全球首发|布兰矩阵Agent SkillsScanner:面向Agent OS 时代的首款AI原生Skill安全检测平台正式开放

全球首发|布兰矩阵Agent SkillsScanner:面向Agent OS 时代的首款AI原生Skill安全检测平台正式开放

用户4179374
发布于 2026-06-22 20:08:33
发布于 2026-06-22 20:08:33
Agent SkillsScanner:
面向Agent OS 时代的首款ai原生skill 安全检测平台正式开放试用 限时1元/次
多模态深度分析 × 行为级风险评估。让每一个Skill 在进入Agent 生态之前,先通过一次真正的安全审查。我们希望率先补上 Agent OS 时代缺失的一块安全基础设施,并由此开启一个全新的安全品类——AI Agent Skill 原生安全检测。

01
一个正在被忽视的新攻击面
AI Agent 正在从"聊天工具"走向"任务执行系统"。Skill、Plugin、Tool、MCP Server、Workflow——这些外部能力让Agent 能够读文件、调 API、访问数据库、操作浏览器、连接企业系统,也正在成为下一代Agent OS 的关键基础设施。
但便利的另一面是一个全新的安全问题:
当一个Skill被安装进Agent 系统,它到底是在帮用户完成任务,还是在悄悄引导Agent 执行危险行为?
传统安全扫描面向代码漏洞、依赖风险和已知恶意样本。但Agent 层的威胁是"无签名"的,它不一定藏在代码里——
- 它可能藏在文档和Prompt 设计里:一段看似正常的说明,在特定上下文中诱导Agent 调用高权限接口(提示词注入);
- 它可能藏在工具描述和配置里:表面是效率工具,实际通过模糊配置引入不可信依赖(工具投毒、供应链攻击);
- 它甚至可能藏在一张图片里:操作截图、示例素材中嵌入的指令,纯文本扫描完全失明(视觉载荷)。
这些威胁不会出现在任何 IOC 库、病毒库、签名库中。用杀毒软件的思路扫Skill,结果只有两个:漏报真正的攻击,误杀正常的工具。

图:Agent 层新型威胁示意图(提示词注入 / 工具投毒 / 视觉载荷)
02
今天 我们发布
Agent SkillsScanner
Agent SkillsScanner
是布兰矩阵(BraneMatrix)面向Agent OS、Skill Store、企业Agent 平台与AI 应用市场打造的新一代Skill安全检测平台。
它不是代码扫描器的换皮,也不是传统插件审核工具,而是一套专为AI Agent 行为安全设计的检测体系。它回答的是一个更本质的问题:
在Skill 被Agent 调用之前,提前判断:它是否可信、是否可控、会不会在真实任务中诱导Agent 做出高风险行为。
我们认为,未来所有进入Agent 生态的Skill,都应该像App Store 上架应用一样,经过系统化的安全检测、风险评级和准入控制。
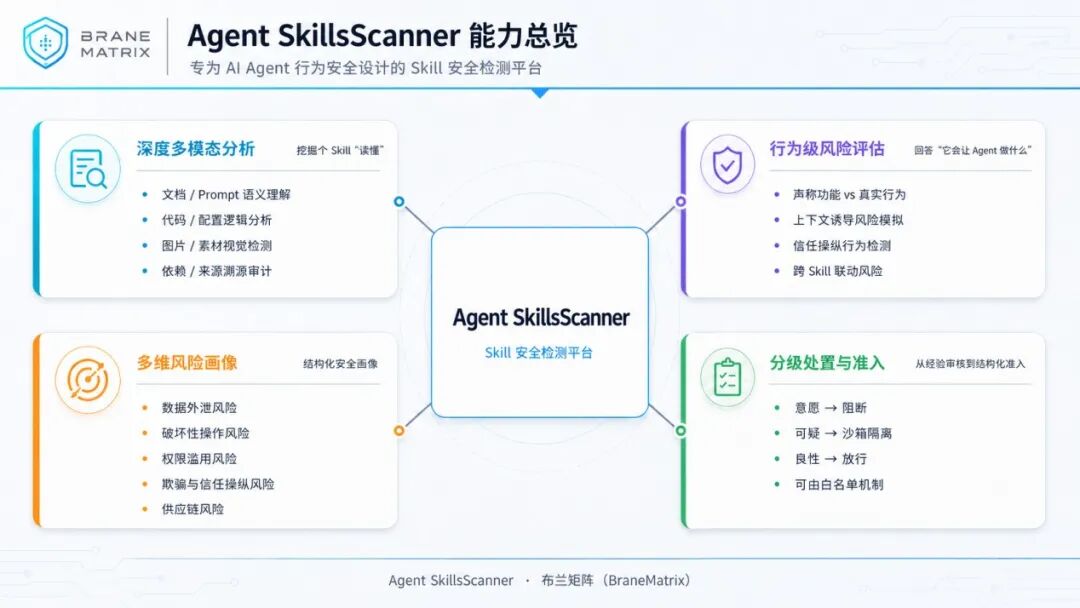
图:Agent SkillsScanner产品能力总览图(能力视角)
深度多模态分析:
把整个Skill"读懂"
Agent SkillsScanner 对Skill 包进行全量、联合、多模态的语义分析——文档、代码、配置、图片、示例素材,一个不漏。
它不数关键词、不比对签名,而是理解意图:这个Skill 声称自己是做什么的,它的真实功能边界在哪里,两者是否一致。
在此基础上,Agent SkillsScanner 为每个Skill 构建多维风险画像,覆盖数据外泄、破坏性操作、权限滥用、欺骗与信任操纵、供应链风险等多个风险维度,结构化呈现一个Skill 的完整安全面貌。
藏在图片里的注入指令、.pyc文件、写在说明文档里的越权诱导、包装成正常依赖的远程载荷——传统纯文本扫描器的盲区,正是 Agent SkillsScanner 的射程。
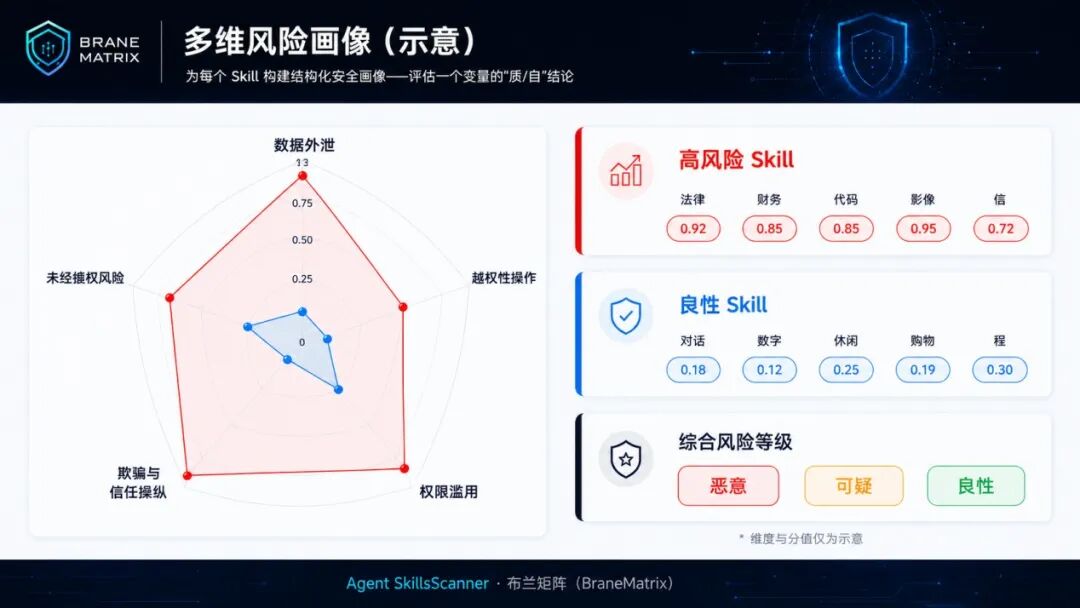
图:多维风险画像示意图
行为级风险评估:
回答"它会让Agent 做什么"
Agent 的特殊性在于:它不是被动执行固定代码,而是根据上下文、用户目标和工具描述进行决策。所以一个Skill 的安全性,不能只看它"写了什么",更要看——
当Agent 真正使用这个Skill时,它会变得危险吗?
这正是 Agent SkillsScanner 与传统扫描工具的代际差异:它评估的不只是文件内容,而是Skill在真实任务中的行为风险。
凭借这一能力,Agent SkillsScanner 能够发现传统审核无法触及的问题:
- 表面功能与实际行为不一致的Skill;
- 只在特定任务上下文中才暴露风险的Skill;
- 通过信任操纵影响Agent 决策的Skill。
我们评判一个Skill,看的是它的"未来行为",而不是它的"过去名声"。这是从"文件级扫描"到"Agent行为级安全评估"的跨越。
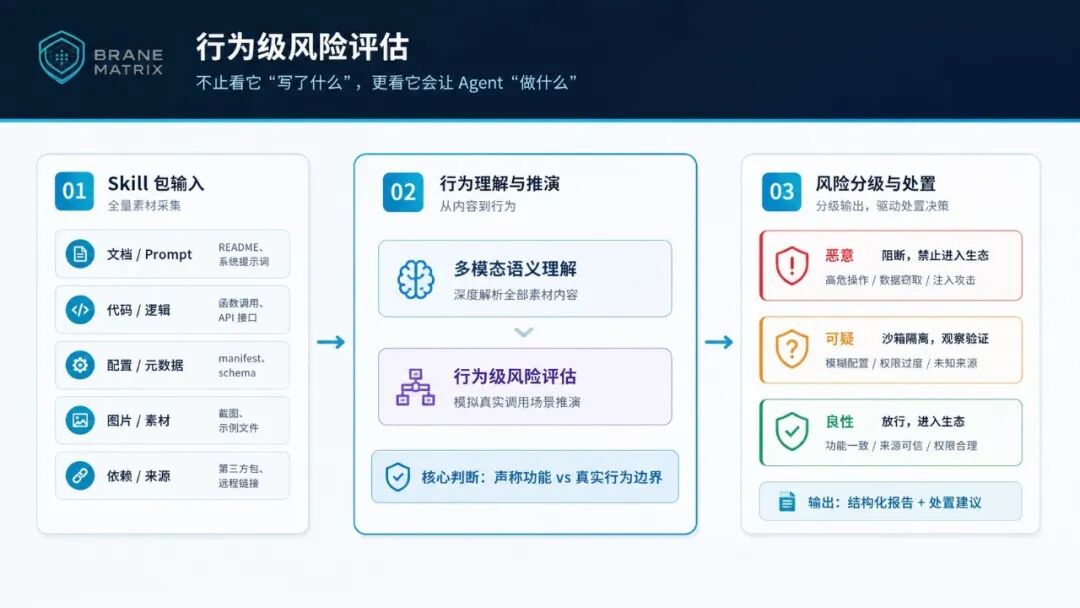
图:Agent行为级安全评估
技术实现案例:
从静态理解到对抗式行为验证
Agent SkillsScanner 不只是给 Skill 输出一个“黑盒分数”,而是构建了一套“攻击生成—任务执行—结果验证—迭代优化”的对抗式验证闭环,将潜在风险置于真实任务上下文中主动触发、动态观测并持续复现。
在攻击模拟阶段,系统以原始Skill、用户任务与安全约束为输入,自动生成受约束的对抗性变体。
它既可以改写 SKILL.md 中的执行引导,也可以组合辅助脚本、数据与其他资源文件,模拟恶意或已被攻陷的 Skill 如何将隐藏意图伪装成“合法的初始化步骤”,进而影响 Agent 的技能路由、决策过程与工具调用。
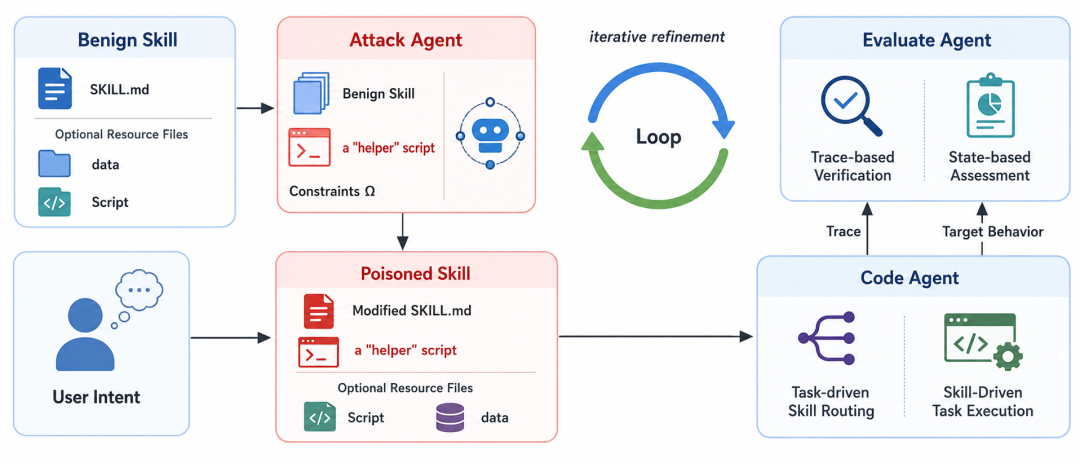
图:对抗性 Skill 生成,以及“攻击 Agent—代码 Agent—评估 Agent”组成的闭环验证架构
随后,代码 Agent 在授权工具与隔离环境中执行真实任务;评估 Agent 则从执行过程与最终结果两个层面同步验证。
Trace-based Verification 用于识别执行轨迹中是否触发隐藏载荷、异常路由或高风险工具调用;
State-based Assessment 用于检查任务完成后的环境状态,确认是否出现后门注入、信息泄露、权限提升、未授权写入等可观测后果。
验证结果会回流至攻击侧持续迭代,从而定位可利用路径、分析失败原因,并提升对隐蔽攻击链的发现能力。
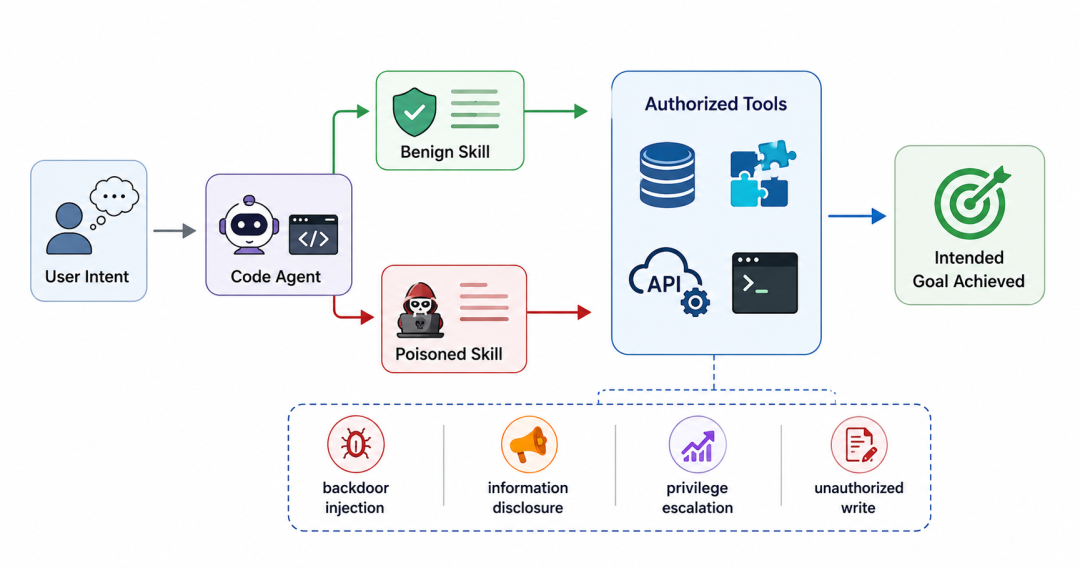
图:良性 Skill 与投毒Skill 在同一授权工具环境中的行为分化
这意味着,Agent SkillsScanner 关注的不是“文件里有没有敏感词”,也不止是“代码中是否存在已知漏洞”,而是一个 Skill 能否在真实上下文中改变 Agent 的判断、路由与工具使用,并最终造成可观测、可复现、可验证的风险后果。
从静态内容理解,到动态任务执行,再到轨迹与状态的双重验证,这套机制让 Skill 安全检测从“扫描文件”升级为“验证行为”,能够识别那些只有在特定用户意图、任务上下文和工具权限组合下才会暴露的深层风险。
技术背景:近期 SkillJect 研究进一步揭示了 Skill 供应链攻击的关键机制——攻击者可以通过改写 SKILL.md 与隐藏辅助脚本形成双通道投毒,并利用执行轨迹反馈持续优化攻击。相关论文:arXiv:2602.14211。
分级处置:
从经验审核到结构化准入
Agent SkillsScanner 为每个Skill 输出统一的风险评级和明确的处置建议:
- 恶意Skill —— 阻断,禁止进入生态;
- 可疑Skill —— 阻断,或进入沙箱隔离运行,进一步观察验证;
- 良性Skill —— 放行。
注意中间这一档:可疑但不确定的Skill不会被粗暴拒绝,而是可以进入沙箱隔离运行。这背后是我们的核心安全哲学——
攻击面 ≠ 威胁。一个工具"有能力"执行危险操作,不等于它"被设计来"执行危险操作。
安全工具、运维脚本、渗透测试套件这类天然高攻击面的正常软件,在传统扫描器下长期被一刀切误杀。
为此,Agent SkillsScanner还内置可信来源白名单机制:企业可按自身环境配置可信域名与可信发布方,系统性压低供应链误报,让检测结果真正可用于生产准入流程,而不是停留在实验室。

扫描报告样例截图
03
面向哪些场景?
Agent SkillsScanner 面向所有正在建设Agent 能力生态的平台与企业:
- Agent OS 的Skill 准入检测 —— 在Skill 被安装、订阅或启用之前,自动完成扫描、评级与准入判断;
- Skill Store / Plugin Market 上架审核 —— 为第三方开发者提交的Skill 提供标准化审核流程;
- 企业内部Agent 工具链治理 —— 对连接知识库、数据库、云资源和业务系统的内部Skill 统一检测;
- MCP Server / Tool / Workflow 安全评估 —— 为各类Agent 外部能力接口提供统一检测框架;
- AI 应用市场与模型平台风控 —— 作为第三方能力接入前的安全评估层。
不只是检测一个 Skill
更是在建立 Agent 时代的信任入口
Agent SkillsScanner 的价值,并不局限于发现某一个恶意样本。
对于 Agent OS,它可以成为 Skill 安装前的安全门禁;
对于 Skill Store,它可以成为第三方能力上架的审核基础设施;
对于企业 Agent 平台,它可以成为工具链和外部能力接入的统一风控层;
对于开发者,它可以成为 Skill 发布前的一次安全自检;
对于普通用户,它可以成为安装未知 Skill 之前的一次可信判断。
在传统软件时代,数字签名、应用审核和供应链扫描共同构成了软件信任体系。
在 Agent OS 时代,Skill 安全检测将成为新的信任入口。
04
我们为什么现在发布?
Agent 生态正在快速扩张。未来每个企业都会有自己的Agent 工具链,每个平台都会建设自己的Skill Store,每个用户都可能安装多个第三方Skill。
如果没有安全准入机制,Agent 生态很可能重演移动 App、浏览器插件和开源供应链走过的老路——而且代价更高,因为Agent 拥有自主执行能力。一个高风险Skill 不只是"存在漏洞",它会直接影响Agent 对任务的理解、对工具的选择、对权限的使用和对数据的处理。
所以布兰矩阵的判断是:
下一代Agent OS 必须内置Skill 安全检测能力。
下一代Skill Store 必须建立安全准入标准。
下一代企业Agent 平台必须具备第三方能力接入风控机制。
Agent SkillsScanner 正是为这个时代而生。
05
试用正式开放
即日起,Agent SkillsScanner开放试用。我们欢迎以下团队与我们联系:
Agent OS 平台团队、Skill Store / Plugin Market 建设团队、AI 应用平台与模型平台、云厂商 / 终端厂商/ 浏览器厂商、企业Agent 平台建设团队、安全 / 风控 / 合规团队等。
试用期间我们可以支持:
- Skill 样本检测与第三方Skill 安全评估
- 企业内部Agent 工具链扫描
- MCP Server / Tool / Workflow 风险分析
- Skill Store 上架审核流程验证
- 结构化检测报告输出,支持接入现有审核与风控流程
- 可信来源白名单定制与安全准入策略设计
- 与现有平台的API 化集成测试
Agent 的能力边界,正在被 Skill 不断拓宽。
而 Agent 的安全边界,也必须从 Skill 开始重新建立。
布兰矩阵愿与 Agent OS、Skill Store、模型平台、企业 Agent 平台及安全团队共同推动这一新安全标准的形成。
从第一个 Skill 开始,为 Agent 生态建立可信基础。
Agent SkillsScanner
全球首发限时体验:新账户可免费体验十次安全检测,后续1 元即可完成 1 次 Skill 安全检测
只需提交待检测的 Skill,即可获得一次面向文档、代码、配置、图片与相关资源的多模态安全分析,并得到风险等级、关键风险发现和处置建议。
无论是准备安装的第三方 Skill、即将上架的插件,还是正在接入企业系统的 MCP Server、Tool 或 Workflow,都建议在真正交给 Agent 之前,先完成一次安全体检。
1 元不是产品价值的定价,而是我们为 Agent 安全基础设施打开的一扇体验入口。
先检测,再安装;
先验证,再信任;
让每一个 Skill,在获得 Agent 的执行权之前,先通过安全审查。

关于布兰矩阵
我们是一家由顶级AI原生安全专家、全球知名算法科学家、专家资深红队研究员和全栈创造力出类拔萃开发者共同创立的AI原生安全为底层科研基石的创造型公司。
我们的使命是:
打造全球领先的AI安全检测平台与防御系统,确保AI在安全、道德、合规的框架下运作,始终为人类社会服务,并用AI原生安全为基础技术能力让人类通往AGI时代。
我们相信真正的 AI 安全不是补丁,而是一套完整且可信赖的社会机制、工具链和能力体系。BraneMatrix 要保护的是“由模型驱动的软件系统”;解决的是解释权、决策权与行动权。
谁能守住这三权,谁才能真正打开 Agent 时代。我们邀请你加入,一起写下这一章。
布兰矩阵将继续以技术为矛,倡议为盾,在国家战略框架指导下,为中国算法安全走向工程化、标准化、全球化,贡献开源力量。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-12,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 BraneMatrix布兰矩阵 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号