我最近整理 AI 图片/视频 API 接入时,发现真正麻烦的是这些细节
原创
我最近整理 AI 图片/视频 API 接入时,发现真正麻烦的是这些细节
原创
genvis ai 开发者
发布于 2026-06-02 20:02:32
发布于 2026-06-02 20:02:32
最近在整理一个 AI 小项目的媒体生成链路,主要包括图片生成、视频生成和后端 API 调用。
刚开始我以为重点是“选哪个模型”。但真正写代码以后,发现更麻烦的其实是这些细节:
- SDK 怎么接,能不能少改业务代码。
- 图片生成和视频生成是不是同一个入口。
- 视频任务状态怎么轮询。
- API Key 怎么管理,能不能避免暴露到前端。
- 失败、超时、重试怎么处理。
- 控制台、充值、文档是否适合中文开发者。
所以这次我没有只看网页介绍,而是先整理了一个最小示例项目,把接入链路跑了一遍。
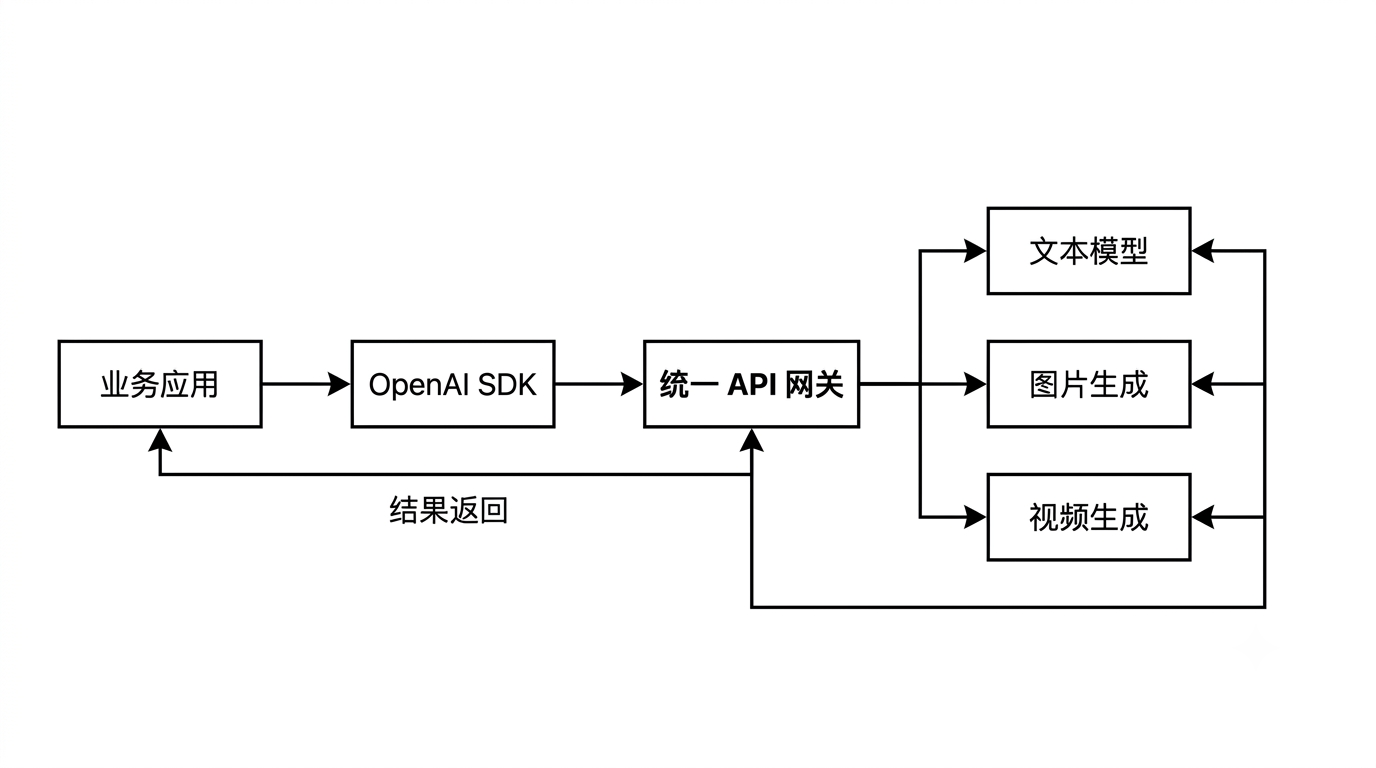
1. 我为什么先看 SDK 兼容
现在很多项目已经用过 OpenAI SDK。如果一个新工具能沿用类似写法,前期验证会轻很多。
比如初始化客户端时,核心就是 API Key 和 Base URL:
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.GENVIS_API_KEY,
baseURL: "https://genvis.xyz/v1", });
这类写法的好处是,业务层可以先围绕“生成图片”“生成视频”来封装,而不是一开始就被某个模型接口绑死。
2. 图片生成:看起来简单,但要记录参数
图片生成最容易被当成“传一个 prompt 就完事”。
但如果真的放进产品里,我建议至少记录这些内容:
- 使用的模型
- prompt
- 图片尺寸
- 生成耗时
- 失败原因
- 最终图片地址
这样后面要复现效果、比较模型、计算成本,才不会全靠记忆。
我这次更关注的场景是产品图、文章封面、应用内配图和活动图。这些场景不一定需要一次就生成完美结果,但需要可复现、可调整。
3. 视频生成:不要按同步接口设计
视频生成比图片生成更适合做成异步任务。
我会按这个状态流处理:
created -> processing -> succeeded / failed / timeout
前端只负责展示任务状态,后端负责提交任务、轮询状态、保存结果和处理失败。
如果后续给真实用户开放视频生成,还需要加队列、额度、内容规则和超时提示。这个部分越早设计清楚,后面越少返工。
4. 中文开发者体验也很重要
这次我测试的是 Genvis AI。
它让我觉得比较顺手的点,不只是模型入口,而是一些很实际的体验:
- 中文控制台。
- 支持微信和支付宝充值。
- 图片生成和视频生成入口比较集中。
- 可以用 OpenAI SDK 兼容方式先跑通。
- 有 GitHub 示例项目,方便复制到自己的项目里改。
这些点不一定听起来很“技术”,但对个人开发者和小团队来说,会直接影响推进速度。
5. 我建议的接入顺序
如果你也在做 AI 图片或视频功能,我建议不要一上来就接生产。
可以按这个顺序来:
- 用最小示例跑通 API Key。
- 先接图片生成,验证 prompt 和结果质量。
- 再接视频生成,把任务状态写完整。
- 加失败、超时、重试和日志。
- 最后再抽象模型配置,避免写死在业务里。
这样做不会很花哨,但比较稳。
6. 示例项目
我把这次整理的最小示例放到了 GitHub,后面会继续补图片生成、视频生成、错误处理和更多前端/后端场景。
GitHub 示例项目:
https://github.com/jimmyliu758-star/genvis-ai-sdk-examples
官网:
如果你正在做 AI 图片、AI 视频或多模型 API 调用,可以先用示例项目跑一下,再按自己的业务场景判断是否适合接入。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号