ClawTeam:让 Claude Code、Codex、OpenClaw 不再单兵作战

ClawTeam:让 Claude Code、Codex、OpenClaw 不再单兵作战

阿特拉斯
发布于 2026-06-15 17:46:53
发布于 2026-06-15 17:46:53
如果你已经在用 Claude Code、Codex、OpenClaw 这类 CLI Agent,应该很快就会碰到一个共同问题:
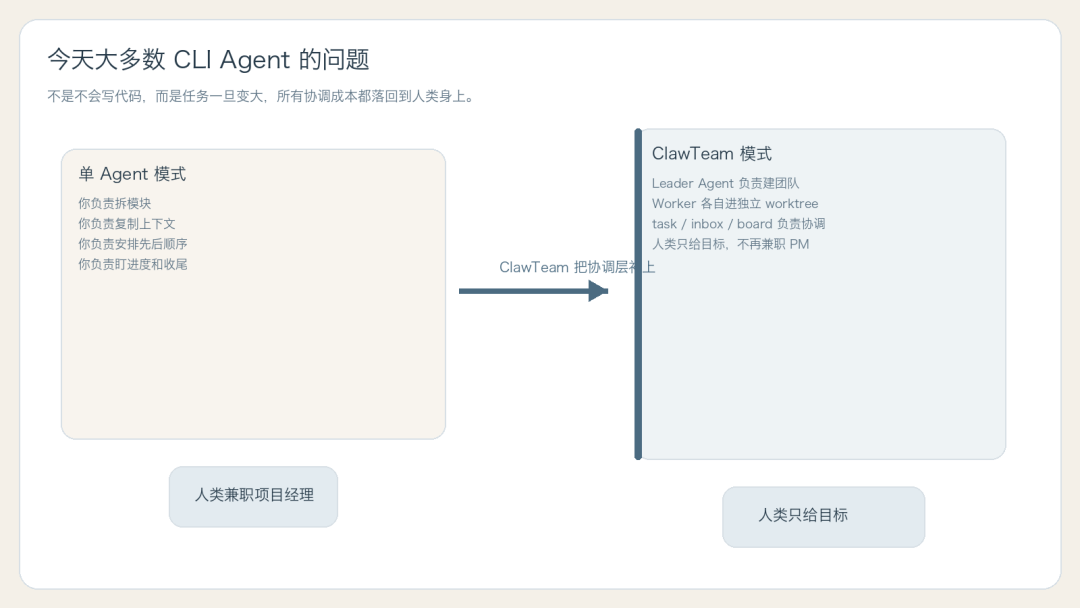
不是模型不会写,而是任务一旦变大,单个 Agent 就开始吃力。
你得自己拆模块、自己安排顺序、自己盯进度、自己合并结果。 所谓“多 Agent 协作”,很多时候其实只是人类自己兼职当项目经理。
最近我认真看了 HKUDS/ClawTeam 这个仓库,觉得它最值得注意的地方,不是它又做了一个“多智能体框架”,而是它试图把这件事压回到 CLI 层:
让一个 Leader Agent 直接通过命令行,去创建团队、分配任务、收消息、盯进度、再把结果合回去。
换句话说,ClawTeam 想做的不是“让 Agent 更聪明”,而是“让 Agent 开始像团队一样工作”。
ClawTeam 把单 Agent 变成团队协同
它到底是什么
先把定位说清楚。
从 pyproject.toml 来看,ClawTeam 把自己定义成一个 framework-agnostic multi-agent coordination CLI。
它不是新的基础模型,不是新的云平台,也不是只服务某一家 Agent 的专用壳子。
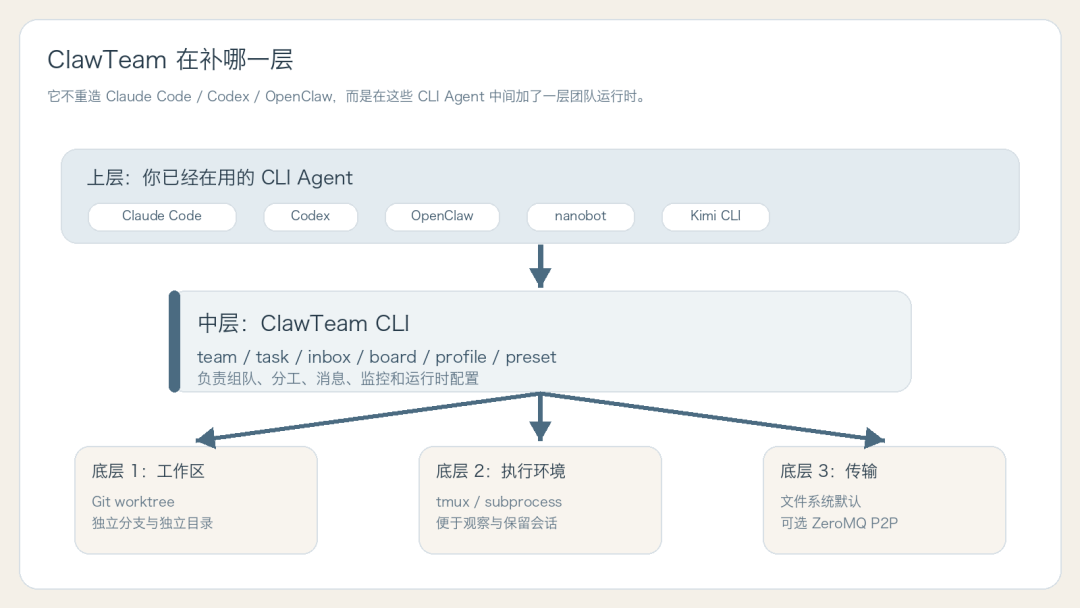
它更像一层团队运行时。
默认情况下,它的数据放在 ~/.clawteam/,默认传输层是文件系统;如果你需要更强的通信能力,再往上加可选的 P2P 传输。
它的结构大致是:
• 上面接 Claude Code、Codex、OpenClaw、nanobot、Kimi CLI 这类已经存在的 CLI Agent
• 中间用 clawteam 这套命令做团队管理
• 底下用文件系统、Git worktree、tmux,以及可选的 ZeroMQ P2P 来承接协作
这个定位很关键。
因为你看很多多 Agent 项目,最后其实是在要求人类重新学一整套 orchestration framework。 而 ClawTeam 的思路是:你已经有能用的 Agent CLI 了,那就别重造 Agent,本质上补的是“协同层”。
ClawTeam 的协同层结构
这套协同层,补了哪几件事
我觉得它最核心的是四层能力。
第一层:团队和任务
从 clawteam/cli/commands.py 和 README 可以看出,它已经把团队管理拆成了比较完整的一组命令:
• team spawn-team
• task create / update / list / wait
• inbox send / receive / peek
• board show / live / attach / serve
也就是说,它不是只有一个“spawn worker”演示命令。 它其实已经把多 Agent 协作里最容易散掉的几件事单独做成了结构化命令:
• 团队是谁
• 谁是 leader,谁是 worker
• 任务在谁手里
• 哪些任务被依赖阻塞
• 谁给谁发过消息
• 现在整个团队在干什么
这也是它比“开几个终端窗口同时跑 Agent”更像产品的地方。
第二层:工作区隔离
ClawTeam 特别强调的一点,是每个 Worker 都可以拿到独立的 Git Worktree 和 tmux 会话。
这件事听起来很工程化,但其实非常重要。
因为多 Agent 一旦真的开始并行写代码,最大的风险不是“它们不够聪明”,而是:
• 改到同一份文件
• 互相覆盖进度
• 上下文串线
• 最后根本不知道哪个结果是谁做出来的
Git worktree 的好处在于,它不是模拟隔离,而是真正给你一份独立分支和独立工作目录。 这比很多只停留在“逻辑上分工”的多 Agent 方案更扎实。
第三层:通信和看板
ClawTeam 里有两条很实用的线:
• 一条是 inbox
• 一条是 board
inbox 本质上就是 Agent 之间的收件箱。
Leader 可以发消息,Worker 可以汇报结果,也可以广播。
board 则负责把团队状态摊开来看:
• board show 看终端看板
• board live 自动刷新
• board attach 直接进 tmux 平铺视图
• board serve 启一个 Web UI
这意味着它不是只管“启动 Agent”,而是把“看着团队运转”也考虑进去了。
第四层:运行时配置
这一层很多人第一次看 README 会忽略,但我觉得它其实很实用。
ClawTeam 里有:
• preset
• profile
• profile wizard
• profile doctor
• profile test
这套东西的意思是,它开始认真处理一个现实问题:
同样是 Claude Code,你可能走默认 provider; 也可能走 Moonshot、MiniMax、Vertex 之类的 provider-aware 路线。
如果每次 spawn 都靠人手工拼环境变量,团队规模一上来就会很乱。 所以它把“运行时配置”单独做成 profile/preset,这点是对的。

ClawTeam 最值得看的四层能力
为什么它值得现在看
我觉得 ClawTeam 最值得看的,不是 README 里那些很燃的口号,而是它抓住了 CLI Agent 现在最真实的痛点。
今天很多人已经不缺单个 Agent 了。
你可能已经有:
• Claude Code
• Codex
• OpenClaw
• nanobot
• 甚至自己封装过的一些脚本式 Agent
真正缺的是一层稳定的组织方式。
你想让它们协同,但又不想立刻上 Docker、消息队列、数据库、复杂编排平台。 ClawTeam 现在这套路线,本质上是在试一个更轻的答案:
先用文件系统、tmux、Git worktree,把团队协作跑起来。
这个方向很像多 Agent 世界里的“Unix 哲学”:
• 尽量复用已有 CLI
• 尽量复用已有 Git 工作流
• 尽量少引入重基础设施
• 先把协作闭环做出来
如果你想自己试,最快怎么上手
这部分我觉得比“概念介绍”更重要。
README 给出的最小前提其实很直接:
• Python 3.10+
• tmux
• 你想驱动的 agent CLI 本机本来就能跑
先安装:
pip install clawteam
如果你想试 P2P 传输,可以从源码装可选依赖:
git clone https://github.com/HKUDS/ClawTeam.git
cd ClawTeam
pip install -e ".[p2p]"
然后先不要急着组团队,先做最小环境检查:
tmux -V
clawteam --help
claude --version
codex --version
nanobot --help
这里有一个非常现实的边界:
如果你的 Agent CLI 自己都跑不起来,ClawTeam 不会替你把它“魔法修好”。 它补的是协同层,不是安装修复层。
两种使用方式
README 里把使用方式拆得很清楚,我觉得这点写得不错。
方式一:让 Agent 自己调用 ClawTeam
仓库里自带了 skills/clawteam/SKILL.md。
也就是说,它不是只提供一堆命令,还提供了给 Claude Code / Codex 接进去的 skill。
对 Codex 来说,大致是把这个 skill 放进:
~/.codex/skills/clawteam
然后你直接对 Agent 说:
用 $clawteam 把这个任务拆成多 Agent 团队,协调执行直到完成。
这条路线的重点不是“人类手工打一串命令”,而是让 Leader Agent 自己开始调用:
• clawteam team spawn-team
• clawteam spawn
• clawteam task create
• clawteam board show
如果这条路真的跑顺,它的意义会比“手工演示多 Agent”大很多。
方式二:你手动操作
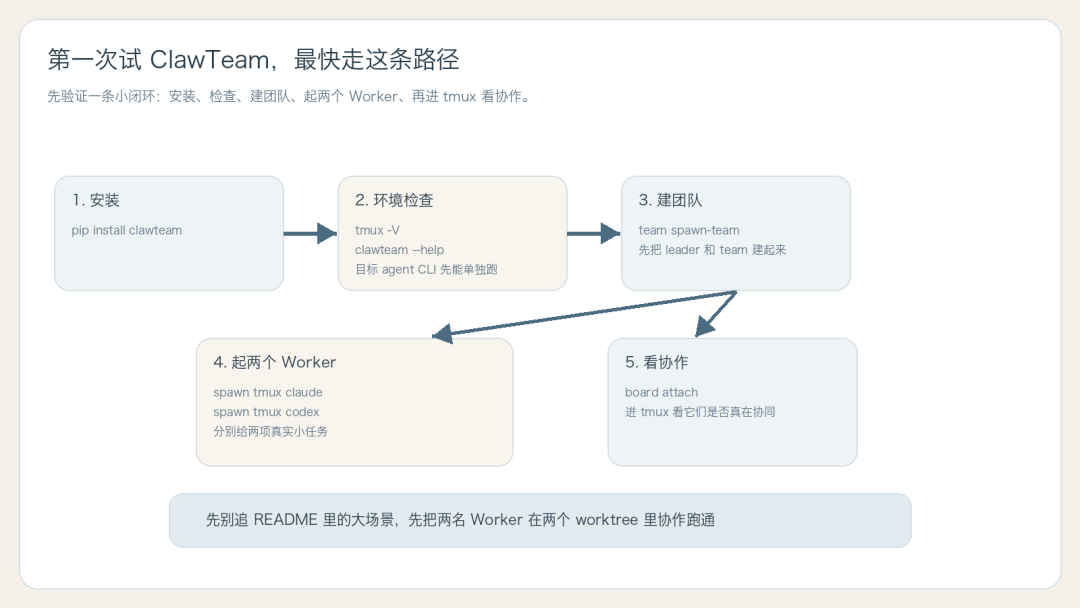
如果你想先验证基本闭环,也可以先手工跑:
clawteam team spawn-team my-team -d "构建认证模块" -n leader
clawteam spawn tmux claude --team my-team --agent-name alice --task "实现 OAuth2 流程"
clawteam spawn tmux codex --team my-team --agent-name bob --task "编写认证单元测试"
clawteam board attach my-team
这样你至少能先看到三件事:
1. 团队能不能建起来
2. Worker 能不能真正被拉起
3. 看板和 tmux 视图能不能反映协作状态
对第一次试的人来说,这条路更稳。
第一次试 ClawTeam 的最短验证路径
它最适合哪几类任务
按 README 当前给的场景,我觉得可以分成三类理解。
第一类:可并行的工程任务
比如:
• API
• 前端
• 数据库
• 测试
这种天然可以拆成多个职责域的任务,最适合它。
因为这类任务的价值,不在“谁写得更聪明”,而在于:
• 能不能拆开
• 能不能并行
• 能不能少打架
• 能不能最后收回来
ClawTeam 的 team/task/worktree/board 组合,正好就是为这类任务准备的。
第二类:研究型实验
README 里最吸睛的是 autoresearch 那段:
• 8 Agent
• 8 H100
• 2430+ 实验
• val_bpb 1.044 -> 0.977
这个例子当然非常强,但我觉得更值得看的不是数字,而是它表达的调度逻辑:
• Leader 读协议
• 分配不同搜索方向
• 定期读取结果
• 把好的发现传播给新 Worker
• 清理空闲 Agent,重新分配资源
这个思路本身是有价值的。 它说明 ClawTeam 想承接的不只是“多人并行写代码”,还包括更开放的实验型工作流。
第三类:固定角色团队
像 README 里的 AI 对冲基金模板,本质上是第三类场景:
不是围绕一个软件模块拆任务,而是围绕一个固定问题,让不同角色给出不同视角,再由 Leader 收敛。
这种模式适合:
• 投研
• 内容生产
• 商业分析
• 调研型任务
仓库把这部分放进了 TOML 模板和 launch 体系里,这比只讲抽象“多 Agent 协同”更可用。
但我觉得它现在最需要警惕的,也有三点
这部分也得说清楚,不然文章会写飘。
第一,它还是 Alpha 项目
pyproject.toml 里明确标的是:
Development Status :: 3 - Alpha
所以它现在更适合:
• 尝鲜
• 做原型
• 做研究型验证
• 给自己的 Agent 工作流补协作层
还不适合把它直接想象成“稳定生产级平台”。
而且从 ROADMAP.md 也能看出来,它现在的默认心智模型仍然是:
• 单机优先
• 文件系统优先
• CLI 优先
这并不是缺点,但意味着你第一次使用它时,最好把期待放在“把本机上的多 Agent 协作跑顺”,而不是直接把它当成完整的分布式多机调度平台。
第二,很多高光场景本身带有演示成分
比如:
• 8 H100 的 autoresearch
• 7 Agent 的 hedge fund
• 全栈团队自动合并
这些场景的方向都对,但你第一次接触这个仓库时,最好先把它理解成:
这是项目给你展示“这套协调层想承接到哪里”。
真正适合你第一天验证的,不是这些大场景,而是更朴素的一条链路:
• 建团队
• 起两个 Worker
• 看任务板
• 发消息
• 进 tmux 看协作
第三,它不是“替你解决 agent 兼容性”的万能层
README 已经说得很明白:
如果你接入别的 Agent,至少要满足:
1. 命令在 PATH 里能找到
2. 能在指定工作目录或 worktree 里运行
3. 能接收初始任务
4. 如果是交互式 Agent,启动后不能立刻退出
这意味着它的前提其实挺硬核:
你得先有一批“本来就能工作的 CLI Agent”,ClawTeam 才有东西可调度。
我对这个仓库的真实判断
如果只看一句话,我会这么概括:
ClawTeam 值得看,不是因为它已经把多 Agent 世界做完了,而是因为它把“CLI Agent 团队化”这件事做得足够具体。
它具体到:
• 有真实的命令分组
• 有真实的工作区隔离
• 有真实的消息和任务板
• 有真实的 profile / preset 运行时配置
• 还有接 Claude Code / Codex 的 skill 入口
这比很多停留在“概念编排图”的多 Agent 项目更有含金量。
如果你现在正好在用:
• Claude Code
• Codex
• OpenClaw
• 其他 CLI Agent
并且已经感受到“单 Agent 到大任务时开始吃力”,那 ClawTeam 是一个很值得试的方向。
但更准确的试法不是一上来就盯着它的宏大 demo,而是先问自己一句:
我能不能先让两个 Agent 在两个 worktree 里,把一件真实的小任务协同跑通?
如果这一步能跑通,这个项目就已经证明它有价值了。
仓库信息
• 仓库名:HKUDS/ClawTeam
• GitHub:直接搜索 HKUDS ClawTeam
• 截至 2026 年 3 月 26 日,仓库约有 3.7k Stars、511 Forks
• 最新正式 release:v0.2.0,发布时间为 2026 年 3 月 23 日
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号