给 Agent 写 Skill,禁令可能比不写还糟:Superpowers 6.0 的 writing-skills 怎么把规则写对
原创
给 Agent 写 Skill,禁令可能比不写还糟:Superpowers 6.0 的 writing-skills 怎么把规则写对
原创
术哥
发布于 2026-06-23 21:17:51
发布于 2026-06-23 21:17:51
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 147 篇,AI 编程最佳实战「2026」系列第 44 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。

封面图:形态匹配失败方法论信息图
封面:四类失败对应四种正确形态,反直觉结论——禁令可能最差
说明:本文内容基于 Superpowers 开源项目源码(github.com/obra/superpowers)和相关官方文档分析整理,文中的方法论结论来自项目
skills/writing-skills/目录的源码与配套文档。文中的实验数据和测试结论均保留官方原文的限定条件(特定场景下的测试,非普适定律),方法和建议仅供参考,实际效果请以你自己的 agent 环境和场景测试结果为准。如果有实际使用经验,欢迎在评论区分享交流。
给 AI agent 写规则,多数人的本能反应是写禁令:不要做 X、禁止 Y、绝不 Z。这很符合直觉——你不想要的结果,就明确说不。
但开源 skill 库 Superpowers 的源码里记着一条反直觉的实验结论:在他们做的措辞对照测试中,禁令组比配方组产生了更多不受欢迎的内容,分布完全分离,甚至比完全不写指导的对照组还有变差的趋势。
换句话说,某些场景下,你辛辛苦苦写了一堆不要,效果还不如什么都不写。
这背后的方法论叫 Match the Form to the Failure(让指导的形态匹配失败的形态),是 Superpowers 6.0 版本沉淀的一套工程化规则设计方法。它回答的问题很具体:给 AI agent 写 skill、prompt、system instruction 时,什么样的指导形态才真正有效,什么样的会适得其反。
翻了一遍这套方法的源码和配套文档,我觉得它对写过 agent 规则的人的启发,远不止于 Superpowers 本身——这是一套可以迁移到任何 agent prompt 设计的方法。下面把关键发现整理出来。
1. 先分类失败,再伸手拿形态
这套方法的核心主张:在写指导之前,先分类基线失败(baseline failure)的类型。 因为能防住一种失败的写法,在另一种失败上会可测量地反噬(measurably backfires)。
源码(writing-skills/SKILL.md:463-468)给了一张映射表,把失败分成四类,每类对应一种正确形态和一种错误形态:
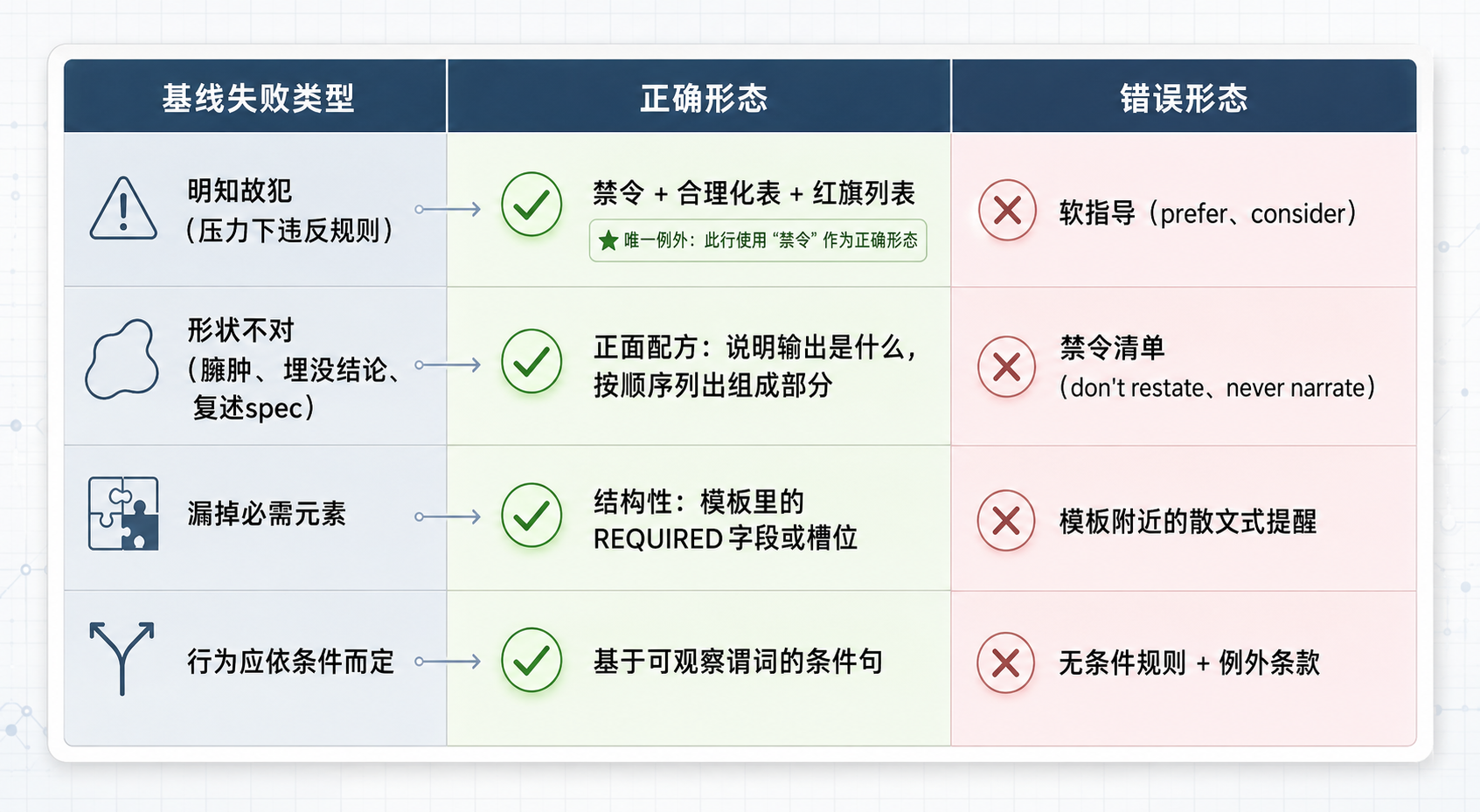
失败基型映射表
图 1:四类失败基型的形态映射——左列失败类型,中列正确形态(绿),右列错误形态(粉),禁令只在明知故犯那行是正确选择
基线失败类型 | 正确形态 | 错误形态 |
|---|---|---|
压力下违反规则(明知故犯) | 禁令 + 合理化表 + 红旗列表 | 软指导(prefer、consider) |
遵守了,但输出形状不对(臃肿 prompt、埋没结论、复述 spec) | 正面配方:说明输出是什么,按顺序列出组成部分 | 禁令清单(don't restate、never narrate) |
漏掉必需元素 | 结构性:模板里的 REQUIRED 字段或槽位 | 模板附近的散文式提醒 |
行为应依条件而定 | 基于可观察谓词的条件句(if the brief exists, reference it) | 无条件规则 + 例外条款 |
这张表的关键不在四类失败本身,而在错误形态那一列。你会注意到一个规律:每一行的错误形态,恰好是很多人写规则时的默认选择。
形状类失败,错误形态是禁令清单;条件类失败,错误形态是无条件规则加例外条款——这不就是我们平时最顺手的那种写法吗?
然后是那个反直觉结论(SKILL.md:470)。源码原文:
under a competing incentive ('make the prompt self-contained'), agents negotiate with 'don't X'. In head-to-head wording tests on dispatch-prompt guidance, the prohibition arm produced clearly more of the unwanted content than the recipe arm (fully separated distributions), and trended worse than even the no-guidance control.
翻译过来:在 dispatch-prompt 指导的对照测试里,禁令组比配方组产生了明显更多的不想要内容(分布完全分离),而且比不写任何指导的对照组还有变差的趋势。
这里有个限定条件必须说清楚——这是在特定场景(dispatch-prompt guidance 加上让 prompt 自包含的竞争性激励)下做的,不是普适定律。源码的建议是:micro-test 你自己的场景,别假设,但永远不要默认伸手拿禁令(never reach for the prohibition by default)。
源码还给了两条对所有形态都适用的铁律(SKILL.md:472-474):
- 不要加细微差别条款(nuance clause)。Don't X unless it matters 这种写法会重新打开谈判空间——给一个有效的配方加一个除非,在同样的测试里让它从一致(consistent)退化到嘈杂(noisy)。
- 例外条款无法限定作用域(exemption clauses don't scope)。这条限制不适用于代码块这种话,实际上仍然会抑制代码块。如果输出的一部分必须豁免,应该重新组织结构,让规则够不到它。
这两条铁律的本质是同一个意思:一旦你写了规则,agent 就会按字面执行,包括你写的例外——例外本身也是一种干扰。
2. 配方为什么比禁令更硬
那为什么禁令在形状类问题上会反噬?
源码(SKILL.md:470)给了一句很精炼的解释:
A recipe leaves nothing to negotiate: the output matches the stated shape or it doesn't.
配方不留谈判空间——输出要么符合声明的形状,要么不符合。而禁令(don't X)给了 agent 在竞争性激励下谈判的余地。
这里的谈判不是拟人化。它指的是:当 agent 同时面对多个目标时(比如让 prompt 自包含 和 不要复述 spec),禁令是一个负面约束,它告诉 agent 不能做什么,但没有告诉 agent 应该做什么。于是 agent 会自己决定怎么平衡这两个目标——而这个平衡往往不是你想要的。
配方正好相反。它是一个正面契约:你的输出必须包含这几个部分,按这个顺序。agent 没有自由发挥的空间,只能照着填。
举个具体的对比。假设你想让 reviewer 的报告结构清晰,不要写成散文。
禁令形态会写成:
不要写成长篇大论。
不要复述 spec。
不要在开头铺垫太多。配方形态会写成(这是 Superpowers 里 task-reviewer-prompt 的真实模板,task-reviewer-prompt.md:139-166):
## Output Format
### Spec Compliance
- ✅ Spec compliant | ❌ Issues found: [what's missing/extra/misunderstood, with file:line references]
- ⚠️ Cannot verify from diff: [...]
### Strengths
[What's well done? Be specific.]
### Issues
#### Critical (Must Fix)
#### Important (Should Fix)
#### Minor (Nice to Have)
### Assessment
**Task quality:** [Approved | Needs fixes]
**Reasoning:** [1-2 sentence technical assessment]前者给了 agent 一堆不要,但没说报告应该长什么样。agent 可能会想:不复述 spec,那我总结一下总行吧?然后写出一堆你以为它不会写的东西。
后者直接定义了报告的骨架:四个部分,每个部分填什么。reviewer 的输出要么符合这个形状,要么不符合——一目了然,没有灰色地带。
这就是 Match the Form to the Failure 里形状类失败要用正面配方的实际效果。配方不留谈判空间,不是一句口号,而是结构上的必然。
3. 两份真实 skill 代码的形态对照
光说理论不够直观,来看看 Superpowers 自己的 skill 是怎么选形态的。
先看纪律类的典型:test-driven-development/SKILL.md。这个 skill 要防的失败是 agent 在压力下违反 TDD 规则(比如已经写了 200 行代码,才想起来没写测试)。它的形态选择是全套禁令工具包:
NO PRODUCTION CODE WITHOUT A FAILING TEST FIRST
Write code before test? Delete it. Start over.配套的还有一句基础原则(SKILL.md:14):违反规则的字面,就是违反规则的精神。 然后是一张合理化表(rationalization table,第 258-271 行),列出 11 个常见借口和对应的现实,比如:
借口:This case is different because... 现实:显式反驳
再往后是 13 条红旗信号(red flags,第 272-288 行),告诉 agent 什么时候该立即停下重来。
这里大量使用 MUST、Never、No exceptions 这种权威语言。这和禁令在形状类问题上反噬并不矛盾——因为 TDD 要防的是明知故犯,属于纪律类失败,禁令形态在这里是正确的。

形态对比图
图 2:两份真实 skill 的形态对照——左为 TDD 的禁令工具包(禁令+合理化表+红旗),右为 task-reviewer 的配方骨架(四段式 Output Format),形态选择决定 skill 整体结构
再看形状类的典型:前面提到的 task-reviewer-prompt.md。这个 skill 要防的失败是 reviewer 的输出形状不对——可能写成散文、可能埋没结论、可能结构混乱。
它的主形态是那个 Output Format 配方模板,没有用 don't write essays、never bury the verdict 这种禁令清单。
有意思的是,它在第 118-121 行确实用了一句禁止式:
Your final message is the report itself: begin directly with the spec-compliance verdict. Every line is a verdict, a finding with file:line, or a check you ran — no preamble, no process narration, no closing summary.
这里的 no preamble 看起来像禁令,但它服务的是配方的收尾约束,不是主形态。整个 skill 的骨架仍然是报告长什么样,而不是不要写成什么样。
这两份代码对照着看,形态选择就不是一个抽象原则了——它实实在在地决定了 skill 的整体结构长什么样。
顺带提一个相关的纪律类禁令。subagent-driven-development/SKILL.md 第 381-383 行禁止在派发 reviewer 时预判结论:
Tell a reviewer what not to flag, or pre-rate a finding's severity in the dispatch prompt ('treat it as Minor at most') — the plan's example code is a starting point, not evidence that its weaknesses were chosen
这也是一个不要做 X 的禁令,但它针对的是 reviewer 在压力下倾向于减轻严重程度的纪律类失败,所以禁令形态是对的。
如果你也在给 agent 写规则,不妨对照一下:你写的那条规则,防的是明知故犯,还是形状不对?这两种情况用的形态应该完全不同。你在项目里写过类似的 agent 规则吗?欢迎在评论区聊聊你踩过的形态选择的坑。
4. description 字段的隐蔽陷阱
形态选择还有一个容易被忽略的地方:skill 的 description 字段。
Superpowers 的源码(writing-skills/SKILL.md:154-158)记录了一个实验发现:当 description 写了工作流摘要时,agent 可能会跟着 description 做,跳过 skill 正文。
具体例子很说明问题。有个 skill 的流程图明明定义了两阶段 review(先 spec 合规,再代码质量),但 description 写成了 code review between tasks(任务之间做代码审查)。结果 agent 只做了一次 review——它读了 description,觉得自己已经知道该干什么了,就没去读正文里的流程图。
当 description 改成只写触发条件(Use when executing implementation plans with independent tasks,不写工作流摘要),agent 才正确读了流程图并执行了两阶段审查。
源码的总结(SKILL.md:158):
Descriptions that summarize workflow create a shortcut agents will take. The skill body becomes documentation agents skip.
摘要工作流的 description 创造了一条 agent 会走的捷径,skill 正文变成了 agent 会跳过的文档。
正确的写法是 description 只描述触发条件,不摘要工作流(SKILL.md:160-172):
# ❌ 摘要工作流:agent 可能跟着这个做,而不是读 skill
description: Use when executing plans - dispatches subagent per task with code review between tasks
# ❌ 太多流程细节
description: Use for TDD - write test first, watch it fail, write minimal code, refactor
# ✅ 只写触发条件,不写工作流摘要
description: Use when executing implementation plans with independent tasks in the current session这个陷阱的本质是:description 是 agent 决定要不要读正文的依据。如果 description 里已经包含了怎么做,agent 就没有动机去读正文里的详细流程。Superpowers 把这个问题单独拎出来,叫 SDO(Skill Discovery Optimization,技能发现优化)陷阱。
5. 用 Micro-Test 验证措辞
说了这么多该怎么选形态,但实际写规则时,你怎么知道自己选的措辞有效?
Superpowers 的答案是:不要靠直觉,要 micro-test(writing-skills/SKILL.md:579-583)。完整的压力场景测试(pressure scenario)是最终关卡,但每次迭代都很慢。micro-test 是在跑昂贵测试前,用最低成本验证措辞本身。
五步方法论:
- 每次调用一个全新上下文样本。用原始 API 调用,或单次 subagent。system prompt 放指导将要生存的真实上下文(完整的 skill 或 prompt 模板),user message 放一个诱使失败的任务。
- 必须包含无指导对照组。如果对照组都不表现出失败,说明没有要修的东西——停下来,不要编写指导。这条很重要:没有基线失败,就不要写规则。
- 每个变体 5 次以上重复。单样本会骗人(Single samples lie)。
- 手动读每个标记的匹配。可以用程序评分,但模板回声和引用反例会伪装成命中;自动化计数会同时高估失败和成功。
- 方差是指标。当指导生效时,重复会收敛到同一种形状。5 次重复出现 5 种不同的解释,意味着措辞没有约束力——先收紧形态,再加词。
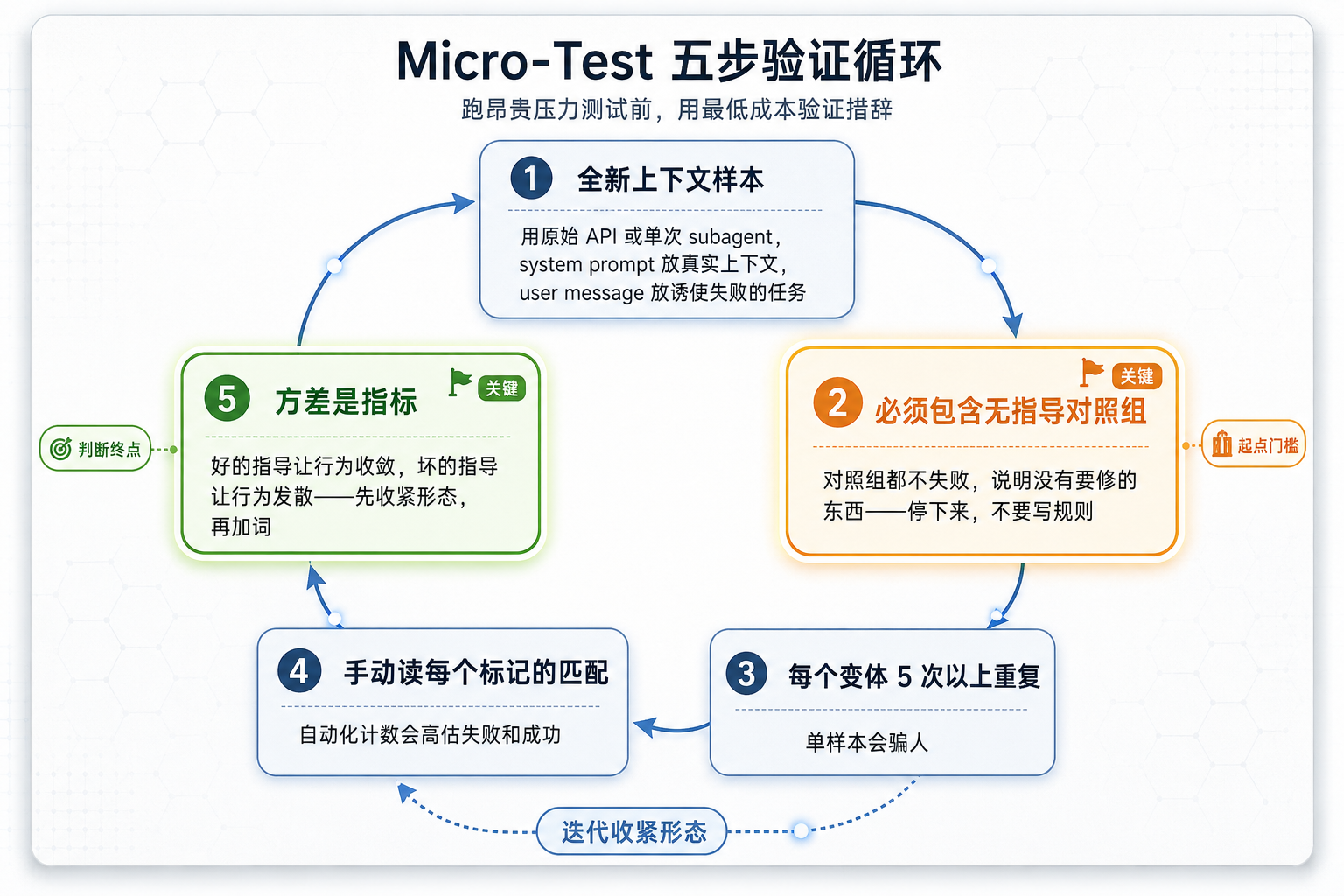
Micro-Test 流程图
图 3:Micro-Test 五步验证循环——无指导对照组是起点门槛(没有基线失败就不写规则),方差是判断终点(发散即收紧形态)
第 5 步值得多说两句。方差是指标这个说法,初读容易滑过去。它的意思是:好的指导会让 agent 的行为收敛,坏的指导会让 agent 的行为发散。
如果你写了条规则,跑 5 次,agent 给你 5 种不同的理解——那不是 agent 的问题,是你的措辞没有约束力。这时候你不应该加更多解释(那往往会让事情更糟),而应该收紧形态,让输出形状更确定。
这个思路对任何写 agent prompt 的人都适用:与其纠结措辞够不够清晰,不如看看重复测试的方差。方差大,说明形态没选对。
最后,micro-test 有它的边界(SKILL.md:585):
Micro-tests verify wording; they do not replace pressure scenarios for discipline skills.
micro-test 验证的是措辞,它不能替代纪律类 skill 的压力场景测试。形状类问题用 micro-test 就够,纪律类问题还得靠完整的压力测试——因为纪律类失败只有在多重压力下才会暴露。
6. 这套方法论的边界与诚实
Superpowers 的这套方法论不是孤立发明。
agentskills.io 的官方实践指南里有一节标题就叫 Match specificity to fragility(让指令的具体程度匹配任务的脆弱程度),原文说:不是 skill 的每个部分都需要同样的指令强度,让具体程度匹配脆弱程度。
这几乎就是 Match the Form to the Failure 的官方同义表述。两者共享同一个洞察:指令不应该全用同一种强度,而应该根据搞错了会怎样来差异化配置。
官方对 description 字段的建议也体现 micro-test 精神:应该说明 skill 做什么 + 什么时候用 + 包含帮助 agent 识别相关任务的具体关键词。
学术研究提供侧面支撑,但要诚实标注边界。两篇 cs.CL 论文值得提:
- Jang 等(2022) 发现了否定句的逆缩放定律:模型越大,在否定句任务上表现反而越差,覆盖 125M–175B 参数(论文:https://arxiv.org/abs/2209.12711)。
- Truong 等(2023) 发现 LLM 对否定词不敏感,无法在否定下正常推理(论文:https://arxiv.org/abs/2306.08189)。
这两篇支持一个底层洞察:LLM 对避免什么的处理,弱于对做什么的处理。 这和 Superpowers 配方优先、禁令慎用的方向一致。
但必须说明边界:这些研究针对的是语言学否定(not、no、never),而 Superpowers 讨论的是指令形态选择(清单、流程图、配方、条件句)。两者层面不同。目前没有找到直接研究指令形态选择有效性的学术论文——这是一个真实的研究空白。
Superpowers 的方法论,以及 agentskills.io 的建议,本质都是实践先行、理论滞后的工程经验总结。它的价值在于经过了大量 skill 的实测验证,而不是因为有什么学术理论背书。
说服心理学这块也有研究支撑(persuasion-principles.md)。Cialdini 的经典研究(2021)提出七大说服原则;Meincke 等(2025)在 28000 次 LLM 对话测试中发现,说服技术把合规率从 33% 提升到 72%,其中权威、承诺、稀缺三个原则最有效。这为纪律类 skill 使用权威语言提供了依据——但要记住,这是纪律类的依据,不是形状类的。不同失败类型,用不同的说服策略,这本身就是 Match the Form to the Failure 的延伸。
总结
把这套方法论浓缩成几条可带走的判断:
- 写规则前先分类失败。明知故犯用禁令,形状不对用配方,漏元素用结构模板,条件行为用基于谓词的条件句。选错形态会反噬。
- 禁令不是默认选项。在形状类问题上,禁令可能比无指导还差。配方不留谈判空间,这是它的核心优势。
- 不要给有效配方加 nuance。除非会让一致的配方退化成嘈杂。例外条款也无法限定作用域。
- description 只写触发条件。摘要工作流的 description 会让 agent 跳过正文。
- 用 micro-test 验证措辞。5 次重复,方差是指标。没有基线失败,就不要写规则。
- 诚实面对边界。这套方法的实证基础是工程经验,学术研究只提供侧面支撑,形态选择有效性的直接研究目前还是空白。
说到底,Match the Form to the Failure 教的不是某种具体写法,而是一种工程态度:给 agent 写规则,和写代码一样,需要测试、需要迭代、需要承认直觉会出错。
如果你也在写 agent 的 skill 或 system prompt,下次动手前可以先问自己一句:我要防的失败,是哪一类? 这个问题答对了,后面的事会顺利很多。
如果你身边有同事在折腾 agent prompt,转发给他看看——形态选择这事儿,踩坑的人不少。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号