AlloGen :用差分状态打分实现构象选择性的蛋白结合物设计

AlloGen :用差分状态打分实现构象选择性的蛋白结合物设计

DrugIntel
发布于 2026-06-08 13:55:29
发布于 2026-06-08 13:55:29

文献信息:AlloGen: Conformation-Selective Binder Generation with Differential State Scoring(Cao et al., arXiv:2606.05474, 2026) 机构:香港中文大学(计算机科学与工程系)× 宾夕法尼亚大学(生物工程系 / 计算机与信息科学系),通讯作者 Pranam Chatterjee 资源:
huggingface.co/ChatterjeeLab/AlloGen
摘要
蛋白结合物设计长期以亲和力为单一优化目标,但对于激酶、核受体、GPCR 这类变构靶点,一个同时结合激活态(holo)和失活态(apo)的 binder 不具备任何功能特异性。AlloGen 的核心贡献是把构象选择性(conformational selectivity)重新定义为一种可学习、可迁移、可微分的界面属性,并将其蒸馏进一个轻量打分器 Qθ(约 898K 参数,SE(3) 不变的边偏置图 Transformer)。
Qθ 与生成器解耦、无需重训,既可作被动重排序器,也可作主动梯度引导接入任意骨架生成器。在覆盖 65 个靶点、15 个蛋白家族、2,896 个复合物的基准上,Qθ 在分布外(OOD)靶点上达到与 DockQ 的 Spearman ρ̄ = 0.520,而所有基于接触的能量代理在同一集合上集体失效。最终,作者用钙调蛋白(CaM)上的前瞻性湿实验钉死结论:高分设计产生多个 holo 选择性肽,低分负对照不结合,且无一结合 apo 态。
1. 背景与问题定义
1.1 蛋白质是构象开关
蛋白质在不同构象状态之间切换以调控信号、催化与变构,这是几乎所有蛋白家族的共性。对治疗性靶点而言,设计目标因此不应是"结合得多牢",而应是构象选择性:稳定一个功能态,同时主动排斥其他状态。这是变构药物设计、构象生物传感器与合成生物学开关的核心诉求。
1.2 现有生成式方法的共同盲区
近年的生成式方法在两个层面都取得突破:序列层面(掩码语言模型、对比语言模型、多目标离散扩散等),结构层面(RFdiffusion、PXDesign、Proteina-ComplexA、BoltzGen、BindCraft 等)。但它们共享同一个根本限制:只条件于单一受体构象,只为贴合该结构做优化。
由此带来的后果是:传统打分函数衡量的是绝对亲和力,而非跨状态的差分亲和力,因此完全不提供构象选择性信号。为某一态设计的 binder 可能同样牢固地结合另一态,使状态选择性的初衷落空。
1.3 问题的形式化
设目标蛋白存在两个构象态:apo(不期望) 与 holo(目标),均以骨架坐标表示。给定 binder 骨架 ,状态选择性打分问题是学习 ,使得对 选择性的候选满足:
注意这是一个条件性目标:非选择性 binder、apo 偏好 binder、非结合物都不要求满足该不等式——训练目标通过配对对比监督实现这一点,而非引入对 的全局偏置。给定冻结生成器 ,两态设计任务即在 个采样中选出选择性最高的候选:
2. 方法:AlloGen 框架
2.1 设计哲学——生成与打分解耦
AlloGen 的关键洞察是:构象选择性是受体–结合物界面的可迁移属性,一旦蒸馏进可微分打分器,即可事后(post hoc)用于两种角色——被动重排序或主动引导。流程为:冻结生成器先对 holo 态生成 个候选骨架;Qθ 对每个候选同时评估 holo 与 apo;按选择性间隔
排序,返回最优候选。Qθ 独立训练、与生成器无关,插入任意生成器都无需重训——这是框架最具工程价值的特性。
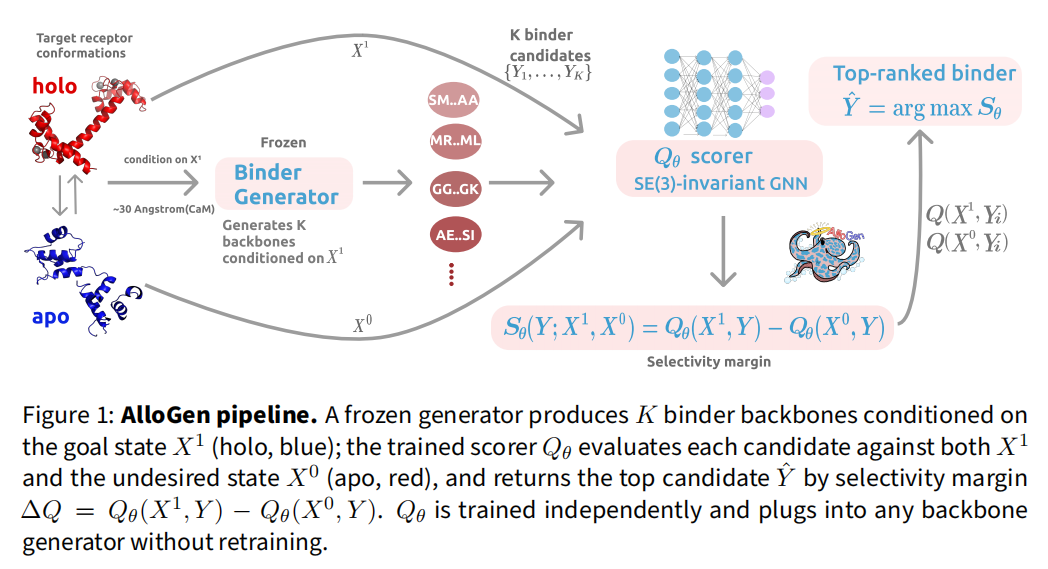
2.2 蛋白骨架表示与 SE(3) 不变性
每个残基 由 Cα 坐标 和局部骨架坐标系 表示,后者由 三联体经 Gram–Schmidt 正交化构造。为保证物理意义,Qθ 必须 SE(3) 不变,即 。作者在残基 的局部坐标系中表达所有残基间几何:
- • 距离
- • 单位方向
- • 相对取向
这些量在对 与 联合施加刚体变换时不变,因而节点/边特征及 Qθ 本身均为 SE(3) 不变。
2.3 界面图构建
每个复合物 表示为稀疏界面图: 包含来自 与 、至少有一条 8 Å 以内跨链 Cα 接触的残基;边连接该截断内的所有残基对。
节点特征:氨基酸 one-hot(20+未知);骨架二面角 (sin/cos 编码);侧链二面角 (无侧链自由度者零填充);链指示位;以及可选的逐残基 ESM-2 嵌入(投影后拼接,提供进化上下文)。
边特征(均在残基 局部坐标系中计算以保证不变性):距离(16 维高斯 RBF,中心 2–12 Å,)、单位方向、相对取向、序列分隔(分箱;跨链对置为最大箱)、同链指示位。
统计:界面图含 34.7 ± 19.7 个节点(范围 3–128,中位 29),其中受体侧 18.1 ± 9.8、binder 侧 16.6 ± 11.0。
2.4 Qθ:边偏置图 Transformer
Qθ 实现为 层、隐藏维 128、8 头的稠密边偏置图 Transformer。每层注意力将边嵌入投影为逐头标量偏置直接加到点积 logit 上:
边嵌入只计算一次、跨层共享。 层后将均值池化与最大池化拼接,经带 sigmoid 的 MLP 输出:
有界输出天然产生选择性间隔 。整个 InterfaceGNN 仅 ~898K 可训练参数(4 层 + 3 层打分 MLP),推理极快(见 §4.9)。
2.5 两阶段训练课程
直接优化选择性会导致退化解:模型忽略受体构象,只要看到特定受体就给高分。作者用两阶段课程规避:
Phase 1——界面质量回归。 先以 DockQ(融合原生接触比例、界面 RMSD、配体 RMSD 的 标量)为监督回归:
训练数据含原生 holo、apo 错配、刚体诱饵与硬负样本。此阶段先建立"什么是好界面"的几何地基,为 Phase 2 提供稳定初始化。
Phase 2——选择性微调。 在配对三元组 (同一 binder 的 与 )上用多负样本 InfoNCE 微调:
负样本跨靶点负样本
其中两类负样本各司其职:apo 负样本逼模型区分同一 binder 的两种构象;跨靶点负样本逼模型区分真正的 holo 搭档与结构无关的其他 holo 受体,从而防止坍缩到固定受体偏置。Phase 2 中丢弃 以避免梯度信号冲突(该选择由 Table 2 验证)。
骨架几何增强(binder dropout)。 推理时 Qθ 只看到无序列、无侧链的 binder 骨架,而训练复合物都有完整序列——存在分布偏移。作者以概率 屏蔽 binder 侧序列特征(氨基酸、、ESM 嵌入置零,保留全部骨架二面角与边特征),迫使 Qθ 依赖骨架几何而非序列身份,且对 施加一致的屏蔽。
关键超参(两阶段):Phase 1 — 40 epochs / lr 5e-4 / batch 512 / 100 warmup;Phase 2 — 15 epochs / lr 4e-5 / batch 256 / InfoNCE τ=0.1;两阶段 weight decay 1e-3、dropout 0.1、binder dropout 0.3、cosine 调度。
2.6 选择性间隔与四种引导策略
logit 空间选择性间隔(可自然推广到多状态 ):
由于 对 binder 骨架坐标可微,支持四种引导:
策略 | 机制 | 特点 |
|---|---|---|
Langevin 精修 | 在完全去噪骨架上做梯度上升 | 梯度始终可靠;但依赖生成器先验 |
Classifier guidance | 在每个去噪步注入梯度 | 高噪声下梯度退化 |
TDS(扭曲扩散采样) | 按 对粒子重加权,不改去噪轨迹 | 更忠实保留生成先验 |
SMC(序贯蒙特卡洛) | 跨多轮按 重采样完整轨迹 | 跨架构最稳健的选择性增益 |
候选在选择前经最小界面尺寸与立体冲突过滤,序列由 ProteinMPNN 在选定骨架上设计。
3. 数据集与评测协议
3.1 靶点与样本构造
作者构建 65 个两态蛋白(15 个家族、2,896 个复合物),入选标准:apo/holo 双态实验结构、目标态至少 3 个含肽/蛋白结合物的共晶、且两态间存在结构明确的构象变化。构象幅度跨度极大——从 CaM ~30 Å 的大尺度结构域重排,到 ERα H12 ~10 Å、ABL1 DFG-loop 翻转 ~6.5 Å、CDK2 Cyclin A 诱导等微妙重定位。家族涵盖激酶(9)、小 GTP 酶(6)、核受体(5)、GPCR/离子通道(6)、蛋白酶(6)等共 15 类。
每个复合物产生 12 个基础训练样本:1 个原生 holo(标签 1.0)、1 个 apo 错配(标签 0.0,apo 受体 Kabsch 对齐到 holo 坐标系)、10 个刚体诱饵(Cα RMSD 1–8 Å,标签 )。此外有 959 个 FastRelax 硬负样本(均值标签 0.304)。三类增强进一步丰富训练:跨家族负样本、构象诱饵(Rosetta FastRelax 重打包产生近原生硬负样本)、GenDecoys(来自结构生成模型的合成 binder,提供更多样的非原生界面几何,共 4,862 个)。
3.2 数据划分与配置
主结果采用 target split(51/6/8),CaM 移入 OOD 测试集作为主要设计靶点,ALK 移入训练,关联靶点(如 SRC / SRC-SH2)强制同分区,从源头杜绝泄漏。
- • OOD 测试 8 靶点:CaM、BCL-2、ERα、MDM2、Ran、A2A、PAI-1、Integrin
- • OOD 验证 6 靶点:14-3-3、14-3-3σ、β2AR、Caspase-3、µ-opioid、Rac1
- • 三种打分配置:S1(仅 Baseline,34,751 样本)、S2(全增强,39,867 样本)、S3(去 GenDecoys 的部分增强,36,080 样本)
3.3 评测指标
与 DockQ 的 Spearman ρ(界面质量秩相关)、选择性间隔 、best-of-K 成功率;设计评测用 ProteinMPNN ΔNLL 与 AlphaFold 3 ΔipTM 等 Qθ 无关指标,并报告三个独立 Qθ 检查点的共识选择性。
4. 结果
4.1 Qθ 作为打分器的 OOD 泛化
在 8 个训练时完全保留的 OOD 靶点上,Qθ 与 DockQ 的 ρ̄ = 0.520 ± 0.010(3 seed),八个靶点全为正,四个超过 0.5。
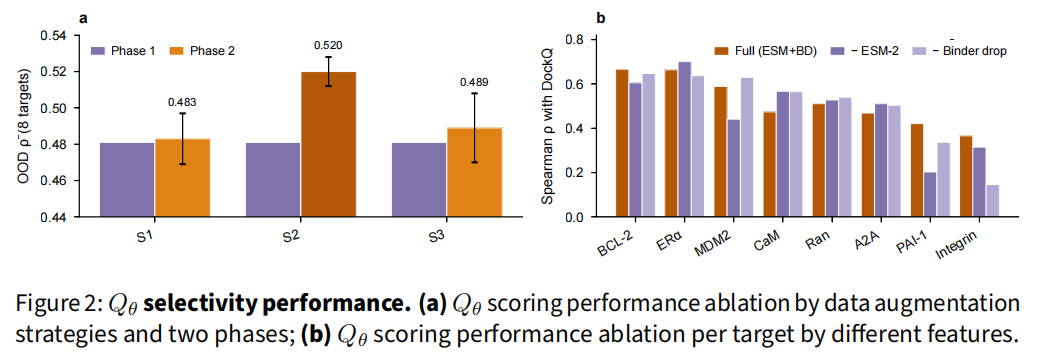
4.2 关键消融
- • 两阶段 > 单阶段:Phase 2 把八靶点均值从 0.481 提到 0.520,增益集中在最难靶点(Integrin +0.166、A2A +0.170),代价是两个最易靶点(BCL-2、ERα)的小幅回落(−0.049 / −0.025)。这是一次明确的"以易换难"权衡。
- • InfoNCE batch 256 最优(ρ̄ 0.530):512 使 softmax 过饱和,64 提供的跨靶点负样本不足;但所有 InfoNCE 配置都优于纯 Phase 1 回归(0.489)。
- • GenDecoys 贡献最大单项增益(Δρ̄ = +0.037),因其提供了更硬的负样本。
- • ESM-2 与 binder dropout 均有益:移除任一都会在最难的 OOD 靶点(Integrin、PAI-1、A2A)上造成最大下降,二者齐备时八靶点全面最优。
4.3 学到的是"构象"而非"通用结合质量"
这是全文最关键的因果质疑,作者用四组干净实验回应:
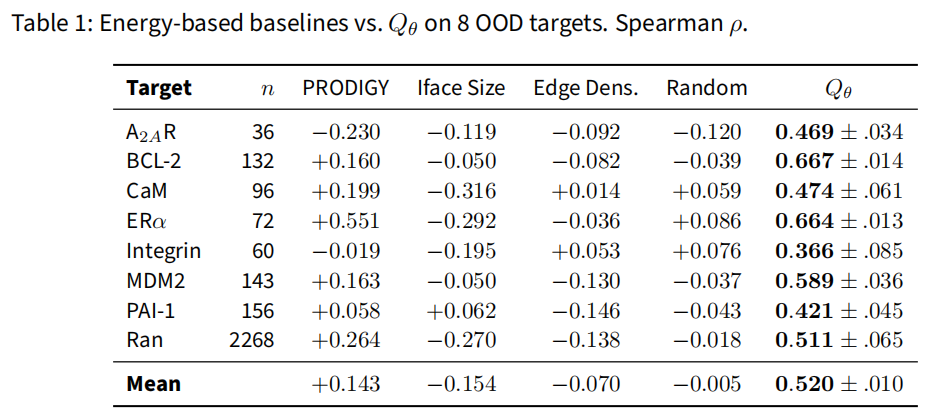
(1) 对照能量代理——完胜。 三种基于接触的代理在 8 OOD 靶点上集体无法追踪 DockQ:
Target () | PRODIGY | 界面尺寸 | 边密度 | 随机 | Qθ |
|---|---|---|---|---|---|
A2AR (36) | −0.230 | −0.119 | −0.092 | −0.120 | 0.469 |
BCL-2 (132) | +0.160 | −0.050 | −0.082 | −0.039 | 0.667 |
CaM (96) | +0.199 | −0.316 | +0.014 | +0.059 | 0.474 |
ERα (72) | +0.551 | −0.292 | −0.036 | +0.086 | 0.664 |
Integrin (60) | −0.019 | −0.195 | +0.053 | +0.076 | 0.366 |
MDM2 (143) | +0.163 | −0.050 | −0.130 | −0.037 | 0.589 |
PAI-1 (156) | +0.058 | +0.062 | −0.146 | −0.043 | 0.421 |
Ran (2268) | +0.264 | −0.270 | −0.138 | −0.018 | 0.511 |
均值 | +0.143 | −0.154 | −0.070 | −0.005 | 0.520 |
(2) 响应"特定构象"而非"通用形状"。 把每个靶点的 50 个 binder 交叉打到全部 8 个受体上,矩阵对角线超出非对角线 19.8 倍。
(3) 群体级 holo>apo。 50 个 vanilla 设计中,7/8 靶点 holo−apo 间隔为正;BCL-2 在每个设计上都分离两态;CaM、MDM2 在三 seed 集成下达到 100%、98% holo 偏好。唯一困难靶点 Integrin 间隔仅 +0.001、52% holo 偏好,与其最低 ρ 一致。
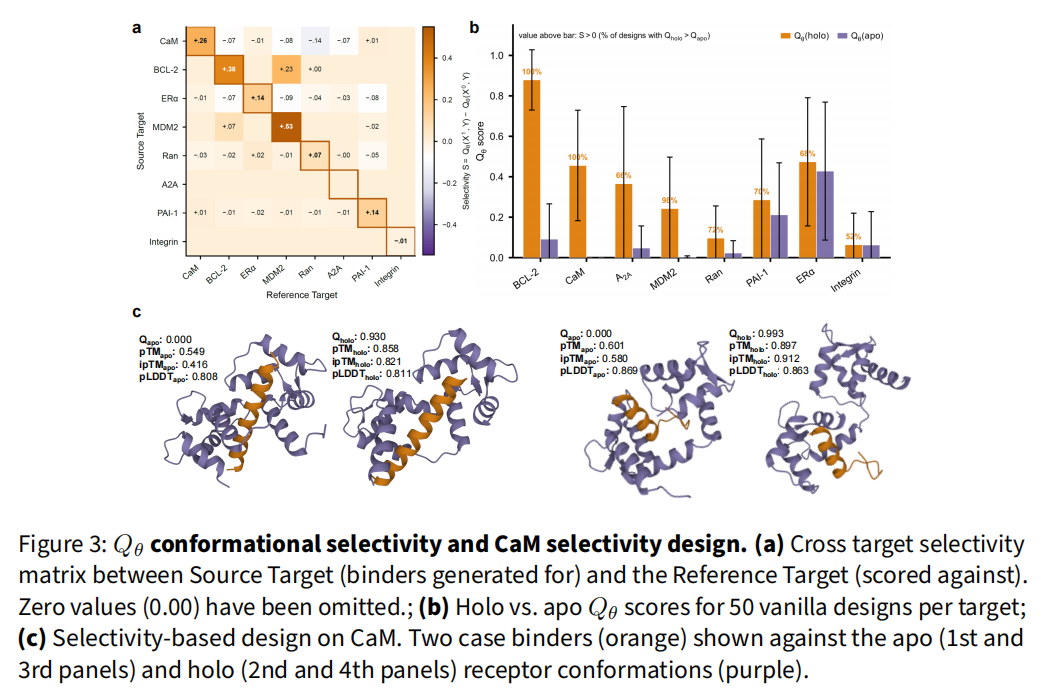
(4) 连续构象地形,而非二元开关。 沿 CaM apo→holo 路径取 11 个插值构象打分,Qθ 单调升向 holo(ρ̄ = +0.518,10/10 单调),说明它学到的是跨转变的连续结构景观。
4.4 选择性引导:跨架构基准
在 3 个架构迥异的生成器 × 5 种模式(vanilla + 4 引导)= 15 组合上,各靶点 50 设计、3-seed 集成打分。每个生成器的共识选择性 均值如下:
生成器 | Vanilla | Classifier | Langevin | SMC | TDS |
|---|---|---|---|---|---|
RFdiffusion | +0.249 | +0.247 | +0.314 | +0.488 | +0.477 |
PXDesign | +0.166 | +0.175 | +0.124 | +0.371 | +0.419 |
Proteina-ComplexA | +0.213 | +0.249 | +0.267 | +0.350 | +0.470 |
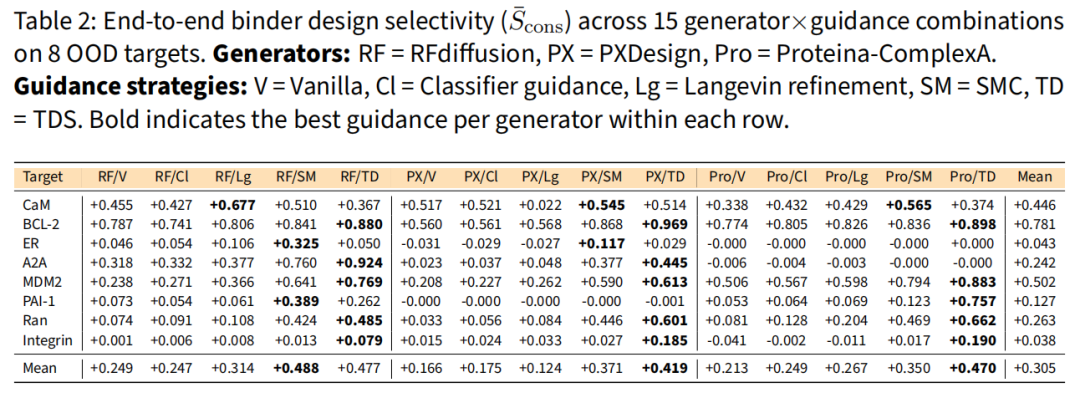
四条一致规律:
- • 重采样类引导(TDS/SMC)最强,全程位列第一或第二,classifier guidance 鲜有超过 vanilla——轨迹级重加权可跨架构迁移。
- • Langevin 依赖生成器先验:改善两个纯结构生成器(RF +0.249→+0.314,Proteina +0.213→+0.267),却拖垮序列敏感的 PXDesign(+0.166→+0.124),因其共设计的界面几何被扰动后失稳。
- • 靶点身份 > 方法选择:BCL-2 在 15 组合中均强选择(=+0.781),Integrin/ERα/PAI-1 在所有组合下都弱。
- • ERα 是有意思的反例:打分 ρ 第二高(0.664)但设计 第二低(+0.043)——瓶颈在生成而非打分,因为当前生成器提不出能利用其微妙 H12 重定位的骨架。
4.5 为什么 Langevin 优于 classifier guidance(机理解释)
作者测量 Qθ 梯度在噪声扰动下的余弦相似度:从 σ=0.1 Å 的 0.75 降到 σ=0.5 Å 的 0.12,σ≥2.0 Å 时趋零。把该曲线映射到 RFdiffusion 去噪调度后,classifier guidance 约 96% 的轨迹处于"梯度无信息"区(只有最后约 2/50 步进入 σ<0.10 Å 的可靠区),而 Langevin 只在 σ≈0.04 Å 的完全去噪骨架上操作,自然规避了该区域。这是对"为何 Langevin 有效"的定量解释,而非事后叙述。
4.6 重排序 vs 梯度精修
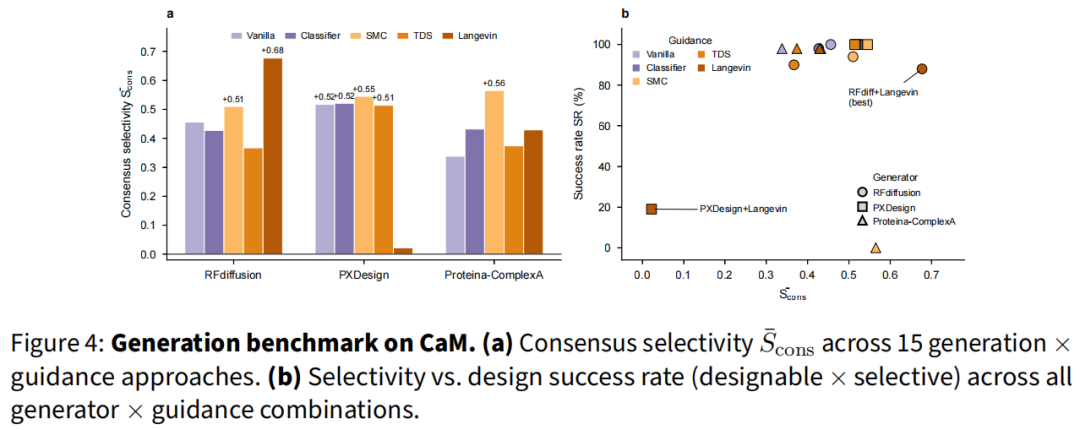
在 CaM 50 设计(vanilla 池已达 =+0.456、100% 正选择性)上,Qθ 作被动重排序器同样强:best-of-5 达 +0.787,best-of-10 达 +0.885,均超过 Langevin 的 +0.677;bootstrap 证实增益随池规模增长(K≈10 后边际收益递减)。结论是二者互补:重排序在大候选池上高效扩展,Langevin 在候选昂贵、需逐设计增益时更优。CaM 全流程中,15 组合有 14 个均值为正,RFdiffusion+Langevin 达 =+0.677、88% 成功率(可设计性 × 选择性)。
4.7 独立打分器交叉验证
为排除"用自身信号自证",作者引入多个未参与训练的独立打分器:
- • Boltz-2 ΔipTM:5/8 靶点为正,设计级与 Qθ 最强一致出现在 A2A(ρ=+0.500)与 CaM(ρ=+0.349)。
- • AlphaFold 3 ΔipTM(单序列模式):ALK 与 ERα 的 50 个设计 100% holo 偏好。
- • Rosetta InterfaceAnalyzer:BCL-2 界面能最优(−9.1 REU),Integrin 最差(+39.1 REU)——与 Qθ 在最强/最弱端排序一致。
- • ProteinMPNN ΔNLL:vanilla 设计在全部 8 靶点上显著偏好 holo(p<0.05),说明 holo 偏置已存在于骨架且无需 Qθ 即可检出;但 Langevin 在 5/8 靶点上降低 ΔNLL 的同时抬高 Qθ——证明二者度量正交维度(Qθ 捕捉几何选择性,ΔNLL 捕捉序列恢复似然),互不充当对方的 ground truth。
- • 退化鲁棒性:482 个 CaM 设计中仅 10 个负选择性,全部为截断或立体不可行的退化骨架,且全来自单一管线(PXDesign+Langevin),无一是"骗过打分器"的真 apo 选择性设计。
值得强调:三个独立打分器只在两端一致、在中间靶点分歧——作者指出这本身是有信息的,因为 Qθ 衡量构象选择性而这些工具衡量整体界面能,两者本就不必重合。
4.8 湿实验:AlloGen 肽选择性结合 holo CaM
这是全文最有说服力的一步。作者从多个生成器–引导组合中按预测间隔 选出 10 条候选肽,外加 1 条低分负对照与经典 Ca²⁺ 依赖的 M13 阳性对照。
关键在于候选漏斗刻意与 Qθ 无关(双态热点条件化 → ProteinMPNN 序列设计 → Boltz-2 双态重折叠 → 埋藏面积 >800 Ų / holo ipTM >0.7 / Δq≥0.3 过滤 → CD-HIT 70% 去冗余),保证检验的公平。结合由 Adaptyv Bio 用 生物层干涉(BLI) 在 Gator Bio Pro 上测量,Twin-Strep 生物传感器固定肽,CaM 浓度 0/100/1000 nM,1:1 模型拟合;holo CaM 加 CaCl₂、apo CaM 加 EGTA,其余条件完全一致。
结果:10 条中 5 条结合 holo CaM,亲和力 46.6 nM – 1.06 µM,且全部来自高 Δq 区间;负对照(Δq=0.228)无可测结合;无一结合 apo 态:
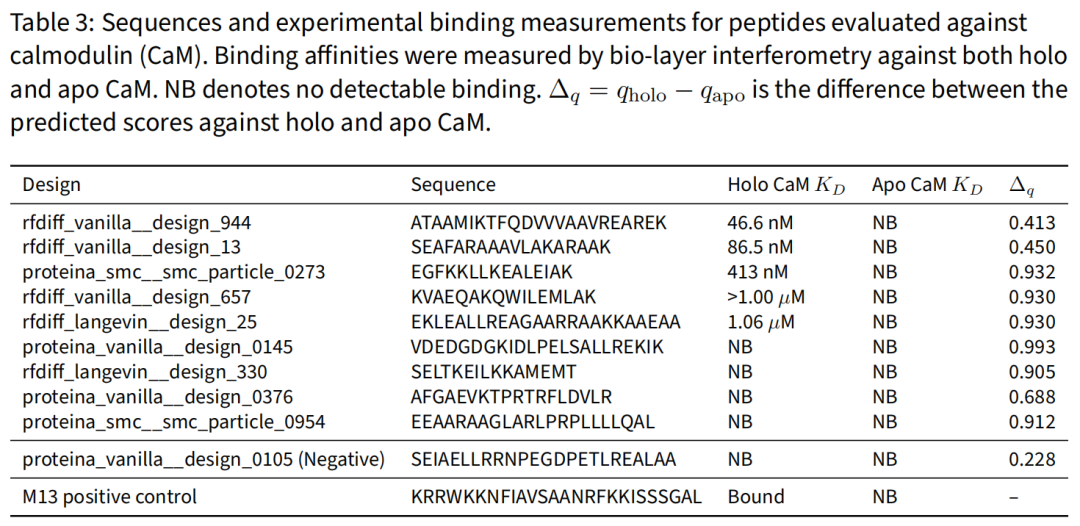
这是直接的物理证据:Qθ 学到的选择性信号可转化为实验可测的结合特异性。
5. 创新点剖析
- 1. 范式转变:首次将构象选择性确立为可学习、可迁移的目标,而非个案式的负设计经验。打分器与设计目标从"绝对亲和力"转向 logit 空间的差分亲和力。
- 2. 解耦 + 即插即用:生成器无关、可微分的 Qθ 既能重排序也能引导,不重训即可接入任意骨架生成器,且 logit 间隔可推广到多状态 。
- 3. 两阶段课程:几何先行(DockQ 回归)、对比在后(双类负样本 InfoNCE),系统性规避"忽略受体构象"的退化坍缩——这是该问题的核心训练难点。
- 4. 训练–推理对齐:binder dropout 使打分器学会仅凭骨架几何判别,匹配"对无序列骨架打分"的真实推理设置。
- 5. 严谨的可信度工程:Qθ 无关的候选漏斗 + 多个独立打分器交叉验证 + 失败模式审计 + 前瞻性 BLI,层层防止"自证"与"作弊设计"。
6. 局限与开放问题
- • 仅两态:实证只演示了 apo/holo 二元判别;虽然 logit 间隔形式上支持多态,但多状态构象景观未被实验验证。
- • 生成端是真正瓶颈:ERα 案例清楚显示,即便打分器很好,当前生成器提不出能利用微妙运动(如 H12)的骨架;AlloGen 改善的是"选哪个",对"能否生成出来"无能为力。
- • 某些组合存在结构性不匹配:PXDesign+Langevin 是唯一负选择性结果,源于序列感知先验被骨架扰动破坏——引导策略需匹配生成器内部机制。
- • 困难靶点仍困难:Integrin 在打分、群体偏好、引导各环节均最弱(ρ 0.366、52% holo),框架对界面信号弱的靶点改善有限。
- • 部分指标只能定向解读:ΔNLL 在 apo 偏离靶点(ERα、Ran、A2A)上参考态被误设,作者明确标注"仅作方向性解读"。
- • 湿实验的边界:① 仅在单一靶点(CaM)验证,而 CaM 是构象变化最剧烈、最"易"的靶点之一;② 5/10 命中率且亲和力多在亚微摩尔到纳摩尔级,偏温和;③ Δq 预测选择性方向很准(高分全选择性、低分负对照失败、无 apo 结合),但并不预测绝对亲和力或可表达性——最高 Δq=0.993 的设计反而完全不结合。换言之,Δq 是"选择性排序器"而非"亲和力预测器"。
7. 意义与展望
AlloGen 把一个长期被默认"无解"的目标——构象选择性——转化为可学习、可迁移、可微分的设计信号,并在 65 靶点 / 15 家族上验证泛化、用湿实验完成闭环。其最具影响力之处在于模块化:Qθ 很可能成为现有蛋白设计流水线中一个即插即用的组件。
作者指明的方向也正切中上述局限:扩展到多状态构象景观、将选择性直接整合进端到端序列生成(而非事后重排/引导)、以及推进到生物活性依赖于特定构象的治疗性靶点。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号