2025洞察与建议 (二)2025年人工智能指数报告 -1 研究与开发

2025洞察与建议 (二)2025年人工智能指数报告 -1 研究与开发

独角兽老头
发布于 2026-06-17 19:29:47
发布于 2026-06-17 19:29:47
对于人工智能来说,2024 年是多么美好的一年。诺贝尔物理学奖和化学奖,以及因强化学习方面的奠基性工作而获得的图灵奖,都体现了人们对人工智能在推动人类知识进步方面所起作用的认可。曾经令人望而生畏的图灵测试已不再被视为一个雄心勃勃的目标,今天的精尖系统已经超越了它。与此同时,人工智能的应用正以前所未有的速度渗透社会生活,数以百万计的人们在专业工作和休闲活动中高频使用人工智能。随着高性能、低成本和开源模型的普及,人工智能的可及性和影响力必将进一步扩大。在经历了短暂的放缓之后,企业对人工智能的投资出现反弹。生成式人工智能初创企业融资案例数量增加了近三倍。商业应用在经过多年的低迷后于 2024 年迎来显著增长。人工智能已从边缘领域成为业务价值的核心驱动力。各国政府也在加大参与力度。政策制定者们不再停留于讨论人工智能,他们正在对其进行投资。一些国家启动了价值数十亿美元体量的国家人工智能基础设施计划,包括能源扩容以支持人工智能发展的重大努力。全球协作机制日益完善,地方性措施也同步成型。
《2025年人工智能指数报告》,是第八版指数报告。项目发起于 2017 年,作为 “人工智能百年研究(One Hundred Year Study of Artificial Intelligence)” 项目分支,人工智能指数报告一直致力于为政策制定者、新闻工作者、高管、研究人员和公众提供准确、经过严格验证和全球来源的数据。使命始终如一:帮助这些利益相关方就人工智能的发展和部署做出更明智的决策。在这个从会议室到厨房餐桌到处都在讨论人工智能的世界里,这一使命显得尤为重要。作为全球公认的人工智能领域权威资源之一,人工智能指数报告被《纽约时报》、彭博社和《卫报》等主要媒体引用,成为数百篇学术论文的文献参考,并服务于世界各地的政策制定者和政府机构。我们已经向埃森哲、IBM、富国银行和富达等公司提供了人工智能现状的简报,并将继续为全球人工智能生态系统输送独立见解。
2025年6月

图片

研究与开发
人工智能研究与发展的最新趋势,首先系统分析人工智能论文发表、专利及标志性的人工智能系统,并基于国家和地区、研发机构与行业领域三维度对上述成果的开发方进行解析。涵盖了对人工智能模型训练成本、学术会议参与度及开源人工智能软件的分析。今年新增的内容包括人工智能硬件生态演进图谱、人工智能训练能耗与环境影响评估及模型推理成本时序分析。

论文发表情况
2013 年至 2023 年间,人工智能相关论文发表的总数翻了一番多,从 2013 年的约 10.2 万篇增至 2023 年的超过 24.2万篇。过去一年间的增长率达 19.7%,这一增幅具有重要意义。计算机科学的众多领域——从硬件与软件工程到人机交互——如今均对人工智能的发展都有所贡献。因此,观测到的增长现象反映出该人工智能更广泛且日益增强的关注度。
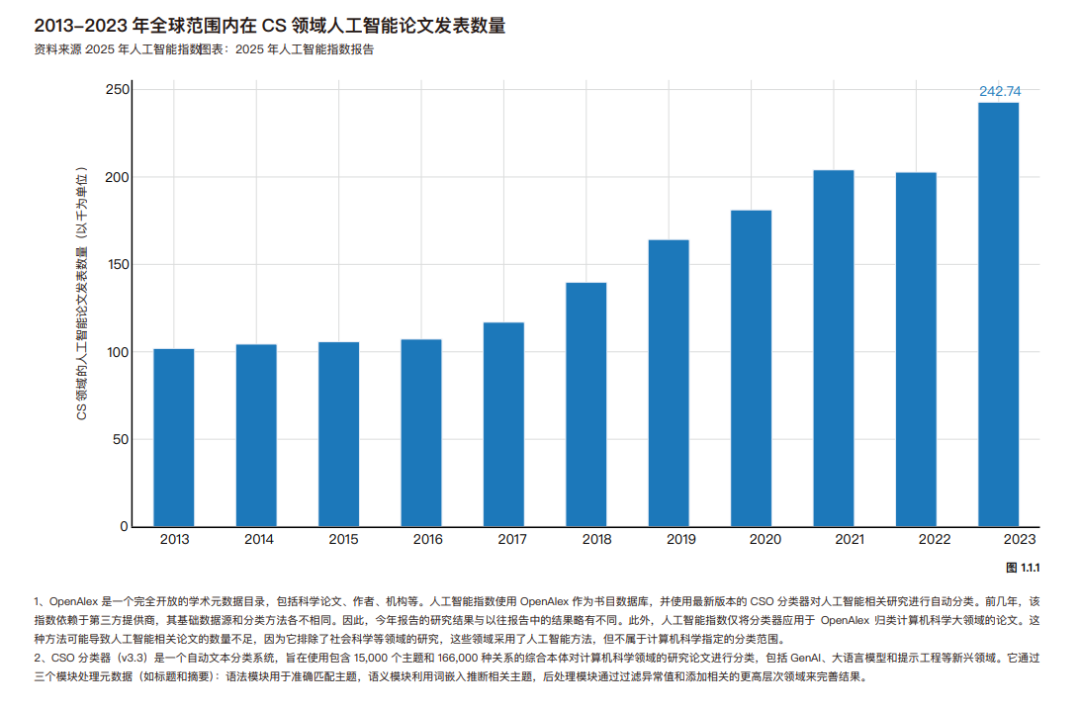
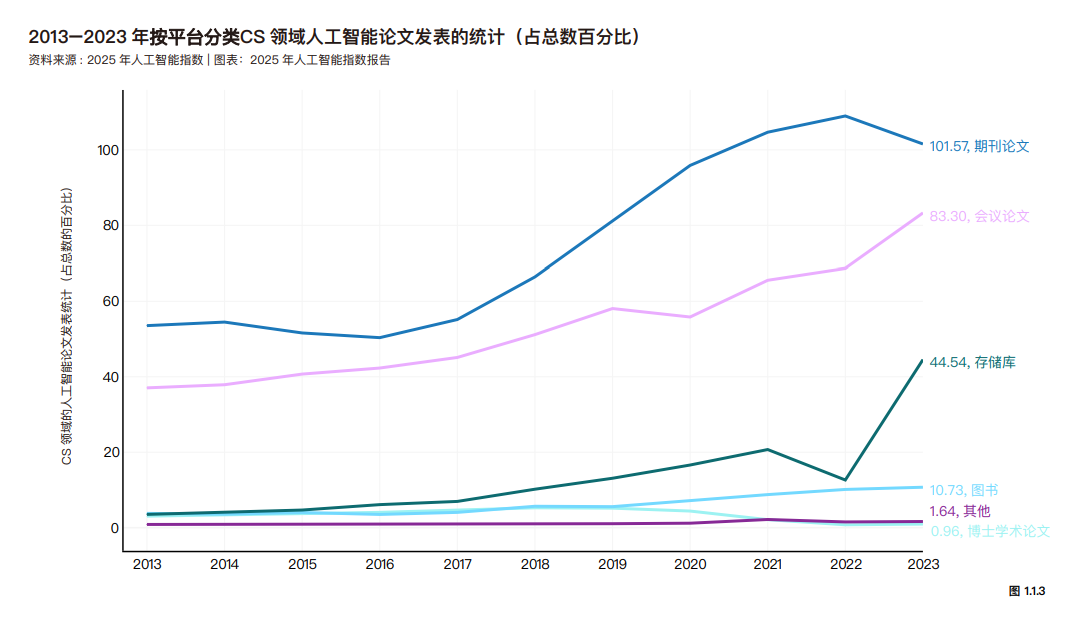
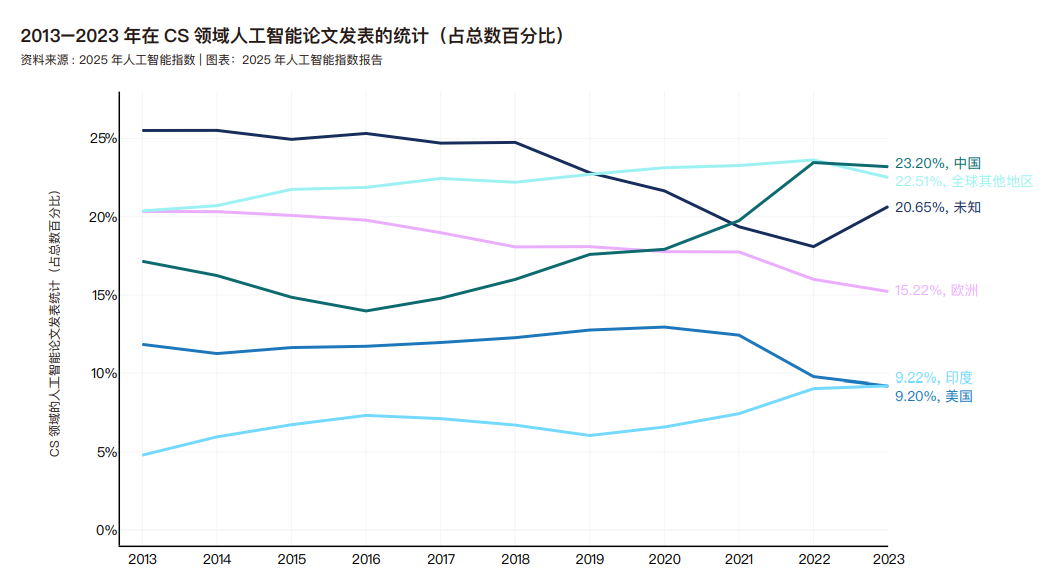
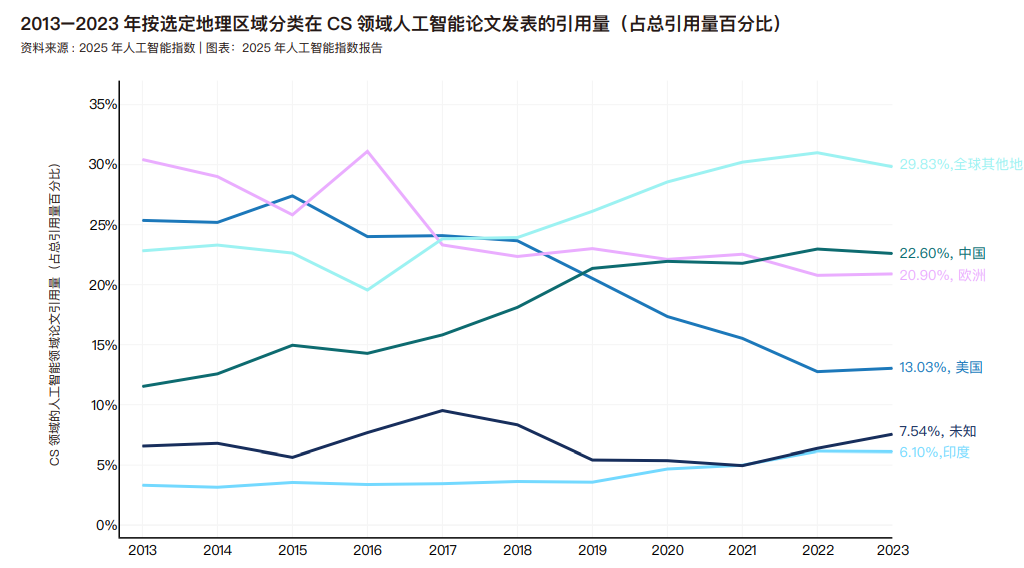
2023 年,中国在人工智能论文发表数量上居全球首位,占比达 23.2%,而欧洲和印度的占比分别为 15.2% 和 9.2%。 自 2016 年以来,中国的份额持续稳步增长,而欧洲的占比则呈现下降趋势。美国在人工智能领域的论文发表比例在 2021 年前保持相对稳定,但此后略有下降。 2023 年,中国人工智能论文的引用量占比达 22.6%,位居全球首位,欧洲和美国分别以 20.9% 和 13.0% 的占比紧随其后。与论文发表总量趋势一致,2010 年代末成为关键转折点——中国在这一时期超越欧美,成为人工智能领域被引用文献的首要来源地。 在 2023 年,东亚和太平洋地区在人工智能研究产出方面领先,占所有人工智能论文发表的 34.5%,其次是欧洲和中亚以及北美摸索。
虽然追踪人工智能论文总量能提供一个对人工智能研究活动的宏观视角,但聚焦于被引用次数最多的论文则能揭示该领域最具影响力的研究成果。这项分析揭示了一些最具开创性和影响力的人工智能研究正在哪里兴起。今年,人工智能指数通过 OpenAlex 的引文数据,确定了 2021 年、2022 年和2023 年被引用次数最多的 100 篇人工智能论文。2023 年被引用次数最多的人工智能论文包括 OpenAI 的 GPT-4 技术报告、Meta 的 Llama 2 技术报告和谷歌的 PaLM-E 的技术报告。值得注意的是,由于引用的滞后性,今年报告中被引用次数最多的论文在今后的版本中可能会有所变化。
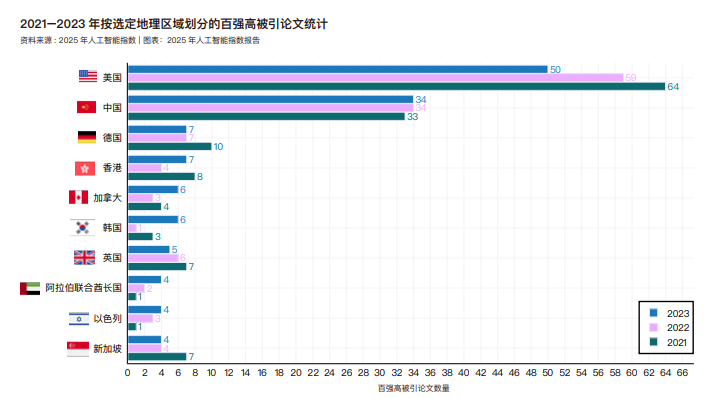
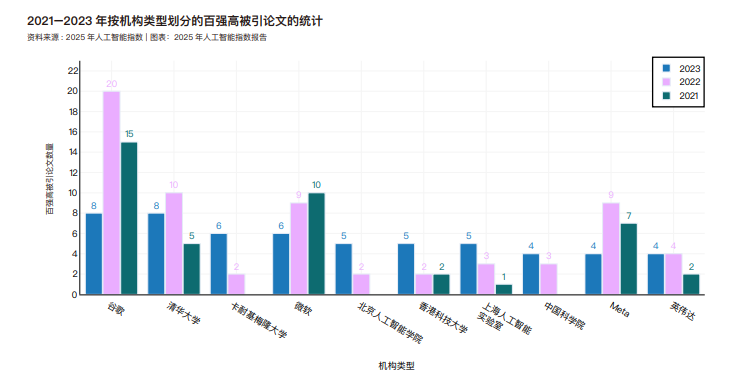
2021 至 2023 年间全球人工智能领域高被引百强论文来源机构分布情况。部分机构在图表中可能出现空白柱,这表明该机构在某年未发表百强论文。仅列出了排名前 10 的机构,尽管许多其他机构也做出了重要贡献。 谷歌每年均位居榜首,但在 2023 年与清华大学并列第一,两者均有 8 篇论文入选百强。2023 年,卡内基梅隆大学是排名最高的美国学术机构。

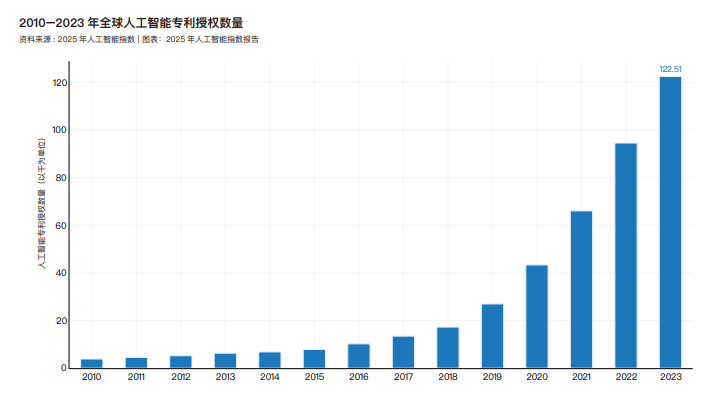
专利
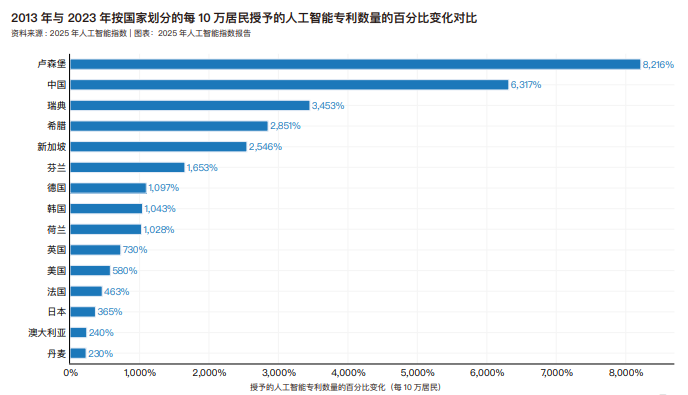
2010 年至 2023 年全球人工智能专利的增长情况。在过去十几年中,人工智能专利数量稳步大幅增长,从 2010 年的 3833 项增至 2023年的 122511 项。去年,人工智能专利总量增长了 29.6%。
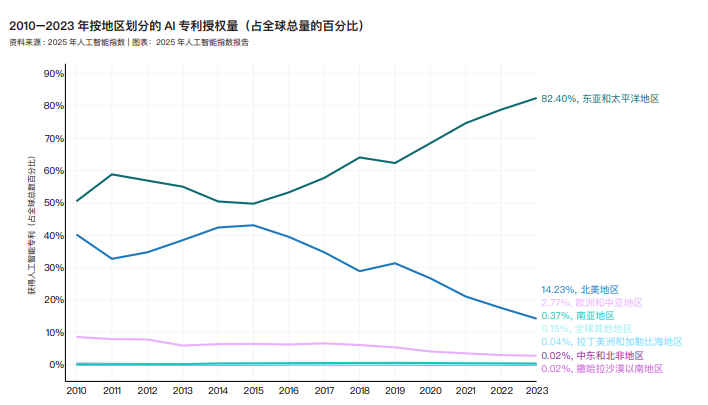
截至 2023 年,全球获授权的人工智能专利中,绝大多数(82.4%)来自东亚和太平洋地区,北美地区以 14.2% 的占比位列第二。自 2010 年以来,东亚和太平洋地区与北美在人工智能专利授权方面的差距不断扩大。按地理区域细分,全球获批的人工智能专利中,绝大多数来自中国(69.7%)和美国(14.2%)。来自美国的人工智能专利占比已从 2015 年的峰值(42.8%)有所下降。

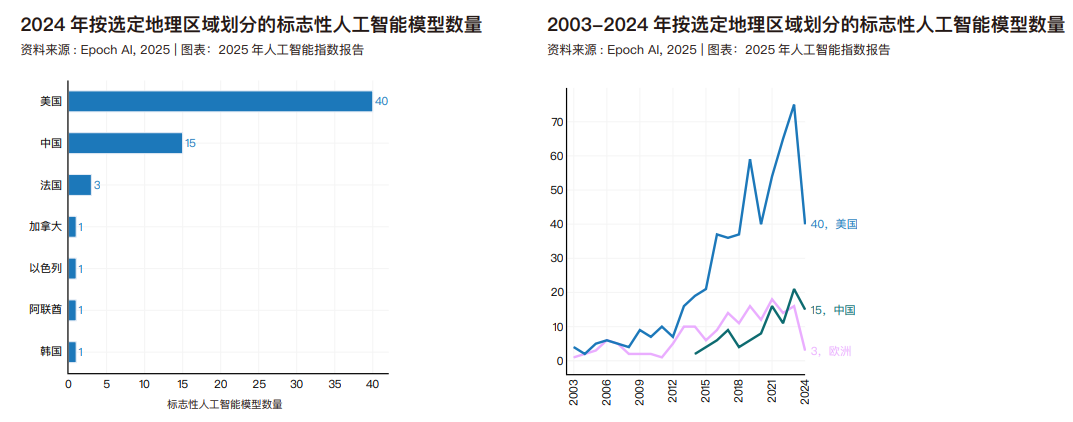
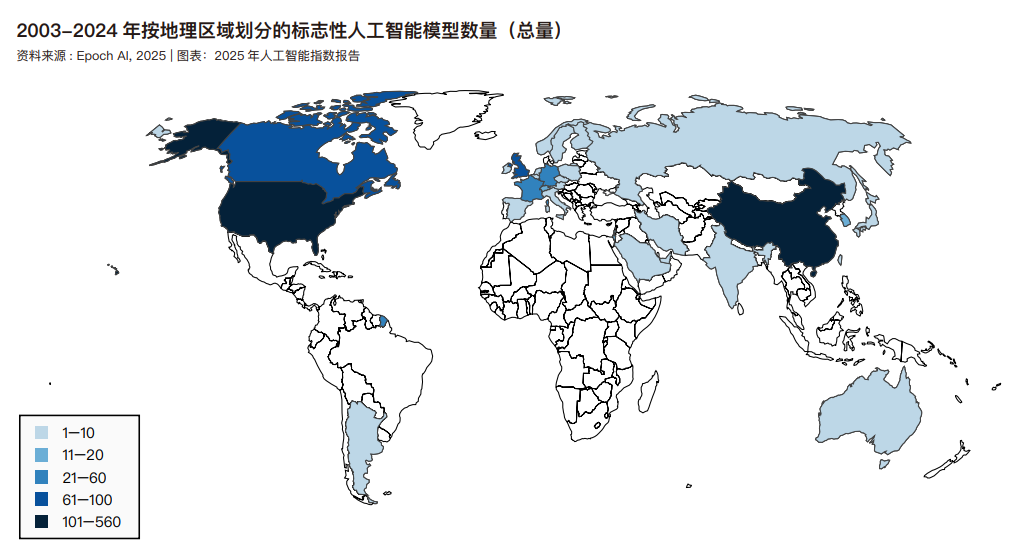
标志性人工智能模型
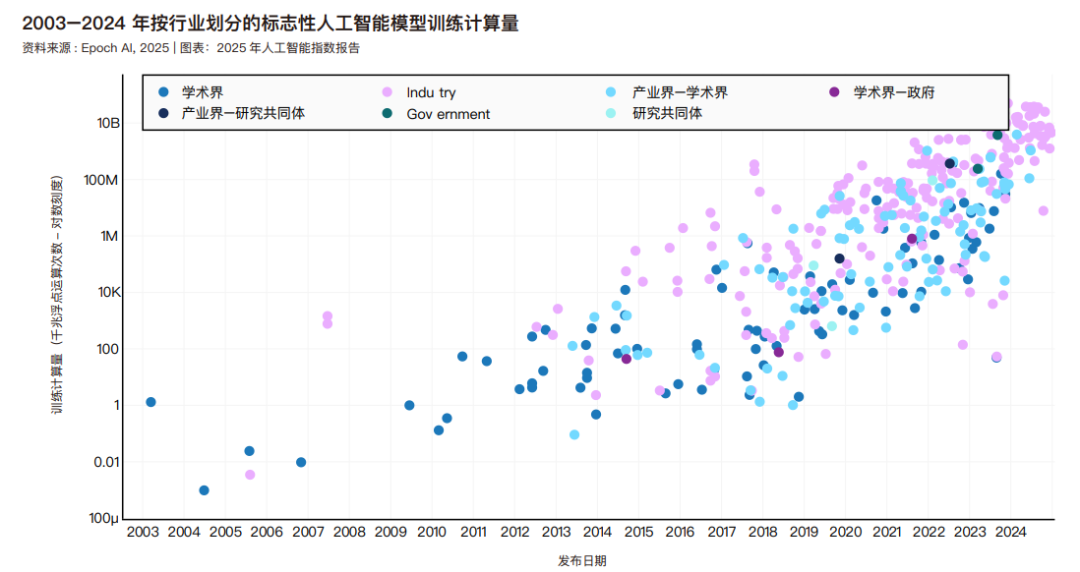
人工智能指数展示了标志性模型所属的国家。归因于研究人员所属机构所在地的标志性人工智能模型总数。16 2024 年,美国以 40 个标志性人工智能模型遥遥领先,中国以 15 个紧随其后,法国则有 3 个。2024 年全球主要经济体包括美国、中国和欧盟均报告说,2024 年发布的标志性模型少于上一年。自 2003 年以来,美国开发的模型数量超过了英国、中国和加拿大等其他主要国家。模型发布总量下降确切原因难以确定,但这可能源于多种因素的综合作用:训练数据规模的不断扩大、人工智能技术的日益复杂化,以及开发新建模方法所面临的挑战日益严峻。Epoch AI 当前收录的标志性模型可能遗漏了部分受关注度较低国家的发布成果。人工智能指数与 Epoch 合作致力于提高人工智能模型生态系统中的全球代表性。如果读者认为缺少了某些国家的模型,欢迎联系人工智能指数团队,我们将努力解决这个问题。
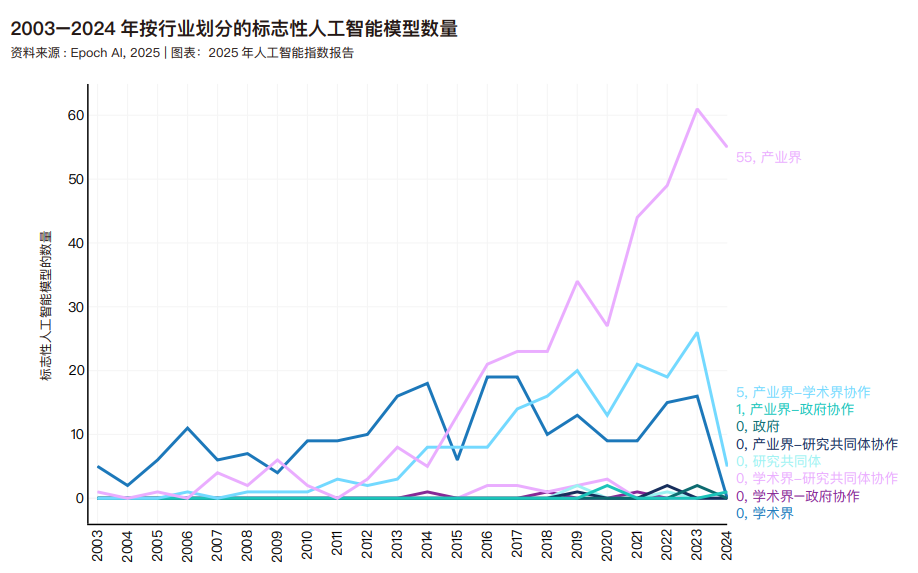
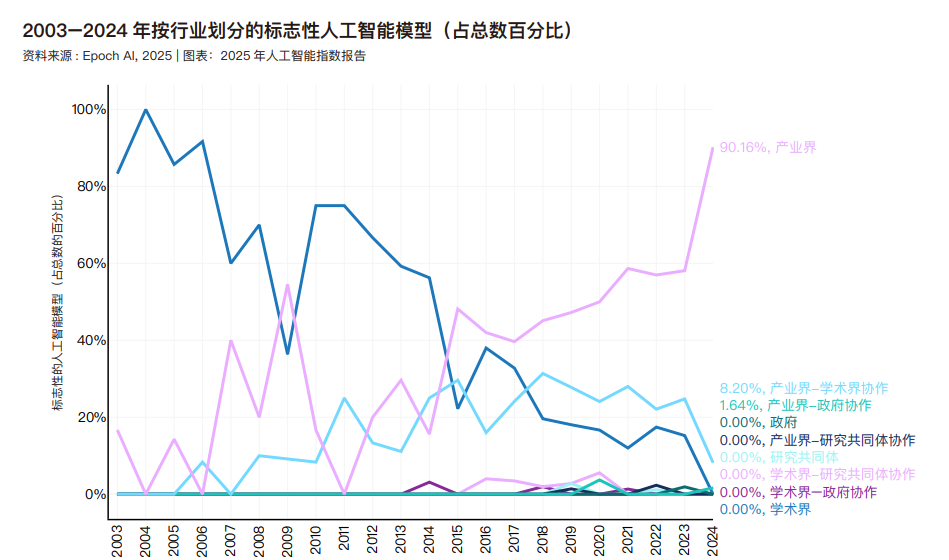
Epoch 根据来源对模型进行了分类:产业界包括谷歌、Meta 和 OpenAI 等公司;学术界包括清华大学、麻省理工学院和牛津大学等大学;政府指国家附属研究机构,如 英 国 的 Alan Turing Institute for AI 和 阿 布 扎 比 的Technology Innovation Institute;研究集体包括非营利性人工 智 能 研 究 组 织 Allen Insititute for AI 和 Fraunhofer Institute。2014 年之前,学术界在发布机器学习模型方面一直处于领先地位。自那以后,工业界开始领跑。根据 Epoch AI 的数据,在 2024 年,工业界将产生 55 个标志性人工智能模型。18 随着时间的推移,产学研合作推动的模型数量持续增长。过去十年间,来自产业界的知名人工智能模型占比稳步上升,至 2024 年已达到 90.2%。
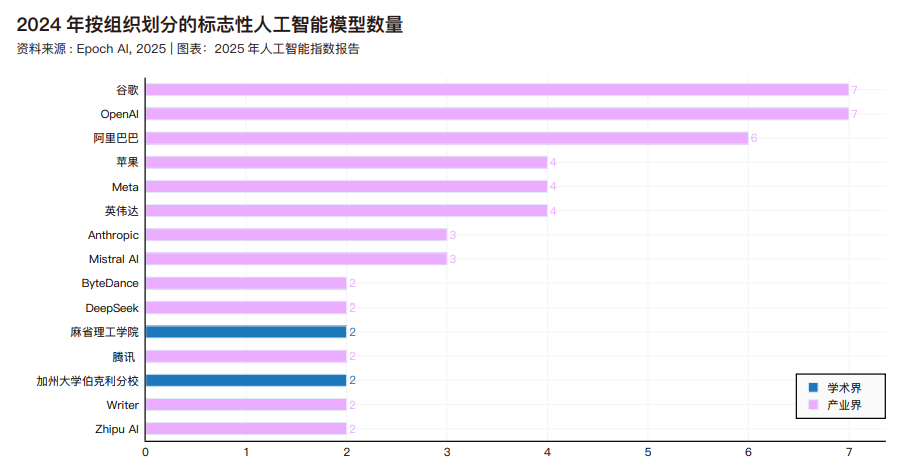
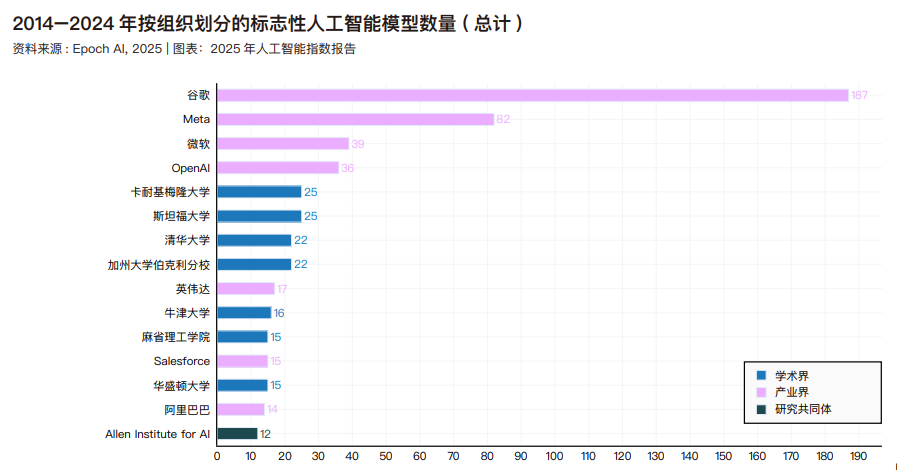
2024 年度及过去十年间,机器学习领域标志性模型研发的主导机构分布情况。2024 年,贡献最多的是谷歌(7 个)、OpenAI(7 个模型)和阿里巴巴(4个)。自 2014 年以来,谷歌以 187 个标志性模型遥遥领先,其次是 Meta(82个)和微软(39个)。在学术机构中,卡内基梅隆大学(25个)、斯坦福大学(25个)和清华大学(22个)自2014 年以来在标志性模型研发方面成果最多。
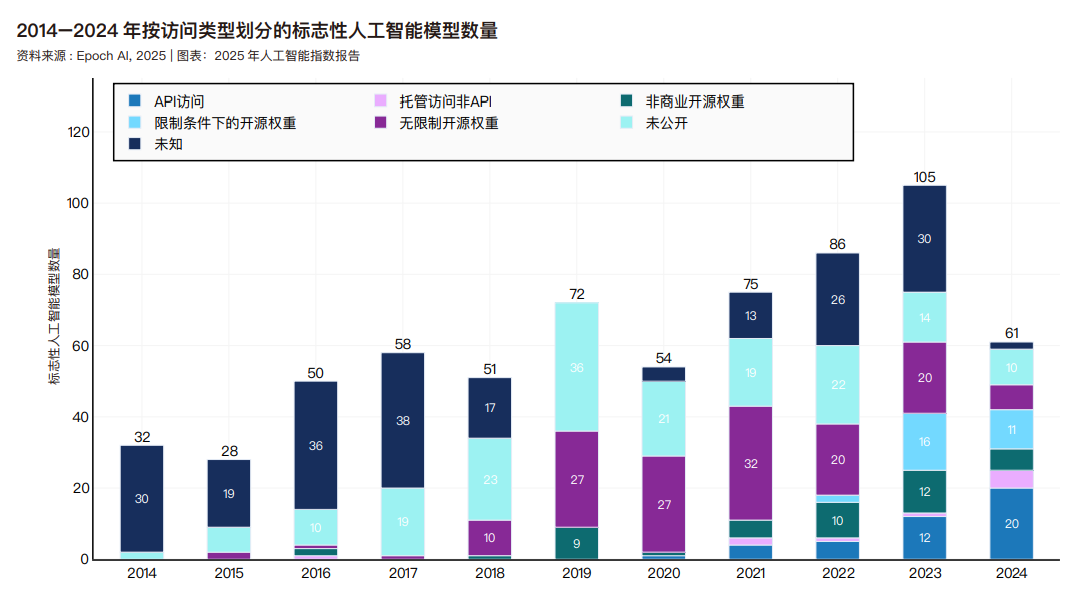
机器学习模型按照开放程度和使用权限可分为多种发布类型。API 访问模型,如 OpenAI 的 o1,允许用户通过查询与模型进行交互,而无需直接访问其底层权重。限制条件下的开源权重模型,如 DeepSeek 的 V3,提供对其权重的访问,但施加了一些限制,如禁止商业使用或二次分发。托管访问非 API 类模型,如 Gemini 2.0 Pro,指仅通过平台界面可用,不提供程序化调用接口的模型。无限制开源权重模型,如 AlphaGeometry,是完全开放的,允许自由使用、修改和再分发。非商业开源权重模型,如 Mistral Large 2,共享权重,但仅限于研究或非商业目的使用。最后,未发布模型,如 ESM3 98B,依然专有,只有其开发人员或选定的合作伙伴才能访问。未知指的是访问类型不明确或未公开的型号。 2024 年,API 访问是最常见的发布类型,61 个模型中有 20 个以这种方式提供,其次是限制使用的开源权重和未发布模型。

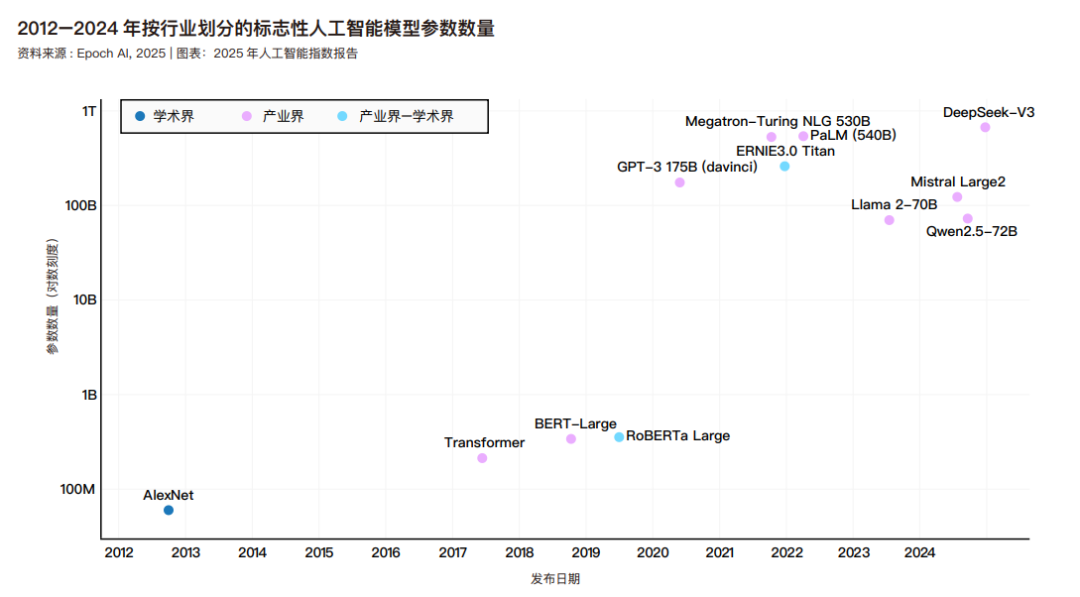
机器学习模型中的参数是在训练过程中学习到的数值,决定了模型如何解释输入数据和进行预测。参数较多的模型需要更多的数据来训练,但它们可以承担更多的任务,通常优于参数较少的模型。Epoch 数据库中机器学习模型的参数数量,并按模型来源的行业进行了分类。下图展示了相同的数据,但选取了较少的标志性模型。自 2010 年代初以来,模型参数量呈现急剧增长态势,这反映了以下关键因素:架构复杂度持续提升、训练数据日益丰富、硬件设施不断改进,以及大模型效能已获验证。高参数量模型在产业界表现尤为突出,这表现出企业机构具备雄厚资金实力,足以支撑海量数据训练所需的巨额计算成本。下列部分图表:采用对数刻度,以准确反映近年来人工智能模型参数量及计算需求的指数级增长态势。
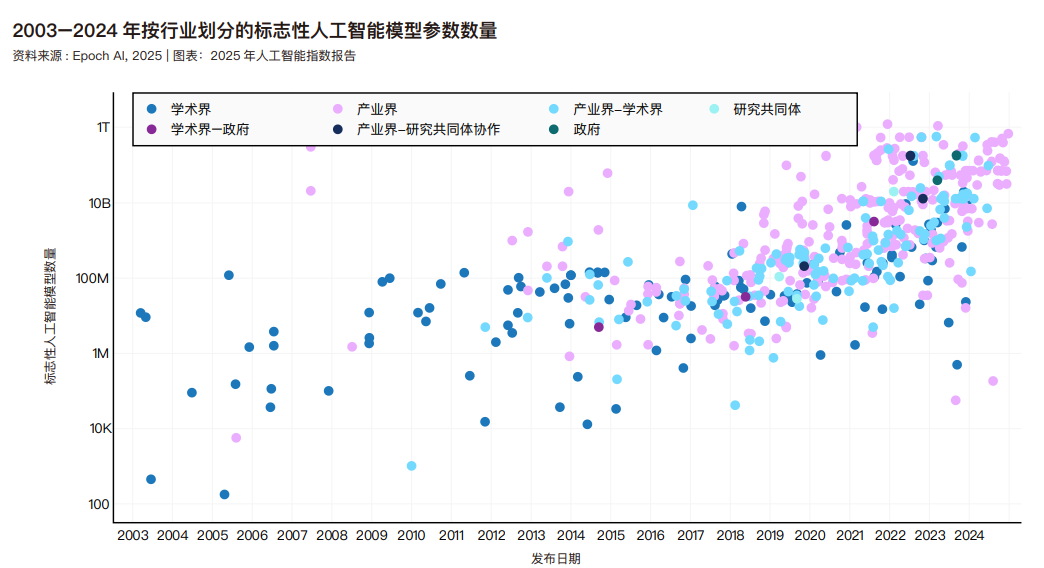
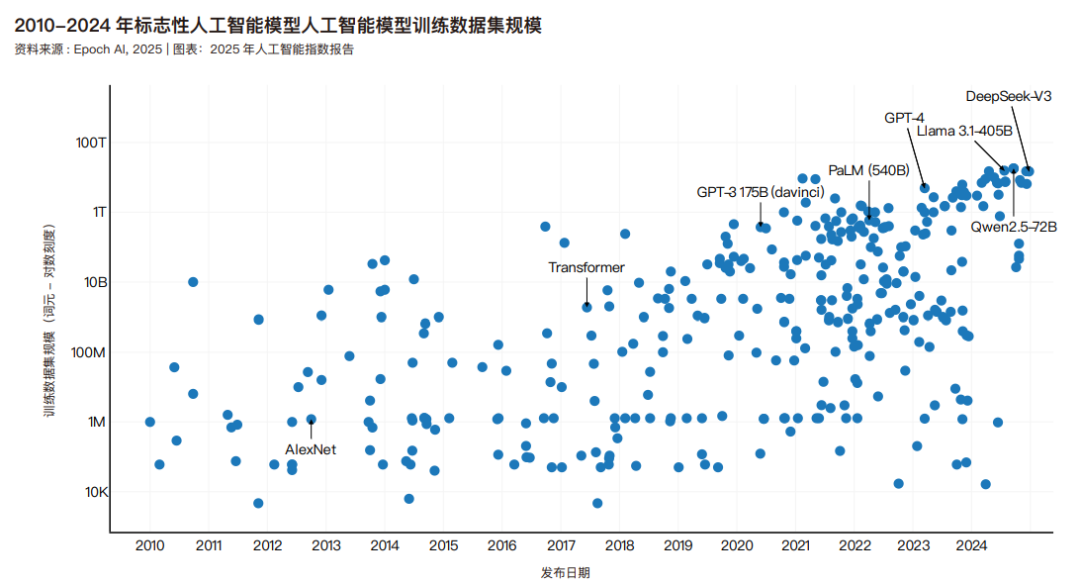
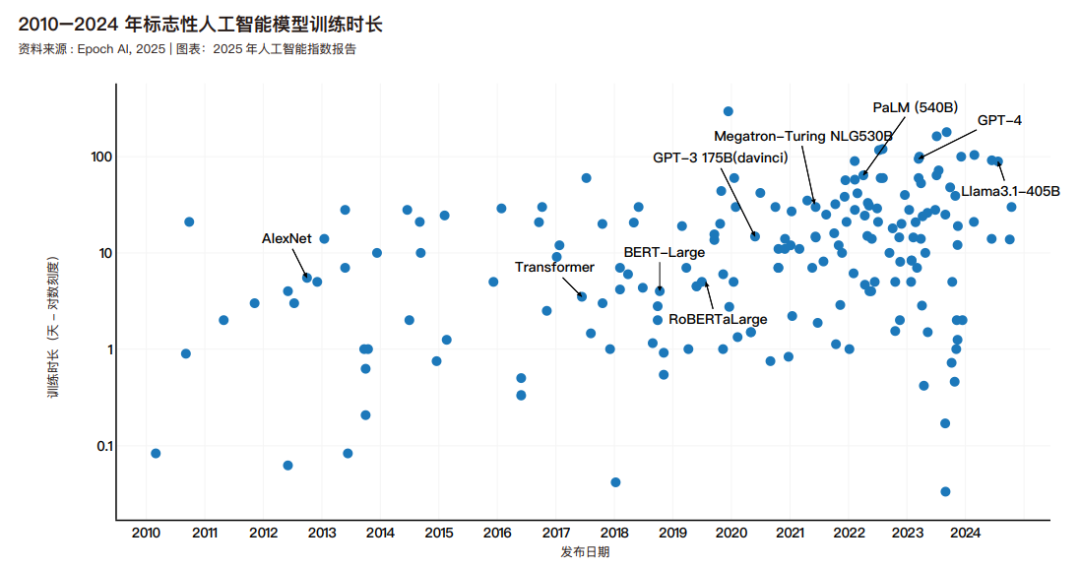
随着模型参数数量的增加,用于训练人工智能系统的数据量也在增加。下图展示了用于训练标志性机器学习模型的数据集规模的增长。2017 年发布并被广泛认为引发了大语言模型革命的 Transformer 模型,是在大约 20 亿个词元的基础上训练出来的。到 2020 年 GPT-3 175B——最初的 ChatGPT的基础模型之一——估计是在 3740 亿个词元上训练出来的。相比之下,Meta 的旗舰大语言模型,即 2024 年夏天发布的Llama 3.3,则是在大约 15 万亿个词元上训练出来的。根据Epoch AI 的数据,大语言模型训练数据集的规模大约每八个月翻一番。在越来越大的数据集上训练模型导致训练时间显著延长。一些最先进的模型,如 Llama 3.1-405B,需要大约 90 天的时间来训练——这在当今标准下是一个典型的训练周期。谷歌于 2023 年底发布的 Gemini 1.0 Ultra 耗时约 100天。这与 AlexNet 形成了鲜明对比,AlexNet 是首批利用GPU 提高性能的模型之一,在 2012 年仅用五到六天就完成了训练。值得注意的是,AlexNet 的训练硬件远不及后者先进。
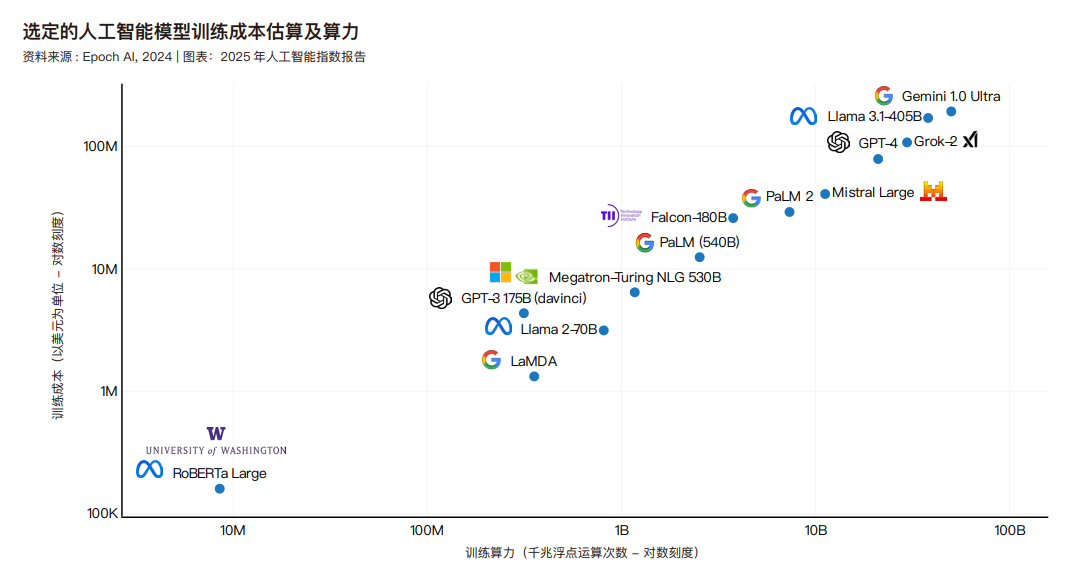
在人工智能模型领域,"compute"(计算资源)特指训练和运行机器学习模型所需的基础算力资源。通常而言,模型复杂度与训练数据集规模将直接影响所需算力资源的多少。模型复杂度越高、训练数据量越大,其训练过程所需的算力规模就越大。在最终训练运行之前,研究人员会在整个研发阶段进行多次测试运行。虽然单个模型的训练成本相对较低,但多次研发迭代所需的累计费用,以及必要数据集费用,将快速攀升至可观规模。需注意,当前数据仅反映最终训练阶段的成本,而非完整研发流程的总投入。下图展示了近 22 年间标志性机器学习模型所需的训练算力变化情况。值得注意的是,近年来重要人工智能模型的算力消耗已呈现指数级增长态势。22 据 Epoch 估算,标志性人工智能模型的训练算力大约每五个月翻一番。这一趋势在过去五年中尤为明显。算力需求的快速增长具有重要影响。以计算密 集 型 模 型 为 例,其 往 往 会 产 生 更 大 的 环 境 足 迹( environmental footprints),而企业机构通常比学术组织拥有更丰富的计算资源。

硬件
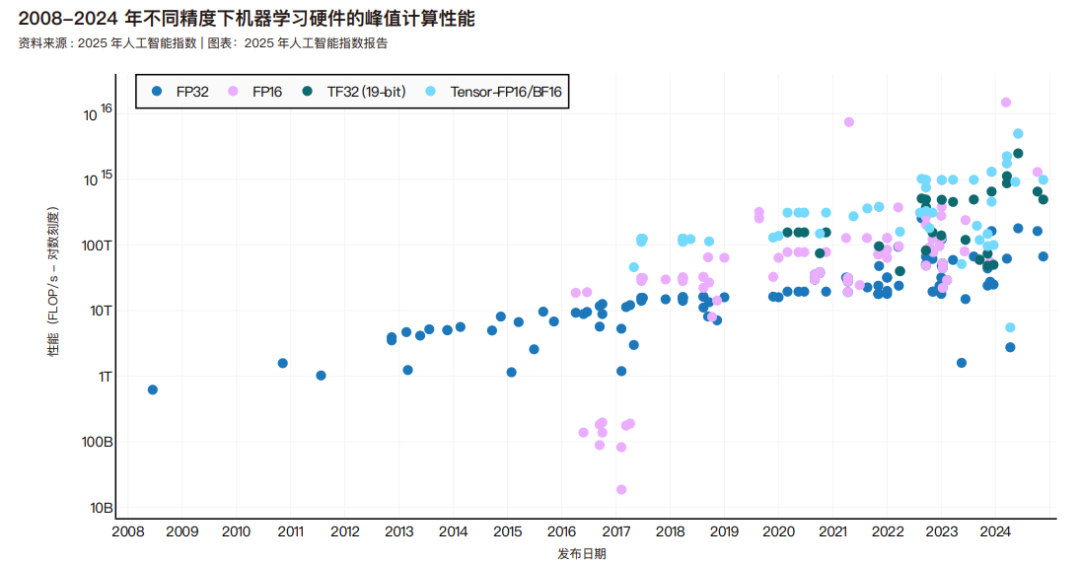
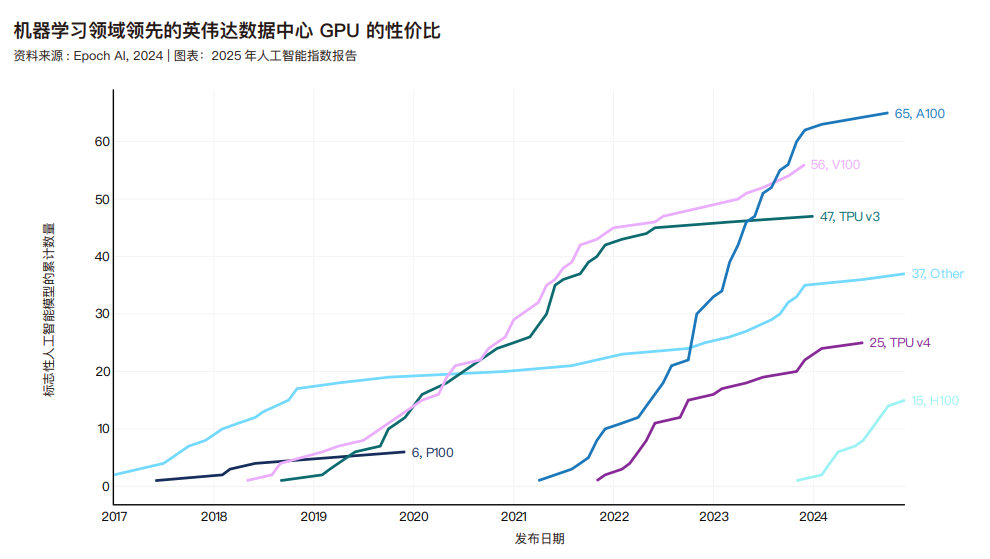
下图展示了不同精度类型的机器学习硬件的峰值计算性能,其中精度是指计算中用于表示数值(尤其是浮点数)的比特数。精度的选择取决于具体目标。例如,低精度硬件需要的比特数更少,内存带宽更低,是优化计算速度和能效的理想选择。这尤其有利于边缘 / 移动设备的人工智能模型或推理速度优先的场景。另一方面,精度更高的硬件可以保留更高的数值准确率,因此对于科学计算和对精度误差敏感的应用至关重要。在下图可视化的精度中,FP32 精度最高,TF32 为中高精度,Tensor-FP16/BF16 和 FP16 则是为速度与效率优化的低精度格式。Epoch 估计以 16 位浮点运算为单位,机器学习硬件的运算能力在2008-2024 年间的年增长率约为 43%,每 1.9 年翻一番。据 Epoch 分析,这一进步源于晶体管数量增加、半导体制造工艺改进以及人工智能专用硬件的发展。

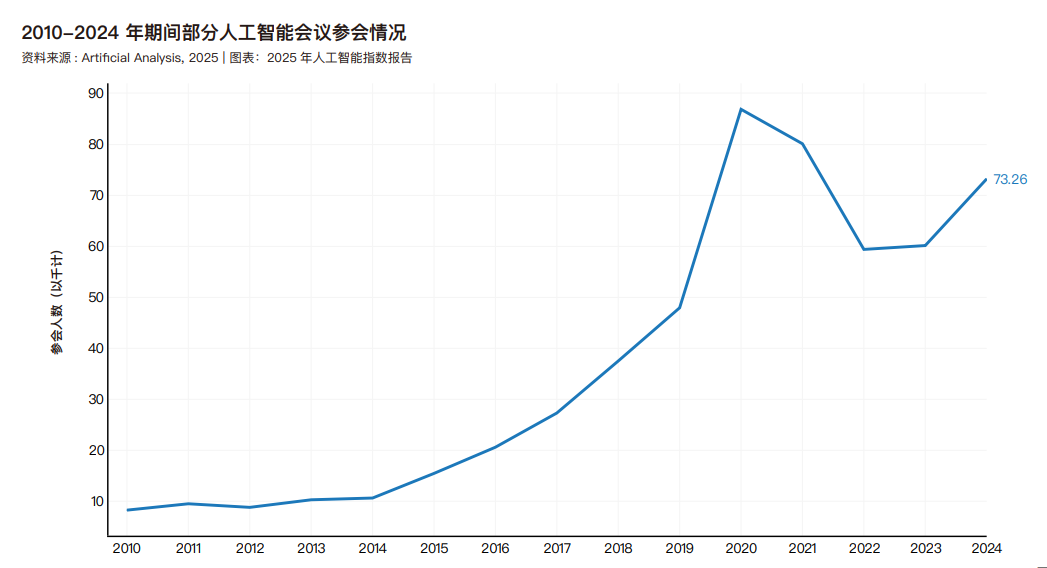
人工智能会议
2010 年以来部分人工智能会议的参会人数。2020 年,新冠疫情迫使会议在线举行,参会人数显著增加。随后,可能由于会议恢复到线下形式,参会人数有所下降,2022年参会人数恢复到疫情前的水平。此后,参会人数稳步增长,2023 至 2024 年增幅达 21.7%。 自 2014 年起,年参会人数增长超 6 万,既反映人工智能研究热度上升,也体现新会议涌现。神经信息处理系统大会(NeurIPS)仍是最受欢迎的人工智能会议,2024 年吸引近 2 万名参会者。在主要的人工智能会议中,NeurIPS、CVPR、ICML、ICRA、ICLR、IROS 和AAAI 去年的参会人数都有所增加。

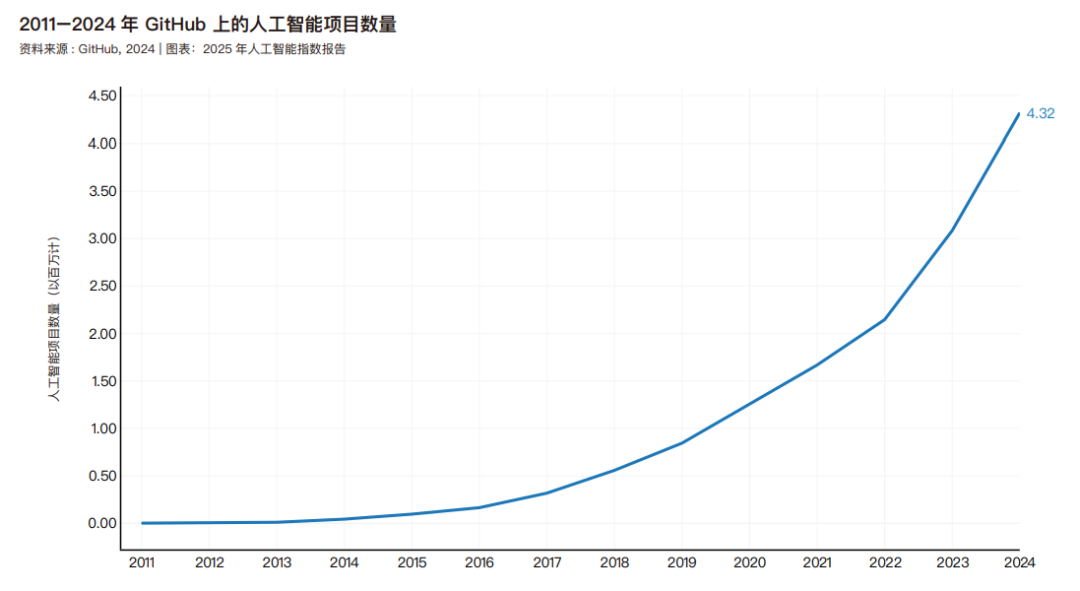
开源人工智能软件
GitHub 项目由一系列文件组成,包括源代码、文档、配置文件和图像,这些文件共同构成了一个软件项目。图 1.6.1 显示了随着时间推移 GitHub 人工智能项目的总数的变化。35 自 2011 年以来,与人工智能相关的 GitHub 项目数量持续增长,从 2011 年的 1,549 个增至 2024 年的约 430 万个。值得注意的是,仅去年一年,GitHub 人工智能项目总数激增了 40.3%。
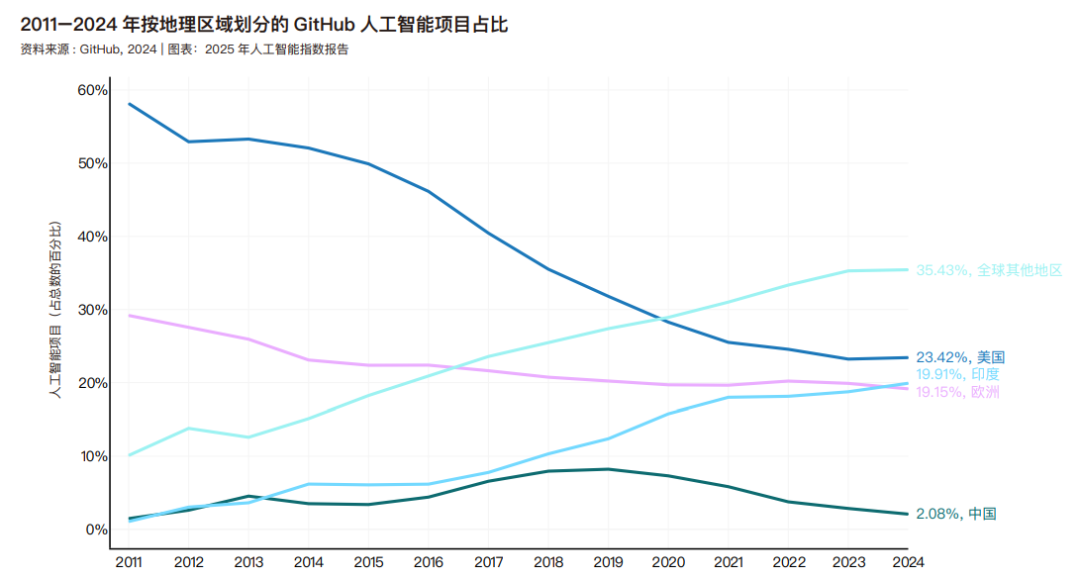
截至 2024 年,美国贡献了 23.4% 的 GitHub 人工智能项目,占比最高;印度以 19.9% 位居第二,欧洲以 19.5% 紧随其后。值得注意的是,自 2016 年起,美国开发者在 GitHub开源人工智能项目中的占比持续下降,近年趋于稳定。
(未完待续....)
------------------------ END ------------------------
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-06-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号