智能体构建:企业级大模型落地核心技术:SKILL架构成本控制与资源管控体系详解.144
原创
智能体构建:企业级大模型落地核心技术:SKILL架构成本控制与资源管控体系详解.144
原创
未闻花名
发布于 2026-06-21 10:14:11
发布于 2026-06-21 10:14:11
一、核心概念
1. SKILL架构介绍
在大模型智能体的工程化落地过程中,传统架构普遍采用端到端黑盒调用模式,即用户输入一句话,系统直接转发给大模型进行完整理解、规划、推理与生成。这种方式虽然开发速度快、接入简单,但在企业级高并发、高可用、低成本的要求下,会迅速暴露出资源不可控、成本爆炸、系统不稳定等问题。
SKILL架构正是为解决这一系列问题而设计的模块化、技能化、可管控的企业级智能体架构体系。其核心设计思想是:将一个完整的AI智能体能力,按照业务功能、任务类型、逻辑复杂度、资源消耗特征,拆解为若干个独立、解耦、可复用、可观测、可管控的最小执行单元,这个单元被称为SKILL,即技能。
一个标准企业级智能体不再是单一模型调用,而是由数十甚至上百个SKILL组合而成。例如:
- 基础信息查询 SKILL
- 入参合法性校验 SKILL
- 多轮对话状态管理 SKILL
- 文本结构化与格式 化SKILL
- 复杂逻辑推理 SKILL
- 外部工具、API调用 SKILL
- 行业规则匹配 SKILL
- 结果聚合与自然语言生成 SKILL
每个SKILL 具备独立的生命周期:独立开发、独立部署、独立升级、独立监控、独立限流、独立缓存、独立模型绑定、独立资源分配。这种“技能原子化”的设计,是实现精细化成本与资源管控的基础,也是SKILL架构能够真正进入企业生产环境的关键前提。

2. 智能体落地的核心瓶颈
企业级智能体落地的核心瓶颈无外乎成本与资源不可控,当前大模型商业化落地中,几乎所有企业都会遇到三个共性瓶颈:
2.1 Token消耗不可控,成本线性增长
- 简单查询、规则判断、格式转换等低复杂度任务,与深度推理、专业决策等高复杂度任务共用同一套大模型,导致大量低成本任务被高成本算力处理,造成严重浪费。
- 在高并发场景下,Token费用会以指数级上升,最终让项目因成本问题被迫停滞或下线。
2.2 资源竞争严重,系统稳定性差
- 传统智能体架构通常采用全局限流、全局配额、全局资源池管理。当
- 某一个功能(例如批量查询)突然流量暴涨时,会瞬间占满全部模型调用额度,导致其他核心业务功能不可用,引发系统性雪崩。
2.3 缺乏精细化调度能力
- 传统架构无法感知任务内部结构,无法区分哪些任务轻、哪些任务重,无法动态分配CPU、内存、模型实例、并发数。
- 资源要么闲置浪费,要么挤兑崩溃,难以满足企业 7×24 小时稳定运行要求。
这些问题并非模型本身能力不足,而是架构层缺失“管控能力”。SKILL架构的出现,正是从架构层面补上这一关键短板。
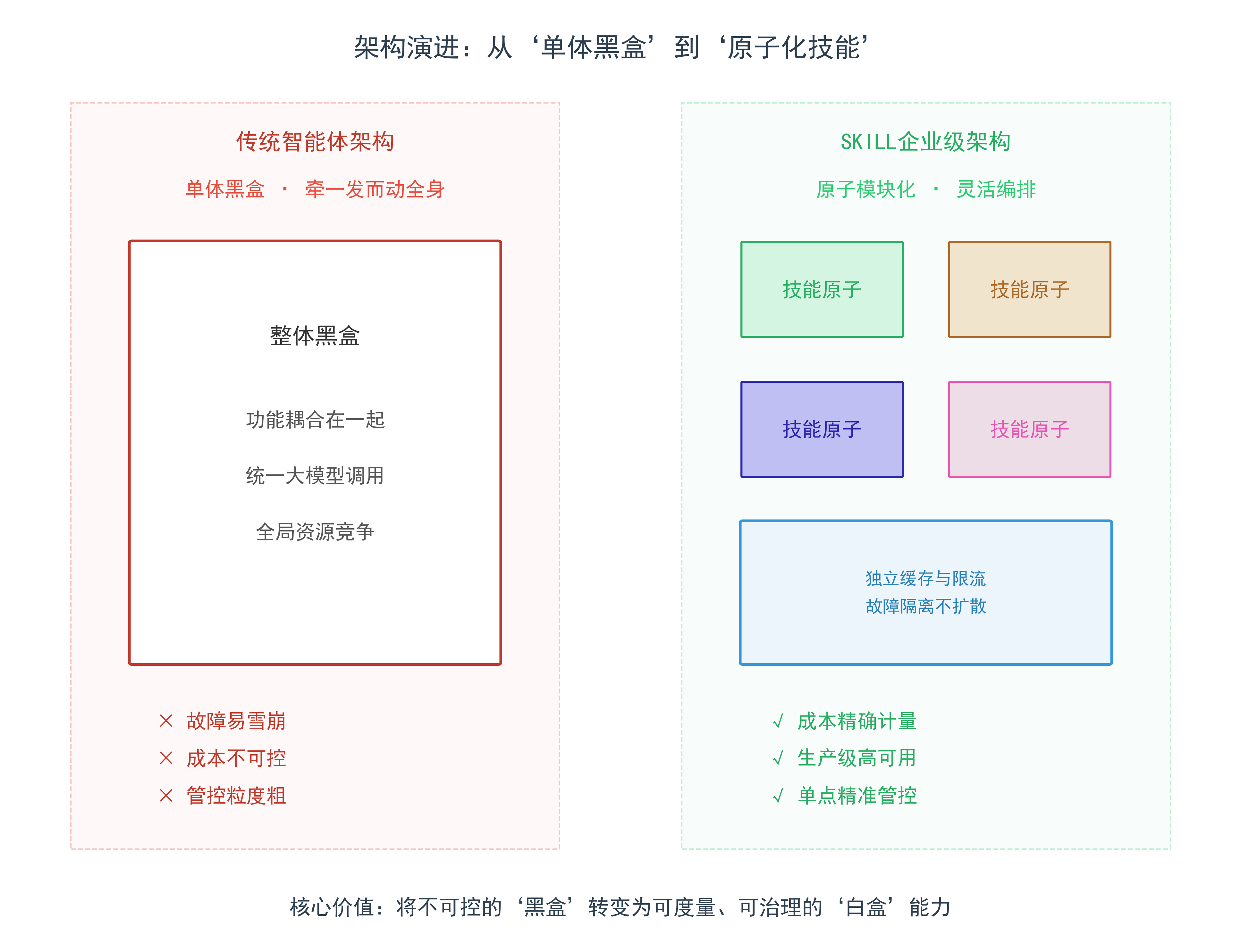
3. 传统智能体的管控缺陷
传统智能体,如单一Agent、端到端LLM调用在设计上存在三个结构性缺陷:
3.1 任务与模型强绑定,无法分级
- 所有请求进入同一链路,无论简单复杂,统一走顶级大模型。无法做到“简单任务小模型、复杂任务大模型”。
3.2 管控粒度粗,只能全局控制
- 限流、配额、缓存均作用于整个系统,无法针对单个功能、接口、技能进行独立配置。一旦某个技能异常,整个智能体瘫痪。
3.3 无模块化复用机制,重复消耗严重
- 相同请求、相似参数、规则类结果无法在技能内部缓存,每次都重新调用模型,导致Token消耗与资源占用成倍增加。
这三点共同导致:传统智能体只能用于Demo、实验、低并发场景,无法真正进入企业级生产环境。
4. SKILL架构成本管控的核心
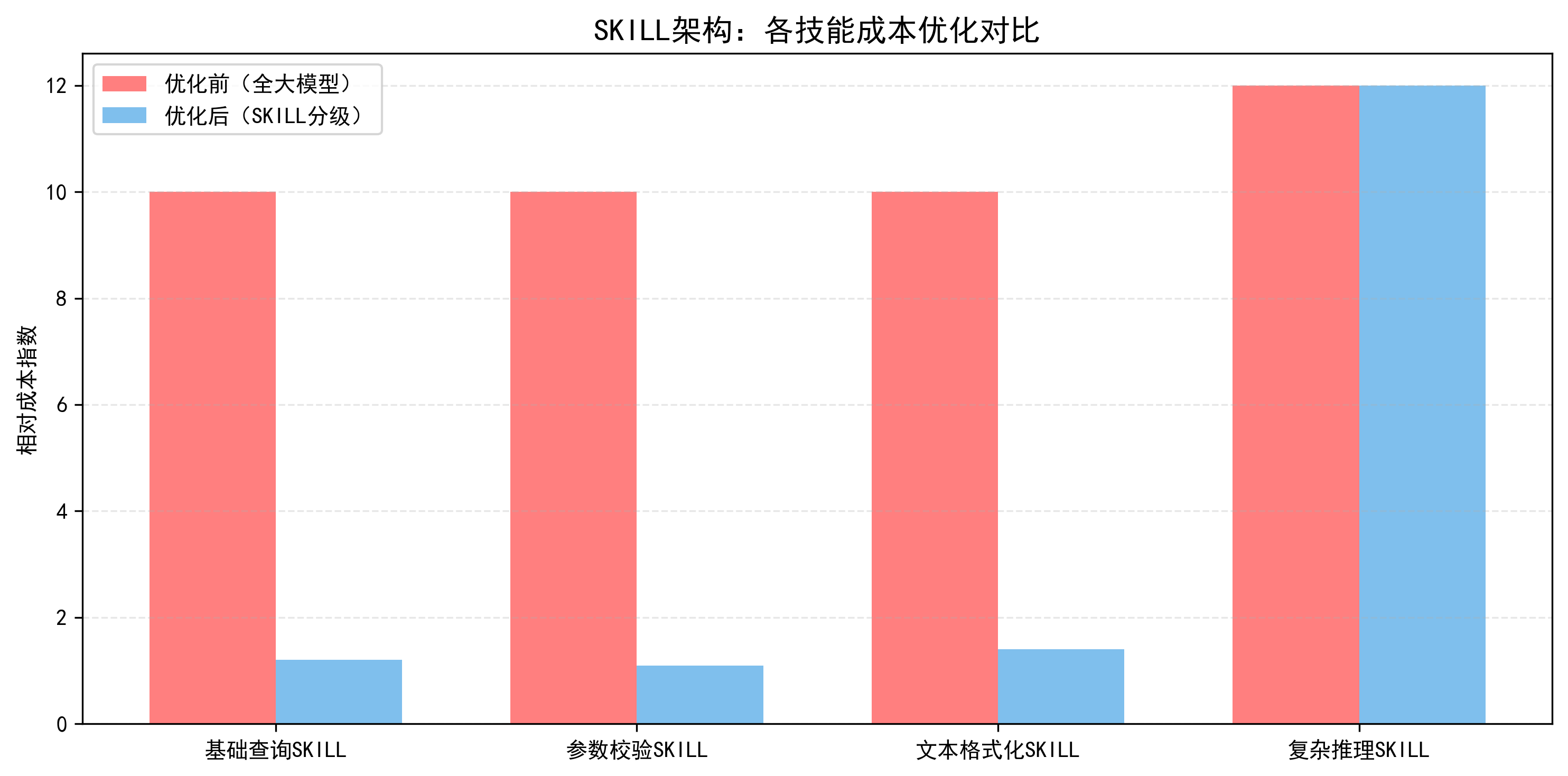
SKILL架构通过“技能原子化”,将成本与资源管控的粒度从“系统级”下沉到“技能级”,实现四大核心价值:
4.1 成本可量化、可控制、可优化
- 企业可以精确统计每个技能、每个接口、每个用户、每类任务的Token消耗、模型费用、资源占用,从而进行持续优化。
4.2 资源隔离,避免单点故障扩散
- 不同SKILL拥有独立配额与限流策略,一个技能异常不会影响其他技能,系统稳定性显著提升。
4.3 模型资源利用率最大化
- 通过动态调度、分级调用、缓存复用,让高成本模型只处理高价值任务,整体资源利用率提升50%–90%。
4.4 支持规模化高并发落地
- 企业可以在不增加模型成本的前提下,支撑数倍甚至数十倍的用户流量,真正实现大模型商业化闭环。
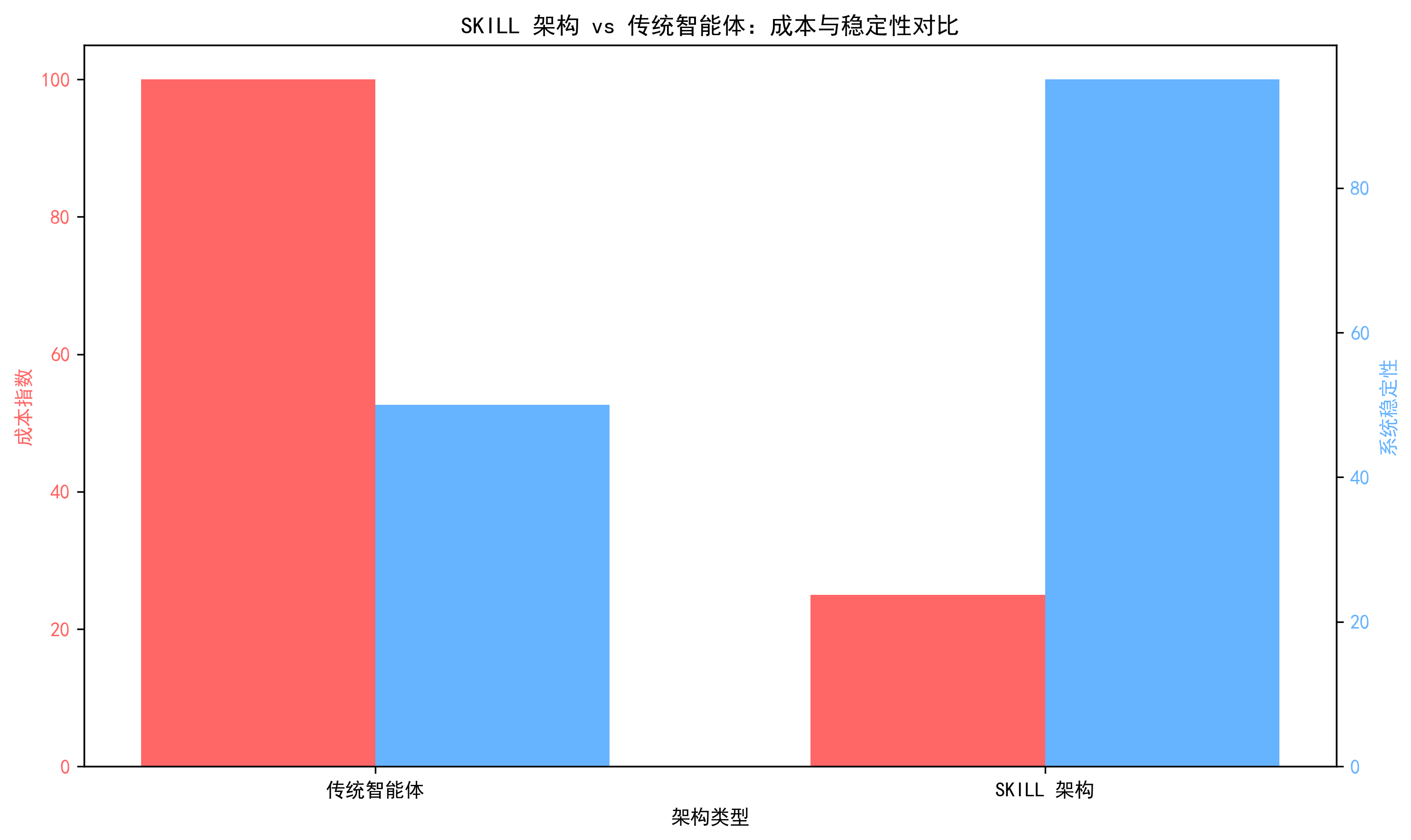
5. SKILL架构与传统架构的差异
这些差异共同决定了企业生产的可用性:
- 传统架构因其僵化、高成本和高风险,往往只适合小范围的试点项目。
- SKILL企业级架构凭借其模块化、精细化管控、成本可控和高可用性等特性,能够支撑高并发、大规模的企业级应用,是智能体从实验走向规模化生产的关键基石。
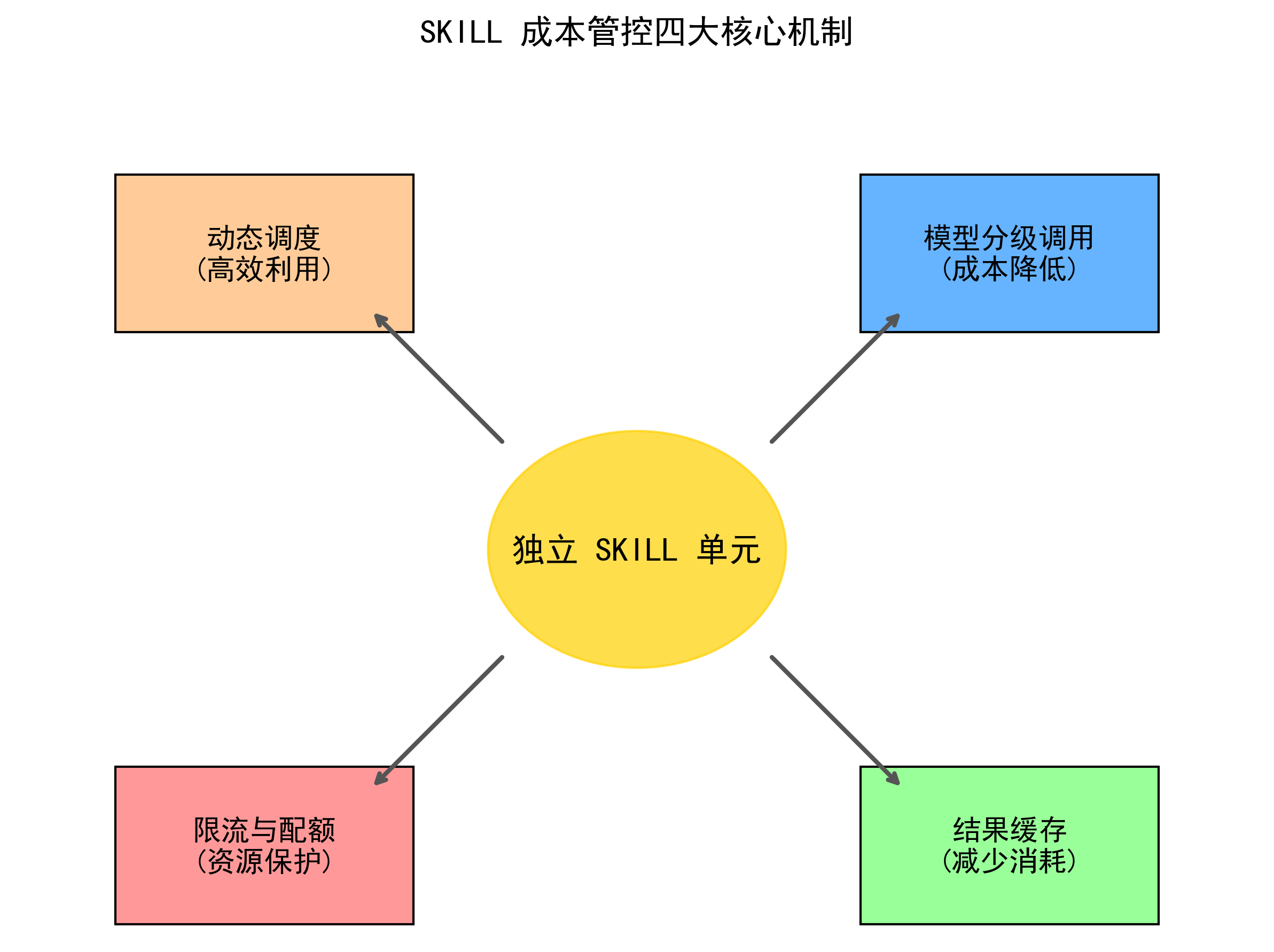
6. SKILL架构核心组成
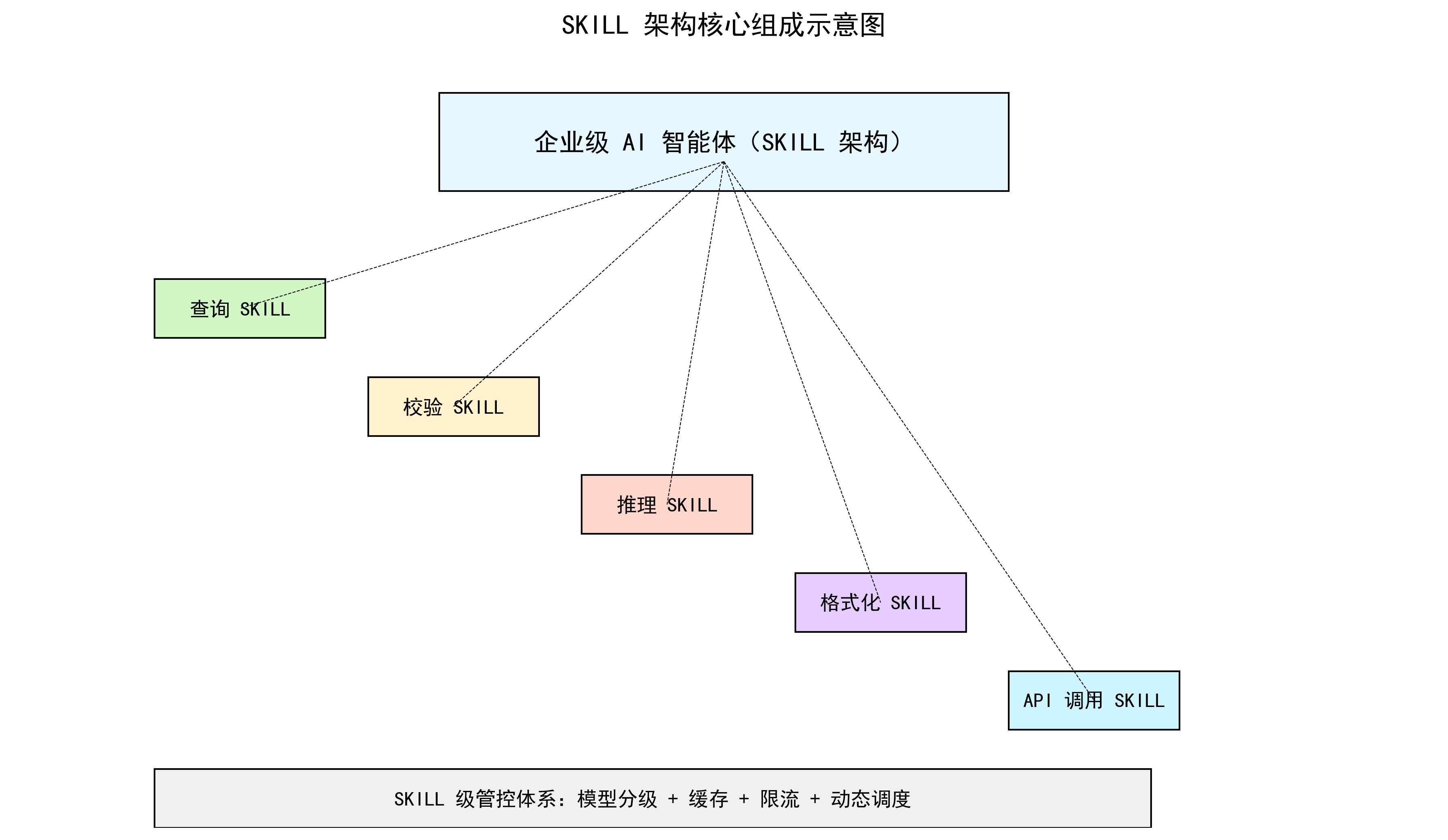
SKILL:智能体最小可执行、可管控功能单元,具备唯一标识、业务逻辑、模型绑定、限流规则、缓存策略、资源配额。
- 模型分级调用:根据SKILL标注的任务复杂度,自动路由至轻量开源模型、中等通用模型、重量级付费大模型。
- SKILL 级缓存:以技能为维度,对高频、确定性结果进行本地或分布式缓存,避免重复模型推理。
- SKILL 级限流:对单个技能设置 QPS、分钟级调用次数、日累计 Token 上限,实现细粒度流控。
- 动态资源调度:基于实时监控指标(延迟、并发、队列长度、资源使用率)自动调整算力分配。
- 调度器(Skill Router):SKILL 架构的核心中枢,负责请求解析、技能匹配、限流校验、缓存命中、模型路由、结果聚合。
二、SKILL请求处理流程
SKILL架构的请求链路严格遵循“管控优先、资源最优、成本最低”原则,每一步都嵌入成本与安全控制,形成标准化、可复现、可监控的执行体系。
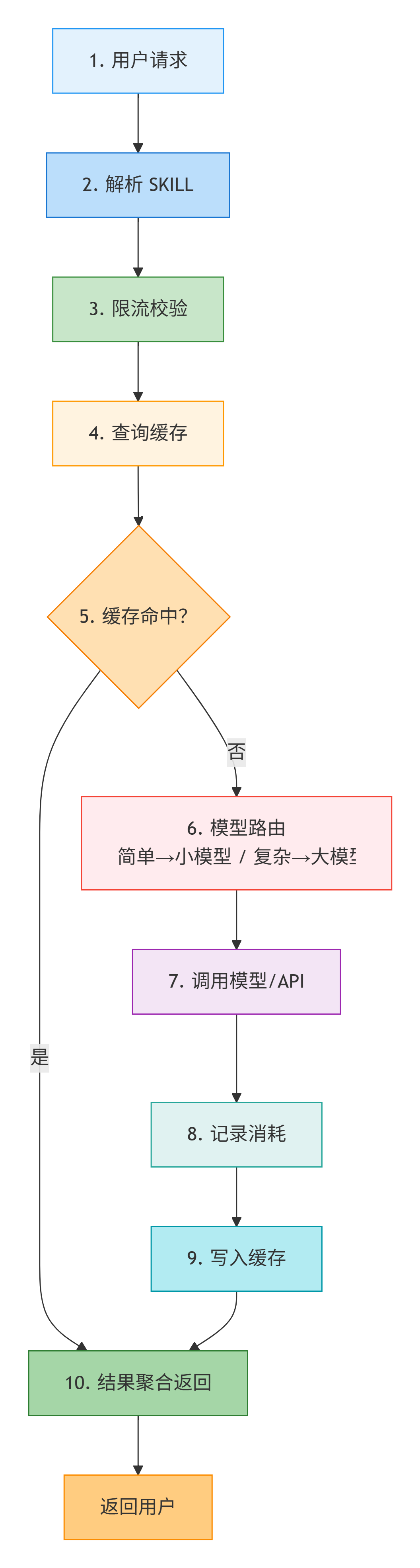
流程说明:
- 1. 用户请求:接收用户输入。
- 2. 解析 SKILL:识别请求应调用的技能。
- 3. 限流校验:检查是否超过并发/频率限制。
- 4. 查询缓存:查看历史结果是否可复用。
- 5. 缓存命中判断:
- 命中 → 直接进入结果聚合返回。
- 未命中 → 进入模型路由。
- 6. 模型路由:根据任务复杂度,简单任务选择小模型或复杂任务选择大模型。
- 7. 调用模型/API:执行实际推理或外部调用。
- 8. 记录消耗:统计Token、时间等成本。
- 9. 写入缓存:将新结果存入缓存供后续复用。
- 10.结果聚合返回:整合所有结果,可能包含多个技能输出,最终返回给用户。
完整流程模块示例:
# 完整SKILL请求执行流程
def execute_skill_full_flow(skill_instance, params: dict):
skill_id = skill_instance.skill_id
print(f"\n===== 开始执行SKILL:{skill_instance.name} =====")
# 步骤1:限流校验
if not skill_instance.check_rate_limit():
return f"ERROR:{skill_id} 触发限流"
# 步骤2:缓存查询
if skill_instance.cache_ttl > 0:
cache_res = SkillCache.get(skill_id, params)
if cache_res:
return f"SUCCESS(缓存):{cache_res}"
# 步骤3:模型路由 & 调用
model = ModelRouter.get_model(skill_instance.complexity)
result = skill_instance.execute(params)
# 步骤4:写入缓存
if skill_instance.cache_ttl > 0:
SkillCache.set(skill_id, params, result, skill_instance.cache_ttl)
# 步骤5:返回结果
return f"SUCCESS(模型):{result}"三、SKILL成本管控机制
1. 模型分级调用
1.1 设计原理
模型分级调用的本质是合适的算力处理合适的任务,避免高射炮打蚊子式的资源浪费。在企业真实场景中,绝大部分的请求属于低复杂度任务:
- 关键词匹配
- 规则校验
- 字段提取
- 简单分类
- 静态知识库查询
- 格式转换与清洗
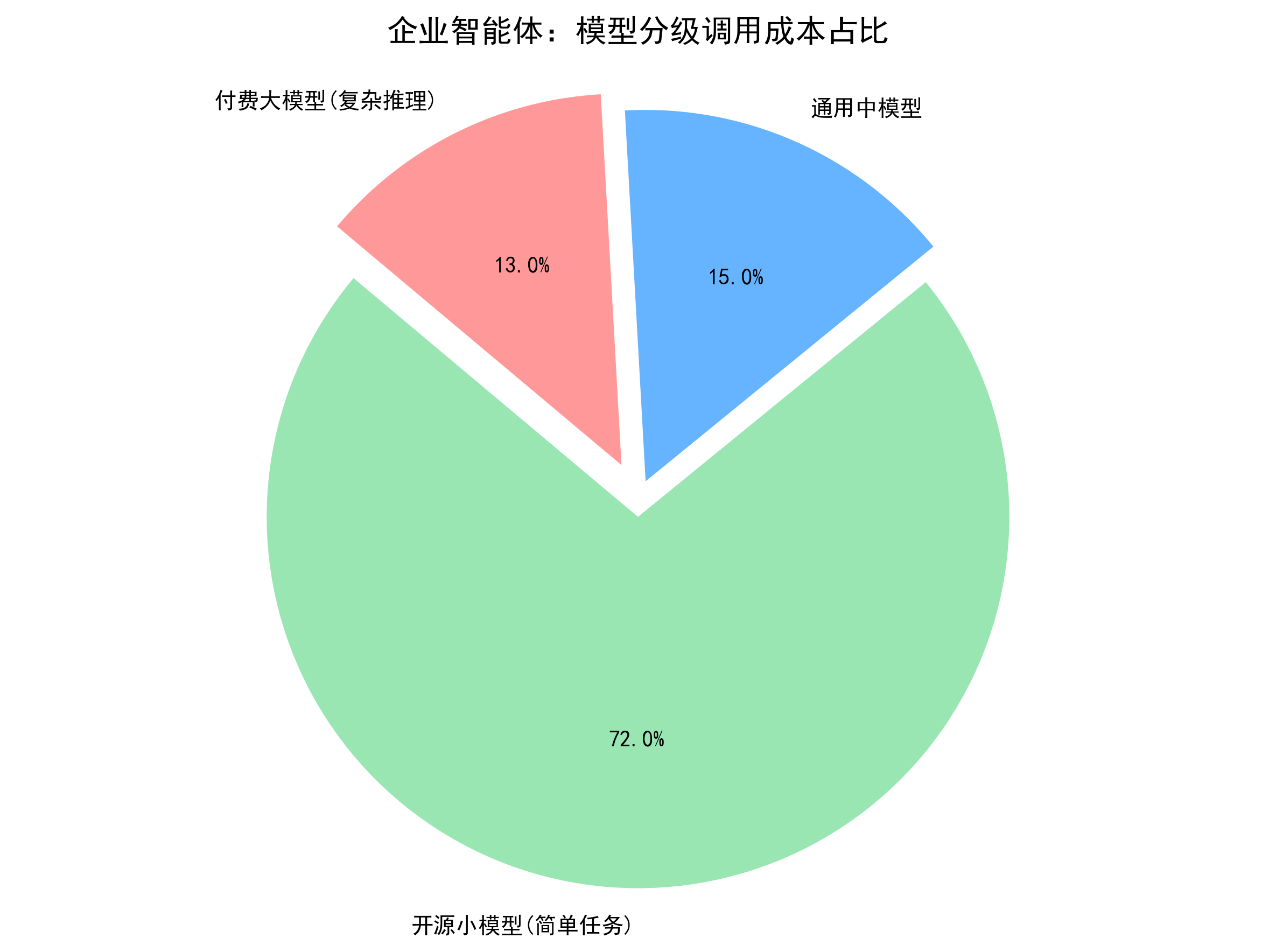
这些任务完全不需要千亿参数大模型,使用1B–7B 开源小模型即可达到 95% 以上准确率。而剩余的复杂任务,如多轮逻辑推理、行业专业决策、跨文档综合分析、创造性生成,才需要调用专业的高质量付费模型。
SKILL 架构通过为每个技能绑定复杂度标签”简单、中等、复杂、极端“,实现请求自动路由,从源头降低 Token 消耗。
1.2 任务复杂度判定标准
在企业落地中,通常从四个维度判断任务等级:
- 逻辑步骤:数量单步判断为低;多步链式推理为高。
- 是否依赖专业知识:通用知识为低;行业深度知识为高。
- 结果是否具备确定性:规则固定、结果唯一为低;开放生成、多元答案为高。
- 是否需要外部工具:联动无需工具为低;多工具协同为高。
基于以上标准,可形成企业内部统一的模型路由规范:
复杂度等级 | 典型 SKILL 类型 | 推荐模型类型 | 成本水平 |
|---|---|---|---|
简单 | 基础查询、参数校验、关键词匹配 | 开源小模型(Llama-3-8B、MiniLM) | 极低 |
中等 | 文本分类、实体抽取、简单意图识别 | 中等闭源模型、私有部署模型 | 低 |
复杂 | 多轮对话、逻辑推理、决策建议 | 通用大模型(GPT-3.5/Turbo) | 中高 |
极端 | 专业决策、深度分析、复杂规划 | 顶级大模型、行业大模型 | 高 |
1.3 技术实现关键点
- 每个SKILL在注册时必须声明 complexity 字段。
- 调度器维护一张可动态热更新的 “模型路由表”,支持按流量百分比灰度切换模型。
- 支持降级策略:当大模型过载时,自动将部分中等任务切回小模型。
1.4 模型分级调用示例
# 模型路由工厂:根据SKILL复杂度自动选择模型
class ModelRouter:
# 复杂度等级对照表
COMPLEXITY_LEVELS = {
"low": "简单",
"medium": "中等",
"high": "复杂",
"extreme": "极端"
}
# 模型配置表(热更新)
MODEL_CONFIG = {
"low": {"name": "7B系列开源模型", "cost": 0.001, "timeout": 1},
"medium": {"name": "通用轻量模型", "cost": 0.01, "timeout": 2},
"high": {"name": "GPT-3.5 Turbo", "cost": 0.1, "timeout": 3},
"extreme": {"name": "GPT-4o", "cost": 1.0, "timeout": 5}
}
@classmethod
def get_model(cls, skill_complexity: str):
"""根据SKILL复杂度返回对应模型配置"""
config = cls.MODEL_CONFIG.get(skill_complexity, cls.MODEL_CONFIG["low"])
level_name = cls.COMPLEXITY_LEVELS.get(skill_complexity, skill_complexity)
print(f"【模型路由】任务复杂度={level_name} → 选用模型={config['name']} | 单轮成本={config['cost']}")
return config
# 调用示例(与SKILL绑定)
if __name__ == '__main__':
# 简单查询SKILL:low复杂度
ModelRouter.get_model("low")
# 复杂推理SKILL:high复杂度
ModelRouter.get_model("high")输出结果:
【模型路由】任务复杂度=简单 → 选用模型=7B系列开源模型 | 单轮成本=0.001 【模型路由】任务复杂度=复杂 → 选用模型=GPT-3.5 Turbo | 单轮成本=0.1
2. 结果缓存复用
2.1 缓存原理
缓存是成本优化最直接、见效最快的手段。对于大量参数相同、结果固定、实时性要求不高的技能,完全没有必要每次都重新调用模型。SKILL架构支持以技能为维度开启独立缓存,缓存Key由”skillId + 参数哈希“构成,保证不同技能之间缓存不冲突。
2.2 适合缓存的SKILL场景
- 基础配置查询 SKILL
- 通用规则校验 SKILL
- 静态知识库问答 SKILL
- 公共字典 / 标准映射 SKILL
- 报表类固定统计 SKILL
2.3 不适合缓存的场景
- 多轮对话状态依赖强的 SKILL
- 实时数据查询 SKILL
- 复杂推理与决策 SKILL
- 涉及用户隐私的个性化 SKILL
2.4 缓存策略
- 缓存存储:Redis 集群
- Key 结构:skill:{skill_id}:{hash(params)}
- 过期机制:按业务配置 TTL
- 淘汰策略: LRU (Least Recently Used - 最近最少使用)/LFU (Least Frequently Used - 最不经常使用)
- 缓存更新:支持手动刷新、定时刷新、事件触发更新
2.5 结果缓存应用示例
import redis
import hashlib
import json
# 分布式缓存客户端
redis_client = redis.Redis(host="localhost", port=6379, db=0, decode_responses=True)
class SkillCache:
@staticmethod
def generate_key(skill_id: str, params: dict) -> str:
"""生成唯一缓存KEY"""
param_str = json.dumps(params, sort_keys=True)
hash_str = hashlib.md5(param_str.encode()).hexdigest()
return f"skill:cache:{skill_id}:{hash_str}"
@staticmethod
def get(skill_id: str, params: dict):
"""查询缓存"""
key = SkillCache.generate_key(skill_id, params)
data = redis_client.get(key)
if data:
print(f"【缓存命中】SKILL={skill_id} | 节省一次模型调用")
return data
return None
@staticmethod
def set(skill_id: str, params: dict, result: str, ttl: int = 300):
"""写入缓存"""
key = SkillCache.generate_key(skill_id, params)
redis_client.setex(key, ttl, result)
# 使用示例
if __name__ == '__main__':
# 参数
skill_id = "query_basic"
params = {"keyword": "企业成本优化方案"}
# 查询
res = SkillCache.get(skill_id, params)
if not res:
# 模拟模型调用
res = "模型返回:企业成本优化核心是分级调用+缓存"
SkillCache.set(skill_id, params, res)
print(res)输出结果:
【缓存命中】SKILL=query_basic | 节省一次模型调用 模型返回:企业成本优化核心是分级调用+缓存
第一次运行时,没有缓存会输出结果,并进行缓存,第二次运行时缓存命中,从缓存输出结果;
3. 限流与配额管控
3.1 核心问题
- 传统全局限流最大问题是:一个异常技能可以饿死整个系统。例如,某个批量查询接口突增流量,瞬间打满全局QPS,导致核心对话、支付、订单类功能完全不可用。
- SKILL架构通过技能级独立限流配额,从根本上杜绝资源挤兑。
3.2 限流维度
- QPS 限流:每秒最大调用次数,防止瞬时流量冲击。
- 分钟级限流:控制单位时间内调用总量,平滑流量。
- 日累计调用量上限:防止恶意刷接口与异常消耗。
- 单用户调用配额:避免单个用户占用大量资源。
- Token 日限额:直接控制成本上限。
- 模型并发数限制:防止模型服务端过载。
3.3 限流算法选择
- 高并发场景:滑动窗口限流,优点是精度高,无突刺问题
- 分布式场景:Redis + Lua 原子操作
- 内部系统:令牌桶算法,允许一定突发流量
3.4 限流管控应用示例
import redis
import time
redis_client = redis.Redis(host="localhost", port=6379, db=0, decode_responses=True)
class SkillRateLimiter:
@staticmethod
def is_allowed(skill_id: str, max_qps: int = 10) -> bool:
"""
技能级QPS限流
:param skill_id: 技能唯一标识
:param max_qps: 每秒最大允许调用次数
:return: 是否允许调用
"""
key = f"skill:limit:qps:{skill_id}"
current = redis_client.incr(key)
if current == 1:
redis_client.expire(key, 1) # 1秒窗口
allowed = current <= max_qps
if not allowed:
print(f"【限流触发】SKILL={skill_id} 超过QPS阈值={max_qps},拒绝调用")
return allowed
# 使用示例
if __name__ == '__main__':
skill_id = "query_basic"
# 模拟连续调用
for i in range(15):
ok = SkillRateLimiter.is_allowed(skill_id, max_qps=10)
print(f"第{i+1}次调用: {'允许' if ok else '拒绝'}")
time.sleep(0.05)输出结果:
第1次调用: 允许 第2次调用: 允许 第3次调用: 允许 第4次调用: 允许 第5次调用: 允许 第6次调用: 允许 第7次调用: 允许 第8次调用: 允许 第9次调用: 允许 第10次调用: 允许 【限流触发】SKILL=query_basic 超过QPS阈值=10,拒绝调用 第11次调用: 拒绝 【限流触发】SKILL=query_basic 超过QPS阈值=10,拒绝调用 第12次调用: 拒绝 【限流触发】SKILL=query_basic 超过QPS阈值=10,拒绝调用 第13次调用: 拒绝 【限流触发】SKILL=query_basic 超过QPS阈值=10,拒绝调用 第14次调用: 拒绝 【限流触发】SKILL=query_basic 超过QPS阈值=10,拒绝调用 第15次调用: 拒绝
4. 动态资源调度
4.1 设计目标
- 企业算力资源通常存在明显波峰波谷:白天高负载、夜间低负载;工作日高负载、周末低负载。传统架构资源固定分配,利用率往往只有20%–40%。
- SKILL架构通过动态调度,实现高峰扩容、低峰缩容、闲时释放,让资源利用率提升至70%–90%。
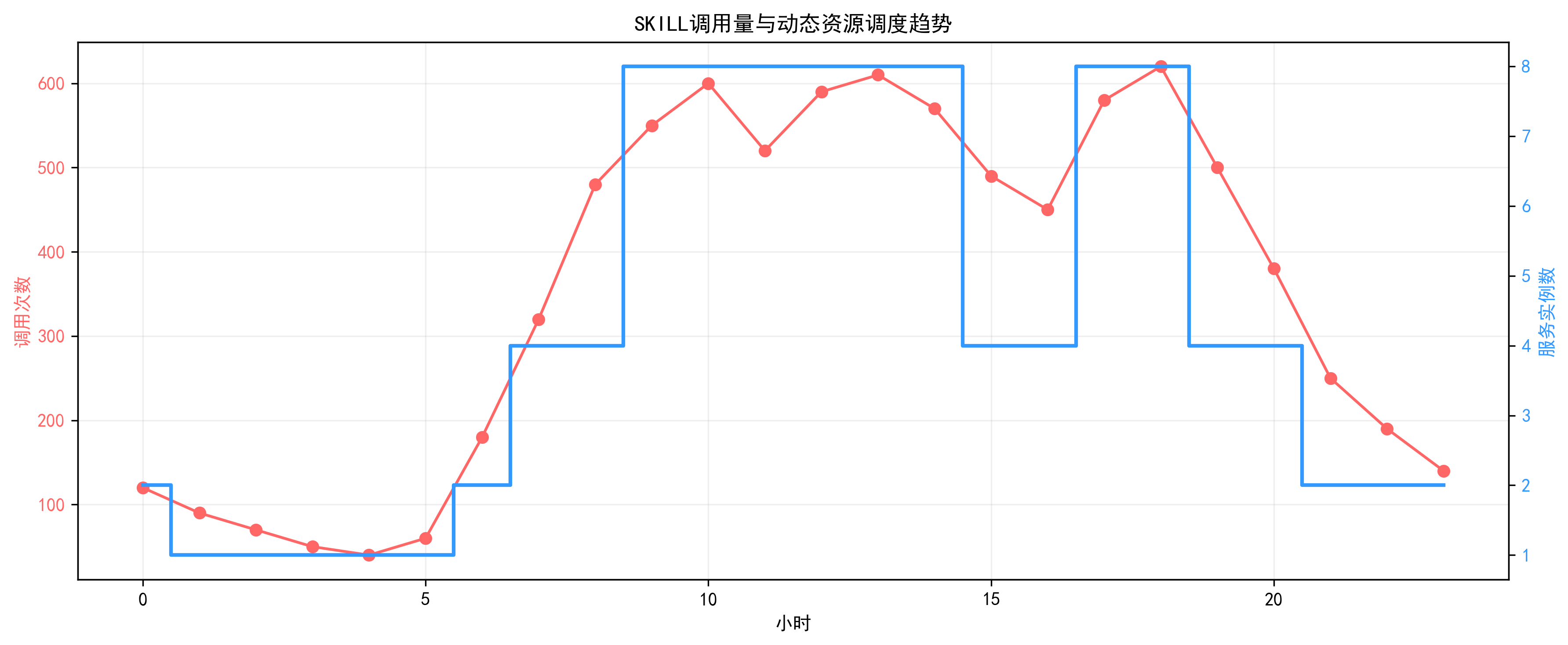
4.2 调度触发指标
- SKILL 调用队列长度
- 模型推理 P95 延迟
- CPU、内存、GPU 使用率
- 异常率与超时率
- 基于历史时序的流量预测
4.3 调度策略
- 高频核心 SKILL:资源优先级最高,在资源有限的情况下,通过差异化对待,确保最关键的业务永远在线且响应迅速
- 低频非核心 SKILL:低优先级,可排队、可降级
- 流量突增时:自动扩容实例,或开启小模型兜底
- 低峰时:释放闲置实例,缩容降本
4.4 动态资源调度示例
class ResourceScheduler:
"""动态资源调度器:根据调用量分配实例数"""
@staticmethod
def auto_scale(skill_id: str, call_count_last_minute: int):
if call_count_last_minute > 1000:
print(f"【高峰调度】SKILL={skill_id} 流量高,扩容至8个实例")
return 8
elif call_count_last_minute > 300:
print(f"【正常调度】SKILL={skill_id} 流量中等,扩容至4个实例")
return 4
else:
print(f"【低峰缩容】SKILL={skill_id} 流量低,缩容至1个实例")
return 1
# 使用示例
if __name__ == '__main__':
ResourceScheduler.auto_scale("query_basic", 1200)输出结果:
【高峰调度】SKILL=query_basic 流量高,扩容至8个实例
四、总结
大模型落地难,从来不是难在模型本身,而是难在管控和成本。通常我们都会一上来就全量调用大模型,看似效果好,结果 Token 费用爆炸、系统一拥就崩,本质就是缺少精细化的管控架构。SKILL架构最核心的思路,就是把智能体拆成一个个独立技能,从全局粗管控变成技能级细管控,用模型分级、缓存、限流、动态调度四件套,从根源上降本提效。简单任务交给开源小模型,复杂任务再上大模型;高频请求直接走缓存,每个技能独立限流不互相拖累,再配合动态资源调度,让算力利用率大幅提升。这套思路不仅适用于医疗,几乎所有企业级智能体都能直接复用。
学习这块内容,建议大家先动手写一写简单的Skill基类、限流和缓存逻辑,跑通一次完整调用流程,才能真正理解技能化拆分的价值。SKILL还是比较务实、可度量、可管控的架构,确实是当前大模型从 Demo 走向生产环境最实用的思路之一。真正用好它,既能把成本压下来,又能让系统稳得住,这才是企业AI落地的关键。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号