dataTransfer: dataTransfer
});
dropZone.dispatchEvent(dropEvent);
}""", file_path)上传进度监控:
async def upload_with_progress(page: Page, file_path: str):
"""带进度监控的上传"""
progress = []
# 监听 XHR 上传进度
await page.route("**/upload**", lambda route: route.continue_())
# 注入进度监控脚本
await page.evaluate("""() => {
const originalFetch = window.fetch;
window.fetch = async (...args) => {
const response = await originalFetch(...args);
if (args[0].url.includes('upload')) {
// 上传完成
window.dispatchEvent(new CustomEvent('uploadComplete'));
}
return response;
};
}""")
# 执行上传
async with page.expect_event("uploadComplete", timeout=60000):
await page.set_input_files('input[type="file"]', file_path)
return True5.4 表单验证与提交
触发前端验证:
# 触发单个字段验证
await page.locator("#email").blur() # 失去焦点触发验证
await page.locator("#email").focus()
# 手动触发 HTML5 验证
await page.evaluate("""() => {
const input = document.querySelector('#email');
input.reportValidity();
}""")
# 检查验证状态
is_valid = await page.evaluate("""() => {
return document.querySelector('#form').checkValidity();
}""")表单提交:
# 方法1:点击提交按钮
await page.click('button[type="submit"]')
# 方法2:直接提交表单
await page.evaluate("""() => {
document.querySelector('#form').submit();
}""")
# 方法3:模拟回车提交
await page.locator("#last-input").press("Enter")
# 等待提交完成
await page.wait_for_response(lambda r: r.url.includes("/api/submit"))
await page.wait_for_load_state("networkidle")表单验证流程:
async def submit_form_with_validation(page: Page, form_selector: str):
"""带验证的表单提交"""
# 尝试提交
await page.click(f"{form_selector} button[type='submit']")
# 检查是否有验证错误
errors = await page.locator(".form-error, .error-message").all_text_contents()
if errors:
error_msg = "\n".join(errors)
raise ValidationError(f"表单验证失败: {error_msg}")
# 等待服务器响应
try:
await page.wait_for_response(
lambda r: r.url.contains("/api/") and r.status in [200, 201, 302],
timeout=15000
)
except Exception:
raise SubmitError("表单提交超时")
# 检查业务错误
error_toast = await page.locator(".toast.error, .alert-danger").is_visible()
if error_toast:
error_text = await page.locator(".toast.error, .alert-danger").text_content()
raise BusinessError(error_text)6. 反爬虫对抗策略
本节为你提供的核心技术价值:理解网站反爬虫机制的核心原理,掌握验证码处理、IP 限制应对、请求指纹伪装等关键技术,使 Browser Agent 能够在对抗环境中稳定运行。
6.1 人机验证处理
人机验证(CAPTCHA)是网站防止自动机器人的主要手段。常见类型包括文本验证码、图像验证码、行为验证码(如 reCAPTCHA、hCaptcha)等。
验证码检测:
async def detect_captcha(page: Page) -> bool:
"""检测页面是否存在验证码"""
captcha_indicators = [
# reCAPTCHA
".g-recaptcha",
"iframe[src*='recaptcha']",
# hCaptcha
".h-captcha",
"iframe[src*='hcaptcha']",
# 图像验证码
".captcha-container",
"#captcha-modal",
# 行为验证
"[data-callback*='verify']",
# 通用
"iframe[src*='captcha']",
"img[alt*='captcha']"
]
for indicator in captcha_indicators:
try:
if await page.locator(indicator).count() > 0:
return True
except:
continue
# 检查页面内容特征
page_content = await page.content()
captcha_keywords = ["captcha", "验证", "人机", "我不是机器人", "点击验证"]
for keyword in captcha_keywords:
if keyword.lower() in page_content.lower():
return True
return FalsereCAPTCHA v2 解决方案:
async def solve_recaptcha_v2(page: Page, api_key: str, site_key: str, url: str):
"""
通过第三方服务解决 reCAPTCHA v2
api_key: 2Captcha 或类似服务提供的 API 密钥
"""
# 获取页面 sitekey
captcha_site_key = await page.evaluate("""() => {
const el = document.querySelector('.g-recaptcha');
return el ? el.getAttribute('data-sitekey') : null;
}""")
if not captcha_site_key:
captcha_site_key = site_key
# 调用验证码解决服务
# 这里以 2Captcha 为例
import http.client
import urllib.parse
conn = http.client.HTTPConnection("2captcha.com")
params = urllib.parse.urlencode({
"key": api_key,
"method": "userrecaptcha",
"googlekey": captcha_site_key,
"pageurl": url,
"json": 1
})
# 请求验证码 token(轮询直到获得结果)
import time
conn.request("GET", f"/res.php?{params}")
response = json.loads(conn.getresponse().read())
if response["status"] == 1:
captcha_id = response["request"]
else:
raise CaptchaError(f"获取验证码失败: {response}")
# 等待验证码解决
time.sleep(20)
while True:
conn.request("GET", f"/res.php?key={api_key}&action=get&id={captcha_id}&json=1")
response = json.loads(conn.getresponse().read())
if response["status"] == 1:
g_recaptcha_response = response["request"]
break
elif response["request"] == "CAPCHA_NOT_READY":
time.sleep(5)
else:
raise CaptchaError(f"验证码解决失败: {response}")
# 注入 token 到页面
await page.evaluate(f"""(token) => {{
document.querySelector('#g-recaptcha-response').innerHTML = token;
if (typeof ___grecaptcha_cfg !== 'undefined') {{
___grecaptcha_cfg['clients'].map(client => {{
Object.values(client).forEach(c => {{
if (c.callback) c.callback(token);
}});
}});
}}
}}""", g_recaptcha_response)
# 触发验证码回调
callback = await page.evaluate("""() => {
const iframes = document.querySelectorAll('iframe[src*="recaptcha"]');
for (const iframe of iframes) {
const win = iframe.contentWindow;
if (win.callback) return 'callback';
}
return null;
}""")
return g_recaptcha_response图像验证码自动识别:
async def solve_image_captcha(page: Page, captcha_img_selector: str, api_key: str):
"""
解决图像验证码
依赖于 OCR 服务(如 2Captcha、Anti-Captcha)
"""
# 截取验证码图片
captcha_element = page.locator(captcha_img_selector)
captcha_image = await captcha_element.screenshot()
# 保存临时文件
temp_path = "/tmp/captcha.png"
with open(temp_path, "wb") as f:
f.write(captcha_image)
# 发送到 OCR 服务
# 这里使用 base64 编码
import base64
with open(temp_path, "rb") as f:
img_base64 = base64.b64encode(f.read()).decode()
# 调用 OCR API
# 示例使用自定义 OCR 服务
result = await call_ocr_service(api_key, img_base64)
# 输入验证码
captcha_input = page.locator("input[type='text'], input[name='captcha']").first
await captcha_input.fill(result.text)
return result.text6.2 IP 限制与代理轮换
网站可能通过 IP 地址识别和限制异常的访问行为。合理的代理轮换策略可以有效分散请求,降低被封禁的风险。
代理池管理:
import asyncio
from dataclasses import dataclass
from typing import Protocol
import aiohttp
@dataclass
class Proxy:
host: str
port: int
username: str = None
password: str = None
@property
def url(self) -> str:
if self.username and self.password:
return f"http://{self.username}:{self.password}@{self.host}:{self.port}"
return f"http://{self.host}:{self.port}"
class ProxyPool:
"""代理池管理器"""
def __init__(self, proxies: list[Proxy] = None):
self.proxies = proxies or []
self.failed_proxies: set[str] = set()
self.proxy_stats: dict[str, dict] = {}
def add_proxy(self, proxy: Proxy):
self.proxies.append(proxy)
self.proxy_stats[proxy.url] = {"success": 0, "fail": 0, "latency": []}
def get_proxy(self) -> Proxy:
"""获取最优代理(根据成功率和延迟)"""
available = [p for p in self.proxies if p.url not in self.failed_proxies]
if not available:
available = self.proxies # 重试失败的
self.failed_proxies.clear()
# 选择评分最高的代理
scored = []
for p in available:
stats = self.proxy_stats.get(p.url, {"success": 0, "fail": 0, "latency": [1]})
success_rate = stats["success"] / max(stats["success"] + stats["fail"], 1)
avg_latency = sum(stats["latency"]) / max(len(stats["latency"]), 1)
score = success_rate * 0.7 - avg_latency * 0.3
scored.append((score, p))
return min(scored, key=lambda x: x[0])[1]
def report_result(self, proxy: Proxy, success: bool, latency: float = None):
"""报告代理使用结果"""
if proxy.url not in self.proxy_stats:
self.proxy_stats[proxy.url] = {"success": 0, "fail": 0, "latency": []}
stats = self.proxy_stats[proxy.url]
if success:
stats["success"] += 1
else:
stats["fail"] += 1
if stats["fail"] >= 3: # 连续失败3次,标记为不可用
self.failed_proxies.add(proxy.url)
if latency is not None:
stats["latency"].append(latency)
if len(stats["latency"]) > 10: # 保留最近10次延迟
stats["latency"] = stats["latency"][-10:]
# Playwright 使用代理
async def browse_with_proxy(page: Page, proxy: Proxy):
"""使用指定代理浏览"""
context = await page.context
# 注意:Playwright 支持在 launch 或 newContext 时设置代理
# 这里展示的是如何动态切换代理
await page.close()
new_context = await page.browser.new_context(
proxy={"server": f"http://{proxy.host}:{proxy.port}"}
)
new_page = await new_context.new_page()
return new_page6.3 浏览器指纹与请求伪装
网站可以通过浏览器指纹识别自动化工具。指纹特征包括 User-Agent、Canvas 指纹、WebGL 指纹、字体列表、时区、语言等。
反指纹策略:
from playwright.async_api import BrowserContext
async def create_stealth_context(browser: Browser) -> BrowserContext:
"""创建反检测的浏览器上下文"""
# 随机 User-Agent
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0",
]
user_agent = random.choice(user_agents)
context = await browser.new_context(
user_agent=user_agent,
locale="zh-CN", # 设置区域
timezone_id="Asia/Shanghai", # 设置时区
permissions=["geolocation"], # 地理位置权限
viewport={"width": 1920, "height": 1080},
)
# 拦截并修改 WebGL 指纹
await context.add_init_script("""() => {
// 修改 Canvas 指纹
const originalToDataURL = HTMLCanvasElement.prototype.toDataURL;
HTMLCanvasElement.prototype.toDataURL = function(...args) {
const ctx = this.getContext('2d');
if (ctx) {
// 添加随机噪声
const imageData = ctx.getImageData(0, 0, this.width, this.height);
for (let i = 0; i < imageData.data.length; i += 4) {
imageData.data[i] += Math.random() * 0.1;
imageData.data[i + 1] += Math.random() * 0.1;
imageData.data[i + 2] += Math.random() * 0.1;
}
ctx.putImageData(imageData, 0, 0);
}
return originalToDataURL.apply(this, args);
};
// 修改 WebGL 指纹
const getParameter = WebGLRenderingContext.prototype.getParameter;
WebGLRenderingContext.prototype.getParameter = function(param) {
if (param === 37445) { // UNMASKED_VENDOR
return 'Intel Inc.';
}
if (param === 37446) { // UNMASKED_RENDERER
return 'Intel Iris OpenGL Engine';
}
return getParameter.apply(this, arguments);
};
// 修改 navigator 属性
Object.defineProperty(navigator, 'webdriver', {
get: () => false
});
// 添加随机化的语言
Object.defineProperty(navigator, 'languages', {
get: () => ['zh-CN', 'zh', 'en-US', 'en']
});
}""")
# 拦截 navigator.permissions 查询
await context.add_init_script("""() => {
const originalQuery = window.navigator.permissions.query;
window.navigator.permissions.query = (parameters) => (
parameters.name === 'notifications' ?
Promise.resolve({ state: Notification.permission }) :
originalQuery(parameters)
);
}""")
return context请求头伪装:
async def set_realistic_headers(page: Page):
"""设置真实的请求头"""
await page.set_extra_http_headers({
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"DNT": "1",
"Upgrade-Insecure-Requests": "1",
"Cache-Control": "max-age=0",
})6.4 访问频率控制
合理的访问频率控制既是反爬虫对抗的一部分,也是对目标网站的尊重。过高频率的访问可能导致对方服务器负载异常,甚至影响正常用户访问。
智能限速器:
import asyncio
import time
from dataclasses import dataclass
from typing import Optional
@dataclass
class RateLimitConfig:
max_requests_per_second: float = 1.0
max_requests_per_minute: float = 60.0
max_requests_per_hour: float = 1000.0
burst_size: int = 3 # 允许的突发请求数
class TokenBucketRateLimiter:
"""令牌桶限速器"""
def __init__(self, config: RateLimitConfig):
self.config = config
self.tokens = config.burst_size
self.last_update = time.time()
self.min_interval = 1.0 / config.max_requests_per_second
# 分钟级和小时级计数
self.minute_requests: list[float] = []
self.hour_requests: list[float] = []
async def acquire(self):
"""获取请求许可(阻塞直到可以发送)"""
while True:
now = time.time()
# 更新令牌
elapsed = now - self.last_update
self.tokens = min(
self.config.burst_size,
self.tokens + elapsed * self.config.max_requests_per_second
)
self.last_update = now
# 清理过期计数
self.minute_requests = [t for t in self.minute_requests if now - t < 60]
self.hour_requests = [t for t in self.hour_requests if now - t < 3600]
# 检查各层级限制
if self.hour_requests and len(self.hour_requests) >= self.config.max_requests_per_hour:
sleep_time = 3600 - (now - self.hour_requests[0])
await asyncio.sleep(sleep_time)
continue
if self.minute_requests and len(self.minute_requests) >= self.config.max_requests_per_minute:
sleep_time = 60 - (now - self.minute_requests[0])
await asyncio.sleep(sleep_time)
continue
if self.tokens < 1:
await asyncio.sleep(self.min_interval)
continue
# 获取令牌
self.tokens -= 1
self.minute_requests.append(now)
self.hour_requests.append(now)
return
def get_stats(self) -> dict:
"""获取当前限速状态"""
now = time.time()
return {
"tokens_available": self.tokens,
"requests_this_minute": len([t for t in self.minute_requests if now - t < 60]),
"requests_this_hour": len([t for t in self.hour_requests if now - t < 3600]),
}
# 使用示例
async def polite_scraping(page: Page, urls: list[str]):
"""礼貌的爬取:自动限速"""
config = RateLimitConfig(
max_requests_per_second=1.0,
max_requests_per_minute=30,
max_requests_per_hour=500
)
limiter = TokenBucketRateLimiter(config)
for url in urls:
await limiter.acquire()
try:
await page.goto(url)
# 处理页面...
print(f"成功抓取: {url}")
except Exception as e:
print(f"抓取失败: {url}, 错误: {e}")
# 额外随机延迟
await asyncio.sleep(random.uniform(0.5, 2.0))7. Playwright Browser Agent 实践
本节为你提供的核心技术价值:通过完整的代码实现,展示如何将前述的定位策略、状态管理、表单操作、反爬虫对抗等技术整合为一个可用的 Browser Agent 系统。
7.1 Browser Agent 架构设计
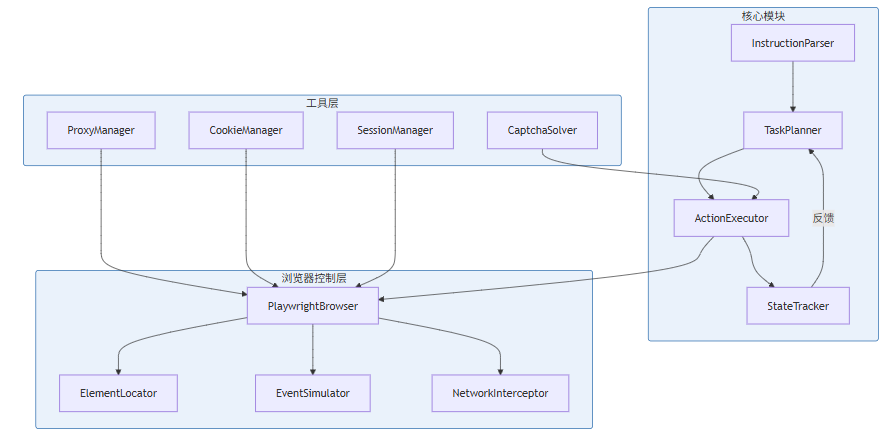
7.2 核心实现
"""
Browser Agent - 基于 Playwright 的 Web 自动化框架
作者:HOS(安全风信子)
版本:1.0.0
"""
import asyncio
import re
import json
import logging
from dataclasses import dataclass, field
from enum import Enum, auto
from typing import Optional, Callable, Any
from pathlib import Path
from urllib.parse import urljoin, urlparse
import random
from playwright.async_api import async_playwright, Page, Browser, BrowserContext, Playwright
from playwright.async_api.models import FilePayload
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class AgentState(Enum):
"""Agent 状态枚举"""
IDLE = auto()
INITIALIZING = auto()
NAVIGATING = auto()
EXECUTING = auto()
WAITING = auto()
ERROR = auto()
STOPPED = auto()
@dataclass
class ActionResult:
"""动作执行结果"""
success: bool
message: str = ""
data: Any = None
error: Optional[Exception] = None
def __bool__(self):
return self.success
@dataclass
class BrowserConfig:
"""浏览器配置"""
headless: bool = True
user_agent: Optional[str] = None
viewport_width: int = 1920
viewport_height: int = 1080
locale: str = "zh-CN"
timezone: str = "Asia/Shanghai"
proxy_server: Optional[str] = None
proxy_username: Optional[str] = None
proxy_password: Optional[str] = None
slow_mo: int = 0 # 慢动作延迟(毫秒)
Stealth: bool = True # 启用反检测
@dataclass
class AgentConfig:
"""Agent 配置"""
default_timeout: int = 30000
navigation_timeout: int = 60000
retry_count: int = 3
retry_delay: int = 1000
screenshot_on_error: bool = True
trace_on_error: bool = True
data_dir: str = "./data"
class InstructionParser:
"""
指令解析器:将自然语言指令转换为可执行的动作序列
"""
# 动作模式定义
ACTION_PATTERNS = {
"navigate": [
r"打开\s*(.+?)(?:\s|$)",
r"访问\s*(.+?)(?:\s|$)",
r"转到\s*(.+?)(?:\s|$)",
r"导航到\s*(.+?)(?:\s|$)",
],
"click": [
r"点击\s*(.+?)(?:\s|$)",
r"单击\s*(.+?)(?:\s|$)",
r"选择\s*(.+?)(?:\s|$)",
],
"input": [
r"在\s*(.+?)\s*(?:中|里)?输入\s*['\"](.+?)['\"](?:\s|$)",
r"填写\s*(.+?)\s*(?:为|成)\s*['\"](.+?)['\"](?:\s|$)",
],
"select": [
r"选择\s*(.+?)\s*(?:的|为)?\s*['\"](.+?)['\"](?:\s|$)",
],
"wait": [
r"等待\s*(.+?)(?:\s|$)",
r"等待\s*(\d+)\s*(?:秒|毫秒)(?:\s|$)",
],
"extract": [
r"提取\s*(.+?)(?:\s|$)",
r"获取\s*(.+?)(?:\s|$)",
r"抓取\s*(.+?)(?:\s|$)",
],
"scroll": [
r"滚动\s*(?:到)?\s*(.+?)(?:\s|$)",
r"向下滚动",
r"向上滚动",
],
"screenshot": [
r"截图",
r"截屏",
],
}
def __init__(self):
self.compiled_patterns = {}
for action, patterns in self.ACTION_PATTERNS.items():
self.compiled_patterns[action] = [re.compile(p) for p in patterns]
def parse(self, instruction: str) -> list[dict]:
"""
解析自然语言指令为动作序列
Args:
instruction: 自然语言指令
Returns:
动作列表,每个动作为字典,包含 type 和参数
"""
instruction = instruction.strip()
actions = []
# 逐个检测动作模式
for action, patterns in self.compiled_patterns.items():
for pattern in patterns:
match = pattern.search(instruction)
if match:
action_def = {"type": action}
groups = match.groups()
if action == "navigate" and groups:
action_def["target"] = groups[0]
elif action == "click" and groups:
action_def["target"] = groups[0]
elif action == "input" and len(groups) >= 2:
action_def["field"] = groups[0]
action_def["value"] = groups[1]
elif action == "select" and len(groups) >= 2:
action_def["field"] = groups[0]
action_def["value"] = groups[1]
elif action == "wait" and groups:
if groups[0].isdigit():
action_def["duration"] = int(groups[0])
else:
action_def["target"] = groups[0]
elif action == "extract" and groups:
action_def["target"] = groups[0]
elif action == "scroll" and groups:
action_def["direction"] = groups[0] if groups else "down"
actions.append(action_def)
break # 每个指令只匹配一个模式
return actions
class ElementLocator:
"""
智能元素定位器:支持多种定位策略的自动选择和回退
"""
def __init__(self, page: Page):
self.page = page
async def locate(self, target: str) -> Optional[Any]:
"""
智能定位元素
Args:
target: 定位目标(可以是文本、ID、类名、选择器等)
Returns:
定位到的元素
"""
locator = None
# 策略1:精确文本匹配(按钮、链接等)
text_patterns = [
(rf".*('{re.escape(target)}'|{re.escape(target)}).*", "text"),
(rf".*{re.escape(target)}.*", "text"),
]
for pattern, match_type in text_patterns:
locator = self.page.get_by_text(re.compile(pattern, re.I))
if await locator.count() > 0:
logger.info(f"通过文本匹配定位: {target}")
return locator
# 策略2:ARIA 角色定位
role_patterns = ["button", "link", "textbox", "checkbox", "radio", "menuitem"]
for role in role_patterns:
locator = self.page.get_by_role(role, name=re.compile(target, re.I))
if await locator.count() > 0:
logger.info(f"通过角色定位: {target}")
return locator
# 策略3:placeholder 定位
locator = self.page.get_by_placeholder(re.compile(target, re.I))
if await locator.count() > 0:
logger.info(f"通过 placeholder 定位: {target}")
return locator
# 策略4:label 关联定位
locator = self.page.get_by_label(re.compile(target, re.I))
if await locator.count() > 0:
logger.info(f"通过 label 定位: {target}")
return locator
# 策略5:CSS 选择器(ID、类、属性等)
selector_patterns = [
f"#{target}",
f".{target}",
f"[id*='{target}']",
f"[class*='{target}']",
f"[name='{target}']",
target,
]
for selector in selector_patterns:
try:
locator = self.page.locator(selector)
if await locator.count() > 0:
logger.info(f"通过 CSS 选择器定位: {selector}")
return locator
except Exception:
continue
# 策略6:XPath 文本包含
xpath_patterns = [
f"//*[contains(text(), '{target}')]",
f"//button[contains(text(), '{target}')]",
f"//a[contains(text(), '{target}')]",
f"//input[@placeholder='{target}']",
]
for xpath in xpath_patterns:
locator = self.page.locator(f"xpath={xpath}")
if await locator.count() > 0:
logger.info(f"通过 XPath 定位: {xpath}")
return locator
logger.warning(f"无法定位元素: {target}")
return None
async def locate_with_retry(self, target: str, max_retries: int = 3, delay: int = 1000) -> Optional[Any]:
"""带重试的元素定位"""
for attempt in range(max_retries):
locator = await self.locate(target)
if locator:
return locator
if attempt < max_retries - 1:
await asyncio.sleep(delay / 1000)
return None
class ActionExecutor:
"""
动作执行器:执行各种浏览器操作
"""
def __init__(self, page: Page, locator: ElementLocator):
self.page = page
self.locator = locator
async def navigate(self, url: str) -> ActionResult:
"""导航到指定 URL"""
try:
if not url.startswith(("http://", "https://")):
url = "https://" + url
await self.page.goto(url, wait_until="domcontentloaded", timeout=30000)
# 等待页面基本可交互
await self.page.wait_for_load_state("networkidle", timeout=15000)
return ActionResult(success=True, message=f"成功导航到 {url}")
except Exception as e:
logger.error(f"导航失败: {e}")
return ActionResult(success=False, message=str(e), error=e)
async def click(self, target: str) -> ActionResult:
"""点击元素"""
try:
locator = await self.locator.locate_with_retry(target)
if not locator:
return ActionResult(success=False, message=f"找不到元素: {target}")
await locator.click(timeout=10000)
await self.page.wait_for_load_state("domcontentloaded", timeout=10000)
return ActionResult(success=True, message=f"成功点击: {target}")
except Exception as e:
logger.error(f"点击失败: {e}")
return ActionResult(success=False, message=str(e), error=e)
async def input_text(self, field: str, value: str) -> ActionResult:
"""输入文本"""
try:
locator = await self.locator.locate_with_retry(field)
if not locator:
return ActionResult(success=False, message=f"找不到输入框: {field}")
await locator.clear()
await locator.fill(value)
return ActionResult(success=True, message=f"成功输入: {value}")
except Exception as e:
logger.error(f"输入失败: {e}")
return ActionResult(success=False, message=str(e), error=e)
async def select_option(self, field: str, value: str) -> ActionResult:
"""选择选项"""
try:
locator = await self.locator.locate_with_retry(field)
if not locator:
return ActionResult(success=False, message=f"找不到选择框: {field}")
# 尝试多种选择方式
try:
await locator.select_option(value)
except:
try:
await locator.select_option(label=value)
except:
await locator.select_option(index=int(value))
return ActionResult(success=True, message=f"成功选择: {value}")
except Exception as e:
logger.error(f"选择失败: {e}")
return ActionResult(success=False, message=str(e), error=e)
async def wait(self, duration: int = None, target: str = None) -> ActionResult:
"""等待"""
try:
if duration:
# 毫秒转秒
await asyncio.sleep(duration / 1000)
elif target:
locator = await self.locator.locate_with_retry(target)
if locator:
await locator.wait_for(state="visible", timeout=30000)
return ActionResult(success=True, message="等待完成")
except Exception as e:
return ActionResult(success=False, message=str(e), error=e)
async def extract(self, selector: str, attribute: str = "text") -> ActionResult:
"""提取内容"""
try:
locator = self.page.locator(selector)
count = await locator.count()
if count == 0:
return ActionResult(success=False, message=f"找不到元素: {selector}")
if attribute == "text":
data = await locator.all_text_contents()
elif attribute == "inner_html":
data = await locator.all_inner_htmls()
elif attribute == "value":
data = await locator.all_input_values()
else:
data = [await el.get_attribute(attribute) for el in [locator] if await locator.count() > 0]
return ActionResult(success=True, message="提取成功", data=data)
except Exception as e:
return ActionResult(success=False, message=str(e), error=e)
async def scroll(self, direction: str = "down") -> ActionResult:
"""滚动页面"""
try:
if direction == "down":
await self.page.evaluate("window.scrollBy(0, window.innerHeight)")
elif direction == "up":
await self.page.evaluate("window.scrollBy(0, -window.innerHeight)")
elif "px" in direction:
await self.page.evaluate(f"window.scrollBy(0, {direction})")
return ActionResult(success=True, message=f"滚动{direction}完成")
except Exception as e:
return ActionResult(success=False, message=str(e), error=e)
async def screenshot(self, path: str = None) -> ActionResult:
"""截图"""
try:
if not path:
path = f"screenshot_{int(asyncio.get_event_loop().time())}.png"
await self.page.screenshot(path=path, full_page=True)
return ActionResult(success=True, message=f"截图保存到 {path}", data=path)
except Exception as e:
return ActionResult(success=False, message=str(e), error=e)
class BrowserAgent:
"""
Browser Agent 主类:协调各模块工作
"""
def __init__(self, config: AgentConfig = None):
self.config = config or AgentConfig()
self.playwright: Optional[Playwright] = None
self.browser: Optional[Browser] = None
self.context: Optional[BrowserContext] = None
self.page: Optional[Page] = None
self.state = AgentState.IDLE
self.parser = InstructionParser()
self.locator: Optional[ElementLocator] = None
self.executor: Optional[ActionExecutor] = None
self.session_data: dict = {}
self.action_history: list[ActionResult] = []
async def initialize(self, browser_config: BrowserConfig = None) -> bool:
"""初始化浏览器"""
try:
self.state = AgentState.INITIALIZING
browser_config = browser_config or BrowserConfig()
self.playwright = await async_playwright().start()
# 启动浏览器
launch_options = {
"headless": browser_config.headless,
"slow_mo": browser_config.slow_mo,
}
# 代理配置
if browser_config.proxy_server:
launch_options["proxy"] = {
"server": browser_config.proxy_server,
"username": browser_config.proxy_username,
"password": browser_config.proxy_password,
}
self.browser = await self.playwright.chromium.launch(**launch_options)
# 创建上下文
context_options = {
"viewport": {
"width": browser_config.viewport_width,
"height": browser_config.viewport_height,
},
"locale": browser_config.locale,
"timezone_id": browser_config.timezone,
}
if browser_config.user_agent:
context_options["user_agent"] = browser_config.user_agent
self.context = await self.browser.new_context(**context_options)
# 反检测脚本
if browser_config.stealth:
await self._apply_stealth_scripts()
self.page = await self.context.new_page()
# 初始化组件
self.locator = ElementLocator(self.page)
self.executor = ActionExecutor(self.page, self.locator)
self.state = AgentState.IDLE
logger.info("Browser Agent 初始化成功")
return True
except Exception as e:
logger.error(f"初始化失败: {e}")
self.state = AgentState.ERROR
return False
async def _apply_stealth_scripts(self):
"""应用反检测脚本"""
await self.context.add_init_script("""() => {
// 修改 navigator.webdriver
Object.defineProperty(navigator, 'webdriver', {
get: () => false
});
// 修改 Canvas 指纹
const originalToDataURL = HTMLCanvasElement.prototype.toDataURL;
HTMLCanvasElement.prototype.toDataURL = function(...args) {
const ctx = this.getContext('2d');
if (ctx) {
const imageData = ctx.getImageData(0, 0, this.width, this.height);
for (let i = 0; i < imageData.data.length; i += 4) {
imageData.data[i] += Math.random() * 0.0001;
}
ctx.putImageData(imageData, 0, 0);
}
return originalToDataURL.apply(this, args);
};
// 修改 WebGL 指纹
const getParameter = WebGLRenderingContext.prototype.getParameter;
WebGLRenderingContext.prototype.getParameter = function(param) {
if (param === 37445) return 'Intel Inc.';
if (param === 37446) return 'Intel Iris OpenGL Engine';
return getParameter.apply(this, arguments);
};
// 修改 permissions
const originalQuery = navigator.permissions.query;
navigator.permissions.query = (parameters) => (
parameters.name === 'notifications' ?
Promise.resolve({ state: Notification.permission }) :
originalQuery(parameters)
);
// 添加真实的语言列表
Object.defineProperty(navigator, 'languages', {
get: () => ['zh-CN', 'zh', 'en-US', 'en']
});
}""")
async def execute(self, instruction: str) -> ActionResult:
"""
执行自然语言指令
Args:
instruction: 自然语言指令
Returns:
执行结果
"""
if self.state == AgentState.ERROR:
return ActionResult(success=False, message="Agent 处于错误状态")
if not self.page:
return ActionResult(success=False, message="Agent 未初始化")
try:
self.state = AgentState.EXECUTING
# 解析指令
actions = self.parser.parse(instruction)
if not actions:
return ActionResult(success=False, message=f"无法解析指令: {instruction}")
logger.info(f"解析到 {len(actions)} 个动作: {actions}")
# 执行动作序列
results = []
for action in actions:
result = await self._execute_action(action)
results.append(result)
self.action_history.append(result)
if not result.success:
# 动作失败,可选择是否继续
logger.warning(f"动作失败,继续执行: {result.message}")
# 返回最后一个结果
return results[-1] if results else ActionResult(success=False, message="无执行结果")
except Exception as e:
logger.error(f"执行异常: {e}")
self.state = AgentState.ERROR
return ActionResult(success=False, message=str(e), error=e)
finally:
self.state = AgentState.IDLE
async def _execute_action(self, action: dict) -> ActionResult:
"""执行单个动作"""
action_type = action["type"]
self.state = AgentState.EXECUTING
if action_type == "navigate":
return await self.executor.navigate(action.get("target", ""))
elif action_type == "click":
return await self.executor.click(action.get("target", ""))
elif action_type == "input":
return await self.executor.input_text(
action.get("field", ""),
action.get("value", "")
)
elif action_type == "select":
return await self.executor.select_option(
action.get("field", ""),
action.get("value", "")
)
elif action_type == "wait":
return await self.executor.wait(
duration=action.get("duration"),
target=action.get("target")
)
elif action_type == "extract":
return await self.executor.extract(action.get("target", ""))
elif action_type == "scroll":
return await self.executor.scroll(action.get("direction", "down"))
elif action_type == "screenshot":
return await self.executor.screenshot()
else:
return ActionResult(success=False, message=f"未知动作类型: {action_type}")
async def execute_script(self, script: str) -> Any:
"""在页面中执行 JavaScript"""
if not self.page:
raise RuntimeError("Agent 未初始化")
return await self.page.evaluate(script)
async def save_session(self, path: str = None):
"""保存会话状态(Cookie、LocalStorage 等)"""
if not self.context:
return
path = path or f"session_{int(asyncio.get_event_loop().time())}.json"
storage = await self.context.storage_state()
with open(path, "w", encoding="utf-8") as f:
json.dump(storage, f, indent=2, ensure_ascii=False)
logger.info(f"会话已保存到 {path}")
return path
async def load_session(self, path: str):
"""加载会话状态"""
if not self.context:
return
await self.context.storage_state(path=path)
logger.info(f"会话已从 {path} 加载")
async def close(self):
"""关闭 Agent"""
if self.page:
await self.page.close()
if self.context:
await self.context.close()
if self.browser:
await self.browser.close()
if self.playwright:
await self.playwright.stop()
self.state = AgentState.STOPPED
logger.info("Browser Agent 已关闭")7.3 使用示例
"""
Browser Agent 使用示例
"""
import asyncio
from browser_agent import BrowserAgent, BrowserConfig, AgentConfig
async def demo_basic_usage():
"""基础用法演示"""
agent = BrowserAgent()
# 初始化
await agent.initialize(BrowserConfig(headless=True))
# 执行一系列操作
# 1. 打开百度
result = await agent.execute("打开 https://www.baidu.com")
print(f"导航结果: {result.success}, {result.message}")
# 2. 在搜索框输入 Python
await agent.execute("在搜索框输入 'Python'")
# 3. 点击搜索按钮
await agent.execute("点击 百度一下")
# 4. 截图
await agent.execute("截图")
# 关闭
await agent.close()
async def demo_login_flow():
"""登录流程演示"""
agent = BrowserAgent()
await agent.initialize()
# 打开登录页面
await agent.execute("打开 https://example.com/login")
# 填写用户名
await agent.execute("在 用户名 输入 'admin'")
# 填写密码
await agent.execute("在 密码 输入 'password123'")
# 点击登录按钮
await agent.execute("点击 登录")
# 等待页面跳转
await asyncio.sleep(2)
# 截图保存登录后状态
await agent.executor.screenshot("after_login.png")
await agent.close()
async def demo_data_extraction():
"""数据提取演示"""
agent = BrowserAgent()
await agent.initialize()
await agent.execute("打开 https://news.ycombinator.com")
# 提取标题列表
result = await agent.execute("获取所有标题")
if result.success:
titles = result.data
for i, title in enumerate(titles[:10], 1):
print(f"{i}. {title}")
await agent.close()
async def demo_session_persistence():
"""会话保持演示"""
agent = BrowserAgent()
# 尝试加载已保存的会话
session_path = "session.json"
try:
await agent.load_session(session_path)
print("加载已保存的会话")
except:
print("创建新会话")
await agent.initialize()
# 执行操作...
await agent.execute("打开 https://example.com")
# 保存会话
await agent.save_session(session_path)
await agent.close()
if __name__ == "__main__":
# 运行基础演示
asyncio.run(demo_basic_usage())7.4 高级配置与扩展
"""
Browser Agent 扩展模块
"""
import asyncio
from typing import Optional
import httpx
from browser_agent import BrowserAgent, BrowserConfig, ActionResult
class CaptchaIntegration:
"""验证码集成模块"""
def __init__(self, agent: BrowserAgent, api_key: str, provider: str = "2captcha"):
self.agent = agent
self.api_key = api_key
self.provider = provider
async def solve_recaptcha(self, site_key: str = None) -> Optional[str]:
"""解决 reCAPTCHA"""
if not site_key:
site_key = await self.agent.execute_script("""
document.querySelector('.g-recaptcha')?.getAttribute('data-sitekey')
""")
if not site_key:
return None
# 调用验证码解决服务
async with httpx.AsyncClient() as client:
if self.provider == "2captcha":
# 获取验证码 ID
resp = await client.get(
f"http://2captcha.com/res.php?key={self.api_key}&method=userrecaptcha&googlekey={site_key}&pageurl={self.agent.page.url}&json=1"
)
data = resp.json()
if data["status"] != 1:
return None
captcha_id = data["request"]
# 轮询获取结果
await asyncio.sleep(20)
for _ in range(30):
resp = await client.get(
f"http://2captcha.com/res.php?key={self.api_key}&action=get&id={captcha_id}&json=1"
)
data = resp.json()
if data["status"] == 1:
return data["request"]
await asyncio.sleep(5)
return None
async def detect_and_solve(self) -> bool:
"""检测并解决验证码"""
page = self.agent.page
# 检测 reCAPTCHA
recaptcha = await page.query_selector(".g-recaptcha")
if recaptcha:
token = await self.solve_recaptcha()
if token:
# 注入 token
await self.agent.execute_script(f"""
document.getElementById('g-recaptcha-response').innerHTML = '{token}';
""")
return True
return False
class ProxyRotator:
"""代理轮换模块"""
def __init__(self, agent: BrowserAgent, proxy_list: list[dict]):
self.agent = agent
self.proxies = proxy_list
self.current_index = 0
async def rotate(self):
"""切换到下一个代理"""
if not self.proxies:
return
proxy = self.proxies[self.current_index]
self.current_index = (self.current_index + 1) % len(self.proxies)
# 关闭当前页面
await self.agent.page.close()
await self.agent.context.close()
# 使用新代理重新创建上下文
browser_config = BrowserConfig(
proxy_server=proxy.get("server"),
proxy_username=proxy.get("username"),
proxy_password=proxy.get("password"),
)
await self.agent.initialize(browser_config)
print(f"已切换到代理: {proxy.get('server')}")
def get_current_proxy(self) -> Optional[dict]:
"""获取当前代理"""
if self.proxies:
return self.proxies[self.current_index - 1] if self.current_index > 0 else self.proxies[0]
return None
class RateLimiter:
"""请求限流器"""
def __init__(self, max_per_second: float = 1.0):
self.max_per_second = max_per_second
self.min_interval = 1.0 / max_per_second
self.last_request = 0
async def wait(self):
"""等待以满足限流要求"""
now = asyncio.get_event_loop().time()
elapsed = now - self.last_request
if elapsed < self.min_interval:
await asyncio.sleep(self.min_interval - elapsed)
self.last_request = asyncio.get_event_loop().time()8. 最佳实践与性能优化
本节为你提供的核心技术价值:总结 Browser Agent 开发中的常见问题与解决方案,提供性能优化策略和工程化实践指南。
8.1 稳定性提升策略
1. 智能等待机制
class SmartWaiter:
"""智能等待器"""
def __init__(self, page: Page):
self.page = page
async def wait_for_element(self, selector: str, timeout: int = 30000):
"""等待元素出现"""
locator = self.page.locator(selector)
await locator.wait_for(state="attached", timeout=timeout)
return locator
async def wait_for_text(self, text: str, timeout: int = 30000):
"""等待文本出现"""
await self.page.wait_for_function(
f"""() => document.body.innerText.includes('{text}')""",
timeout=timeout
)
async def wait_for_navigation(self, timeout: int = 30000):
"""等待导航完成"""
await asyncio.gather(
self.page.wait_for_load_state("networkidle", timeout=timeout),
self.page.wait_for_load_state("domcontentloaded", timeout=timeout),
)
async def wait_for_network_idle_with_timeout(self, timeout: int = 30000):
"""带自定义超时的网络空闲等待"""
try:
await self.page.wait_for_load_state("networkidle", timeout=timeout)
except Exception:
# 网络空闲等待超时,强制继续
pass2. 错误恢复机制
class ErrorRecovery:
"""错误恢复机制"""
def __init__(self, agent: BrowserAgent):
self.agent = agent
self.max_retries = 3
async def with_recovery(self, action: Callable, *args, **kwargs) -> ActionResult:
"""带错误恢复的动作执行"""
last_error = None
for attempt in range(self.max_retries):
try:
result = await action(*args, **kwargs)
if result.success:
return result
last_error = result.error
except Exception as e:
last_error = e
logger.error(f"尝试 {attempt + 1} 失败: {e}")
# 重试前等待
if attempt < self.max_retries - 1:
delay = 1000 * (2 ** attempt) # 指数退避
await asyncio.sleep(delay / 1000)
# 尝试刷新页面恢复状态
await self._refresh_state()
return ActionResult(
success=False,
message=f"重试 {self.max_retries} 次后仍失败: {last_error}",
error=last_error
)
async def _refresh_state(self):
"""刷新页面状态"""
try:
await self.agent.page.reload()
await self.agent.page.wait_for_load_state("domcontentloaded")
except Exception as e:
logger.warning(f"状态刷新失败: {e}")8.2 性能优化技巧
1. 并行操作
async def parallel_navigation(pages: list[Page], urls: list[str]):
"""并行导航多个页面"""
tasks = [page.goto(url) for page, url in zip(pages, urls)]
await asyncio.gather(*tasks)
async def parallel_extraction(page: Page, selectors: list[str]):
"""并行提取多个选择器的内容"""
tasks = [
page.locator(selector).all_text_contents()
for selector in selectors
]
results = await asyncio.gather(*tasks)
return dict(zip(selectors, results))2. 上下文复用
async def batch_operations(agent: BrowserAgent, urls: list[str]):
"""批量操作复用上下文"""
# 在同一上下文中打开多个页面
pages = []
for url in urls:
page = await agent.context.new_page()
pages.append(page)
await page.goto(url)
# 执行操作...
# 批量关闭
for page in pages:
await page.close()3. 资源优化
# 禁用不必要的资源加载
await page.route("**/*", lambda route: route.abort() if route.request.resource_type in ["image", "stylesheet", "font"] else route.continue_())
# 启用请求缓存
await page.context.set_extra_http_headers({
"Cache-Control": "max-age=86400"
})8.3 工程化建议
1. 配置管理
# config.py
from dataclasses import dataclass
@dataclass
class Environment:
base_url: str
api_timeout: int
headless: bool
max_retries: int
ENVIRONMENTS = {
"dev": Environment(
base_url="https://dev.example.com",
api_timeout=30000,
headless=False,
max_retries=3,
),
"prod": Environment(
base_url="https://www.example.com",
api_timeout=60000,
headless=True,
max_retries=5,
),
}
# 使用
import os
env_name = os.getenv("ENV", "dev")
config = ENVIRONMENTS[env_name]2. 日志规范
import logging
from functools import wraps
def log_action(action_name: str):
"""动作执行日志装饰器"""
def decorator(func):
@wraps(func)
async def wrapper(*args, **kwargs):
logger.info(f"[ACTION] 开始执行: {action_name}")
try:
result = await func(*args, **kwargs)
if result.success:
logger.info(f"[ACTION] 成功: {action_name}")
else:
logger.warning(f"[ACTION] 失败: {action_name} - {result.message}")
return result
except Exception as e:
logger.error(f"[ACTION] 异常: {action_name} - {e}")
raise
return wrapper
return decorator3. 测试框架集成
import pytest
@pytest.fixture
async def browser_agent():
"""Browser Agent 测试 fixture"""
agent = BrowserAgent()
await agent.initialize()
yield agent
await agent.close()
@pytest.mark.asyncio
async def test_login_flow(browser_agent):
"""登录流程测试"""
await browser_agent.execute("打开 https://example.com/login")
await browser_agent.execute("在用户名输入 'test'")
await browser_agent.execute("在密码输入 'password'")
result = await browser_agent.execute("点击登录")
assert result.success9. 总结与展望
Browser Agent 作为连接 AI 智能与 Web 交互的桥梁,正在成为自动化领域的重要技术方向。本文系统讲解了 Browser Agent 的核心实现机制:
核心技术要点:
- 架构设计:Browser Agent 由交互接口层、AI 决策层、操作执行层、浏览器引擎层四部分组成,各层职责清晰、协同工作。
- 框架选型:Selenium、Playwright、Puppeteer 各有优劣。Playwright 以其原生 CDP 支持、自动等待机制和跨浏览器能力,正成为现代 Browser Agent 的首选。
- 元素定位:CSS Selector、XPath、语义定位三种策略互补。语义定位对页面结构变化具有最强鲁棒性,应作为首选方案。
- 状态管理:现代 Web 应用的动态特性要求 Browser Agent 实现复杂的加载状态处理、AJAX 等待、Shadow DOM 穿透等能力。
- 反爬虫对抗:验证码处理、IP 轮换、指纹伪装、访问限速是应对反爬虫机制的关键技术。
- 工程实践:智能等待、错误恢复、性能优化、配置管理等工程化实践是构建可靠 Browser Agent 系统的重要保障。
未来发展方向:
随着大语言模型(LLM)能力的不断提升,Browser Agent 将变得更加智能:
- 更强的理解能力:LLM 可以理解更复杂的自然语言指令,甚至从网页截图直接理解页面结构。
- 自主决策优化:Agent 可以在执行过程中根据页面反馈自主调整策略,实现真正的"边做边学"。
- 多模态交互:结合视觉模型,Agent 可以处理验证码、图像识别等传统上难以自动化的任务。
- 协作式 Agent:多个专业化的 Agent 协同工作,分别负责导航、填写、验证等不同子任务。
Browser Agent 的发展为 Web 自动化打开了新的可能性,无论是企业级业务流程自动化,还是个人效率工具,都将从中受益。掌握其核心原理和最佳实践,将使开发者能够构建更加智能、可靠的自动化系统。
参考链接
- Playwright 官方文档 - Microsoft 官方维护的 Playwright API 参考
- Selenium 官方文档 - Selenium WebDriver 协议与最佳实践
- Puppeteer 官方文档 - Google Chrome 团队维护的 Puppeteer API 参考
- W3C WebDriver 规范 - WebDriver 协议的官方 W3C 标准
- Chrome DevTools Protocol 文档 - CDP 协议完整参考
- WAI-ARIA 规范 - 无障碍富互联网应用规范
- 2Captcha 服务 - 验证码识别服务提供商
- Browser Agent Architecture - Microsoft Research - 浏览器自动化研究论文
附录(Appendix):
A. Browser Agent 完整代码
以下是 Browser Agent 的完整可运行代码,整合了本文讲解的所有核心模块:
"""
Browser Agent - 完整实现
作者:HOS(安全风信子)
日期:2026-05-24
版本:1.0.0
"""
import asyncio
import re
import json
import logging
import random
import time
from dataclasses import dataclass, field
from enum import Enum, auto
from typing import Optional, Callable, Any, List
from urllib.parse import urlparse
from playwright.async_api import async_playwright, Page, Browser, BrowserContext, Playwright
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
class AgentState(Enum):
"""Agent 状态枚举"""
IDLE = auto()
INITIALIZING = auto()
NAVIGATING = auto()
EXECUTING = auto()
WAITING = auto()
ERROR = auto()
STOPPED = auto()
@dataclass
class ActionResult:
"""动作执行结果"""
success: bool
message: str = ""
data: Any = None
error: Optional[Exception] = None
@dataclass
class BrowserConfig:
"""浏览器配置"""
headless: bool = True
user_agent: Optional[str] = None
viewport_width: int = 1920
viewport_height: int = 1080
locale: str = "zh-CN"
timezone: str = "Asia/Shanghai"
proxy_server: Optional[str] = None
proxy_username: Optional[str] = None
proxy_password: Optional[str] = None
slow_mo: int = 0
stealth: bool = True
class InstructionParser:
"""自然语言指令解析器"""
ACTION_PATTERNS = {
"navigate": [r"(?:打开|访问|转到|导航到)\s*(.+?)(?:\s*$)",],
"click": [r"(?:点击|单击|选择)\s*(.+?)(?:\s*$)",],
"input": [r"在\s*(.+?)\s*(?:中|里)?输入\s*['\"](.+?)['\"](?:\s*$)",],
"wait": [r"等待\s*(\d+)?\s*(?:秒|毫秒)?(?:\s*$)",],
"screenshot": [r"(?:截图|截屏)(?:\s*$)",],
"extract": [r"(?:提取|获取|抓取)\s*(.+?)(?:\s*$)",],
}
def __init__(self):
self.compiled_patterns = {}
for action, patterns in self.ACTION_PATTERNS.items():
self.compiled_patterns[action] = [re.compile(p) for p in patterns]
def parse(self, instruction: str) -> List[dict]:
"""解析自然语言指令"""
instruction = instruction.strip()
actions = []
for action, patterns in self.compiled_patterns.items():
for pattern in patterns:
match = pattern.search(instruction)
if match:
action_def = {"type": action}
groups = match.groups()
if action == "navigate" and groups:
action_def["target"] = groups[0]
elif action == "click" and groups:
action_def["target"] = groups[0]
elif action == "input" and len(groups) >= 2:
action_def["field"] = groups[0]
action_def["value"] = groups[1]
elif action == "wait" and groups and groups[0]:
action_def["duration"] = int(groups[0]) * (1000 if '毫秒' not in instruction else 1)
elif action == "extract" and groups:
action_def["target"] = groups[0]
actions.append(action_def)
break
return actions
class BrowserAgent:
"""
Browser Agent 主类
"""
def __init__(self):
self.playwright: Optional[Playwright] = None
self.browser: Optional[Browser] = None
self.context: Optional[BrowserContext] = None
self.page: Optional[Page] = None
self.state = AgentState.IDLE
self.parser = InstructionParser()
async def initialize(self, config: BrowserConfig = None) -> bool:
"""初始化浏览器"""
try:
self.state = AgentState.INITIALIZING
config = config or BrowserConfig()
self.playwright = await async_playwright().start()
launch_options = {
"headless": config.headless,
"slow_mo": config.slow_mo,
}
if config.proxy_server:
launch_options["proxy"] = {
"server": config.proxy_server,
"username": config.proxy_username,
"password": config.proxy_password,
}
self.browser = await self.playwright.chromium.launch(**launch_options)
context_options = {
"viewport": {"width": config.viewport_width, "height": config.viewport_height},
"locale": config.locale,
"timezone_id": config.timezone,
}
if config.user_agent:
context_options["user_agent"] = config.user_agent
self.context = await self.browser.new_context(**context_options)
if config.stealth:
await self._apply_stealth()
self.page = await self.context.new_page()
self.state = AgentState.IDLE
logger.info("Browser Agent 初始化成功")
return True
except Exception as e:
logger.error(f"初始化失败: {e}")
self.state = AgentState.ERROR
return False
async def _apply_stealth(self):
"""应用反检测脚本"""
await self.context.add_init_script("""() => {
Object.defineProperty(navigator, 'webdriver', { get: () => false });
const originalToDataURL = HTMLCanvasElement.prototype.toDataURL;
HTMLCanvasElement.prototype.toDataURL = function(...args) {
const ctx = this.getContext('2d');
if (ctx) {
const imageData = ctx.getImageData(0, 0, this.width, this.height);
for (let i = 0; i < imageData.data.length; i += 4) {
imageData.data[i] += Math.random() * 0.0001;
}
ctx.putImageData(imageData, 0, 0);
}
return originalToDataURL.apply(this, args);
};
Object.defineProperty(navigator, 'languages', { get: () => ['zh-CN', 'zh', 'en-US', 'en'] });
}""")
async def execute(self, instruction: str) -> ActionResult:
"""执行自然语言指令"""
if not self.page:
return ActionResult(success=False, message="Agent 未初始化")
try:
self.state = AgentState.EXECUTING
actions = self.parser.parse(instruction)
if not actions:
return ActionResult(success=False, message=f"无法解析指令: {instruction}")
result = ActionResult(success=True, message="执行成功")
for action in actions:
result = await self._execute_action(action)
if not result.success:
break
self.state = AgentState.IDLE
return result
except Exception as e:
logger.error(f"执行异常: {e}")
self.state = AgentState.ERROR
return ActionResult(success=False, message=str(e), error=e)
async def _execute_action(self, action: dict) -> ActionResult:
"""执行单个动作"""
action_type = action["type"]
if action_type == "navigate":
target = action.get("target", "")
if not target.startswith(("http://", "https://")):
target = "https://" + target
try:
await self.page.goto(target, wait_until="domcontentloaded", timeout=30000)
return ActionResult(success=True, message=f"导航到 {target}")
except Exception as e:
return ActionResult(success=False, message=str(e), error=e)
elif action_type == "click":
target = action.get("target", "")
try:
# 尝试多种定位方式
locator = self._create_locator(target)
await locator.click(timeout=10000)
return ActionResult(success=True, message=f"点击 {target}")
except Exception as e:
return ActionResult(success=False, message=str(e), error=e)
elif action_type == "input":
field = action.get("field", "")
value = action.get("value", "")
try:
locator = self._create_locator(field)
await locator.clear()
await locator.fill(value)
return ActionResult(success=True, message=f"输入 {value}")
except Exception as e:
return ActionResult(success=False, message=str(e), error=e)
elif action_type == "wait":
duration = action.get("duration", 1000)
await asyncio.sleep(duration / 1000)
return ActionResult(success=True, message=f"等待 {duration}ms")
elif action_type == "screenshot":
path = f"screenshot_{int(time.time())}.png"
await self.page.screenshot(path=path, full_page=True)
return ActionResult(success=True, message=f"截图保存到 {path}", data=path)
elif action_type == "extract":
target = action.get("target", "")
try:
locator = self._create_locator(target)
texts = await locator.all_text_contents()
return ActionResult(success=True, message="提取成功", data=texts)
except Exception as e:
return ActionResult(success=False, message=str(e), error=e)
return ActionResult(success=False, message=f"未知动作: {action_type}")
def _create_locator(self, target: str):
"""创建元素定位器"""
# 尝试不同的定位策略
locators = [
self.page.get_by_text(re.compile(target, re.I)),
self.page.get_by_role("button", name=re.compile(target, re.I)),
self.page.get_by_label(re.compile(target, re.I)),
self.page.get_by_placeholder(re.compile(target, re.I)),
self.page.locator(f"#{target}"),
self.page.locator(f".{target}"),
self.page.locator(f"[name='{target}']"),
self.page.locator(target),
]
# 返回第一个能匹配到的定位器
for loc in locators:
try:
if loc.count() > 0:
return loc
except:
continue
# 最后返回原始选择器
return self.page.locator(target)
async def close(self):
"""关闭 Agent"""
if self.page:
await self.page.close()
if self.context:
await self.context.close()
if self.browser:
await self.browser.close()
if self.playwright:
await self.playwright.stop()
self.state = AgentState.STOPPED
logger.info("Browser Agent 已关闭")
# 使用示例
async def main():
"""主函数"""
agent = BrowserAgent()
# 初始化
if not await agent.initialize(BrowserConfig(headless=True)):
print("初始化失败")
return
# 执行操作
result = await agent.execute("打开 https://www.baidu.com")
print(f"导航结果: {result.success}")
if result.success:
result = await agent.execute("在搜索框输入 'Playwright'")
print(f"输入结果: {result.success}")
result = await agent.execute("点击 百度一下")
print(f"点击结果: {result.success}")
await agent.execute("截图")
# 关闭
await agent.close()
if __name__ == "__main__":
asyncio.run(main())B. 常用选择器速查表
场景 | Playwright 选择器 | XPath |
|---|---|---|
按文本 | get_by_text("文本") | //*[text()="文本"] |
按角色 | get_by_role("button") | //button |
按标签 | locator("button") | //button |
按ID | locator("#id") | //*[@id="id"] |
按类 | locator(".class") | //*[contains(@class, "class")] |
按属性 | locator("[name='n']") | //*[@name='n'] |
按占位符 | get_by_placeholder("输入") | //*[@placeholder="输入"] |
按标签文本包含 | get_by_text(re.compile("包含")) | //*[contains(text(), "包含")] |
Shadow DOM | locator("::-p-ashadow") | N/A |
兄弟元素 | locator("button").locator("..") | //button/following-sibling::* |
C. 常见问题排查
问题 | 原因 | 解决方案 |
|---|---|---|
元素找不到 | 选择器错误/页面未加载 | 增加等待、使用更稳定的定位器 |
点击无效 | 元素不可点击/被遮挡 | 使用 force=True、先滚动到可见区域 |
输入丢失 | 事件未触发 | 使用 press_sequentially 或手动触发 input 事件 |
页面卡死 | 网络请求挂起 | 设置 wait_until="domcontentloaded"、禁用网络拦截 |
内存泄漏 | 上下文未关闭 | 确保调用 browser.close()、限制并发数量 |
关键词: Browser Agent、Web 自动化、Playwright、Selenium、Puppeteer、元素定位、DOM 解析、页面状态管理、表单操作、反爬虫、验证码识别、浏览器指纹

在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-06-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号