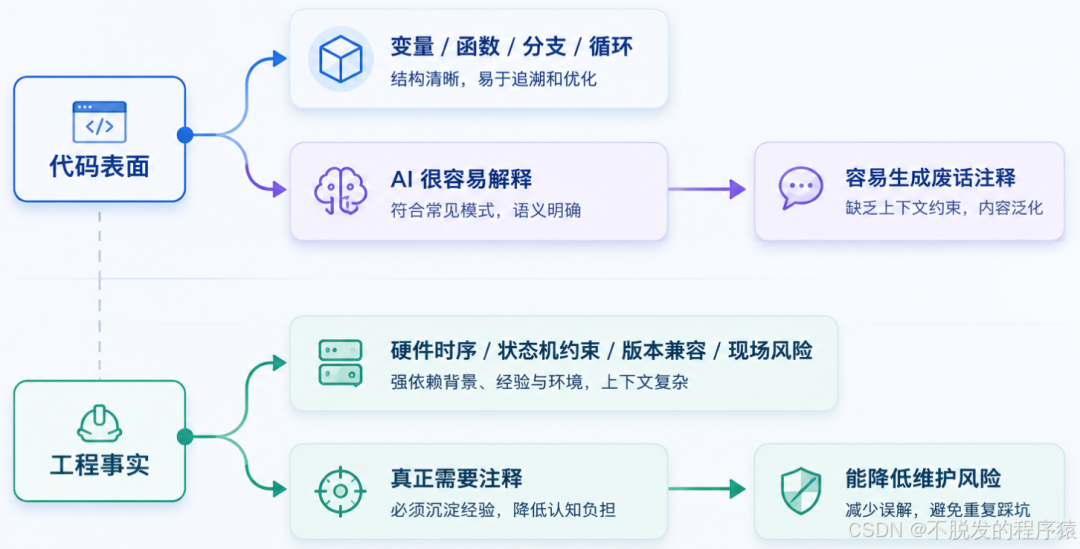
别让AI把你的代码注释成废话



有些注释看起来很多,实际一点用都没有。
比如这种:
cnt++; // 计数加一还有这种:
if (voltage < threshold) { // 如果电压小于阈值
power_off();
}它没有告诉你为什么要加一,也没有告诉你阈值从哪里来,更没有告诉你断电前有没有保存状态、有没有通知上位机、有没有可能误触发。
这种注释不是文档,是噪声。
嵌入式项目里,真正值得注释的地方,往往不是语法表面,而是代码背后的现场约束。
为什么这个 GPIO 初始化顺序不能改?
为什么 RS485 方向脚翻转后要等 20 微秒?
为什么 ADC 采样要避开 PWM 翻转边沿?
为什么这个状态机不能直接从运行态跳回空闲态?
为什么这个错误码不能删除?
这些信息通常不在代码本身里。老工程师知道,新人不知道;当年调过板子的人知道,两年后接手的人不知道;AI 更不知道。
所以我一直觉得,给嵌入式代码自动加注释这件事,不能简单理解成“让 AI 扫一遍代码,把每个函数解释一下”。
那样很容易把项目注释成一堆正确但无用的废话。
真正有价值的做法,是设计一个团队可复用的 Skill,让 AI 按统一规则给用户自己写的代码补关键注释,同时避开开源库、芯片库和自动生成文件。注释要少而准,能解释设计意图、状态机、边界条件和硬件约束。
1
嵌入式代码最缺的不是注释数量
很多项目并不是没有注释,而是注释没有打在关键点上。
我见过不少代码,函数头写得很长,真正危险的逻辑却没有一句说明。
/**
* @brief 处理电机状态
*/
void Motor_Process(void)
{
switch (motor_state) {
case MOTOR_STATE_RUN:
if (fault_flags & MOTOR_FAULT_OVERCURRENT) {
motor_state = MOTOR_STATE_STOPPING;
}
break;
}
}这个 @brief 没错,但也没什么价值。
真正需要说明的是:
- 过流后为什么不是直接进入停止态?
- STOPPING 状态里是否要保留减速过程?
- 这个状态切换是否和功率驱动保护时序有关?
- 中断里会不会同时改 fault_flags?
嵌入式注释的价值,不是把代码翻译成中文,而是把代码看不出来的工程事实补上。
如果团队要批量使用 AI 自动注释,第一条规则就应该写清楚:不要解释语法,要解释意图、边界和风险。
2
自动注释最容易翻车的三个地方
第一个翻车点,是注释范围失控。
AI 如果不加限制,很可能连 CMSIS、HAL、FreeRTOS、第三方协议栈、开源算法库都一起注释。结果仓库里多出一堆无意义改动,代码评审根本看不完。
第二个翻车点,是注释内容太虚。
比如“该函数用于处理数据”“该变量表示状态”“这里进行错误判断”。这些话看似没错,但读代码的人并不需要它。
第三个翻车点,是注释破坏工程节奏。
嵌入式项目经常对行宽、编码、编译宏、静态分析、MISRA、Doxygen 格式有要求。批量注释如果不统一,后面维护起来会很痛苦。
所以这个 Skill 不能只写一句“给代码加注释”。它至少要管住五件事。
要管住什么 | 具体要求 | 不管会怎样 |
|---|---|---|
注释范围 | 只处理用户自研代码,排除开源库和生成文件 | 引入大量无关变更 |
注释位置 | 只注释关键变量、函数接口、状态机、边界逻辑 | 注释膨胀,代码变吵 |
注释内容 | 解释意图、约束、风险、单位、并发关系 | 变成语法翻译 |
注释格式 | 函数头、变量、局部逻辑统一模板 | 团队风格混乱 |
验证方式 | 编译、静态检查、差异评审 | 注释影响代码或掩盖风险 |
如果这五件事没定义清楚,AI 自动注释很容易从效率工具变成仓库污染源。
3
先分清哪些文件不能碰
嵌入式项目里有很多文件不应该被 AI 批量注释。
比如:
- 芯片厂商库。
- RTOS 内核。
- USB、TCP/IP、文件系统等开源组件。
- 自动生成的初始化代码。
- 第三方算法库。
- 已经受版本控制的协议头文件。
- 只读导入的客户 SDK。
这些文件不是不能读,而是不要随便改。
Skill 里必须先定义排除规则。
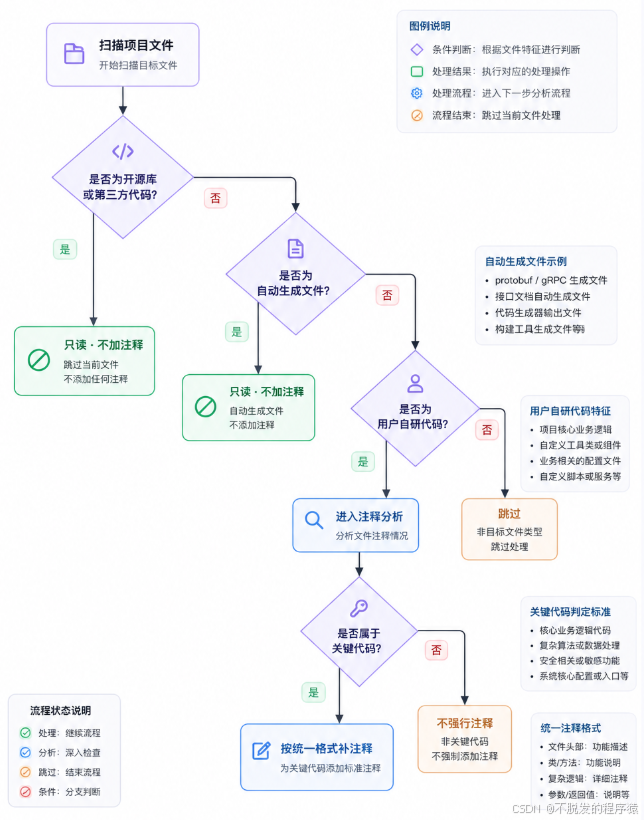
建议在 Skill 里直接写排除目录和文件特征。
类型 | 常见路径或特征 | 处理方式 |
|---|---|---|
芯片厂商库 | Drivers/CMSIS/、Drivers/STM32*_HAL_Driver/、SDK/ | 不修改 |
RTOS 内核 | FreeRTOS/、rt-thread/、ThreadX/ | 不修改 |
开源组件 | lwip/、fatfs/、mbedtls/、tinyusb/ | 不修改 |
自动生成文件 | 文件中包含 Generated by、DO NOT EDIT、.ioc 生成痕迹 | 不修改 |
第三方协议库 | third_party/、external/、components/vendor/ | 不修改 |
用户自研代码 | App/、BSP/、User/、Src/ 中非生成部分 | 可分析 |
这里要注意:BSP/ 不一定都能改。有些板级文件是用户写的,可以注释;有些是工具生成的,只能跳过。Skill 不能死板,要先识别文件来源。
4
不是每一行都值得注释
自动注释最难的地方,是克制。
嵌入式代码里,应该优先注释这些地方:
注释对象 | 注释重点 | 示例 |
|---|---|---|
全局变量 | 单位、更新者、并发访问、生命周期 | g_adc_mv 的单位是毫伏,由 ADC 任务更新 |
状态变量 | 状态含义、合法迁移、异常回退 | 电机状态机不能从运行态直接回空闲态 |
函数参数 | 输入范围、单位、是否允许为空 | timeout_ms 为毫秒,0 表示不等待 |
返回值 | 错误码含义、调用方处理方式 | 返回负数表示硬件错误,需要重新初始化 |
中断逻辑 | ISR 内只做什么、不做什么 | 只置位和计数,不解析协议 |
DMA 缓冲区 | 读写者、边界、覆盖策略 | DMA 写入,任务读取,满时丢弃新帧 |
状态机分支 | 分支触发条件和硬件原因 | 等待驱动电源稳定后再进入运行态 |
协议兼容 | 旧版本保留原因 | 兼容现场旧上位机,不可删除 |
安全保护 | 阈值来源、动作顺序 | 先关 PWM,再断使能,避免桥臂误导通 |
不建议注释这些地方:
- 单纯的赋值。
- 一眼能看懂的条件判断。
- 标准库调用。
- 普通循环计数。
- 与业务无关的临时变量。
- 已经很清楚的枚举名称。
注释应该增加信息密度,而不是增加文字密度。
5
团队要先统一注释格式
自动注释要能批量用,格式必须统一。
我比较推荐嵌入式 C 项目使用接近 Doxygen 的函数头,同时保持局部注释克制。
函数注释模板可以这样定:
/**
* @brief 处理 RS485 接收事件并推进协议解析状态机。
*
* @param port 通信端口索引,取值范围为 0 到 COMM_PORT_MAX - 1。
* @param event 接收事件,必须来自串口空闲中断或 DMA 完成回调投递。
*
* @return 0 表示处理成功;负数表示端口无效、缓冲区异常或协议状态机错误。
*
* @note 本函数运行在通信任务上下文,不能在中断中直接调用。
* @note 只消费环形缓冲区中的完整帧,不负责清空 DMA 原始缓冲区。
*/
int Comm_ProcessRxEvent(uint8_t port, const CommRxEvent_t *event);变量注释可以这样定:
/* DMA 写入位置,由串口空闲中断更新;通信任务只读取快照,避免直接改写。 */
static volatile uint16_t s_uart3_dma_write_pos;
/* 电机保护状态机当前状态,只允许 Motor_Task 在任务上下文推进。 */
static MotorProtectState_t s_protect_state;局部逻辑注释可以这样定:
/* RS485 方向脚释放后需要等待收发器进入接收态,V2.1 板卡实测最小稳定时间约 15us。 */
Delay_Us(20);
/* 零长度接收通常来自空闲中断重复进入,不能推进写指针,否则会破坏环形缓冲区边界。 */
if (rx_len == 0U) {
s_uart3_zero_len_cnt++;
return;
}状态机注释可以这样定:
switch (s_motor_state) {
case MOTOR_STATE_STOPPING:
/*
* 先等待 PWM 输出降为 0,再关闭驱动使能。
* 直接跳到 IDLE 会绕过制动释放流程,可能导致功率桥残余电流未泄放。
*/
Motor_UpdateStopRamp();
break;
}这样的注释有几个特点:
- 不重复代码表面含义。
- 说明上下文和约束。
- 能被后来的人验证。
- 不把一句话写成论文。
6
一个团队可用的自动注释 Skill 应该长这样
下面是一个完整的中文 Skill 示例,可以作为团队内部版本的雏形。
---
name: embedded-code-commenter
description: 当用户要求为嵌入式 C 或 C++ 项目自动补充代码注释、统一注释格式、批量生成函数说明、变量说明、状态机说明、参数返回值说明,并且需要排除开源库、芯片库、自动生成文件和第三方代码时,使用本技能。
---
# 嵌入式代码自动注释
## 目标
为用户自研的嵌入式代码补充少量、准确、统一、可维护的注释。注释重点是设计意图、硬件约束、状态机规则、并发关系、参数单位、返回值含义和边界条件。不要把代码逐行翻译成中文。
## 处理范围
优先处理:
- `App/`
- `User/`
- `BSP/` 中用户手写部分
- `Src/` 中非自动生成部分
- `Inc/` 中用户定义的接口头文件
- 项目中特别标记为业务代码、板级代码、驱动适配代码的文件
必须跳过:
- 芯片厂商库
- RTOS 内核
- 开源组件
- 第三方 SDK
- 自动生成文件
- 已经明确禁止修改的协议文件
- 用户没有授权修改的目录
## 排除规则
遇到以下路径或特征时,不修改文件:
- `CMSIS`
- `HAL_Driver`
- `FreeRTOS`
- `rt-thread`
- `lwip`
- `fatfs`
- `mbedtls`
- `tinyusb`
- `third_party`
- `external`
- `vendor`
- 文件中包含 `DO NOT EDIT`
- 文件中包含 `Generated by`
如果文件来源不确定,先只读分析,不直接修改。
## 注释原则
1. 只给关键代码加注释。
2. 不解释一眼能看懂的语句。
3. 不写空泛评价,例如“提高稳定性”“保证安全运行”,除非说明具体机制。
4. 不改变代码逻辑。
5. 不改变量名、函数名、宏名和文件结构。
6. 不引入新的头文件。
7. 不扩大编译产物。
8. 保持原有编码、缩进和行宽风格。
9. 注释必须能被代码或工程事实支撑。
10. 如果无法判断设计意图,写成待确认注释或不写。
## 必须优先注释的对象
- 对外接口函数。
- 带有硬件时序要求的函数。
- 中断服务函数和回调函数。
- DMA、环形缓冲区、双缓冲相关逻辑。
- 状态机状态和关键迁移条件。
- 安全保护、降额、故障恢复逻辑。
- 协议兼容分支。
- 全局变量、静态变量、跨中断和任务共享的变量。
- 带单位的参数和返回值。
- 魔法数、阈值、延时值、重试次数。
## 函数注释格式
使用以下格式:
```c
/**
* @brief 用一句话说明函数职责,避免重复函数名。
*
* @param 参数名 说明参数含义、单位、范围、是否允许为空。
* @return 说明返回值含义,特别是错误码和调用方应如何处理。
*
* @note 说明调用上下文、硬件约束、并发限制或版本兼容。
*/
```
没有参数时不写 `@param`。没有返回值时不写 `@return`。没有特殊约束时不强行写 `@note`。
## 变量注释格式
全局变量、静态变量和跨上下文共享变量使用行前注释:
```c
/* 说明变量含义、单位、更新者、读取者和并发约束。 */
static volatile uint16_t s_xxx;
```
局部变量只在含义不明显、单位容易误解或涉及边界条件时注释。
## 逻辑注释格式
关键分支、状态迁移、硬件延时和异常处理使用块注释:
```c
/*
* 说明为什么需要这段逻辑,以及删掉或改错后会导致什么风险。
*/
```
## 状态机注释要求
为状态机补注释时,优先说明:
- 当前状态的意义。
- 允许从哪些状态进入。
- 允许迁移到哪些状态。
- 禁止直接跳转的原因。
- 与硬件动作或安全保护的关系。
## 中断和并发注释要求
遇到中断、DMA、任务共享变量时,必须说明:
- 哪个上下文写。
- 哪个上下文读。
- 是否需要 `volatile`。
- 是否依赖临界区、关中断、互斥锁或原子操作。
- 中断里禁止执行的动作。
## 输出流程
1. 先列出准备处理的文件。
2. 再列出跳过的文件和跳过原因。
3. 对每个文件先识别关键函数、关键变量和关键状态机。
4. 只补必要注释。
5. 修改后汇总新增注释类型。
6. 提醒用户运行编译、静态检查和代码评审。
## 质量检查
完成后检查:
- 是否误改开源库或生成文件。
- 是否出现“该函数用于”“这里判断”“变量赋值”等低价值注释。
- 是否重复解释代码表面含义。
- 是否漏掉参数单位、返回值错误码、调用上下文。
- 是否把不确定的设计意图写成确定事实。
- 是否破坏原有格式。这个 Skill 的关键,不是写得长,而是把自由度控制住。
它告诉 AI:哪些能动,哪些不能动;哪些必须注释,哪些不要注释;注释应该写什么,不能写什么;最后还要检查什么。
这才像一个团队能批量使用的工具。
7
批量使用时,先小范围试跑
我不建议第一次就让 AI 扫完整个仓库。
正确做法是先选一个模块试跑,比如 App/Protocol/ 或 App/Motor/。
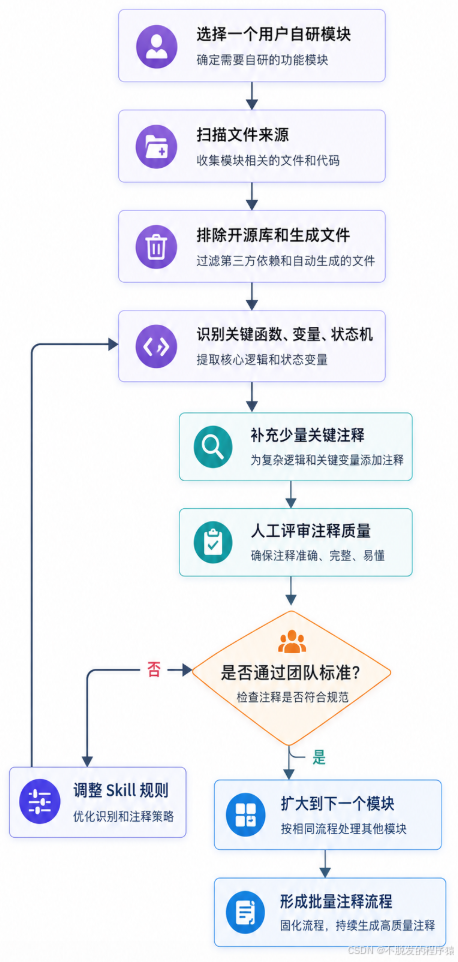
建议第一轮只处理 5 到 10 个文件。
评审时重点看:
- 有没有注释废话。
- 有没有把不确定的现场原因写死。
- 有没有漏掉关键参数单位。
- 有没有误改第三方代码。
- 有没有让代码更难读。
通过之后,再扩大到整个用户自研目录。
好注释不是给编译器看的,也不是给领导看的。
它是给半年后的自己、刚接手项目的同事、半夜处理现场问题的人看的。
嵌入式代码里,很多真正重要的信息都藏在代码外面:板卡版本、现场波形、硬件余量、客户兼容、故障复现条件、当年踩过的坑。
AI 可以帮我们把这些信息补到代码边上,但前提是我们要给它规则。
这才是 AI Coding 在嵌入式团队里该做的事。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号