深度原理发布材料基座模型MPA | 以物理对齐提升真实实验性质预测能力

深度原理发布材料基座模型MPA | 以物理对齐提升真实实验性质预测能力

DrugOne
发布于 2026-06-02 19:33:53
发布于 2026-06-02 19:33:53


材料基座模型的真正价值,最终取决于能否在真实实验数据和工业研发任务中稳定工作。
过去几年,AI4S领域在材料结构生成、性质预测和高通量筛选等方向取得了快速进展。许多模型已经能够在理论计算数据集和公开基准上取得较高精度。然而,从理论计算走向真实实验,仍然存在一条难以忽视的鸿沟。
一方面,第一性原理计算数据规模更大、质量更稳定,适合作为模型学习材料结构与性质关系的基础来源;另一方面,真实实验数据往往规模有限,并且包含测量误差、实验条件差异和工业任务中的特定约束。对于真正面向研发和生产的材料AI系统而言,仅在计算数据上取得好结果并不足够推动化学材料产业变革。

针对这一问题,「深度原理Deep Principle」提出了材料基座模型MPA(Materials Property Axiom)。MPA将大语言模型中已经被验证有效的多阶段训练思想引入材料性质预测,通过物理对齐训练和面向实验任务的模型结构设计,提升模型在真实实验性质预测中的泛化能力。
在40个真实实验性质预测任务上,MPA相比多个主流材料基座模型取得综合最优表现,并在其中35个任务上达到SOTA。尤其在更接近真实研发场景的骨架划分(scaffold split)条件下,MPA表现出更明显的优势。

从理论计算到真实实验的预测鸿沟
材料性质预测长期面临一个核心问题:模型在标准基准上表现良好,并不等于能够在真实实验任务中直接发挥作用。
理论计算数据通常来自统一的计算流程,数据形式较为规整,噪声相对可控。基于这类数据训练模型,有利于模型学习材料结构、原子相互作用和能量相关性质之间的基础关系。
但真实实验数据具有更复杂的来源。实验测量会受到样品制备、测试条件、仪器误差和数据记录方式的影响;工业场景中的预测目标,也往往不是单一标准化指标,而是与具体应用需求直接相关的综合性质。
因此,材料AI模型需要解决的不只是“从结构到性质”的映射问题,还需要在理论计算和真实实验之间建立更稳定的迁移能力。
这也是MPA模型设计的出发点:通过更加系统的训练流程,让模型不仅记住材料结构特征,也能够学习与真实性质预测相关的物理规律。
借鉴LLM三阶段训练,进行物理对齐
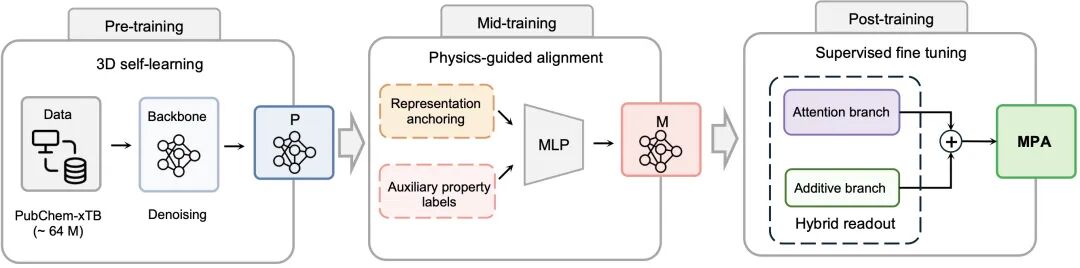
MPA的基础架构基于Transformer,可以分为“躯干”和“头”两部分。
其中,“躯干”是通用的图Transformer,用于学习和存储材料体系中的基础表征能力;“头”则根据不同训练阶段和任务目标进行调整,用于完成具体性质预测。
与以往材料基座模型常见的“先预训练再微调”流程不同,MPA在预训练和微调之间加入了一个关键阶段:mid-training。
在大语言模型的发展中,多阶段训练已经被证明是一条有效路径。预训练负责建立通用知识基础;中期训练进一步强化模型在通用任务上的能力;后训练和微调则用于适配具体任务。
MPA将这一思路迁移到材料性质预测中。预训练阶段让模型学习材料结构和基础化学知识;mid-training阶段则利用大规模计算数据和部分通用实验数据,对模型进行physics-guided alignment(物理引导的对齐)。
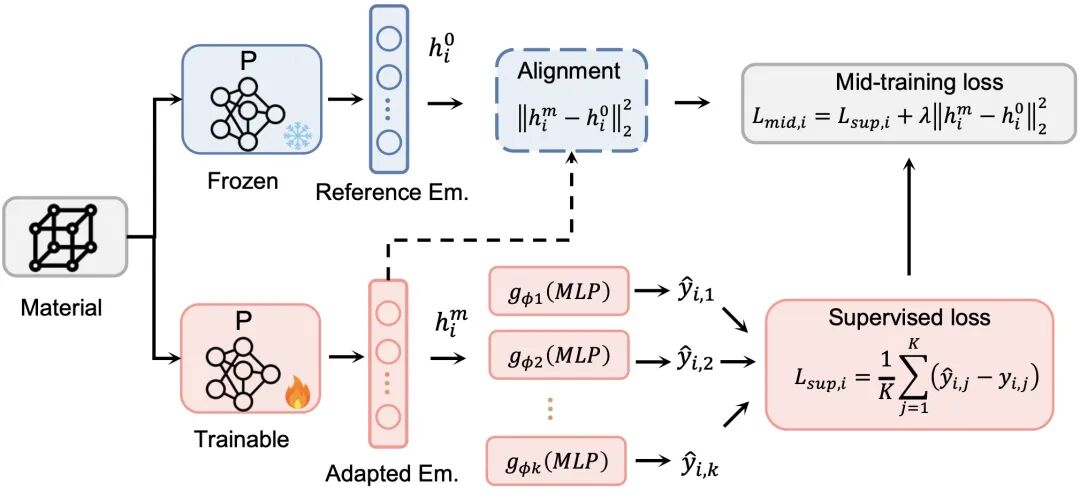
这一阶段的目的,是弥合理论结构表征与真实实验性质之间的差距。
对于材料模型而言,仅理解原子组成、键长、构型等结构信息是不够的。模型还需要进一步学习不同结构背后的物理规律,例如生成焓、偶极矩、热容等性质与局部结构和整体材料之间的关系。
第一性原理计算数据具有可规模化生成、噪声相对较低、物理含义明确等优势,因此适合作为mid-training阶段的核心数据来源。同时,接近实验精度的复核理论(composite theory)和通用性质的实验数据在mid-training也可发挥关键作用。通过这一过程,MPA可以在进入真实实验数据微调之前,先建立更强的物理归纳偏置。
Hybrid Readout:面向实验性质预测的后训练结构
除训练流程外,MPA的另一项关键设计,是在后训练阶段引入Hybrid Readout(混合读出)。
不同材料性质具有不同的物理结构。有些性质更依赖材料整体表征,例如沸点、生物活性等;另一些性质则具有更明显的加和特征,例如生成焓、燃烧焓、热容等,整体数值与各原子或局部结构贡献密切相关。
如果使用单一读出方式处理所有性质,模型需要同时学习两类差异很大的规律,训练难度和数据需求都会增加。
因此,MPA在后训练阶段设计了两条并行路径。
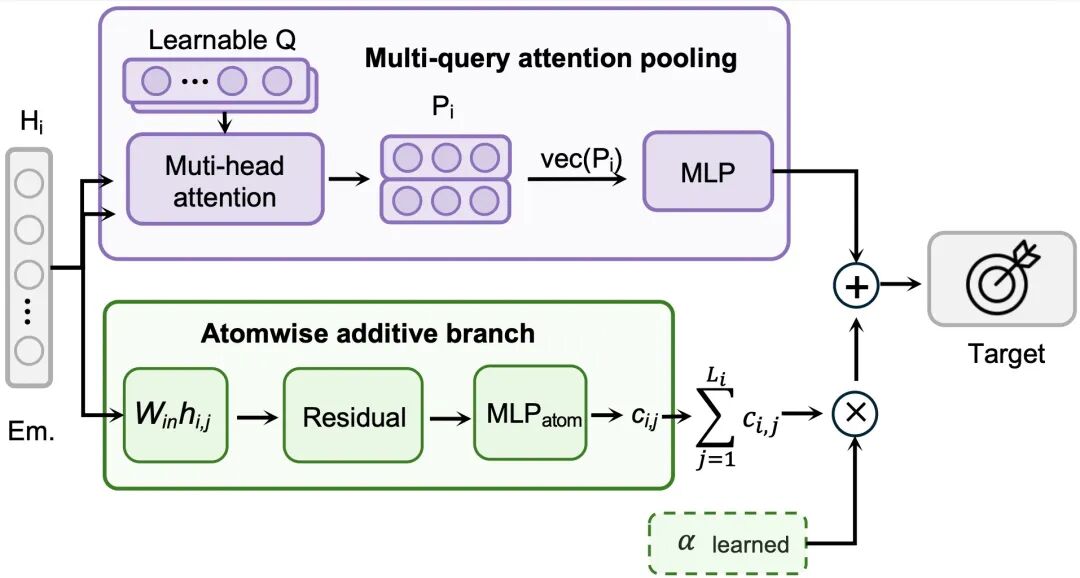
第一条路径是注意力池化(attention pooling)。模型通过注意力机制从全局角度读取材料信息,不对性质形式做强假设,适合处理更依赖整体结构和复杂相互作用的性质。
第二条路径是原子加和(atomic summation)。模型先预测每个原子的贡献,再将所有原子贡献相加,从结构上引入“整体性质由局部贡献累积而来”的物理约束。这种方式更适合处理具有加和特征的热力学性质。
MPA通过一个可训练参数α对两条路径进行融合,使模型能够针对不同性质自动调整读出方式。当任务更依赖整体表征时,模型可以更多使用注意力池化;当任务更符合局部贡献加和规律时,模型可以更依赖原子加和路径。
这种设计并不是简单增加模型复杂度,而是将性质预测中的物理先验直接编码进模型结构,使模型在数据有限的实验任务中更容易学习到合理规律。
在更接近真实研发的场景中提升更明显
为了验证MPA的训练流程和模型结构是否有效,研究首先进行了消融对比。
对照组使用相同的MPA预训练checkpoint,但直接进入微调阶段,不加入mid-training物理对齐,也不使用Hybrid Readout。完整版本则采用三阶段训练流程,并在后训练阶段使用混合读出头。
在40个真实实验性质预测任务中,完整MPA在随机划分下有38个性质预测结果得到提升,平均误差降低14.0%;在更具挑战性的骨架划分下,同样有38个性质预测结果得到提升,平均误差降低14.6%。
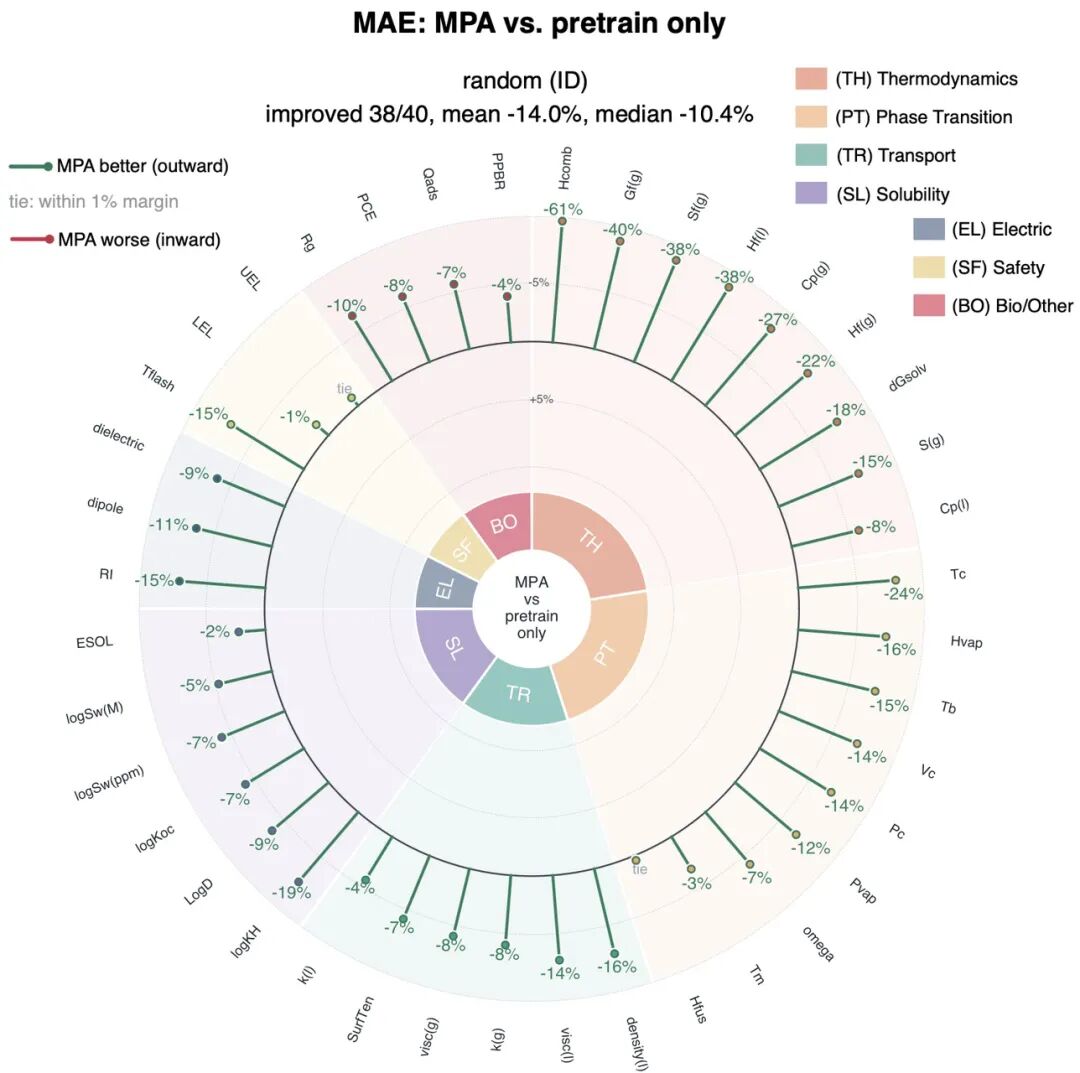
骨架划分要求训练集和测试集在材料骨架上更加不同,因此更接近真实研发中“预测全新结构”的任务条件。MPA在这一设置下提升更明显,说明模型并非只是在记忆训练集中已有的材料结构,而是在学习可以迁移到陌生结构上的物理规律。

研究进一步将MPA与ChemBERTa、ChemProp、Chemeleon、Uni-Mol2、Suiren等主流材料性质预测模型进行比较。结果显示,无论在随机划分还是骨架划分下,MPA的综合表现均处于领先位置,并在40个真实实验性质任务中的35个任务上取得SOTA。
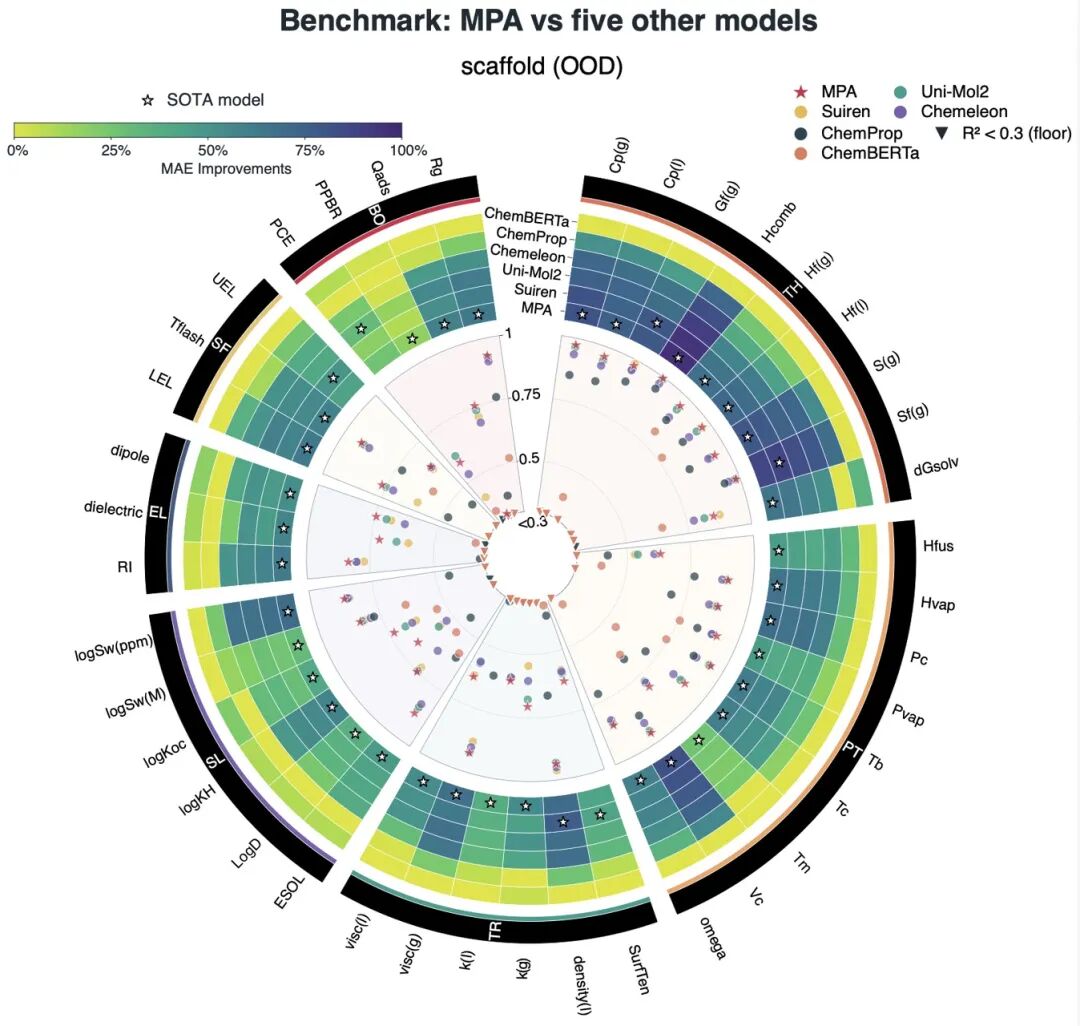
这一结果表明,面向真实实验数据的材料性质预测,不能只依赖更大的预训练数据或更复杂的网络结构。如何让模型在进入实验任务之前完成物理对齐,并在后训练阶段引入合适的任务结构,同样是提升泛化能力的关键。
让材料基座模型走向可持续迭代
MPA为材料基座模型提供了一条更可扩展的训练路线。
在传统范式下,不同性质预测任务往往需要分别构建模型、清洗数据和调参优化。这种方式可以解决具体问题,但难以将持续积累的计算数据和实验数据沉淀为统一的模型能力。
MPA尝试将第一性原理计算数据、高质量实验数据和面向具体任务的后训练过程整合到同一个框架中。随着数据规模和任务类型持续增长,模型可以不断通过中期训练和实验任务反馈更新自身能力。
这与当前大语言模型的发展路径具有一致性:模型能力的提升不只来自预训练规模扩大,也来自更有效的中期训练、对齐机制和后训练设计。
“之前材料基座大模型的scaling效应不明显,很可能是预训练和多重复杂下游任务的不匹配导致的。”「深度原理Deep Principle」创始人兼CTO段辰儒表示,“现在MPA通过mid-training的物理对齐解决了这个问题。下一步就是扩大模型参数,并收集更大量、更多样的第一性原理计算和湿实验数据。”
目前,MPA已经作为skill之一接入「深度原理Deep Principle」的agent产品。未来,随着计算数据、实验数据和自动化实验能力进一步增长,材料基座模型有望从单点性质预测工具,逐步发展为支撑材料研发闭环的基础能力。
对于MPA性质预测能力和效果感兴趣,可以在
https://sciclaw.cn/?invite_code=CN-SIMVL9WF
注册试用。
更多信息详见:
博客:
https://blog.deepprinciple.com/introducing-materials-property-axiom/
技术报告:
https://www.deepprinciple.com/papers/mpa.pdf
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号