Nature登文——一款自动化科学发现的多智能体系统

Nature登文——一款自动化科学发现的多智能体系统

乐小野
发布于 2026-06-02 19:24:50
发布于 2026-06-02 19:24:50
一款2014年上市的青光眼眼药水,被一套三Agent系统改写成了治失明的新药
📌 先讲清楚 Robin不是一个单一的模型,它是一套4阶段、3 Agent的pipeline。它的真正价值不在AI做出了发现,而在三个工程决策,pairwise + Elo替代LLM-as-judge、Jupyter kernel作为tool接口、Falcon-Crow分工的两类RAG。这三件事的可迁移性远比Ripasudil本身重要。
按理说一款2014年在日本上市、原本只用来治青光眼的眼药水,不该在2026年的Nature上被重新讲一次。
但5月19日Nature挂出来的这篇论文里,FutureHouse的Robin系统就把这件事干成了。Robin盯上的是干性年龄相关性黄斑变性(dAMD),全球约2亿患者,目前没有任何能恢复视力的药。它给出的答案是 Ripasudil,一种ROCK激酶抑制剂,2014年在日本以青光眼药物Glanatec名义上市,从未有任何文献提过它能治dAMD。
真正的看头在Robin这套系统的工程选型,特别是它怎么把 读文献+生成假设+排序+实验设计+数据分析 这条本来由人类博士后串起来的工作流,拆解成三个分工明确的Agent,再用一个非平凡的排序算法把质量稳住。
🧭 Robin的总体架构
Robin是一个 4阶段编排系统,三个领域Agent加一个Orchestrator,三个Agent通过 LiteLLM 接入多模型后端,主用 GPT-4o,部分综述任务用 Claude 3.5 Sonnet。
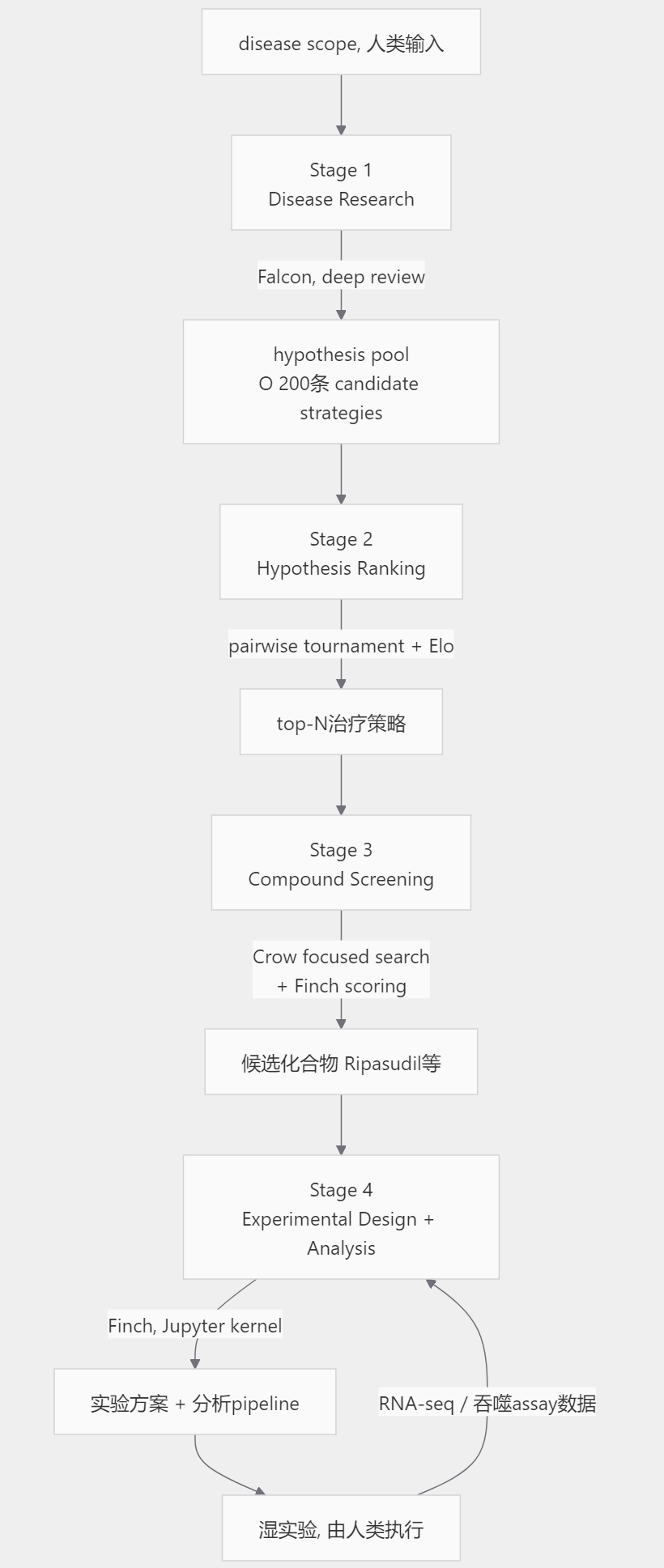
四阶段不是单向流水线,Stage 4跑完一轮实验,数据回灌到Stage 1的hypothesis pool,整个loop多轮迭代。Robin端到端跑一次发现周期约 2.5个月,Stage 1+2这个核心子任务跑了 2小时,论文Extended Data里给出的人类博士后等价工作量是 937小时。
💡 工程要点 Robin的端到端时长卡在湿实验环节而不是Agent推理。Agent部分的wall-clock是分钟级到小时级,实验执行才是周级到月级。这个比例决定了未来短期内Robin类系统的迭代速度上限不在算力,在湿实验自动化。
🦅 Crow vs Falcon, 两个文献Agent的设计动机
很多人会觉得同时挂Crow和Falcon是冗余,实际上这是FutureHouse在 PaperQA2 上做的明确分工,处理两类截然不同的检索负载。
Agent | 任务类型 | 典型问题 | 输出 | RAG loop轮数 |
|---|---|---|---|---|
Crow | focused search | 「Y-27632在RPE吞噬功能上有哪些已发表证据」 | 3-10篇高相关文献 + 引文锚定回答 | 2-3轮 |
Falcon | deep search | 「dAMD发病机理中可干预的细胞功能障碍有哪些」 | 跨百篇文献的综述 | 不固定,按gap迭代 |
两个Agent底层共用PaperQA2,调度的tool和prompt完全不同。PaperQA2自身的工具集是 Search Papers、Gather Evidence、Generate Answer 三件套。
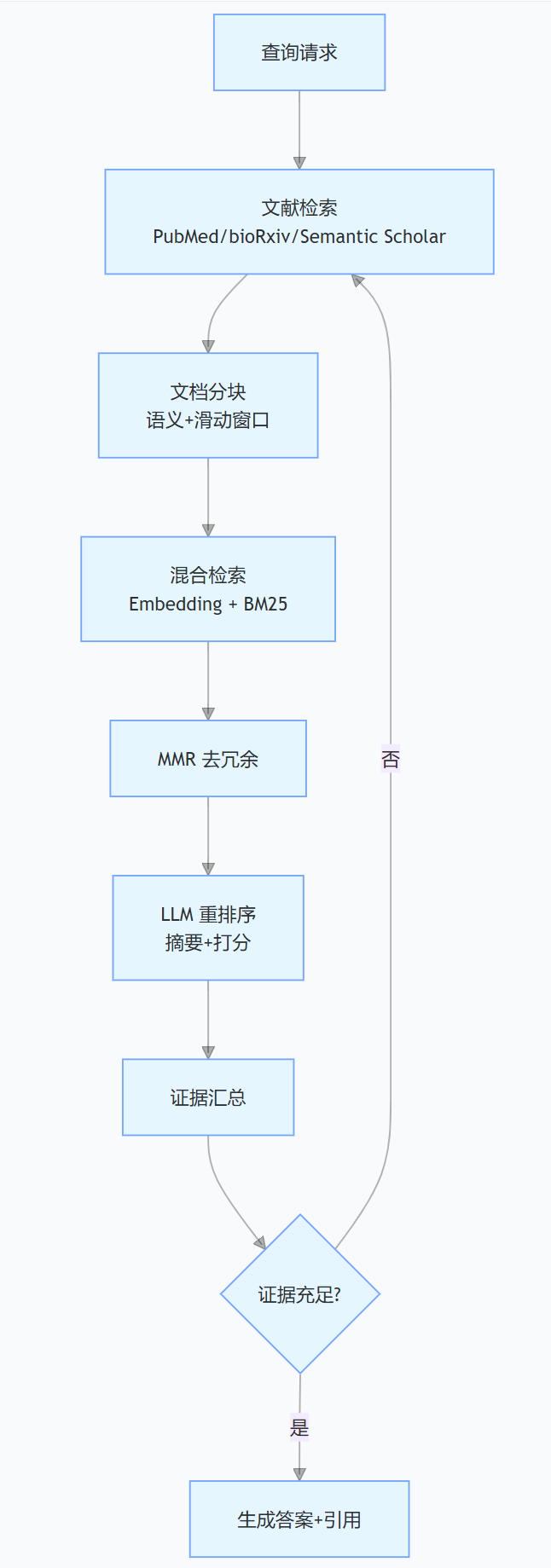
Falcon的关键不在retrieval本身,在它把Gather Evidence设计成可反复触发,每轮根据证据池的gap自动重写query,是一个agentic loop而不是单次RAG。Crow把整个loop压在2到3轮以内,控制延迟。
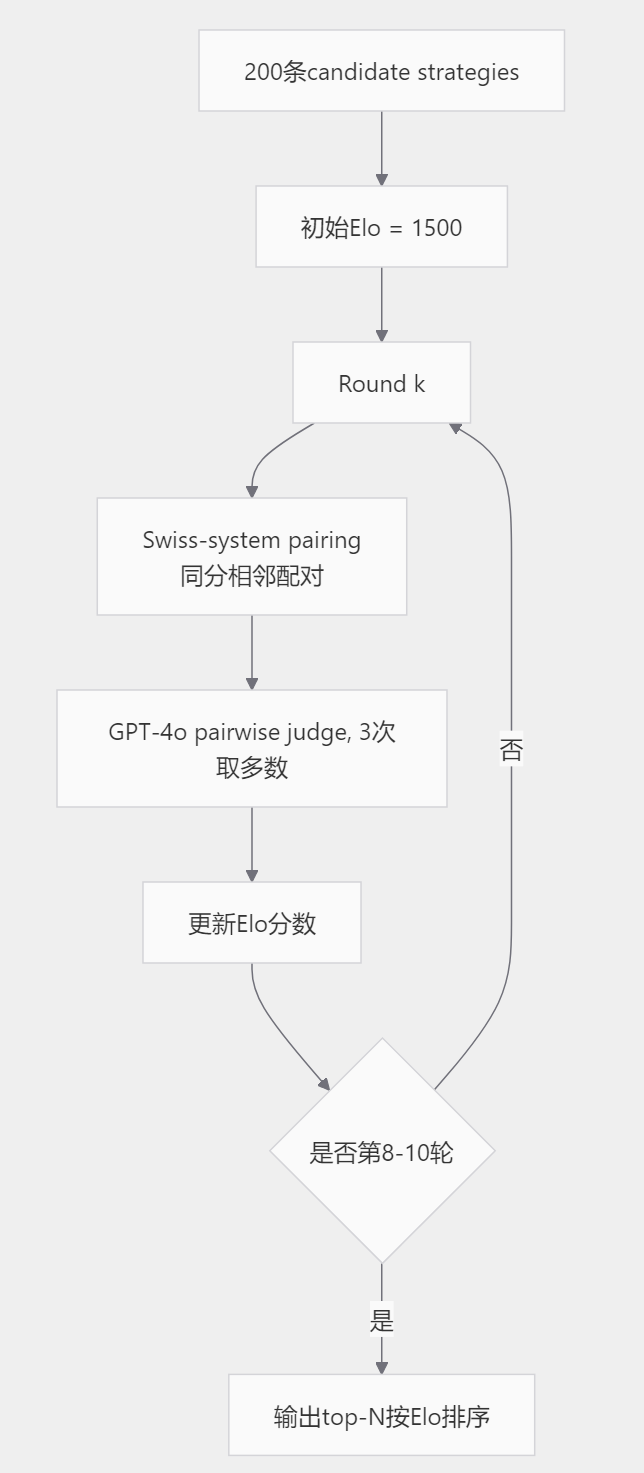
⚖️ 排序算法, 为什么Robin选了pairwise + Elo
这一段是整篇论文里对AI工程师最有借鉴意义的部分。
Robin在Stage 1结束后会拿到一个 100到200条的candidate strategies池。要从中选出top-N给后续阶段,最直觉的做法是 LLM-as-judge打分,每条让模型给一个1到10的得分。Robin开发过程中早期版本试过这个方案,结论是不可用。
原因有两个。
⚠️ LLM-as-judge的两个硬伤
- 1. 校准失败,LLM对绝对分数的校准能力极差,同一条假设跑10次能拿到3到9分的差异。
- 2. 位置污染,分数受prompt里其他候选项的顺序影响,position bias明显。
Robin选的是 pairwise comparison + Elo ranking。每两条假设拿出来让GPT-4o做一次「哪个更有希望」的判断,每场记录胜负,最后把胜负序列转成Elo分数。这套思路borrowed自Chatbot Arena的人类偏好评测。
工程上做了两个优化。
🎯 优化一:Swiss-system tournament pairwise的全排列是 O(N²),200条假设要做19900场比较不可接受。Robin用Swiss-system tournament,每轮按当前Elo做匹配,跑8到10轮就能稳定top-N,比较次数压到 约2000场。
🎯 优化二:3-run majority voting 每场比较跑3次取多数,缓解GPT-4o自身的非确定性。
💡
可迁移性
这个设计的隐含假设是「成对偏好比绝对评分更稳」,跟RLHF同构。Robin论文里没特别强调,但这是整套系统能稳定输出的关键。换成LLM-as-judge打绝对分,同样的pipeline跑出来Ripasudil不一定能进top-10。
🐦 Finch, 把Jupyter当tool calling接口
Finch是三个Agent里架构最特殊的,它的执行环境就是一个 Jupyter内核。
主流的代码执行Agent(OpenAI Code Interpreter、Claude Code、Devin)都用 sandbox + bash + Python 这套组合。Robin Finch的差异在把Jupyter notebook的cell执行模型直接暴露给LLM,每个tool call对应一个cell,cell之间共享kernel state。
这个选择带来三个好处。
好处 | 说明 |
|---|---|
state持久化 | LLM可以在第N次调用时直接reference前N-1次产生的DataFrame或模型对象 |
输出无损回灌 | 每个cell的stdout和图像输出可以无损回灌给LLM做下一步推理,对matplotlib图形输出特别友好 |
错误恢复成本低 | 一个cell挂了局部修复,不用重置整个session |
Finch的tool call schema大致长这样。
1
2
3
4
5
{
"tool": "execute_cell",
"code": "df = pd.read_csv('rpe_phagocytosis.csv')\nprint(df.describe())",
"expected_outputs": ["dataframe summary", "potential issues"]
}
Finch执行后把stdout、错误、图像base64塞回context,模型基于这些决定下一步是画图、跑t-test还是建议新实验。论文Extended Data里一个完整Finch trace有 43个cell,从加载bulk RNA-seq数据一路跑到火山图+GO富集分析+下一轮experimental design,全程没有人工介入。
🧪 Stage 4的实验设计自动化
Stage 3挑出Ripasudil之后,Stage 4要回答两个问题,用什么in vitro model验证、用什么实验终点。
Robin的in vitro model selection逻辑是Falcon先做综述,列出dAMD研究里常用的模型(iPSC-RPE、ARPE-19、原代猪RPE、小鼠模型),再让Finch按可获得性、文献成熟度、与人类生理相关性三个维度打分,最后选 iPSC-RPE。
实验终点的选择更精彩。Robin从假设链反推:
🔗 假设链 ROCK抑制剂改善RPE细胞骨架重组 → 恢复吞噬功能 → 减缓drusen沉积
确定核心终点是「RPE对外节膜盘碎片的吞噬效率」,对应的标准assay是 pHrodo-labeled photoreceptor outer segment phagocytosis。
实验做完之后,Finch直接接管RNA-seq数据。Robin报告Ripasudil处理组中 ARHGEF18、ABCA1 等多个细胞骨架和脂质转运相关基因显著上调,吻合ROCK抑制释放actin cytoskeleton重组的预期机制。整个 from-data-to-mechanism 的解释链条由Finch自动产出。
🆚 与同类系统对比
把Robin放到2024到2026年这一波AI for science工作里横向比,差异主要在三个维度。
系统 | 发布时间 | 目标领域 | 编排方式 | 关键算法选择 | 端到端验证 |
|---|---|---|---|---|---|
Sakana AI Scientist v1 | 2024.08 | ML研究 | 单Agent循环 | LLM自打分 | 无湿实验,论文质量被诟病 |
DeepMind Co-Scientist | 2025.02 | 通用生物医学 | 多Agent辩论 | multi-agent debate | 仅benchmark集验证 |
Stanford Virtual Lab | 2025.03 | 蛋白设计 | 角色扮演多Agent | 自由对话 | 部分湿实验,无新发现 |
FutureHouse Robin | 2025.05 preprint / 2026.05 Nature | 药物repurposing | 4-stage pipeline + 三专用Agent | pairwise + Elo | 完整湿实验, 新治疗假设 |
Robin的工程胜负手有三个。
1️⃣ pipeline结构化 而不是agent debate,可调试可复现。 2️⃣ pairwise + Elo的排序算法 回避了LLM绝对评分不可靠的硬伤。 3️⃣ drug repurposing任务设计 给了Robin一个相对窄的搜索空间(已批准化合物约2000个),让Stage 3的compound screening可解。
📅 同期对照 5月19日Nature连发Robin、Carl(Lila Sciences)、Coscientist(CMU)三篇AI scientist论文,Robin是其中唯一一个在末端给出可直接进入临床的候选药。
🐛 失败模式与自检机制
论文里没回避失败模式,开发过程中累积的可复现错误大致分三类。
❌ 错误类型1, 文献幻觉 Falcon写综述时偶尔生成不存在的paper title。 兜底机制:Crow做交叉验证,每条引用都被强制要求能在 PubMed 或 Semantic Scholar API 里命中真实record,不命中即丢弃。
❌ 错误类型2, 统计错误 Finch跑t-test或多重比较时出过p值计算错误。 兜底机制:Finch内部的double-pass,第二次跑用不同的代码路径(例如
scipy.statsvsstatsmodels)做cross-check,结果不一致触发人类审核。❌ 错误类型3, 排序污染 pairwise比较时GPT-4o偶尔会被假设里的「热门关键词」(例如mTOR、senolytic)系统性偏好。 兜底机制:blind comparison,把假设里的具体药名和明星基因替换成代号再做比较,降低偏好bias。
这三类自检都不是100%可靠,论文明确指出Robin不能脱离人类终审,特别是涉及临床推荐的关键节点。
🇨🇳 落到产业侧
🧬 AI药企
英矽智能、晶泰、剂泰这一批AI药企过去两年的工作主要在分子生成和靶点预测,pipeline覆盖度跟Robin的「问题立项→候选→实验→机制」全链条还有差距。Robin代码已开源在 Future-House/robin,PaperQA2更早开源,国内复现+本土化适配的窗口期就在未来12个月。
🔬 CRO行业 中后台知识工作(文献综述、experimental design、bioinformatics分析)被自动化是确定的,倒过来纯湿实验执行能力会更值钱。药明康德这种重资产做湿实验和动物模型的公司护城河变深,做CRO informatics的中小公司压力会大。
🤖 国产基座模型 Robin这套pipeline对tool calling稳定性、长context连贯性、code执行精准性的要求都很高。Qwen3.7-Max和DeepSeek-R1目前在Berkeley Function Calling Leaderboard上跟GPT-4o还有差距,要支撑Robin级别的pipeline需要专门做science domain的SFT。
❓ 几个还没看清楚的点
🔍 复现成本 论文给的「2小时vs937小时」对照里人类组工作流细节没完全交代,第三方独立团队跑Robin的成功率与算力成本(论文未披露完整token账单)目前没有可靠数据。
🔍 临床有效性 Ripasudil在iPSC-RPE上的吞噬恢复是体外结果,从体外到III期临床历史成功率不到10%。从Robin给出假设到Ripasudil能不能真治dAMD,至少3到5年。
🔍 方法学迁移 dAMD是「文献厚、机制相对收敛、候选化合物可枚举」的Robin友好型问题。换到罕见病、新机制疾病、未知靶点场景,Robin的Stage 1 hypothesis pool质量会显著退化,pairwise排序也会因为信号稀疏失效。
🔍 合理但错误的因果链 Robin的兜底机制能抓事实性幻觉,但抓不住「证据链每一步都成立、整体推论错误」的case。这一类错误在医药领域代价极高,目前没有公开可用的检测方法。
✍️ 写在最后
🎯 真正的takeaway Robin不是一个具体药物的故事,是一个 pipeline工程模板。 把 pairwise + Elo替代LLM-as-judge、Jupyter kernel作为tool接口、Falcon-Crow分工的两类RAG 这三个工程决策抽出来,可以套用到任何「文献密集 + 假设排序 + 实验闭环」的科学发现领域。
我自己最关注的是Stage 2那个pairwise + Elo设计,这套思路同样适用于推荐系统的策略选择、AI产品的多方案评测、code review的自动化排序。Robin把它从评测领域搬到科研pipeline,这件事的可迁移性比Ripasudil本身更值得注意。
📚 References
- 1. Ghareeb, A. et al., A multi-agent system for automating scientific discovery, Nature, 2026-05-19, https://www.nature.com/articles/s41586-026-10652-y
- 2. arXiv preprint, Robin: A Multi-Agent System for Automating Scientific Discovery, 2025-05-20, https://arxiv.org/abs/2505.13400
- 3. FutureHouse官方研究公告, https://www.futurehouse.org/research-announcements/demonstrating-end-to-end-scientific-discovery-with-robin-a-multi-agent-system
- 4. PaperQA2开源仓库, https://github.com/future-house/paper-qa
- 5. Robin开源仓库, https://github.com/Future-House/robin
- 6. Skarlinski et al., Language agents achieve superhuman synthesis of scientific knowledge, FutureHouse PaperQA2论文, 2024
- 7. Sakana AI, The AI Scientist论文与代码, https://github.com/SakanaAI/AI-Scientist
- 8. DeepMind, Towards an AI Co-Scientist, https://deepmind.google/discover/blog/co-scientist
- 9. Swanson et al., The Virtual Lab of AI Agents, Stanford, 2025
- 10. Chatbot Arena, pairwise preference + Elo ranking方法论, https://lmarena.ai
- 11. NIH National Eye Institute, dAMD流行病学数据, https://www.nei.nih.gov/learn-about-eye-health/eye-conditions-and-diseases/age-related-macular-degeneration
- 12. Apellis Pharmaceuticals, Pegcetacoplan(Syfovre)dAMD治疗数据
- 13. Kowa Pharmaceutical, Ripasudil(Glanatec)2014年日本上市信息, https://www.pmda.go.jp
- 14. Berkeley Function Calling Leaderboard, https://gorilla.cs.berkeley.edu/leaderboard.html
- 15. The Scientist, An AI-Powered Scientist Proposes a Treatment for Blindness, https://www.the-scientist.com/an-ai-powered-scientist-proposes-a-treatment-for-blindness-73079
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号