为什么各路巨头都盯上Marvell?

为什么各路巨头都盯上Marvell?

通信行业搬砖工
发布于 2026-06-08 10:32:26
发布于 2026-06-08 10:32:26
在2026年6月初的台北南港展览馆,Computex智算峰会的现场被长枪短炮围得水泄不通。台下的华尔街分析师和全球科技记者都在焦灼地等待英伟达最新的显卡架构,或者哪怕是一个关于下一代大模型参数的惊人数字。然而,当英伟达首席执行官黄仁勋阔步走上舞台时,他却把身边的Marvell董事长墨非拉到了聚光灯的正中央。

黄仁勋面对台下黑压压的镜头,扔出了一颗让所有人始料未及的深水炸弹。他伸出手指向墨非,声音通过音响震动着整个会场,他说,当你使用代理AI时,把一个运算问题拆解成许多部分,并分散到整座数据中心中执行,最不可或缺的就是连接能力,这就是为什么墨非做得这么好,也就是为什么Marvell如此关键。
台下的绝大多数普通观众对这家低调的美国半导体公司感到困惑,但太平洋对岸的华尔街财阀们已经在神谕降临的瞬间按下了交易键。
几个小时内,纽约证券交易所的盘面发生了史诗级的震荡。Marvell的看涨期权持仓量被做多资金强行拉爆,股价在单日内录得超过32%的疯狂暴涨,一举击穿历史新高。期权市场上爆发了恐怖的伽马挤压,那些习惯了做空网通周期股的对冲头寸在短短几个小时内遭遇了无情的血洗。
资本市场之所以如此失控,是因为在此之前,英伟达向Marvell闪电注资20亿美元、并连带在一夜之间扫货光通信供应链的底牌被彻底坐实。这场真金白银的军备圈地运动揭开了一个残酷的行业共识:在GPU单卡算力增速逼近边际递减的迷雾中,AI产业最确定、也最庞大的一笔利润重新分账,已经在连接技术这一隐秘的阵地里悄然打响。
但这绝不仅仅是一个硅谷算力新贵与华尔街财阀合谋的财富故事。当大模型的算力成本高企,正变成一场抽干全球电网、逼迫普通人用更高代价订阅AI服务的数字税时,Marvell在光电连接领域的爆发,本质上是科技巨头们为了维持这个算力神话不破灭,在物理学绝壁前筑起的最后一道数字长城。
要理解这场资本狂欢背后的窒息感,必须把时间拉回到大模型爆发前的传统网络基础设施时代。
在那个由传统电信运营商和传统公有云主导的缓慢世界里,人类数据中心基础设施的迭代遵循着一条极其优雅且省钱的物理时间表。从10G、40G跨越到400G,网络带宽的升级像温水煮青蛙一样缓慢,按照传统的摩尔定律和电信周期规律,从机架内的铜缆互连演进到全面昂贵的光网络机柜,原本是一场允许跨越30年的漫长改良运动。
说到这里让我们想起中国移动、中国联通这群背负着大国网络通信基础设施建设使命的修路人,曾经背负着沉重的成本去铺设庞大的光纤网络,最后却眼睁睁看着坐在车上的BAT为代表的互联网、内容电商等巨头抽干了最后一滴流量红利。而如今,AI以一种更为暴力的姿态,把这条30年的优雅路线图硬生生压缩到了5年内走完。
这背后的本质是,资本从来不会发明新故事,它只是给老赌徒换了一张更昂贵的赌桌。
- 早在二十年前的宽带泡沫时代,墨非和陈福阳(博通CEO)就在为了抢夺一根小小的以太网网线专利在法庭上撕咬得鲜血淋漓。
- 二十年过去了,当年的网线变成了今天的全光织物,战场从传统的电信机房搬到了万卡智算中心,但这两只从硅谷死人堆里爬出来的老鳄鱼,撕咬的姿势和当年没有任何区别。
AI对计算集群、内存频宽和数据吞吐的贪婪索求,是一头每天都在吞噬资源的物理怪兽。当单通道lane速率直奔224G这一历史极限时,传统的铜导线遇到了一面无法逾越的物理南墙。在224G的超高频电信号下,铜导线的阻抗和信号衰减呈指数级飙升,它甚至无法在超过1米的物理距离内保持信号不失真。这意味着,铜缆连拉满一个普通的计算机架都做不到了。
物理学规律从来没有变过,变的是AI在后面挥舞的鞭子,它强制把整个人类半导体行业推向了必须立刻以光代电的绝壁。
AI基础设施的所谓四条战线(scale in/scale up/scale out/scale across),说白了就是一场对现有网络基础设施展开了一场全方位的光电拆迁运动。
- 芯片内部不够用了,就得搞“微观拆迁”把内存和算力强行合租;
- 机柜连不上了,就得搞“跨界搭桥”用光纤把GPU绑成连连看;
- 集群之间数据海啸了,就是“全城修高架”。
Marvell干的不是什么探索宇宙的科学大计,也不是新能源自动智驾的星辰大海,它就是在这个万亿智算工地里,垄断了所有高架桥收费站、顺便把持了钢筋水泥标号的终极包工头。
这四条战线如同一个密不透风的全光合围模型,将所有的半导体巨头逼入死角,而每一个关口的钥匙,都恰好握在Marvell手里。
真正把这场全光合围推向全面失控的,是2026年全球软件层发生的产业革命。
当AI的演进路径全面从简单的文本生成迈向下一代世界模型,也就是对物理世界进行实时多模态模拟时,底层的硬件绞肉机被彻底启动。世界模型要求数十万卡集群在微秒级别内完成时空对齐与物理规律渲染,这意味着哪怕模型的总参数量不发生指数级翻倍,为了实现毫秒级的空间物理同步,集群内部的超低延迟同步需求也会暴增数倍。任何微小的网络抖动,都会导致模拟世界的物理规律发生崩溃。
此时,在远离硅谷风暴中心的中国光通信之乡,武汉光谷,民营光模块工厂的老板们正盯着每天都在更新的订单订单出神。这些企业虽然拿下了Greater China市场大半的光模块订单,虽然说Greater China市场占据全球通信产业巨大份额,他们却在2026年开春后陷入了集体的彻夜难眠。
因为世界模型对延迟的极限压榨,与黄仁勋在Computex上疯狂推崇的AI PC端云混合推理概念撞在了一起。数以亿计的边缘PC终端不再是孤立的硬件,它们成为了高频调用云端大上下文的触手,引发了人类通信史上最猛烈的一次算力外溢,云端与边缘端的双向夹击,让1.6T高速光模块的需求瞬间被拉到了历史顶峰。
面对这场饕餮暴食数据的海啸,英伟达比任何人都清楚自己的软肋在哪里。
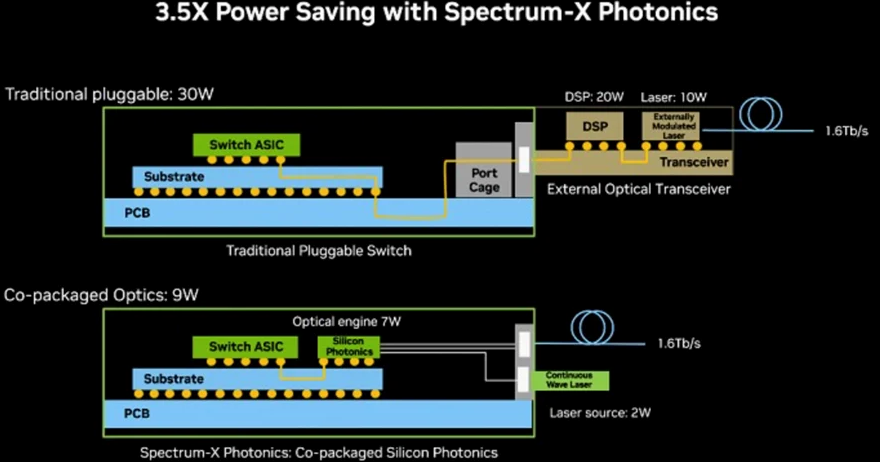
如果继续使用传统的网络架构,英伟达引以为傲的NVLink机柜就会沦为一个无法突破1米物理限制的孤岛。为了打破这堵墙,Marvell在2026年2月悄然完成了一笔震惊业界的动作,斥资32.5亿美元彻底完成了对Celestial AI的收购,将核心黑科技光子织物技术平台完美纳入麾下。
这项光子织物技术能提供比传统普通光网络高出25倍的超大带宽,同时将延迟和功耗直降10倍,真正实现了计算与内存的解耦。当英伟达把这套全光交织技术引入NVLink Fusion架构后,50米范围内的零延迟光传输彻底打破了高带宽内存的容量墙,数万颗GPU在光子的牵引下,像单颗芯片一样进行统一的高频内存调度,老黄梦寐以求的“机柜即电脑”终于从图纸变成了现实。
然而,在通往全光终局的道路上,半导体行业不得不先经历一场由物理学发动的残酷清算。
在过去几年的智算大跃进中,市场为了追求省电和降低成本,曾天真地以为用不带数字信号处理芯片的线性驱动技术可以省掉高昂的oDSP。资本市场一度为这种无DSP的低功耗方案画出了一块巨大的饼,然而,当1.6T光模块的核心工艺,也就是单通道224G时代在2026年强行降临时,高频物理学的铁拳狠狠地砸在了每个投机者脸上。
单Lane 224G就像是让一万辆超跑在一条全是急转弯、没有护栏的单行道上飙到时速500公里。在这样的极速下,稍微一点风吹草动带来的信号衰减与高频噪声,都会让车全部撞成废铁,电信号传过去直接变成了一堆无法分辨的电子乱码,行业使用误码率来衡量这一指标。
线性驱动方案天真地以为只要老司机技术好就能省掉安全带,然而在变态的噪声面前,系统的自动纠错机制会直接罢工。没有oDSP作为“AI交警”在微秒之间用超级数学算力实时纠正每辆车的方向盘,整座数据中心就是一个连环追尾的废铁厂。物理学在这一天收回了人类所有的自作聪明,行业不得不低下高傲的头颅,重新排队去买oDSP的入场门票。
所以当光通信的CPO技术迈向下一代的时候,oDSP技术是必不可少的选项。
这正是Marvell最宽阔的一道护城河。在当年通过百亿美元鲸吞Inphi之后,Marvell在高端PAM4 oDSP市场上与博通Broadcom形成了恐怖的实质双寡头垄断。
光模块的两大核心里,磷化铟激光器是提供纯净光源的底层基石,而oDSP则是操控信号的大脑。在1.6T时代,为了解决高功率下的散热与可维护性,整个共封装光学方案被迫全面转向外置光源。Marvell不仅用3nm先进制程的1.6T oDSP死死卡住了全行业的脖子,还通过定义外置光源的接口标准,将全球上游的磷化铟激光器巨头们死死捆绑在了自己的全光战车上。
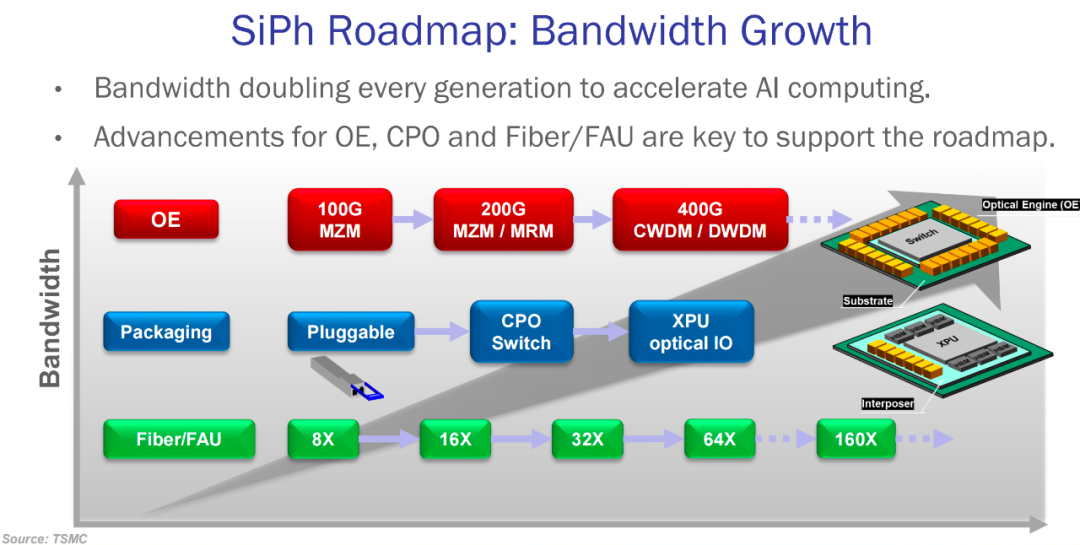
这种不可替代性让华尔街的精算师们得出了一个极为明确的远期预测:未来三年内,任何试图绕过oDSP技术和PF光交织技术的下一代方案都将沦为乌托邦。Marvell的身份正在从一个网通配件供应商,暴力跃升为下一代全光系统架构的底层标准制定者。
而对于武汉光谷的老板们来说,最残酷的事情正在发生:因为核心的3nm先进制程oDSP和物理层核心协议的技术铁幕落下,中国企业虽然造得出全世界最便宜的光纤,调得出最精密的激光,却在这场全光分账里只能拿到最微薄的封装苦力钱。全球算力通胀,底层的利润却在向顶端加速收拢。
在这场波谲云诡的万亿分账里,Marvell最恐怖的生存智慧在于它成功扮演了“半导体瑞士”的角色。
英伟达是算力帝国的霸主之一,它最希望的是全天下都使用其私有的InfiniBand协议和闭环的NVLink,把整个AI生态做成如同苹果系统一般的铁幕,而博通则是传统以太网和定制化芯片领域的绝对霸主,手段同样强硬。
在西雅图和山景城的深夜办公室里,萨蒂亚·纳德拉和皮查伊看着每个季度给英伟达开出的百亿算力账单,内心都在滴血,这群硅谷高管们嘴上全是人类命运共同体,心里算的全身布料钱。他们名义上是世界科技的领航员,实际上在这个夏天,他们和每一个排队去抢周杰伦演唱会门票的普通粉丝一样,都在卑微地乞求黄仁勋能在产能配额上对他们多看一眼。

他们极度渴望摆脱博通高昂的定制费和英伟达的芯片配额大棒,而Marvell走了一条极其聪明的两头通吃路线。
它一边靠着光交织技术,成为了英伟达帝国扩建全光机柜时离不开的首席工程师,借此从老黄手里拿到了20亿美元的续命军粮。
另一边,它看穿了北美超级数据中心巨头极度渴望“去英伟达化”、“去博通化”的阳谋。Marvell聪明地将自己的oDSP和光交织技术做成模块化的小芯片乐高积木,大开方便之门。客户只需要专注于编写自己的AI算法,高难度的物理层连接直接套用Marvell现成的芯片积木。对于那些渴望在深夜反抗算力霸权的巨头来说,Marvell递过来的技术积木,就像是深夜里送到手里的制敌武器。这种极具弹性的中立姿态,让它在2026年成为了全球云端巨头对抗垄断的第一顺位厂商。
墨非(Marvell CEO)在一次接受记者采访时,曾淡淡地提到,他每天最关心的不是算力能翻多少倍,而是如何在两个巨人的脚趾缝间,找到那根最结实的光纤。这种在夹缝中跳舞的艺术,才是硅谷丛林里最真实的生存密码。
这场由物理极限和巨头角力逼出来的全光革命,绝对不是停留在硅谷白皮书里的行业黑话。当全球封测龙头日月光的吴田玉博士高调站上舞台,宣布锁定产能并即将为Marvell大批量出货时,这场技术海啸完成了它在工业制造端的最终闭环。
从台积电3nm车间里走出的先进制程前端晶圆,在日月光的先进封装平台上与硅光子器件进行毫米级别的异质整合,最终变成了贴着Marvell标签的成品。
在东莞、苏州、或者张江高科那些拿着固定月薪的硅光封装测试工程师们,正穿着密不透风的无尘服,在无声的车间里经历着魔鬼般的加班。正是这群人在工艺极限的边缘高频调校着磷化铟激光器的对准精度,才撑起了华尔街单日32%的暴涨。在这个坚固的东方供应链铁三角里,流动的不是什么数字魔法,而是不知疲倦的工厂流水线轰鸣声。
人类自以为是用AI在开启上帝视角的“世纪模型”,在虚拟中重构物理规律,但极具讽刺意味的是,为了支撑这个虚拟神话,人类却在现实世界中,被最基础、最沉重的物理学规律死死勒住了喉咙。
大模型越聪明,人类对光子、对铜线、对铟激光器的依赖就越回到了原始和笨拙。
在这场由华尔街期权、硅谷天才和东方无尘车间共同堆砌出来的全光史诗里,每个人都觉得自己是赢家。老黄卖出了更多的机柜,墨非赚到了几辈子花不完的分红,对冲基金在香槟的泡沫里弹冠相庆。
但当深夜的硅谷高管敲击键盘,生成最新的AI提示词时,那道指令将化作一道冰的光信号,穿过大洋底部的幽暗光缆,最终变成东莞工厂流水线上,女工护目镜上一闪而过的一缕微光。人类用最顶级的智慧,在物理学的绝壁前修筑了一座密不透风的光子牢笼。到最后,Marvell赢得了解锁下一个时代的万亿门票,而那个在工位上被算法鞭笞、在无尘车间里熬红了眼的普通人,也一如既往地,成为了这台由光子织成的终极怪兽身上,最先被磨损掉的那颗零件。
参考资料:
1. TSMC 高阶 CPO 技术与先进封装发展研究报告解读
https://www.eet-china.com/mp/a458654.html
2. Nvidia, Arm and Marvell emerge as key Computex winners
3.
#科技工业巨头 #Ericsson #AI #Nokia #Marvell
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号