【AI Agent实战】不用视频生成模型,小白用小龙虾0成本处理视频

【AI Agent实战】不用视频生成模型,小白用小龙虾0成本处理视频

用户1589488
发布于 2026-06-02 12:57:03
发布于 2026-06-02 12:57:03
🦞 养虾系列- · 真实场景下用 AI Agent 解决工作问题的实战记录第15篇目标:自从养虾之后,利用小龙虾做了不少事情,也持续分享实操案例;视频一直是我想要尝试的领域;今天我们就来一起看看。 |
|---|
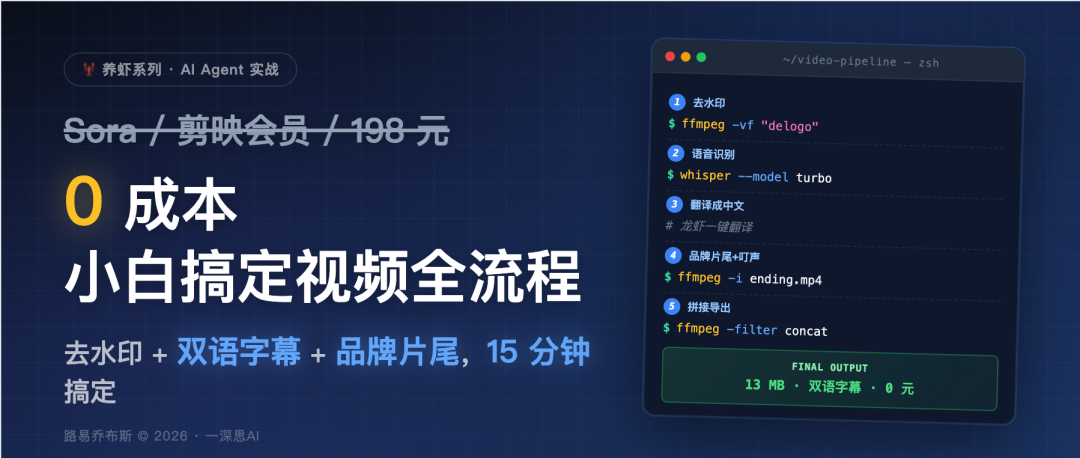
从「一个带水印的英文视频」到「去水印+中英双语字幕+自定义品牌片尾+叮声音效」的完整成品,全程没打开任何视频剪辑软件,没买任何会员,没调用任何视频生成大模型。只用了一只龙虾、一条 ffmpeg 命令行、一个本地 whisper 模型。

- •bold: 小白 0 成本把英文视频做成带品牌片尾的中文视频
- •subtitle: 不用 Sora、不用 Runway、不用剪映会员,全程命令行+本地模型
- •strikethrough: 花 198 买剪映专业版 → 学习 3 小时剪辑软件 → 导出还带水印
- •highlight: 关键不是"用什么工具",是"把视频处理拆成 ffmpeg 能懂的原子操作"
PART01
为什么这篇值得看
你手头有一个视频,想做四件事:
- •去掉右下角那个烦人的 NotebookLM 水印
- •加上中英双语字幕(视频是英文的,你想发中文受众)
- •把结尾替换成自己的品牌片尾(带二维码、带叮声)
- •还得保持原画质、原音频不失真
传统方案:打开剪映/Premiere/DaVinci,一个一个拖时间轴,每个效果一个面板,字幕一句一句对齐,三小时起步。
我刚才花了多少时间?从"这个视频"到"成品"一共 15 分钟。其中 10 分钟是 whisper 第一次下载模型。真正的处理时间:5 分钟。
龙虾的工作路径是这样的:
输入: Building_Your_AI_Assistant.mp4 (36MB, 英文, 带水印)
↓
[ffmpeg delogo] 模糊遮盖水印
↓
[whisper turbo] 识别英文语音 → SRT
↓
[直接翻译] 英文 SRT → 中文 SRT → 双语 SRT
↓
[ffmpeg overlay] 截取主体 + 拼接自定义片尾
↓
[ffmpeg concat] 合成最终视频
↓
输出: Building_Your_AI_Assistant_最终版.mp4 (13MB, 双语, 带品牌片尾)PART02
先看结果
项目 | 原视频 | 最终视频 |
|---|---|---|
大小 | 36 MB | 13 MB(压缩 3 倍) |
时长 | 7 分 39 秒 | 7 分 35 秒 |
水印 | NotebookLM 右下角 | 已去除 |
字幕 | 无 | 中英双语软字幕 |
片尾 | NotebookLM 默认片尾 | 一深思AI 品牌片尾+二维码+叮声 |
花费 | —— | 0 元 |
用时 | —— | 5 分钟(不含模型下载) |
视频没法在文章里放,但你可以相信——这四件事,命令行都能干。
PART03
准备工作:你需要什么
一台 Mac 或 Linux(Windows 也行,命令稍有不同)。然后装两个东西:
PROMPT🤖
# 装 ffmpeg(视频处理瑞士军刀) brew install ffmpeg
>
pip3 install openai-whisper
完事。不需要 API key,不需要联网(whisper 模型下载后完全本地跑),不需要账号。
💡小白提示
ffmpeg 是这篇文章的主角。它是一个命令行工具,一行命令能替代 90% 剪辑软件的功能。学会它你就能处理任何视频。 whisper 是 OpenAI 2022 年开源的语音识别模型,turbo 版本准确度接近 large-v3 但速度快 3 倍,完全免费,完全本地。
PART04
Step 01:去水印——ffmpeg 的 delogo 滤镜
STEP01搞清楚水印在哪
先提取视频里的一帧,人肉确认水印坐标
# 截取视频第 19 秒的画面保存为 PNG
ffmpeg -ss 19 -i input.mp4 -vframes 1 frame.png打开 frame.png,用系统自带的预览工具量一下水印在哪。我这个视频是 1280×720,NotebookLM 在右下角,大概位置:
- •左上角坐标:
x=1100, y=650 - •宽高:
w=160, h=50
STEP02用 delogo 滤镜模糊覆盖
ffmpeg 的 delogo 滤镜会用周围像素插值填补这个矩形区域,视觉上像是"糊掉了"
ffmpeg -i input.mp4 -vf "delogo=x=1100:y=650:w=160:h=50" -c:a copy output.mp4解读这条命令:
输入文件✨为什么不直接裁剪
因为裁剪会改变视频尺寸(1280×720 → 1280×670),上传平台会被识别为"非标尺寸"。delogo 保持原尺寸,肉眼看就是一片轻微模糊,但不影响观看。
PART05
Step 02:语音识别——whisper turbo
STEP01先把音频抠出来
whisper 吃的是音频文件不是视频,虽然它也能直接读视频但单独抠音频更省内存
# 提取 16kHz 单声道 WAV(whisper 最友好的格式)
ffmpeg -i input.mp4 -vn -acodec pcm_s16le -ar 16000 -ac 1 audio.wav- •
-vn:no video,丢掉视频流 - •
-ar 16000:采样率 16kHz(whisper 内部就是这个采样率,省了它自己重采样) - •
-ac 1:单声道
STEP02跑 whisper 识别
turbo 是目前最推荐的模型——大模型级别的准确度,small 级别的速度
whisper audio.wav --model turbo --language en --output_format json --output_dir .为什么 turbo 是最佳选择:
模型 | 参数量 | 速度 | 准确度 | 第一次下载 |
|---|---|---|---|---|
tiny | 39M | 极快 | 一般 | 75MB |
small | 244M | 快 | 可用 | 466MB |
medium | 769M | 中 | 好 | 1.5GB |
large-v3 | 1550M | 慢 | 最好 | 3GB |
turbo | 809M | 快(接近 small) | 接近 large | 1.5GB |
第一次跑会下载模型到 ~/.cache/whisper/,之后就秒起。我这个 7 分 40 秒的视频,识别花了 5 分钟。
输出是一个 JSON 文件,里面有每一段话的起止时间和识别出的文本。转成 SRT 标准字幕格式只要几行 Python:
PROMPT🤖
import json def ts(s): h, m = int(s // 3600), int((s % 3600) // 60) return f'{h:02d}:{m:02d}:{s%60:06.3f}'.replace('.', ',') data = json.load(open('audio.json')) lines = [f'{i}\n{ts(seg["start"])} --> {ts(seg["end"])}\n{seg["text"].strip()}\n' for i, seg in enumerate(data['segments'], 1)] open('en.srt', 'w').write('\n'.join(lines))
PART06
Step 03:翻译——这一步我作弊了
最简单的方案是直接让 AI 帮你翻译整个 SRT 文件。
我的做法:把 en.srt 整个扔给龙虾,让他逐条翻译成中文。AI 领域的术语(LLM/token/context/agent/prompt)保留英文原词加中文解释,这样反而更清晰。
💡这一步的效率秘诀
不要一条一条翻译。把整个 SRT 扔给 AI,让它保持时间戳不变,只替换文本行。一次对话搞定 134 条字幕翻译。 如果你不想用 AI,可以考虑 DeepL API(50 万字符/月免费)或者 Google Translate Python 库,效果都不错。
翻译完得到 zh.srt,然后合并成双语 SRT(中文在上、英文在下):
# 合并双语字幕:把 en.srt 和 zh.srt 的同一条记录拼起来
for i in range(len(en_entries)):
idx, timing, en_text = en_entries[i]
zh_text = zh_entries[i][2]
# 关键:中文在第一行(下方渲染更显眼),英文在第二行
bilingual.append(f'{idx}\n{timing}\n{zh_text}\n{en_text}\n')PART07
Step 04:做一个自己的片尾
原视频最后几秒是 NotebookLM 的默认片尾——有 logo、有 CTA。我们要替换成自己的。
STEP01先做一张静态片尾图
用 HTML+Chrome headless 生成,完全可控的排版
写一个 ending.html(1280×720,深蓝科技风,品牌文字+二维码),然后:
"/Applications/Google Chrome.app/Contents/MacOS/Google Chrome" \
--headless --disable-gpu --window-size=1280,720 \
--screenshot=ending.png file://ending.html✨为什么不直接用 Canva 或 Figma
因为我们要的是 完全可编程 的流程。HTML 改个字、换个二维码就能重新生成,不需要打开任何 GUI 软件。下次做第二个视频直接复用模板。
STEP02合成"叮"音效
ffmpeg 可以直接生成正弦波音频,加点回声就是标准的提示音
ffmpeg -f lavfi -i "sine=frequency=1200:duration=0.4" \
-af "volume=0.7,aecho=0.8:0.9:60:0.3,afade=t=in:st=0:d=0.005,afade=t=out:st=0.2:d=0.2" \
-ar 44100 -ac 1 ding.wav拆解一下:
生成 1200Hz 正弦波,时长 0.4 秒STEP03把静态图+叮声合成 5 秒视频
loop 参数让静态图重复 5 秒变成视频流
# 先做一个 5 秒的音频:前面响叮声,后面是静音
ffmpeg -f lavfi -i anullsrc=r=44100:cl=mono:d=5 -i ding.wav \
-filter_complex "[0:a][1:a]amix=inputs=2:duration=first" \
ending-audio.wav
# 然后静态图+音频合成 5 秒视频
ffmpeg -loop 1 -i ending.png -i ending-audio.wav \
-c:v libx264 -t 5 -pix_fmt yuv420p -r 24 \
-c:a aac -shortest ending.mp4PART08
Step 05:拼接主视频 + 片尾
STEP01去水印 + 截到 7:30
原视频最后 9 秒是 NotebookLM 片尾,直接砍掉
ffmpeg -i input.mp4 -t 450 \
-vf "delogo=x=1100:y=650:w=160:h=50" \
-c:v libx264 -preset fast -c:a aac -r 24 \
main.mp4- •
-t 450:只截取前 450 秒(7 分 30 秒) - •
-preset fast:编码预设,平衡速度和文件大小 - •
-r 24:固定帧率 24fps(和片尾保持一致)
STEP02concat 拼接
ffmpeg 的 concat filter 要求两段视频的编码参数一致(分辨率、帧率、采样率),所以上一步统一成了 1280×720/24fps/44.1kHz
ffmpeg -i main.mp4 -i ending.mp4 \
-filter_complex "[0:v][0:a][1:v][1:a]concat=n=2:v=1:a=1[v][a]" \
-map "[v]" -map "[a]" \
-c:v libx264 -c:a aac \
final-no-subs.mp4💡concat 的坑
如果两段视频的编码参数不一致(比如一段是 30fps、一段是 24fps),concat 会报错或者拼接处卡顿。解决方案有两个:统一参数重编码(上一步就是这么做的)或者用 concat demuxer(适合参数已经一致的场景)。
PART09
Step 06:挂载双语字幕
最后一步——把字幕文件挂载到视频里。
ffmpeg -i final-no-subs.mp4 -i bilingual.srt \
-c:v copy -c:a copy -c:s mov_text \
-metadata:s:s:0 language=zho \
-metadata:s:s:0 title="中英双语" \
Building_Your_AI_Assistant_最终版.mp4- •
-c:s mov_text:MP4 容器里的字幕编码格式 - •
-metadata:s:s:0:给字幕流打标签,播放器才能识别
✨软字幕 vs 硬字幕
软字幕:嵌入视频容器,可开关。QuickTime/VLC/Chrome 原生支持。优点是原画质不受损、字幕可单独提取翻译。缺点是上传到抖音/视频号可能不显示(因为平台会重编码)。硬字幕:直接画在画面上,不可关闭。优点是所有平台 100% 显示。缺点是画面上多一层字幕,无法再改。 建议做双份:软字幕版自己存档和发 B 站,硬字幕版发抖音/视频号。
PART10
完整流程的 SOP
我把整个流程抽象成一个可复用的模板。下次遇到类似需求:
┌─────────────────────────────────────┐
│ 1. 探测:ffprobe 看视频参数 │
│ → 尺寸、时长、音频格式 │
├─────────────────────────────────────┤
│ 2. 定位:ffmpeg -ss N -vframes 1 │
│ → 截图人肉确认水印坐标 │
├─────────────────────────────────────┤
│ 3. 提音:ffmpeg -vn → whisper │
│ → 识别 → JSON → 转 SRT │
├─────────────────────────────────────┤
│ 4. 翻译:把整个 SRT 扔给 AI │
│ → 保持时间戳、替换文本 │
│ → 合并为双语 SRT │
├─────────────────────────────────────┤
│ 5. 片尾:HTML → PNG → ending.mp4 │
│ → 叮声 sine + aecho + fade │
├─────────────────────────────────────┤
│ 6. 拼接:delogo + cut + concat │
│ → 注意编码参数统一 │
├─────────────────────────────────────┤
│ 7. 字幕:-c:s mov_text 挂载 │
│ → 软字幕可开关 │
└─────────────────────────────────────┘我把这套流程封装成了一个 Skill,名字叫 video-watermark-remover(其实它已经不只是去水印了)。下次需要时,一句"把这个视频做成带字幕的"就能跑完全流程。
PART11
小白常见问题
Q1:没装过 whisper,第一次跑会很慢吗?
会。turbo 模型 1.5GB,第一次下载要 5-10 分钟。之后就秒起了。建议你安装完的第一件事就是先跑一个 10 秒小音频触发下载,别等到真要用的时候才发现在下载。
Q2:我不想学命令行行不行?
行。把这篇文章整个扔给 ChatGPT 或 Claude,然后说"帮我把 /path/to/my/video.mp4 做成带中文字幕的"。AI 会问你几个问题(水印在哪、视频是什么语言、要不要片尾),然后一条条命令敲给你。你就是那个只会复制粘贴的人。
Q3:视频识别不准怎么办?
几种情况:
- •如果是中文内容:
--language zh显式指定语言 - •如果是中英混合:用 medium 或 large-v3(turbo 对混合语种识别一般)
- •如果背景音乐大:先用
ffmpeg -af "highpass=f=200,lowpass=f=3000"过滤频段再识别 - •如果是方言:对不起,whisper 搞不定,换 PaddleSpeech 或者找专业转录服务
Q4:为什么是 ffmpeg 不是剪映?
因为 ffmpeg 免费、开源、可脚本化、所有参数可调。剪映是给"用鼠标点"的人用的,ffmpeg 是给"用脑子想"的人用的。
一旦你能用命令行做视频处理,你就能:
- •批量处理 100 个视频(剪映你试试)
- •写脚本自动化(剪映你试试)
- •在服务器上跑(剪映你试试)
- •嵌入到 Agent 的工作流里(剪映你试试)
这才是 AI Agent 时代的姿势。
PART12
三条硬结论
- •视频处理不需要视频生成大模型。Sora/Runway 是用来"创造"视频的。你要"处理"视频,用 ffmpeg 就够。
- •学会一条 ffmpeg 命令,胜过买十个剪辑软件会员。会员是按订阅收费的,命令行是你的永久资产。
- •小白的突破口,是把"复杂流程"拆成"原子命令"。剪映把 20 个命令封装成一个按钮,看起来简单,但你永远不知道里面发生了什么;ffmpeg 让你看清每一步,你就掌握了这个工作流。
PART13
附:配套资源
- •Skill 文件:
.codebuddy/skills/video-watermark-remover/(含 SKILL.md + 自动化脚本) - •完整命令清单:本文所有代码块都可以复制直接跑
- •示例视频:
Building_Your_AI_Assistant.mp4+Building_Your_AI_Assistant_最终版.mp4对比
下次想发视频前,先问一句:「这事 ffmpeg 能不能干?」90% 的情况是能。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号