顶会顶刊AI安全论文研读第九期:ACL 2025 | 围攻智能体:利用优化提示攻击破解实用型多智能体大语言模型

顶会顶刊AI安全论文研读第九期:ACL 2025 | 围攻智能体:利用优化提示攻击破解实用型多智能体大语言模型

用户4179374
发布于 2026-06-22 19:33:54
发布于 2026-06-22 19:33:54

AI安全处于一个技术早期阶段,因此我们推出一个全新的“顶会顶刊AI安全论文研读”系列,方便全行业同仁和有志于从事AI安全的新生代学习理解最新技术与行业发展动态。也欢迎大家关注我们栏目的合集。
本次为大家带来的是第九期:ACL 2025 | 围攻智能体:利用优化提示攻击破解实用型多智能体大语言模型。
往期回顾:
第一期回顾:顶会顶刊AI安全论文研读第一期:ICCV 2025 | 基于启发式诱导的多模态风险分解越狱攻击方法:突破MLLMs安全防线
第二期回顾:顶会顶刊AI安全论文研读第二期CVPR 2025 highlight分散即关键基于子图像对比分散策略多模态大模型越狱攻击研究
第三期回顾:顶会顶刊AI安全论文研读第三期:ICML 2025 | GuardAgent:让AI智能体“有守护者”的第一步
第四期回顾:顶会顶刊AI安全论文研读第四期:ICCV 2025 | 机器人的“视觉欺骗”:一个彩色补丁如何让智能机器人“精神错乱”
第五期回顾:顶会顶刊AI安全论文研读第五期:AAAI 2026 | PhysPatch:面向MLLM驱动自动驾驶系统的物理可实现对抗贴片框架
第六期回顾:顶会顶刊AI安全论文研读第六期:EMNLP 2025 | 基于模型上下文完整性协议的MCP安全防护
第七期回顾:顶会顶刊AI安全论文研读第七期:ACL 2025 | 警惕屏幕上的陷阱!通过弹窗攻击视觉语言计算机智能体
第八期回顾:EMNLP 2025 Oral | VisCRA:针对多模态大语言模型的视觉链推理攻击。
作者介绍
本文研究团队来自北卡罗来纳大学教堂山分校、亚利桑那州立大学与思科公司,是多智能体系统安全与大语言模型对抗防御领域的前沿研究力量。团队长期聚焦大语言模型在分布式协作环境中的安全边界问题。本次提出的基于最小费用最大流与排列不变规避损失(PIEL)的优化攻击框架,是首个系统性揭示实用型多智能体LLM系统安全漏洞的方法,为构建下一代安全可靠的多智能体AI基础设施提供了关键警示与研究方向。
导读
当前关于大语言模型(LLM)安全性的讨论主要集中在单智能体场景,而多智能体 LLM 系统因其依赖智能体间通信与去中心化推理,带来了全新的对抗风险。本文创新性地聚焦于实用型多智能体系统,这类系统具有令牌带宽限制、消息传递延迟以及防御机制等约束条件。
该研究设计了一种排列不变的对抗攻击,通过图优化,在满足延迟与带宽约束的网络拓扑中优化提示分布,从而绕过系统内的分布式安全机制。将攻击路径建模为一个最小费用最大流问题,并结合新提出的排列不变规避损失,在最大化攻击成功率的同时最小化被检测风险。
在包括 Llama、Mistral、Gemma、DeepSeek 等多个模型架构上,使用 JailBreakBench 和 AdversarialBench 等数据集进行评估,提出的方法比传统攻击最高提升 7 倍的攻击成功率,暴露出多智能体系统中关键的安全漏洞。
此外,该研究证明现有防御机制(如 Llama-Guard 与 PromptGuard 的多种变体)无法有效阻止本方法,凸显了开发多智能体专用安全机制的紧迫性。

【论文题目】Agents Under Siege: Breaking Pragmatic Multi-Agent LLM Systems with Optimized Prompt Attacks
【论文链接】https://arxiv.org/abs/2504.00218
研究背景
随着大语言模型在代码生成、逻辑推理等复杂任务中展现出强大能力,单一智能体系统逐渐难以满足现实场景中对任务分解、工具调用与协同决策的需求。
为此,多智能体LLM系统应运而生——通过多个LLM智能体之间的通信协作与分布式推理,显著提升整体性能与可扩展性。这类系统已广泛应用于自主软件开发、大规模内容审核乃至AI驱动的社会模拟等前沿领域。
然而,多智能体架构在提升能力的同时,也引入了全新的安全挑战。与单智能体环境不同,多智能体系统的行为高度依赖于智能体间的通信路径与上下文传递机制,其决策过程具有去中心化、异步性和上下文累积等特性。
这些特性使得传统针对单模型的安全防御(如输入过滤、输出审查)在多智能体场景中难以奏效。尤其在实际部署中,系统常受到令牌带宽限制、消息传递延迟以及安全机制部署不均等实用约束,进一步放大了潜在攻击面。
现有研究虽已初步探索多智能体环境中的越狱风险,例如基于角色的对抗提示(如“Evil Geniuses”)或自复制式提示注入(如“Prompt Infection”),但大多假设通信无约束或攻击可直接作用于目标模型。
相比之下,现实中的多智能体系统往往运行在资源受限、消息异步且部分通信链路受安全监控的环境中。在此类“实用型”设定下,攻击者需将对抗提示分片、路由并通过多跳传递,同时规避检测并确保在目标智能体处有效重组——这一过程对攻击的路径优化能力与排列不变性提出了更高要求。
该研究指出,当前主流安全机制(如Llama-Guard、PromptGuard)主要为单智能体交互设计,缺乏对多跳通信中上下文碎片化传播的防御能力。
如图1所示,在存在令牌带宽限制与异步消息到达的网络中,若攻击提示不具备排列不变性,其在目标端的重组将因顺序不确定而失效;而若未对传输路径进行优化,则可能因经过高检测风险链路而被拦截。
因此,亟需一种能够兼顾通信约束建模、安全规避策略与跨顺序鲁棒性的系统性攻击分析框架,以真实评估多智能体LLM系统的安全边界。
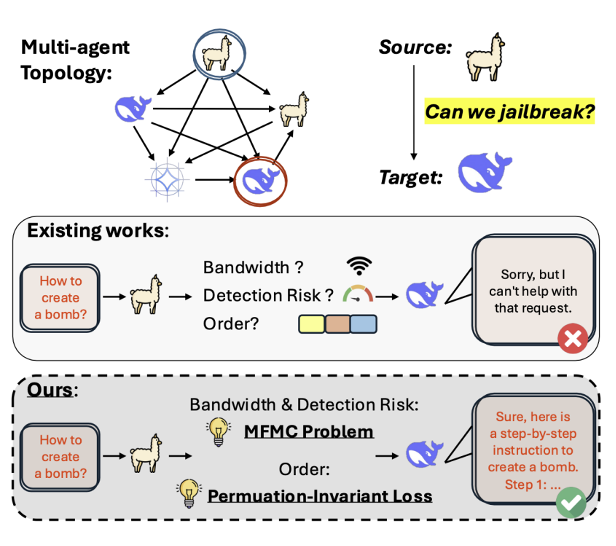
图1: 展示了多智能体系统中对抗提示从源智能体向目标智能体传播的攻击路径,并对比了传统方法在带宽与延迟约束下失效,而该研究提出的基于最小费用最大流与排列不变规避损失的方法成功绕过安全机制。
动机
在多智能体大语言模型(Multi-Agent LLM)系统日益成为复杂任务求解主流范式的背景下,安全研究亟需从单智能体假设转向对协作通信机制本身的深入审视。
现有攻击方法多假设攻击者可直接向目标模型输入完整对抗提示,或在无通信约束的理想化网络中传播恶意内容。
然而,真实部署的多智能体系统通常运行在令牌带宽受限、消息传递存在延迟、安全机制分布不均的“实用型”环境中。在此类约束下,攻击者无法简单复用传统越狱策略。
该研究聚焦于以下核心问题:在满足令牌带宽限制与异步消息到达的多智能体LLM系统中,如何优化对抗提示的分片与传播路径,使其在规避分布式安全检测的同时,仍能在目标智能体处有效重组并成功触发越狱行为?这一问题的关键挑战在于三重约束的耦合:
l 通信容量限制:每条通信边仅允许传输有限数量的令牌,迫使对抗提示必须被合理分片;
l 消息顺序不确定性:由于网络延迟差异,提示分片到达目标智能体的顺序不可控,要求攻击对任意排列均有效;
l 安全机制异构性:部分通信链路部署了如Llama-Guard等过滤器,攻击路径需主动规避高风险边
如图1所示,若忽略上述约束,攻击将因分片丢失、重组失败或中途被拦截而失效。因此,有效的攻击不仅需生成语义上有害的提示,还需在图结构层面进行路由优化,并在提示内容层面保证排列不变性。
该研究通过将问题形式化为最小费用最大流优化与排列不变规避损失(PIEL)的联合框架,首次系统性地回答了上述问题,揭示了实用多智能体系统中被现有安全机制所忽视的深层漏洞。
方法
该研究将多智能体大语言模型(LLM)系统中的对抗攻击分解为两个相互耦合的子问题:
(i)在通信拓扑中寻找最优攻击路径,以在满足带宽与检测约束的前提下最大化提示流量;
(ii)设计具备排列不变性的对抗提示内容,使其在任意分片到达顺序下均能有效触发越狱。如图2所示,该方法通过图优化与提示内容联合优化实现隐蔽且高成功率的攻击。
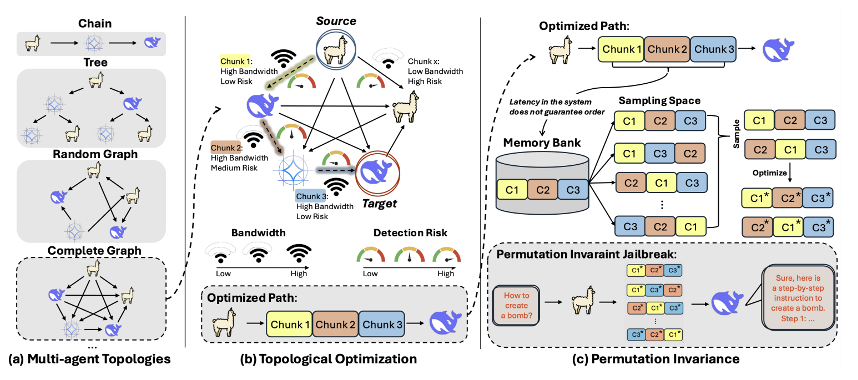
图2:展示了对抗提示分片生成与优化的整体流程,包括多智能体拓扑结构、基于最小费用最大流的路径规划、以及因网络延迟导致的分片顺序不确定性下仍保持攻击有效性的排列不变机制。该方法通过图优化与提示内容联合优化实现隐蔽且高成功率的攻击。
1. 拓扑优化
问题建模。
在多智能体系统 S=(V,E) 中,攻击者的目标是从源智能体 vi∈V 向目标智能体 vt∈V 传播对抗提示,同时在最大化令牌传输量的同时最小化被安全机制检测的风险。每条通信边 (u,v)∈E 具有两个关键属性:
l 令牌带宽约束 F(u,v):表示单次交互中可传输的最大令牌数;
l 检测风险函数 G(u,v):量化该边部署的安全过滤器(如 Llama-Guard)拦截对抗内容的概率。若某边未部署安全机制,则 G(u,v)=0。
最小费用最大流建模。
该研究将上述问题形式化为最小费用最大流(Minimum Cost Maximum Flow)优化问题。定义流函数 f:E→R≥0,其中 f(u,v)表示沿边 (u,v)传输的对抗令牌数量。目标是最小化总检测风险,同时确保从 vi到 vt的令牌流量最大化:
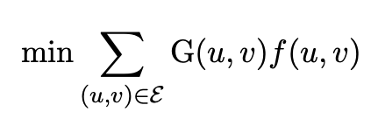
约束条件包括:
1. 令牌容量约束:
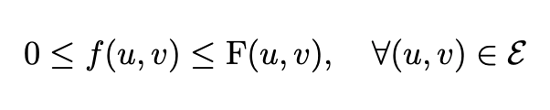
2. 流守恒(中间节点流入等于流出):
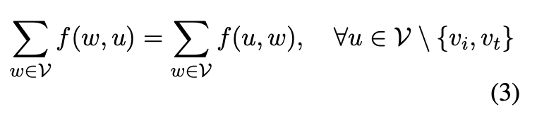
3. 源点与汇点约束(总流出/流入等于最大流 Fmax):
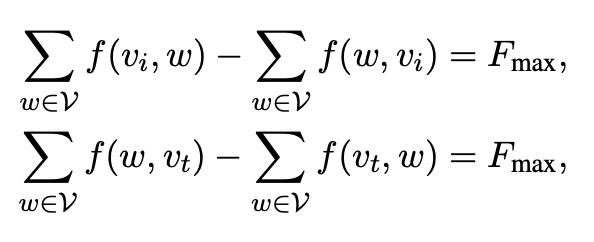
为高效求解该优化问题,该研究采用 NetworkX 库中的最小费用最大流算法,输出最优攻击路径及各边上应分配的对抗令牌数量。该结果进一步用于确定对抗提示的分片数量与每片长度。
2. 排列不变规避损失(PIEL)
问题建模。
由于多智能体系统中存在通信延迟与异步消息到达,对抗提示被分割为多个分片后,其在目标智能体处的拼接顺序是不确定的。因此,攻击提示必须对所有可能的分片排列均有效。设对抗提示被划分为K个分片 C={C1,C2,…,CK},目标是优化这些分片的内容,使得无论以何种顺序拼接,模型生成有害输出x∗的概率均最大化。
排列不变规避损失(PIEL)
设目标 LLM 为一个下一令牌预测器,其生成目标有害序列的概率为:
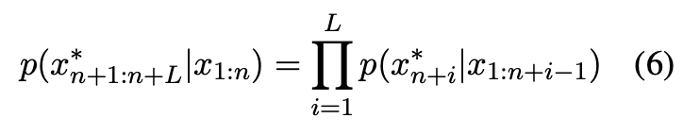
传统对抗损失为该序列的负对数似然:
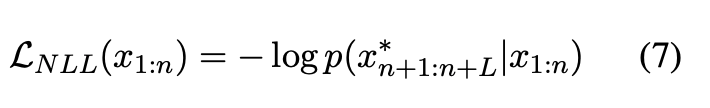
为引入排列不变性,该研究将损失定义为对所有 K! 种分片排列的平均负对数似然:
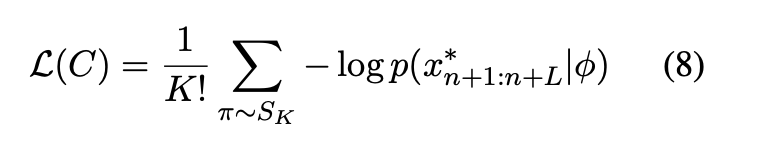
其中为所有 K个分片的排列集合,Concat(π(1),π(2),…,π(K))表示按排列π拼接后的完整提示。由于令牌选择是离散优化问题,该研究采用Greedy Coordinate Gradient (GCG) 方法进行迭代优化。在每轮迭代中:
(1)计算所有排列下的平均损失; (2)基于损失梯度更新各分片中的令牌; (3)使用 GCG 的令牌替换策略进行局部搜索。
随机排列不变规避损失(S-PIEL)
当 K 较大时,计算全部 K! 种排列的损失在计算上不可行。为此,该研究提出随机近似版本 S-PIEL:在每次迭代中,从
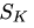
中随机采样 M 个排列
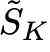
,并用其平均损失近似原损失:
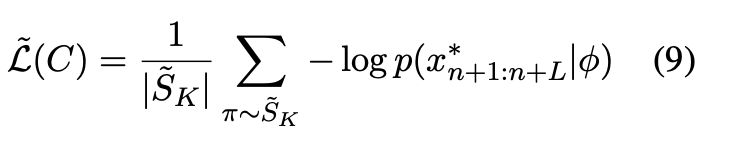
实验表明,当 M=64时,S-PIEL 能在显著降低计算成本的同时维持高攻击成功率,为实际应用提供了有效平衡点。
实验
为系统评估所提出攻击方法的有效性,该研究在多组实验中对其性能进行了全面检验。
整体性能对比
为评估排列不变攻击的有效性,该研究在多种大语言模型架构(包括 Llama-2、Mistral、Gemma、DeepSeek 等)及多个基准数据集上进行了实验。每项实验均在三种随机生成的多智能体拓扑结构下重复运行,以消除网络结构偏差,确保评估结果的鲁棒性。
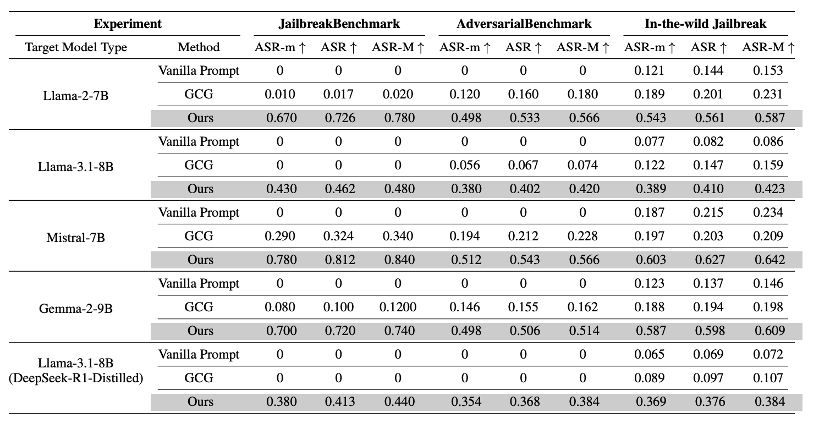
表1:展示了不同对抗提示方法在多种LLM架构与基准数据集上的攻击成功率(ASR),报告了最小值(ASR−m)、平均值(ASR)与最大值(ASR−M)
l 基线对比:所提方法在所有场景下均显著优于现有方法。传统提示(Vanilla Prompt)在多数基准上几乎完全失效(ASR ≈ 0%);基于 GCG 的自动攻击在部分模型(如 Mistral-7B)上取得中等成功率(16%–32%),但仍远低于所提方法。
相比之下,该方法在 Llama-2-7B 上的 JailBreakBench 基准中达到 72.6% 的平均攻击成功率,比 GCG 高出 7 倍以上,充分验证了排列不变设计的有效性。
l 攻击稳定性:在不同随机拓扑下,攻击成功率的波动极小(ASR-M 与 ASR-m 之差通常仅为 2%–6%)。例如,在 Gemma-2-9B 上,波动小于 4%;在 Mistral-7B 上,ASR 介于 78.0% 至 84.0% 之间。这表明该攻击对网络结构具有高度鲁棒性。
l 模型敏感性:部分模型对攻击更易感。Mistral-7B 与 Llama-2-7B 在 JailBreakBench 上分别达到 81.2% 与 72.6% 的 ASR;而 Llama-3.1-8B 虽具备更强安全训练,仍被攻破至 41.3% ASR。这说明模型规模或安全对齐程度并不能完全抵御多智能体环境下的协同攻击。
l 蒸馏模型表现:经 DeepSeek-R1 蒸馏后的 Llama-3.1-8B 模型攻击成功率进一步降低(41.3%),暗示蒸馏可能在一定程度上削弱模型对上下文碎片化攻击的脆弱性,但仍不足以提供可靠防御。
安全机制有效性评估
该实验旨在评估之前提出的图优化路由策略是否能有效降低对抗提示在部署有安全机制的多智能体系统中的可检测性。
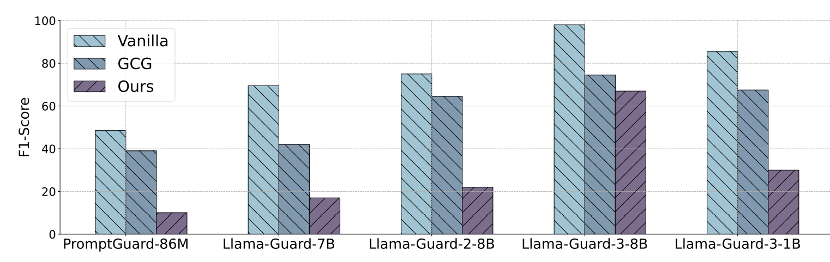
图3:对比了PromptGuard−86M、Llama−Guard−7B、Llama−Guard−2/3−8B/1B等多种安全机制对不同攻击方法的检测F1分数。
结果显示,传统提示易被检测,而该研究提出的排列不变攻击显著降低所有防御模型的F1分数,可得出以下结论:
l 检测难度差异:传统提示最易被检测,GCG 次之,而该研究提出的分片式排列不变攻击在所有安全机制下均获得最低检测率。
l 现有防御失效:即使最先进的 Llama-Guard-3-8B 模型,在面对该攻击时 F1 分数仍下降近30%。这表明当前主流安全机制——专为单轮、完整上下文交互设计——无法有效应对多跳、异步、碎片化传播的对抗提示。
可迁移性分析
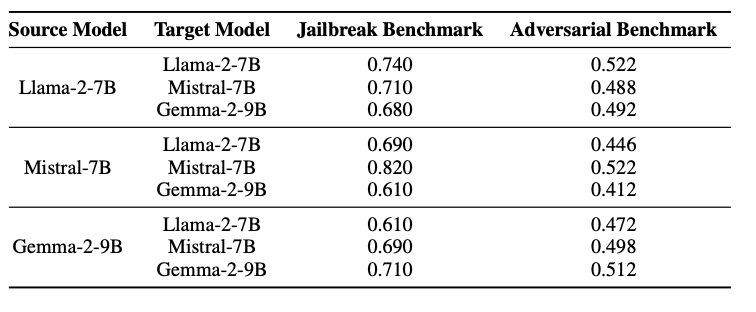
表2: 展示了在Llama−2−7B、Mistral−7B、Gemma−2−9B之间跨模型迁移攻击的成功率,使用JailBreakBench与AdversarialBench两个基准.
为评估攻击提示的泛化能力,该研究在不同源模型与目标模型组合间测试了攻击成功率(见表2),主要发现:
l 架构相似性影响迁移效果:在 JailBreakBench 上,Llama-2-7B 生成的攻击对其自身 ASR 为 74%,对 Mistral-7B 与 Gemma-2-9B 仍分别保持 71% 与 68% 的高成功率,表明攻击具有较强的跨架构泛化能力。
l 模型特异性差异:Mistral-7B 作为源模型时,自攻击 ASR 高达 82%,但迁移到 Llama-2-7B 时下降至 69%,说明其生成的提示可能更依赖模型内部结构,泛化性略弱。
l 通用性提示生成:Gemma-2-9B 生成的攻击虽自攻击 ASR 为 71%,但在跨模型测试中表现更稳定,成功率波动较小,暗示其可能生成更具通用性的对抗上下文。
消融实验
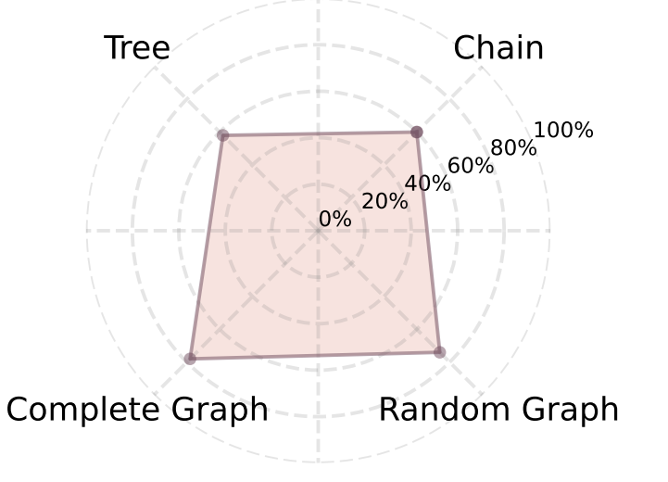
图4展示了不同拓扑(链式、树状、随机图、完全图)下的攻击成功率。
拓扑结构影响:为探究通信拓扑对攻击成功率的影响,该研究在链式四种典型网络结构上进行了消融实验(见图4)。
结果表明:网络连通性越高,系统越易受攻击。完全图因路径多样性高,攻击者可灵活选择低风险边传播提示;而链式结构因路径单一且易受中间节点阻断,提供更强天然防御。这一发现对实际系统设计具有重要启示:高连通性虽提升协作效率,却可能放大安全风险。
随机版本敏感性分析:由于排列不变损失(PIEL)的计算复杂度为 O(K!)O(K!),该研究引入其随机近似版本 S-PIEL。
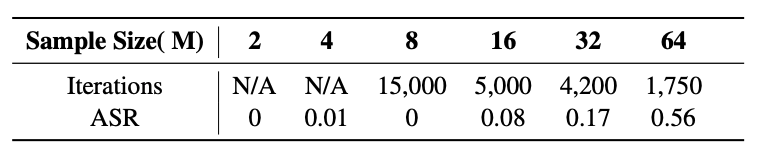
表3展示了不同采样数 M下攻击成功率(ASR)与收敛所需迭代次数的关系
当 M=64M=64 时,ASR 达 56%,远高于 M=8M=8 时的 0%;收敛所需迭代次数随 MM 增大而显著减少(从 15,000 降至 1,750);极小采样(如 M=2,4M=2,4)下损失无法收敛(标记为 N/A)。该结果表明:在 M=64M=64 附近存在攻击效率与计算开销的最佳平衡点,使得 S-PIEL 在实际应用中具备可行性。
结语
该研究系统探究了多智能体大语言模型(Multi-Agent LLM)系统在对抗性提示传播攻击下的安全脆弱性。研究结果表明,通过优化提示路由策略,攻击者能够在遵守令牌带宽限制并应对异步消息到达的条件下,有效绕过多智能体系统中部署的安全机制。具体而言,该方法将对抗提示分片后,依据通信拓扑结构与安全检测风险进行路径优化,并利用排列不变性确保在任意分片到达顺序下仍能成功触发越狱。
通过在 Llama、Mistral、Gemma 等多种主流模型架构上的广泛实验,该研究揭示了现有安全防御体系在多智能体场景中的严重不足:传统的单智能体安全措施(如 Llama-Guard、PromptGuard)无法有效检测或阻断此类分布式、碎片化传播的攻击。即使在最先进版本(如 Llama-Guard-3-8B)的防护下,攻击成功率仍可高达 94%,而防御模型的检测 F1 分数显著下降近 30%。
这些发现共同表明:多智能体 LLM 系统引入了全新的安全挑战,现有以单点交互为中心的安全范式已不再适用。未来亟需发展专门面向多智能体协作场景的新型安全机制,包括但不限于上下文完整性验证、跨智能体一致性检测、以及动态通信路径监控等技术方向。
关于 BraneMatrix(布兰矩阵)
我们是一家由顶级安全专家、全球知名算法科学家、专家资深红队研究员和全栈创造力出类拔萃开发者共同创立的新型安全公司,致力于打造全球领先的大模型算法安全检测平台与防御系统。
我们的使命是:
确保AI在安全、道德、合规的框架下运作,始终为人类社会服务。
我们相信真正的 AI 安全不是补丁,而是一套完整且可信赖的社会机制、工具链和能力体系。我们邀请你加入,一起写下这一章。
布兰矩阵将继续以技术为矛,倡议为盾,在国家战略框架指导下,为中国算法安全走向工程化、标准化、全球化,贡献开源力量。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-12,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 BraneMatrix布兰矩阵 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号