Quality-Loop技能:给 AI Agent 装上质量闭环(附下载)
原创
Quality-Loop技能:给 AI Agent 装上质量闭环(附下载)
原创
大泽同学
发布于 2026-06-03 14:03:39
发布于 2026-06-03 14:03:39
Quality-Loop:给 AI Agent 装上质量闭环
AI 写早报,昨天的和今天的重复了 42%——没人发现。undefinedAI 生成 PPT,缺了关键章节——照样交了。undefinedAI 自动同步知识库,静默失败——一周后才发现。
这就是 AI Agent 的质量困境:模型本身不知道自己做得对不对,也没有内置的校验机制。传统软件开发有单元测试、CI/CD、Code Review 三个关卡,而 AI Agent 目前只有"希望它做对了"一个念头。
我们基于质量管理领域经典的 PDCA 循环理论(Plan-Do-Check-Act,由 W. Edwards Deming 推广),为 AI Agent 场景设计并开源了 quality-loop——一个嵌入 Agent 工作流的质量闭环系统。它的核心逻辑很简单:定义检查标准 → 执行并记录 → 自动审查 → 纠偏或升级。让 Agent 在执行每一步后,都有一个自动化的质检员在旁守候。
一、问题:Agent 产出的"薛定谔质量"
AI Agent 不同于传统软件的确定性问题——同一个 prompt,两次执行可能得到完全不同的结果。传统流程中的 QA 环节在这里是缺失的:
场景 | 没有质量闭环 | 有质量闭环 |
|---|---|---|
早报生成 | 缺了"AI 论文"章节,没人知道 | 自动检测章节齐全性,失败则重试 |
知识库同步 | 重复录入旧内容,浪费存储 | 自动计算与昨日重叠度,超标则报警 |
PPT 生成 | 文件生成了但是空文件 | 自动检查文件大小和关键元素 |
批量任务 | 某个子任务静默失败 | 每一步都有 trace,失败可追溯 |
核心痛点一句话:Agent 不知道自己做得对不对,也没有机制让别人知道。
二、解决方案:五步闭环
quality-loop 参考质量管理中经典的 PDCA 循环,但为 AI Agent 场景做了适配:
- P(Plan)— 定义检查标准:不是写死代码,而是用 JSON spec 声明"这个任务要检查什么"
- D(Do)— 执行 + 记录 Trace:按正常流程执行,同步记录环境、工具、步骤、输出
- C(Check)— 三层检查引擎:L1 格式检查 → L2 逻辑检查 → L3 语义评审
- A(Act)— 自动响应:重试、降级、报警、或弹出选项让用户决策
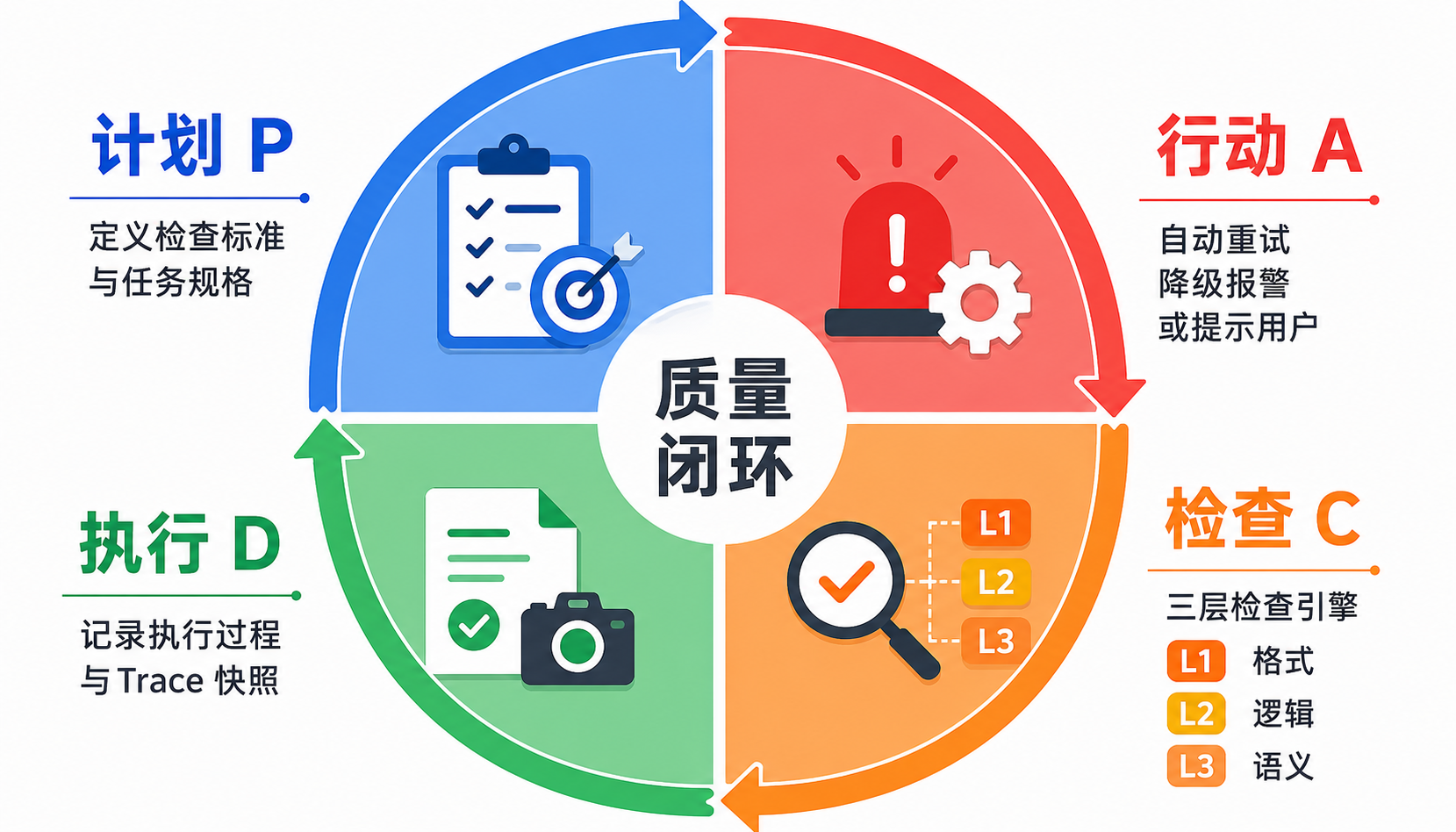
PDCA闭环
完整工作流
Step 1: 加载或创建 Task Spec(P)
检查 specs/{task_type}.spec.json 是否存在
├── 存在 → 读取 spec
└── 不存在 → 引导创建:"这个任务检查什么?失败时如何响应?"
→ 生成 spec JSON → 保存
Step 2: 执行任务 + 记录 Trace(D)
按正常流程执行,同步记录:
- 环境快照(Python/Node 版本、Git HEAD)
- 使用的工具和模型
- 逐步步骤(动作、目标、结果、耗时)
- 输出物(文件、字数、外部动作)
Step 3: 运行检查引擎(C)
加载 task spec → 依次执行 L1→L2→L3 规则
每条规则返回: { rule_id, passed, detail, evidence }
Step 4: 分析结果 → 决定响应(A)
全部通过 → Step 5
L1 失败 → 自动重试(max=3次)
L2 失败 → 展示审查结果 + 方案选择
L3 失败 → 展示评分 + 建议
Step 5: 交付审查报告
全部通过:✅ 简洁摘要 + 产物路径
有问题:⚠️ 详细报告 + 根因 + 建议 + 选项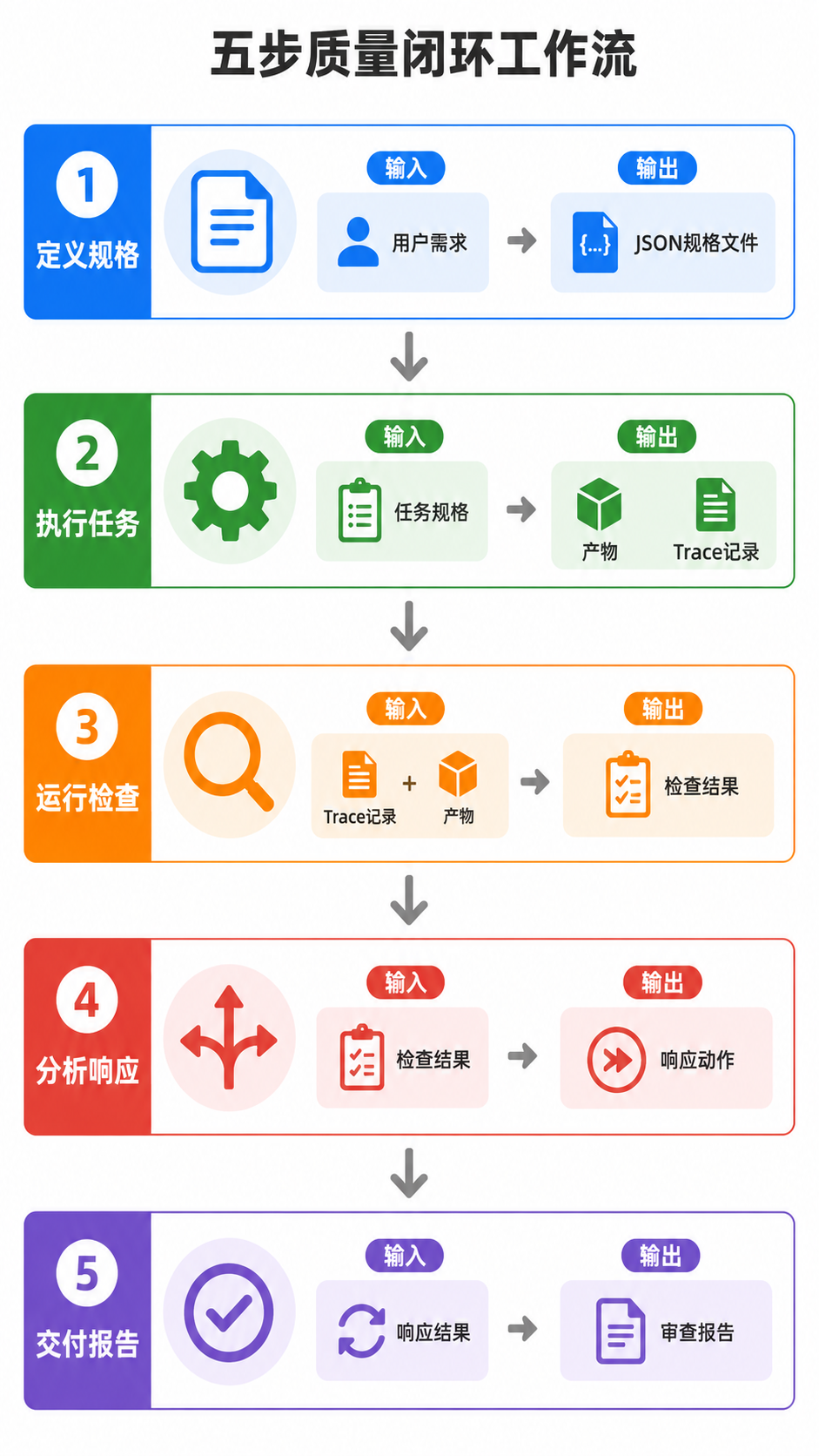
五部质量闭环工作流
三、三层检查体系
这是 quality-loop 的核心设计 —— 不是一刀切的"过/不过",而是按严重程度分层的三级检查:
L1:格式检查(100% 自动化,零外部依赖)
规则 | 参数 | 示例 |
|---|---|---|
| 文件路径 | 早报文件是否存在 |
| 必需章节列表 | 是否包含"AI 论文"等 5 个章节 |
| 文件路径 | Trace 文件是否是合法 JSON |
| 文件路径 | 文件大小 > 0 |
L1 失败 → 大概率是执行故障 → 自动重试(最多 N 次,用户可配置)。重试通过则不打扰用户。
L2:逻辑检查(100% 自动化,可能有外部依赖)
规则 | 参数 | 示例 |
|---|---|---|
| min, max | 早报 1500-5000 字 |
| max 0-1 | 与昨日重叠度 ≤ 30% |
| section, min | "思维模型" ≥ 200 字 |
| 正则 | 是否包含合规声明 |
| 索引文件 | 索引是否被更新 |
L2 失败 → 软件问题——产物存在但不合格 → 展示问题 + 建议方案 + 用户选择。
L3:语义检查(LLM-as-Judge,按需启用)
当 L1/L2 不够,需要判断"质量好还是差"时启用。使用 Rubric 评分:
评分标准 (1-5):
1 = 不可用,严重错误或完全偏离
2 = 有框架但内容空洞
3 = 内容合格,无重大错误
4 = 内容准确,有一定深度
5 = 专业水准,内容精准,有独到见解L3 失败 → 始终提示用户(语义评判结果不可自动纠偏)。
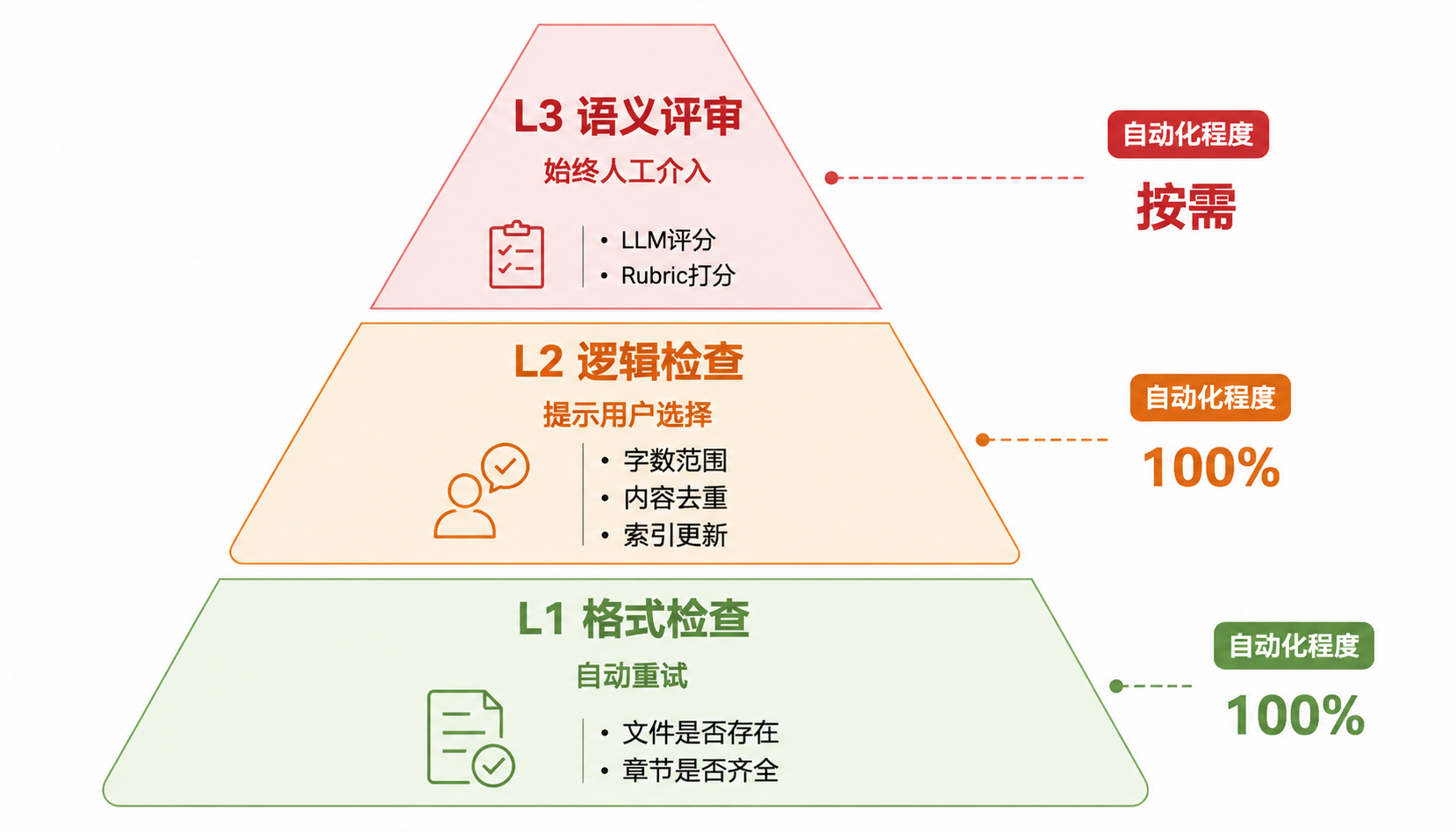
三层检查体系
四、响应引擎:不只检查,更要行动
检查只是手段,行动才是目的。quality-loop 的 Act Engine 定义了 8 种标准响应动作:
动作 | 含意 | 适用场景 |
|---|---|---|
| 重新执行任务 | L1 格式失败 |
| 重试指定步骤 | 单一步骤超时 |
| 执行降级脚本 | L2 软退化 |
| 推送通知 | 关键错误 |
| 标记待人工复核 | 需要人类判断 |
| 展示选项等用户选择 | L2/L3 问题 |
| 接受当前结果 | 已知可容忍 |
| 抑制此规则 | 临时关闭某检查 |
自动 vs 手动分流策略
L1 失败 → 自动重试(不打扰用户)
├── 重试通过 → 静默继续
└── 重试耗尽 → prompt_user(展示问题 + 选项)
L2 失败 → prompt_user(展示审查结果 + 方案选择)
└── 可选 degrade:自动执行降级策略
L3 失败 → 始终 prompt_user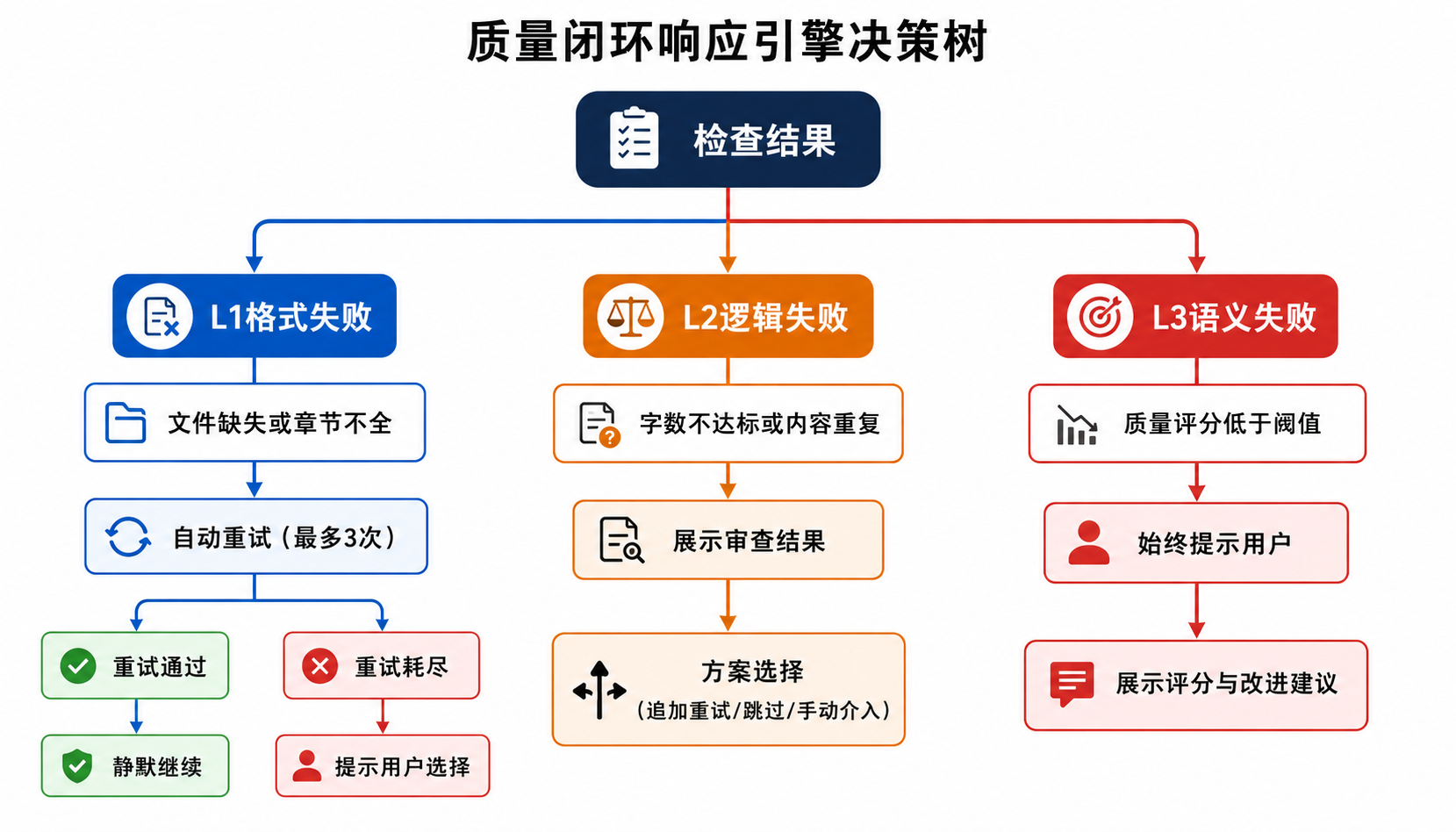
决策树
五、实战:早报生成的质量闭环
以每日早报为例,看一个完整的质量闭环如何运行:
Task Spec (morning-brief.spec.json)
{
"task_type": "morning-brief",
"checks": {
"L1_format": {
"rules": [
{"type": "file_exists", "path": "morning-briefs/YYYY-MM-DD/brief.md"},
{"type": "sections_present", "required": ["时事热点","AI论文","行业应用","天气","思维模型"]}
]
},
"L2_logic": {
"rules": [
{"type": "word_count_range", "min": 1500, "max": 5000},
{"type": "overlap_with_yesterday", "max": 0.30},
{"type": "section_min_words", "section": "思维模型", "min": 200}
]
}
},
"actions": {
"on_fail": [
{"level": "L1", "action": "retry", "max": 3},
{"level": "L2", "action": "prompt_user", "options": ["追加搜索后重试","跳过","手动介入"]}
]
}
}通过时
✅ 质量闭环通过
· L1 格式检查: 2/2 通过
· L2 逻辑检查: 3/3 通过
· Trace 已存档: memory/traces/2026-06-03_morning-brief.json
产物就绪: morning-briefs/2026-06-03/brief.md (3240 字)发现问题时
⚠️ 质量闭环发现问题
L2 逻辑检查: 2/3 通过 (1项问题)
┌─ [FAIL] overlap_with_yesterday: 重叠度 42% > 30%
│ 原因: 今日搜索结果与昨日高度重复
│ 建议方案:
│ [1] 追加一轮新关键词搜索后重试
│ [2] 跳过此检查接受当前版本
│ [3] 手动介入修改
└─ 请选择 (1/2/3):🖼️ 建议插图:此处放一张质量闭环通过的截图 + 一张发现问题的对比截图,让读者直观感受两种输出模式。
六、不只自动化——任何 AI 任务都能用
quality-loop 不限于定时自动化任务。以下场景同样适用:
编码场景
在 AI 辅助编程中,quality-loop 可以作为代码质量监督员。每次 AI 生成代码后,自动检查:
{"type": "eslint_passes", "description": "代码无 lint 错误"},
{"type": "typescript_no_errors", "description": "TypeScript 编译通过"},
{"type": "test_coverage_min", "min": 80, "description": "测试覆盖率 ≥ 80%"},
{"type": "file_count_match", "expected": 3, "description": "生成了预期数量的文件"}长任务场景
撰写一篇 5000 字的技术文章、生成一个 20 页的 PPT、处理一个包含 100 条数据的批量任务——这些长任务最容易出现"中间某步悄无声息地出错"。quality-loop 在每个阶段结束时执行检查,确保每一步的输出都符合预期。
对话式场景
在和 AI 的日常对话中,如果需要 AI 完成一个有明确交付物的任务("帮我写一份调研报告"、"整理这 20 条数据生成一份表格"),可以在对话中附加一句"带上质评",quality-loop 就会在生成结果后自动执行一轮检查再交付。
七、设计哲学
1. 分层不越界
L1 不应该去检查语义,L3 不应该去管文件存在。每层有明确的职责边界,规则声明式定义,引擎通用化执行。
2. 自动化程度与风险匹配
- 格式错误(L1)→ 自动重试,99% 能修复
- 逻辑问题(L2)→ 展示 + 等用户决策
- 语义退化(L3)→ 始终人工介入
3. Trace 不是日志
Trace 不是给人看的流水账,而是给机器读的结构化执行快照。它的目的是让 check engine 能精确定位根因,让 act engine 知道该重试哪个步骤。
4. Spec 驱动,不是代码驱动
新增一个检查规则不需要改代码。在 spec 里加一条 JSON 规则即可。这让质量闭环可以覆盖任意类型的 Agent 任务——早报、PPT、代码生成、知识库同步。
八、适用场景
任务类型 | 建议检查层级 | 示例规则 |
|---|---|---|
定时早报 | L1 + L2 | 文件存在、章节齐全、字数范围、内容去重 |
PPT 生成 | L1 + L2 | 文件存在、页数范围、关键元素检查 |
知识库同步 | L1 + L2 | 文件存在、索引更新、无重复录入 |
代码生成 | L1 + L2 + L3 | 文件存在、语法检查、语义评分 |
文档撰写 | L1 + L2 + L3 | 章节齐全、字数范围、质量评分 |
九、开源与使用
quality-loop 已开源在 GitHub,MIT 协议,开箱即用。
开源仓库: github.com/jafferchong/quality-loop
安装方式:
将 quality-loop/ 目录放入你的 AI 平台的 skills 目录即可,零外部依赖。
git clone https://github.com/jafferchong/quality-loop.git三种使用方式:
- 显式触发——对任何任务追加 "带上质评" 或
/qa:帮我写一份Python脚本做数据分析 /qa - 定时任务默认开启——在你的自动化流水线配置中,将 quality-loop 作为默认执行的最后一步。
- 编码中调用——在长编码任务中,执行到关键里程碑时手动触发一次质量检查。
自定义你的第一个 Spec:
{
"task_type": "my-code-review",
"checks": {
"L1_format": {
"rules": [
{"type": "file_exists", "path": "src/output.py"},
{"type": "file_not_empty", "path": "src/output.py"}
]
},
"L2_logic": {
"rules": [
{"type": "word_count_range", "min": 50, "max": 2000}
]
}
},
"actions": {
"on_fail": [
{"level": "L1", "action": "retry", "max": 2}
]
}
}十、总结
quality-loop 解决的不是"AI 能不能干好活",而是"AI 干完活之后谁能发现它没干好"。
它把 QA 从外部评审变成了内嵌流程——不是事后 review,而是每个任务执行的最后一步。三层检查体系让不同严重等级的问题得到不同力度的响应;Spec 驱动的设计让它能覆盖任意任务类型;开源 MIT 协议让你可以在任何项目中使用和扩展。
无论是定时早报、自动编码、长文档生成,还是日常对话中的交付物——quality-loop 都可以作为你的 AI 质量守门员,在你不看的时候,替你盯着。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号