OpenCLI:把网站、Electron 和本地命令,统一成 AI Agent 能调用的一层 CLI

OpenCLI:把网站、Electron 和本地命令,统一成 AI Agent 能调用的一层 CLI

阿特拉斯
发布于 2026-06-15 17:40:06
发布于 2026-06-15 17:40:06
最近看到一个挺有意思的仓库:jackwener/opencli。
如果只看名字,你可能会以为它只是又一个“把网页包装成命令行”的小工具。 但我认真看完 README、中文文档和它的适配器说明之后,感觉它真正想做的事情其实更大:
它不是单纯在做 CLI,而是在给 AI Agent 做一层统一的工具入口。
这也是它最近会被很多人关注的原因。
截至 2026 年 3 月 24 日,GitHub 页面显示这个仓库大约有 5k+ Stars、446 Forks。
这类项目能涨起来,通常不是因为“又支持了几个网站”,而是因为它踩中了一个越来越现实的问题:
AI 会写代码了,也会调 API 了,但它怎么稳定地操作网站、桌面应用和本地工具,仍然是割裂的。
而 OpenCLI 给出的答案非常直接:
把这些东西都收成命令行。
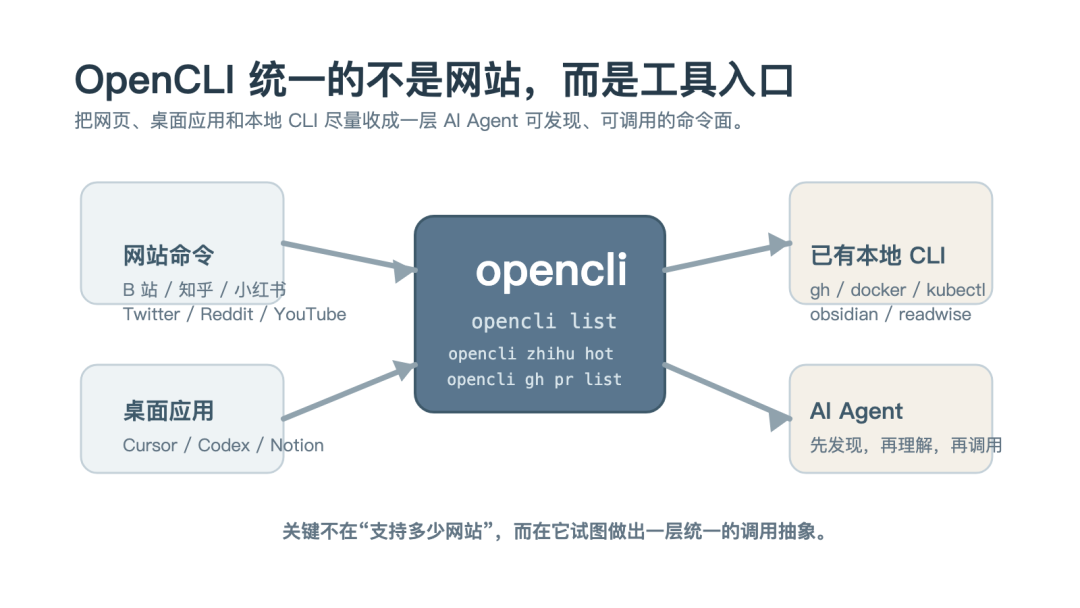
OpenCLI 统一命令面示意图
它到底在做什么
用仓库自己的话说,OpenCLI 的目标是:
把任何网站、本地工具、Electron 应用,变成可以让 AI 调用的命令行。
这个定义听起来很像宣传语,但拆开来看,其实非常具体。
它做的是三类事情:
1. 网站 CLI 化
比如:
• B 站
• 知乎
• 小红书
• Twitter/X
• YouTube
这些原本只能在网页里点来点去的东西,现在被包装成了像下面这样的命令:
opencli bilibili hot --limit 5
opencli zhihu hot -f json
opencli xiaohongshu publish
这意味着,对于人来说它是 CLI;对于 AI 来说,它就变成了一个可发现、可调用、可组合的工具。
2. 桌面应用 CLI 化
这是它最有辨识度的一点。
README 里写得很猛: 它不仅想 CLI 化网站,还想 CLI 化 Electron 应用和桌面应用。
仓库里已经列出来的适配对象包括:
• Cursor
• Codex
• ChatGPT 桌面端
• ChatWise
• Notion
• Discord
• Doubao 桌面端
• Antigravity Ultra
这件事为什么重要?
因为很多 AI 工作流现在已经不只发生在浏览器里,还发生在:
• IDE
• 桌面端聊天应用
• 本地生产力工具
OpenCLI 的野心,其实就是把这些也变成一层统一的命令接口。
3. 本地 CLI 收编成统一入口
它不仅能代理网站和桌面应用,也能把你已有的本地 CLI 工具纳入统一入口。
比如 README 里直接举了这些例子:
• gh
• docker
• kubectl
• obsidian
• readwise
• gws
用法就是这种风格:
opencli gh pr list --limit 5
opencli docker ps
opencli kubectl get pods
而且它还有一个非常实用的设计:
如果底层 CLI 没装,OpenCLI 会优先尝试通过系统包管理器自动安装,再重新执行。
这件事看起来像个小细节,但对 AI Agent 很关键。
因为对 Agent 来说,真正麻烦的从来不是“怎么调一个命令”,而是:
• 这个命令到底存不存在
• 没装怎么办
• 参数怎么查
• 输出怎么统一
OpenCLI 想做的,就是把这层摩擦尽量抹平。
这个项目最值得注意的地方,不是“支持很多平台”,而是它的统一抽象
如果一个项目只是支持很多网站,其实不一定能走远。
真正让我觉得它有意思的,是它在试图把这些不同来源的能力,压到一套相对统一的抽象下面。
从仓库文档看,它大概把工具来源分成了几类:
• Public:直接走公开接口
• Browser:走浏览器登录态和页面能力
• Desktop:走桌面应用适配
• External CLI:透传和管理已有命令行工具
你会发现,这不是“采集器大全”的思路,而更像是:
不管能力来自网页、桌面端还是本地命令,最后都尽量变成一条统一的命令调用路径。
这件事为什么对 AI 特别重要?
因为 AI 最怕的是工具形态混乱。
今天如果你让一个 Agent 去完成任务,它面对的现实通常是这样的:
• 有些能力只能调 HTTP API
• 有些能力只能点网页
• 有些能力要靠浏览器登录态
• 有些能力藏在本地 CLI 里
• 有些能力还在 Electron 应用内部
这会导致一件事:
工具调用逻辑非常分裂。
而 OpenCLI 的价值,就在于它想把这件事尽量统一。
它为什么会强调“AI Agent Ready”
README 里有一句话我觉得特别关键:
它建议你在全局 AGENT.md 或 .cursorrules 里告诉 AI:
• 去执行 opencli list
• 先发现有哪些工具
• 再按对应用法调用
这其实已经不是普通 CLI 项目的思路了。
普通 CLI 项目面向的是人。 OpenCLI 面向的是人,但更面向 Agent。
也就是说,它想解决的不是“我作为人能不能在终端里跑命令”,而是:
一个 Agent 能不能先发现工具,再正确调用工具。
这个差别非常大。
因为很多工具仓库虽然也能被 AI 用,但它们并不是为“被 AI 自动理解和调用”而设计的。
OpenCLI 明显在往这个方向靠。
它真正能跑起来,靠的是 Browser Bridge 和分层认证策略
这种项目最容易被误解的一点是:
“不就是套一层爬虫吗?”
如果只是爬虫,它很难做到现在这个覆盖面。
OpenCLI 真正的关键设计,有两层。
第一层:复用 Chrome 登录态
它的基本思路不是让你到处输 token,也不是把账号密码塞进工具里。
而是:
• 你先在 Chrome 里正常登录网站
• OpenCLI 通过 Browser Bridge 扩展和本地 daemon 去连接浏览器
• 浏览器命令直接复用现有登录状态
这也是 README 里一直强调的点:
运行浏览器类命令之前,你必须先在 Chrome 里登录目标网站。
这个设计很现实。
它的好处是:
• 少配置
• 少重新登录
• 少额外保存凭证
但它的边界也很清楚:
• 你依赖浏览器环境
• 你依赖页面当前登录态
• 你依赖扩展和 daemon 的连通性
所以它不是“零前提”,而是“把前提换成了浏览器会话复用”。
第二层:5 级认证策略
这个项目另一个很聪明的地方,是它没有把所有网站都当成同一类目标。
在 SKILL.md 里,它把认证和接入策略直接分成了 5 层:
1. public:无认证,直接调公开接口
2. cookie:走浏览器 credentials: include
3. header:需要额外头,比如 CSRF / Bearer
4. intercept:通过 XHR 拦截和 store mutation 取数据
5. ui:实在不行,再走点击、输入、滚动这类 UI 自动化
这个分层我觉得非常重要。
因为它说明 OpenCLI 不是在赌“一个方法搞定所有站点”,而是在做一套现实世界里的策略升级路径:
• 最简单的先走公开 API
• 再走 Cookie
• 再走 Header
• 再走拦截
• 最后才退回 UI 自动化
这个思路很工程化,也很适合 AI Agent。

OpenCLI README 内置命令节选
它不只是能用,还在努力降低“做一个新适配器”的门槛
如果一个项目只靠作者自己加平台,扩展性很快就会撞墙。
OpenCLI 明显也意识到了这一点,所以它在“怎么加一个新命令”这件事上,做了两层设计。
1. YAML 管道
适合比较规则、比较直接的场景。
文档里给的模板就很清晰:
• navigate
• evaluate
• select
• map
• filter
• sort
• limit
这意味着很多简单的网站命令,不需要写太多代码,直接靠声明式 pipeline 就能拼出来。
2. TypeScript 适配器
如果场景更复杂,就退回到 TS。
比如:
• XHR 拦截
• 无限滚动
• Cookie 抽取
• GraphQL 数据结构解包
这时候就可以用 TS adapter 去写更底层的逻辑。
也就是说,它不是只给你一个黑盒命令集合,而是在给你一个:
从简单适配到复杂适配都能覆盖的 adapter 系统。
这里还有一个很适合传播的点:CLI-ONESHOT
我觉得这个仓库很容易传播,还有一个原因:
它不是只讲“架构”,也在讲“怎么最快做出一个命令”。
CLI-ONESHOT.md 里给的思路非常直接:
给一个 URL + 一句话描述,4 步生成一个 CLI 命令。
这 4 步其实非常像一条面向 AI 的开发流程:
1. 打开页面并抓 JSON 请求
2. 锁定目标 API
3. 验证接口能不能复现
4. 选 YAML 或 TS 模板生成 adapter
这很像是把“给网页做自动化适配”这件事,拆成了一条足够短、足够能复制的流水线。
这就是它容易让开发者产生兴趣的地方:
不是因为它功能最多,而是因为它一直在问:
怎么让一个新工具更快进入系统。
如果你今天想快速体验,我建议就走这 5 步
如果你看完这篇文章,想马上试一下 OpenCLI,我建议顺序非常简单:

OpenCLI README 快速开始节选
第一步
先装:
npm install -g @jackwener/opencli
第二步
去装 Browser Bridge 扩展。
最省事的方式是:
• 下载 release 里的 opencli-extension.zip
• 在 Chrome 扩展页开启开发者模式
• 选择“加载已解压的扩展程序”
第三步
先跑诊断:
opencli doctor
这一步会帮你确认:
• 扩展是不是连上了
• daemon 是不是正常
• 浏览器侧通信是不是通了
第四步
先看它到底已经接了哪些工具:
opencli list
这一步很重要,因为它能让你立刻理解 OpenCLI 的思路不是“硬记命令”,而是先发现工具,再决定调用什么。
第五步
再分别试一条公开命令和一条依赖登录态的命令,比如:
opencli hackernews top --limit 5
opencli zhihu hot -f json
opencli bilibili hot --limit 5
如果这一步能正常出结果,你对这个项目的感觉会立刻从“概念很炫”变成“它真的能干活”。
它适合谁,不适合谁
我觉得 OpenCLI 最适合三类人:
1. 想给 AI Agent 接更多工具的人
如果你已经在做 Agent,OpenCLI 最有价值的地方就是:
它不是再给你一个模型,而是在给你一层更统一的工具入口。
2. 想把常用网站和桌面应用纳入自动化流的人
尤其是那些本来就习惯:
• 用浏览器完成工作
• 用桌面应用完成工作
• 又希望这些能力能进入 AI 工作流
的人,会对这个项目特别有感觉。
3. 想做平台适配和工具封装的人
如果你本来就在做某种“网页能力接入”“Agent 工具化”“桌面应用自动化”,OpenCLI 的适配器系统会很有参考价值。
但它也不是没有边界。
不适合谁
如果你想要的是:
• 完全不依赖浏览器环境
• 所有平台都稳定像官方 API 一样
• 不需要登录态、不需要页面适配、不需要扩展
那 OpenCLI 并不是这种项目。
它更像一个现实世界里的“统一适配层”,而不是一个魔法抽象层。
最后
如果你让我用一句话总结 jackwener/opencli,我会这么说:
它真正有意思的,不是又收了一批网站命令,而是在尝试给 AI Agent 做一层统一的工具命令面。
网站也好,Electron 应用也好,本地 CLI 也好,它都想把它们往一个方向压:
让 AI 能先发现,再理解,再调用。
如果这个方向走通,OpenCLI 的价值就不只是“命令多”,而是它可能会成为很多 AI 工作流里真正实用的一层工具底座。
参考信息
本文主要基于 2026 年 3 月 24 日可公开访问的仓库资料整理,包括:
• README.md
• README.zh-CN.md
• SKILL.md
• CLI-ONESHOT.md
• package.json
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号