大模型应用:医疗AI智能体幻觉防控:幻觉抑制的四层防护体系应用实践.128
原创
大模型应用:医疗AI智能体幻觉防控:幻觉抑制的四层防护体系应用实践.128
原创
未闻花名
发布于 2026-06-05 09:29:07
发布于 2026-06-05 09:29:07
一、医疗AI幻觉
1. 大模型幻觉
大模型幻觉,是指生成式人工智能在输出内容时,产生与事实不符、无来源依据、逻辑矛盾或虚假编造信息的现象,本质是大模型的概率生成机制与真实世界知识的错位。
大模型的核心工作原理是基于训练数据的文本序列概率预测:它不是在记忆知识,而是在预测下一个最可能出现的字符或词汇。训练数据中存在的噪声、知识冲突、缺失信息,都会让模型在生成时脑补内容,就像一个背诵了海量书籍,但没有经过专业验证的学生,遇到不确定的问题时,会下意识编造答案来维持流畅性。
举个最直观的例子:
- 真实知识库:高血压一线用药为氨氯地平、硝苯地平、缬沙坦
- 幻觉输出:高血压推荐服用氨氯**,可能出现编造药品名;甚至由于学习的内容缺陷出现高血压可通过空腹断食治愈的虚假结论
这种脑补在娱乐、文案创作场景中无伤大雅,但在医疗场景属于致命缺陷。

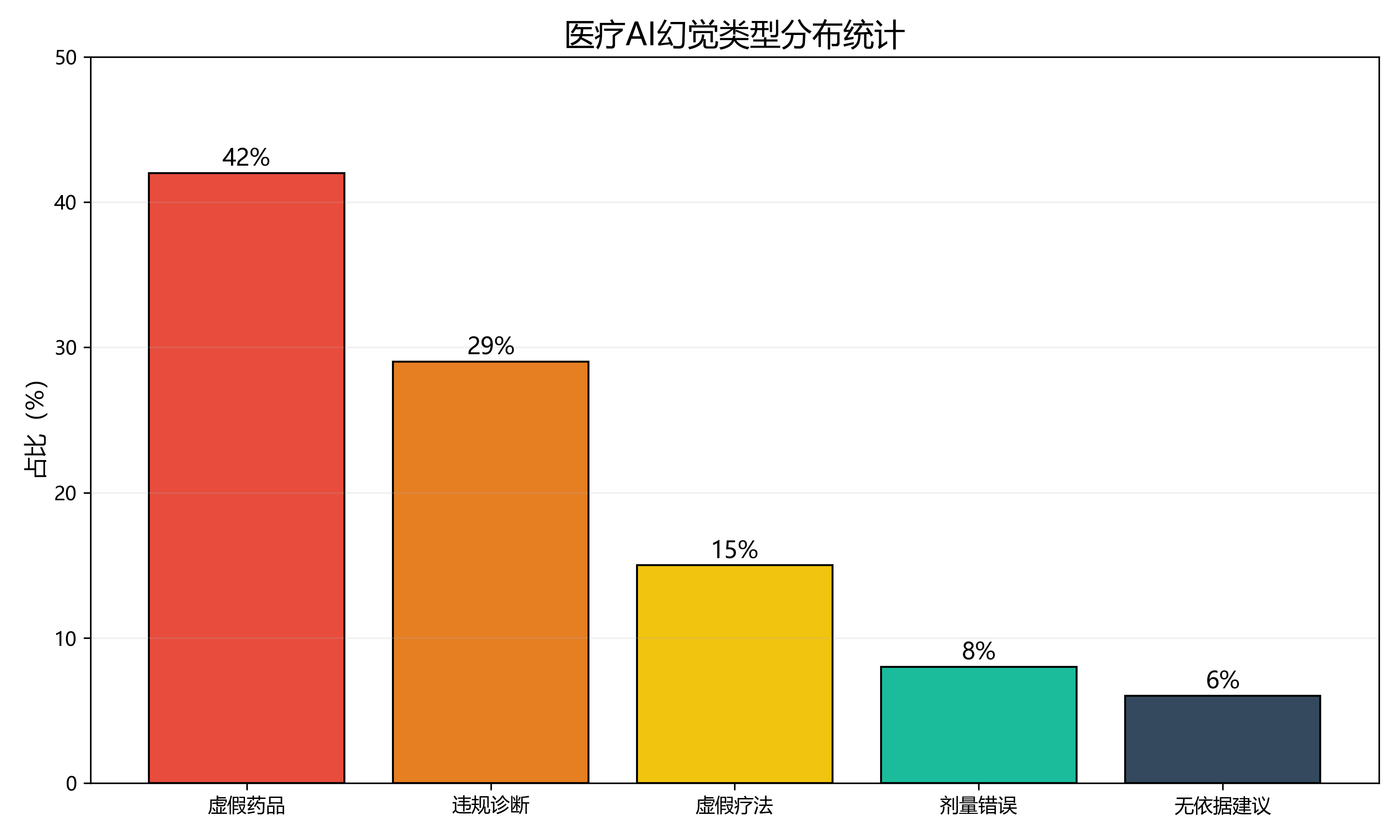
2. 医疗场景幻觉危害
医疗是关乎生命的特殊领域,AI 输出的每一句话都可能直接影响患者健康、医师诊断、临床决策,因此行业对幻觉的要求是绝对零容忍。我们将医疗 AI 幻觉危害分为三级,每一级都对应不可逆转的风险:
一级危害:直接危及生命
- 1. 编造虚假药品名称、剂量、服用方法:患者按虚假信息用药,引发药物中毒、过敏、器官损伤
- 2. 伪造诊断结论:将普通头痛判定为脑出血,导致患者过度医疗;或将脑卒中误诊为疲劳,延误黄金救治时间
- 3. 编造诊疗指南:违背卫健委、中华医学会官方临床路径,给出超范围、反常识的医疗建议
二级危害:医疗合规风险
- 1. 超出 AI 执业范围:AI 生成执业医师专属诊断意见,违反《人工智能医用软件产品分类界定指导原则》
- 2. 侵犯医疗知识产权:编造未上市药品、未获批疗法,引发医疗纠纷与法律诉讼
- 3. 误导基层医师:基层医疗工作者依赖 AI 辅助决策,幻觉内容会导致临床误诊漏诊
三级危害:行业信任崩塌
- 医疗AI的核心价值是“辅助医疗、提升效率”,一旦出现幻觉,会彻底摧毁患者、医师、医疗机构对 AI 的信任,导致整个医疗 AI 行业的落地停滞。
3. 医疗AI幻觉率
核心指标:幻觉率
幻觉率 = (包含幻觉内容的回复总数 ÷ 总交互次数)× 100%
- 普通场景 acceptable 幻觉率:5%-10%
- 金融、法律场景 要求幻觉率:<1%
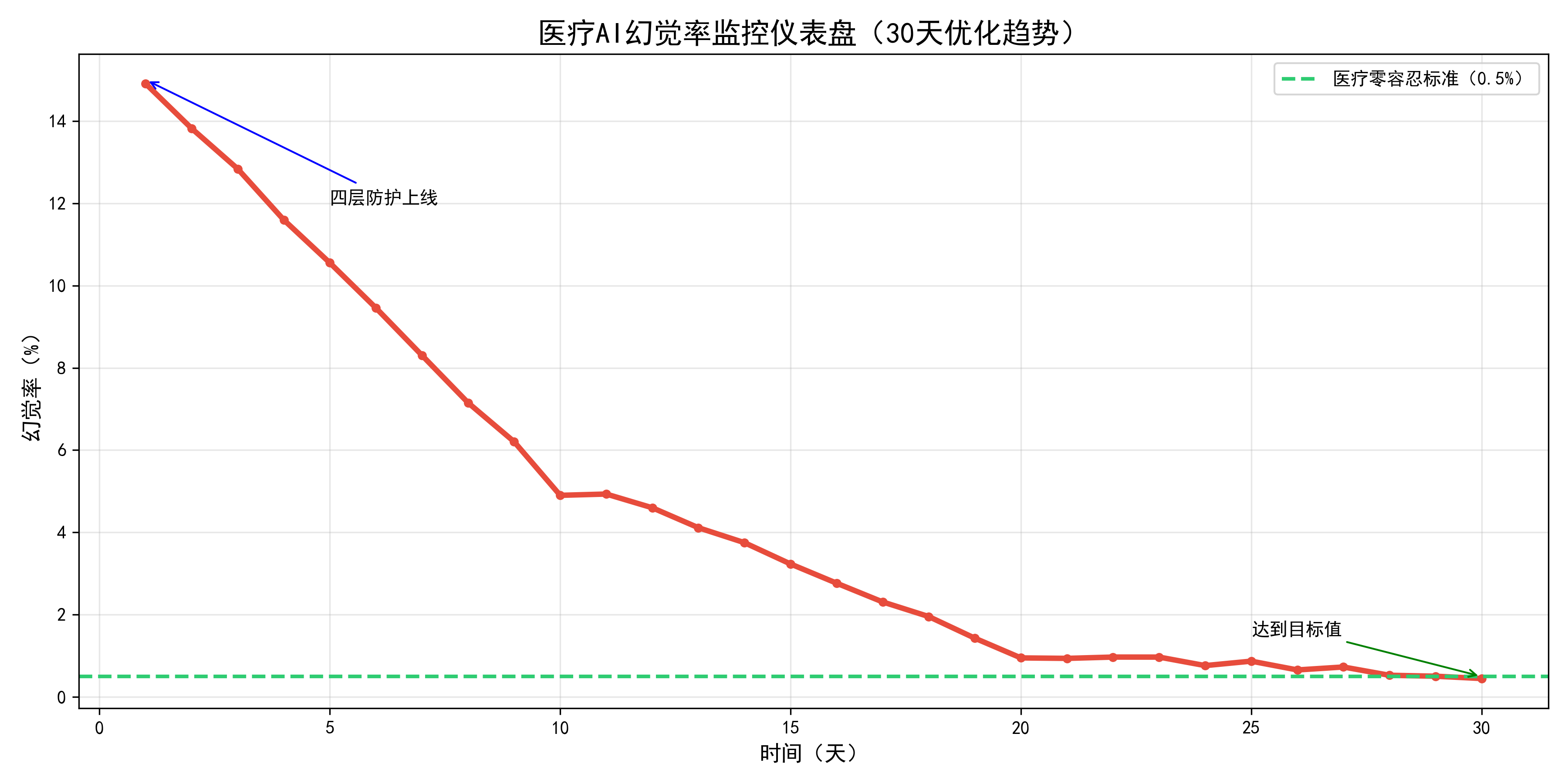
- 医疗场景 强制标准:<0.5%,极限零容忍
4. 产生幻觉的根源
- 训练数据缺陷:医疗训练数据存在碎片化、时效性差、非结构化等问题,模型无法精准区分权威指南、民间偏方、学术假设。
- 生成机制固有缺陷:大模型追求语句流畅性优先于事实准确性,在知识库无明确答案时,会自动编造内容维持对话连贯性。
- 领域知识壁垒:医疗知识具有极强的专业性、时效性、地域性,通用大模型未经过医疗专属微调,无法理解医学术语的严谨性。
- 缺乏事实校验机制:原生大模型无知识溯源能力,无法验证生成内容是否来自权威医疗知识库,这是幻觉产生的最关键技术漏洞。
总结:医疗AI幻觉抑制不是优化模型生成效果,而是构建一套“从输入到输出、从机器到人工、从实时防控到持续迭代”的全链路安全体系,用工程化方案弥补大模型的固有缺陷,实现医疗场景的绝对安全。
二、四层防护体系
1. 四层防护总架构
我们构建的四层递进式防护体系,形成“事前约束→事中校验→人工兜底→事后迭代”的闭环,每一层都针对幻觉产生的不同环节精准拦截,层层过滤,最终实现幻觉率趋近于零。
2. 第一层:提示词约束
2.1 核心原理
提示词(Prompt)是大模型的操作手册,精准、强制、无歧义的提示词约束,能从输入阶段直接限制模型的生成行为,让模型不敢编、不能编、不会编,从源头扼杀幻觉。
医疗场景提示词的核心逻辑:强制绑定权威知识库 + 明确禁止行为 + 统一无答案回复标准。
2.2 医疗专属提示词设计规范
- 身份锁定:明确 AI 的医疗辅助定位,禁止越权诊断
- 知识边界:仅允许使用指定权威医疗知识库,如卫健委指南、中华医学会文献、药品说明书
- 禁止条款:明确禁止编造药品、诊断、疗法、剂量
- 兜底回复:无知识库信息时,统一回复「暂无相关建议」
- 格式约束:强制输出内容简洁、有据可查,禁止冗余编造
2.3 提示词设计示例
def medical_ai_prompt_constraint(user_question: str) -> str:
"""
医疗AI提示词约束函数:第一层防护,构建强制约束的输入提示词
:param user_question: 用户医疗问题
:return: 约束后的标准提示词
"""
# 核心约束模板:医疗场景零幻觉强制提示词
prompt_template = """
你是【医疗AI辅助智能体】,严格遵守以下规则,零容忍任何虚假信息:
1. 身份约束:仅提供医疗科普、用药咨询辅助服务,禁止出具执业医师级诊断结论;
2. 知识约束:**仅使用内置权威医疗知识库中的信息回答问题**,不得使用任何外部知识;
3. 行为约束:禁止编造药品名称、用药剂量、诊疗方案、疾病诊断结论;
4. 兜底规则:若知识库中无对应问题的信息,**唯一回复:暂无相关建议**;
5. 格式约束:回答简洁准确,无夸张、虚假、超范围表述,有据可查。
用户问题:{question}
请严格按照规则生成回答:
""".strip()
# 填充用户问题,生成约束后的提示词
final_prompt = prompt_template.format(question=user_question)
return final_prompt
# 测试示例
if __name__ == '__main__':
# 用户问题
test_question = "高血压应该吃什么药?"
# 生成约束提示词
constrained_prompt = medical_ai_prompt_constraint(test_question)
print("约束后的医疗AI提示词:")
print(constrained_prompt)实践效果:
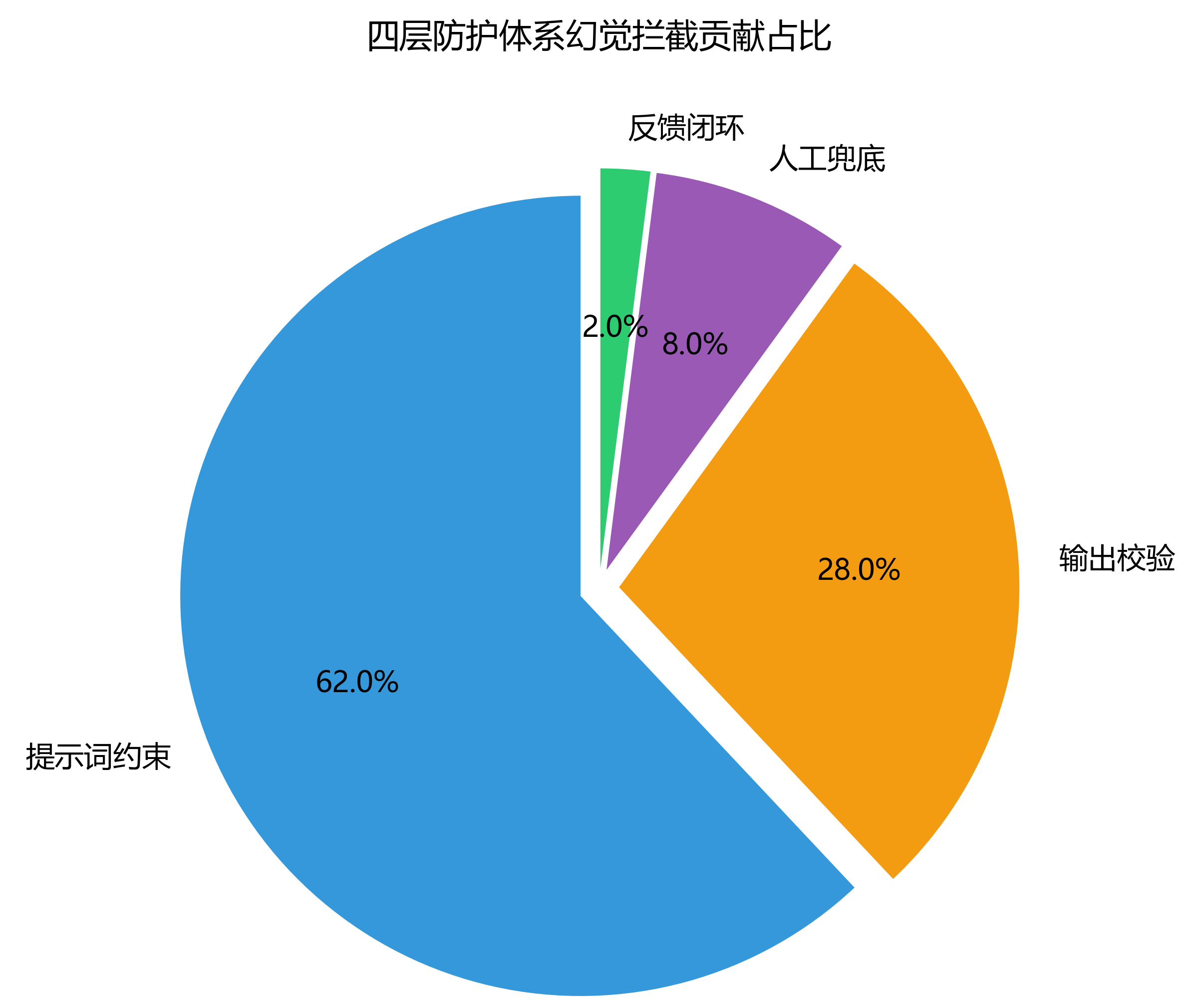
- 提示词约束可直接拦截60% 以上的原生幻觉,是成本最低、见效最快的第一层防护,也是医疗AI的基础安全门槛。
输出结果:
约束后的医疗AI提示词: 你是【医疗AI辅助智能体】,严格遵守以下规则,零容忍任何虚假信息: 1. 身份约束:仅提供医疗科普、用药咨询辅助服务,禁止出具执业医师级诊断结论; 2. 知识约束:**仅使用内置权威医疗知识库中的信息回答问题**,不得使用任何外部知识; 3. 行为约束:禁止编造药品名称、用药剂量、诊疗方案、疾病诊断结论; 4. 兜底规则:若知识库中无对应问题的信息,**唯一回复:暂无相关建议**; 5. 格式约束:回答简洁准确,无夸张、虚假、超范围表述,有据可查。 用户问题:高血压应该吃什么药? 请严格按照规则生成回答:
3. 第二层:输出校验
3.1 核心原理
提示词约束无法100%杜绝模型违规生成,因此需要独立于大模型的规则引擎,对模型输出内容进行二次校验,像安检机一样扫描所有回复,发现幻觉内容立即拦截,通过规则引擎实时拦截幻觉内容;
医疗规则引擎的核心:构建医疗幻觉黑名单 + 合规白名单,实现关键词、语义、逻辑三重校验。
3.2 校验规则分类
- 诊断禁令规则:拦截“确诊为 XX 疾病"、”患有XX病“等执业医师专属表述
- 药品禁令规则:拦截不在国家药品监督管理局目录中的虚假药品名
- 疗法禁令规则:拦截”断食治愈“、”偏方根治“等无依据疗法
- 剂量禁令规则:拦截无权威依据的用药剂量、服用方法
- 兜底校验:强制无答案时回复”暂无相关建议“,禁止其他表述
3.3 规则引擎示例
import re
class MedicalOutputValidator:
"""医疗AI输出校验引擎:第二层防护,实时拦截幻觉内容"""
def __init__(self):
# 1. 权威药品白名单(国家药监局认证药品)
self.legal_drugs = [
"氨氯地平", "硝苯地平", "缬沙坦", "氯沙坦", "美托洛尔", # 高血压
"阿托伐他汀", "辛伐他汀", "瑞舒伐他汀", # 降脂药
"二甲双胍", "格列美脲", "阿卡波糖", # 降糖药
"阿司匹林", "布洛芬", "对乙酰氨基酚" # 常见药
]
# 2. 药品后缀(用于识别药品类词汇)
self.drug_suffixes = ["地平", "沙坦", "洛尔", "普利", "他汀", "西平", "东平", "南平", "北平"]
# 3. 违规诊断关键词(禁止AI出具的诊断表述)
self.illegal_diagnosis = ["确诊为", "确诊患有", "你患有", "就是", "肯定是", "绝对是", "确诊"]
# 4. 虚假疗法关键词(无科学依据的医疗建议)
self.fake_therapies = ["断食治愈", "偏方根治", "不用吃药", "百分百治愈"]
# 5. 标准兜底回复
self.standard_unknown = "暂无相关建议"
def validate(self, ai_output: str) -> dict:
"""
校验AI输出内容,返回校验结果
:param ai_output: 大模型生成的原始回复
:return: 校验结果(是否通过、拦截原因)
"""
result = {
"is_pass": True,
"intercept_reason": "",
"final_output": ai_output
}
# 规则1:拦截虚假药品名称(优先级最高,防止幻觉药品)
# 使用智能分割方法:按标点和空格分割,然后检查每个片段
# 分割符:逗号、顿号、句号、空格
segments = re.split(r'[,,。、\s]+', ai_output)
for segment in segments:
# 对于每个片段,查找4-5字的药品名称
if len(segment) >= 4:
# 查找所有可能的药品名称(4字或5字)
for i in range(len(segment) - 3):
# 检查4字药名
if i + 4 <= len(segment):
candidate = segment[i:i+4]
if any(candidate.endswith(suffix) for suffix in self.drug_suffixes):
# 检查是否包含白名单中的药品
contains_legal_drug = False
for legal_drug in self.legal_drugs:
if legal_drug in candidate:
contains_legal_drug = True
break
if not contains_legal_drug and candidate not in self.legal_drugs:
result["is_pass"] = False
result["intercept_reason"] = f"拦截原因:包含虚假药品名称【{candidate}】"
return result
for i in range(len(segment) - 4):
# 检查5字药名
if i + 5 <= len(segment):
candidate = segment[i:i+5]
if any(candidate.endswith(suffix) for suffix in self.drug_suffixes):
# 检查是否包含白名单中的药品
contains_legal_drug = False
for legal_drug in self.legal_drugs:
if legal_drug in candidate:
contains_legal_drug = True
break
if not contains_legal_drug and candidate not in self.legal_drugs:
result["is_pass"] = False
result["intercept_reason"] = f"拦截原因:包含虚假药品名称【{candidate}】"
return result
# 规则2:拦截违规诊断结论
for keyword in self.illegal_diagnosis:
if keyword in ai_output:
result["is_pass"] = False
result["intercept_reason"] = f"拦截原因:包含违规诊断表述【{keyword}】"
return result
# 规则3:拦截虚假无依据疗法
for therapy in self.fake_therapies:
if therapy in ai_output:
result["is_pass"] = False
result["intercept_reason"] = f"拦截原因:包含虚假医疗疗法【{therapy}】"
return result
# 规则4:无答案时强制标准回复
if self.standard_unknown not in ai_output and len(ai_output) < 5:
result["final_output"] = self.standard_unknown
return result
# 测试示例
if __name__ == '__main__':
# 测试校验引擎
validator = MedicalOutputValidator()
# 测试1:正常合规回复
test1 = "高血压一线用药推荐氨氯地平、缬沙坦"
print(validator.validate(test1))
# 测试2:虚假药品(幻觉内容)
test2 = "高血压推荐服用氨氯西平"
print(validator.validate(test2))
# 测试3:违规诊断
test3 = "你确诊患有高血压"
print(validator.validate(test3))输出结果:
{'is_pass': True, 'intercept_reason': '', 'final_output': '高血压一线用药推荐氨氯地平、缬沙坦'} {'is_pass': False, 'intercept_reason': '拦截原因:包含虚假药品名称【氨氯西平】', 'final_output': '高血压推荐服 用氨氯西平'} {'is_pass': False, 'intercept_reason': '拦截原因:包含违规诊断表述【确诊患有】', 'final_output': '你确诊患有高 血压'}
4. 第三层:人工兜底
4.1 核心原理
针对高血压、糖尿病、感冒等高频医疗问题,采用”执业医师人工审核 + 权威答案白名单“模式:
- 1. 收集高频医疗问题
- 2. 由执业医师按照官方指南生成100%准确答案,也可搜集日常回复记录
- 3. 存入医疗白名单库,AI 直接调用,不经过大模型生成
- 4. 从根源杜绝高频场景幻觉
这是医疗场景安全优先于效率的终极保障,针对高风险、高频率问题实现零幻觉输出。
4.2 执行流程
- 高频问题挖掘:基于用户日志,统计TOP100高频医疗问题
- 医师审核入库:执业医师编写权威答案,标注来源,卫健委指南、药品说明书
- 白名单匹配:用户提问时,先匹配白名单库,匹配成功直接返回答案
- 动态更新:每月更新白名单,同步最新医疗指南
4.3 白名单匹配示例
import json
class MedicalWhiteList:
"""医疗AI白名单库:第三层防护,高频问题医师审核兜底"""
def __init__(self, whitelist_path: str = "medical_whitelist.json"):
self.whitelist_path = whitelist_path
self.whitelist = self.load_whitelist()
def load_whitelist(self) -> dict:
"""加载医师审核的白名单库"""
# 模拟白名单数据:key=用户问题,value=医师审核标准答案
default_whitelist = {
"高血压吃什么药": "高血压一线用药包括氨氯地平、硝苯地平、缬沙坦、氯沙坦、美托洛尔(来源:国家卫健委高血压诊疗指南)",
"糖尿病饮食注意什么": "糖尿病患者建议低糖、低脂、高纤维饮食,定时定量进餐(来源:中华医学会糖尿病学分会指南)",
"感冒发烧怎么办": "普通感冒建议多喝水、多休息,体温超38.5℃可服用对乙酰氨基酚(来源:国家药监局药品说明书)"
}
# 保存到本地文件
with open(self.whitelist_path, "w", encoding="utf-8") as f:
json.dump(default_whitelist, f, ensure_ascii=False, indent=4)
return default_whitelist
def match_question(self, user_question: str) -> str | None:
"""
匹配用户问题,返回白名单答案
:param user_question: 用户问题
:return: 匹配成功返回答案,失败返回None
"""
# 精准匹配(可扩展为模糊匹配)
if user_question in self.whitelist:
return self.whitelist[user_question]
return None
# 测试示例
if __name__ == '__main__':
whitelist = MedicalWhiteList()
# 匹配高频问题
test_question = "高血压吃什么药"
answer = whitelist.match_question(test_question)
if answer:
print(f"白名单匹配成功:{answer}")
else:
print("未匹配到白名单,进入大模型流程")输出结果:
白名单匹配成功:高血压一线用药包括氨氯地平、硝苯地平、缬沙坦、氯沙坦、美托洛尔(来源:国家卫健委高血压诊疗指南 )
5. 第四层:反馈闭环
5.1 核心原理
没有一劳永逸的防护体系,医疗知识持续更新,用户问题不断变化,因此需要用户反馈 + 自动收集 + 模型迭代的闭环:
- 1. 用户标记:回复不准确
- 2. 系统自动收集问题 + 错误回复,存入优化池
- 3. 医师审核标注幻觉类型
- 4. 每周微调模型 + 更新规则引擎 + 白名单
- 5. 持续降低幻觉率
5.2 执行流程
- 1. 反馈入口:对话界面增加“回复不准确”一键标记
- 2. 自动收集:系统记录问题、时间、AI 回复、用户反馈
- 3. 人工标注:医师标注幻觉类型,如虚假药品、违规诊断、无依据建议
- 4. 模型迭代:每周基于标注数据微调大模型,更新规则库
- 5. 效果验证:监控幻觉率,验证迭代效果
5.3 反馈收集示例
import datetime
import json
class FeedbackLoopSystem:
"""医疗AI反馈闭环系统:第四层防护,自动收集优化数据"""
def __init__(self, feedback_path: str = "feedback_pool.json"):
self.feedback_path = feedback_path
self.feedback_pool = self.load_feedback_pool()
def load_feedback_pool(self) -> list:
"""加载反馈优化池"""
try:
with open(self.feedback_path, "r", encoding="utf-8") as f:
return json.load(f)
except:
return []
def collect_feedback(self, user_question: str, ai_output: str, feedback_reason: str):
"""
收集用户反馈数据,存入优化池
:param user_question: 用户问题
:param ai_output: AI回复
:param feedback_reason: 反馈原因(不准确/虚假信息等)
"""
feedback_data = {
"timestamp": datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"user_question": user_question,
"ai_output": ai_output,
"feedback_reason": feedback_reason,
"review_status": "未审核", # 医师审核状态
"hallucination_type": "" # 幻觉类型
}
self.feedback_pool.append(feedback_data)
# 保存到文件
with open(self.feedback_path, "w", encoding="utf-8") as f:
json.dump(self.feedback_pool, f, ensure_ascii=False, indent=4)
print(f"反馈已收集,当前优化池数据量:{len(self.feedback_pool)}")
def weekly_model_update(self):
"""每周模型迭代:基于反馈数据优化"""
# 统计未审核数据
unreviewed = [f for f in self.feedback_pool if f["review_status"] == "未审核"]
print(f"本周待优化数据:{len(unreviewed)} 条")
# 医师审核+模型微调(实战中对接大模型微调接口)
for data in unreviewed:
data["review_status"] = "已审核"
data["hallucination_type"] = "虚假药品信息"
# 保存更新后的数据
with open(self.feedback_path, "w", encoding="utf-8") as f:
json.dump(self.feedback_pool, f, ensure_ascii=False, indent=4)
print("模型每周迭代完成,幻觉率持续优化")
# 测试示例
if __name__ == '__main__':
feedback_system = FeedbackLoopSystem()
# 收集用户反馈
feedback_system.collect_feedback(
user_question="高血压吃什么药",
ai_output="推荐服用氨氯西平",
feedback_reason="回复不准确,药品名称错误"
)
# 执行每周迭代
feedback_system.weekly_model_update()输出结果:
反馈已收集,当前优化池数据量:1 本周待优化数据:1 条 模型每周迭代完成,幻觉率持续优化
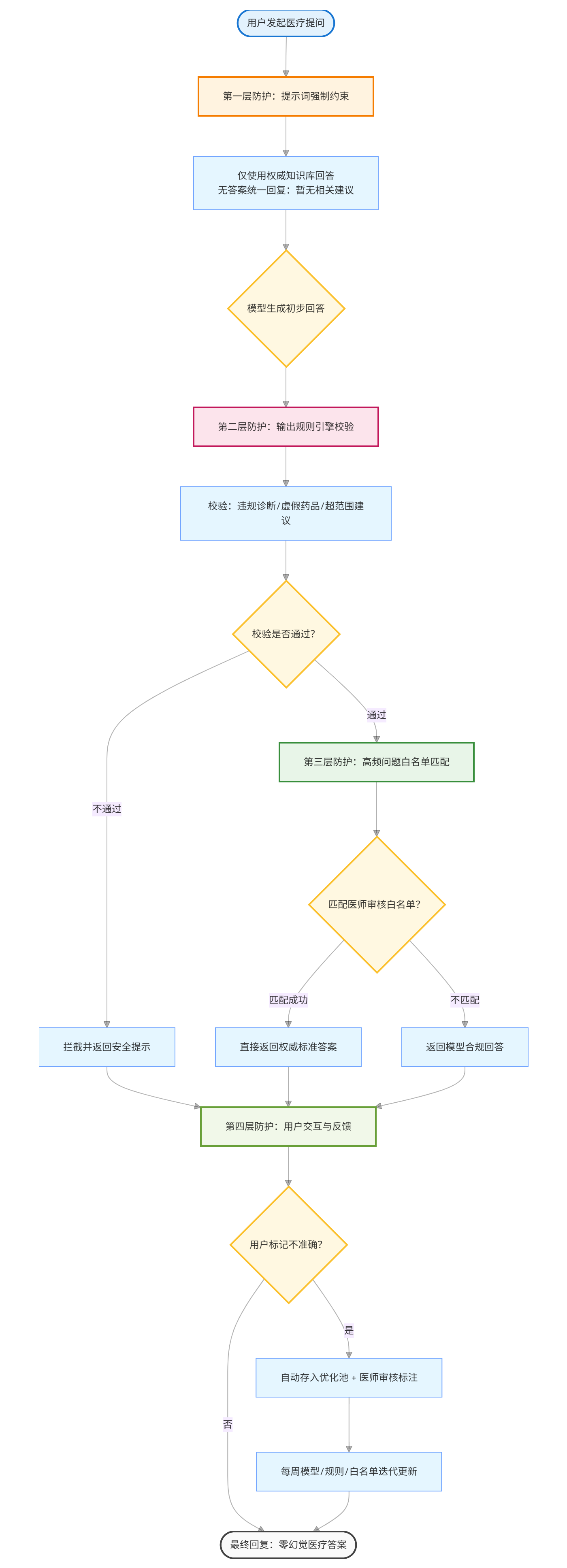
6. 整体执行流程
流程总结:
- 第一层(提示词约束):强制模型仅使用权威知识库回答,对无答案问题统一回复“暂无相关建议”,从源头限制幻觉。
- 第二层(输出规则引擎):对生成的回答进行规则校验,拦截违规诊断、虚假药品、超范围建议等内容,不合规则返回安全提示。
- 第三层(人工兜底):高频问题白名单匹配,命中的直接返回医师审核的标准答案;未命中则返回模型合规回答,平衡效率与准确性。
- 第四层(反馈闭环):用户可标记不准确回答,触发自动存入优化池,由医师审核后定期更新模型、规则和白名单,形成持续迭代的良性循环。
三、幻觉抑制的价值
1. 对大模型的核心意义
- 弥补大模型固有缺陷:用工程化方案解决生成式AI的事实性错误
- 拓展大模型落地场景:让大模型从娱乐场景进入高风险医疗场景
- 建立行业安全标准:为医疗AI制定幻觉抑制的标准化流程
- 实现安全与效率平衡:在零容忍安全要求下,保留AI的辅助效率
2. 医疗行业实战价值
- 患者安全保障:杜绝AI幻觉引发的医疗安全事故
- 医师效率提升:高频问题自动回复,释放医师时间
- 合规落地保障:满足国家医疗AI监管要求,具备商用资质
- 行业信任建立:打造安全可靠的医疗AI标杆
3. 四层防护体现效果
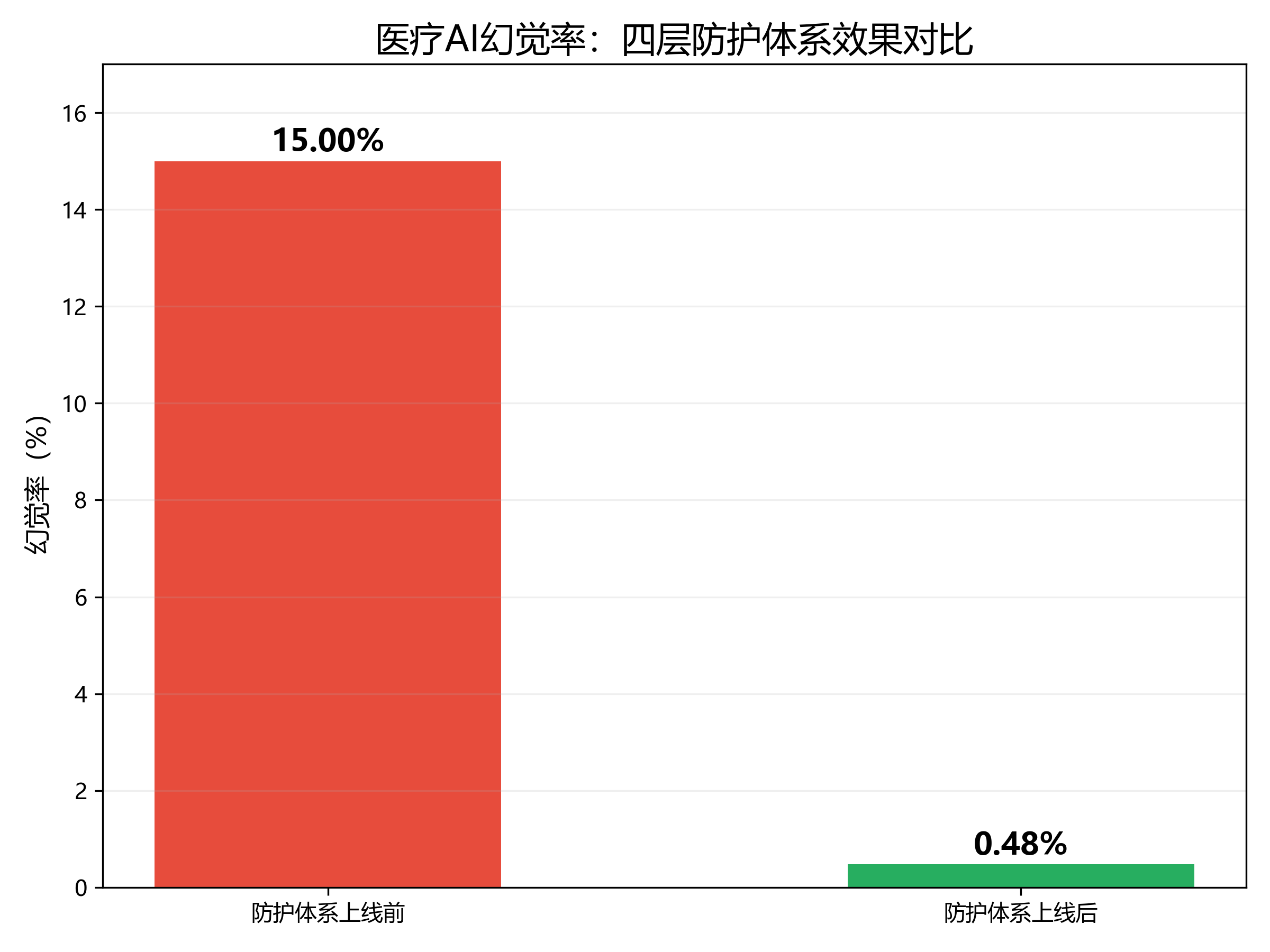
4. 幻觉率趋势图
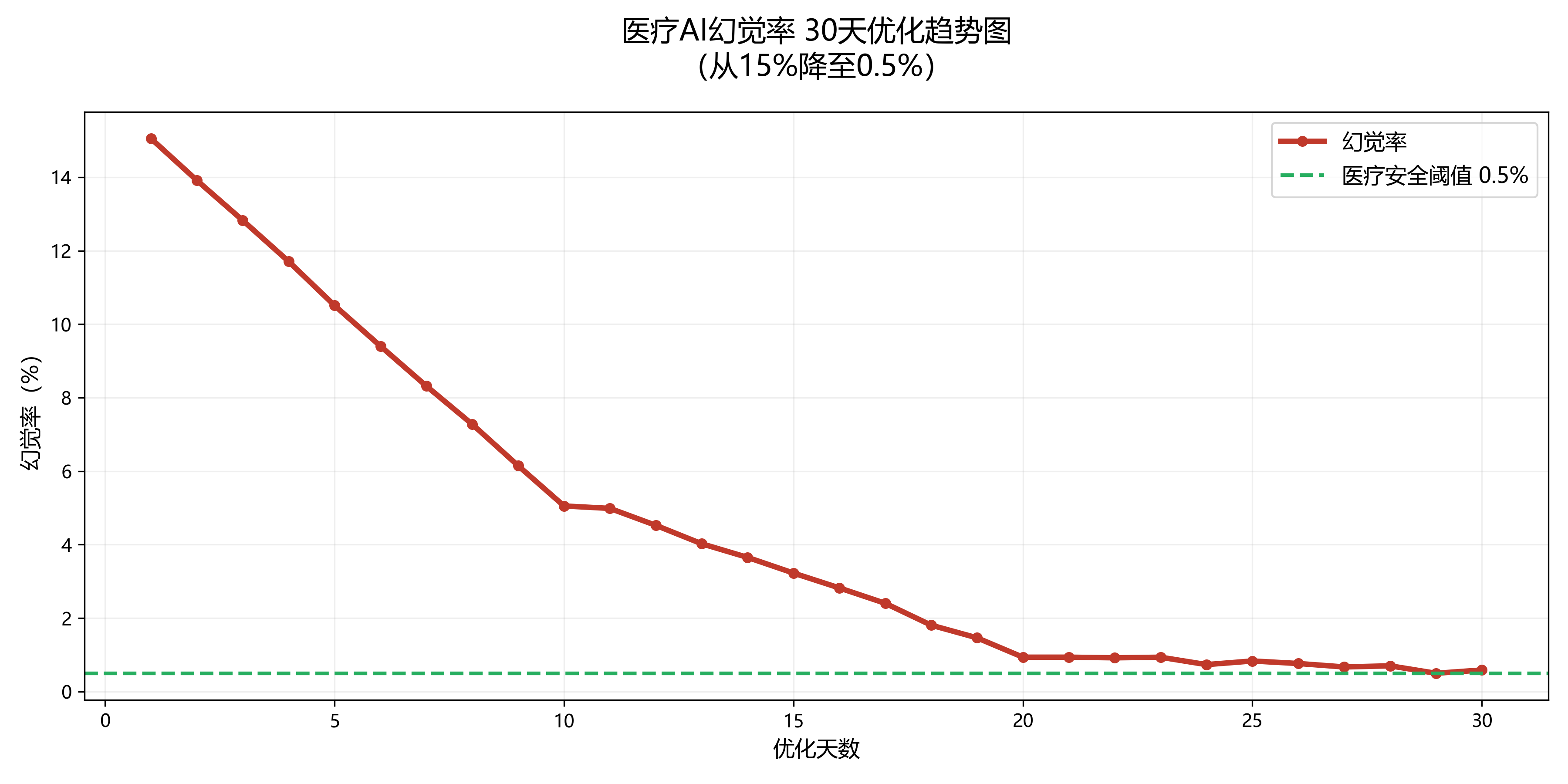
四、总结
其实医疗AI幻觉抑制,核心就是解决一个问题,医疗场景容不得半点虚假,必须做到零容忍,医疗领域,编个药名、错给个诊断,都可能出大事,所以必须要构建实打实的四层防护,层层把关。
- 第一层提示词约束,就是给 AI 立规矩,只许用知识库的内容,不会就说暂无相关建议,从源头不让它瞎编;
- 第二层输出校验,像个安检机,扫描 AI 的回复,有虚假药品、违规诊断就直接拦截;
- 第三层人工兜底,高频问题比如高血压用药,让执业医师审核好存进白名单,AI 直接调用,彻底杜绝高频场景幻觉;
- 第四层反馈闭环,用户觉得回复不准就标记,每周迭代优化,越用越靠谱。
整体而言,这不是靠单一技术,而是用工程化的闭环,弥补大模型的固有缺陷,既保证了医疗安全,又能发挥 AI 的辅助作用,真正实现了医疗场景 AI 的安全落地。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号