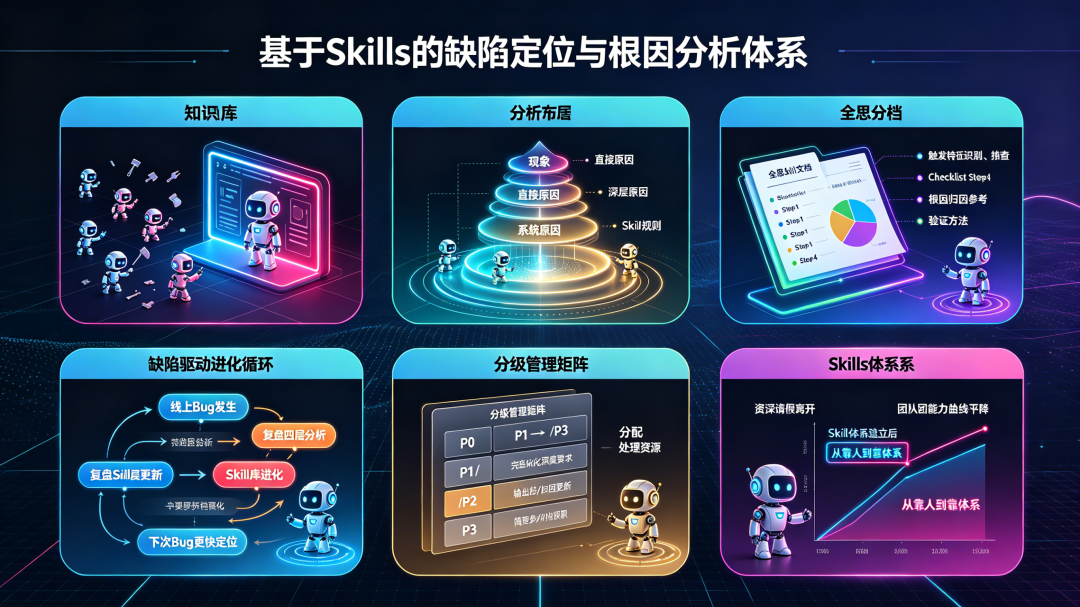
基于 Skills 的缺陷定位与根因分析体系

基于 Skills 的缺陷定位与根因分析体系

AI智享空间
发布于 2026-06-08 13:18:26
发布于 2026-06-08 13:18:26
有一类线上故障,是每个测试工程师和开发工程师的噩梦。
不是那种一眼能看出来的 NPE(空指针异常),不是那种日志里清清楚楚写着“数据库连接失败”的错误。而是那种:系统运行正常,日志没有报错,监控指标平稳,但用户就是在反馈“结果不对”。
你开始排查。看代码逻辑,没问题。看数据库数据,没问题。看上游接口,没问题。三天过去了,问题依然没有定位。最后,一个老员工突然说:“等等,上个月我们改过一个精度处理的逻辑,你看一下那里。” 果然,就是那里。
这个故事的问题不在于老员工的经验——而在于那段经验,只在他一个人的脑子里。
这篇文章想讨论的,就是如何用 Skills 把这类“只有老人才知道”的定位经验,变成团队可以系统性调用的能力。
一、缺陷定位的现状高度依赖个人的赌博
1.1 现有定位方式的结构性缺陷
大多数团队的缺陷定位流程,本质上是这样的:
- 收到告警或用户反馈
- 指派“最熟悉这块”的工程师去查
- 工程师凭经验、凭直觉、凭记忆开始排查
- 运气好的话几小时定位,运气不好的话几天没有进展
- 写一份复盘报告,归档,然后大概率不会再被提起
这套流程最大的问题是:它把定位能力完全押注在了人身上,而不是体系上。
同一类问题,有人查需要三天,有人查只需要三小时,差异来自个人经验,而非系统能力。更糟糕的是,这个经验差距在人员流动时会被彻底清零。
1.2 根因分析的常见误区
很多团队有“根因分析”的意识,但在实践中容易陷入两个极端:
流于表面:根因分析停留在“代码写错了”、“测试没覆盖”这个层面,没有追问“为什么这类代码容易写错”、“为什么这个场景的测试覆盖逻辑是这样设计的”。这样的分析,下次遇到类似问题依然束手无策。
过度抽象:另一种极端是把根因归结为“流程不规范”、“团队协作有问题”。这类结论无法落地,因为它没有告诉任何人下次遇到类似问题时,第一步应该检查什么。
真正有效的根因分析,需要既有足够的深度(追到可操作的层面),又有足够的结构化(让下一个人能复用这套分析路径)。这正是 Skills 能发挥作用的地方。
二、Skills 在缺陷定位中扮演什么角色
2.1 不是万能的,但能填补关键空白
在聊具体做法之前,需要先明确一个认知边界:Skills 不能替代工程师做定位判断,它做的是另一件事——把历史上成功定位问题的经验,结构化为可复用的排查路径。
这个区别很重要。Skills 不是一个“智能侦探”,它更像一个“经验丰富的向导”——它知道在这片地形里,哪条路走过、哪个坑踩过、哪个方向大概率有结果。具体走不走得通,还是要人来判断。
2.2 Skills 能做的三件事
第1件:模式识别。当一个新问题进来,Skills 可以基于问题的特征(报错类型、影响范围、触发条件、模块归属)快速匹配历史上最相似的缺陷模式,给出“这个问题大概率属于哪一类”的初步判断。
第2件:排查路径生成。对于已知的缺陷类型,Skills 可以输出结构化的排查 Checklist——先看什么、再看什么、每一步的预期结论是什么。这把“老员工的直觉”变成了可以交给任何人执行的步骤。
第3件:根因归因框架。当问题被定位后,Skills 可以辅助完成根因分析——基于问题类型,给出这类缺陷通常的根因分布,帮助工程师更快找到真正的“为什么”,而不是停留在现象层面。
三、构建排查 Skill 的核心方法
3.1 从历史缺陷中提炼模式
构建缺陷定位 Skill 的原材料,是真实发生过的 Bug。具体做法是:
拉出过去一年的线上缺陷记录,按以下维度进行分类整理:
- 触发特征:什么样的用户行为、数据状态、系统负载触发了这个问题
- 表现形式:用户看到什么、系统报什么错、监控指标有什么变化
- 定位路径:实际排查时走了哪些步骤,哪些步骤是有效的,哪些是弯路
- 根因类型:最终定位到的根因属于哪一类(逻辑错误、并发问题、数据异常、配置错误等)
- 修复验证:修复后如何验证问题确实解决
把这五个维度填完,你会发现大多数缺陷并不是完全独立的——它们在某几个维度上高度相似,可以被归并为有限的几类模式。
这些模式,就是 Skill 的骨架。
3.2 一个具体的 Skill 结构示例
以“数据展示结果不一致”这类问题为例,一个结构化的定位 Skill 大致是这样的:
【缺陷类型】数据展示结果不一致(用户侧看到的数据与预期不符,但无报错)
【触发特征识别】
- 问题是否可稳定复现?
- 是否所有用户受影响,还是特定账号/场景?
- 是否与最近的发版时间点相关?
【排查路径 Checklist】
Step 1:确认数据源
→ 直接查数据库,确认原始数据是否正确
→ 预期结论:若数据库正确,问题在读取/处理层;若数据库错误,问题在写入层
Step 2:检查数据处理逻辑
→ 查最近 30 天内涉及该模块的代码变更
→ 重点关注:精度处理、单位换算、时区转换、数据格式化
→ 预期结论:高频根因之一,历史上 40% 的此类问题在此层定位
Step 3:检查缓存一致性
→ 确认该数据是否有缓存层,缓存 TTL 是否合理
→ 构造绕过缓存的请求,对比结果是否与展示一致
→ 预期结论:若绕过缓存结果正确,问题为缓存未及时更新
Step 4:检查权限与数据隔离
→ 确认当前账号的数据访问范围是否配置正确
→ 对比同类账号的访问结果
【根因归因参考】
- 精度/格式处理错误:40%
- 缓存未更新:25%
- 数据写入逻辑错误:20%
- 权限配置问题:10%
- 其他:5%
【验证方法】
修复后,按触发特征中的场景逐一验证,重点覆盖历史复现路径这个结构的价值在于:任何人拿到这份 Skill,都知道从哪里开始、每一步看什么、期望看到什么结论。它把“老员工的直觉”变成了“团队的标准动作”。
四、根因分析的 Skill 化:从“查到了”到“真的懂了”
4.1 根因分析的四层模型
缺陷被定位之后,很多团队的复盘就结束了。但真正有价值的根因分析,需要追问到第四层:
第1层(现象):用户看到了什么错误?
第2层(直接原因):哪段代码、哪个配置、哪条数据导致了这个现象?
第3层(深层原因):为什么这段代码会写成这样?是设计上的缺陷、边界条件的疏漏,还是对某个依赖的理解偏差?
第4层(系统原因):什么样的流程、机制、认知缺失,导致这类问题没有在测试阶段被拦截?
大多数复盘停在第二层。有些团队能到第三层。真正能系统性减少同类问题的,是第四层的分析。
4.2 案例:一次支付金额精度问题的四层复盘
背景:某电商平台发生线上故障,部分订单的实付金额显示错误(小数点后两位的精度丢失),影响约 0.3% 的交易。
第1层:用户在订单详情页看到的金额与实际扣款不符,差值在 0.01 元量级。
第2层:定位到一处金额计算逻辑,使用了浮点数运算(double),在特定金额组合下产生精度误差,未做四舍五入处理直接写入数据库。
第3层:开发工程师在实现这段逻辑时,参考了另一个模块的代码,但那个模块处理的是展示金额(不精确要求高),而非交易金额(精度要求严格)。代码复用时没有识别场景差异。
第4层:团队没有针对“金融金额处理”建立明确的编码规范,测试用例设计时也没有系统覆盖“金额精度”这个维度的测试场景——因为这个知识点只在老员工的经验里存在,没有被显式化为测试 Skill。
Skill 的产出:这次复盘的结论,直接转化为两个 Skill:
- 金融金额类接口测试 Skill(必覆盖精度场景)
- 金额处理代码 Review Skill(浮点数使用的 Checklist)
下一次有人接手类似模块,这两个 Skill 会自动触发相应的测试覆盖和代码审查动作——不需要靠记忆,不需要靠碰到同类问题。
五、体系落地:三个关键机制
5.1 缺陷驱动的 Skill 更新机制
Skills 体系不是一次性建成的,它需要随每一次真实的缺陷不断生长。
建议在团队中建立一个简单的规则:每一次线上 Bug 的复盘,必须明确输出对应的 Skill 更新。更新的内容可以是:
- 新增一个触发特征的识别模式
- 在某个排查步骤里补充一个检查项
- 更新根因归因的概率分布
- 新增一个验证方法
这个规则执行起来并不重,但它确保了 Skills 体系会随着团队经验的积累而持续进化,而不是在建成之日就开始腐化。
5.2 分级管理:不是所有 Bug 都需要同等深度的 Skill 化
不同级别的缺陷,Skill 化的深度应该不同:
缺陷级别 | 影响范围 | Skill 化要求 |
|---|---|---|
P0 / 核心功能崩溃 | 全量用户受影响 | 完整的四层根因分析 + 完整排查路径 Skill |
P1 / 核心功能异常 | 大量用户受影响 | 排查路径 Skill + 根因归因更新 |
P2 / 次要功能问题 | 少量用户受影响 | 触发特征更新 + 简要排查步骤 |
P3 / 体验问题 | 个别用户反馈 | 归档记录,积累足够多同类问题后再 Skill 化 |
这个分级机制的价值是:把有限的精力集中在真正值得深度分析的问题上,避免 Skill 化变成一项没有边界的负担。
5.3 让新人成为 Skills 的“压力测试者”
这是一个很多团队没有意识到的机制:新人是发现 Skill 缺陷的最好工具。
老员工使用 Skills 时,会不自觉地用自己的经验弥补 Skill 的不足,因此很难发现 Skill 哪里写得不够清楚、哪里有逻辑跳跃、哪里缺少上下文。
但新人会严格按照 Skill 的描述执行,一旦卡住,就意味着那个地方的 Skill 需要补充。
建议在新人入职的头一个月,指定一到两个模块,让他们完全依赖现有的 Skills 完成缺陷定位训练,并记录所有“Skills 没有说清楚”的地方——这些记录,直接转化为 Skill 的迭代输入。
结语:从“靠人”到“靠体系”的真正跨越
我认识的一位质量负责人,有一句话让我印象深刻:
“判断一个测试团队的成熟度,看一个指标就够了:当最有经验的那个人请假,团队处理线上问题的能力会下降多少?”
答案直接反映了团队的能力是否真正被体系化了,还是只寄托在几个关键人身上。
基于 Skills 的缺陷定位与根因分析体系,做的正是这件事:把“只有老人才知道”的定位经验,变成团队可以系统调用的能力;把“这次查到了”的偶然性,变成“每次都能快速定位”的确定性。
这不是一个短期项目,而是一个需要持续投入的方向。但每一次 Bug 复盘、每一次 Skill 更新,都是在让这个体系变得更强——直到有一天,你发现团队的定位能力不再随人员的变动而波动,而是在稳定地、持续地提升。那才是质量体系真正成熟的标志。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号