IM分布式架构系列(12)消息序号为什么不能用雪花 | 三种发号方案比较
原创
IM分布式架构系列(12)消息序号为什么不能用雪花 | 三种发号方案比较
原创
拉丁解牛说技术
修改于 2026-06-07 21:05:13
修改于 2026-06-07 21:05:13
当机器能背下全世界的知识,你的价值就不再是'你知道什么',而是'你能用知道的东西,做出什么判断'。
AI 抹平了'信息差',但抹不平'认知差'。未来真正稀缺的,不是会干活的人,是知道'该干什么'的人。
一、消息序号与实体 ID 是两道不同的题
1.1 消息标识在 IM 链路中的位置
1.2 同一个系统里的两种取舍
二、三种发号方案与会话级号段的落地
2.1 方案一:客户端 UUID 与去重键
2.2 方案二:全局发号与连续性的缺口
2.3 方案三:按会话分配的单调号段
2.4 前驱链与会话级锁的代价
2.5 步长批量与本地缓存
三、大厂如何设计
四、如何优化提升
一、消息序号与实体 ID 是两道不同的题
1.1 消息标识在 IM 链路中的位置
一条消息从客户端发出到对端收到要经过几道处理:客户端先打一个本地标识用于重传去重,上行到服务端后分配一个会话内序号用于排序和补洞,再落库、扇出、推送。
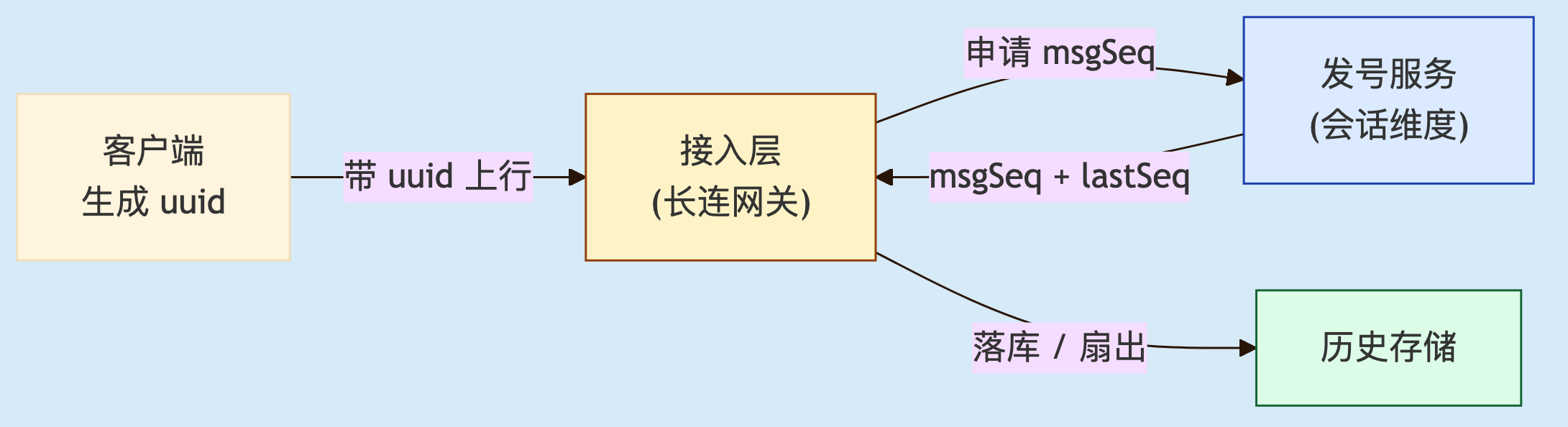
一条消息的ID("唯一性")和序号("顺序性")是两个要求,如果仅用一个字段表示,分布式下很难同时满足。拆开就清楚——唯一性交给一个无序但永不重复的 ID,顺序性交给有序但不必跨会话唯一的序号。
序号在IM分布式环境下,对业务的影响非常大,生产实践过程中反复见过的故障有:
- 序号在会话内不连续,客户端会误判"漏消息"。客户端本地维护一个"已收到的最大序号",靠它和服务端比对来判断有没有缺。如果服务端发的序号本就跳号(比如 105 直接到 108,中间的 106、107 是别的会话占走的),客户端无从分辨这是正常空洞还是真漏了,保守起见只能触发一次全量拉取。单个客户端拉一次不要紧,可一旦某次发号逻辑批量产生跳号,成千上万的客户端会在同一时间窗里集体回源全量拉,把历史存储瞬间打穿——这是典型的拉取风暴。
- 用雪花当消息序号,增量同步接口算不出"从哪拉"。增量同步的契约是客户端报上本地最大序号
N,服务端返回N之后的所有消息。这要求序号在会话内是稠密递增的,服务端拿N就能定位区间。可雪花是全局趋势序,同一会话相邻两条可能差出一大截,服务端拿到客户端报的雪花值,根本算不出该从哪条往后捞——这个接口直接退化成只能全量比对,增量同步名存实亡。
1.2 同一个系统里的两种取舍
实体 ID 要的是"全局唯一",雪花天然满足:时间戳在高位保证趋势递增,机器位保证不撞号,本地生成无网络开销。用在用户、设备这类标识上挑不出毛病。
但是消息序号,要的不是全局唯一,而是雪花给不了的事:在一个会话内严格单调,且最好连续。客户端判断"这个会话有没有漏消息""增量同步从哪一条拉",靠的就是序号在会话内连成一条没有断点的线——这点连续性正是雪花结构上给不了的。
二、三种发号方案与会话级号段的落地
IM 的消息标识至少要满足以下几个要求:
- 唯一去重:同一条消息因弱网重传多次,服务端必须认出"这是同一条",只落一份。
- 会话内单调连续:同一会话序号严格递增、尽量不跳号,支撑排序、未读补洞、增量同步。
- 高吞吐低延迟:发号在主链路上,每条上行消息都要过一次,慢一点就是全局尾延迟。
2.1 方案一:客户端 UUID 与去重键
第一个标识在客户端生成:每条消息发出前,客户端给它生成一个 uuid(本地唯一、随机不可预测的字符串)。它的价值只有一个——去重。
弱网下客户端发完消息没收到 ACK 会重发,重发携带的 uuid 和上次完全一样。服务端只要见过这个 uuid,就知道是重传,直接返回上次结果,不再走第二遍落库和扇出。这是 IM 幂等性最朴素的闸。
但 uuid 无序、不可比较:两条 uuid 比大小毫无意义,既不能排序,也不能判断"少了哪条"。所以它只能当去重键,绝不能当消息序号——满足唯一性,却完全不碰顺序性。
2.2 方案二:全局发号与连续性的缺口
到这一步很多人的第一反应是:那就上一个全局发号器,雪花或时间戳类,给每条消息发一个全局唯一且趋势递增的 ID,顺序问题不就解决?
理想很丰满。全局发号确实能给出趋势递增的序,落到 IM 消息场景却有两道坎:
第一,依赖机器时钟。雪花的高位是毫秒时间戳,一旦时钟回拨(NTP 校时、虚拟机漂移都可能触发),同一时刻可能发出和过去重复的 ID。消息系统对回退极其敏感——序号一回退,增量同步会算错该拉哪段,消息要么重复要么凭空消失。
第二,也更致命,它是"全局"序,不是"会话内"的连续序。两条雪花 ID 比大小只能知道粗粒度的先后。但 IM 要做的"这个会话有没有漏消息""从本地最大序号往后增量拉",需要的是会话内连续的序号——客户端本地最大是 105,下一条必须是 106,缺了就知道要补。雪花的全局序里,同一会话相邻两条可能是 8801 和 9532,中间跳一大段,客户端无法判断这是别的会话占走的、还是自己真漏了。连续性,雪花结构上就给不了。
所以全局发号能当实体 ID,却不适合当消息序号。这正是开头那个反差的答案:不是雪花差,是消息序号多要了"会话内连续"。
2.3 方案三:按会话分配的单调号段
把前两个方案的缺口补上,落点清晰了:用一个号段模式发号器,按会话维度给每条消息分配严格单调递增的 msgSeq。
号段模式的核心是"批发"而非"零售"(类似业界常见的 segment 模式,美某团 Leaf 是公开代表实现):不是每来一个请求就去存储 +1,而是一次从 Redis 取一批连续序号缓到本地,用完前从本地内存直接发,发完再取下一批。
alloc_seq(conv_id):
segment = local_cache.get(conv_id)
if segment is None or segment.exhausted():
// 一次批发一段,减少 Redis 往返
start = redis_incrby("seq:" + conv_id, step) // step 默认 10,最大 100
segment = Segment(start - step + 1, start)
return segment.next() // 本地自增,无网络开销按会话分号段是关键决策:每个会话有独立发号空间,A 怎么发都不影响 B。这正好对上"会话内单调连续"的要求——同一会话的序号一定是 …, 104, 105, 106, … 连续不断的。
去重则旁挂一层:服务端拿到上行 uuid 后,先查一个 Redis key(uuid → 已分配的 msgSeq,TTL 设置个20 分钟),命中就直接返回老序号。这样同一条消息在 TTL 窗口内无论重传几次,拿到的都是同一个 msgSeq。20 分钟的 TTL 覆盖绝大多数弱网重传窗口,又不让去重 key 无限堆积。
2.4 前驱链与会话级锁的代价
光有 msgSeq 还差一口气。客户端判断"有没有漏消息",光知道自己这条是 106 不够——它得知道"106 的前一条是不是已收到的 105"。于是每条消息除了自己的 msgSeq,还要记下前一条的序号 lastSeq,串成一条前驱链。客户端靠 (lastSeq, msgSeq) 就能判断中间断没断。
问题来了:要拿到"前一条的序号",得先读当前会话已分配的最新值、再把自己写进去,这是一个 get-then-set。并发下两条消息同时读到 105、都把前驱记成 105,前驱链就串了。要避免串链必须串行化——实践里在会话维度上加一把分布式锁,锁内用一段 Lua 完成"读旧值、写新值"。
锁粒度是会话级,有意为之:不同会话互不阻塞,只有同一会话的并发写才竞争同一把锁。代价在热点会话上现形——一个高频群多条消息挤在同一把锁上,拿不到的要自旋重试(典型重试 3 次、间隔 200ms),这段等待直接进尾延迟。
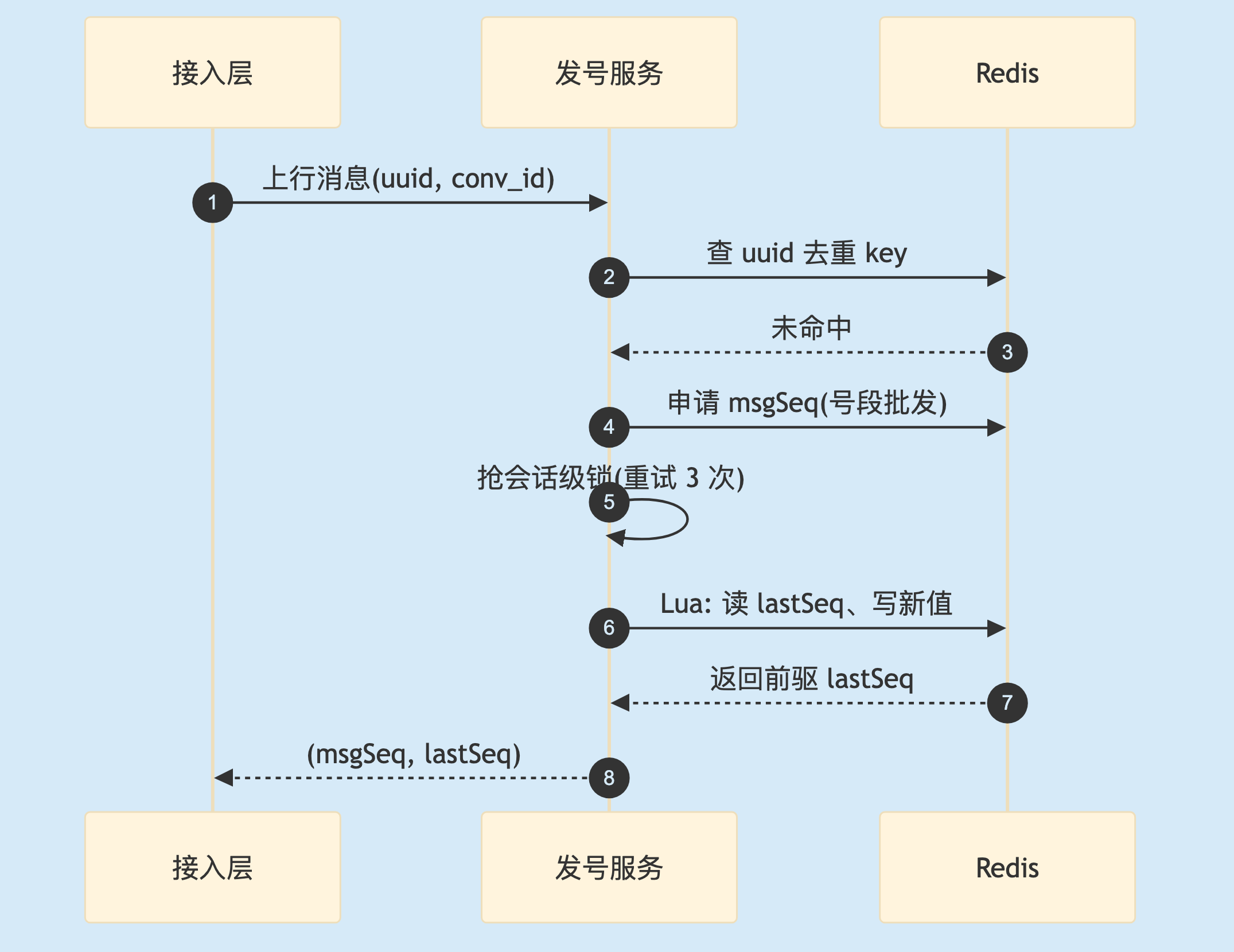
还有个瑕疵要诚实交代:发 msgSeq 和记 lastSeq 是两步、非原子。极端下 msgSeq 发了、lastSeq 更新却失败,前驱链会出现一个小断点。概率低但存在,是两步设计固有的账。
2.5 步长批量与本地缓存
号段模式省 Redis 往返的关键在步长。步长设 10 意味着每发 10 个序号才打一次 Redis,设到 100 就是 100 个序号一次往返。步长越大 Redis 压力越小,但重启时浪费的号也越多。实践里给一个默认步长、一个上限,在两者之间取中间。
还有一类消息能再省一层。端到端加密场景下,客户端常常一次密钥协商后批量连发多条,落在同一会话、时间挨得近。针对连发在发号服务本地再加一层小容量进程内缓存,同一会话的号段直接本地命中,连批发那次 Redis 都省了。但这层缓存只对"连发"有效;普通单聊消息到达分散,大多不命中,去重还得回查 Redis。
完整方案是:uuid 管去重,会话号段发 msgSeq 管单调连续,前驱 lastSeq 管补洞,步长批量加本地缓存管吞吐。
三、大厂如何设计
3.1 某信:按用户分配的 seqsvr
某信内部的序列号生成器 seqsvr,给每份需要和客户端同步的数据(含聊天消息)分配一个递增序号当数据版本号——客户端带上本地最大版本号,服务端算出增量返回。据公开分享的量级,这套系统每天有数千亿级的调用,申请序列号平时 1ms,99.9% <3ms。
它的核心设计有两点。其一,每个用户有独立的序号空间。公开资料明确说,全局唯一序号会有严重的申请互斥问题,难以做高性能;按用户隔离后,小明怎么发都不影响小红。其二,预分配号段中间层:内存里存当前值和上限,发号时自增,超过上限才把上限抬一个步长并持久化(实际步长取 10000),硬盘 IO 从每秒千万级降到千级。工程上拆成 StoreSvr(多机 NRW 保证不丢)和 AllocSvr(分摊请求),再按 uid 范围分 Set 灾难隔离。
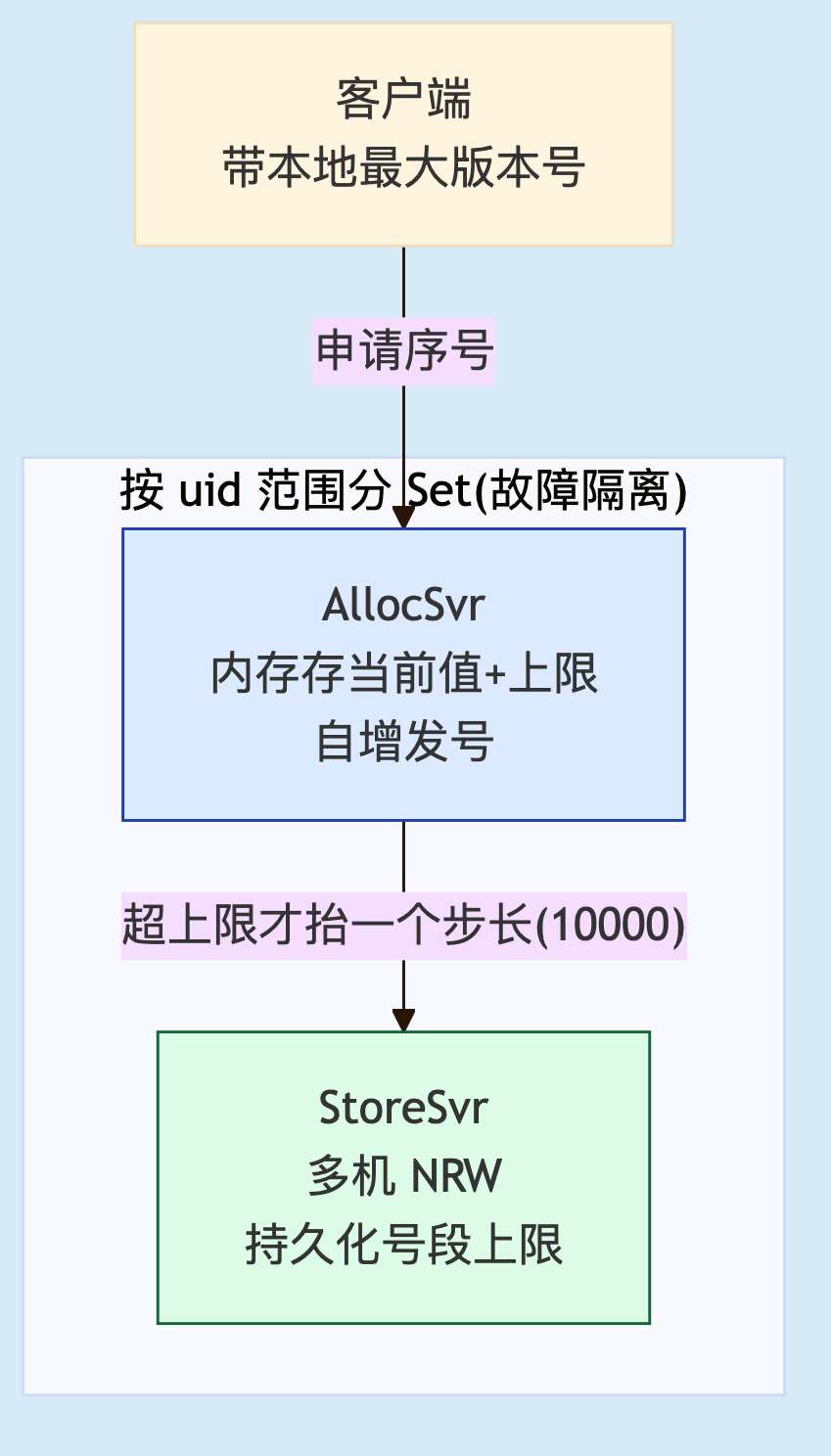
维度 | 详情 |
|---|---|
优势 | 按用户隔离避开全局互斥,吞吐极高;号段预分配把存储 IO 压到千分之一;分 Set 故障隔离 |
代价 | 只递增不连续,重启第一个序号跳一大段;按用户而非会话,会话级"漏没漏"需上层处理;整套架构重,中小项目养不起 |
3.2 美某团 Leaf:号段与雪花的双模式
美某团的分布式 ID 系统 Leaf ,它公开总结过业务对 ID 的四类要求:全局唯一、趋势递增、单调递增、信息安全——并指出单调递增和信息安全互斥,没法用同一方案满足。这正是"实体 ID 和消息序号要分开"的理论依据。
Leaf 因此提供两种模式:号段模式从数据库批量取号段缓在本地,双 buffer 预加载避免取号段毛刺,适合要求趋势/单调递增的场景;雪花模式本地生成 64 位 ID,适合只要唯一、容忍非连续的场景。两种模式并存本身就说明:同一个团队,也得为不同场景配不同的发号方式。
维度 | 详情 |
|---|---|
优势 | 双 buffer 预加载,取号段无毛刺;双模式覆盖"要连续"和"只要唯一";有开源实现可借鉴 |
代价 | 号段模式依赖 DB,DB 抖动影响发号;雪花模式仍受时钟回拨困扰;同样有重启丢号的浪费 |
3.3 融某云:把维度内嵌进 ID
前面几家都在解"怎么分配一个序号",融某云换了个思路:不分配,直接拼。据公开分享,融某云的消息 ID 是一个 80 Bit 的结构,切成四段——42 Bit 时间戳(高位放时间,整体按时间有序,可表示到 2109 年)、12 Bit 同毫秒内的自旋序号(单机每毫秒最多标识 4096 条)、再加会话类型和会话 ID 两段。最后每 5 Bit 做一次 32 进制编码,80 Bit 转成 16 个字符,加 3 个分隔符拼成形如 BD8U-FCOJ-LDC5-L789 的 19 字符 ID。
这个设计最关键的一点:ID 里内嵌了会话维度,所以不需要中心发号器。时间戳和自旋序号每台机器本地就能算,会话类型和会话 ID 本就来自消息上下文,四段一拼即得——每个节点独立生成,无状态、可水平扩缩容,没有任何一处需要去中心节点申请号。它和其余几家的对照很鲜明:某信、Leaf、Snowflake 都在想办法把"发号"这件事做快做稳,融某云则干脆把发号这一步从主链路上抹掉了。
维度 | 详情 |
|---|---|
优势 | 无中心发号器,节点独立生成、无状态可水平扩缩容;时间戳在高位保证整体趋势有序;ID 自带会话维度,定位会话无需回查 |
代价 | 同机同毫秒受 12 Bit(4096)上限约束;ID 是 19 字符串而非紧凑整数,存储与索引开销更大;会话内并非稠密连续,补洞仍需上层配合 |
四、如何优化提升
会话级号段前面也说了,其实都是有短板有问题的: 会话级锁的尾延迟、两步非原子的前驱链瑕疵、发号键膨胀、重启丢号。具体有没有优化空间?
4.1 发号与记前驱的原子化
那把会话级锁,根子在"发号"和"记前驱"是两步,靠锁串行化。但这两步可以合并成一次原子操作——用一段 Lua 在 Redis 里同时完成:读出旧序号 oldSeq、算新序号 newSeq = oldSeq + 1、写回,然后一次返回 newSeq 和 oldSeq。oldSeq 就是前驱,newSeq 就是本条序号,前驱链天然不串,显式分布式锁整个去掉。
这么改有两个收益:省掉一次抢锁加自旋重试,热点会话尾延迟立刻下来;发号和记前驱原子完成,那个"msgSeq 发了但 lastSeq 没更新"的小断点也消失了。
4.2 冷热会话的动态步长
固定步长是个偷懒的选择。但是一个冷会话:一个一年发三条消息,批发 100 个号,99 个永远用不上;另外一个每秒几十条的热点群,步长 10 意味着频繁打 Redis。
更合理的做法是步长跟着会话热度走:冷会话步长压到很小(甚至 1,退化成零售),省下浪费的号;热会话步长自动抬高,减少 Redis 往返。判断冷热看会话最近的发号频率即可。某信固定步长 10000 建立在"几乎所有用户都活跃"的前提上;中小 IM 会话活跃度差异极大,一刀切两头不讨好。动态步长本质是把批发批量和会话的实际消费速度对齐。
4.3 会话发号键的膨胀治理
按会话分号段有个隐性的账:Redis 里的 key 数量随会话数膨胀。每个活跃会话至少一个号段 key,再加去重的 uuid key——会话总量大起来都是真金白银的内存。toB IM 动辄几十万会话,这笔账不容忽视。
治理方向有两条。其一,冷会话号段回收:长期不发号的会话,把号段 key 连同当前值持久化到冷存储后从 Redis 清掉,下次有消息再恢复——用一次恢复延迟换常驻内存。其二,去重 key 的 TTL 收紧:20 分钟覆盖弱网重传足够,内存压力大时可再压。核心判断是:哪些 key 是"活跃必需",哪些只是"以防万一还留着"。
4.4 重启浪费这笔账要不要省
号段模式有个绕不开的特性:发号服务重启,当前号段里没发完的号就废了。比如步长 100、批发到 1100 才发到 1105 就重启,1106 到 1200 直接跳过,下次从 1201 起。看着浪费,这笔账我倾向不省。
理由是号段方案最该死守的底线是不重号,而"重启跳号"恰恰为了守住它——重启后从持久化的号段上限往后发,绝不回头用已批发出去的号,代价就是丢一段。要把这段省回来,得引入更复杂的状态持久化,在主链路加 IO,还容易在恢复逻辑里埋下重号隐患。消息序号本就只要求单调连续,不要求"绝对不跳号"——客户端靠 (lastSeq, msgSeq) 判断的是"前驱对不对",跳号只要前驱链不断就不影响补洞。用一段可接受的浪费换"绝不重号",划算。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号