Agent 和传统软件开发最大的区别:控制流变了


前几天看一个 Agent 项目的代码 review。
页面做得挺像回事:左边是聊天框,右边是任务进度,模型会回复“我正在分析需求”“我已经调用知识库”“我准备生成方案”。产品同学看完很兴奋,说这不就是下一代软件入口吗?
结果后端同学点开日志,空气突然安静。
2026-06-08 14:21:09 user: 帮我给退款失败的订单重新发起补偿
2026-06-08 14:21:11 agent.plan: 查询订单 -> 判断失败原因 -> 调用补偿接口
2026-06-08 14:21:13 tool.call: query_order(order_id=202606080013)
2026-06-08 14:21:14 tool.result: status=REFUND_FAILED, retry_count=2
2026-06-08 14:21:17 tool.call: compensate(order_id=202606080013, amount=129.00)
2026-06-08 14:21:18 tool.result: success=false, error=IDEMPOTENCY_KEY_REQUIRED
2026-06-08 14:21:21 agent.plan: 上一次补偿失败,换一个请求参数重试
2026-06-08 14:21:23 tool.call: compensate(order_id=202606080013, amount=129.00)
2026-06-08 14:21:24 tool.result: success=false, error=IDEMPOTENCY_KEY_REQUIRED
乍一看只是少传了一个幂等键。
但这个问题很要命。
传统系统里,少传幂等键大概率是一次接口调用失败。Agent 系统里,模型可能会把失败解释成“需要重试”,然后继续调用工具,把一个小错误放大成循环错误、成本错误,甚至业务资金风险。
这就是我现在看 Agent 项目最关心的地方。
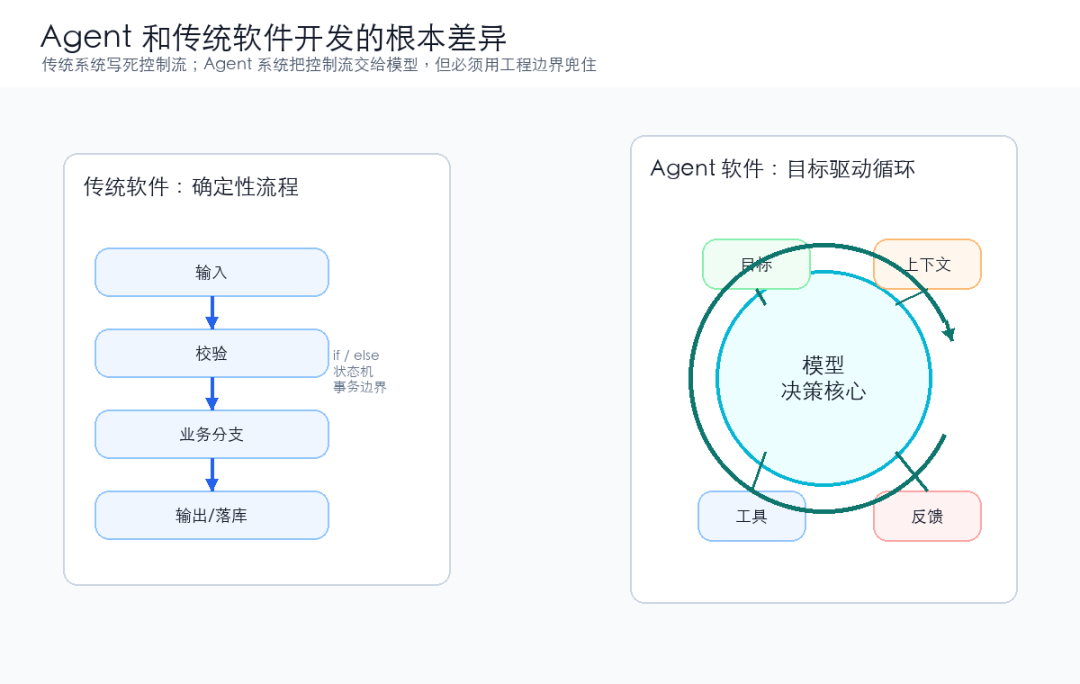
Agent 和传统软件开发的区别,不是多了一个 ChatBot 界面,而是软件从“确定性流程”变成了“目标驱动的执行循环”。
以前我们写系统,是把路径写死。
现在搭 Agent,是把目标交给模型,让它自己规划、调用工具、观察结果、再决定下一步。
这会重写软件开发范式。
不是因为程序员不用写代码了,而是程序员要开始设计另一套东西:上下文、工具、权限、评测、可观测、回滚和人类审批边界。
ChatBot 回答问题,Agent 改变世界
很多人把 Agent 做成 ChatBot,是因为第一版 demo 最容易这么做。
用户问一句,模型答一句。
只要回答看起来像人,产品就觉得“智能”。
但 ChatBot 和 Agent 的工程风险完全不是一回事。
对比项 | ChatBot | Agent |
|---|---|---|
核心动作 | 生成回复 | 完成目标 |
控制流 | 人类一问一答 | 模型持续决策 |
外部影响 | 多数是文本输出 | 可能读写数据库、调用接口、发消息、改代码 |
失败形态 | 答错、编造、跑题 | 错调工具、重复执行、越权操作、成本失控 |
工程重点 | 知识、提示词、对话体验 | 工具边界、执行闭环、审计和回滚 |
一句话说清楚:
ChatBot 的产物是答案,Agent 的产物是动作。
动作一旦进入生产系统,就不能只靠“模型应该会懂”。
它要有权限模型,要有幂等控制,要有审批阈值,要有 trace,要能复盘每一步为什么发生。
所以很多所谓 Agent 项目,问题不在模型不够强,而在团队还用做 ChatBot 的方式做 Agent。
他们只写了 prompt,没有设计执行系统。
以前写系统:控制流写在代码里
传统软件开发的基本假设是确定性。
用户点按钮,后端进入 Controller,Service 校验参数,查库,分支判断,写库,返回结果。
就算业务很复杂,本质上也是开发者提前把路径写进代码里。
比如一个退款补偿接口:
public CompensationResult compensate(String orderId, BigDecimal amount, String idempotencyKey) {
if (idempotencyKey == null || idempotencyKey.isBlank()) {
thrownew BizException("IDEMPOTENCY_KEY_REQUIRED");
}
Order order = orderRepository.findById(orderId)
.orElseThrow(() -> new BizException("ORDER_NOT_FOUND"));
if (!order.isRefundFailed()) {
thrownew BizException("ORDER_STATUS_NOT_ALLOWED");
}
if (order.getRetryCount() >= 3) {
thrownew BizException("RETRY_LIMIT_EXCEEDED");
}
return compensationService.submit(orderId, amount, idempotencyKey);
}
这段代码并不高级,但它有一个非常强的工程属性:
每一条路径是谁写的,什么时候会走,失败后返回什么,基本都能静态分析。
测试也围绕路径展开:
case_01: idempotencyKey 为空 -> 拒绝
case_02: 订单不存在 -> 拒绝
case_03: 订单不是退款失败 -> 拒绝
case_04: retry_count >= 3 -> 拒绝
case_05: 参数合法 -> 提交补偿
这就是传统软件的舒适区。
它不是没有复杂度,但复杂度主要来自业务分支、数据一致性、并发、性能和系统边界。
开发者的工作是把不确定的需求,翻译成确定的代码路径。
现在搭 Agent:控制流变成运行时生成
Agent 不是这么跑的。
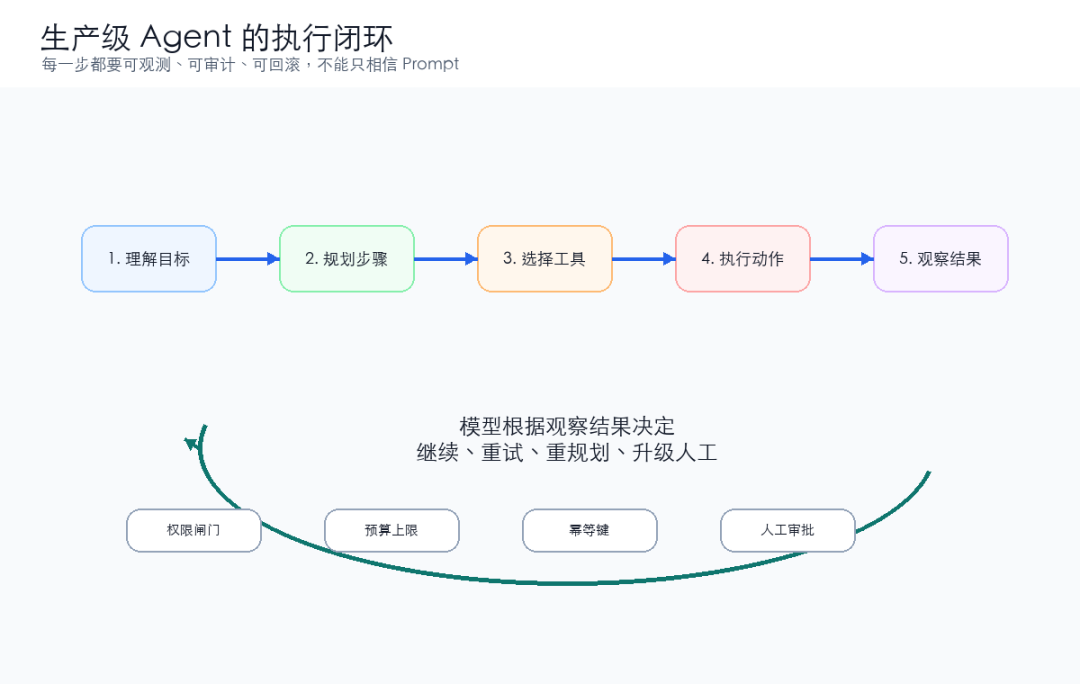
Agent 的执行过程更像这样:
用户只给一个目标:
帮我给退款失败的订单重新发起补偿。
Agent 需要自己拆:
1. 识别用户意图:订单补偿
2. 补齐必要参数:订单号、金额、失败原因
3. 查询订单状态
4. 判断是否满足补偿条件
5. 选择补偿工具
6. 执行工具调用
7. 观察结果
8. 成功则回复,失败则决定重试、终止或升级人工
看起来只是多了一层模型。
其实控制流已经变了。
以前是开发者写:
if retry_count >= 3:
reject
else:
compensate
现在是模型在运行时判断:
当前工具失败了,是参数不完整、状态不允许、临时网络问题,还是应该换一个方案?
这一步最危险。
因为模型不是传统意义上的流程引擎。它会推理,也会误判;会调用工具,也会填错参数;会观察结果,也可能把错误信息理解错。
所以 Agent 工程的第一原则不是“让模型更聪明”。
而是:
把模型允许自由决策的空间,限制在业务能承受的范围内。
变化一:需求文档变成可执行规格
传统软件里,需求文档经常是给人看的。
人读完,开会,拆接口,写代码。
Agent 开发里,需求不能只给人看,还要给模型看、给评测系统看、给 guardrail 看。
也就是说,需求要变成规格。
比如“订单补偿 Agent”不能只写:
支持用户对退款失败订单发起补偿。
这句话对人类产品经理够用,对 Agent 完全不够。
它至少要写成这样:
goal: refund_compensation
description:对退款失败订单发起一次补偿请求
required_inputs:
-order_id
-user_id
preconditions:
-order.status==REFUND_FAILED
-order.retry_count<3
-order.owner_user_id==current_user.id
tool_policy:
compensate_order:
max_calls_per_task:1
require_idempotency_key:true
require_human_approval_when:
-amount>=500
-user_risk_level==HIGH
acceptance:
-成功时必须返回补偿单号
-失败时必须返回失败原因和下一步处理建议
-不允许绕过用户归属校验
这就是 Agent 时代需求形态的变化。
以前需求是“描述功能”。
现在规格要同时描述目标、约束、工具策略和验收标准。
如果没有这层规格,模型生成的计划看起来会很顺,但每一步都可能偏离业务边界。
变化二:接口不再只是给前端调,也是给模型调
传统后端接口主要面向人写的程序。
前端同学知道字段含义,后端同学知道错误码,大家通过文档和联调对齐。
Agent 调工具不是这样。
模型只能通过工具名、描述、参数 Schema、错误信息来理解这个工具。
所以一个工具定义写得烂,等于给模型挖坑。
比如这个工具:
{
"name": "do_refund",
"description": "处理退款",
"parameters": {
"type": "object",
"properties": {
"id": { "type": "string" },
"money": { "type": "number" }
}
}
}
人能猜出来,模型未必猜得稳定。
id 是订单 ID、退款单 ID,还是用户 ID?
money 是退款金额、补偿金额,还是可退余额?
更好的写法应该是:
{
"name": "compensate_refund_failed_order",
"description": "仅用于对状态为 REFUND_FAILED 的订单发起一次补偿。不能用于普通退款、取消订单或提现补偿。",
"parameters": {
"type": "object",
"additionalProperties": false,
"properties": {
"order_id": {
"type": "string",
"description": "业务订单号,必须来自 query_order 的返回结果或用户明确提供"
},
"amount": {
"type": "number",
"description": "补偿金额,单位元,必须等于订单可补偿金额"
},
"idempotency_key": {
"type": "string",
"description": "本次补偿任务的幂等键,同一个 task_id 内必须保持不变"
}
},
"required": ["order_id", "amount", "idempotency_key"]
}
}
这里的关键不是 JSON 写得漂亮。
关键是工具 Schema 开始承担一部分“运行时约束”的职责。
OpenAI 的 function calling、Structured Outputs,以及 MCP 的 tools,本质上都在解决同一个工程问题:让模型调用外部能力时,输入输出尽可能结构化、可校验、可审计。
但注意,Schema 只能约束格式,不能替你判断业务风险。
amount 是 number,不代表它就是合法金额。
所以工具后面还要有服务端权限校验、业务校验和审计日志。不能因为调用者换成模型,就把后端基本功丢了。
变化三:异常处理从 try/catch 变成执行策略
传统代码里,异常处理通常是局部的。
接口失败了,返回错误码。
调用超时了,重试三次。
数据库写失败了,回滚事务。
Agent 的异常更麻烦,因为模型会“解释异常”。
看这段执行日志:
tool.result:
code: IDEMPOTENCY_KEY_REQUIRED
message: idempotency key is required
agent.reasoning:
工具返回缺少幂等键,可能是本次请求参数缺失。
我将重新生成参数并再次调用。
这个推理看起来很合理。
但如果平台规则是“补偿工具每个任务最多调用一次”,那模型继续重试就是错的。
所以 Agent 系统要把异常分成几类:
异常类型 | 例子 | Agent 应该怎么做 |
|---|---|---|
可补全参数 | 缺少订单号、缺少用户确认 | 追问用户或查上下文 |
可重试技术错误 | 网络超时、临时 503 | 按退避策略重试 |
不可重试业务错误 | 状态不允许、超过次数、缺幂等键 | 终止任务并解释原因 |
高风险动作 | 大额补偿、删除数据、改权限 | 升级人工审批 |
语义冲突 | 文档 A 和接口 B 规则不一致 | 停止自动执行,要求人工确认 |
这段策略不能只写在 prompt 里。
prompt 可以提醒模型,但真正的执行层要兜住:
NON_RETRYABLE_CODES = {
"ORDER_STATUS_NOT_ALLOWED",
"RETRY_LIMIT_EXCEEDED",
"IDEMPOTENCY_KEY_REQUIRED",
}
def should_continue(task, tool_result):
if task.tool_calls.count(tool_result.tool_name) >= task.policy.max_calls_per_tool:
return"STOP_MAX_TOOL_CALLS"
if tool_result.code in NON_RETRYABLE_CODES:
return"STOP_NON_RETRYABLE"
if tool_result.code in {"TIMEOUT", "TEMPORARY_UNAVAILABLE"}:
return"RETRY_WITH_BACKOFF"
if task.risk_score >= 80:
return"ASK_HUMAN_APPROVAL"
return"LET_AGENT_PLAN_NEXT_STEP"
这段代码的意义不是替代模型。
它是告诉模型:你可以规划,但不能越过系统策略。
Agent 工程里很多坑,都是把“策略”误写成了“建议”。
建议写在 prompt 里,模型可能遵守,也可能忘。
策略写在执行层里,系统必须遵守。
变化四:测试从断言输出,变成评测行为轨迹
传统软件测试喜欢断言结果。
输入 A,输出 B。
Agent 当然也要测输出,但只测输出不够。
因为同样一句“处理完成”,背后的轨迹可能完全不同。
一种轨迹是:
query_order -> compensate_order -> reply_success
另一种轨迹是:
compensate_order -> compensate_order -> compensate_order -> reply_success
最后都可能返回“处理完成”,但第二种明显有风险。
所以 Agent 评测至少要看三层:
评测层 | 关注点 | 示例 |
|---|---|---|
输出评测 | 回答是否正确、清楚、有引用 | 是否说明失败原因 |
轨迹评测 | 工具调用顺序是否合理 | 是否先查订单再补偿 |
策略评测 | 有没有越权、重复、高风险动作 | 是否触发人工审批 |
一个最小评测样例可以这么写:
case_id: refund_compensation_missing_idempotency
input:帮我给订单202606080013重新发起退款补偿
mock_tools:
query_order:
status:REFUND_FAILED
retry_count:2
amount:129.00
compensate_order:
code:IDEMPOTENCY_KEY_REQUIRED
expected:
must_call:
-query_order
must_not_call_more_than:
compensate_order:1
final_state:STOP_NON_RETRYABLE
response_should_contain:
-幂等键
-无法自动重试
这里测的不是模型文采。
而是它有没有按工程策略行动。
这也是 Agent 和传统软件最大的测试差异:你不只验证结果,还要验证过程。
如果一个 Agent 不能回放轨迹,不能解释每次工具调用的原因,不能在评测里稳定通过关键场景,那它还停留在 demo 阶段。
变化五:可观测性从日志,升级成决策链路
传统系统的日志大多记录“发生了什么”。
Agent 系统还要记录“为什么这么做”。
一个生产级 trace 至少要包含这些字段:
{
"task_id": "task_202606080001",
"user_id": "u_1024",
"goal": "refund_compensation",
"model": "gpt-4.1",
"context_tokens": 18432,
"step": 3,
"decision": "call_tool",
"reason_summary": "订单为退款失败且重试次数小于 3,准备发起补偿",
"tool_name": "compensate_refund_failed_order",
"tool_args_hash": "sha256:8f1a...",
"risk_score": 62,
"policy_result": "ALLOW",
"latency_ms": 1380,
"cost_usd": 0.018
}
这里有几个字段很关键。
reason_summary 不是为了保存模型完整思维链,而是为了保存可审计的决策摘要。
tool_args_hash 可以避免日志里直接落敏感参数,又能做幂等和追踪。
policy_result 能告诉你这次动作是被允许、拦截,还是升级人工。
context_tokens 和 cost_usd 则是 Agent 系统特有的成本维度。
很多传统系统性能问题是 CPU、内存、数据库慢。
Agent 系统还会多出一类问题:上下文越塞越长,工具越调越多,延迟和成本一起涨。
没有 trace,你连它为什么贵都不知道。
程序员的工作正在变,不是消失
所以“以前写系统,现在搭 Agent”到底变在哪里?

我觉得变化主要有五个。
过去的主要工作 | Agent 时代对应工作 |
|---|---|
写业务流程 | 设计 Agent 执行闭环 |
写接口文档 | 设计工具 Schema 和语义边界 |
写异常处理 | 设计重试、终止、升级人工策略 |
写单元测试 | 写轨迹评测和策略评测 |
看服务日志 | 看模型决策、工具调用、成本和风险 trace |
这不是说传统能力不重要了。
正好相反。
Agent 项目越往生产走,越吃传统工程能力。
权限、事务、幂等、审计、灰度、回滚、限流、熔断、数据一致性,这些东西不会因为外面套了个大模型就消失。
模型只会把它们的重要性放大。
以前一个 bug 可能只影响一个接口。
Agent 会自己规划下一步,它可能把 bug 带进后续工具调用里。
这就是为什么我不太喜欢“Agent 会替代程序员”这种说法。
更准确的说法是:
Agent 会替代一部分重复编码,但会放大架构设计、系统治理和工程判断的价值。
一个能上线的 Agent,至少要有四道闸门
回到工程落地。
如果你现在要把一个 ChatBot 改成 Agent,我不建议一上来就追求复杂规划、多 Agent 协作、自动长期记忆。
先把四道闸门补上。

第一,工具闸门
工具不是越多越好。
每个工具都要回答四个问题:
- 这个工具能做什么?
- 这个工具不能做什么?
- 哪些参数必须来自可信来源?
- 调用失败后能不能重试?
高危工具要默认人工审批,比如付款、删除、改权限、批量通知、代码自动合并。
第二,上下文闸门
Agent 不是看到的信息越多越好。
上下文要控制来源、时效、优先级和 token 预算。
尤其是 RAG 场景,不同文档冲突时,不能让模型自己猜。要明确规则:接口返回优先于旧文档,线上配置优先于 Wiki,人工确认优先于模型推断。
第三,策略闸门
策略要写在执行层,不要只写在 prompt。
比如:
- 每个任务最多调用一次补偿接口
- 大于 500 元必须人工审批
- 缺少幂等键不能自动重试
- 工具返回权限错误必须终止
- 连续两步失败必须停止自动执行
这些不是“建议模型这么做”,而是系统必须拦截。
第四,评测闸门
没有评测的 Agent 上线,本质上是开盲盒。
至少要沉淀一批回归用例:
- 正常成功路径
- 参数缺失路径
- 工具超时路径
- 业务不允许路径
- Prompt 注入路径
- 高风险动作路径
- 多轮上下文遗忘路径
每次改 prompt、换模型、增工具、调检索策略,都要跑一遍。
Agent 的稳定性,不是靠“这次试了一下能跑”证明的。
它要靠持续评测证明。
面试怎么答:Agent 和传统软件开发到底有什么区别?
如果面试官问你:
★Agent 和传统软件开发的区别是什么?
不要只答“Agent 会调用工具”“Agent 有记忆”“Agent 能自主规划”。
这些都对,但不够工程。
可以这么答:
我理解最大的区别是控制流的位置变了。
传统软件开发里,控制流主要由开发者写死在代码里,比如 if/else、状态机、工作流引擎。
Agent 系统里,控制流有一部分转移到了模型运行时,由模型根据目标、上下文和工具结果动态决定下一步。
这会带来三个工程变化:
第一,接口要变成模型可理解、可校验的工具 Schema。
第二,异常处理要从局部 try/catch 升级成执行策略,比如哪些错误可重试、哪些必须终止、哪些要人工审批。
第三,测试不能只测最终输出,还要评测工具调用轨迹、权限边界、成本和风险。
所以 Agent 不是 ChatBot 套工具,而是一套带不确定性的执行系统。
真正难的不是让它能跑,而是让它在生产环境里可控、可观测、可回滚。
这个回答的重点在“控制流转移”。
你抓住这个点,后面聊 Tool Calling、MCP、RAG、Memory、Guardrail、Eval,都能串起来。
最后回到那个补偿 Agent
开头那个项目,最后怎么改?
不是把 prompt 写得更长。
而是补了三层东西。
第一,把补偿接口重新定义成严格工具 Schema,明确 idempotency_key 必填,且必须由系统生成,不能让模型自由编。
第二,在执行层加策略:补偿工具每个任务最多调用一次,IDEMPOTENCY_KEY_REQUIRED 属于不可重试业务错误,直接终止并提示人工处理。
第三,把所有关键路径做成评测用例,尤其是“缺参数”“状态不允许”“工具失败后模型想继续重试”这几类。
改完以后,它看起来反而没那么“智能”了。
不会动不动就自己想办法。
不会什么都自动重试。
不会假装自己能处理所有异常。
但它更像一个能上线的软件系统。
这就是 Agent 开发最反直觉的地方:
真正成熟的 Agent,不是最自由的 Agent,而是知道自己什么时候不能继续行动的 Agent。
以前写系统,我们追求把流程写清楚。
现在搭 Agent,我们要追求把边界搭清楚。
ChatBot 改变的是交互方式。
Agent 改变的是软件的执行方式。
而执行方式一变,程序员的工作就不再只是写代码路径。
我们开始设计一套能让模型参与决策、但又不让它把系统带偏的工程秩序。
这才是 Agent 真正会重写软件开发范式的地方。
参考资料
- OpenAI Agents SDK Documentation: https://openai.github.io/openai-agents-python/
- OpenAI Agents SDK Guardrails: https://openai.github.io/openai-agents-python/guardrails/
- OpenAI Function Calling Guide: https://platform.openai.com/docs/guides/function-calling
- Model Context Protocol Documentation: https://modelcontextprotocol.io/docs
- LangChain Agents Documentation: https://docs.langchain.com/oss/python/langchain/agents
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号