顶会顶刊AI安全论文研读第十七期:AAAI 2026 | Phantom Menace:探索并增强VLA模型对物理传感器攻击的鲁棒性

顶会顶刊AI安全论文研读第十七期:AAAI 2026 | Phantom Menace:探索并增强VLA模型对物理传感器攻击的鲁棒性

用户4179374
发布于 2026-06-22 19:46:13
发布于 2026-06-22 19:46:13

AI安全处于一个技术早期阶段,因此我们推出一个全新的“顶会顶刊AI安全论文研读”系列,方便全行业同仁和有志于从事AI安全的新生代学习理解最新技术与行业发展动态。也欢迎大家关注我们栏目的合集。
本次为大家带来的是【第17期】AAAI 2026 | Phantom Menace:探索并增强VLA模型对物理传感器攻击的鲁棒性
往期回顾:
第一期回顾:顶会顶刊AI安全论文研读第一期:ICCV 2025 | 基于启发式诱导的多模态风险分解越狱攻击方法:突破MLLMs安全防线
第二期回顾:顶会顶刊AI安全论文研读第二期CVPR 2025 highlight分散即关键基于子图像对比分散策略多模态大模型越狱攻击研究
第三期回顾:顶会顶刊AI安全论文研读第三期:ICML 2025 | GuardAgent:让AI智能体“有守护者”的第一步
第四期回顾:顶会顶刊AI安全论文研读第四期:ICCV 2025 | 机器人的“视觉欺骗”:一个彩色补丁如何让智能机器人“精神错乱”
第五期回顾:顶会顶刊AI安全论文研读第五期:AAAI 2026 | PhysPatch:面向MLLM驱动自动驾驶系统的物理可实现对抗贴片框架
第六期回顾:顶会顶刊AI安全论文研读第六期:EMNLP 2025 | 基于模型上下文完整性协议的MCP安全防护
第七期回顾:顶会顶刊AI安全论文研读第七期:ACL 2025 | 警惕屏幕上的陷阱!通过弹窗攻击视觉语言计算机智能体
第八期回顾:EMNLP 2025 Oral | VisCRA:针对多模态大语言模型的视觉链推理攻击。
第九期回顾:顶会顶刊AI安全论文研读第九期:ACL 2025 | 围攻智能体:利用优化提示攻击破解实用型多智能体大语言模型
第十期回顾:顶会顶刊AI安全论文研读第十期:ACL Findings 2025 | Mousetrap:利用迭代混沌链欺骗大型推理模型越狱
第十一期回顾:顶会顶刊AI安全论文研读第十一期:ACL 2025 | 内存提取攻击:揭示LLM智能体内存中的隐私风险
第十二期回顾:顶会顶刊AI安全论文研读第十二期:EMNLP 2025 | AGENTVIGIL:面向黑盒大语言模型智能体的通用自动化红队测试框架
第十三期回顾:顶会顶刊AI安全论文研读第十三期:ICLR 2025 | 坏机器人:物理世界中具身大语言模型的越狱攻击
第十四期回顾:NeurIPS 2025 | BadVLA:基于目标解耦优化的视觉-语言-动作模型后门攻击研究
第十五期回顾:顶会顶刊AI安全论文研读第十五期:AAAI 2026 | MPMA:针对模型上下文协议(MCP)的偏好操纵攻击
第十六期回顾:顶会顶刊AI安全论文研读第十六期:AAAI2026 | Fact2Fiction: 针对智能体事实核查系统的定向投毒攻击
作者介绍
本文作者团队来自浙江大学与香港科技大学,在多模态具身智能与AI安全领域具有深厚研究基础。团队聚焦真实世界中的模型安全问题,尤其是传感器层面的物理攻击。
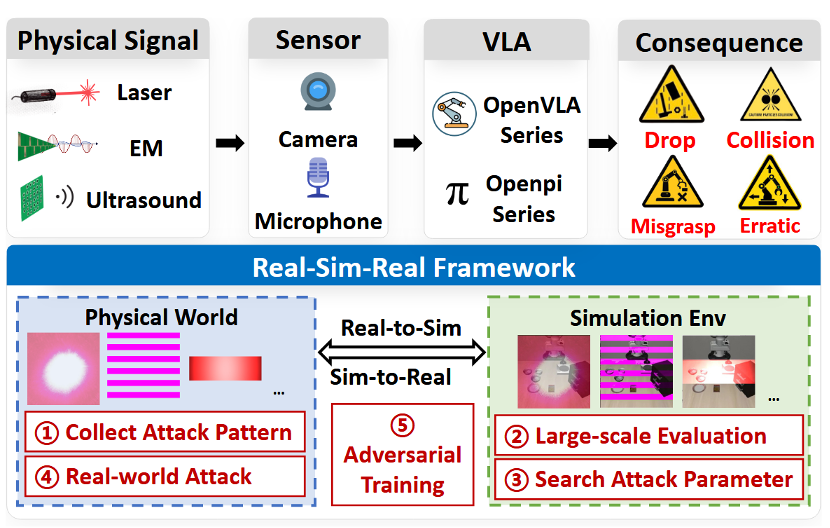
本文首次揭示 Vision-Language-Action(VLA)模型在激光、电磁与超声等物理信号干扰下的系统性脆弱性,并提出“Real-Sim-Real”框架实现从仿真到真实机器人的闭环验证,为VLA模型的安全部署提供了关键参考。
导读
近年来,Vision-Language-Action(VLA)模型作为具身智能的重要范式,正在推动机器人系统向端到端、多模态感知–决策–执行一体化快速发展。
通过融合视觉、语言与动作信息,VLA 模型在复杂操作任务、长时序规划以及开放环境交互中展现出强大的能力。然而,这类模型对传感器输入的高度依赖,也使其在真实物理世界中的安全性面临新的挑战。尽管已有研究开始关注 VLA 模型在数字域中的对抗脆弱性,但针对物理世界中传感器层攻击的系统性研究仍然严重不足。
本文首次系统性地研究了针对 VLA 模型的物理传感器攻击(Physical Sensor Attacks)问题,揭示激光、电磁干扰与超声等真实物理信号,如何在不接触模型本身的情况下,直接通过摄像头与麦克风破坏 VLA 系统的感知与决策过程。
不同于以往依赖图像扰动或文本注入的数字攻击,本研究从真实物理攻击路径出发,表明即便模型在标准评测中表现稳健,其在现实部署中仍可能出现灾难性失效。为此,本文提出了一个新的系统性评测框架——Real-Sim-Real。该框架围绕“真实攻击模式—高保真仿真—真实机器人验证”的闭环流程展开,核心包含三项关键设计:
• 物理攻击建模与仿真(Physics-based Attack Simulation):基于真实攻击原理,构建六类摄像头攻击与两类麦克风攻击的高保真仿真模型,并支持不同攻击强度的参数化搜索。
• 大规模跨模型评测(Large-scale Robustness Evaluation):在多种主流 VLA 架构与任务设置下系统评估攻击影响,量化不同模型、不同任务对传感器攻击的敏感性差异。
• 仿真到现实验证(Sim-to-Real Validation):将仿真中搜索到的攻击参数直接迁移至真实机器人系统,验证攻击效果与风险后果。
实验结果表明,当前主流 VLA 模型在多种物理传感器攻击下均表现出显著脆弱性,轻则任务失败,重则引发错误抓取、物体坠落、机械臂碰撞与异常运动等危险行为。进一步分析发现,不同模型结构与任务类型对攻击的敏感性存在系统性差异,表明传感器安全已成为制约 VLA 实际部署的关键瓶颈。
在此基础上,本文提出了一种基于对抗训练(Adversarial Training)的防御策略,通过在训练阶段引入物理攻击数据,显著提升模型在分布外物理扰动下的鲁棒性,同时基本保持其在干净环境中的性能。该研究不仅揭示了 VLA 模型在真实物理世界中的潜在安全隐患,也强调了在具身智能系统中,将物理安全性纳入模型评测与训练流程的迫切性。

【论文题目】Phantom Menace: Exploring and Enhancing the Robustness of VLA Models Against Physical Sensor Attacks
【论文链接】https://arxiv.org/abs/2511.10008
【代码链接】https://github.com/ZJUshine/Phantom-Menace
研究背景
近年来,Vision-Language-Action(VLA)模型作为具身智能的重要范式,正在推动机器人系统向端到端多模态决策演进。通过融合视觉、语言与动作信息,VLA 模型能够直接将传感器输入映射为物理行为,在复杂操作与开放环境中展现出强大能力,并被逐步部署于真实世界场景。
然而,VLA 模型对摄像头、麦克风等物理传感器的高度依赖,也使其安全性面临新的挑战。一旦传感器层受到干扰,模型即便未被直接攻击,其端到端决策过程仍可能被系统性误导,进而引发任务失败甚至危险行为。现有研究主要关注数字域输入扰动,而对真实世界中通过物理信号注入传感器所产生的安全风险缺乏系统分析。
尽管安全领域已提出多种针对摄像头与麦克风的物理攻击方法,但真实物理实验难以规模化,纯仿真评测又难以准确反映物理攻击效果。这一矛盾使得 VLA 模型在真实部署中的安全边界长期缺乏有效评估。
为此,本文提出 Real-Sim-Real 框架,通过将真实物理传感器攻击进行高保真建模,引入仿真环境开展大规模鲁棒性评测,并将关键攻击参数回迁至真实机器人系统进行验证,形成“真实—仿真—真实”的闭环流程,如图1所示。
该框架为系统性研究物理传感器攻击对 VLA 模型端到端行为的影响提供了可扩展的方法基础。在此基础上,本文提出了一种基于对抗训练(Adversarial Training)的防御策略,通过在训练阶段引入物理攻击数据,显著提升模型在分布外物理扰动下的鲁棒性,同时基本保持其在干净环境中的性能。
动机
随着 VLA模型逐步走向真实世界部署,其安全评估仍主要停留在数字域输入扰动的理想化假设之上,难以反映现实环境中的真实风险。相比直接操控模型输入,现实中的攻击更可能通过激光、电磁干扰或超声等物理信号作用于摄像头和麦克风,从传感器层间接影响模型感知与决策,而这一攻击面在现有研究中长期被忽视。
与此同时,真实物理攻击难以规模化评测,纯仿真方法又难以准确刻画物理效应,导致我们尚不清楚不同物理攻击、模型架构与任务设置对 VLA 端到端行为的系统性影响。基于此,本文的动机在于弥合真实物理攻击与可扩展评测之间的鸿沟,系统揭示物理传感器攻击对 VLA 模型安全性的实际威胁,并为其稳健部署提供可靠的评测与防御依据。
方法
随着VLA模型逐步走向真实世界部署,其安全评估仍主要停留在数字域输入扰动的理想化假设之上,难以反映现实环境中的真实风险。相比直接操控模型输入,现实中的攻击更可能通过激光、电磁干扰或超声等物理信号作用于摄像头和麦克风,从传感器层间接影响模型感知与决策,而这一攻击面在现有研究中长期被忽视。
与此同时,真实物理攻击难以规模化评测,纯仿真方法又难以准确刻画物理效应,导致我们尚不清楚不同物理攻击、模型架构与任务设置对 VLA 端到端行为的系统性影响。基于此,本文的动机在于弥合真实物理攻击与可扩展评测之间的鸿沟,系统揭示物理传感器攻击对 VLA 模型安全性的实际威胁,并为其稳健部署提供可靠的评测与防御依据。本文总共提出了六个针对摄像头的攻击和两个针对针对麦克风的攻击,如图2所示。
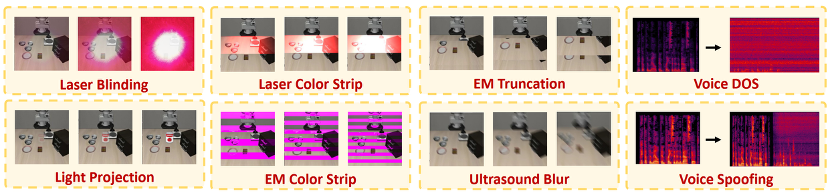
图2: 实现并模拟八种传感器攻击,包括六个目标摄像机和两个目标麦克风,涵盖激光、光线、声学和电磁信号
1) 引入
• 威胁场景:本文考虑真实部署中的 VLA 机器人系统,其通过摄像头与麦克风感知环境并执行动作,广泛应用于制造、医疗等场景。攻击者可通过向传感器注入激光、电磁或超声等物理信号实施攻击。
• 攻击目标:攻击者的目标是干扰摄像头或麦克风输入,诱导 VLA 系统产生异常或定向错误行为,从而导致任务失败甚至潜在风险。
• 攻击能力:攻击者仅具备对传感器的物理信号注入能力,无法直接操控模型输入或进行任何形式的数字域攻击(如噪声注入、压缩或模糊)。
• 模型知识:攻击者仅拥有对 VLA 模型的黑盒访问权限,不了解模型结构、训练数据或参数,也不了解具体使用的传感器类型与感知算法。
2) 针对麦克风的攻击
针对麦克风的攻击利用其物理感知与信号处理链路中的非线性特性,在不产生可听声音的前提下,将恶意音频信息注入系统。整体上,麦克风接收到的音频信号可以建模为原始语音信号与恶意信号的叠加,即:
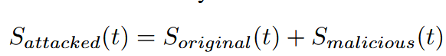
由于恶意信号位于人类不可感知的频段或以物理方式注入,系统在感知层面难以区分其来源,从而为攻击提供了隐蔽入口。本文主要研究两类典型的麦克风物理攻击:语音拒绝服务攻击(Voice DoS)与语音欺骗攻击(Voice Spoofing)。
1. 语音拒绝服务攻击
该攻击通过向麦克风注入高强度的超声信号,使其传感器或放大电路进入饱和状态,从而破坏正常语音信号的采集。攻击信号虽然对人类听觉不可感知,但会显著降低麦克风输出的信噪比,导致语音识别系统无法正确解析用户指令。
在实现上,攻击者首先在数字域生成高能量噪声信号,随后利用超声扬声器将其注入麦克风,并记录麦克风在物理条件下的响应;最终将记录到的恶意噪声与原始语音指令叠加,用于仿真与评测 Voice DoS 对 VLA 系统的影响。
2. 语音欺骗攻击
语音欺骗攻击的目标并非破坏语音输入,而是向系统注入精确的恶意语义内容。攻击者可通过调制激光或超声信号,将构造好的语音指令直接注入麦克风,实现对原始语音的附加、替换或细粒度操控。该攻击不仅可以在原有语音指令后附加恶意后缀,还可以对用户指令进行定向修改。
在实现过程中,攻击者首先利用文本到语音(TTS)技术生成恶意语音内容,再通过物理设备将其注入麦克风并记录响应,最终将记录到的恶意语音作为后缀叠加到原始语音信号中,以模拟真实世界中的语音欺骗场景。
总体而言,这两类攻击分别从可用性破坏与语义操控两个维度揭示了麦克风作为 VLA 系统关键输入通道所面临的安全风险,表明即便攻击者无法直接接触模型输入或内部结构,仅通过物理信号注入也足以显著影响系统的端到端行为。
3) 针对摄像机的攻击
针对摄像机的攻击旨在通过干扰进入镜头的光信号或利用传感器与成像算法本身的脆弱性,操纵模型所感知到的视觉输入。整体上,摄像机捕获的图像可建模为环境光与恶意光信号的叠加,或通过特定攻击变换函数对环境光进行畸变,即:
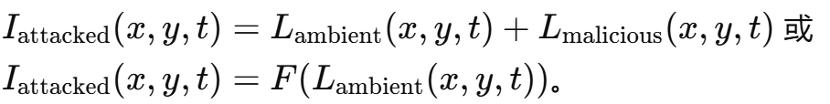
由于这些攻击直接作用于成像过程或底层硬件链路,模型往往难以在感知阶段识别异常来源。本文重点研究了六类具有代表性的摄像机物理攻击,涵盖激光、投影、电磁与超声等不同信号形式。
1. 激光致盲攻击
该攻击通过高功率激光直接照射摄像机的光电传感器,使其进入饱和状态,从而丧失对环境光变化的感知能力。在实现上,首先在真实环境中记录激光照射产生的攻击模式,再将该模式以不同权重叠加到原始图像中,用于模拟不同强度下的致盲效果。
2. 光投影攻击
攻击者利用投影设备将伪造图像投射到环境中,或直接投射至摄像机镜头,使反射或直射光进入成像系统,从而注入虚假视觉信息。该攻击通过记录真实投影图案,并将其以不同位置和强度叠加到原始图像中,模拟现实场景下的视觉欺骗。
3. 激光色条攻击
该攻击利用 CMOS 摄像机的滚动快门特性,通过调制激光在图像中注入彩色条纹,从而破坏局部或整体视觉结构。攻击效果通过调整激光波长、RGB 通道比例及强度进行控制,可产生不同形态和严重程度的色条干扰。
4. 电磁色条与截断攻击
通过向摄像机图像传输接口(如 MIPI CSI-2 总线)注入电磁干扰信号,攻击者可诱发图像传输错误。传输错误会导致部分图像行被丢弃或错误解码,形成彩色条纹;若缓冲区地址被破坏,还可能造成跨帧内容错误拼接,引发图像截断。该类攻击通过控制条纹数量、位置及截断比例来模拟不同攻击强度。
5. 超声模糊攻击
针对配备防抖模块的摄像机,攻击者通过注入超声信号诱发惯性测量单元(IMU)共振,误导防抖算法错误地检测到相机运动,从而触发不必要的运动补偿并导致图像模糊。本文将模糊效果划分为线性、径向与旋转三类,并通过调节模糊幅度来模拟不同强度的攻击。
总体而言,这些摄像机攻击从光学干扰、硬件接口破坏与算法误导等多个层面系统性地破坏视觉输入质量。由于 VLA 模型高度依赖视觉感知进行决策,这类攻击能够在不直接接触模型的情况下,对其端到端行为产生显著甚至灾难性的影响。
实验效果
实验设置
• 数据集和模拟器:实验在 Libero 视觉–语言机器人模拟器中进行,该平台为 VLA 模型提供灵活的评测环境。使用的 Libero 数据集覆盖空间配置变化、物体识别与操控、目标变化以及长时序规划等多种任务类型。
• 目标模型:评测选取了四个代表性 VLA 模型:OpenVLA、OpenVLA-OFT、pi0 和 pi0-fast,涵盖不同结构与训练范式。所有模型均在 Libero 数据集上进行微调,以保证其在模拟环境中的基础性能。
• 评测指标:模型性能通过任务成功率(Task Success Rate, TSR)进行衡量。该指标定义为成功完成任务的回合数占总回合数的比例。
• 攻击参数:在仿真中设置弱、中、强三种攻击强度,并为不同攻击类型配置对应的参数。语音 DoS 攻击使用空指令,语音欺骗攻击附加固定恶意后缀,真实实验直接采用仿真中搜索到的攻击参数,如表1所示。
• 真实世界实验设置:真实实验基于 Franka Panda 机械臂,配备全局摄像头、腕部摄像头及麦克风,语音指令通过 Whisper ASR 转换为文本,如图3所示。通过遥操作采集一小时真实数据对模型进行微调,以适配现实中的抓取与放置任务。
• 模型评测与对抗训练:模型推理在 NVIDIA 4090 GPU 上运行,微调与对抗训练使用 NVIDIA H800 GPU 并采用 LoRA 技术。对抗训练中引入 30% 的攻击数据,攻击类型与强度在多种摄像机攻击和不同强度范围内随机采样。

图3: 真实世界实验设计
在模拟器上的鲁棒性评估
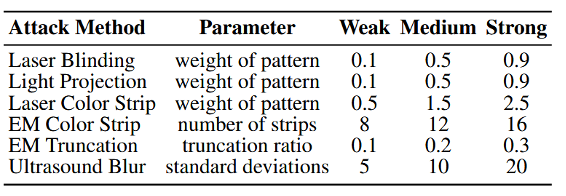
表1:不同攻击强度的攻击参数
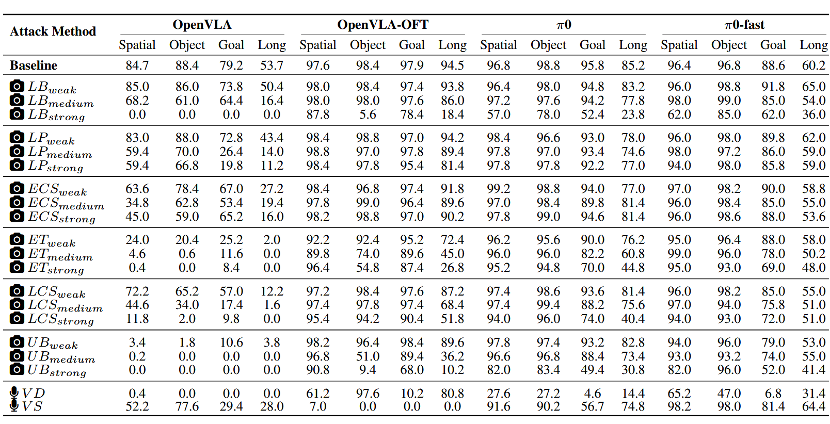
表 2:模拟器中VLA模型在各种传感器攻击下的鲁棒性
1)物理传感器攻击对VLA有效
如表 2 所示,在无传感器攻击条件下,四种 VLA 模型在 Libero 数据集上均表现出较强的基础能力,在 Libero-Spatial 与 Libero-Object 等任务中任务成功率可接近或超过 90%,表明其在理想感知条件下具备稳定的端到端执行能力。
然而,当引入物理传感器攻击后,表 2 显示所有模型的性能均出现显著下降,且退化幅度随攻击类型、攻击强度与任务复杂度而明显变化。在多数设置下,尤其是在强攻击或长时序任务(Libero-Long)中,多个模型的成功率接近崩溃,甚至降至接近 0。该结果清晰表明,尽管 VLA 模型在无攻击评测中表现优异,但其对传感器输入扰动高度敏感,现实部署中的可靠性远低于理想化实验环境所呈现的水平。
2)对VLA的攻击影响各不相同
如表2所示,实验结果表明,不同类型的物理传感器攻击对 VLA 模型的影响存在显著差异。激光致盲(LB)、电磁截断(ET)和超声模糊(UB)等攻击会直接破坏关键视觉特征,在中高强度下显著削弱目标定位与物体识别能力,导致严重任务失败甚至潜在危险行为;相比之下,光投影(LP)、激光色条(LCS)和电磁色条(ECS)主要通过干扰注意力而非摧毁核心视觉信息,因此对任务成功率的影响相对较小。
语音 DoS 攻击的效果高度依赖任务设置,在需要依赖语言区分目标的场景中会使模型完全失效,而在可从视觉上下文推断指令的任务中影响有限。语音欺骗攻击的成功率则与模型的语义理解和指令跟随能力高度相关,采用 LLM 作为骨干的 OpenVLA 与 OpenVLA-OFT 更易受到指令注入影响,其中 OpenVLA-OFT 由于强化了语言调制机制,在该攻击下表现出最显著的性能退化。
3)VLA对传感器攻击表现出不同的鲁棒性
如表2所示,实验结果表明,OpenVLA 对各类物理传感器攻击普遍敏感,在中高强度攻击下性能显著下降,显示其鲁棒性机制不足。OpenVLA-OFT 通过多摄像头融合与本体感知增强了整体稳健性,但在语音欺骗攻击下几乎完全失效,暴露出对语言指令注入的严重脆弱性。
相比之下,pi0 与 pi0-fast 在视觉攻击下表现出更强的抗扰能力,表明其多视觉传感架构有助于维持任务执行,可能依赖于对环境、指令与动作之间关系的隐式记忆。
在真实世界上的鲁棒性
在真实机器人系统中,实验首先验证了各 VLA 模型在无攻击条件下具备稳定的基线性能。随后,按照仿真阶段搜索得到的攻击参数对传感器注入物理攻击,表 3 显示其结果与仿真评测高度一致,验证了 Real-Sim-Real 框架在攻击建模与参数搜索上的有效性。
如图 4 所示,这些物理攻击不仅导致任务失败,还会引发多种具有现实风险的异常行为,包括抓取过程中物体意外坠落、机械臂或夹爪与环境发生碰撞、抓取错误目标以及机械臂出现无序或剧烈运动。上述结果表明,物理传感器攻击在真实部署中具有直接且可观察的危害性,凸显了对 VLA 系统进行现实场景安全评估的必要性。
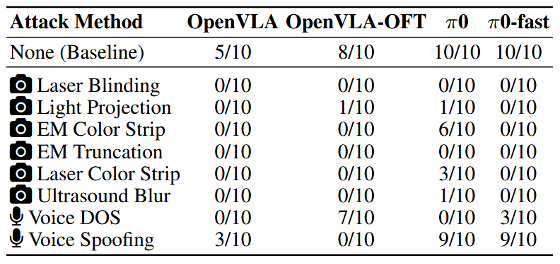
表3:VLA模型在现实世界中的鲁棒性

图4:现实世界的攻击后果
对抗训练结果
如表 4所示,引入对抗训练后,VLA 模型在物理传感器攻击下的鲁棒性显著提升,同时仅对干净数据性能造成有限影响。与表 2 的无防御结果相比,模型在干净数据上的平均性能下降约为 3%,但在中等强度传感器攻击场景中,各模型的任务成功率普遍提升,其中 OpenVLA 的性能提升最为显著,最高可达约 60%。
该结果表明,基于物理攻击数据的对抗训练能够在保持基础能力的同时,有效增强 VLA 模型对分布外物理扰动的适应性。
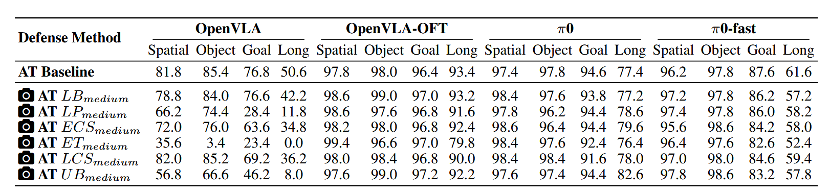
表4:对抗训练之后VLA模型的鲁棒性
结论与展望
本文系统性研究了 Vision-Language-Action(VLA)模型在真实物理世界中面对传感器攻击时的安全性,揭示激光、电磁干扰与超声等物理信号可在不接触模型的情况下严重破坏其端到端行为。
为弥合真实物理攻击难以规模化评测与仿真评测缺乏现实可信度之间的鸿沟,本文提出 Real-Sim-Real 框架,通过真实攻击建模、仿真评测与真实机器人验证的闭环流程,对 VLA 模型的物理鲁棒性进行系统分析。
实验结果表明,在无攻击条件下表现稳健的 VLA 模型,在传感器输入被干扰后往往出现显著性能退化,甚至在强攻击或长时序任务中发生灾难性失效,真实实验进一步验证了仿真结论并揭示了多种具有现实风险的异常行为。
在此基础上,本文探索了基于物理攻击数据的对抗训练防御策略,在仅带来轻微干净性能损失的前提下显著提升了模型鲁棒性。整体而言,该工作首次从端到端系统层面系统揭示了 VLA 模型在物理世界中的安全边界,为其安全评测与可靠部署提供了重要参考。
关于 BraneMatrix(布兰矩阵)
我们是一家由顶级安全专家、全球知名算法科学家、专家资深红队研究员和全栈创造力出类拔萃开发者共同创立的新型安全公司,致力于打造全球领先的大模型算法安全检测平台与防御系统。
我们的使命是:
确保AI在安全、道德、合规的框架下运作,始终为人类社会服务。
我们相信真正的 AI 安全不是补丁,而是一套完整且可信赖的社会机制、工具链和能力体系。我们邀请你加入,一起写下这一章。
布兰矩阵将继续以技术为矛,倡议为盾,在国家战略框架指导下,为中国算法安全走向工程化、标准化、全球化,贡献开源力量。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-07,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 BraneMatrix布兰矩阵 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号