AI 工程知识图谱:从 Transformer 到 Agentic AI 的全景地图

AI 工程知识图谱:从 Transformer 到 Agentic AI 的全景地图

用户1589488
发布于 2026-06-03 12:12:18
发布于 2026-06-03 12:12:18
写在前面
最近在研究怎么把一个agent(不局限于某个类型的小龙虾)养成有记忆,会思考,能反思,可自进化的专家。其中,涉及到很重要的一部分内容,就是领域知识的积累。所以就把AI工程相关的知识给做了个搜索,归纳和总结,先分享出来,后续基于这个地图,我再一一展开进行学习及实践。
下面开始正文(5000字左右,建议先收藏有时间细读)
一张图看懂 AI Engineering 全貌——7 大模块、50+ 核心概念、5 层技术栈,帮你建立系统化的 AI 工程认知框架。
前言:为什么需要一张 AI 工程知识图谱
过去两年,AI 领域的论文数量呈指数增长,新框架每周冒出来,新概念层出不穷。很多同学的感受是:
- 学不完:今天学 RAG,明天出 GraphRAG,后天又来 Agentic RAG
- 连不上:Transformer、Prompt Engineering、Agent、MCP 之间是什么关系?
- 用不对:知道概念但不知道什么时候用、怎么选型
知识图谱解决的就是"连不上"的问题——不是教你每个概念的细节,而是帮你建立概念之间的连接关系,形成一张可导航的地图。
本文将 AI 工程拆解为 7 大模块,每个模块给出核心概念、关键论文、选型决策和模块间关联,最终形成一张完整的知识图谱。
一、知识图谱总览
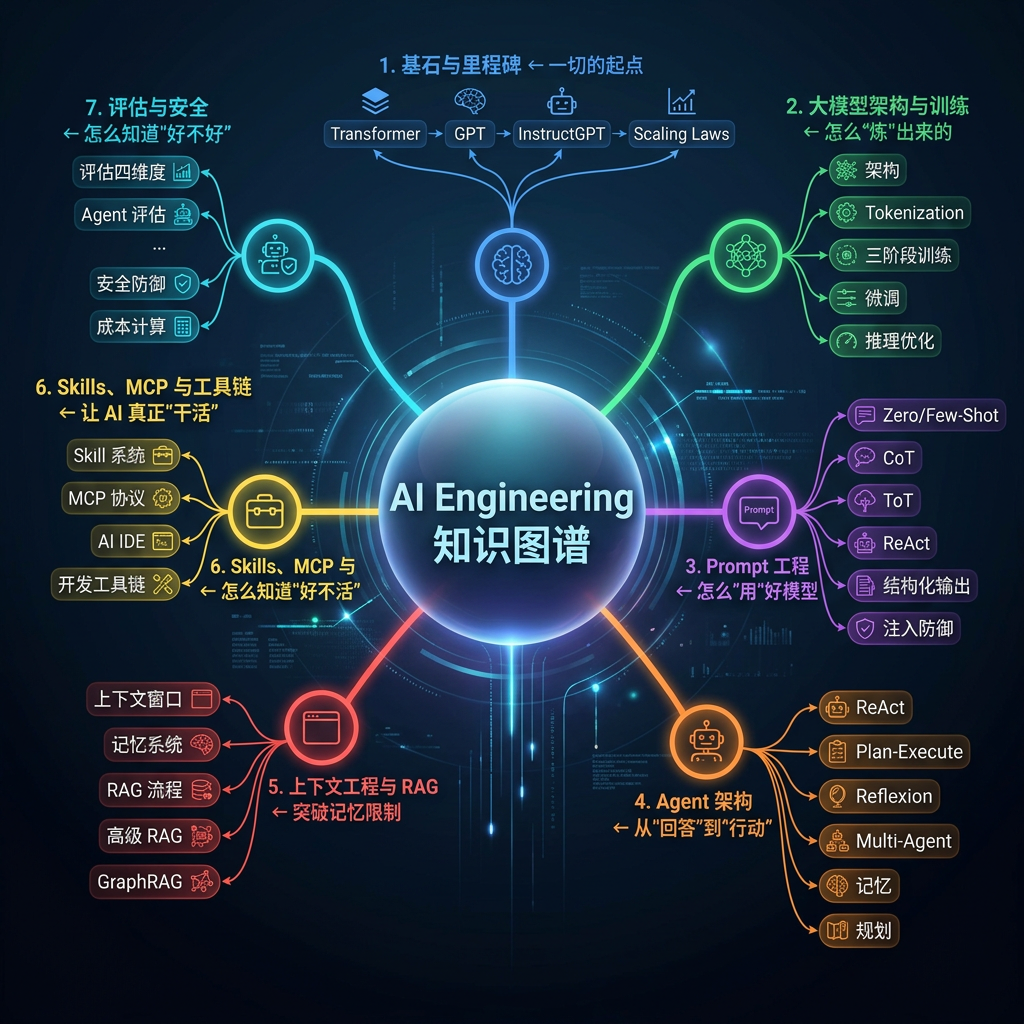
二、模块 1:基石与里程碑
1. 核心时间线
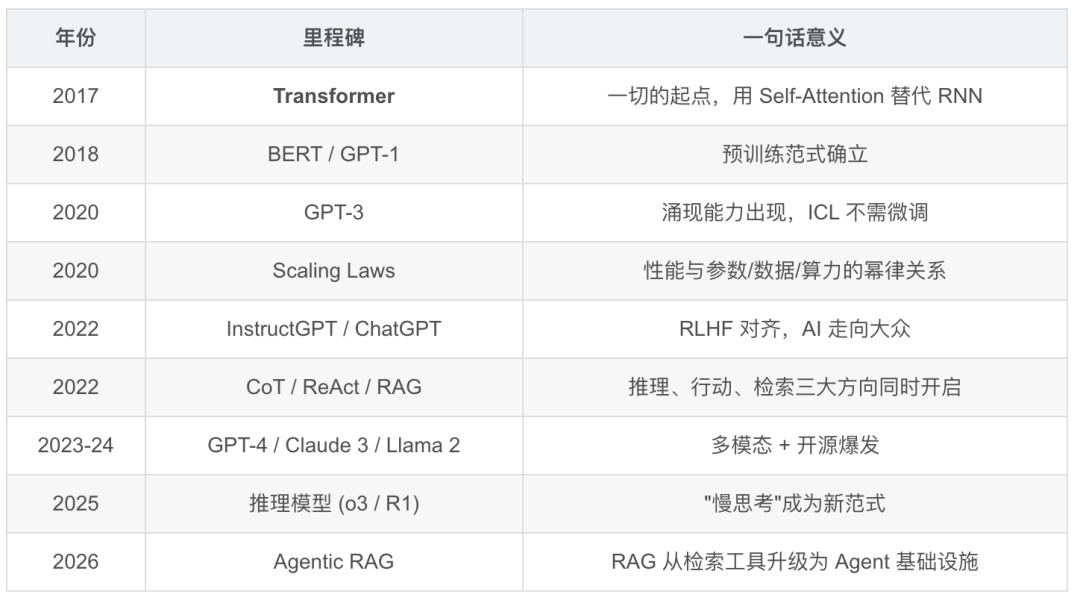
2. 必读论文 Top 5(入门优先级排序)
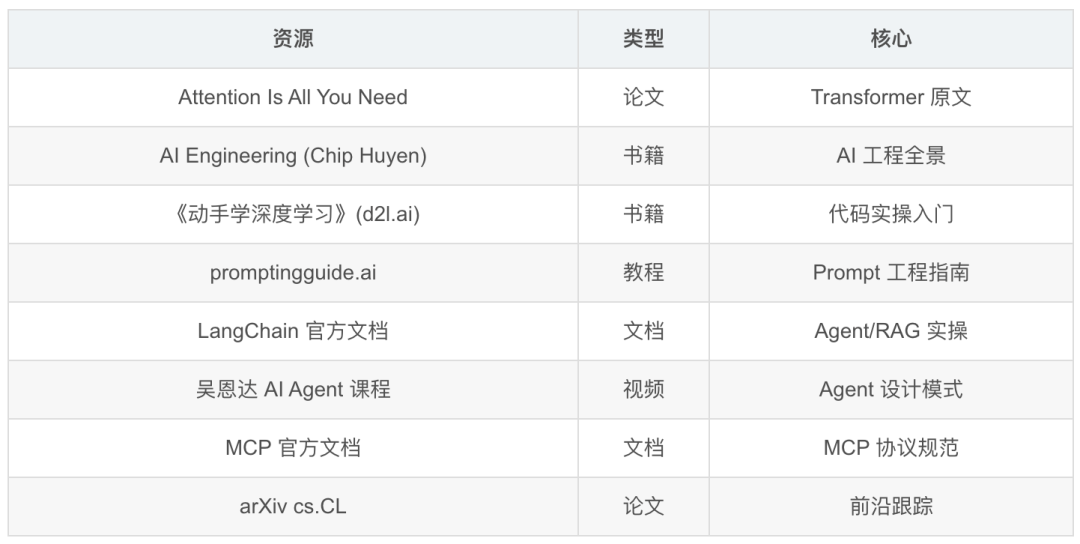
- Attention Is All You Need (2017) — Transformer,所有大模型的祖先
- GPT-3 (2020) — 涌现能力,In-Context Learning
- InstructGPT (2022) — RLHF 对齐三阶段
- Chain-of-Thought (2022) — 让模型一步步思考
- ReAct (2022) — Agent 架构的理论基础
3. 关键术语速查
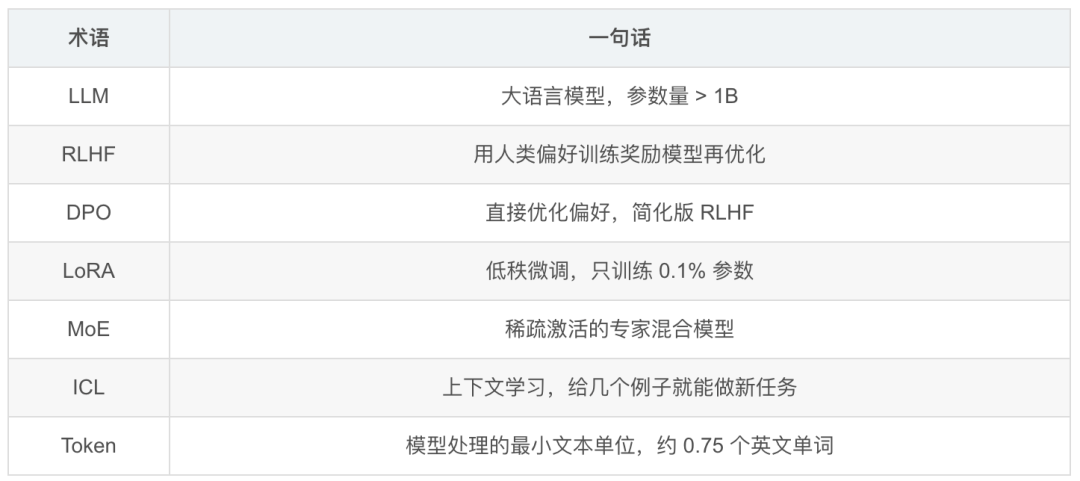
三、模块 2:大模型架构与训练
1. Transformer 核心结构
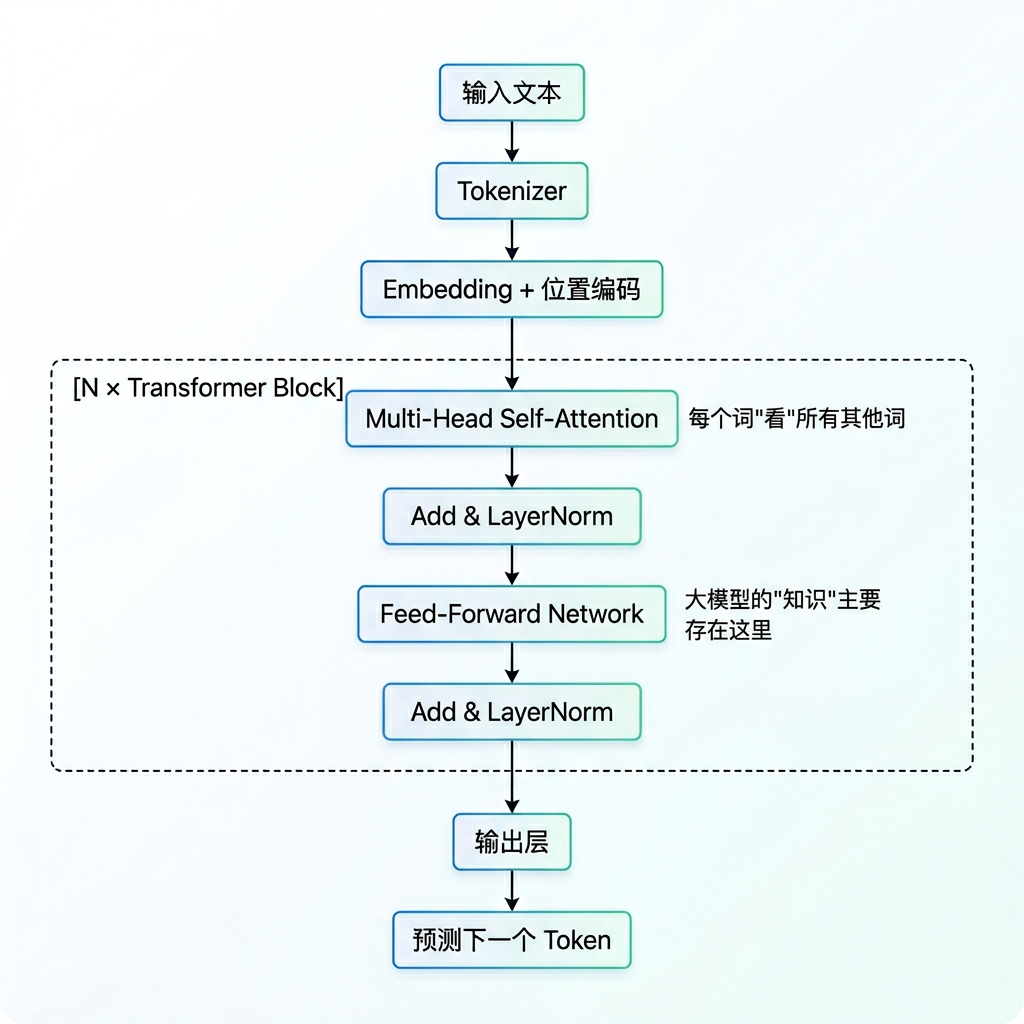
2. Self-Attention 直觉类比:
- Q(Query)= “我在找什么”
- K(Key)= “我是什么”(被搜索的标签)
- V(Value)= “我的内容”(实际信息)
就像在图书馆:Q 是你的问题,K 是书名,V 是书的内容。根据问题与书名的匹配度,决定花多少注意力在每本书上。
3. 训练三阶段
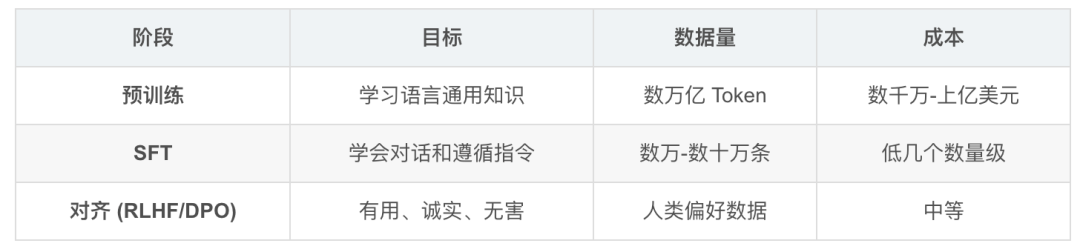
核心公式:数据质量 >> 数据数量。宁可 1 万条高质量,不要 100 万条低质量。
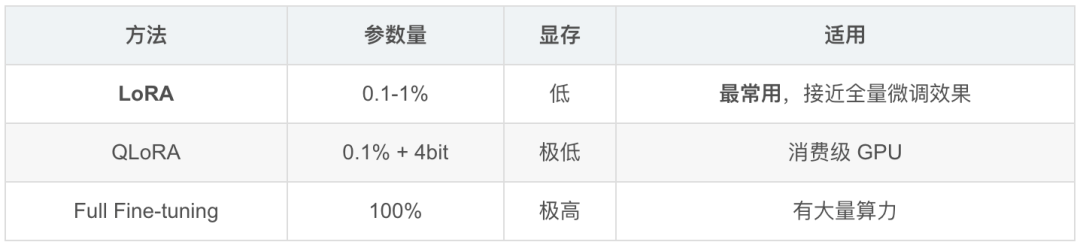
4. 高效微调方法选型
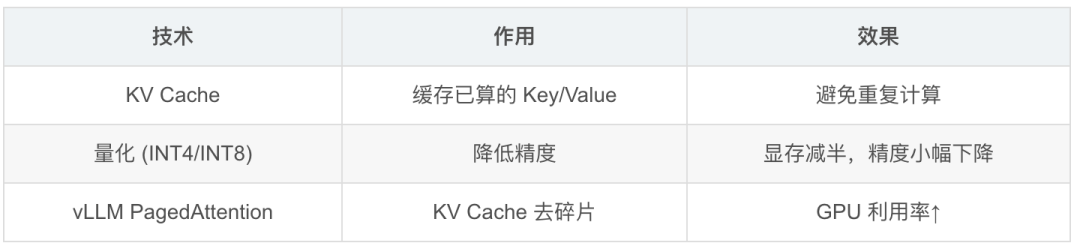
5. 推理优化
6. 模型选型决策树
你的场景:
├── 通用对话/创作 → GPT-4o / Claude Sonnet
├── 复杂推理/数学 → o3 / DeepSeek-R1
├── 代码生成 → Claude Opus 4
├── 超长文档 → Gemini 2.0 (1M 窗口)
├── 本地部署/隐私 → Llama 3.1 / Qwen 2.5
├── 中文场景 → Qwen 2.5 / DeepSeek
└── 成本敏感 → DeepSeek-V3四、模块 3:Prompt 工程
- Prompt 的本质
完整的 Prompt = 角色 + 上下文 + 指令 + 输入 + 输出格式 + 约束
同一个模型,Prompt 不同,输出质量可以差 10 倍。
- 核心模式
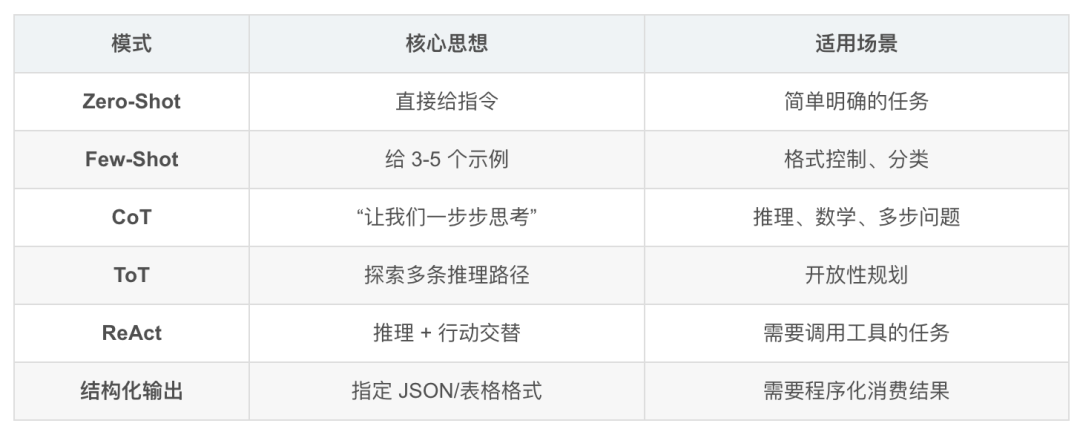
- CoT 的变体进化
Zero-Shot CoT → "Let's think step by step"
↓
Few-Shot CoT → 给带推理过程的示例
↓
Self-Consistency → 多次采样取一致性最高的答案
↓
Tree of Thoughts → 树状搜索多条推理路径- System Prompt 架构设计
一个优秀的 System Prompt 应该是分层的:
System Prompt = 身份层 (我是谁)
+ 灵魂层 (我怎么思考)
+ 知识层 (我知道什么)
+ 记忆层 (我经历过什么)
+ 工具层 (我能做什么)- Prompt 注入防御
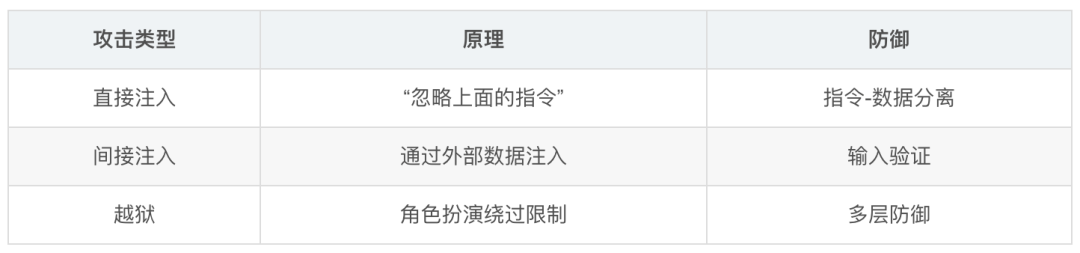
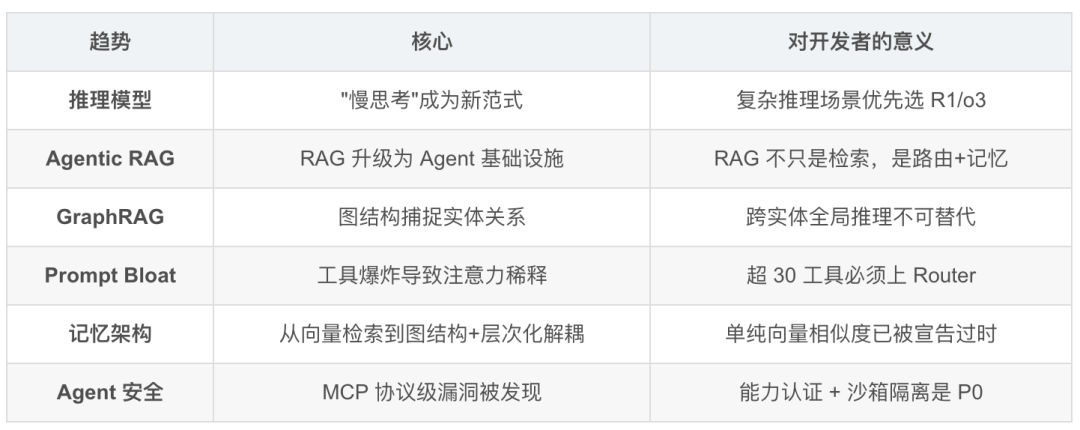
- 2026 前沿:Prompt Bloat 问题
MCP 工具数量爆炸 → 工具描述塞满 context → LLM 工具选择准确率下降。解法:RAG-as-Routing,用语义检索预筛选工具(top-k),只把相关工具注入 Prompt。实测 prompt token 降低 60%+。
五、模块 4:Agent 架构
1. Agent = LLM + 记忆 + 工具 + 规划
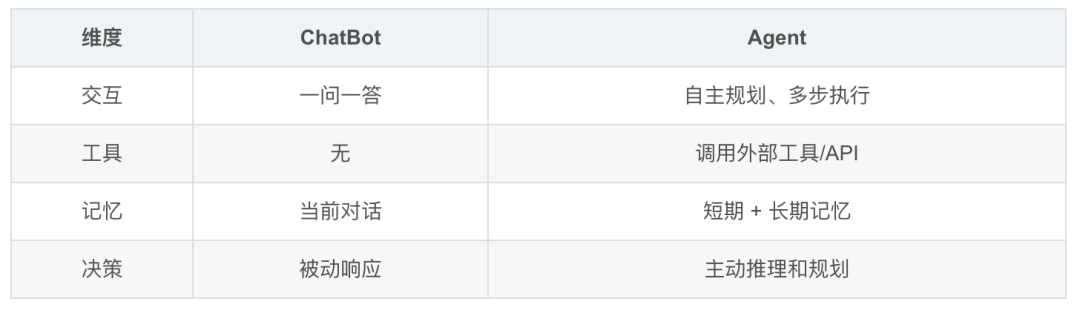
2. Agent 核心循环
Perceive (感知) → Think (思考) → Act (行动) → Observe (观察) → 循环3. 五大设计模式
模式 1:ReAct(最广泛使用)
Thought → Action → Observation → Thought → Action → ...
简单直观,但串行执行,没有全局规划。
模式 2:Plan-and-Execute
制定完整计划 → 逐步执行 → 根据中间结果 Replan
有全局视角,适合复杂任务。
模式 3:Reflexion
执行 → 自我评估 → 存储反思 → 下次避免同类错误
持续自我改进。
模式 4:Multi-Agent
Orchestrator
├── Researcher → 信息收集
├── Writer → 内容生成
└── Reviewer → 质量检查—— 分工协作,适合复杂工作流。
模式 5:Tool-Use Agent
LLM 决定何时调用什么工具。模型不是"执行"工具,而是生成工具调用的 JSON 描述,由外部系统执行。
4. 记忆系统设计
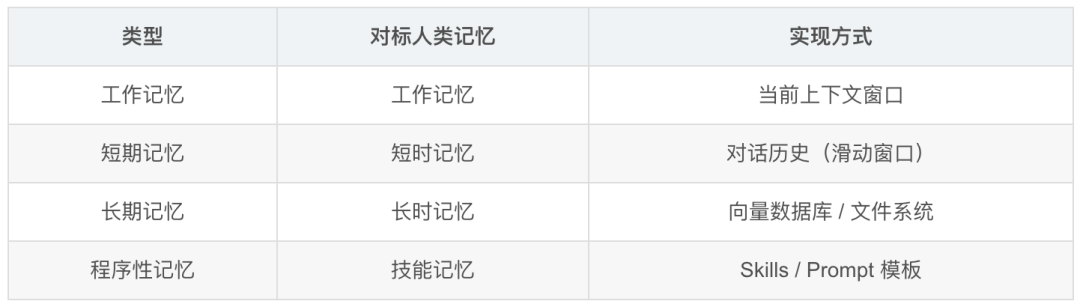
5. Agent 框架选型
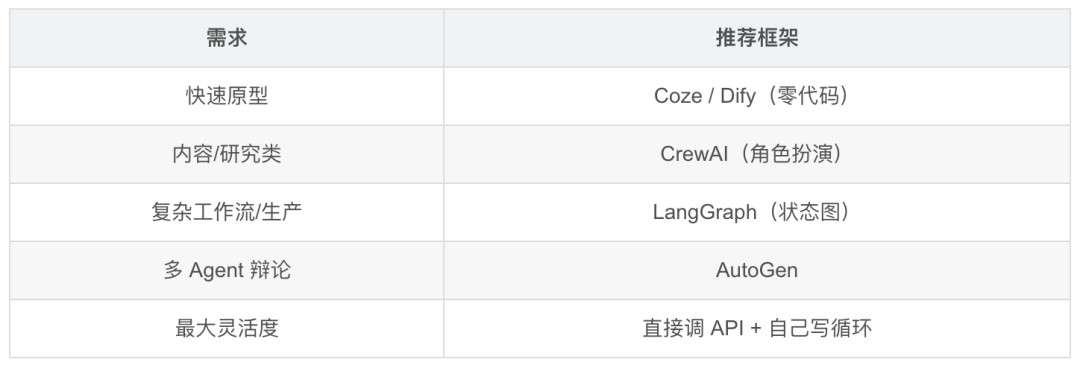
6. 2026 关键洞察
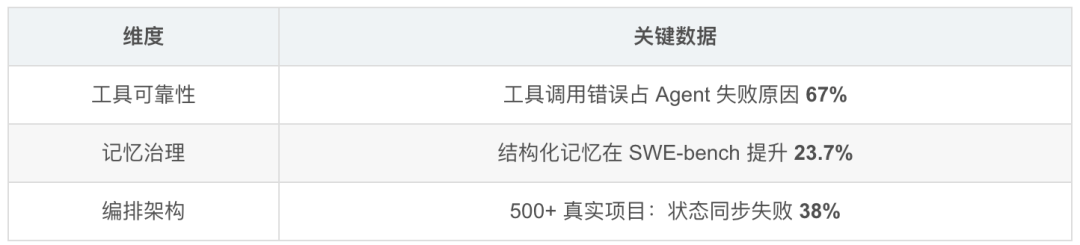
Agent 系统工程三角:编排 + 记忆治理 + 工具可靠性,决定 Agent 能否真正落地。
六、模块 5:上下文工程与 RAG
1. 核心矛盾:“看到” ≠ “记住”
Lost in the Middle 问题:模型对上下文开头和结尾更敏感,中间部分容易被忽略。即使窗口有 200K,实际有效利用的可能只有 50-70%。
2. 上下文工程原则
上下文 = System Prompt (固定层)
+ User Profile (半固定层)
+ Retrieved Knowledge (动态检索层)
+ Conversation History (对话层)
+ Current Query (当前输入层)5 条黄金法则:
- 最相关的信息放在开头和结尾
- System Prompt 越精简越好
- 动态检索胜于静态塞入
- 摘要压缩胜于直接截断
- 结构化(Markdown/JSON)胜于纯文本
3. RAG 完整流程
离线:文档 → 解析 → 清洗 → 分块 → Embedding → 向量数据库
在线:查询 → Query Embedding → 向量检索 → 重排序 → 拼 Prompt → 生成3.1 分块策略选型
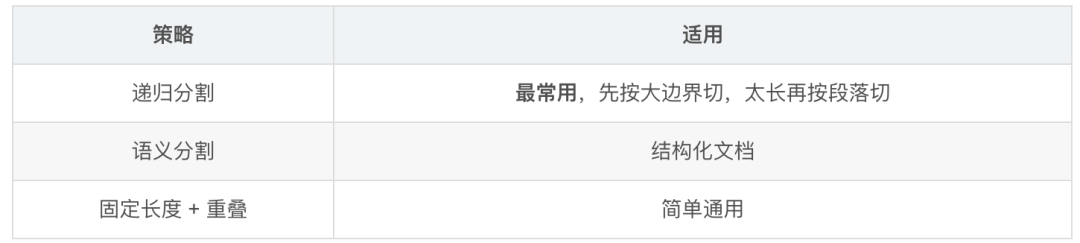
最佳实践:块大小 256-1024 Token,重叠 10-20%。
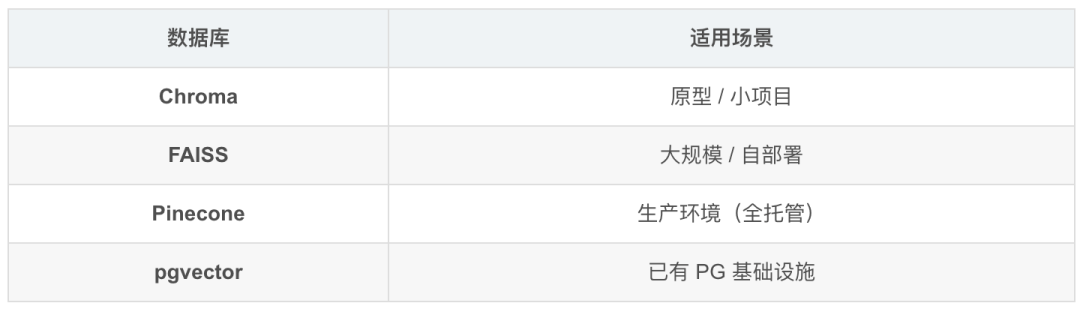
3.2 向量数据库选型
3.3 高级 RAG 技术矩阵
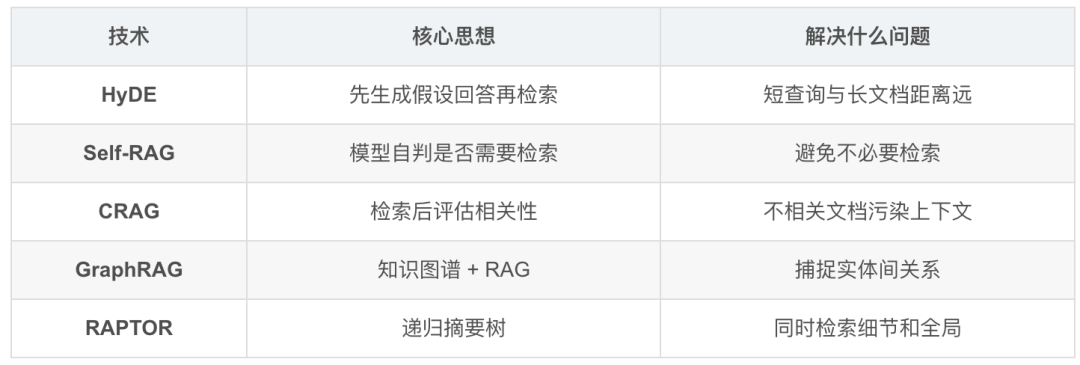
2026 前沿:Agentic RAG
RAG 正在从"检索工具"升级为"Agent 基础设施":

架构选型:
- 简单问答 → Agentic RAG(成本低)
- 跨实体全局推理 → GraphRAG(不可替代)
七、模块 6:Skills、MCP 与工具链
1. MCP = AI 的 USB 接口
MCP (Model Context Protocol) = Anthropic 提出的开放协议,让 AI 模型标准化地连接外部工具和数据源。
MCP Client (AI应用) ←─MCP协议─→ MCP Server (工具提供方)
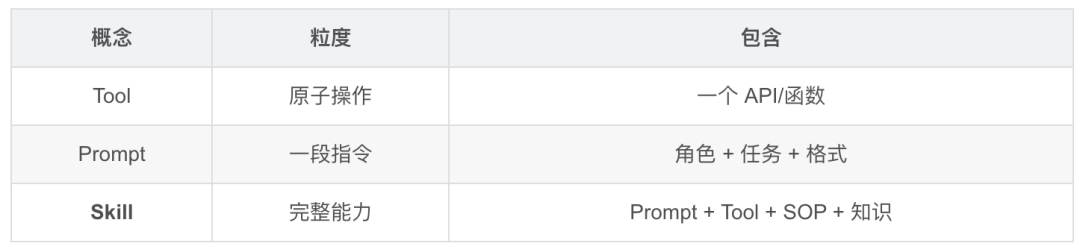
Claude/Cursor/CodeBuddy GitHub/Slack/数据库/文件系统2. Skill vs Prompt vs Tool
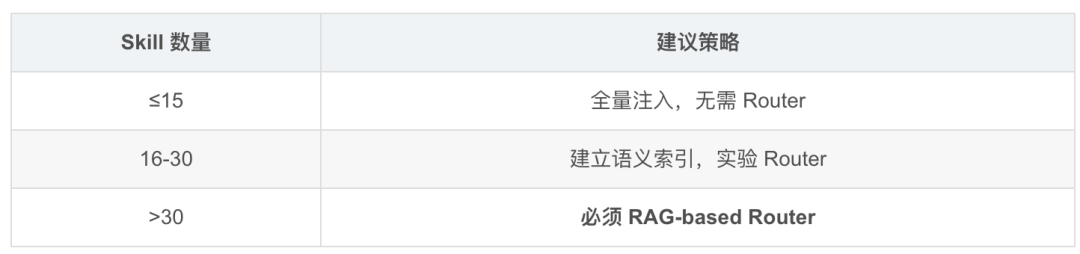
2026 关键洞察:RAG-MCP
MCP 工具超过 30 个后,必须启用 RAG-based Skill Router,否则工具选择准确率崩溃:
八、模块 7:评估与安全
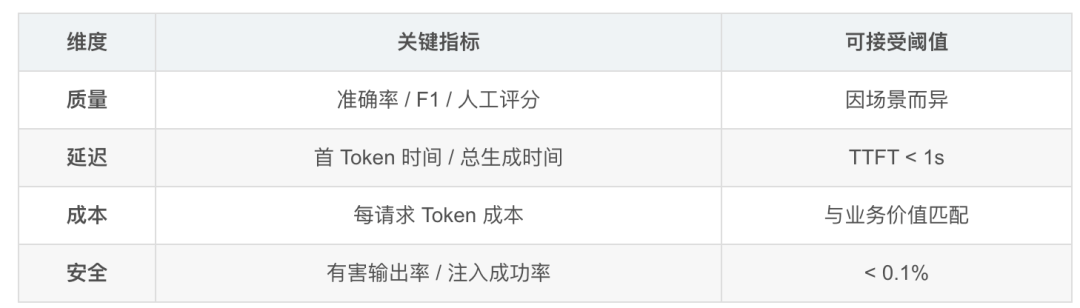
1. 成本计算公式
月成本 = 日均请求数 × 平均 Token 数 × Token 单价 × 30
例:10000 请求/天 × 2000 Token × 0.003/1K × 30 = 1,800/月
2. Agent 评估维度
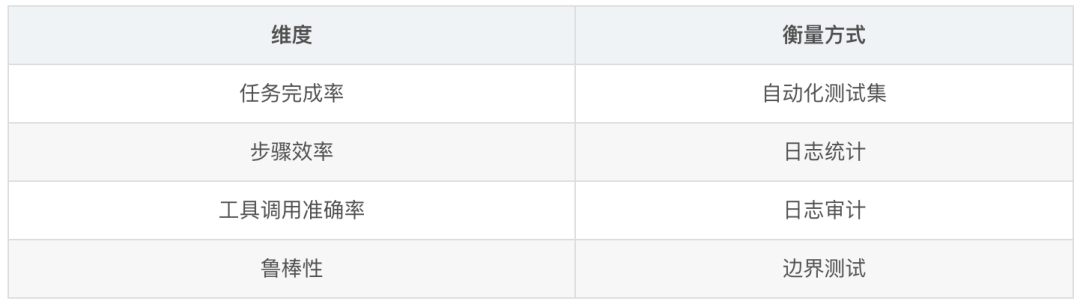
3. 安全红线
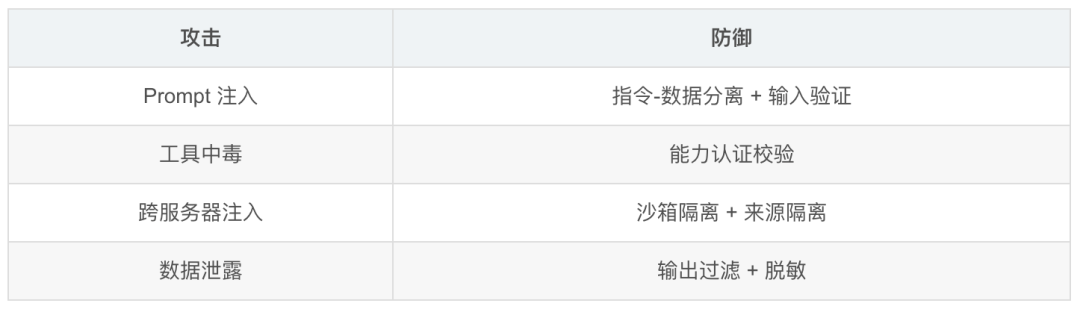
九、跨模块关联:知识图谱的关键边
知识图谱的价值不在于节点(单个概念),而在于边(概念间的关系)。
关键关联 1:Transformer → Prompt → Agent
Transformer 的 Self-Attention 机制
→ 使得模型能理解长距离依赖
→ 使得 CoT (链式思考) 成为可能
→ 使得 ReAct (推理+行动) 成为可能
→ Agent 架构的基础关键关联 2:Embedding → RAG → Agent
Embedding 将文本映射到向量空间
→ 使得语义检索成为可能
→ RAG 用 Embedding 检索相关知识
→ Agent 用 RAG 扩展知识边界
→ Agentic RAG 让 Agent 自主决定检索策略关键关联 3:MCP → Skill → Agent
MCP 统一工具接口
→ Skill 封装为可复用能力单元
→ Agent 通过 Skill 调用工具
→ RAG-MCP 解决工具选择问题关键关联 4:记忆 → 上下文 → 压缩
长期记忆(文件/向量库)
→ 上下文窗口有限(200K)
→ 需要压缩(摘要/截断/检索)
→ 迭代式摘要 + Handoff 框架
→ 记忆的 CRUD + 遗忘机制十、学习路线图
1. 入门路线(2-3 周)
- 3Blue1Brown 神经网络视频 → 建立直觉
- Jay Alammar “The Illustrated Transformer” → 理解 Transformer
- 精读模块 1-3(基石 + 架构 + Prompt)→ 打基础
- 动手写 Prompt,跑通 CoT / Few-Shot
2. 进阶路线(4-6 周)
- 搭建一个 ReAct Agent(LangChain/LangGraph)
- 实现一个 RAG 系统(Chroma + OpenAI Embedding)
- 精读模块 4-6(Agent + RAG + MCP)
- 读 Chip Huyen《AI Engineering》
3. 深入路线(持续)
- 精读 ReAct / RAG / CoT 原始论文
- 研究 Hermes Agent 源码(上下文压缩 + 记忆系统设计)
- 关注 2026 前沿:Agentic RAG / GraphRAG / 推理模型
- 关注 arXiv cs.CL 每月热门论文
十一、2026 趋势总结
十二、推荐资源
结语
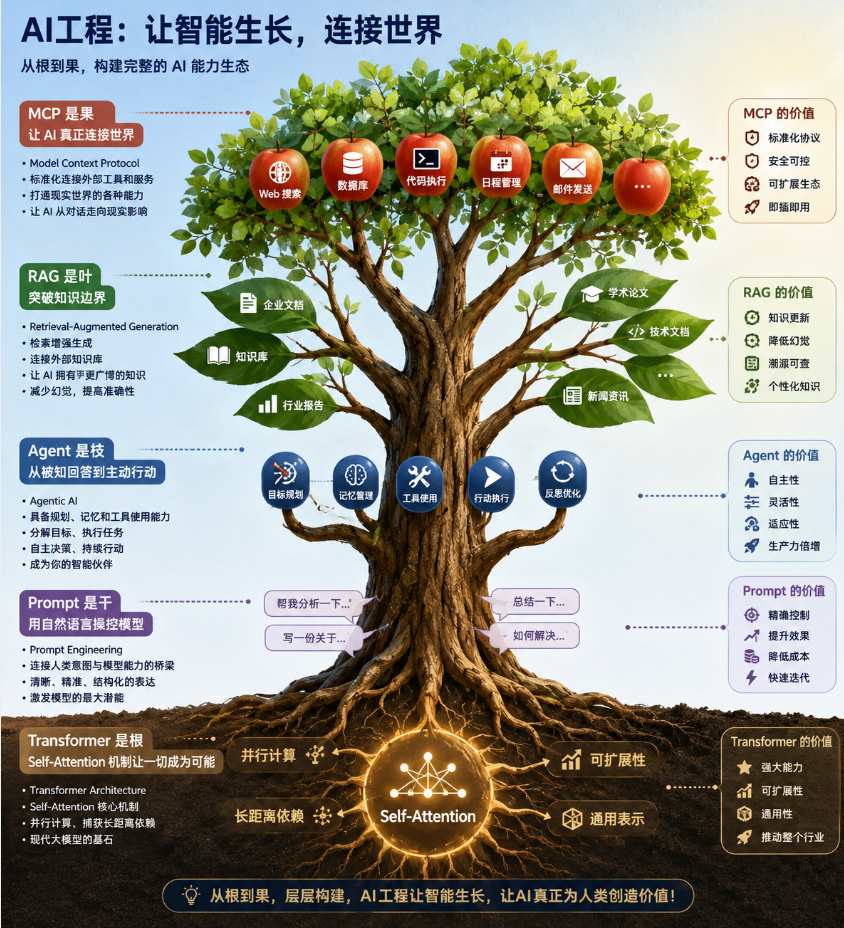
AI 工程不是一堆孤立概念的堆砌,而是一棵从 Transformer 根基长出的知识树:
- Transformer 是根——Self-Attention 机制让一切成为可能
- Prompt 是干——用自然语言操控模型
- Agent 是枝——从被动回答到主动行动
- RAG 是叶——突破知识边界
- MCP 是果——让 AI 真正连接世界
记住这张图,你就不会在 AI 工程的知识海洋中迷路。
近期将围绕上述议题,对AI工程的上述内容,进行系统性地学习。相关进展和思考将定期在这里和大家分享。
持续关注AI前沿,AI Agent实战
如果这篇文章对你有帮助
点个赞、收藏起来,或者转发给需要的朋友
点赞
收藏
转发
【历史合集】20+篇openclaw&Agent实战 和 大模型产品解读 👇
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-03,如有侵权请联系 cloudcommunity@tencent.com 删除
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号