Agent概述技术文档

Agent概述技术文档

wuzhigang
发布于 2026-06-18 08:31:07
发布于 2026-06-18 08:31:07
一、Agent的发展背景?
Agent智能体的发展始于1950年代图灵测试的理论基础,与人工智能行业的发展有着
密不可分的关系,
历经60~80年代基于符号规则驱动的专家系统(如MYCIN、DENDRAL),执行预设的命令(被动执行)、
2010~2020年深度学习(如ResNet)、强化学习(如AlphaGo)的发展,增强了其感知力与决策力、
2021-2024人工智能大语言模型的爆发,结合多模态,已经发展成能够自主思考、感知、决策、
执行复杂任务的智能体,实现了从被动执行命令到主动思考、决策、执行复杂任务的巨大转变!二、什么是Agent智能体?
Agent智能体是指能够感知周围环境、通过算法模拟像人一样主动进行思考、动态决策、
执行单一或复杂任务的角色,相比传统AI助手,具备主动感知 、决策、执行、学习的能力!三、Agent的架构原理?
1、架构图
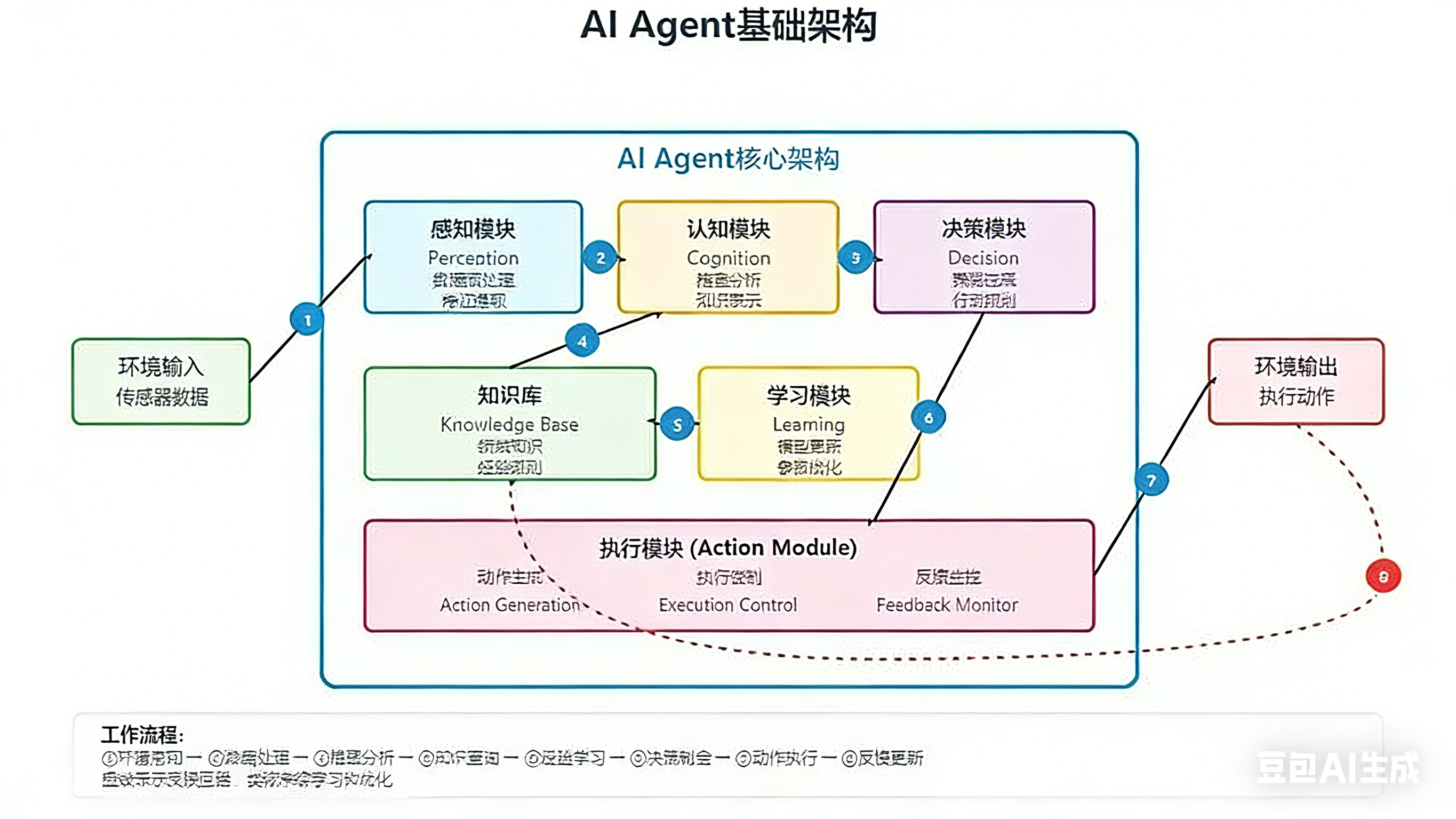
在这里插入图片描述
2、Agent底层运行原理与核心模块
工作原理:感知->决策->执行->反馈(学习)
1、感知模块:主动感知、收集周围环境信息(例如:语音、视频、文字、图片、传感器数据等等),
其目标是为Agent在执行单一或复杂任务时为其决策提供核心信息,是Agen接触外界的关键模块!
2、认知模块:基于感知模块提供的外界信息,初步理解需求,拆解任务目标,处理执行单一或
复杂任务时的反馈信息,为决策模块提供信息和认知支撑!
3、记忆层:存储着感知模块的外界信息、上下文不同链路之间的数据、外部RAG知识库以及
处理单一或复杂任务是的反馈信息、处理经验,为决策、认知模块提供领域知识与经验的支持!
记忆类型 存储内容 技术实现
短期记忆 当前对话上下文 Transformer注意力机制
长期记忆 业务文档/历史数据 Chroma向量数据库
长期记忆 专业领域知识、实时行业知识、信息 RAG检索增强技术
创新应用
Graph-RAG 实体关系图\支持多跳推理(如"A公司创始人的配偶是谁?")
MemGPT 动态记忆管理、突破上下文窗口限制
4、决策模块:根据认知结果和知识库信息,制定具体的行动步骤(比如 “先调用搜索工具查
行业数据→再用文档工具整理框架”),同时规划步骤的优先级、容错方案,(比如某工具
调用失败时切换替代工具)
5、执行模块:
把决策模块的规划转化为实际动作(比如生成代码、调用 MCP 协议连接外部工具、输出文本),
同时监控动作的执行状态(是否成功、是否符合预期),收集反馈信息!
6、反馈模块:即学习模块,基于执行模块的执行情况反馈收集到的信息,将其失败经验反馈给
认知模块、决策模块、将反馈的失败经验存储在记忆模块中,为下一步的思考、调整决策提供支持!四、Agent的种类与区别?
1、React Agent(动态交互型Agent,边想边做)?
核心逻辑:
Thought → Action → Observation → (循环)
每一步都实时与环境交互,根据反馈动态调整。
技术特点:
无预设计划,通过推理-行动循环逐步推进任务
依赖LLM的即时推理能力(如"我需要查订单状态→调用API→收到结果→分析异常")2、Plan-and-Execute Agent(计划型Agent,“先谋后动”)?
核心逻辑:
Planning → Execution → Monitoring → Replanning
先制定完整计划,再执行,执行中监控并可能重规划。
技术特点:
需预定义任务分解(如用CoT生成步骤树)
执行阶段较少中断,重规划仅在关键节点触发3、Workflow Agent(机械型Agent无思考,按照设定流程执行任务)?
核心逻辑:
预定义工作流 → 机械执行 → 无自主决策
完全依赖外部设计的流程,Agent仅是执行者。
技术特点:
无LLM推理,纯流程引擎驱动(如Airflow/BPMN)
无法处理流程外的异常(需人工干预)五、不同种类Agent的优缺点与应用场景?
架构类型 | 核心机制 | 优点 | 缺点 | 典型应用场景 |
|---|---|---|---|---|
ReAct | 动态交互:Thought → Action → Observation 循环 | 灵活性高、适应未知环境、实时响应能力强 | LLM调用频繁、成本高、复杂任务执行效率较低 | 智能客服、开放域问答、探索性任务(如故障排查) |
Workflow | 静态流程:预定义步骤 + 规则引擎执行 | 可靠性高、流程清晰、执行高效、易于审计 | 无自主决策、无法处理流程外异常、扩展性差 | 订单履约、审批流、报销自动化、CI/CD流水线 |
Plan-and-Execute | 分阶段:规划 → 执行 → 监控 →(必要时)重规划 | 结构清晰、资源效率高、支持复杂任务分解与容错 | 初始规划耗时、对动态环境适应性弱于ReAct | 报告生成、数据分析、代码开发、多步研究任务 |
总结:
ReAct:边走边想,适合探索未知;
Plan-and-Execute:先谋后动,适合高效执行;
Workflow:按设定流程计划执行,适合固化流程。六、workflow Agent 的与roact Agent的调优策略?
架构选择:根据任务特性和业务需求选择合适的Agent架构,或采用混合架构平衡稳定性和灵活性。
渐进式优化:从简单任务开始,逐步扩展到复杂任务,确保agent在稳定运行的基础上不断优化。
优先优化高价值任务,而非全量覆盖。
安全优先:所有Agent系统都应遵循最小权限原则,通过沙箱隔离限制工具调用权限
数据驱动:建立完善的监控和分析体系,通过AgentBoard等评测工具收集和分析数据,指导agent
优化方向。
Agent记忆优化:对于持久性价值高的,将来可能被用到的、或个性化价值信息(用户习惯、偏好)
永久存储,对于结构化信息(时间、地点、事实等实体)优先存储,对于纯应答的客套话不存,
同时设置记忆衰减机制,对每一条记忆信息进行打分,其权重可根据用户主动强调、涉及
实体关系以及出现频次高,提升权重、客套话降低权重,对于长期3个月都没有调用的且
重要性分数低的就遗忘。七、Agent智能体发展的瓶颈?
当前Agent智能体的发展虽在大模型驱动下展现出强大潜力,但仍面临六大核心瓶颈,严重制约
其在真实企业场景中的规模化落地,且目前没有出现较大的用户需求互动的应用场景。
第一,可靠性不足与幻觉问题突出。 Agent依赖的大语言模型(LLM)易生成事实错误、逻辑
矛盾或虚构工具调用,在多步任务中错误持续累积,难以满足金融、医疗等高风险领域对准确
性和可信赖性的基本要求。
第二,长期任务管理能力薄弱。 现有架构缺乏对复杂、跨会话任务的全局状态感知与一致性
维护。受限于上下文窗口,即使结合RAG等外部记忆机制,仍难以精准召回关键信息,导致
目标漂移、重复执行或任务中断。
第三,工具泛化与环境适应性差。 多数Agent仅能在预定义、封闭的工具集中运行,无法自动
理解新API、处理非结构化输出(如网页、PDF),或在动态变化的真实环境中稳健交互,限制了
其开放世界应用能力。
第四,评估体系严重缺失。 当前缺乏统一、多维度、可自动化的评测基准,难以客观衡量Agent
在成功率、效率、鲁棒性、安全性等方面的综合表现,导致技术迭代依赖主观判断,阻碍产业
信任建立。
第五,安全与对齐风险加剧。 高度自主的Agent可能越权操作(如自动发送邮件、修改数据)、
生成偏见内容,或被提示注入攻击诱导执行恶意行为,带来隐私泄露、合规违规甚至法律责任。
第六,工程成本与运维复杂度高。 复杂任务需多次调用LLM与外部服务,导致延迟高、
费用昂贵,且缺乏轻量化、可中断恢复、可观测的执行框架,企业级部署门槛极高。本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-06-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号