一文读懂稀疏注意力,DeepSeek、Kimi、MiniMax为什么集体动了Transformer的根

一文读懂稀疏注意力,DeepSeek、Kimi、MiniMax为什么集体动了Transformer的根

乐小野
发布于 2026-06-08 12:38:35
发布于 2026-06-08 12:38:35
📌 一句话讲明白 Transformer的注意力是O(n²)复杂度,上下文每翻一倍,计算量翻四倍。这是长上下文又慢又贵的总根源。2026年,DeepSeek、Kimi、MiniMax几乎同时做了一份答卷,NSA、MoBA、MSA,三家路线不同但思路一致,别让每个token都去看全部token。 今天我们先讲清楚O(n²)到底贵在哪,再讲稀疏注意力这一派三家的不同打法,最后把它跟容易混淆的另外两条路线(线性注意力、KV压缩)摆在一起掰扯掰扯。
注意力的O(n²)问题,已经卡了Transformer八年。
2017年「Attention is All You Need」那篇论文奠定了现代大模型的地基,但也埋下了一个从第一天起就存在的硬伤,自注意力的计算复杂度是序列长度的平方。当年训练数据的上下文也就几百个token,这个平方没人当回事。到了2026年,大家张口就要1M上下文、要让agent连续跑几小时长任务,这个平方就成了所有人头上的紧箍咒。
今年上半年最密集的一波架构创新,全都在这个点上。DeepSeek出了NSA,Kimi出了MoBA,MiniMax在M3上换了MSA。三家头部一起对注意力机制动刀,这在过去几年是没有过的。名字不一样,但要解决的是同一个问题——怎么不让注意力的成本随着上下文平方级爆炸。
🧭 注意力为什么是平方
标准的自注意力干的事情,是让序列里每一个token都去「看」一遍序列里所有的token,算出一个相关性权重,再加权求和。
写成公式就是这个,
关键在中间那个 。Q和K都是 的矩阵(是序列长度,是维度),它俩相乘得到一个 的注意力矩阵。这个矩阵的每一个元素,代表第i个token和第j个token的相关性。
问题就出在这个 上。序列长度n翻一倍,这个矩阵的面积就变成四倍。算1M token的注意力,这个矩阵理论上有一万亿个元素。
这个平方带来两笔账。一笔是计算量,矩阵越大,乘法和softmax的运算越多,解码越慢。另一笔是显存,推理时为了不重复计算,要把历史token的K和V缓存起来(就是KV Cache),上下文越长,这个缓存吃的显存越多。
💡 工程要点 这两笔账其实是两个不同的优化方向,后面会反复用到。一个是省「算力」(注意力矩阵的计算),一个是省「显存」(KV Cache的存储)。稀疏注意力和线性注意力主要省算力,MLA那类主要省显存。搞混这两个,就理解不了为什么有些技术能叠加使用。
那能不能不让每个token看全部token?这就是稀疏注意力的出发点。直觉上很合理,一个token真正需要关注的,往往就是附近的几个词加上前文某几个关键位置,没必要把一百万个token全看一遍。难点在于,怎么聪明地选出该看的那一小部分,而且选的过程本身不能太贵。
🔬 DeepSeek NSA,三条分支各管一段
DeepSeek的NSA(Native Sparse Attention,原生稀疏注意力)是这一派里设计最完整的一个。梁文锋本人参与了这篇论文。
NSA的核心思路是用三条并行的分支,各自负责捕捉不同尺度的信息,最后用一个门控机制把三条的输出融合起来。
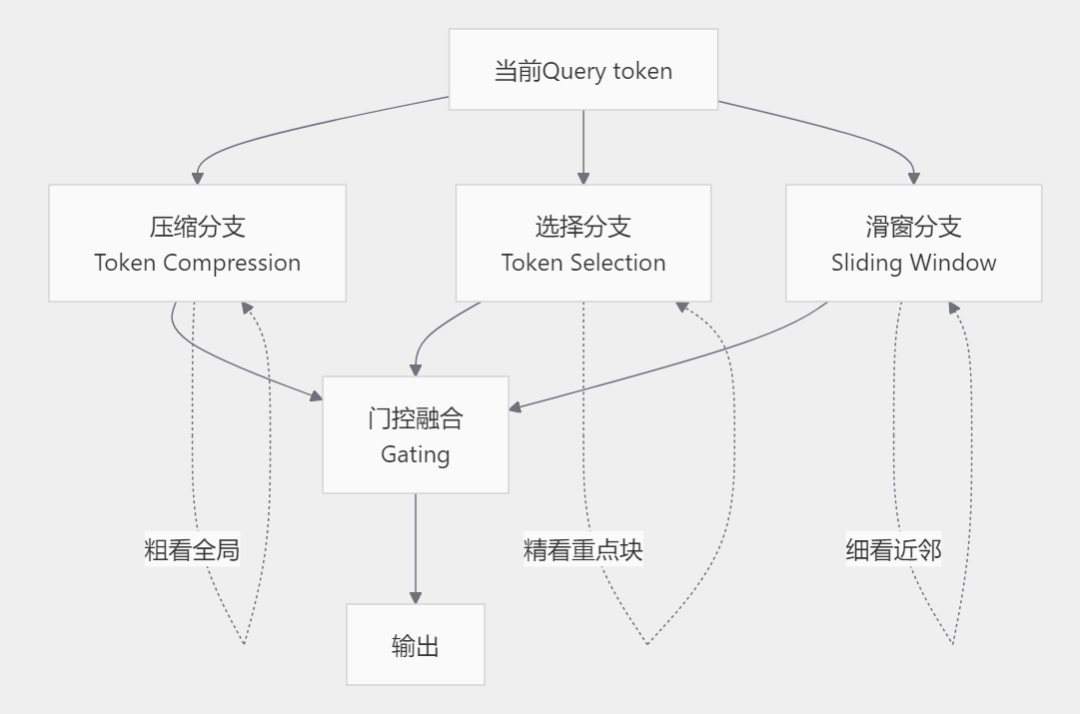
- 压缩分支负责粗看全局。它把远处的token按块压缩成一个个摘要,用少量的压缩token代表大段历史,这样就能用很低的成本扫一遍全局大意。
- 选择分支负责精看重点。它在全部历史块里挑出最相关的若干个块,对这些块做细粒度的注意力。这一步是稀疏的精髓,绝大部分块被跳过了,只有被选中的少数块参与精算。
- 滑窗分支负责细看近邻。语言里相邻的词关系最紧密,这条分支固定关注当前位置往前的一个窗口,保证局部信息不丢。
三条分支的输出由一个门控网络加权合并。这套设计的复杂度从O(n²)降到了接近线性,论文报告的端到端加速达到约9倍。
🎯 takeaway NSA名字里的「原生(Native)」是它最关键的一个词。过去很多稀疏注意力只在推理阶段用稀疏,训练时还是用全注意力,这就导致训练和推理对不齐,效果打折。NSA从训练阶段就用稀疏,训练和推理用的是同一套机制,这是它效果能保持住的根本原因。它还专门做了硬件对齐设计,让稀疏的计算模式能在GPU上真正跑出速度,而不是理论上稀疏、实际上更慢。
🐦 Kimi MoBA,把MoE的思路搬到了注意力上
Kimi(月之暗面)的MoBA(Mixture of Block Attention,混合块注意力)走的是另一条更优雅的路。它的灵感直接来自MoE(专家混合)。
MoE是怎么干活的,把一个大的前馈网络拆成很多个专家,每次只激活其中最相关的几个。MoBA把这个思路平移到了注意力上,把上下文切成很多个块,每个query token通过一个门控路由,只选择跟它最相关的top-k个块去做注意力。
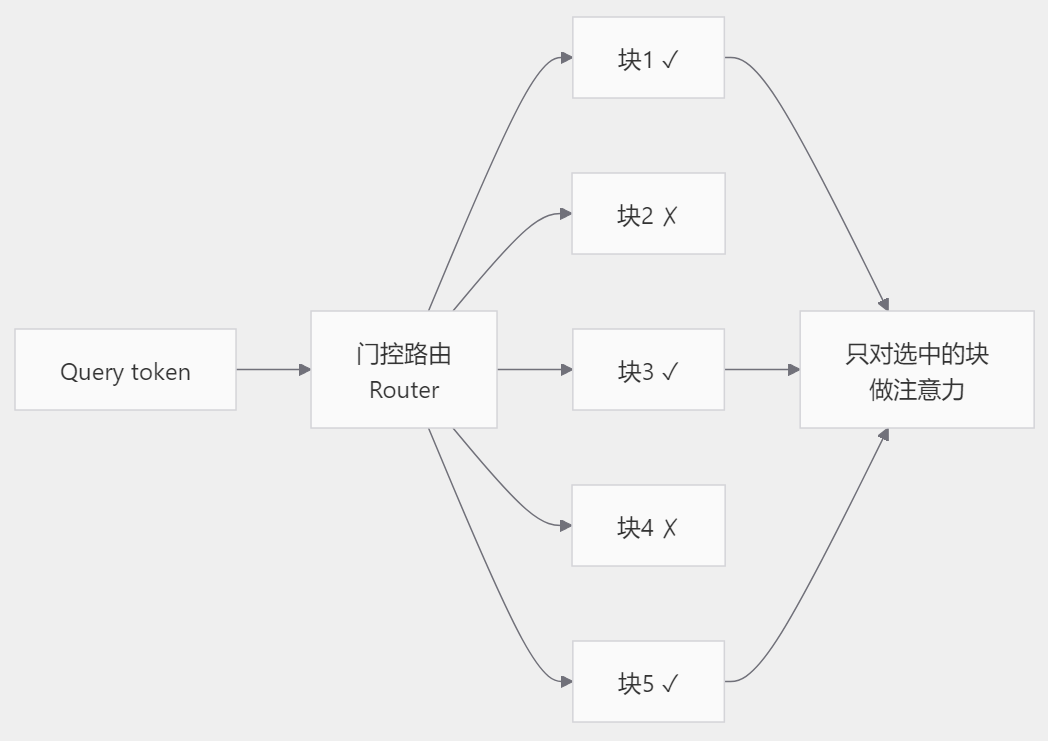
跟NSA比,MoBA的设计更简洁,它没有三条分支,就是一个门控加块选择。而且它的门控是无参数的,靠的是query和每个块的代表向量算相关性,不额外引入需要训练的参数。
MoBA有个很实用的特性,它能在全注意力和稀疏注意力之间无缝切换。同一个模型,需要精度的时候可以切回全注意力,需要速度的时候切稀疏,两种模式共享同一套权重。官方数据,1M上下文下比全注意力快6.5倍,10M上下文下快16倍,而性能基本持平。
📅 同期对照 NSA和MoBA几乎是前后脚发的,业内当时直接把它俩放一起读。两者都属于「动态稀疏」,都是在运行时根据内容选该关注谁,区别在选择的粒度和实现。NSA三分支更复杂但捕捉的尺度更全,MoBA单门控更简洁也更灵活。有意思的是,两篇论文的作者圈子有重叠,国内这波注意力创新的人才是高度集中的。
⚡ 线性注意力,它跟稀疏不是一回事
到这里必须岔开说一下线性注意力,因为很多人会把它和稀疏注意力搞混,而MiniMax的故事恰好横跨了这两条路。
稀疏注意力的做法是,保留softmax,但只算一部分token。线性注意力更激进,它直接改掉了计算方式,去掉softmax,利用矩阵乘法的结合律,把 的计算顺序换成 ,这样就绕开了那个 的矩阵,复杂度真正降到O(n)线性。
MiniMax早期的M1和01用的就是线性注意力,叫Lightning Attention(闪电注意力),是一种I/O感知的线性注意力变体。它的算力效率极高,官方算过百万级长文本只要全注意力1/2700的算力。
但线性注意力有个老毛病,检索和回忆能力弱。因为它把历史信息压缩进了一个固定大小的状态里,当你需要精确从前文捞出某个具体细节时,它容易记不准。MiniMax的解法是混合架构,每7个线性注意力块配1个标准softmax注意力块,用少量的全注意力来补回检索能力。
这里有个细节。MiniMax在M3上,从线性注意力(M1)换成了稀疏注意力(MSA)。一家公司在两代旗舰之间切换了注意力路线,它半年前还公开说稀疏注意力不够成熟,半年后自己换了过去。
⚠️ 限制 MiniMax这次换路线,官方没有详细解释MSA(MiniMax Sparse Attention)的具体实现,也没给出跟Lightning Attention正面对比的数据。从结果反推,线性注意力那个检索弱的硬伤,可能在复杂agent和编程任务上暴露得比较明显,而这两个恰恰是M3主打的场景。稀疏注意力保留了softmax,检索精度天然比线性注意力强。但这只是合理推测,确切原因要等技术报告。
🏭 还有一条容易混的路,KV压缩
把视角再拉宽一点。前面说过,注意力的成本有两笔账,算力和显存。稀疏和线性主要砍算力,但显存这笔账,是另一拨技术在管,代表就是DeepSeek的MLA。
MLA(Multi-head Latent Attention,多头潜在注意力)解决的是KV Cache太占显存的问题。它的办法是低秩压缩,把原本要完整存储的K和V,联合压缩成一个低维的潜在向量(latent vector),用的时候再还原。
这跟之前的MQA、GQA思路不同。MQA和GQA是粗暴地减少KV头的数量,几个query头共享一组KV,省了显存但损失表达能力。MLA不减头,它是把信息压进低维空间,既省显存又尽量保住多头的表达能力。官方数据,MLA能把KV Cache的显存占用降低到原来的极小一部分,有分析给到约93%的节省。
💡 工程要点 关键是要理解MLA和稀疏注意力不是竞争关系,是可以叠加的。DeepSeek自己就是MLA管显存、NSA管算力,两个一起上。这也是为什么前面强调要分清「省算力」和「省显存」这两笔账,它们在不同的维度上,互不冲突。一个模型完全可以一边用稀疏注意力少算token,一边用MLA把KV Cache压小,两头都省。
⚖️ 三派一张表
把这几条路线放一张表里对比,关系更清楚。
技术 | 代表 | 解决什么 | 核心手段 | 复杂度 |
|---|---|---|---|---|
稀疏注意力 | NSA(DeepSeek) | 省算力 | 三分支(压缩/选择/滑窗)+门控 | 近线性 |
稀疏注意力 | MoBA(Kimi) | 省算力 | 块选择+无参数门控 | 近线性 |
稀疏注意力 | MSA(MiniMax M3) | 省算力 | 稀疏注意力(细节未公开) | 近线性 |
线性注意力 | Lightning(MiniMax M1) | 省算力 | 去softmax+改计算顺序 | O(n) |
KV压缩 | MLA(DeepSeek) | 省显存 | KV低秩压缩成潜向量 | 不改算力 |
KV压缩 | MQA/GQA | 省显存 | 减少KV头数量 | 不改算力 |
读这张表有三个层次。
- 第一层,稀疏和线性都在砍算力,但稀疏保留softmax(精度好)、线性改计算方式(更快但检索弱)。
- 第二层,KV压缩是另一个维度,砍的是显存,可以跟前两者叠加。
- 第三层,2026年头部公司的选择,正在向「稀疏注意力」这一格集中,NSA、MoBA、MSA三家都落在这里,连原本押注线性注意力的MiniMax都转了过来。
🔗 假设链 如果稀疏注意力确实成了头部共识,那么接下来会发生几件事。一是开源生态会快速跟进,把这几套机制做成标准算子,让中小团队也能用上。二是1M甚至10M上下文会从「旗舰卖点」变成「基础配置」,因为成本压下来了。三是依赖长上下文的应用(整库代码理解、超长文档分析、长程agent)会迎来一波体验跃升。这条链的起点,就是注意力终于不那么贵了。
❓ 几个还没看清楚的点
MSA的实现细节没公开。MiniMax只说了M3用MiniMax Sparse Attention,但它具体是接近NSA的多分支、还是接近MoBA的块选择、还是另有设计,官方没披露,得等技术报告。
各家的加速数字口径不一。9倍、6.5倍、16倍这些数字,测试的上下文长度、硬件、对比基准都不一样,不能直接横向比。看趋势可以,当精确排名不行。
稀疏会不会丢信息这个根本问题,没有定论。稀疏的本质是只看一部分token,理论上总有漏掉关键信息的风险。各家都说性能基本持平,但「基本」这个词里藏着多少特定任务上的损失呢?
❓ 留白 最大的开放问题是,稀疏注意力是不是终局?线性注意力火过一阵又被稀疏盖过,谁能保证稀疏不会被下一个东西取代。注意力机制这个地基层,过去八年改了无数次都没动摇O(n²)的根,这一波到底是真突破还是又一次局部最优?
References
- 1. DeepSeek-AI, 「Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention」, 2025, https://arxiv.org/abs/2502.11089
- 2. Moonshot AI, 「MoBA: Mixture of Block Attention for Long-Context LLMs」, https://platform.moonshot.cn/blog/posts/moba
- 3. 腾讯云开发者, 「NSA稀疏注意力深度解析:DeepSeek如何将Transformer复杂度从O(n²)降下来」, https://cloud.tencent.com/developer/article/2557089
- 4. 开源中国, 「原生稀疏注意力(NSA),创始人亲自提交论文」, https://www.oschina.net/news/334671/deepseek-nsa
- 5. 博客园 Big-Yellow-J, 「Kimi/DeepSeek最新论文MoBA与NSA阅读」, https://www.cnblogs.com/Big-Yellow/p/18746230
- 6. 知乎, 「MoBA详细解析,长上下文LLMs的块注意力混合」, https://zhuanlan.zhihu.com/p/25113509749
- 7. 火山引擎开发者社区, 「MiniMax-M1技术报告关键技术点解读」, https://developer.volcengine.com/articles/7517866310463275019
- 8. 知乎, 「MiniMax-01:线性注意力实现超长上下文窗口」, https://zhuanlan.zhihu.com/p/18586235194
- 9. 智源社区, 「Deepseek-V2多头潜在注意力(Multi-head Latent Attention)原理及实现」, https://hub.baai.ac.cn/view/42912
- 10. MiniMax, 「MiniMax M3: Frontier Coding, 1M Context, Native Multimodality」, 2026年6月1日, https://www.minimax.io/blog/minimax-m3
- 11. Vaswani et al., 「Attention is All You Need」, 2017, https://arxiv.org/abs/1706.03762
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号