Agent 术语别再混着用了:Model、Scaffold、Harness 到底怎么分?

Agent 术语别再混着用了:Model、Scaffold、Harness 到底怎么分?

唐斩
发布于 2026-06-22 17:21:05
发布于 2026-06-22 17:21:05
原文:Harness, Scaffold, and the AI Agent Terms Worth Getting Right
大家好,我是唐斩,第149天第170篇分享 今天分享一篇 Hugging Face 的 Agent 术语梳理文章。
这篇文章发布时间是 2026 年 5 月 25 日,标题是《Harness, Scaffold, and the AI Agent Terms Worth Getting Right》。它不是一篇产品发布,也不是一篇教程,而是试图把 Agent 领域里一堆经常被混着用的词讲清楚。
比如 Model、Scaffolding、Harness、Agent、Context Engineering、Policy、Tool Use、Skills、Sub-agents,还有训练侧的 RL Environment、Trainer、Rollout、Reward。
如果只看标题,可能会觉得这是术语表,比较枯燥。
但我觉得这篇文章很值得技术人看,原因不是记单词,而是它说明了一个变化:
Agent 开发正在从“会调模型”进入“会设计系统”的阶段。
过去大家讨论 AI 应用,常常只问模型强不强、prompt 怎么写、工具怎么接。
现在真正复杂的问题是:模型外面那一整套东西怎么设计?上下文怎么组织?工具怎么调用?什么时候停?失败怎么处理?记忆怎么保存?子任务怎么拆?这些才是 Agent 工程的重点。
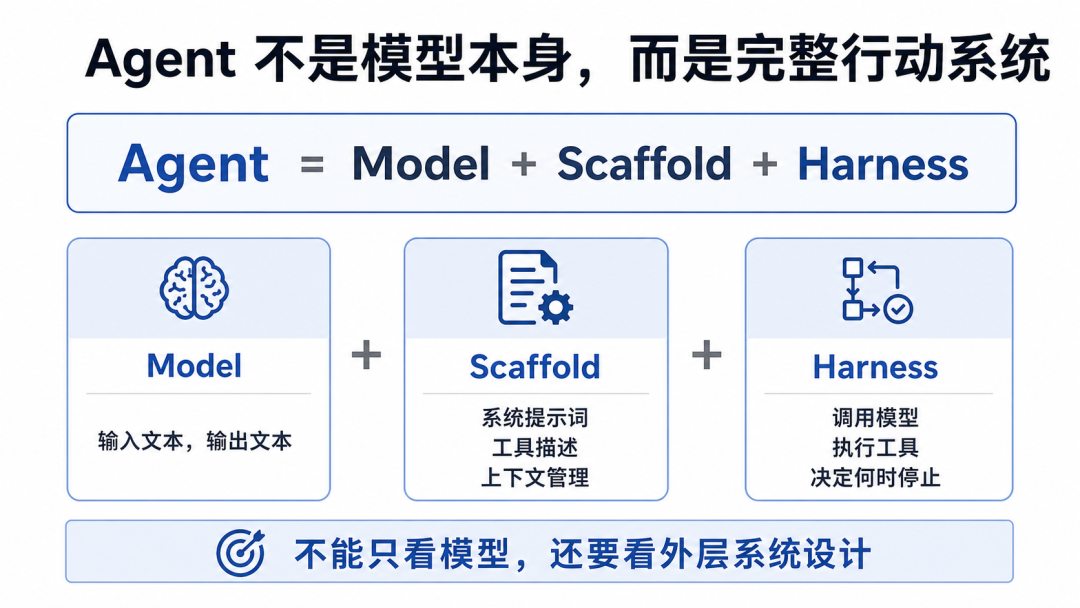
1、Agent 不是模型本身
文章里最重要的一个区分是:Model 不是 Agent。
Model 就是 LLM,本质是输入文本、输出文本。比如 Claude、Qwen、GPT、Kimi、DeepSeek。
模型自己没有跨调用记忆,也不会自己循环执行任务。它可以表达“我想调用工具”,但真正执行工具、拿回结果、继续下一轮的,不是模型自己,而是外层系统。
所以,一个 Agent 更准确地看,是:
Agent = Model + Scaffold + Harness
当然,不同社区会有不同说法,比如很多人会说 Agent = Model + Harness。这里的重点不是争定义,而是要知道:模型只是 Agent 的一部分。
这对程序员很重要。
因为我们现在用 Claude Code、Codex、Cursor、Antigravity CLI 的时候,实际体验不只取决于底层模型,也取决于它外面的 harness 怎么设计。
同一个模型,被不同产品包起来,体验可能完全不同。
反过来,同一个 harness 换一个更强模型,体验也会变化。
所以以后评价 AI 编程工具,不能只说“它用了什么模型”。还要看它的上下文管理、工具调用、任务循环、错误处理、停止条件和产品交互。
2、Scaffold 和 Harness 不要混着用

这篇文章专门解释了 Scaffold 和 Harness 的区别。
我的理解是:
Scaffold 是行为定义层,Harness 是执行控制层。
Scaffold 主要包括:
- system prompt
- tool descriptions
- 模型输出格式
- 上下文管理
- 记忆怎么放进去
- 模型每一步看到什么
它决定模型“以什么身份、看什么信息、按什么格式做事”。
Harness 则是让 Agent 跑起来的执行层,主要负责:
- 调用模型
- 接收工具调用
- 真正执行工具
- 把工具结果塞回上下文
- 决定是否继续
- 处理错误和重试
- 加上 guardrails
一个简单类比:
Scaffold 像是给员工的工作说明书和材料包。
Harness 像是项目经理和流程引擎,负责推进、调度、检查、停止。
文章也提到,很多产品会把这一整套都叫 harness,比如 Claude Code 文档里就说自己是 Claude 外面的 agentic harness。
这没问题。实际产品里,Scaffold 和 Harness 常常是打包在一起的。
但如果我们要做 Agent 系统设计,最好拆开理解。不然问题会混在一起。
模型输出乱,是 scaffold 问题? 工具执行错,是 harness 问题? 上下文丢了,是 context engineering 问题? 任务停不下来,是 stop condition 问题?
拆清楚以后,才知道该改哪里。
3、上下文工程不是写一个 prompt
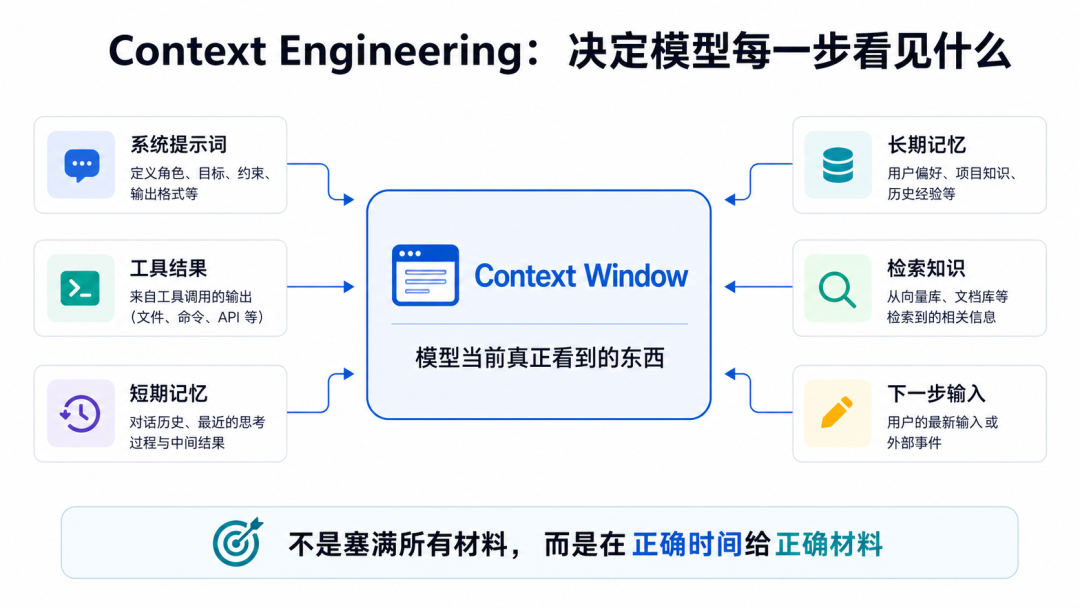
文章对 Context Engineering 的定义也很实用:
它不是一次性写好 prompt,而是设计 Agent 每一步上下文窗口里应该放什么。
包括:
- system prompt
- tool descriptions
- 对话历史
- 工具结果
- 检索出来的知识
- 短期记忆
- 长期记忆
重点是,这不是静态的。
Agent 每运行一步,上一轮的输出、工具结果、错误信息、用户补充,都会影响下一步应该看到什么。
所以真正的上下文工程,是 harness 在运行过程中持续管理上下文。
这里也能解释为什么很多 AI 编程工具看起来都是“问模型”,但实际体验差很多。
有的工具只会把一堆文件塞进去,模型窗口很快乱掉。
有的工具知道什么时候读文件、什么时候压缩历史、什么时候保留关键决策、什么时候重新检索。
差距就在这里。
我觉得这也是程序员做 AI 应用必须补的一课。过去我们做后端,会设计数据库、缓存、队列、日志。现在做 Agent,要设计上下文结构、短期记忆、长期记忆、工具返回内容和压缩策略。
上下文不是越多越好,而是在正确时间给模型正确材料。
4、Tool、Skill、Sub-agent 是三种不同能力
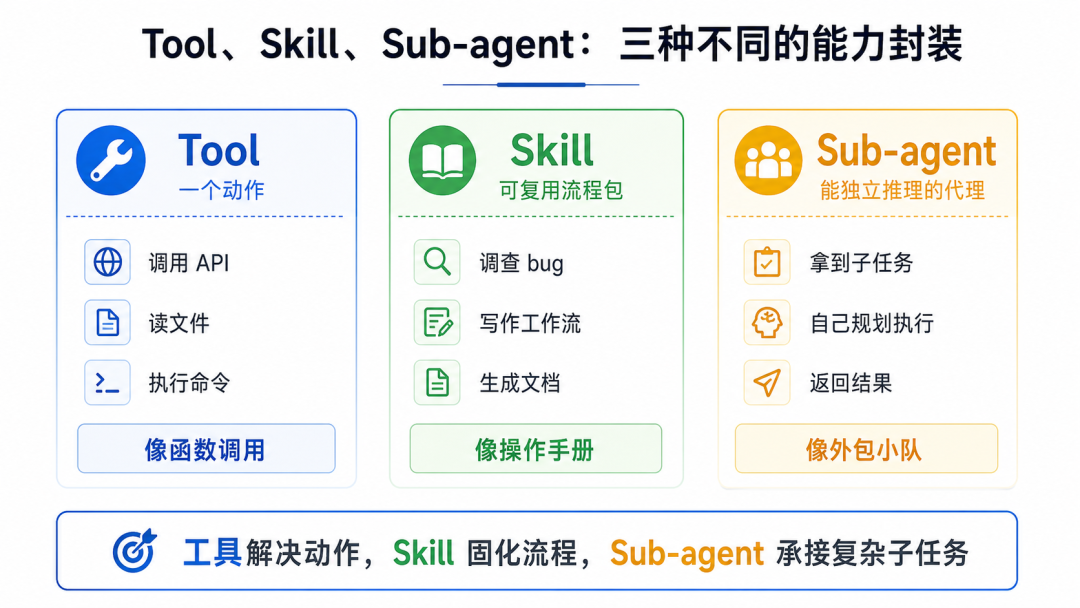
这篇文章里还有一个我很关注的点:Tool、Skill、Sub-agent 的边界。
这几个词在不同框架里经常混着用,但按工程实现来看,确实应该区分。
Tool 是一个动作。
比如调用 API、读文件、执行命令、查数据库、搜索网页。
它更像函数调用。
Skill 是一套可复用的任务知识包。
比如“调查这个 bug 并形成修复方案”“把这篇文章转成我的写作风格”“生成一份可发布的 PPT”。
Skill 不是单个动作,而是把流程、规则、经验、模板打包起来,让 Agent 下次不用重新学习。
Sub-agent 是能独立推理的代理。
它拿到一个子任务,可以自己分析、使用工具、继续拆任务,最后返回结果。它不是函数,也不是说明书,而是一个具备独立执行能力的小 Agent。
这三个东西在实践中的区别很关键。
如果只是查一个接口,用 tool。
如果是重复流程,用 skill。
如果是需要独立判断、调研、执行和汇总的复杂子任务,用 sub-agent。
我之前做写作系统时,其实就是把“从一篇文章到唐斩风格分享”的流程做成了 Skill。它不只是一个 prompt,而是一套工作流:抓取、结构化、判断、选题、成文、质检。
这就是 Skill 的价值。
5、训练侧术语,普通开发者先理解边界
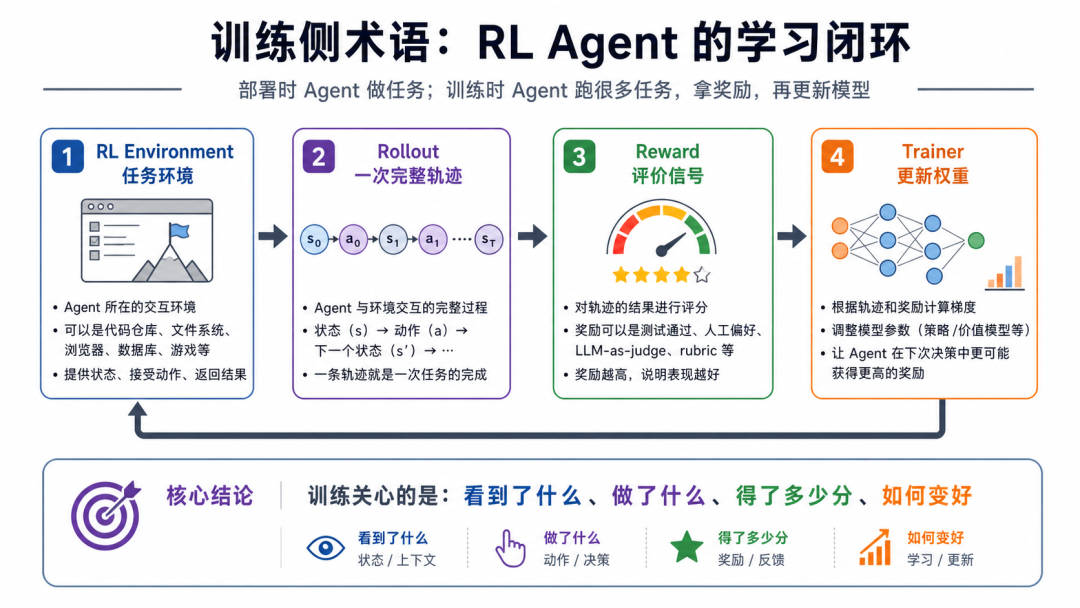
文章最后讲了一组训练侧术语:
- RL Environment
- Trainer
- Rollout
- Reward
如果你不是做模型训练的,可以不用一上来就深挖,但要理解它们和部署侧 Agent 的区别。
部署时,我们更关心 Agent 能不能完成任务。
训练时,系统会让 Agent 跑很多任务,把每次完整运行记录下来,也就是 rollout。然后根据 reward 评分,再由 trainer 更新模型权重。
Environment 就是 Agent 交互的环境,可以是文件系统、浏览器、代码仓库、游戏环境,也可以是一个可验证任务集合。
Reward 是学习信号,可以是测试是否通过,也可以是人工偏好、LLM-as-judge,或者一组 rubric。
这部分对 AI 编程也有启发。
我们现在用 Codex、Claude Code 跑任务时,本质上也在构造一个“环境”和“验证信号”。
比如:
- 测试通过就是 reward
- lint 通过就是 reward
- bug 复现被修掉就是 reward
- E2E 流程跑通就是 reward
虽然我们没有训练模型权重,但我们在训练自己的工作流。
6、对程序员的启发
总结一下,我觉得这篇文章最有价值的地方,不是给大家背术语,而是帮我们把 Agent 工程拆清楚。
以后看一个 AI 编程工具,不要只问:
这个模型强不强?
还要问:
- 它的 harness 怎么设计?
- 它怎么管理上下文?
- 它怎么执行工具?
- 它什么时候停止?
- 它怎么处理错误?
- 它有没有长期记忆?
- 它能不能沉淀 skill?
- 它能不能调用 sub-agent?
- 它有没有可验证的 reward 信号?
这些问题,比“prompt 怎么写”更接近真正的 Agent 工程。
我的观点是,未来程序员要补三层能力。
第一层,继续理解模型能力。知道不同模型的边界和适用场景。
第二层,学习 Harness Engineering。知道怎么让模型和工具、上下文、循环、验证器组成一个可靠系统。
第三层,沉淀自己的 Skill 和工作流。把自己重复做的事情固化下来,让 Agent 越用越像自己的外脑和团队。
短期看,这些术语只是讨论 AI Agent 的共同语言。
长期看,它们会变成 Agent 工程的基础概念。
就像以前后端工程师必须理解数据库、缓存、消息队列、事务、监控一样,未来 AI 工程师也要理解 model、scaffold、harness、context、tool、skill、sub-agent、reward。
不会这些词,不一定不能用 AI。
但想把 AI 用到生产力工具和真实业务里,迟早要把它们搞清楚。
原文地址:https://huggingface.co/blog/agent-glossary
我是唐斩,AI知识库专家。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号